MaskFormer
借助了DETR 的核心思想,不过将原本的目标检测任务迁移到了语义分割和全景分割领域。
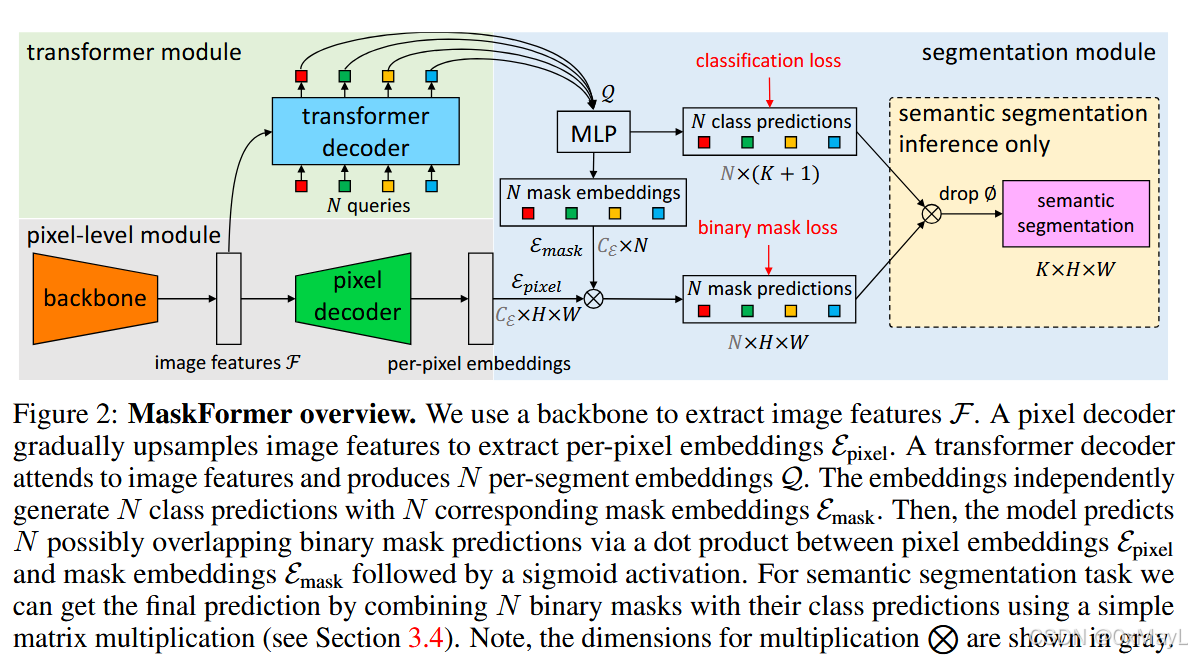
方法
前向过程
- 和DETR一样,使用骨干网络获取一个低分辨率特征图。再使用一个FPN获得分辨率与输入图像相同的特征图(缘于语义分割任务的特点)。
 + 设置N个查询向量,然后每个查询向量作为Q,特征图作为K和V,进行交叉注意力计算 ,得到对应N个段嵌入。
+ 设置N个查询向量,然后每个查询向量作为Q,特征图作为K和V,进行交叉注意力计算 ,得到对应N个段嵌入。

- 然后和DETR一致,这N个段嵌入首先通过一个简单的MLP得到维度为N×(K+1)N\times (K+1)N×(K+1)的类别概率分布,也是引入了一个No object类别,K是目标数。

- 不同的是,需要生成掩码,不能直接通过段嵌入+线性层得到。于是段嵌入会被映射为掩码嵌入 ,掩码嵌入与特征图进行QK矩阵乘法操作,得到N×H×WN\times H\times WN×H×W个语义掩码。
- 需要注意的是:这些掩码不是二值的!这些掩码不是二值的!这些掩码不是二值的!,只经过了sigmoid进行简单的激活。
训练损失
- 损失与DETR的原理保持基本一致
- 生产的N个软掩码与M个真实掩码进行匹配。
如何定义真实掩码GT mask?
图像中可能有x个类别的注释,这x个注释可以看作是一个真实掩码。对于示例分割,还要求这x个注释互相不连通(也就是属于同一类别且连通的掩码才是真实掩码)。
- 匹配上非no object类 的计算掩码损失:就是语义分割任务中常用的dice和focal损失
- 所有查询对应的类别概率分布都要计算交叉熵损失 。
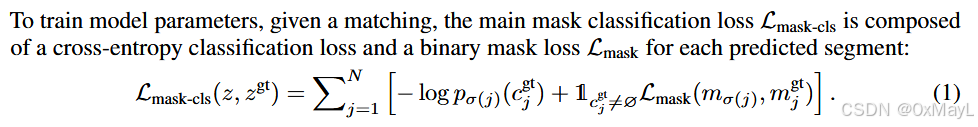
推理方式
- 对于一般的语义分割任务:每一个查询向量的类别概率分布p_i×\times×生成的软掩码m_i,最后求和即可,得到H*W的类别概率分布,最后取最大值即可。
- 注意:对于属于no object的类别不进行任何计算 。
