摘要
本周学习了自监督学习在语音与影像领域的技术路径与发展现状。课程从文本自监督基础框架出发,聚焦语音与影像数据的预训练方法,包括生成式建模、预测式学习与对比学习三大方向,并进一步介绍了无需负样本的Bootstrapping及正则化方法VICReg等新兴范式,充分体现了自监督技术在多模态场景下的强适应与泛化能力。
abstract
This week, we studied the technical approaches and developmental trends of self-supervised learning in the fields of speech and visual data. Starting from the basic framework of text-based self-supervision, the course focused on pre-training methods for speech and image data, covering three main directions: generative modeling, predictive learning, and contrastive learning. It further introduced emerging paradigms such as negative-sample-free Bootstrapping and the regularization-based method VICReg, fully demonstrating the strong adaptability and generalization capability of self-supervised techniques in multimodal scenarios.
一,自监督学习
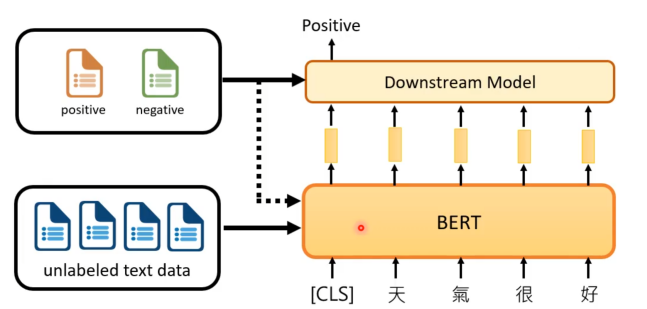
回顾了自监督学习在文本领域的应用,以BERT为例:它通过无标签文本进行预训练,能为每个输入字符生成对应向量。为执行情绪分析等具体任务,需在BERT生成的向量基础上,利用有标签数据训练一个分类模型,并可进一步对BERT本身进行微调,使其更好地适应下游任务。
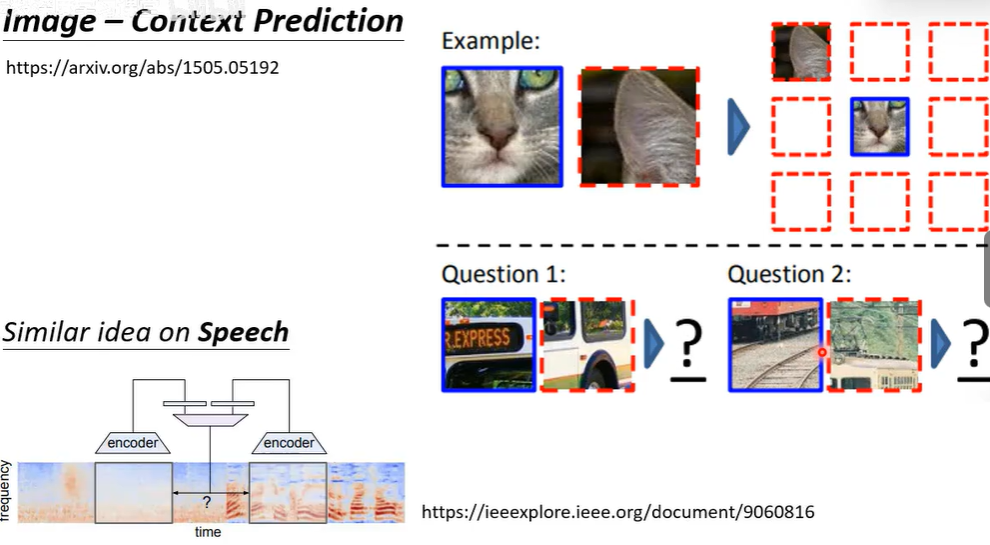
二.语音和影像自监督式学习
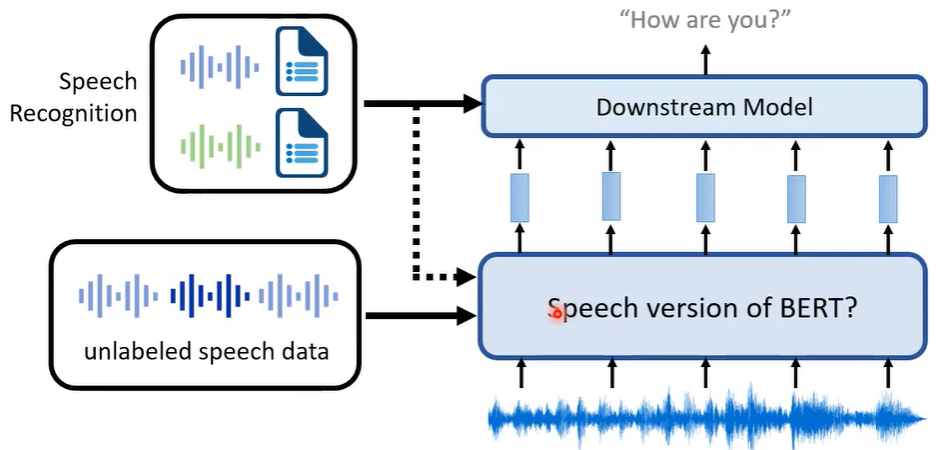
自监督学习通过设计预训练任务(如对比学习中的wav2vec 2.0和掩码重建中的HuBERT),让模型从海量无标签语音中自动学习高质量的通用语音表示。其核心思想是利用掩码并预测等自生成监督信号,迫使模型理解语音的深层结构和内容。学到的表示可作为强大特征,通过"预训练+微调"范式,显著提升语音识别、语音翻译、说话人验证等下游任务的性能,并大幅减少对标注数据的依赖。
自监督学习在图像领域旨在让模型无需人工标注,直接从图像本身挖掘监督信息来学习有效的视觉特征。其主流技术路径可大致分为两种:一是基于实例判别的方法,例如让模型学会将同一张图片经过不同裁剪、变色等变换后的版本视为相似,而与其他任意图片的版本区分开,从而学习对形变鲁棒的特征;二是基于掩码重建的方法,通过随机遮盖图像的大部分区块,然后驱使模型根据剩余的可见上下文来预测被遮盖部分的像素或高级语义,以此训练模型掌握图像的结构与组成规律。这些预训练得到的通用视觉模型,为后续的图像理解、分析与生成任务提供了强大的基础,显著降低了特定任务对标注数据的需求