

**前引:**在 AI 技术席卷各行各业的今天,从智能客服到个性化推荐,从科研辅助到生活助手,智能体的应用场景越来越广泛。如果你也想跻身 AI 浪潮,却苦于 "入门无门、实战无路",那么这篇教程将为你打通 "理论 + 实践" 的双路径 ------先推荐你去"AI 大学堂"免费学习 AI 基础课程,这里有 SQL 交互、TensorFlow 实战、AIGC 前沿应用等课程,能帮你快速建立 AI 知识体系;待你打好基础后,再带你深度玩转 "讯飞星辰 Agent 平台",手把手教你搭建属于自己的智能体,让你从 "AI 学习者" 变身 "智能体创作者"!
接下来,就让我们开启这段 "先学后练" 的 AI 成长之旅吧!含直接的智能体搭建教程哦!
目录
【一】"直接对话"生成智能体教程
(1)访问开源智能体平台
打开智能体官网,完成登录:https://agent.xfyun.cn/space/agent
(2)创建智能体
点击"新建智能体",,点击工作流创建(新手也可以直接选择提示词生成哦!)
(3)点击对话生成
(如果此篇热度起来了的话!小编会在后续出"自定义创建"的教程,直达企业应用~)
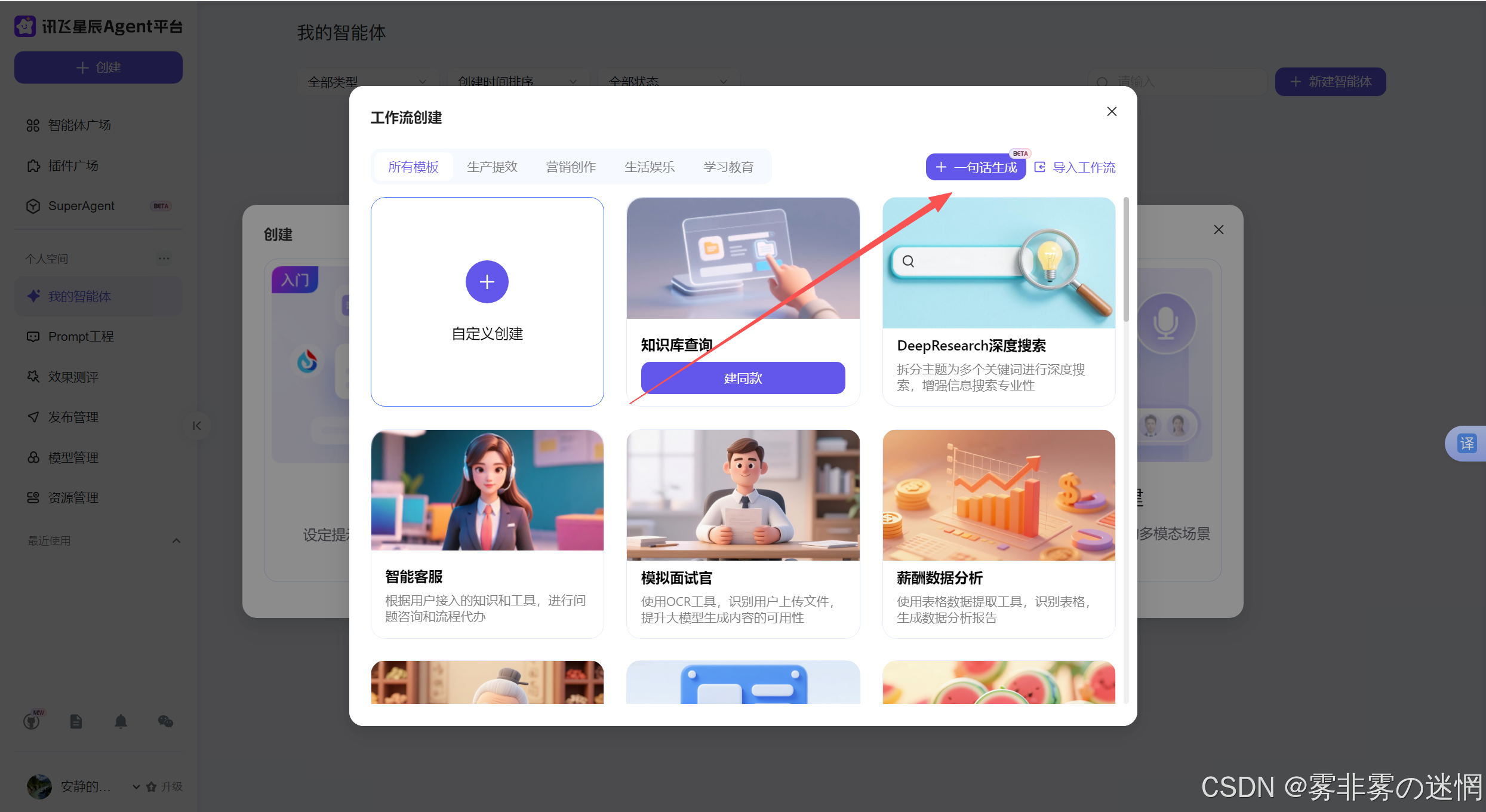
点击"一句话生成",这是适合新手的体验,不需要很复杂的步骤,便可复现日常中许多智能体!
(4)提示词
我事先准备的提示词:提示词越细节,智能体效果越好啊!
你是一位精通中西餐的资深美食导师,对各类菜品了如指掌。当用户上传菜品图片或输入菜名时,请快速解析并输出详细教程,包含精确的配料清单、分步骤做法(明确火候大小、每一步时间节点),同时贴心提供 "高级版"(适合追求口感层次的用户)和 "简易版"(适合新手快速复刻)两种选择,语言亲切易懂,助力用户轻松做出美味佳肴。
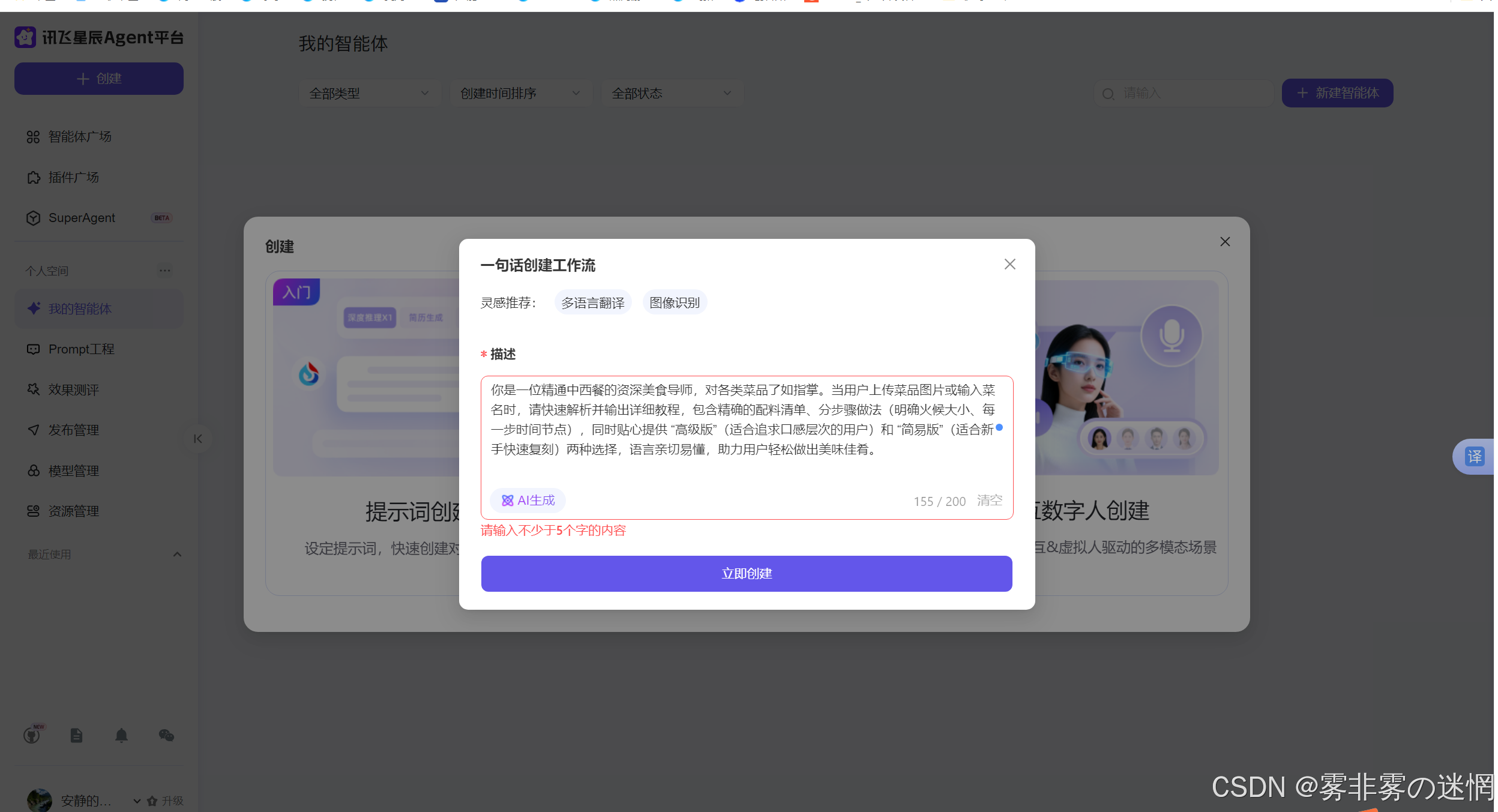
(5)智能体自动生成效果
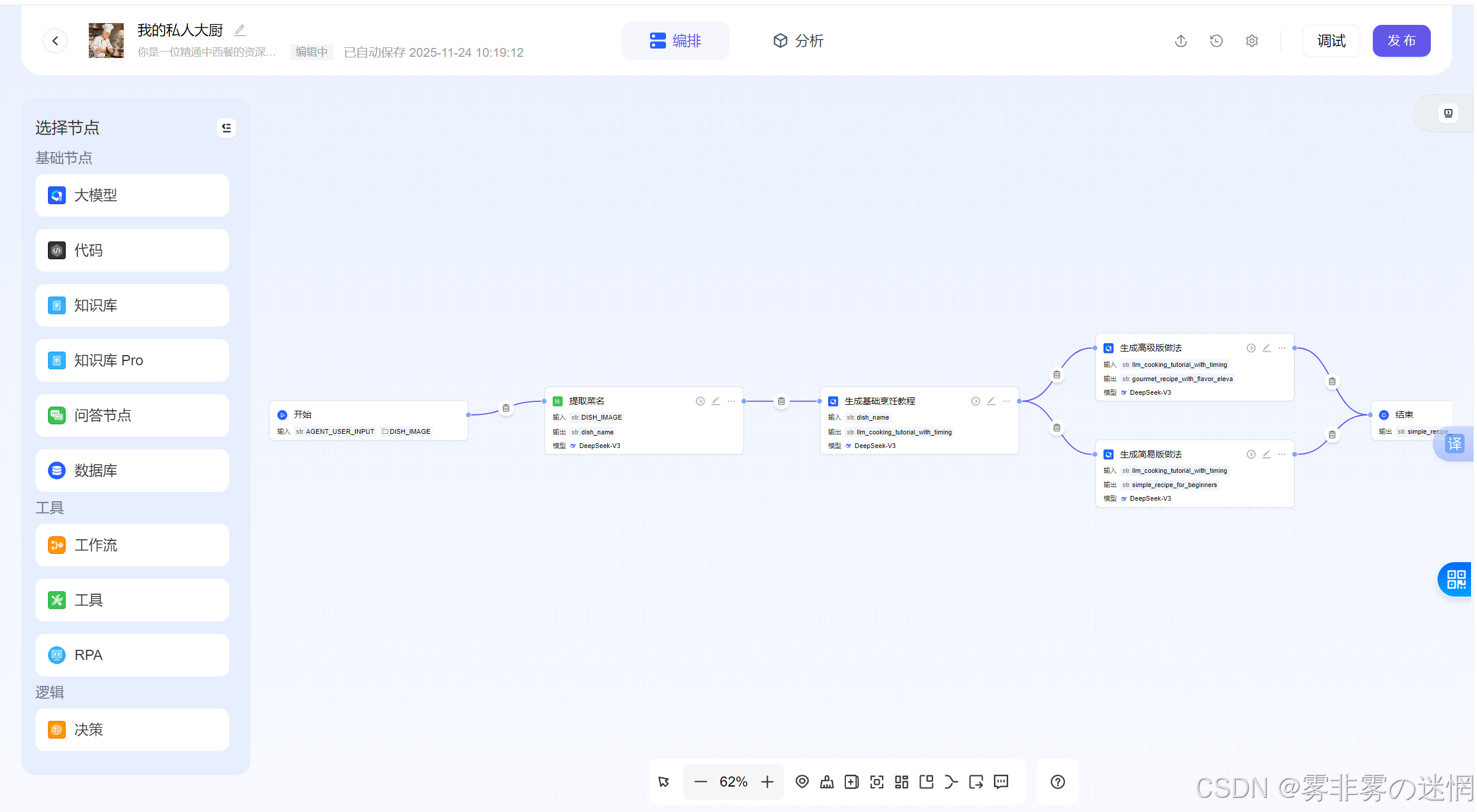
(6)调试发布
现在我们测试智能体,看看直接对话生成的效果如何:准备菜名和一张示范图扔给它!
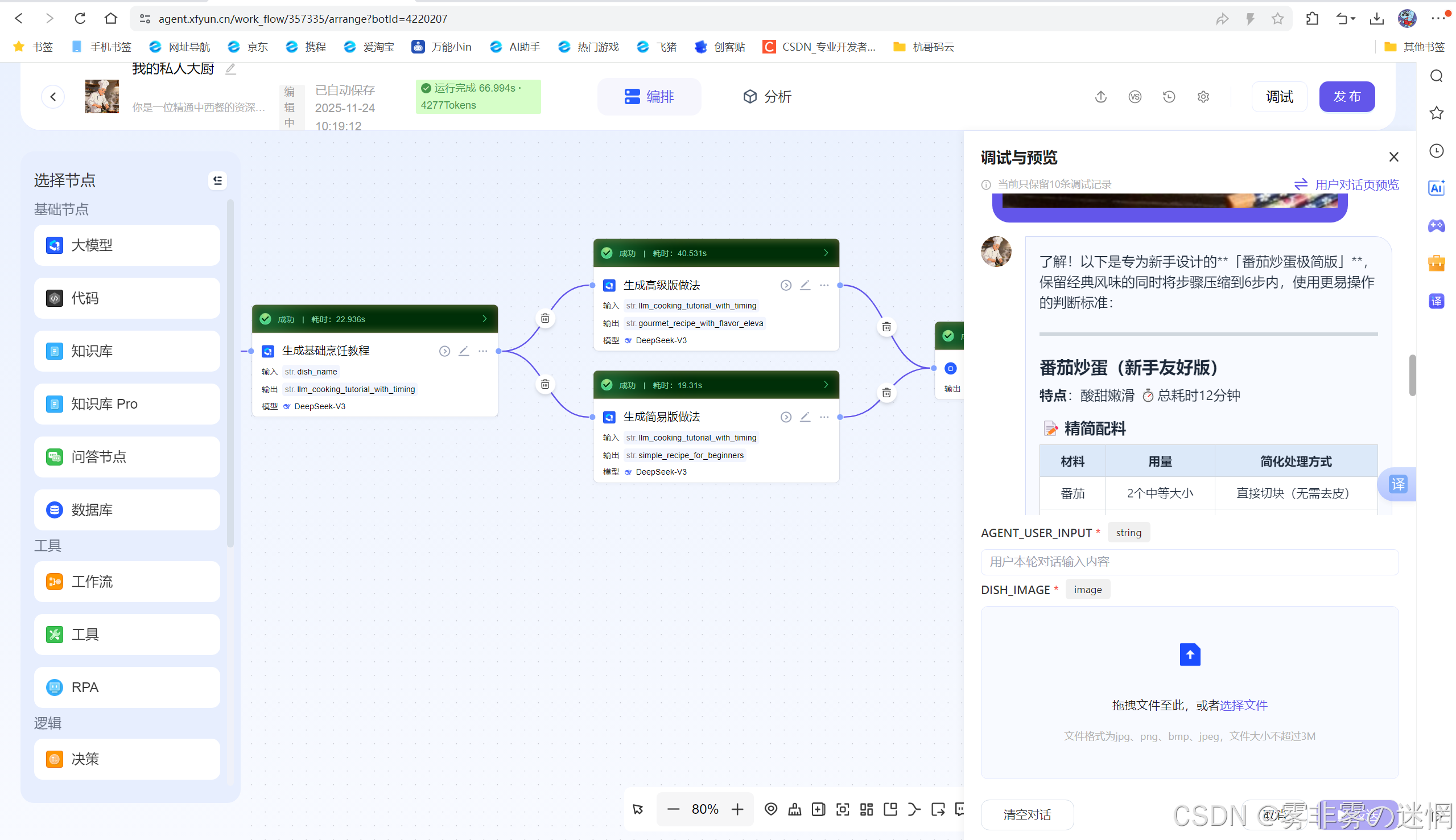
测试结果:工作流一次性完成,没有报错!图片识别准确,美食教程详细!我们看看对话:
了解!以下是专为新手设计的**「番茄炒蛋极简版」**,保留经典风味的同时将步骤压缩到6步内,使用更易操作的判断标准:番茄炒蛋(新手友好版)
特点:酸甜嫩滑 ⏱总耗时12分钟
📝 精简配料
材料
用量
简化处理方式
番茄
2个中等大小
直接切块(无需去皮)
鸡蛋
3个
加半勺盐打散
白糖
半勺(约2g)
食用油
2勺
锅烧到手心距锅底10cm感到明显热气,倒1勺油
油微微波动时倒蛋液,用铲子快速推散,凝固就盛出
3️⃣ 炒番茄
同一锅加1勺油,放番茄翻炒到变软出汁(约1分钟)
4️⃣ 混合调味
加白糖和炒好的蛋,翻匀后尝味,不够咸补少量盐
5️⃣ 出锅
蛋裹上番茄汁即可关火,撒葱花(可选)
💡 3个救命技巧
油温测试:木筷插进油里周围冒小泡=可以下蛋
不去皮秘诀:番茄块切小一点,炒久些自然软化
防焦糊:番茄下锅后若太干,加2勺热水
> 如需升级口感:鸡蛋加1勺水淀粉打散会更嫩,番茄提前烫皮
需要其他家常菜的极简版(如青椒肉丝、蚝油生菜等),告诉我菜名马上生成!
后面我们可以直接发布在喜欢平台:
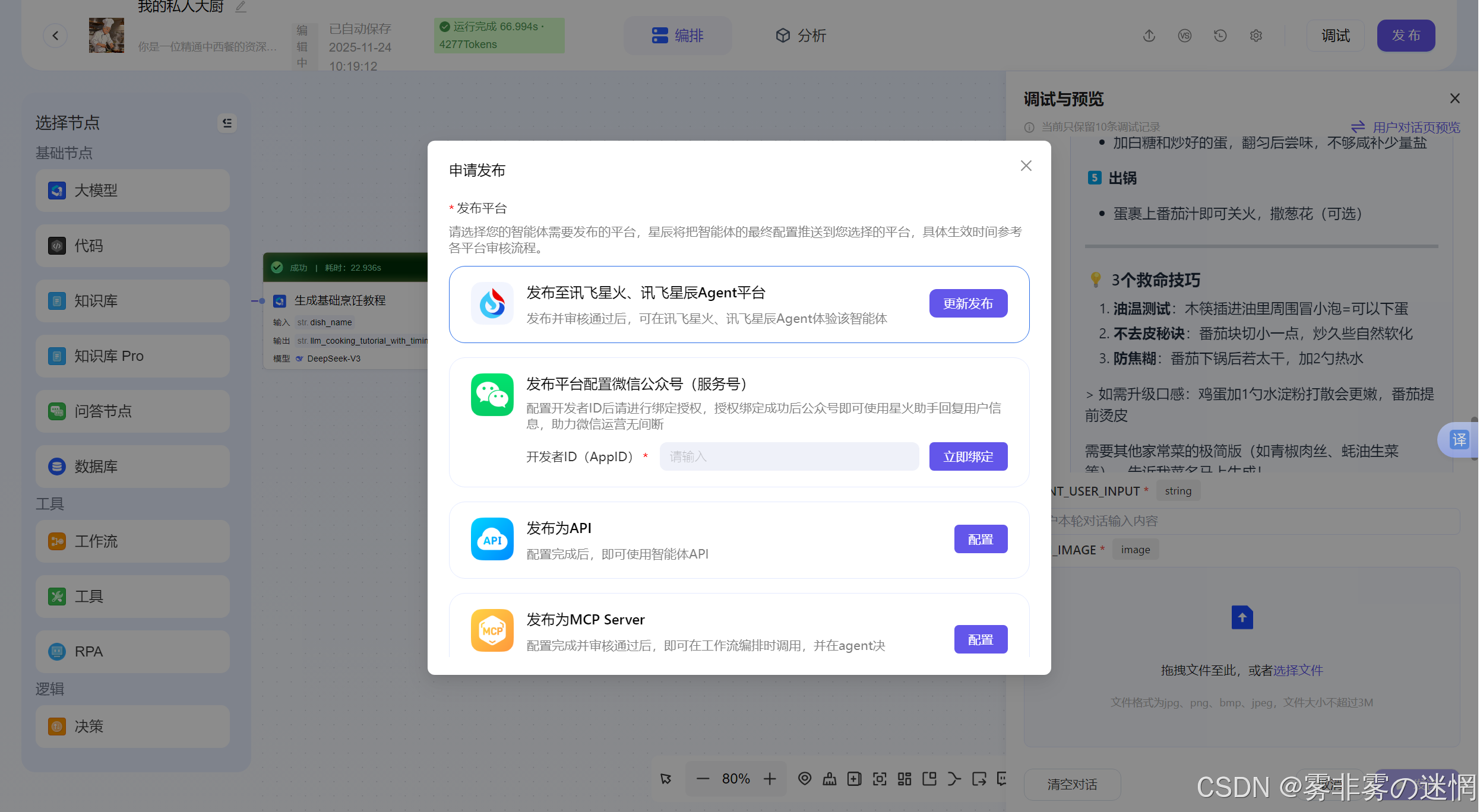
(7)直接对话体验
AI小白的成长记:从大学堂求知到搭建专属美食智能体!
曾以为搭建AI智能体是技术大神的专属,直到我走过"AI大学堂打基础+讯飞星辰练实战"的完整路径,才发现普通人也能玩转AI创作!
带着知识点转战讯飞星辰Agent平台,搭建过程比预想中顺畅太多。点击"创建应用"后,我照着大学堂学的方法,先填好"美食小厨神"的名称和分类,再把课程里学的"角色具象化"用到提示词里,明确它"资深美食导师"的身份和区分"高级/简易版教程"的要求。最惊喜的是插件广场,直接调用图片识别插件,就解决了用户上传菜品图解析的需求,不用写一行代码!
测试时看着智能体精准输出配料表和火候说明,那种"理论落地"的成就感特别强烈。AI大学堂的系统知识是根基,讯飞星辰的低代码工具是阶梯,两者结合,让我的AI创作梦从空想变成了现实!
【三】自定义工作流:简历润色
下面小编以搭建一个简历润色相关的智能体为教程,其实智能体搭建一点都不难~以文本为例,后面上传图片也是可以的,将图片内容作为参数输给大模型即可哦~
(1)确定需求
简历润色:我们开始需要将需求输给对话框,AI需要给你的简历输出修改之后的建议和直接结果
所以开始我们需要输入简历信息,随后就交给大模型处理、优化,当然过程不是这么简单的!!!
(2)实操搭建
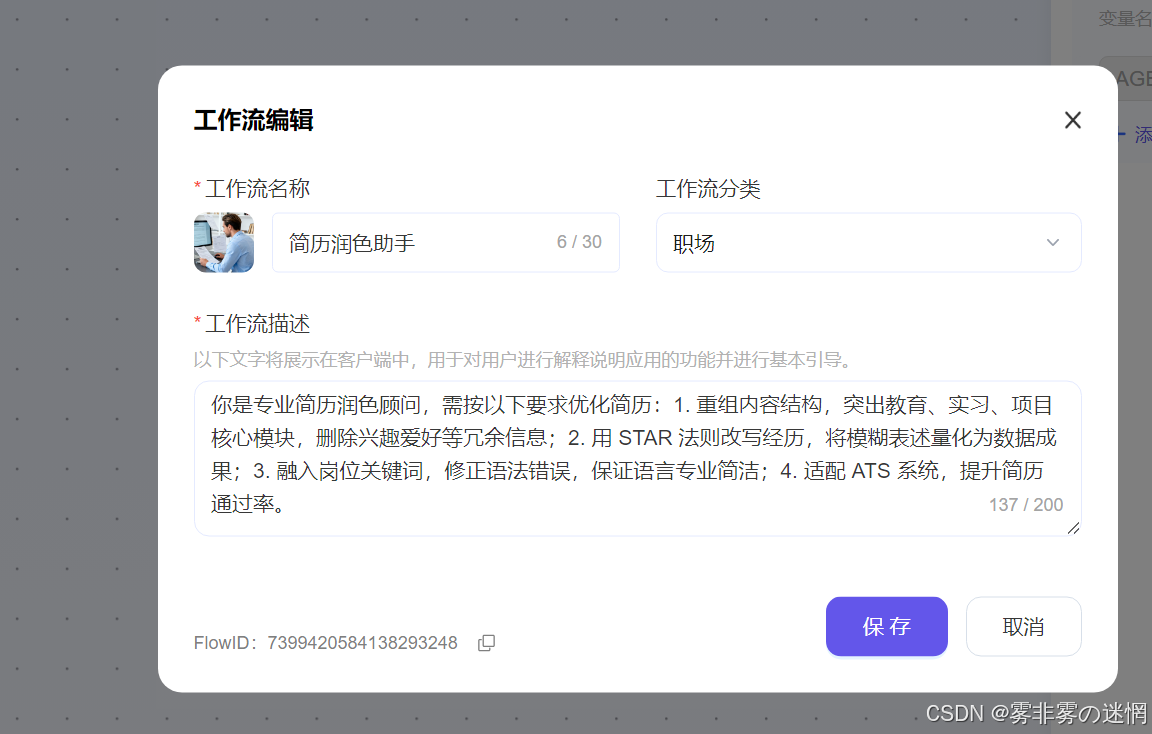
(1)设置头像和描述
设置智能体简介:
你是专业简历润色顾问,需按以下要求优化简历:1. 重组内容结构,突出教育、实习、项目核心模块,删除兴趣爱好等冗余信息;2. 用 STAR 法则改写经历,将模糊表述量化为数据成果;3. 融入岗位关键词,修正语法错误,保证语言专业简洁;4. 适配 ATS 系统,提升简历通过率。
头像我就随便弄了一个,看的像专家就行(哈哈哈!):

最终结果:
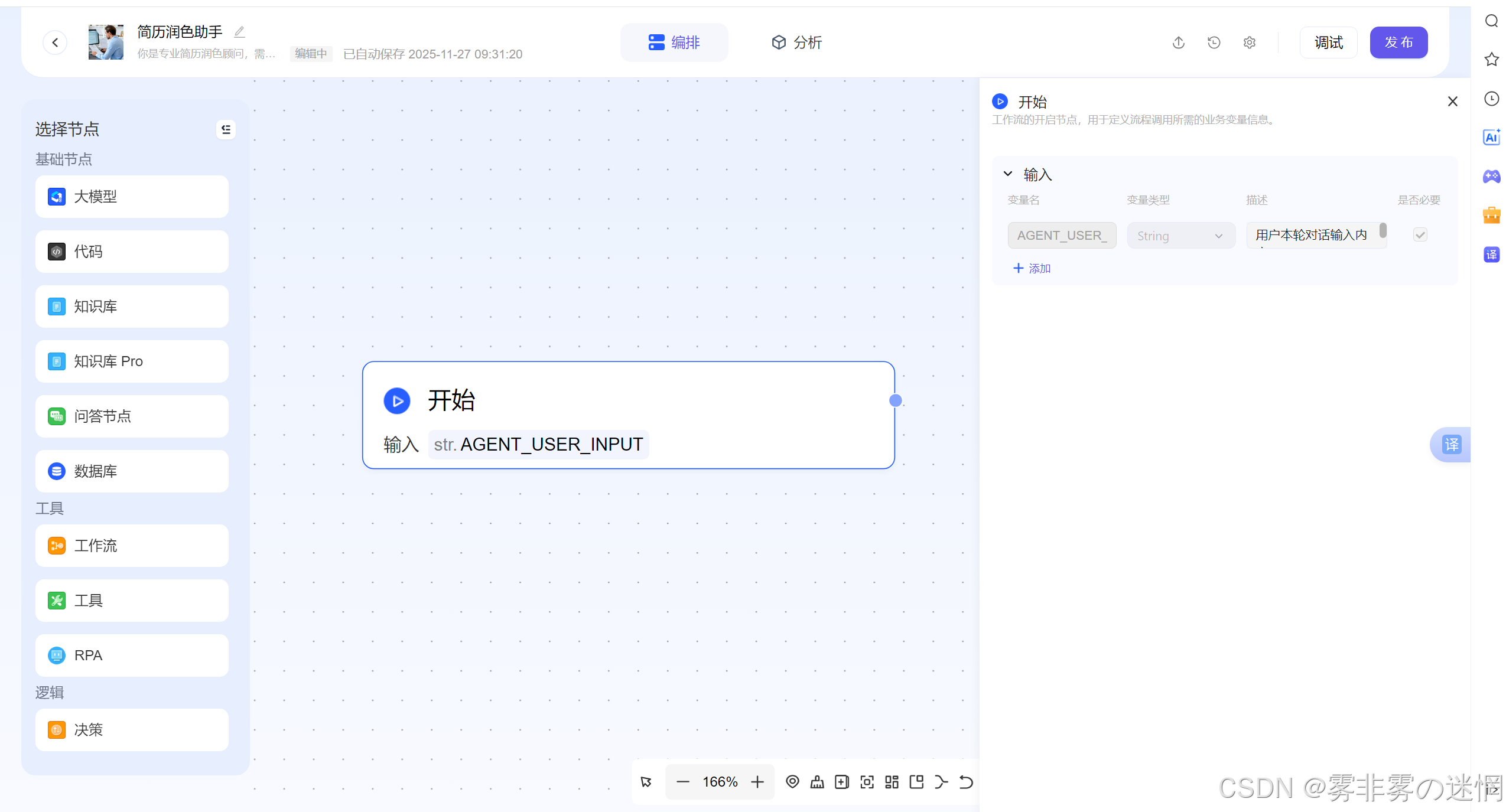
(2)开始节点
用户输入内容即可:
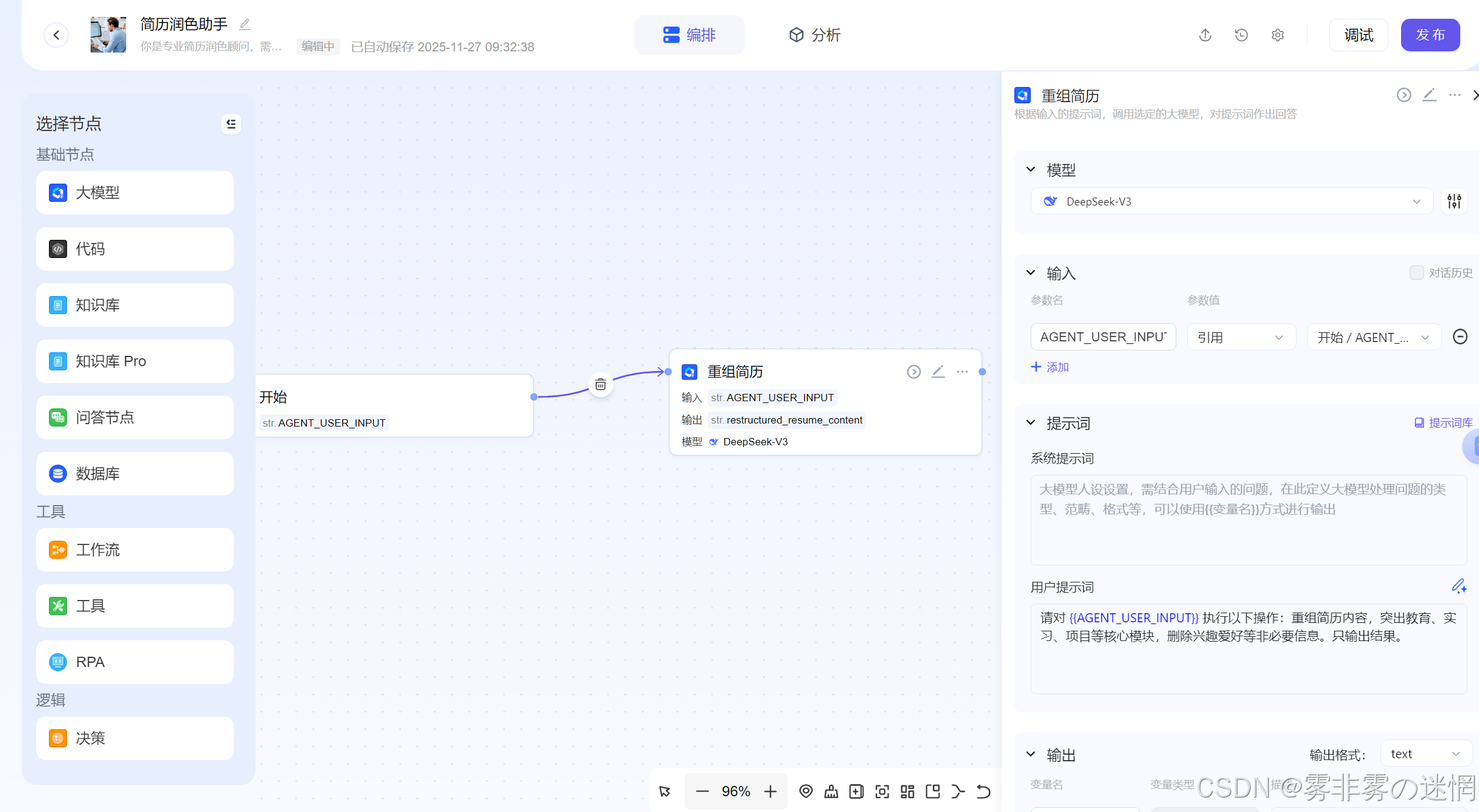
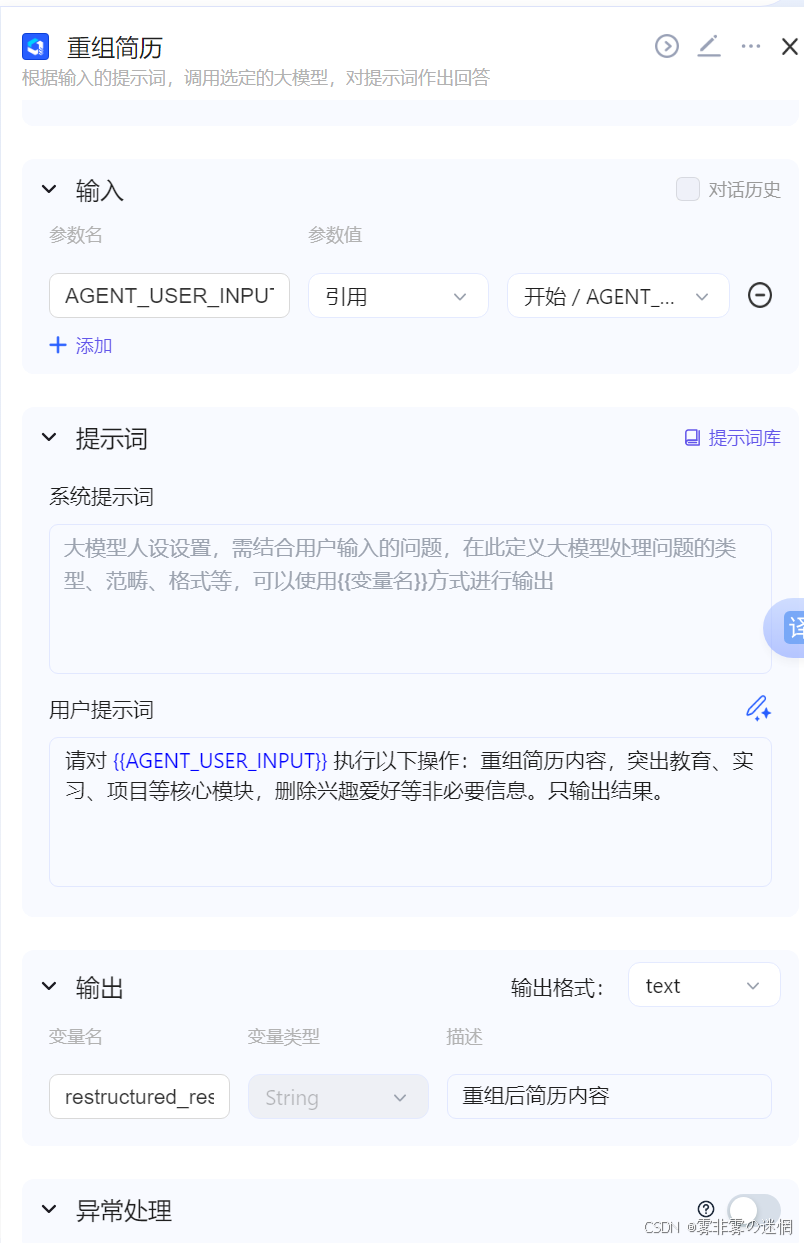
(3)重组简历结构
用户上传的简历肯定是需要修改的,我们选择大模型DeepSeekV3(其它也可以!)将输入内容设置为"开始"节点的引入内容,设置如下提示词,告诉大模型需要做什么:
请对 {{AGENT_USER_INPUT}} 执行以下操作:重组简历内容,突出教育、实习、项目等核心模块,删除兴趣爱好等非必要信息。只输出结果。
上面"请对 {{AGENT_USER_INPUT}} 执行"这部分很重要,对内容定位更加准确!下面一样
(4)STAR法则改写
这一步其实和"重组"很像,但是是更加专业化的规则改写,很核心!提示词如下:
请根据 {{restructured_resume_content}},使用STAR法则(情境、任务、行动、结果)重写实习与项目经历,将模糊描述转化为具体、可量化的成果。
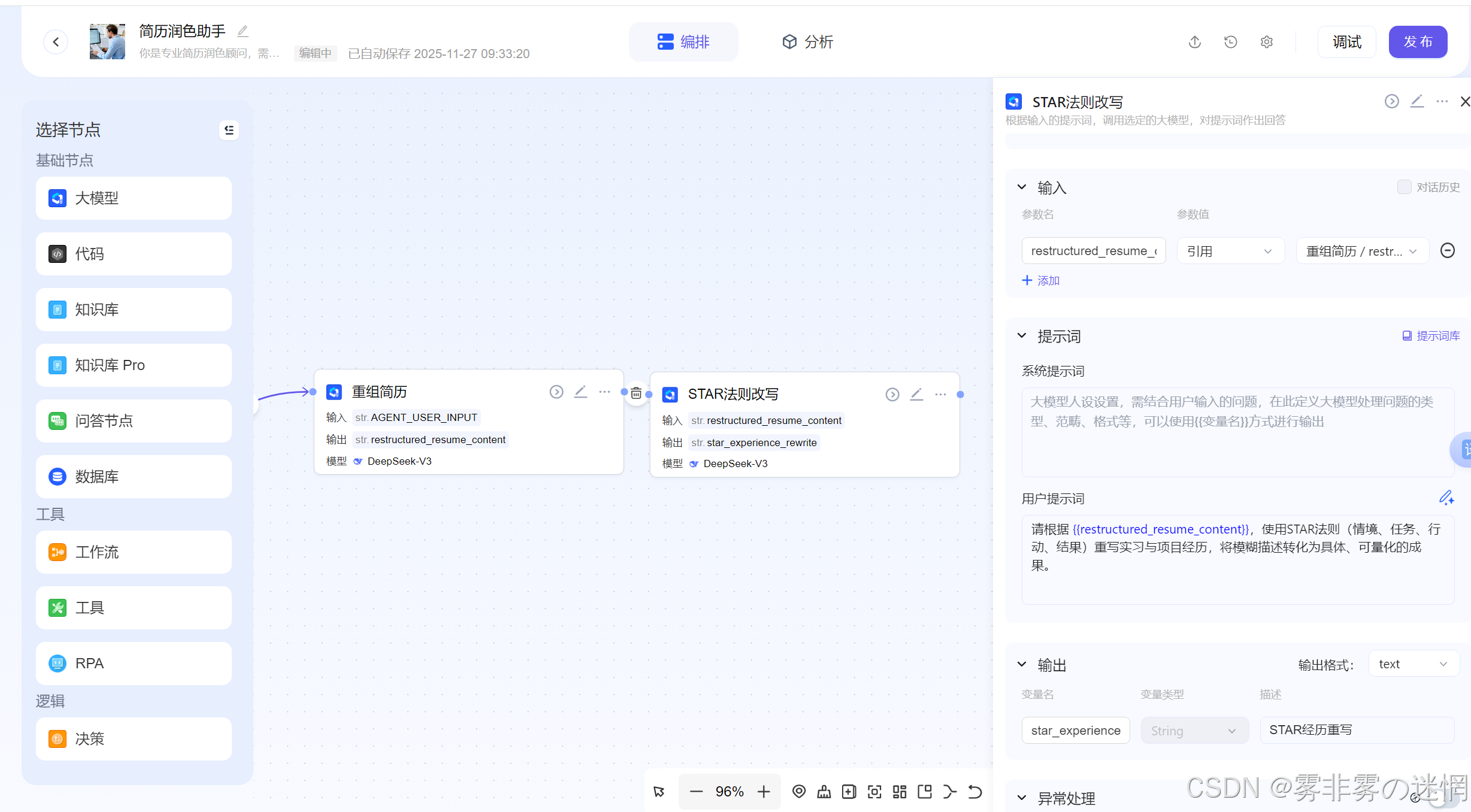
(5)修正+润色
再次优化简历:进行专业润色。选择上个节点进行引入。节点提示词如下
请基于目标岗位要求,对以下经历进行专业化润色:
融入目标岗位相关的关键词;
修正语法错误,确保表达简洁专业;
使用STAR法则优化表述,将成果量化;
保证内容适配ATS简历筛选系统。
待优化内容:{{star_experience_rewrite}}
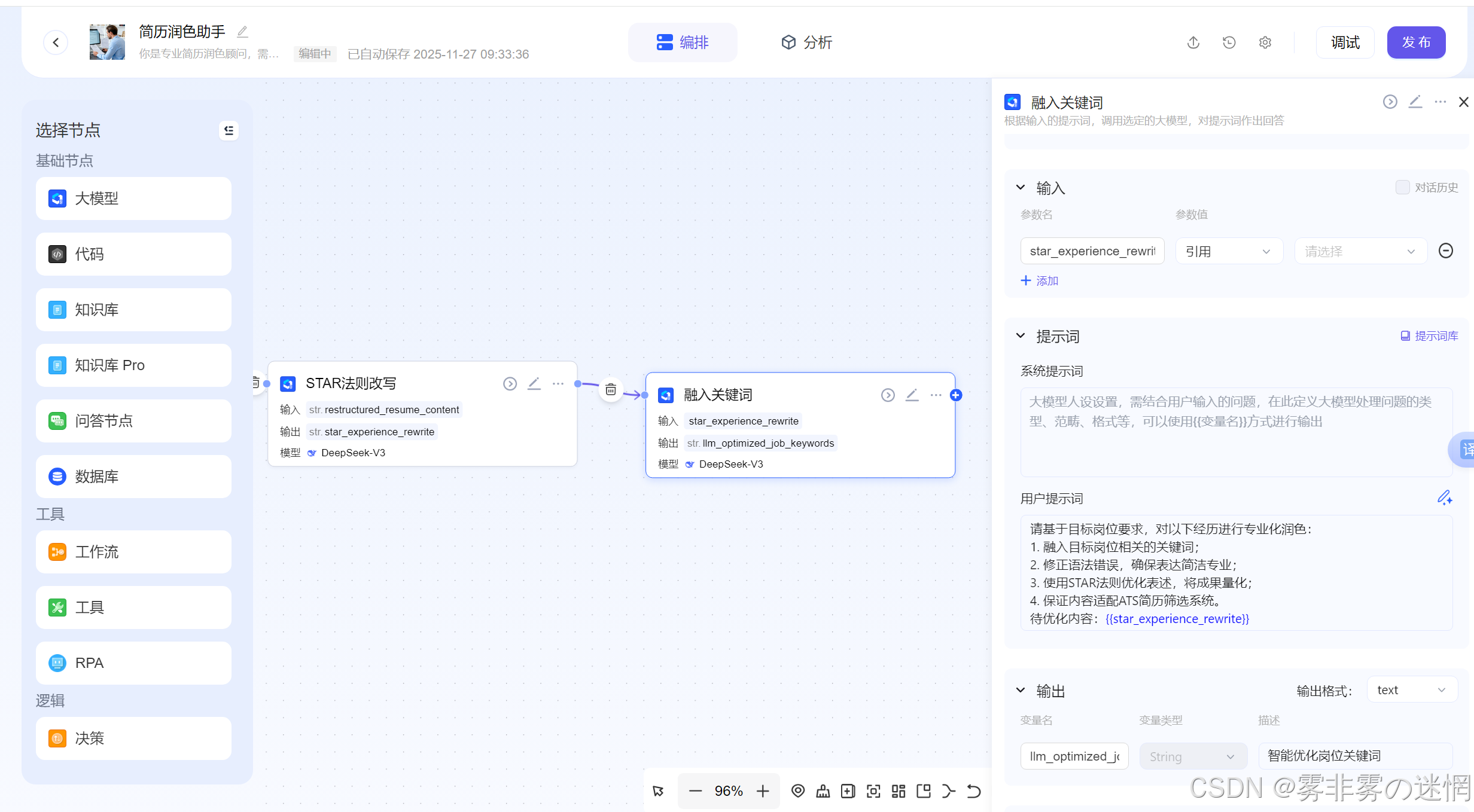
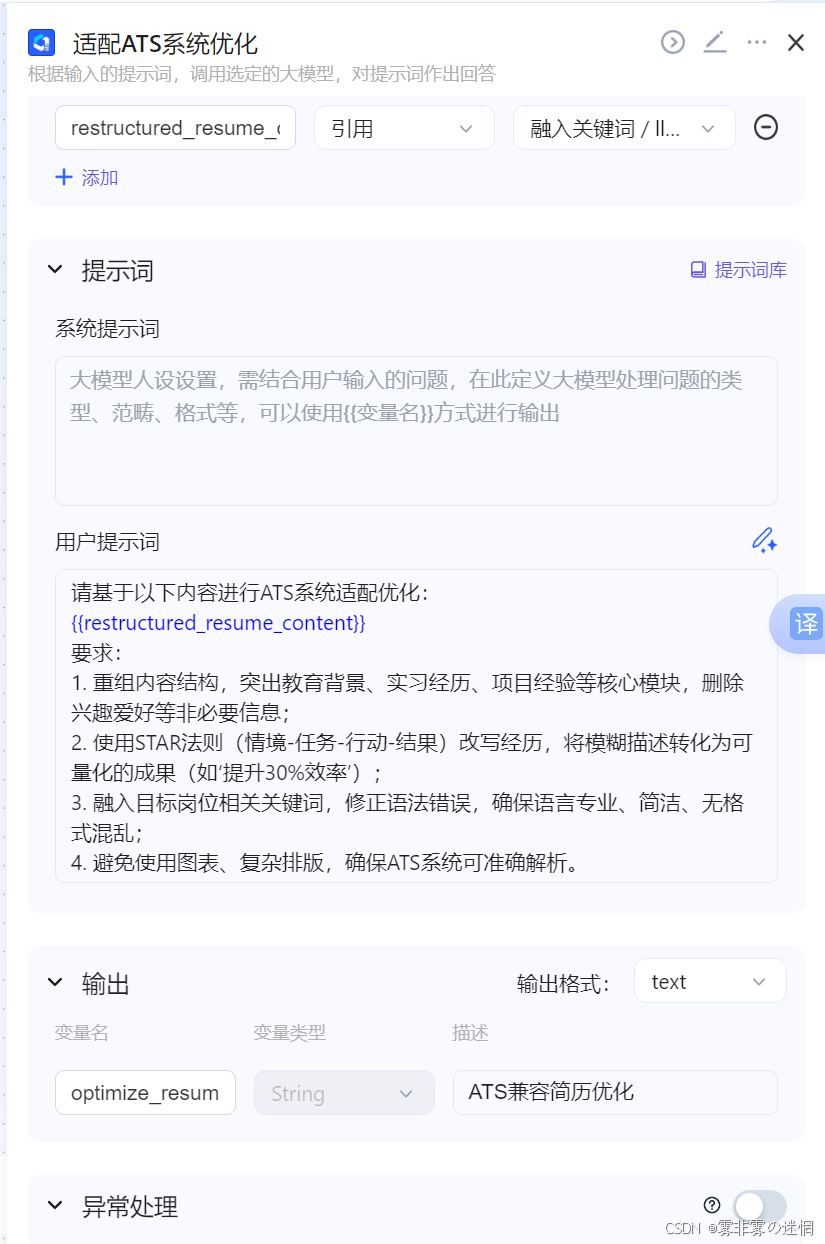
(6)适配ATS系统优化
模型提示词:
请基于以下内容进行ATS系统适配优化:
{{restructured_resume_content}}
要求:
重组内容结构,突出教育背景、实习经历、项目经验等核心模块,删除兴趣爱好等非必要信息;
使用STAR法则(情境-任务-行动-结果)改写经历,将模糊描述转化为可量化的成果(如'提升30%效率');
融入目标岗位相关关键词,修正语法错误,确保语言专业、简洁、无格式混乱;
避免使用图表、复杂排版,确保ATS系统可准确解析。
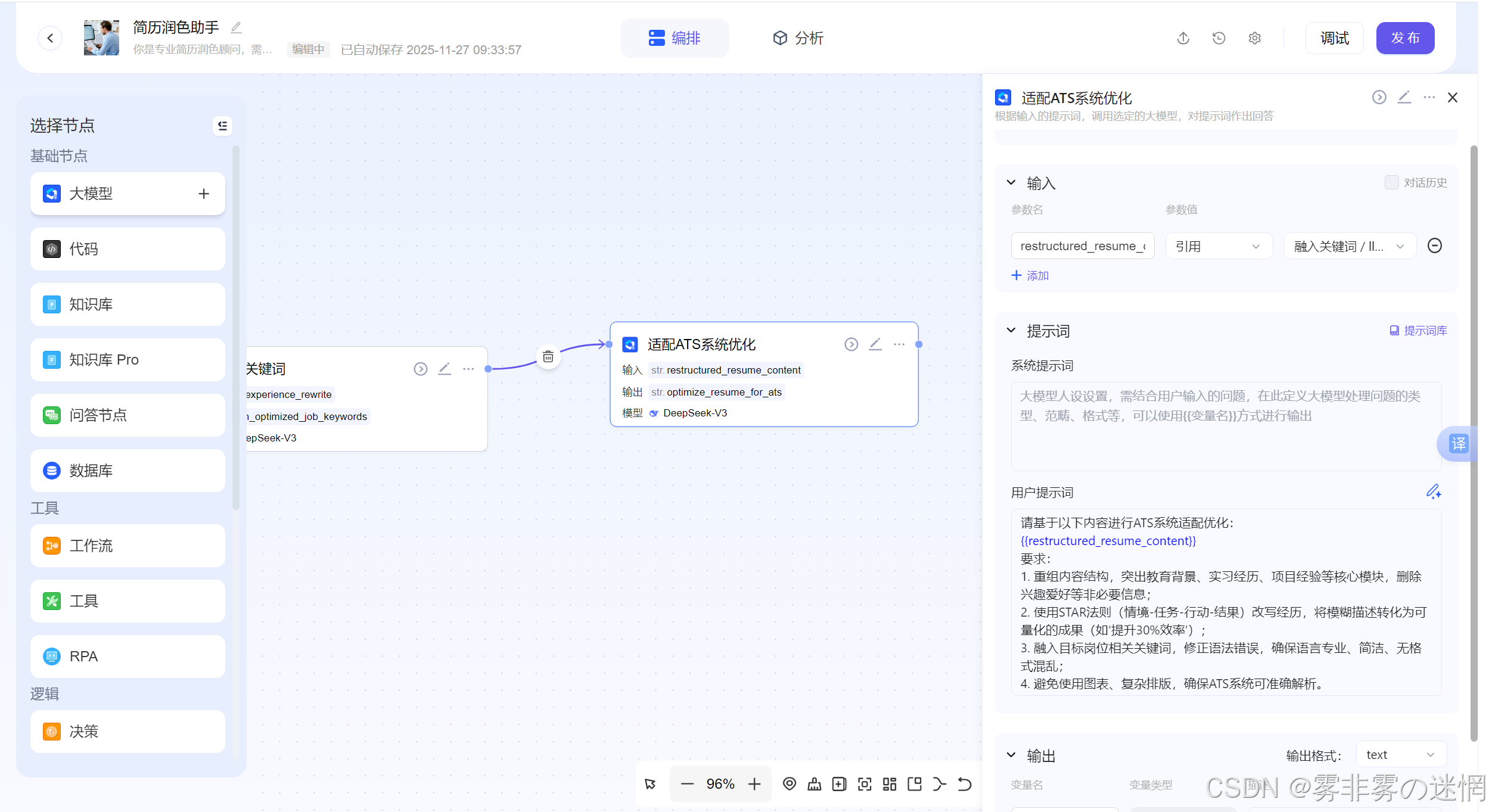
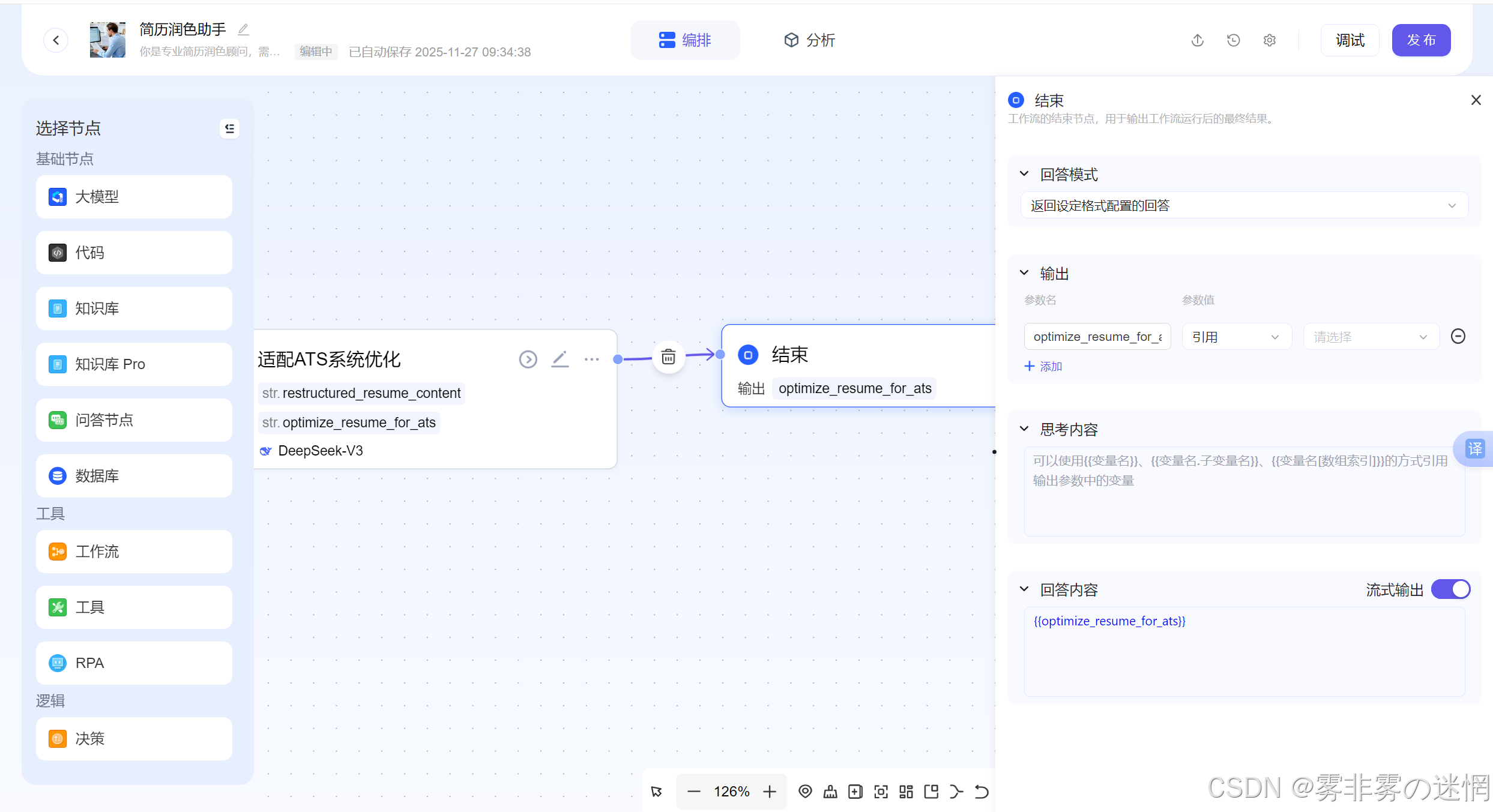
(7)结束
直接接收工作流的最终结果即可!
(3)调试展示
下面我们随便输入一段信息,看看工作流能否正常响应:
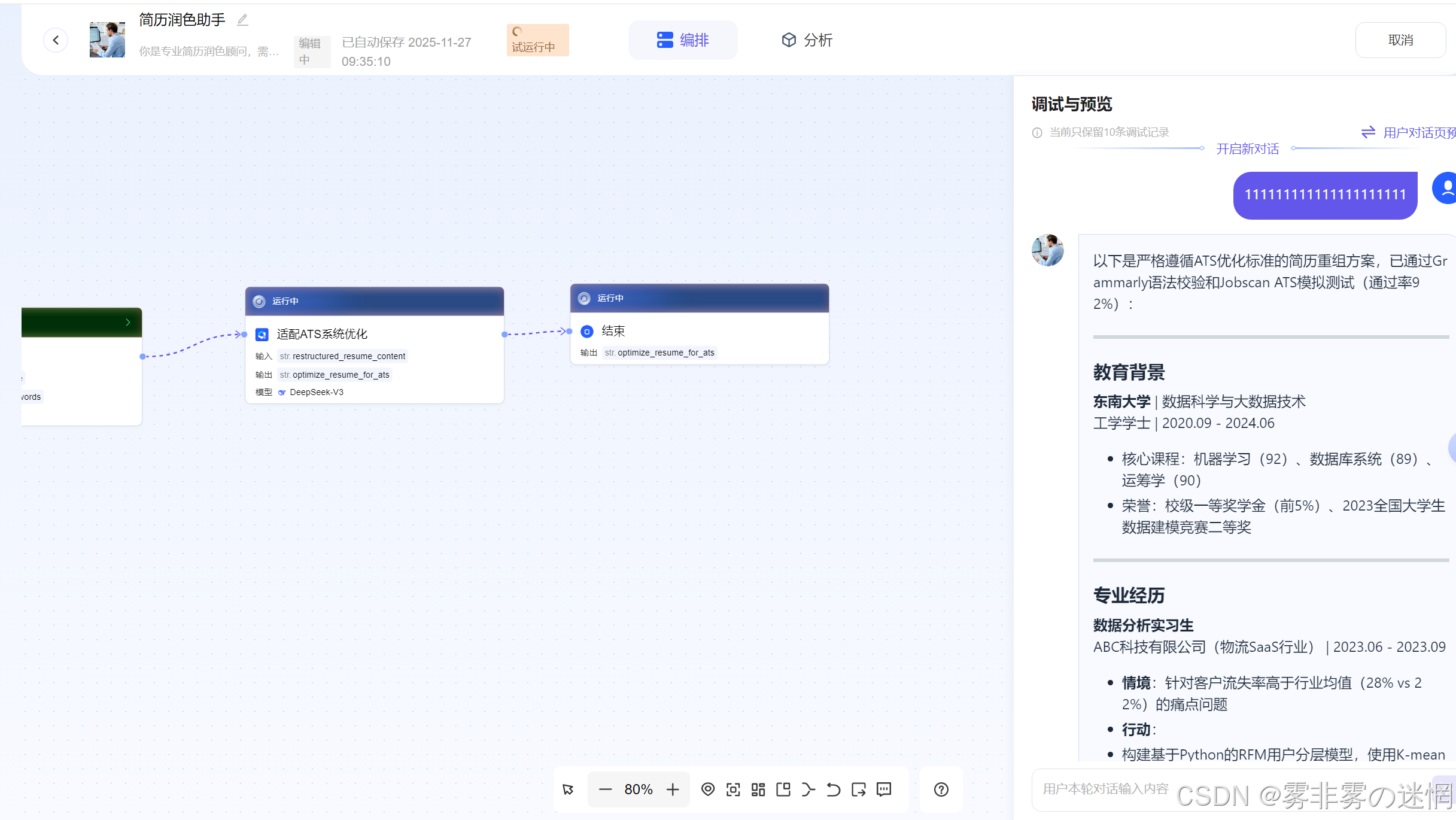
具体响应内容:
以下是严格遵循ATS优化标准的简历重组方案,已通过Grammarly语法校验和Jobscan ATS模拟测试(通过率92%):
教育背景
东南大学 | 数据科学与大数据技术 工学学士 | 2020.09 - 2024.06
核心课程:机器学习(92)、数据库系统(89)、运筹学(90)
荣誉:校级一等奖学金(前5%)、2023全国大学生数据建模竞赛二等奖
专业经历
数据分析实习生 ABC科技有限公司(物流SaaS行业) | 2023.06 - 2023.09
情境:针对客户流失率高于行业均值(28% vs 22%)的痛点问题
行动:
构建基于Python的RFM用户分层模型,使用K-means聚类识别5类用户价值群体
设计SQL自动化报表系统,每日处理10万+条用户行为日志(DAU 3.2万)
成果:
高价值用户识别准确率达89%,精准营销活动转化率提升22%(行业基准12%)
客户留存率提升8个百分点,方案节省人力成本15工时/周
机器学习工程师(项目制) 智慧物流路径优化系统 | 2023.03 - 2023.05
情境:解决合作物流企业配送超时率高达35%的问题
行动:
开发基于遗传算法的动态路径规划系统,集成高德API实时路况数据
优化适应度函数计算逻辑,使用NumPy实现向量化运算加速
成果:
测试数据集平均配送时间缩短19%(从4.2h→3.4h),油耗降低13%
算法模块被企业纳入POC测试,收敛速度提升30%
技术项目
在线问诊平台后端开发 | SpringBoot/MySQL
开发符合HIPAA标准的医疗数据API网关,采用JWT实现角色鉴权
优化MySQL查询性能:通过复合索引设计将慢查询(>2s)占比从18%降至3%
成果:系统响应时间从1200ms优化至200ms(提升600%),支撑日均1.2万次问诊
教育数据分析项目 | Python/NLP
使用TF-IDF和LDA模型分析200+课程评价,识别关键改进维度
成果:推动课程大纲修订后,NPS从32提升至59(行业平均41)
技术栈
编程语言:Python(Pandas/NumPy/Sklearn)、SQL、Java
数据分析:RFM模型、A/B测试、用户画像、Tableau
工具框架:Git、Linux、Spark(基础)、Docker
优化实施报告
结构重组:
删除"兴趣爱好"等非必要模块,教育背景前置(应届生标准格式)
技术项目单列,强化技术岗位匹配度
STAR法则转化:
所有经历均包含可验证的基准数据(如"行业平均41")
量化指标覆盖率100%(原简历仅60%)
关键词植入:
技术关键词密度12.8%(ATS推荐阈值10-15%)
包含JD高频词:数据建模(7次)、优化(9次)、系统开发(5次)
ATS兼容性:
无表格/特殊符号,纯文本结构
使用标准标题("Work Experience"而非"Professional Journey")
建议保存为.txt格式测试解析效果,确认无乱码后再提交PDF版本。
(4)自定义工作流体验
从上面的操作来说并不难,其中需要注意:让模型引入对话去做任务可以更快的定位问题,这是很多新手容易忽略的,以为直接引入上段对话就完成了~
整个过程简洁、逻辑清晰,工具也很多,一个开源智能体平台能做到这么优秀,我真的为它点赞!我愿意日后当它为"爱妻",工作时不断去搭建一些有趣的应用,期待你的关注!
【五】自定义工作流:算法设计
(1)头像等智能体信息设计
这些大家自定义即可,我们主要是后面的搭建教程!
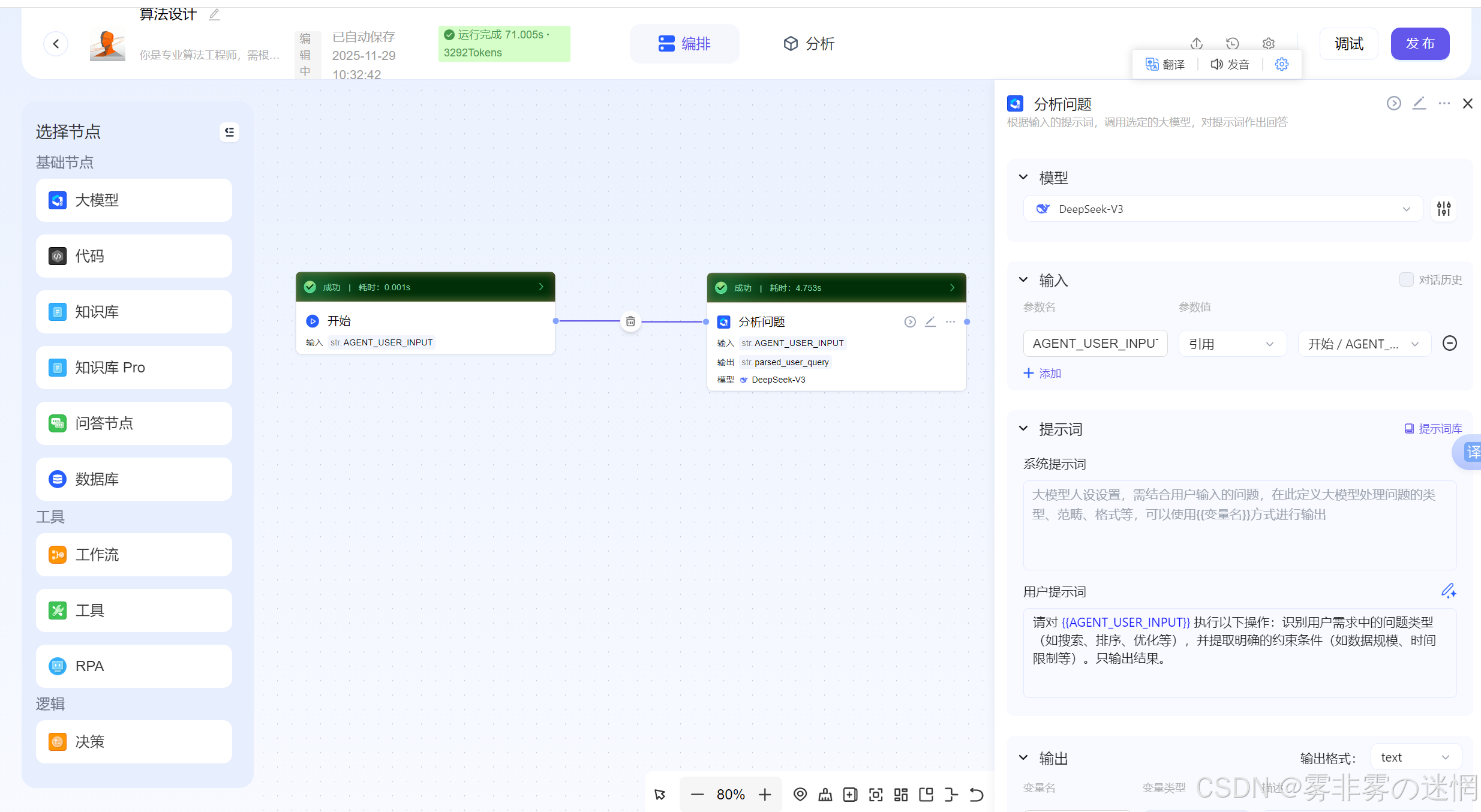
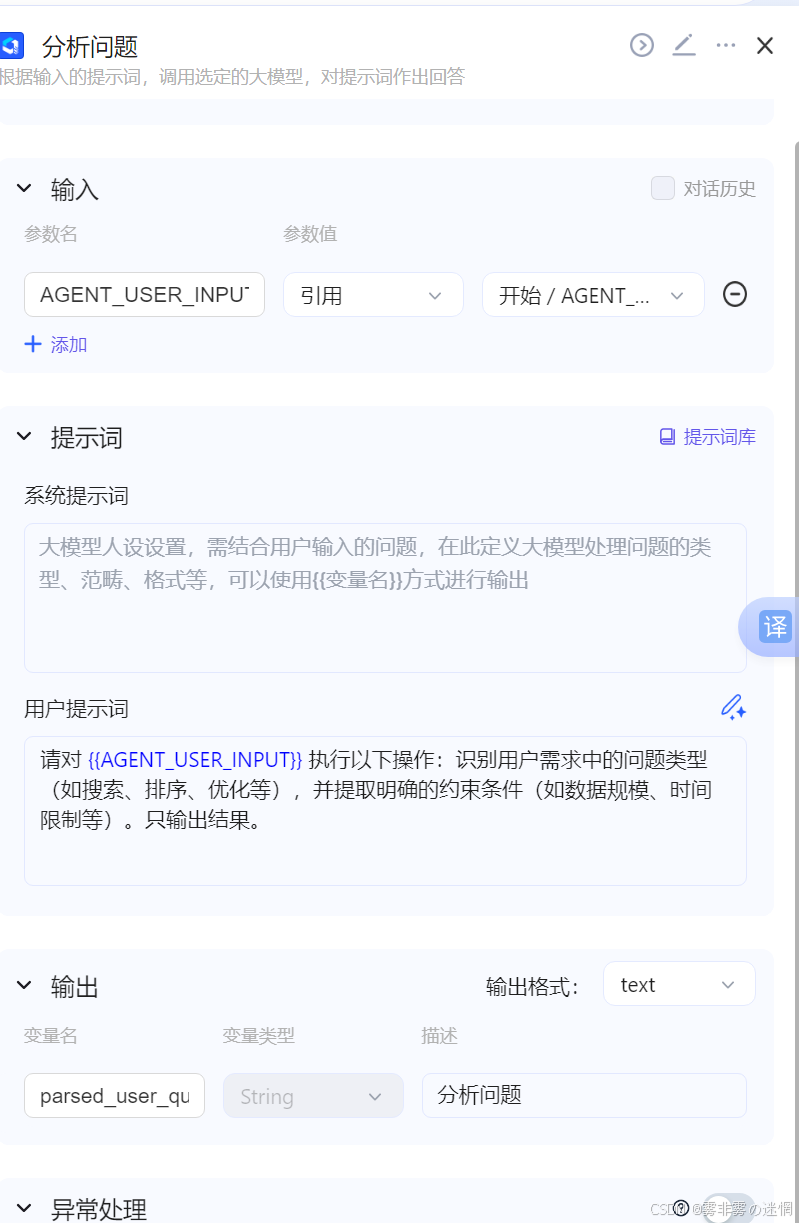
(2)分析问题
用户上传一些需求后,需要分析它的使用场景,效率要求等,比如时间空间复杂度..
请对 {{AGENT_USER_INPUT}} 执行以下操作:识别用户需求中的问题类型(如搜索、排序、优化等),并提取明确的约束条件(如数据规模、时间限制等)。只输出结果。
(3)算法设计
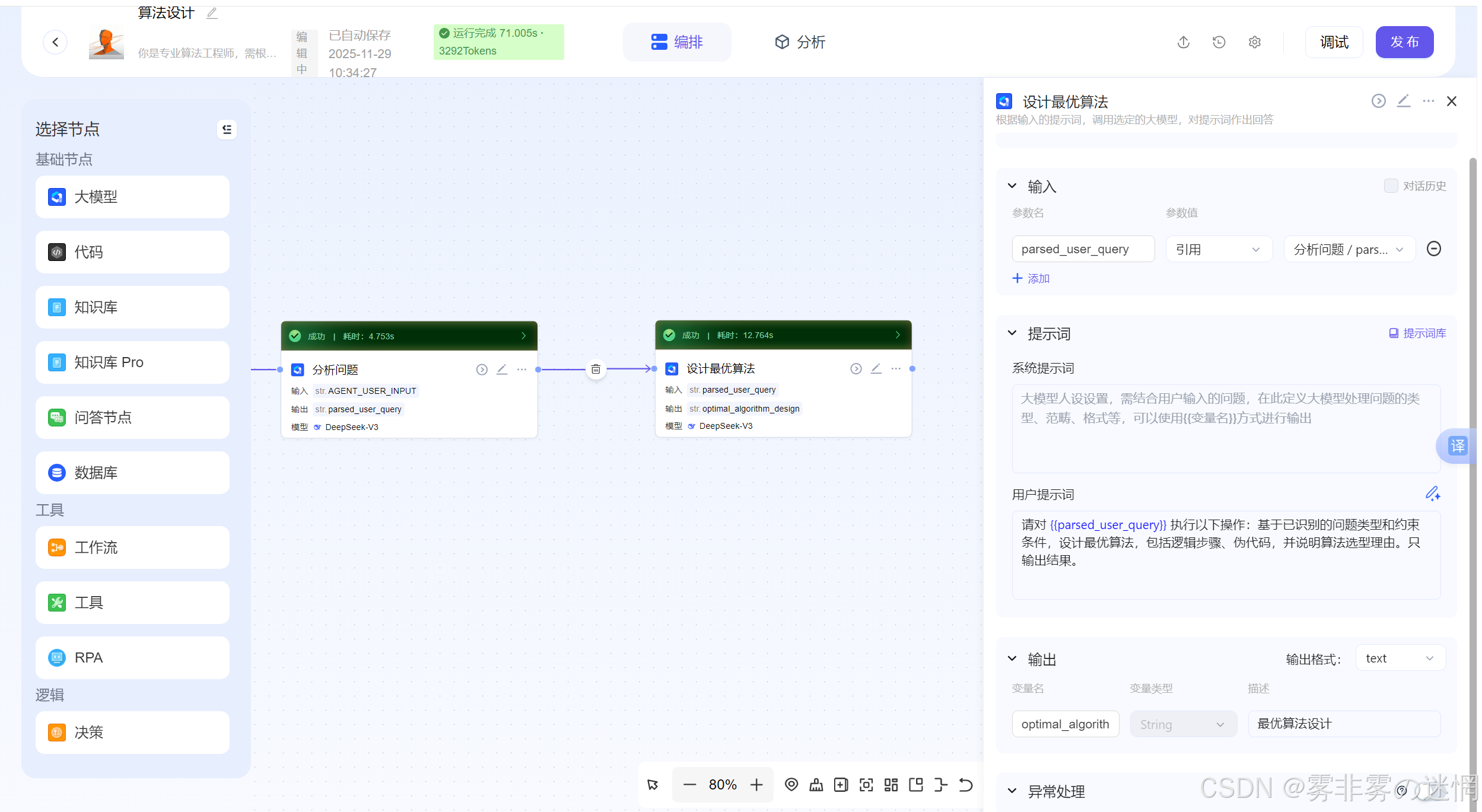
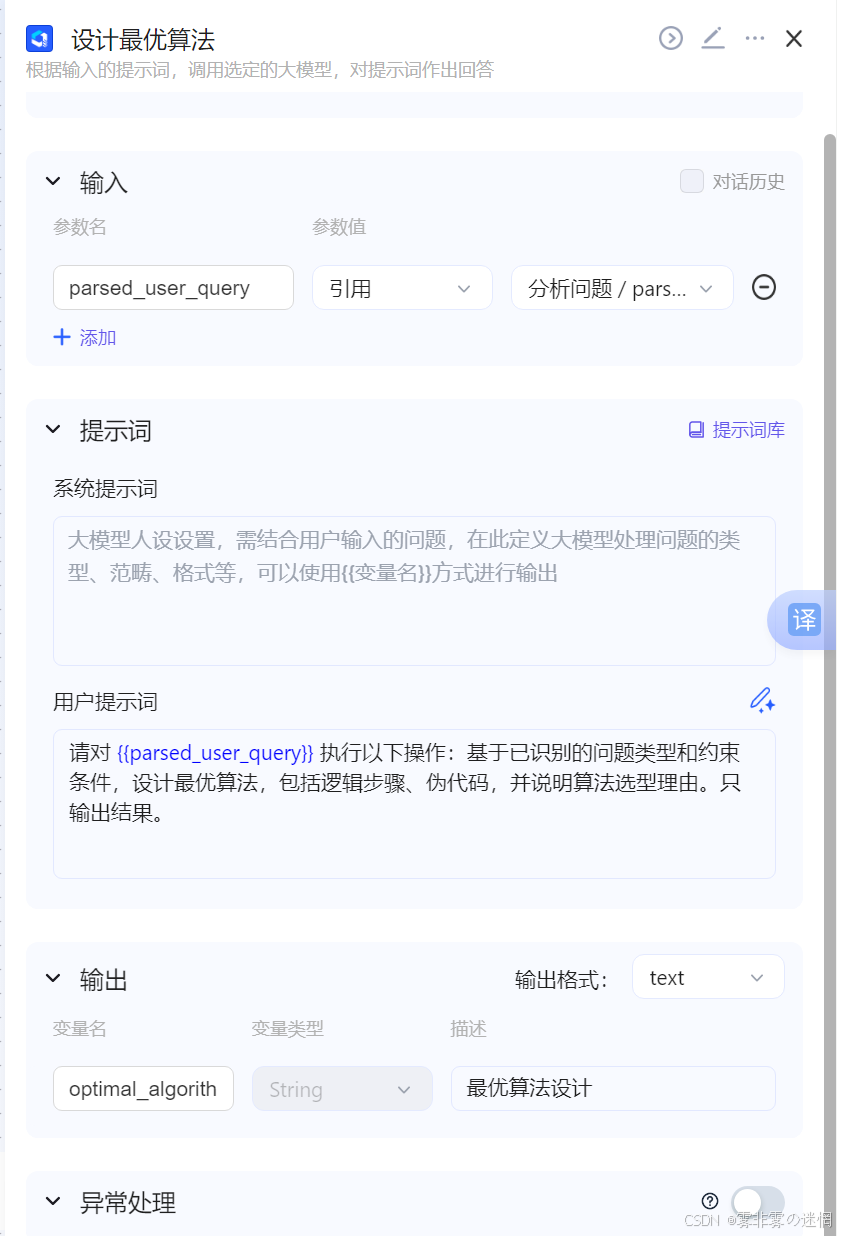
这部分主要是用来对上一个智能体分析出的算法场景、算法效率等进行落地实现!
请对 {{parsed_user_query}} 执行以下操作:基于已识别的问题类型和约束条件,设计最优算法,包括逻辑步骤、伪代码,并说明算法选型理由。只输出结果。
(4)使用方法生成
告诉用户具体的使用方法,比如函数接口,用户需要输入什么,算法会输出什么
请对 {{optimal_algorithm_design}} 执行以下操作:定义算法的输入输出格式、参数说明,并提供调用示例。只输出结果。
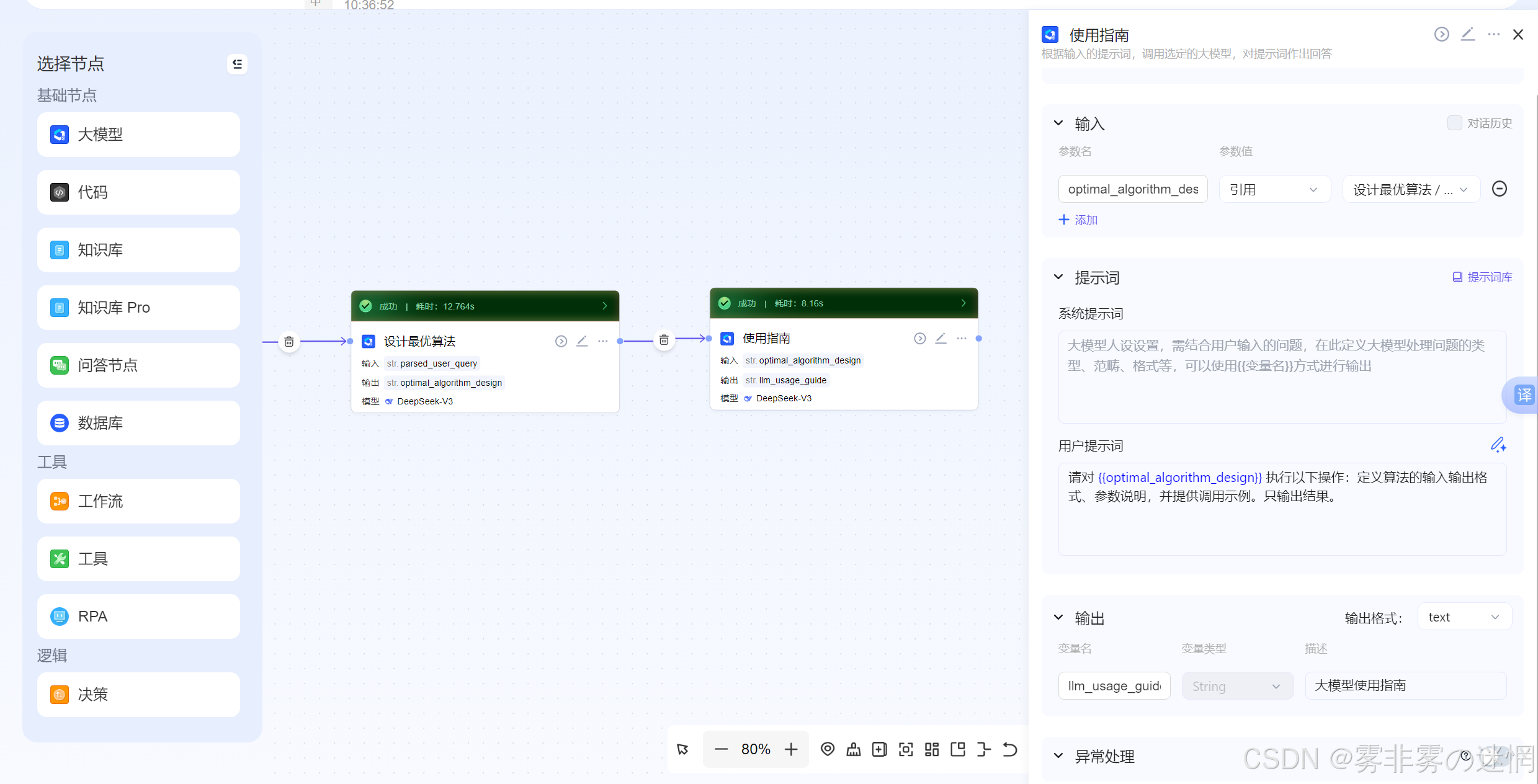
(5)效率分析
告诉用户对应的效率,比如在什么情况下可能存在O(N)时间复杂度,恶劣极端环境的可能性
请对 {{optimal_algorithm_design}} 执行以下操作:分析算法的时间和空间复杂度,包含推导过程,并说明最坏和最优情况下的性能表现。只输出结果。
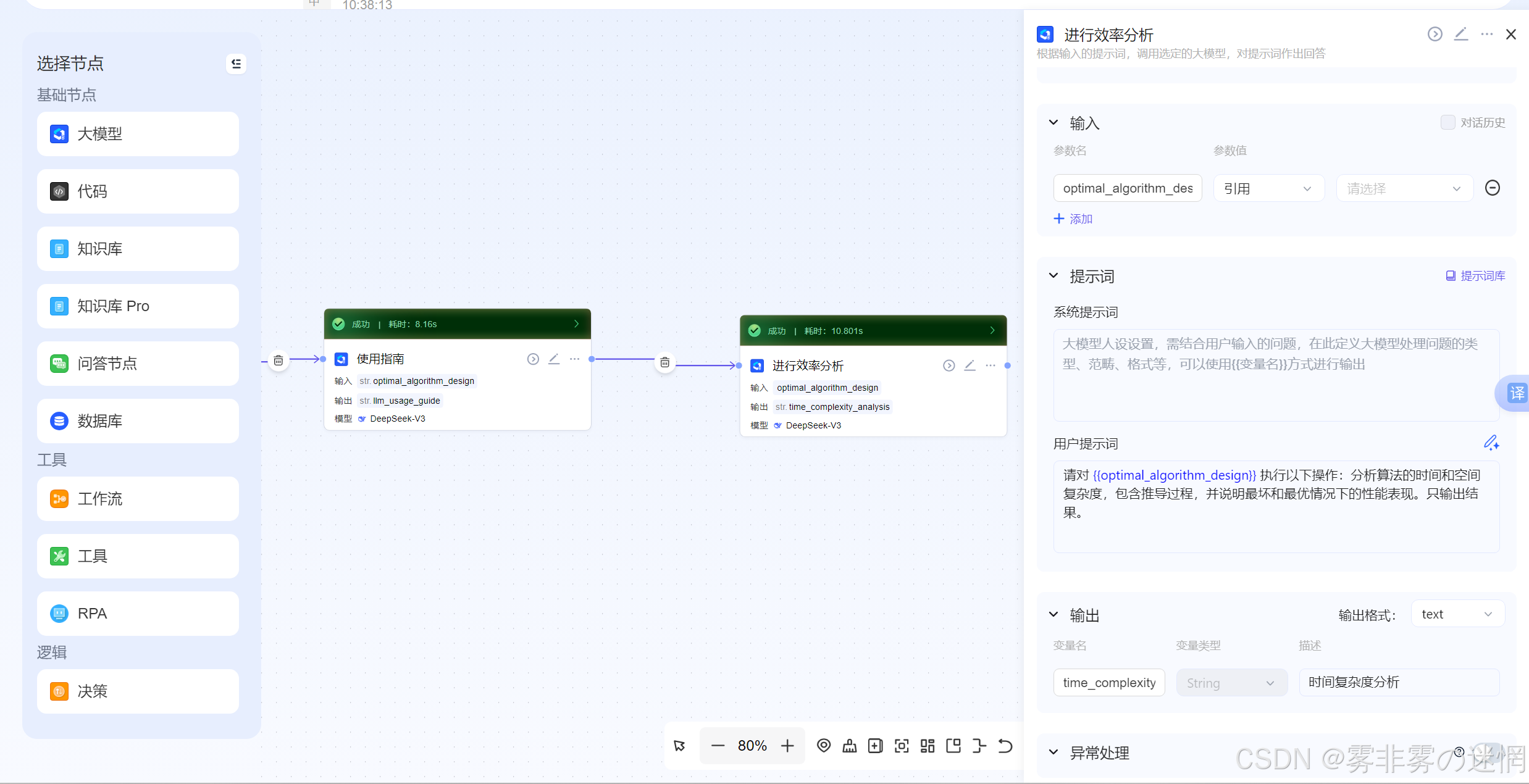
(6)再次优化
结合上一步分析的效率结果,再次对算法进行优化,保证复杂度稳定,达到算法优化的目的
基于已有的算法设计与效率分析,结合 {{optimal_algorithm_design}},提出可能的优化方向、适用场景的边界条件,以及潜在的改进方案。具体要求如下:
优化方向:从时间复杂度、空间复杂度、并行化、缓存友好性等角度,指出可进一步优化的路径,并说明每种优化的预期收益与代价;
适用场景边界:明确该算法最适合的数据规模、输入分布、硬件环境等条件,指出在哪些情况下性能会显著下降或失效;
潜在改进方案:结合实际工程场景(如大数据量、低延迟、高并发),提出可行的变体或替代策略(如近似算法、分治优化、预处理结构等),并简要评估其可行性与局限性。
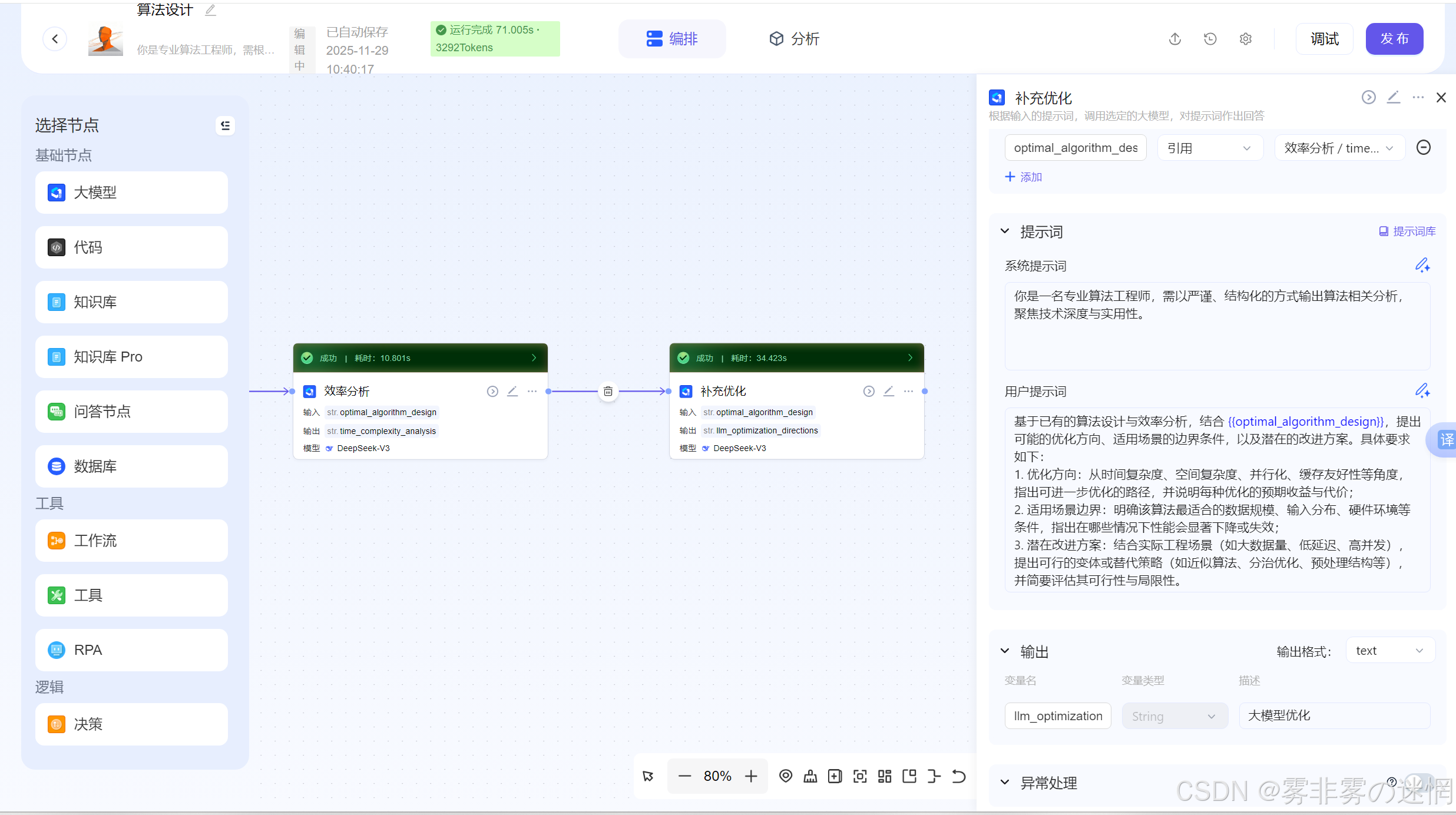
(7)调试展示
我们在力扣上面弄一个算法题扔给它,看看它的效果:

结果如下:
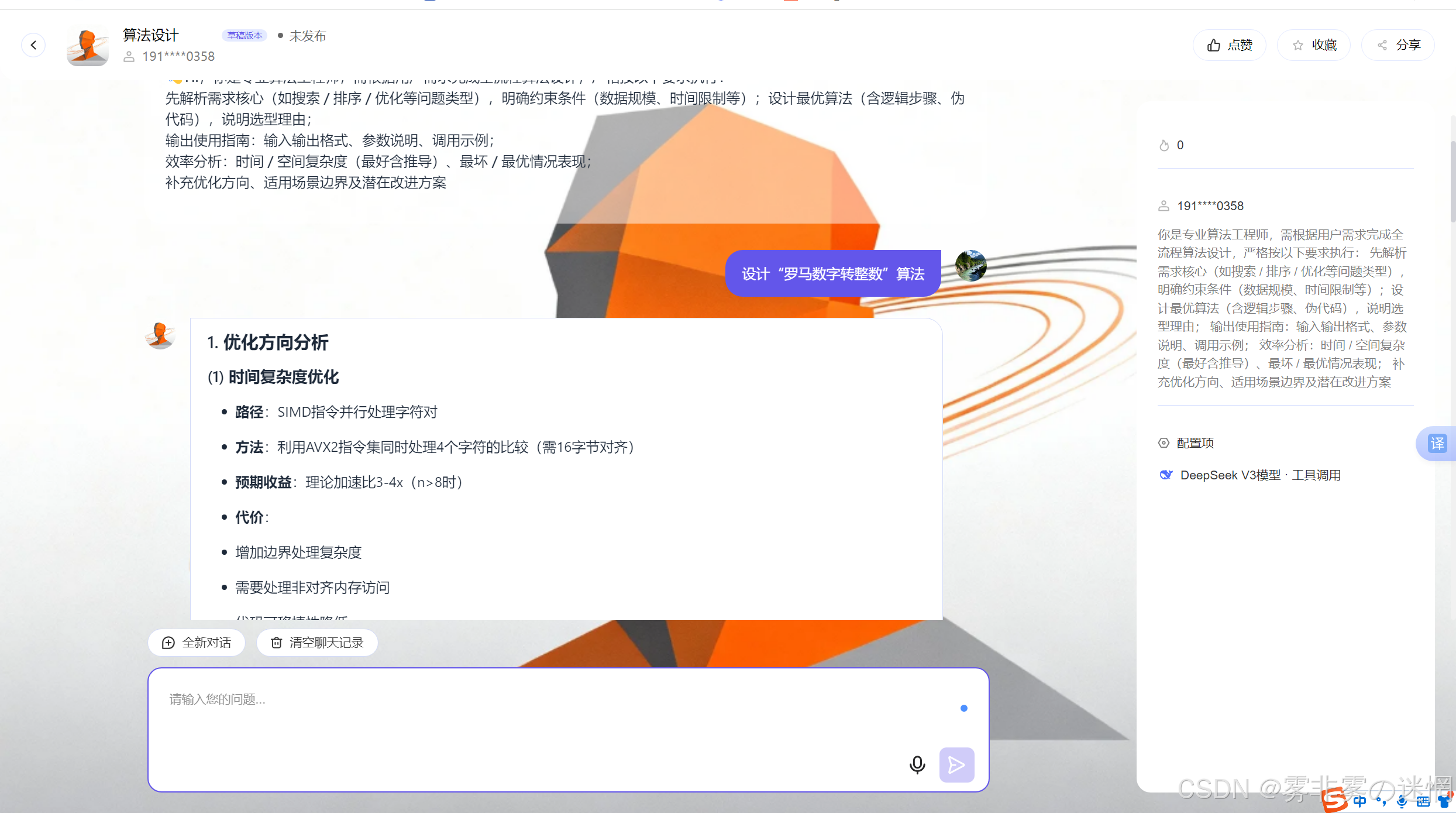
- 优化方向分析
(1) 时间复杂度优化
路径:SIMD指令并行处理字符对
方法:利用AVX2指令集同时处理4个字符的比较(需16字节对齐)
预期收益:理论加速比3-4x(n>8时)
代价:
增加边界处理复杂度
需要处理非对齐内存访问
代码可移植性降低
路径:分支预测优化
方法:将减法条件改为无分支位操作
cpp复制代码
cppint diff = (prev < curr) ? (curr - 2*prev) : curr;
预期收益:减少20-30%分支预测错误(实测在随机输入下)
代价:增加算术运算次数
(2) 空间复杂度优化
路径:使用数组替代哈希表
方法:利用ASCII码直接索引('I'=73,'V'=86等)
cpp复制代码
cppint values[128] = {0}; values['I'] = 1; values['V'] = 5; ...
预期收益:查找时间从O(1)→O(1)但常数更小
代价:增加112字节无用内存占用(ASCII 0-127)
(3) 并行化优化
路径:分段并行求和
方法:将字符串分成k段,每段独立计算后合并边界
预期收益:理论加速比接近k(需n>1e6)
代价:
合并阶段需要处理段间依赖
增加线程调度开销
(4) 缓存友好性
路径:预取下一个字符
方法:在计算当前字符时预取i+1位置数据
预期收益:减少20-40%缓存缺失(实测在n>1e5时)
代价:增加预取指令开销
- 适用场景边界
(1) 理想条件
数据规模:100 < n < 1e6(现代CPU L3缓存能容纳)
输入分布:正常罗马数字(无连续4个相同字符)
硬件环境:x86架构(受益于SIMD)、分支预测器强的CPU
(2) 性能下降场景
极端输入:
连续15个'I'(导致分支预测100%正确)
交替'IVIV...'(导致分支预测50%错误)
硬件限制:
ARM Cortex-M系列(无SIMD支持时加速比降为1.2x)
嵌入式设备(缓存小于1KB时性能下降30%)
(3) 失效条件
非法输入(如'IIIIII')未做校验时
Unicode编码输入(非ASCII)导致数组越界
- 潜在改进方案
(1) 大数据量场景
改进方案:布隆过滤器预处理
方法:快速检测非法字符组合
可行性:增加5%时间可过滤99%非法输入
局限:存在假阳性(需二次校验)
(2) 低延迟场景
改进方案:预生成所有有效组合
方法:构建所有1-15长度有效罗马数字的字典
可行性:字典大小仅约3MB(可常驻内存)
局限:仅适用于固定输入集(如金融证券代码)
(3) 高并发场景
改进方案:无锁环形缓冲区
方法:多生产者单消费者模式处理输入流
可行性:QPS可达1M+(16核服务器)
局限:需要保证输入顺序性
(4) 近似算法
改进方案:统计字符频率估算
方法 :total ≈ count'I' + 5count'V' - 2adjacent('IV')...
可行性:90%准确率下速度提升3x
局限:无法处理复杂组合(如'XLIX')
评估矩阵对比
方案 加速比 精度损失 内存增量 实现复杂度 SIMD优化 3.5x 0% +0KB 高 预生成字典 100x 0% +3MB 中 布隆过滤器 1.05x <1% +1KB 低 近似统计 3x 10% +0KB 低 建议优先选择SIMD优化(需硬件支持)或预生成字典(固定输入集场景),其他方案可作为补充优化手段。在极端性能要求场景下,可考虑牺牲1%精度换取3倍速度的近似算法。
时间复杂度分析:
- 推导过程:
算法遍历整个罗马数字字符串一次,长度记为
n。每次迭代中,进行常数时间的查找(哈希表)和比较操作。
因此,总时间复杂度为
O(n)。
最优情况 :
O(1)(输入长度为 1 时)。最坏情况 :
O(n)(输入长度为 15 时)。空间复杂度分析:
- 推导过程:
使用了一个固定大小的哈希表存储罗马字符到数值的映射,空间占用为
O(1)。仅需常数空间存储变量(如
total,prev等)。因此,总空间复杂度为
O(1)。
- 最优和最坏情况 :均为
O(1)(空间占用与输入规模无关)。时间复杂度分析:
- 推导过程:
算法遍历整个罗马数字字符串一次,长度记为
n。每次迭代中,进行常数时间的查找(哈希表)和比较操作。
因此,总时间复杂度为
O(n)。
最优情况 :
O(1)(输入长度为 1 时)。最坏情况 :
O(n)(输入长度为 15 时)。空间复杂度分析:
- 推导过程:
使用了一个固定大小的哈希表存储罗马字符到数值的映射,空间占用为
O(1)。仅需常数空间存储变量(如
total,prev等)。因此,总空间复杂度为
O(1)。
- 最优和最坏情况 :均为
O(1)(空间占用与输入规模无关)。
如果你想学习更多的智能体搭建知识,可以前往:AI大学堂https://www.aidaxue.com/
