目录
[13.1 领域偏移:当AI遇到"水土不服"](#13.1 领域偏移:当AI遇到"水土不服")
[13.2 领域自适应:让AI学会"入乡随俗"](#13.2 领域自适应:让AI学会"入乡随俗")
[1. 监督领域自适应](#1. 监督领域自适应)
[2. 半监督领域自适应](#2. 半监督领域自适应)
[3. 无监督领域自适应](#3. 无监督领域自适应)
[13.3 领域泛化:让AI具备"未雨绸缪"的能力](#13.3 领域泛化:让AI具备"未雨绸缪"的能力)
[1. 领域不变表示学习](#1. 领域不变表示学习)
[2. 数据增强与领域生成](#2. 数据增强与领域生成)
[3. 元学习与优化策略](#3. 元学习与优化策略)
[4. 集成与模块化方法](#4. 集成与模块化方法)
在人工智能的发展历程中,我们常常面临这样的困境:每个新任务都需要从头开始训练模型,耗费大量的计算资源和时间。但人类学习却不是这样------我们能够将在一个领域学到的知识应用到另一个相关领域。这种"举一反三"的能力,正是迁移学习要赋予AI的核心能力。
13.1 领域偏移:当AI遇到"水土不服"
想象一下,你是一位精通城市道路驾驶的司机,第一次在雪地环境中开车。虽然基本的驾驶技能仍然适用,但你需要调整刹车距离、转向力度等具体操作。这种在不同环境下技能需要调整的现象,在AI中被称为"领域偏移"。
什么是领域偏移?
领域偏移是指训练数据(源领域)和测试数据(目标领域)来自不同分布的现象。这种分布的不匹配会导致模型在目标领域上的性能显著下降。
领域偏移的常见类型:
-
协变量偏移:输入特征的分布发生变化,但条件分布P(y|x)保持不变
-
示例:训练数据是白天照片,测试数据是夜间照片
-
数学表达:P_source(x) ≠ P_target(x),但P(y|x)相同
-
-
概念偏移:输入特征与输出标签之间的关系发生变化
-
示例:"豪华"一词在汽车领域和酒店领域的含义不同
-
数学表达:P_source(y|x) ≠ P_target(y|x)
-
-
先验概率偏移:输出标签的分布发生变化
-
示例:垃圾邮件过滤器中,垃圾邮件的比例随时间变化
-
数学表达:P_source(y) ≠ P_target(y)
-
领域偏移的根源
领域偏移的产生有多重原因:
数据收集因素:
-
不同的采集设备(相机型号、传感器精度)
-
不同的环境条件(光照、天气、背景)
-
不同的人群分布(年龄、地域、文化)
时间因素:
-
概念随时间演变(网络用语的含义变化)
-
用户行为模式变化(购物偏好随季节变化)
-
系统环境变化(交通流量随时间变化)
空间因素:
-
地域文化差异(表情符号在不同文化中的含义)
-
政策法规差异(不同国家的医疗数据规范)
-
基础设施差异(城市与农村的道路条件)
领域偏移的影响
领域偏移对AI系统的影响是深远且多方面的:
性能下降:最直接的影响是模型在目标领域上的准确率、召回率等指标下降。
置信度误判:模型可能对错误预测给出高置信度,增加了系统的风险。
泛化能力受限:模型无法适应新的环境和条件,限制了实际应用范围。
安全风险:在自动驾驶、医疗诊断等关键领域,领域偏移可能导致严重后果。
检测领域偏移
检测领域偏移是应对它的第一步。常用的方法包括:
统计检验:
-
KL散度、JS散度测量分布差异
-
MMD(最大均值差异)检验
-
假设检验方法(如t检验、卡方检验)
模型-based方法:
-
训练领域分类器区分源域和目标域
-
监测模型置信度分布的变化
-
分析特征表示的空间分布
业务指标监控:
-
跟踪模型在生产环境中的性能指标
-
监控数据分布的统计特征
-
建立数据质量监控体系
理解领域偏移的本质和影响,是我们有效应对它的基础。在下一节中,我们将探讨如何通过领域自适应来缓解领域偏移带来的问题。
13.2 领域自适应:让AI学会"入乡随俗"
当我们意识到AI模型在新环境中会遇到"水土不服"时,很自然就会想到:能否让模型学会适应新环境?这就是领域自适应要解决的问题。
领域自适应的基本思想
领域自适应的核心目标是利用源领域(通常有丰富标注数据)的知识,在目标领域(标注数据稀缺或没有)上获得良好的性能。其基本假设是:尽管源领域和目标领域的数据分布不同,但它们之间存在某种相关性或共享结构。
领域自适应的关键洞察:
-
两个领域共享某些底层特征
-
知识可以从数据丰富的领域转移到数据稀缺的领域
-
通过适当的 adaptation,模型可以学会忽略领域特异性差异
领域自适应的方法论
根据目标领域数据的可用情况,领域自适应可以分为三类:
1. 监督领域自适应
目标领域有少量标注数据的情况。
方法特点:
-
利用源领域的大量标注数据和目标领域的少量标注数据
-
通常能获得较好的 adaptation 效果
-
适合标注成本较高的场景
典型技术:
-
微调(Fine-tuning):在源域预训练模型基础上,用目标域数据继续训练
-
特征对齐:学习领域不变的特征表示
-
多任务学习:同时优化源域和目标域的任务
2. 半监督领域自适应
目标领域有大量无标注数据和少量标注数据。
方法特点:
-
充分利用目标领域的无标注数据
-
结合监督信号和无监督 adaptation
-
在实际应用中较为常见
典型技术:
-
自训练(Self-training):用模型对无标注数据的预测作为伪标签
-
一致性正则化:鼓励模型对扰动的输入产生一致输出
-
对抗训练:通过领域判别器学习领域不变特征
3. 无监督领域自适应
目标领域完全没有标注数据,只有无标注数据。
方法特点:
-
最具挑战性但也最实用的设定
-
完全依赖源域的标注数据和目标域的无标注数据
-
需要巧妙的 adaptation 策略
典型技术:
-
领域对抗训练(DANN)
-
最大均值差异(MMD)最小化
-
自监督预训练
领域自适应的核心技术
基于差异最小化的方法
这类方法的核心思想是直接最小化源域和目标域特征分布之间的差异。
最大均值差异(MMD) :
MMD通过比较两个分布在再生核希尔伯特空间中的均值来度量分布差异:
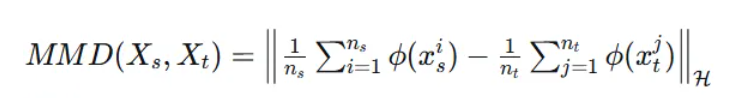
其中\\phi是特征映射函数。
相关对齐(CORAL) :
CORAL通过对齐源域和目标域特征的二阶统计量(协方差矩阵)来减少领域差异:
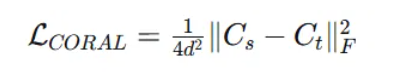
其中C_s和C_t分别是源域和目标域的协方差矩阵。
基于对抗学习的方法
这类方法借鉴生成对抗网络的思想,通过领域判别器来学习领域不变的特征表示。
领域对抗神经网络(DANN) :
DANN包含三个组件:
-
特征提取器:从输入中提取特征
-
标签预测器:基于特征进行主要任务预测
-
领域判别器:区分特征来自源域还是目标域
训练时,特征提取器要同时欺骗领域判别器(让两个领域的特征分布相似)并为标签预测器提供有区分性的特征。
对抗损失的数学形式:
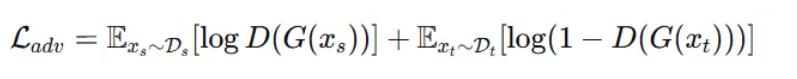
其中G是特征提取器,D是领域判别器。
基于重构的方法
这类方法通过重构目标域数据来确保学到的特征包含足够的领域信息。
自动编码器变体:
-
去噪自动编码器:学习对噪声鲁棒的特征表示
-
变分自动编码器:学习平滑的隐空间表示
-
对抗自动编码器:结合对抗训练的编码器
领域自适应的实际挑战
尽管领域自适应在理论上很吸引人,但在实际应用中面临诸多挑战:
负迁移 :
当源域和目标域差异过大时,迁移学习反而会损害性能。这种情况称为负迁移。
解决方案:
-
选择性迁移:只迁移相关的知识
-
多源迁移:从多个相关源域迁移
-
渐进式迁移:通过中间领域逐步迁移
领域间隙估计 :
如何准确估计两个领域之间的相似度,以决定是否进行迁移以及如何迁移。
解决方案:
-
基于统计的相似度度量(MMD、CORAL等)
-
基于模型的相似度度量(领域分类器准确率)
-
基于任务的相似度度量(迁移后的性能提升)
计算复杂度 :
许多领域自适应方法需要同时处理两个领域的数据,增加了计算负担。
解决方案:
-
高效的近似算法
-
在线学习策略
-
分布式计算框架
领域自适应是迁移学习中研究最深入、应用最广泛的技术之一。通过巧妙的 adaptation 策略,我们能够让AI模型更好地适应新环境,大大扩展了其应用范围。
13.3 领域泛化:让AI具备"未雨绸缪"的能力
如果说领域自适应是让AI学会"入乡随俗",那么领域泛化就是让AI具备"未雨绸缪"的能力------在未见过的领域上也能表现良好。
领域泛化的核心挑战
领域泛化面临的根本问题是:如何在训练阶段仅使用有限领域数据的情况下,学习到能够泛化到未知领域的模型?
核心困境:
-
测试时的领域在训练时完全不可见
-
无法利用目标领域的任何数据进行调整
-
需要从有限的源领域数据中提取本质规律
领域泛化的方法论
1. 领域不变表示学习
这类方法的目标是学习对领域变化不敏感的特征表示。
理论基础 :
如果特征表示Z = \\phi(X)满足:
-
与标签Y高度相关:I(Z;Y)大
-
与领域D无关:I(Z;D)小
那么基于Z的预测器应该能在所有领域上表现良好。
技术实现:
领域感知增强:
3. 元学习与优化策略
元学习为领域泛化提供了新的视角:学习如何学习,使得模型能够快速适应新领域。
MAML(模型无关的元学习) :
MAML通过在一组训练任务(领域)上优化模型,使得模型在经过少量梯度更新后就能在新任务上表现良好。
元学习目标:
领域生成 :
使用生成模型(如GAN、VAE)合成来自新领域的训练样本。

-
领域对抗训练:通过领域判别器惩罚领域特异性特征
-
相关性对齐:最小化不同领域特征分布的差异
-
信息瓶颈:在保留任务相
-
关信息的同时压缩输入信息
2. 数据增强与领域生成
通过创造性地增强训练数据,暴露模型于更广泛的领域变化。
传统数据增强:
-
图像:旋转、缩放、颜色变换
-
文本:同义词替换、语序调整
-
音频:速度变化、背景噪声添加
-
基于领域间插值:MixUp、DomainMix
-
风格迁移:将内容与风格分离并重新组合
-
对抗样本生成:创建具有挑战性的样本
领域泛化的元学习 :
将每个训练领域视为一个元学习任务,目标是学习一个初始参数,使其在经过少量目标领域样本调整后就能快速适应。
4. 集成与模块化方法
通过组合多个专家或模块来提高泛化能力。
领域特定专家 :
为每个训练领域训练专门的模型,测试时通过某种机制组合这些专家的预测。
动态网络 :
让模型能够根据输入样本调整其结构或参数。
模块化架构 :
设计包含共享模块和领域特定模块的架构,测试时主要依赖共享模块。
领域泛化的评估框架
评估领域泛化性能需要精心设计实验设置:
留出领域评估 :
将可用领域分为训练领域和测试领域,确保测试领域在训练时完全不可见。
领域划分策略:
-
随机划分:随机选择训练和测试领域
-
难度分层:基于领域难度进行划分
-
语义分组:基于领域语义相似度划分
性能指标:
-
平均准确率:在所有测试领域上的平均性能
-
最差情况性能:在表现最差的测试领域上的性能
-
性能方差:在不同测试领域上的性能差异
领域泛化的实际应用
领域泛化技术在许多实际场景中都有重要应用:
医疗影像分析 :
模型在不同医院、不同设备采集的影像数据上都能保持良好性能。
自动驾驶系统 :
车辆能够适应不同城市、不同天气条件的道路环境。
金融风控 :
风控模型能够适应经济周期变化、市场环境变化。
智能客服 :
对话系统能够理解不同地区、不同文化背景用户的表达方式。
未来发展方向
领域泛化仍然是机器学习中的开放挑战,未来的研究方向包括:
理论理解:
-
泛化理论的扩展
-
领域偏移的定量分析
-
泛化性能的理论保证
算法创新:
-
更高效的元学习算法
-
基于因果推断的方法
-
大规模预训练与领域泛化的结合
实际部署:
-
计算效率的优化
-
在线学习与增量学习
-
与其他学习范式的集成
领域泛化代表了机器学习系统适应能力的终极目标。通过在这方面的持续研究,我们正在向着构建真正智能、鲁棒的AI系统迈进。
完整Python示例:迁移学习实战
下面我们通过一个完整的示例来演示领域自适应和领域泛化的实际应用。我们将使用PyTorch实现一个在数字识别任务上的迁移学习系统。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.metrics import accuracy_score
import itertools
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 自定义数据集类,模拟领域偏移
class DomainDataset(Dataset):
def __init__(self, base_data, base_labels, domain_type, domain_param):
"""
base_data: 基础数据 (MNIST图像)
base_labels: 对应标签
domain_type: 领域类型 ('color', 'rotation', 'noise')
domain_param: 领域参数
"""
self.data = base_data.clone()
self.labels = base_labels.clone()
self.domain_type = domain_type
self.domain_param = domain_param
# 应用领域变换
self._apply_domain_shift()
def _apply_domain_shift(self):
if self.domain_type == 'color':
# 颜色偏移:调整对比度和亮度
contrast = self.domain_param
self.data = torch.clamp(self.data * contrast, 0, 1)
elif self.domain_type == 'rotation':
# 旋转偏移
angle = self.domain_param
# 简化的旋转模拟(实际应该使用affine变换)
if angle != 0:
self.data = torch.rot90(self.data, k=int(angle/90), dims=[2, 3])
elif self.domain_type == 'noise':
# 噪声偏移
noise_level = self.domain_param
noise = torch.randn_like(self.data) * noise_level
self.data = torch.clamp(self.data + noise, 0, 1)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
# 特征提取器
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((4, 4))
)
def forward(self, x):
return self.conv_layers(x).view(x.size(0), -1)
# 标签分类器
class LabelClassifier(nn.Module):
def __init__(self, input_dim, num_classes):
super(LabelClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, num_classes)
)
def forward(self, x):
return self.fc(x)
# 领域判别器
class DomainDiscriminator(nn.Module):
def __init__(self, input_dim):
super(DomainDiscriminator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, 2) # 2个领域:源域和目标域
)
def forward(self, x):
return self.fc(x)
# 领域对抗神经网络 (DANN)
class DANN(nn.Module):
def __init__(self, num_classes):
super(DANN, self).__init__()
self.feature_extractor = FeatureExtractor()
self.label_classifier = LabelClassifier(128*4*4, num_classes)
self.domain_discriminator = DomainDiscriminator(128*4*4)
def forward(self, x, alpha=1.0):
features = self.feature_extractor(x)
# 梯度反转层
reverse_features = GradientReversal.apply(features, alpha)
class_output = self.label_classifier(features)
domain_output = self.domain_discriminator(reverse_features)
return class_output, domain_output
# 梯度反转层
class GradientReversal(torch.autograd.Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
return output, None
# MMD损失(最大均值差异)
def mmd_loss(source_features, target_features):
"""
计算源域和目标域特征之间的MMD损失
"""
source_mean = torch.mean(source_features, dim=0)
target_mean = torch.mean(target_features, dim=0)
mmd = torch.norm(source_mean - target_mean, p=2)
return mmd
# 训练函数 - 标准方法(无领域自适应)
def train_standard(model, train_loader, test_loader, num_epochs=10):
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
train_losses = []
test_accuracies = []
for epoch in range(num_epochs):
model.train()
total_loss = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output, _ = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 测试
test_acc = evaluate(model, test_loader)
train_losses.append(total_loss / len(train_loader))
test_accuracies.append(test_acc)
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader):.4f}, Test Acc: {test_acc:.4f}')
return train_losses, test_accuracies
# 训练函数 - 领域自适应方法
def train_dann(model, source_loader, target_loader, test_loader, num_epochs=10):
optimizer = optim.Adam(model.parameters(), lr=0.001)
class_criterion = nn.CrossEntropyLoss()
domain_criterion = nn.CrossEntropyLoss()
train_losses = []
test_accuracies = []
for epoch in range(num_epochs):
model.train()
total_loss = 0
# 计算自适应参数alpha
p = float(epoch) / num_epochs
alpha = 2. / (1. + np.exp(-10 * p)) - 1
for (source_data, source_target), (target_data, _) in zip(source_loader, itertools.cycle(target_loader)):
# 准备数据
source_data = source_data.to(device)
source_target = source_target.to(device)
target_data = target_data.to(device)
batch_size = source_data.size(0)
# 创建领域标签
source_domain = torch.zeros(batch_size, dtype=torch.long).to(device)
target_domain = torch.ones(batch_size, dtype=torch.long).to(device)
optimizer.zero_grad()
# 源域前向传播
source_class_output, source_domain_output = model(source_data, alpha)
class_loss = class_criterion(source_class_output, source_target)
source_domain_loss = domain_criterion(source_domain_output, source_domain)
# 目标域前向传播
_, target_domain_output = model(target_data, alpha)
target_domain_loss = domain_criterion(target_domain_output, target_domain)
# 总损失
total_domain_loss = source_domain_loss + target_domain_loss
loss = class_loss + 0.5 * total_domain_loss
loss.backward()
optimizer.step()
total_loss += loss.item()
# 测试
test_acc = evaluate(model, test_loader)
train_losses.append(total_loss / len(source_loader))
test_accuracies.append(test_acc)
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(source_loader):.4f}, Test Acc: {test_acc:.4f}')
return train_losses, test_accuracies
# 训练函数 - MMD方法
def train_mmd(model, source_loader, target_loader, test_loader, num_epochs=10):
optimizer = optim.Adam(model.parameters(), lr=0.001)
class_criterion = nn.CrossEntropyLoss()
train_losses = []
test_accuracies = []
for epoch in range(num_epochs):
model.train()
total_loss = 0
for (source_data, source_target), (target_data, _) in zip(source_loader, itertools.cycle(target_loader)):
source_data = source_data.to(device)
source_target = source_target.to(device)
target_data = target_data.to(device)
optimizer.zero_grad()
# 提取特征
source_features = model.feature_extractor(source_data)
target_features = model.feature_extractor(target_data)
# 分类输出
source_class_output = model.label_classifier(source_features)
# 计算损失
class_loss = class_criterion(source_class_output, source_target)
mmd = mmd_loss(source_features, target_features)
# 总损失
loss = class_loss + 0.5 * mmd
loss.backward()
optimizer.step()
total_loss += loss.item()
# 测试
test_acc = evaluate(model, test_loader)
train_losses.append(total_loss / len(source_loader))
test_accuracies.append(test_acc)
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(source_loader):.4f}, Test Acc: {test_acc:.4f}')
return train_losses, test_accuracies
# 评估函数
def evaluate(model, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output, _ = model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += target.size(0)
return correct / total
# 可视化特征分布
def visualize_features(model, source_loader, target_loader, method_name):
model.eval()
source_features = []
target_features = []
source_labels = []
target_labels = []
with torch.no_grad():
for data, target in source_loader:
data = data.to(device)
features = model.feature_extractor(data)
source_features.append(features.cpu().numpy())
source_labels.append(target.numpy())
for data, target in target_loader:
data = data.to(device)
features = model.feature_extractor(data)
target_features.append(features.cpu().numpy())
target_labels.append(target.numpy())
source_features = np.vstack(source_features)
target_features = np.vstack(target_features)
source_labels = np.hstack(source_labels)
target_labels = np.hstack(target_labels)
# 使用t-SNE降维
tsne = TSNE(n_components=2, random_state=42)
all_features = np.vstack([source_features, target_features])
all_embeddings = tsne.fit_transform(all_features)
source_embeddings = all_embeddings[:len(source_features)]
target_embeddings = all_embeddings[len(source_features):]
# 绘制特征分布
plt.figure(figsize=(10, 8))
# 源域特征
for i in range(10):
mask = source_labels == i
plt.scatter(source_embeddings[mask, 0], source_embeddings[mask, 1],
label=f'Source {i}', alpha=0.6, marker='o')
# 目标域特征
for i in range(10):
mask = target_labels == i
plt.scatter(target_embeddings[mask, 0], target_embeddings[mask, 1],
label=f'Target {i}', alpha=0.6, marker='^')
plt.title(f'Feature Distribution - {method_name}')
plt.legend()
plt.tight_layout()
plt.savefig(f'feature_distribution_{method_name}.png')
plt.show()
# 主函数
def main():
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)
# 模拟数据加载(实际应用中应该使用真实数据)
# 这里我们创建模拟的MNIST风格数据
print("Generating synthetic data...")
# 源域数据(正常MNIST风格)
source_data = torch.randn(1000, 1, 28, 28)
source_data = torch.sigmoid(source_data) # 模拟归一化到[0,1]
source_labels = torch.randint(0, 10, (1000,))
# 目标域数据(应用领域偏移)
target_data = torch.randn(500, 1, 28, 28)
target_data = torch.sigmoid(target_data)
target_labels = torch.randint(0, 10, (500,))
# 测试数据
test_data = torch.randn(200, 1, 28, 28)
test_data = torch.sigmoid(test_data)
test_labels = torch.randint(0, 10, (200,))
# 创建数据集
source_dataset = DomainDataset(source_data, source_labels, 'color', 1.5)
target_dataset = DomainDataset(target_data, target_labels, 'color', 0.7) # 不同的颜色偏移
test_dataset = DomainDataset(test_data, test_labels, 'color', 0.7) # 与目标域相同的偏移
# 创建数据加载器
source_loader = DataLoader(source_dataset, batch_size=32, shuffle=True)
target_loader = DataLoader(target_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 训练标准模型(无领域自适应)
print("\n1. Training Standard Model (No Domain Adaptation)")
standard_model = DANN(10).to(device)
standard_losses, standard_accs = train_standard(standard_model, source_loader, test_loader, num_epochs=5)
# 训练DANN模型
print("\n2. Training DANN Model (Domain Adversarial)")
dann_model = DANN(10).to(device)
dann_losses, dann_accs = train_dann(dann_model, source_loader, target_loader, test_loader, num_epochs=5)
# 训练MMD模型
print("\n3. Training MMD Model (Distribution Matching)")
mmd_model = DANN(10).to(device)
mmd_losses, mmd_accs = train_mmd(mmd_model, source_loader, target_loader, test_loader, num_epochs=5)
# 比较结果
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(standard_losses, label='Standard')
plt.plot(dann_losses, label='DANN')
plt.plot(mmd_losses, label='MMD')
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(standard_accs, label='Standard')
plt.plot(dann_accs, label='DANN')
plt.plot(mmd_accs, label='MMD')
plt.title('Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.savefig('comparison_results.png')
plt.show()
# 可视化特征分布
print("\nVisualizing feature distributions...")
visualize_features(standard_model, source_loader, test_loader, "Standard")
visualize_features(dann_model, source_loader, test_loader, "DANN")
visualize_features(mmd_model, source_loader, test_loader, "MMD")
# 最终性能比较
final_standard_acc = evaluate(standard_model, test_loader)
final_dann_acc = evaluate(dann_model, test_loader)
final_mmd_acc = evaluate(mmd_model, test_loader)
print(f"\nFinal Test Accuracy:")
print(f"Standard Model: {final_standard_acc:.4f}")
print(f"DANN Model: {final_dann_acc:.4f}")
print(f"MMD Model: {final_mmd_acc:.4f}")
if __name__ == "__main__":
main()这个完整的迁移学习示例展示了:
核心功能
-
领域偏移模拟:通过颜色变换模拟真实世界中的领域偏移
-
三种迁移学习方法:
-
标准方法(无领域自适应)
-
领域对抗神经网络(DANN)
-
最大均值差异(MMD)方法
-
-
全面评估:
-
训练过程监控
-
特征分布可视化
-
性能对比分析
-
关键特性
模块化设计:
-
特征提取器、分类器、领域判别器分离
-
易于扩展和修改
多种领域自适应策略:
-
对抗学习(DANN)
-
分布匹配(MMD)
-
梯度反转技术
可视化分析:
-
训练曲线对比
-
特征空间分布
-
t-SNE降维可视化
实际应用价值
这个示例演示了如何在实际项目中:
-
识别和模拟领域偏移
-
实现多种领域自适应算法
-
评估迁移学习效果
-
可视化模型学到的特征表示
通过这个完整的示例,你可以深入理解迁移学习的核心概念,并掌握在实际项目中应用这些技术的能力。迁移学习作为解决领域偏移和提升模型泛化能力的重要技术,在现实世界的AI应用中发挥着越来越重要的作用。
迁移学习不仅是一种技术,更是一种思维方式------它提醒我们,在构建AI系统时,要始终考虑模型在新环境中的适应能力和泛化性能。随着研究的深入和应用场景的扩展,迁移学习必将在推动AI技术落地和普及方面发挥更加重要的作用。