今天开发者说采访的对象是郭志才,他曾在外企和京东工作,后投身大模型相关的行业,一干就是八年。
今年他在Github发布的 AI 生成 PPT 的项目,仅上线半年就斩获 1.4k star。在探索Ai生成内容的尝试中,他勇敢迈出了一步,在这个过程中他也遇到了许多志同道合的朋友,今天他希望能在这里和更多人相遇。

从"组装电脑大神"到NLP工程师
本科阶段,我就读于天津工业大学光电专业,并非计算机科班出身,但因为我一直对计算机领域抱有浓厚兴趣,我主动选修了相关课程。当时我还热衷于硬件研究,那时候特别流行组装电脑,我也喜欢捣鼓这些,当时我们全系的人几乎都知道我会组装电脑和做系统,不少同学组装电脑时都会来寻求我的帮助。
毕业后,我进入一家外企担任运维开发工程师,主要负责服务器管理、监控维护及服务开发等工作。之后,我又跳槽到京东,转型从事大数据运维相关岗位;后续又加入一家初创企业,聚焦 NLP 小模型的研发工作。如今,我的工作方向已拓展至大模型、多模态技术及 Agent 相关领域。
目前,我任职于一家医疗科技公司,主要做的是医疗+ AI 的赛道。今年 11 月,国家卫健委发布相关政策,明确提出要实现基层诊疗智能 AI 全覆盖,并从八个维度阐述了医疗与 AI 的融合路径,其中多项内容已落地或处于持续完善阶段。我们当前的核心发力点是医疗 + 科研方向,我对该领域的未来前景也十分看好。
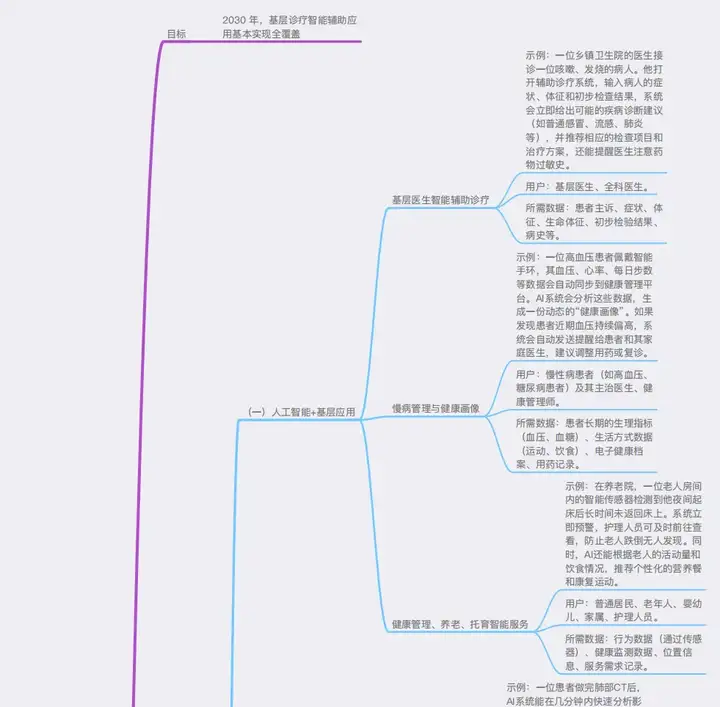
做了一套Ai生成PPT项目,斩获1.4K star
做这个 AI 生成 PPT 项目的初衷其实特别简单:我想做出一款好用的产品。
做这个项目之前,我调研了不少大厂的产品和开源项目,那时候PPT 系统的市场需求还挺大的,所以我就着手开发了第一套系统。不过第一版系统还很不成熟,存在不少问题。
这套系统的开发界面是另一个开发者做的,他的前端思路是用 XML 渲染,先让大模型生成 XML,再由 XML 生成 PPT------ 这个思路本身不错,但有两个明显的缺点:一是模板样式特别少,二是预览的 PPT 和最终导出的版本不一致,毕竟 HTML 格式渲染成 PPT 很难做到 1:1 还原。当时我做了很多升级和维护来解决这些问题,用了谷歌的 A2A 和 ASK 搭建多 agent 系统,现在这套 PPT 系统也还是基于这个思路来实现的。
最初的核心逻辑是:用户输入一个主题,系统先检索大量资料生成大纲,再把大纲拆分成不同部分,自动生成多个并行的 agent,每个 agent 负责研究其中一部分,研究完汇总结果,最后再把汇总的内容写成 PPT。说白了就是总分总的结构:先有整体大纲,再分模块研究,最后汇总成完整的 PPT。
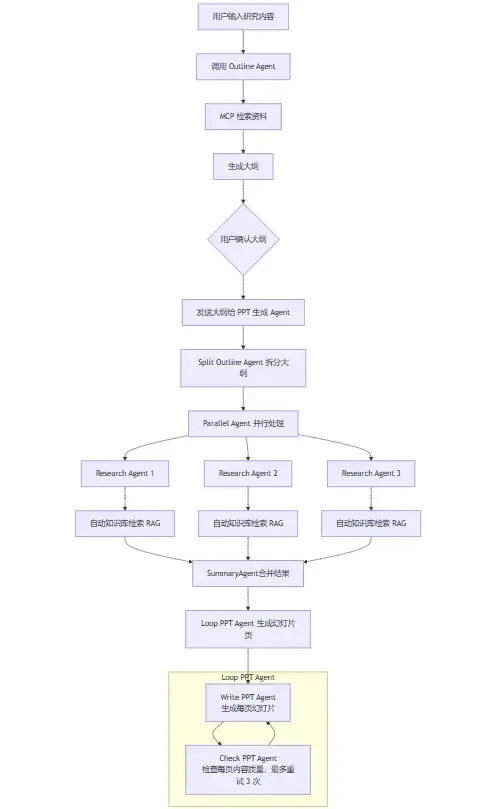
这个思路本身没问题,但因为第一版系统的那些缺点,后来我就想着开发第二套系统 ------ 模板式 PPT。这一版解决了模板少、导出渲染不一致的问题,还把 agent 做了简化。为了提升速度简化 agent ,我又专门写了一套强化学习的训练代码。
现在的训练模式已经变成了 agent 训练,核心是动态调用工具、动态决定下一步动作,用的是 react 模式,也就是 "思考 - 观察 - 行动"。最开始我试过用 art 框架做,但翻墙太麻烦,就换成了国内的 model scope 框架,效果还不错,不过目前强化学习这块还得继续升级。
强化学习最大的难点是奖励机制不好判断。举个例子,生成一份大纲,得先定义清楚什么样的大纲才算 "好",模型才能跟着学。奖励可以自定义,比如格式奖励 ------ 生成的大纲符合 Markdown 格式就给奖励;或者内容奖励 ------ 内容质量高、有深度也给奖励。不同奖励的判断方式不一样,格式奖励能靠规则判断,内容奖励得用更优质的大模型打分,但奖励机制一旦不稳定,模型训练的效果也会受影响。
还有个难点是,现在的训练都是单个 agent 针对单一任务练,比如先训练生成大纲的 agent,再训练写内容的 agent,要么同时练两个,要么一个模型练两遍。但在同一个模型里先练完大纲 agent,再练内容 agent,很容易导致模型退化;可做 PPT 本身是个完整流程,必须先写大纲再写内容。这里面至少涉及到四类奖励:大纲格式、大纲内容、PPT 格式、PPT 内容,奖励维度越多,模型训练的稳定性就越差。
不过现在也有不少新框架出来了,比如国外微软的 agent-lightning、国内阿里的 agent scope,主流方向都是研发多任务训练的框架,专门针对 agent 训练设计的,比我之前手动拼接的框架好用多了。到现在我已经开发了两版 PPT 系统、两版训练框架,第三版训练框架也在升级迭代中。我觉得到今年年底,这类训练框架应该能成熟起来,到时候多 agent 的智能水平也能再上一个台阶。
这是一个"众筹项目"
在这个项目从上线到后续升级维护的过程中,我认识了特别多朋友,他们不光给我的项目提了许多实用的意见和建议,还有不少人直接贡献代码,跟着我一起改进这个系统。比如 PPT 里怎么插图片、发图片,还有一键启动这些功能,都是热心网友和我一起做出来的。
还有很多网友给我提了不少新的功能改进想法。比如有人说,能不能支持根据上传的文件生成 PPT------ 有的用户不想联网搜最新资料,就想拿自己的一篇文章来做 PPT,那只要把文章传上来,系统就能照着文章生成对应的 PPT。另外还有两个还没实现的功能:一个是自动化相关的,还有一个是用 AI 生成模板。比如有些公司有自己专属的 PPT 模板,用户把模板传上来,AI 能先把模板转换成在线 PPT 格式,之后再照着这个模板的风格生成 PPT。这些都是网友给我的特别宝贵的建议,我也希望在不远的将来能把这些功能都实现。
开发第一套系统的时候,上线才一周就涨了八百多个关注,那会儿我突然就觉得,自己做的项目真的被很多人用上了,说实话还挺震撼的。我也发现,能解决大家日常高频遇到的问题、或者是常用的工具类产品,更容易受到关注 ------ 这也成了我之后做开发的一个方向。
现在的技术更新特别快,差不多每三个月就至少有一次比较大的迭代。我觉得下一步的迭代重点还是会放在 agentic training 这块。因为每个人关注的点、使用的场景都不一样,用这种 agent 的方式去训练,能适配更多不同的情况,按这个思路做训练,整体的逻辑也会更顺畅。
AI正在模糊内容的产权边界
AI生成内容的版权争议,确实特别难解决。你说现在的 AI 有版权吗?就拿谷歌、OPEN AI 来说,他们训练模型的时候,会从全网搜集各种数据,这些数据的来源是否有版权,AI是无法精确判断的,这些模型训练完生成内容提供给全世界,但它的数据源 90% 以上都存在版权问题。
再说咱们国内的模型,为啥一个新模型出来后,其他模型很快也变聪明了?因为这里面有个 "蒸馏" 的过程。比如现在最新的模型是 Gemini3,它一出来,很快就会有模型达到接近它的水平,但基本不会超越它。因为咱们现在开发模型,大多是做模型蒸馏 ------ 把 Gemini3 当成 "老师",让它教 "学生" 模型,获取对应的数据集、答案和解题思路,再用这些去训练自己的模型。靠这种方式训练,想超越 "老师" 很难,真要做到的话,得在强化学习这块下更大的功夫。要是没有 "老师" 指导,给模型设定奖励的时候,谁来判断奖励是否合理?模型蒸馏就好比有能力比你强的人给你指明方向。现在的开源数据,大多能给出明确答案,不管是数学验证还是代码验证,都能得出清晰的奖励标准。但像 PPT 这种东西,什么样的质量才算 "好",有时候根本说不清楚,这时候就得靠更智能的模型来判断;咱们获取数据集也是一样,得向更聪明的模型去要数据。
所以我觉得版权问题肯定是存在的,但 AI 正把这个问题变得越来越模糊。有人问过我:用 AI 生成图片、代码,或者写教案、写歌、写网络小说,这些东西的版权就归AI所有了吗?要是真这样,那世界上估计没几家独立的公司了,所有公司都成了 AI 的 "小弟",其他人都没版权了 ------ 这显然不可能。所以我觉得,AI 其实是让版权的边界变模糊了,也让全人类的知识在慢慢走向共享。
外企和国内私企的工作异同
外企和私企的职场氛围差异挺明显的。我之前在国内私企和外企都待过,外企那种"规规矩矩讲平等"的感觉特别突出。当时我们团队有日本同事、爱尔兰同事、美国同事,我们的年龄差别很大,当时我是算最年轻的,其次是日本同事,大概30多岁,而美国同事大概50岁,爱尔兰同事大概是50多岁,胡子都白了。我那时候刚毕业没几年,是队里最年轻的,但从没因为资历浅被冷落过------不管是开需求会还是查运维故障,大家都围着屏幕平等讨论,领导也不会摆架子,这种氛围对程序员来说真的很舒服。
有一次我们去号称印度硅谷的班加罗尔出差了一星期,我们从出发前就开始"做功课",网上总说"印度水质可能不行",结果到了之后,我们几个人紧张了好几天,倒也没人闹肚子,算是虚惊一场。饮食上的冲击更直接。我们在当地吃咖喱,端上来的时候香气特别浓,但看到旁边印度人直接用手抓着吃,还是受到了一点文化冲击。
比饮食更特别的是当地的风土人情。工作间隙我们去参观了几处佛像古迹,进佛殿必须光脚,那时候是夏天,光脚出入的时候还有点烫脚。还有路上的牛,真的是"横行无忌",后来才知道在印度牛是神圣的象征,连堵车的时候,司机都会停下来等牛慢悠悠走过。
让我印象更深的是印度的交通。我们住的地方离办公点也就五到十公里,搁国内开十分钟就到了,在班加罗尔却要堵一个小时。我们挤在一辆小巴士里,红绿灯仿佛只是个摆设。这几天的出差让我感受到了不一样的风土人情和工作氛围,印象还是很深的。

我此前任职的外企主营企业邮箱系统,核心服务对象是中国移动、中国电信等通信运营商。当时企业邮箱市场规模持续萎缩,行业内企业频繁合并,业务范围不断收缩 ------ 在缺乏创新突破的情况下,企业发展明显走下坡路。出于职业发展的考量,我最终选择了离职。
之后我跳槽至京东,当时电商大促活动热度很高。每逢双十一、618 这类大促节点,系统升级工作需提前一周暂停,所有精力都投入到保障系统稳定上。大促期间,用户习惯在凌晨 12 点集中抢购,服务器承载着巨大压力;双十一当天公司也会通过数据大屏实时展示每分钟的销售额,整个大促过程极具挑战。大促当天我们基本需要连续工作 24 小时,公司会安排丰盛的餐食,到后半夜三四点后,无需全员值守,大多数人可以前往公司安排的酒店休息。高强度的工作持续到后半夜,脑子都转不动了,现在回想起那段经历就像 "渡劫" 一样。
现在就好多了,平台把深夜整点促销的玩法取消了,用户的购物欲也没那么强了,不用像以前那么卷了。
未来的职业规划
我平时工作里会攒下不少 idea,很多还没来得及落地。我还是想往 AI 创新这块儿深耕,也确实有一些自己的想法。之前在 AIGC 相关的大会上认识过一个人,他们当时在做的事特别有意思 ------ 用 AI 帮人类创新、拓宽思维。AI 不只能做那些有规律的事,还能尝试无规律的创新,他们当时是靠知识图谱来做创新挖掘,现在我们也在做类似的事,不过是聚焦在医学方向的创新。怎么挖掘创新点、落地创新想法,我觉得这块儿大有可为。
核心问题其实是:AI 该怎么帮人创新,还能验证这个创新确实符合大的创新方向?这事没那么容易,既要大量思考,还得做很多数据统计。创新得既结合实际,又能天马行空 ------ 首先得读透海量文献,才能判断某个主题或方向是不是未来的发展趋势,进而找到可能的创新点;提出创新想法后,还得想办法验证它的可行性:要去全网搜集相关知识,通过大数据统计确认这个方向没人做过,而且从实际层面来说确实能落地,这才能算找到一个好的创新点。
创新对人类来说本就很难,对 AI 而言也一样,但这块儿的价值特别大。你看美国那边做药物、蛋白质、基因相关的研究,还有神经网络模型里注意力结构更高效这类课题,都在靠 AI 做创新突破。我们日常工作里其实也有很多创新机会,比如把不同领域的点结合起来 ------ 就拿做 PPT 来说,哪个切入点能让人眼前一亮?哪两个看似不相关的领域交叉融合能出惊喜?这些都得结合创新理论、具体数据,再加上天马行空的思路,才能打磨出好的创新点。
正因为这块儿的价值和潜力都很大,我未来也打算往 AI 助力创新这个方向深入研究。
给AI新手的建议
我觉得现在要敢于迈出这一步。敢想敢做,读万卷书不如行万里路,你要真正去做起来。现在 AI 门槛越来越低了,以前做NLP的时候,你要学很多数学公式,你要看它到底是怎么去算的,计算原理是什么,现在基本上统一了,以前是各种各样的模型,每个领域还不通用,现在用一个生成模型就全部解决了,训练算法也比较统一,因为好的算法可能就那几种,对年轻人来说,不用学那么多老旧的东西了,只需要你去尝试最新的算法和技术,很快就能掌握皮毛。
现在借助 AI 去实现编程的话也很快,因为我们现在写代码,80%也是靠 AI 去写。所以对于现在想入门的年轻人来说,你只要大胆去做就行,有什么不懂的去问 AI 。以前需要自己探索,或者是上网查很多资料,现在AI可以解决 90 %以上的问题,现在对想入行的年轻人来说,学习 AI 的难度大大地降低了,这也算是我们的一个时代红利吧。
=故事征集=
《开发者说》是程序员客栈推出的一个访谈栏目,邀请了一些国内外有趣的程序员来分享他们的经验、观点与成长故事,我们尝试建立一个程序员交流与学习的平台。欢迎大家推荐朋友或自己来参加我们的节目,分享与对话是一件利他又利己的事。