西安交通大学联合华为等机构发表在2025 EMNLP上的RAG+框架,恰恰戳中了这个痛点。它通过引入"应用感知推理",让模型不仅能"搜到知识",更能"用好知识",在三大领域实现3%-5%的平均性能提升,峰值增益高达13.5%。下面来详细了解这个让RAG"脱胎换骨"的新方案~

在大模型时代,检索增强生成(RAG)早已成为解决知识密集型任务的标配------它就像给模型配了个"外挂知识库",能动态抓取最新信息,大幅提升回答的准确性。但用过的人都懂,传统RAG总有点"水土不服":明明检索到了正确的知识点,模型却不知道怎么用在具体任务里,尤其在数学、法律、医学这些需要复杂推理的领域,常常栽跟头。
西安交通大学联合华为等机构发表在2025 EMNLP上的RAG+框架,恰恰戳中了这个痛点。它通过引入"应用感知推理 ",让模型不仅能 "搜到知识 ",更能 "用好知识",在三大领域实现3%-5%的平均性能提升,峰值增益高达13.5%。下面来详细了解这个让RAG"脱胎换骨"的新方案~
论文地址:https://aclanthology.org/2025.emnlp-main.1630.pdf
01、传统RAG的"致命短板":懂知识,不会用
传统RAG的核心逻辑很简单:先根据用户查询检索相关知识,再把知识喂给模型生成答案。但这个流程存在一个关键漏洞------只关注"检索到什么",却忽略了"怎么用"。
比如解决数学题"从6名男生4名女生中选3人,至少1名女生有多少种选法",传统RAG能轻松检索到组合公式C(n,k)=n!/(k!(n−k)!),却会直接算出C(10,3)=120的错误答案。问题就出在它不知道"至少1名女生"需要用"总情况减全男生情况"的解题逻辑------这正是传统RAG缺失的"应用能力"。
从认知科学角度看,布鲁姆认知层次理论早就指出,"应用知识"是超越"记忆知识"的独立技能;而ACT-R认知架构也强调,事实知识(是什么)和程序性知识(怎么用)结合才能高效完成复杂任务。传统RAG只聚焦前者,自然在推理任务中力不从心。
现有改进方案也没能解决根本问题:有的微调检索器让知识更贴合生成需求,有的把任务拆分成子步骤逐个检索,但都没提供明确的"知识应用指南",模型还是得自己摸索怎么用检索到的内容。

02、RAG+的核心创新:给知识配"使用说明书"
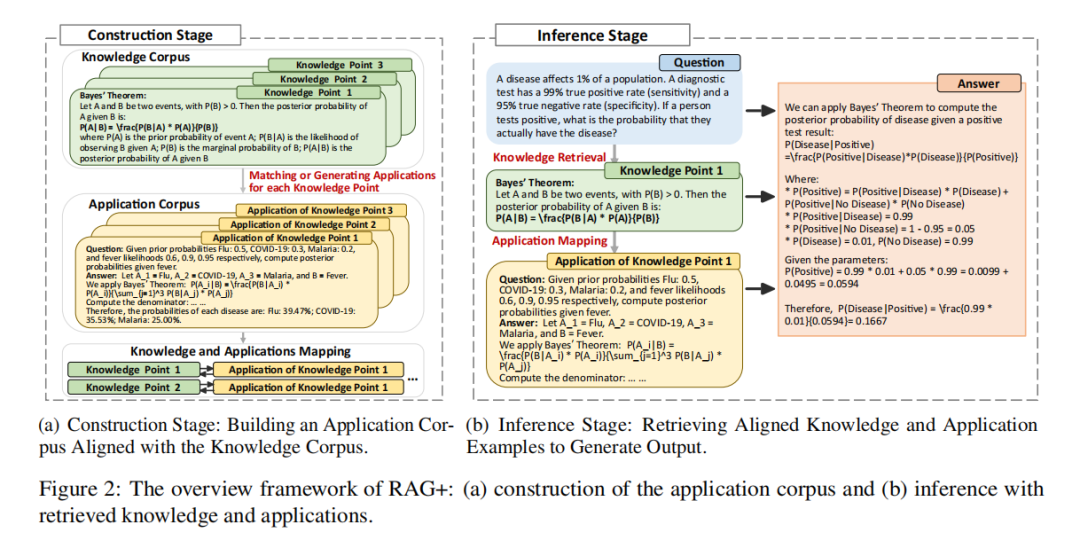
RAG+的解决方案其实很直观:既然模型不会用知识,那就直接给每个知识点配上"应用示例",让模型照着学、跟着用。它在传统RAG基础上增加了一个"应用语料库",形成"知识+应用"的双语料库结构,整个框架分为两大阶段。
构建阶段:给每个知识点找"应用搭档"
这个阶段的核心是打造一个与知识语料库K对齐的应用语料库A,对于每个知识项 k∈K ,会检索或生成一个应用示例 a∈A 来展示 k 的实际用途。简单说就是给每个知识点配好"使用说明书"。针对不同领域的数据情况,RAG+设计了两种构建策略:
- 应 用生成 :如果某个领域缺乏现成的应用案例(比如法律、医学),就用大模型自动生成。首先把知识分为两类:
概念性知识:包括静态的描述性信息,如定义、理论解释或实体和原理的描述。相应的应用通常涉及理解任务、上下文解释或类比,以阐明含义并加深理解。

程序性知识:动态的、可操作的信息,包括解决问题的策略、推理规则和分步方法。比如用具体例题展示贝叶斯定理的计算步骤。

- 应 用匹配:如果有现成的真实案例(比如数学题库),就通过"类别对齐+相关性选择",把知识点和真实应用案例配对,再人工优化确保准确性。对于没有匹配案例的少数知识点(不足10%),用自动生成的示例补充。
通过这两种策略,每个知识点都能找到对应的应用示例,形成"知识-应用"成对数据,为后续推理打下基础。
推理阶段:知识和应用"双检索"
推理时,RAG+会同时做两件事:
- 根据用户查询检索相关知识点(和传统RAG一样);
- 自动调取这些知识点对应的应用示例;
- 把"知识点+应用示例"一起塞进提示词,让模型既能参考事实,又能模仿应用逻辑。
关键是,RAG+是模块化设计,不用修改模型架构,也不用额外微调,直接就能集成到任何现有RAG pipeline里,真正实现"即插即用"。
03、实验结果:三大领域全面碾压传统RAG
研究团队在数学、法律、医学三个推理密集型领域做了全面测试,对比了传统RAG、Answer-First RAG、GraphRAG、Rerank RAG等主流方案,覆盖Qwen、LLaMA、DeepSeek、ChatGLM四大系列9个模型,结果相当亮眼。
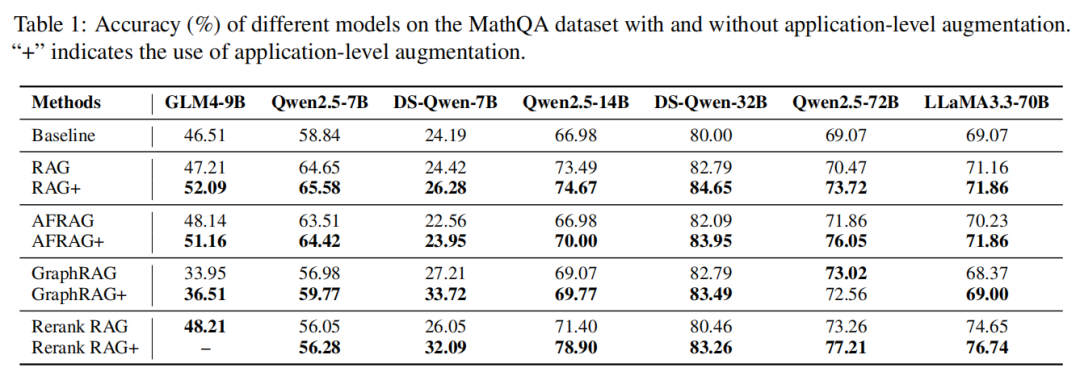
数学领域:小模型也能逆袭
数学任务的核心挑战是"将抽象公式转化为步骤化解题逻辑",实验结果清晰证明:RAG+通过补充应用示例,能有效解决传统RAG"知公式、不会用"的问题。
- 几乎所有RAG+变体均优于非增强版本:无论是小模型还是大模型,加入应用增强后性能均有提升:小模型DS-Qwen-7B用GraphRAG+时准确率较GraphRAG提升6.5%,用Rerank RAG+时较Rerank RAG提升6.0%;中模型Qwen2.5-14B在Rerank RAG+配置下表现最优,准确率较Rerank RAG提升超7.5%;大模型Qwen2.5-72B在RAG+、AFRAG+配置下,准确率分别较基础RAG、AFRAG提升3.25%、4.19%,虽增幅小于中小模型,但胜在稳定。
- 传统GraphRAG在数学领域"水土不服",应用增强可修复:GraphRAG因侧重"实体关系检索"(如"多项式"与"插值"的关联),与数学任务"需要步骤化计算"的需求不匹配,导致部分大模型性能下降(如Qwen2.5-72B用GraphRAG时准确率略低于普通RAG)。但加入应用示例后(GraphRAG+),模型能通过示例学到"如何用实体关系解题",Qwen2.5-7B、Qwen2.5-14B的准确率分别较GraphRAG提升2.79%、0.7%。
- **推理复杂度越高,RAG+增益越显著:**简单数学题(如基础组合计算)中,RAG+提升约0.7%-2.5%;复杂题(如多项式插值、积分计算)中,提升幅度可达5%-7.5%。这表明:当任务需要"知识应用"而非"知识回忆"时,RAG+的价值更突出。
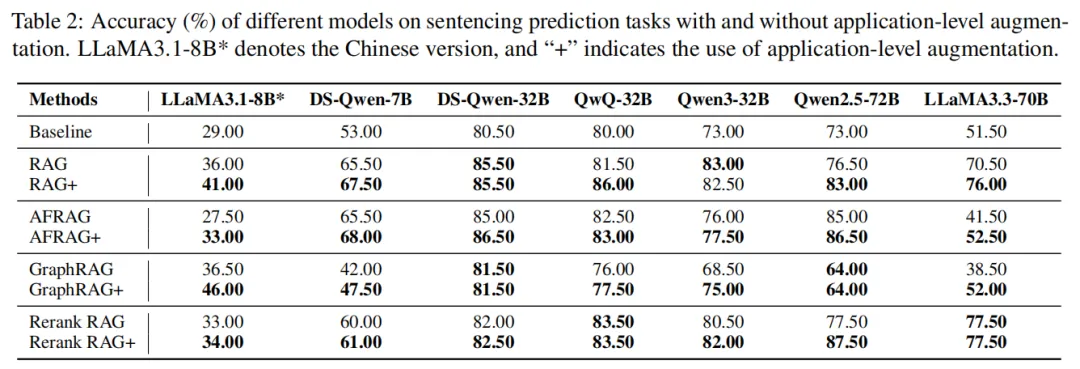
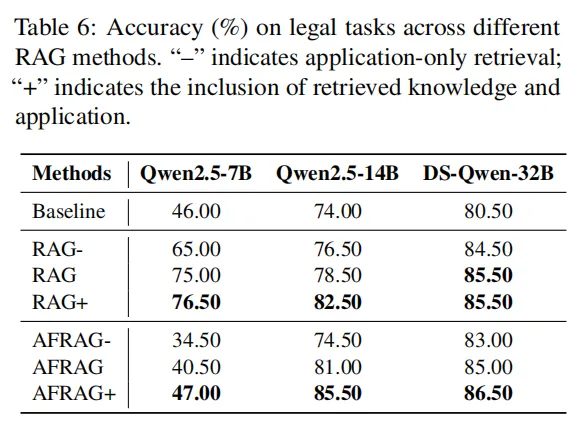
法律领域:量刑推理更精准,大模型增益最显著
- 大模型突破性能天花板:Qwen2.5-72B用Rerank RAG+时准确率达87.5%,较非增强版本(77.5%)提升10%,是所有领域中单一模型的最大增幅。原因是RAG+能同时检索"刑法条文"与"类似判例",帮模型精准判断"轻伤+持械""自首"等情节对量刑的影响,避免传统RAG"只看法条、忽略案情"的错误。
- 小模型摆脱"结构理解困境":DS-Qwen-7B、LLaMA3.1-8B等小模型,因难以理解GraphRAG的实体关系,单独使用GraphRAG时准确率仅42.0%、36.5%;加入应用增强后(GraphRAG+),准确率分别提升至47.5%、46.0%,应用示例将"实体关系"转化为"量刑步骤",降低了小模型的理解门槛。
- 大模型存在边际效应:LLaMA3.3-70B本身推理能力强,用RAG+后准确率较RAG仅提升5.5%,说明模型规模越大,对应用示例的依赖度越低,但RAG+仍能补充"罕见案情"的推理经验。
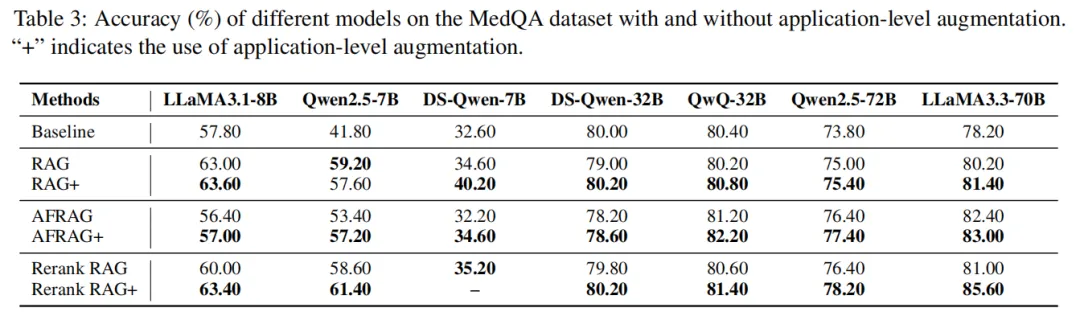
医学领域:诊断逻辑更严谨,Rerank RAG+成最优配置
- R erank RAG+适配多数模型:LLaMA3.3-70B用Rerank RAG+时准确率达85.6%,较Rerank RAG(81.0%)、基线(78.2%)分别提升4.6%、7.4%;Qwen2.5-7B、LLaMA3.1-8B等小模型,用Rerank RAG+后准确率也有2.2%-3.4%的提升。重排序保证了"症状-疾病"知识的相关性,应用示例则教模型建立"基础病→血管病变→多症状"的因果链,避免传统RAG"症状误判"。
- A FRAG+提供稳定补充:AFRAG(先生成答案再检索证据)在医学领域表现优于普通RAG(如QwQ-32B用AFRAG时准确率81.2%,RAG时80.2%),加入应用增强后(AFRAG+)进一步提升至82.2%,说明"生成引导检索+应用指导"能减少"漏诊",让诊断更全面。
消融实验
模型规模的影响:规模与应用增强呈"互补关系"
实验用Qwen2.5系列(7B/14B/72B)测试发现:
- 模 型规模越大,RAG+的增益越显著:法律领域中,7B模型用RAG+时准确率76.5%,14B提升至82.5%,72B达87.5%;医学领域中,7B模型RAG+准确率57.6%,14B、72B分别提升至69.8%、75.2%。
- 核心原因:大模型的 "逻辑提炼能力 "更强,能从应用示例中总结 "通用推理模板 ";小模型则更依赖应用示例的 "步骤模仿 ",虽有增益但幅度有限。
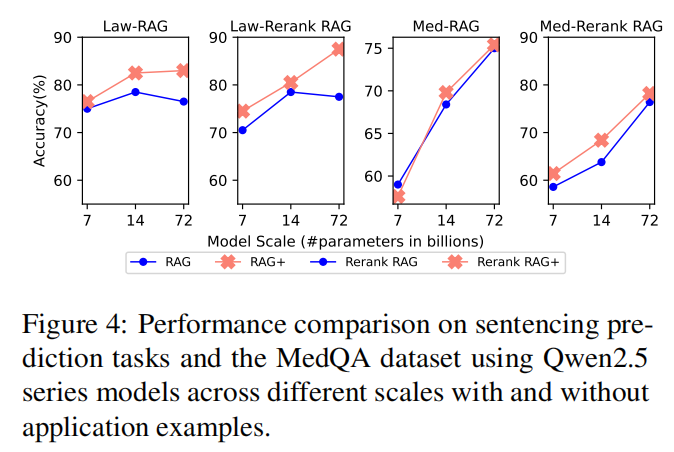
重排序模型的影响:大模型重排+应用增强实现"1+1>2"
传统Rerank RAG的痛点是"小模型重排失效"(如Qwen2.5-7B常因看不懂指令直接生成答案),实验用Qwen2.5-72B(大模型)替代小模型做重排序,结果显示:
- 大模型重排本身即有增益:Qwen2.5-7B在法律任务中,用大模型重排的Rerank(72B)RAG准确率72.5%,较自排的Rerank RAG(70.5%)提升2%;
- 叠加应用增强后增益翻倍:Qwen2.5-7B用Rerank(72B)RAG+时,法律任务准确率飙升至83.5%,较自排Rerank RAG+(74.5%)提升9%。这证明"高质量检索结果+应用指导 "是性能最大化的关键,且跨模型协作(大模型重排+小模型生成)能平衡 "效果与成本"。
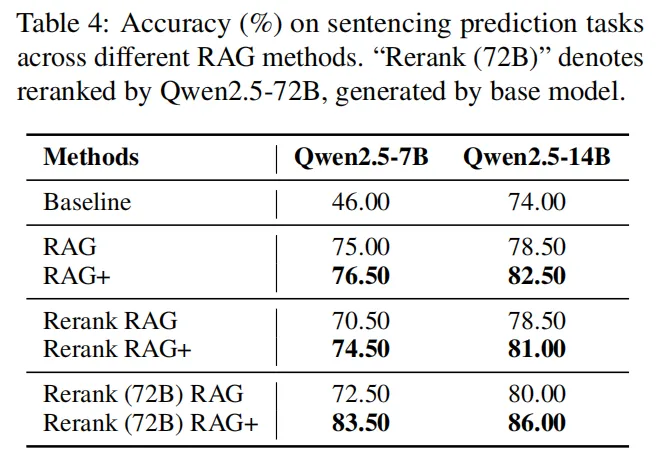
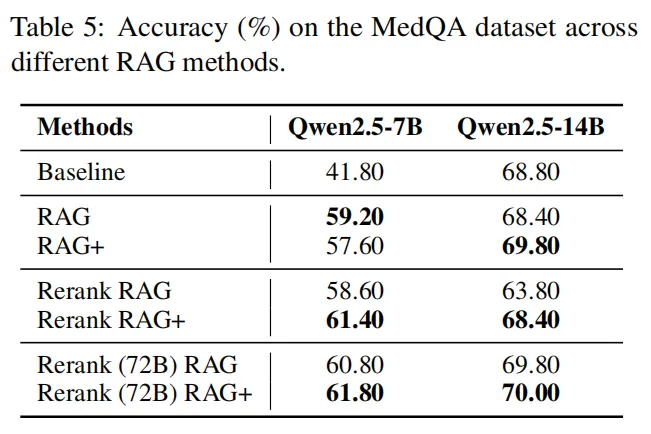
仅应用示例的影响:应用示例可"救急",但不能替代知识
实验测试"只检索应用示例、不检索知识"(RAG-、AFRAG-)的效果,发现:
- 仅应用示例有基础增益:Qwen2.5-14B在法律任务中,用RAG-时准确率76.5%,较基线(74.0%)提升2.5%,应用示例能提供"推理结构线索"(如解题步骤模板);
- 但"知识+应用 "才是最优解:Qwen2.5-14B用RAG+时准确率82.5%,较RAG-提升6%;DS-Qwen-32B用AFRAG+时86.5%,较AFRAG-(83.0%)提升3.5%。无知识支撑时,应用示例易"用错场景"(如用数学步骤套法律推理),而知识能提供"事实锚点",确保应用逻辑不偏离。
案例直击:RAG+是怎么纠正错误的
以数学领域 "多项式插值问题" 为核心案例,对比传统 RAG 与 RAG + 的推理过程,即使传统 RAG 检索到正确知识,也可能因 "方法误用" 或 "执行失误" 出错;而 RAG + 的 "知识 + 应用" 双检索,能为模型提供 "方法选择依据" 与 "步骤校验模板",让复杂推理更精准、更可靠。

04、总结:RAG的下一站,是"会用知识"
对于需要复杂推理的特定场景(如数学计算、法律量刑、医学诊断),RAG+无需对现有RAG链路进行大幅算法改动,仅通过轻量化升级即可实现性能突破。这种升级看似简单,却精准解决了实际应用中"知识用不对、用不好"的核心痛点,让RAG从"事实回忆工具"进化为"复杂推理助手"。
现存难点:落地过程中需平衡"效果"与"成本"
尽管RAG+表现亮眼,但实际落地仍面临三大挑战:
- 应用语料库构建成本高:高质量应用示例需结合人工校验(如法律领域需律师审核判例、医学领域需医师验证临床逻辑),而纯LLM自动生成的示例可能存在错误(如简化复杂病情推理)或场景偏差,影响模型判断;
- 依赖"知识-应用"强对齐:若检索到的知识本身存在噪声(如错误法条解读、过时医学指南),或内容不完整(如缺失关键公式条件),与之绑定的应用示例可能"错上加错",反而误导模型推理;
- 检索效率未优化:随着"知识+应用"双语料库规模扩大,现有检索链路(如向量匹配、重排序)的耗时会同步增加,尚未针对双语料库设计更高效的检索策略,可能影响实时性需求较高的场景(如在线医疗问答)。
未来思考:从"可用"到"好用"的优化方向
RAG+的思路仍有巨大延伸空间,可从三个维度进一步探索:
- 场景化动态适配:当前应用示例多为静态匹配(一个知识点对应固定示例),未来可尝试让示例"动态调整"------例如根据用户查询的具体场景(如"轻伤量刑"vs"重伤量刑"),生成或筛选更贴合的应用案例,提升推理针对性;
- 技术融合优化:结合强化学习(RLHF)优化"知识-应用"的匹配精度,让模型在交互中学习"哪些示例更有效";或引入轻量化模型辅助生成应用示例,降低人工标注成本;
- 效率与效果平衡:针对双语料库设计专用检索优化方案(如知识与应用的联合索引、增量更新机制),在保证检索质量的同时提升速度,满足更多实时场景需求。
对开发者而言,RAG+的启示尤为明确:未来RAG开发不能只聚焦"如何搜得更准",更要关注"如何用得更好"。毕竟,检索到知识只是基础,让模型真正学会运用知识,才能释放RAG在复杂任务中的全部价值。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。