
【往期Linux回顾】:
/------------Linux入门篇-----------/
/------------Linux工具篇------------/
/------------Linux进程篇-------------/
【进程优先级目录】:
[1、侵入式链表管理 task_struct](#1、侵入式链表管理 task_struct)
[① 传统链表 vs 侵入式链表](#① 传统链表 vs 侵入式链表)
[② 通过节点指针 + 偏移量计算,反向获取结构体对象](#② 通过节点指针 + 偏移量计算,反向获取结构体对象)
[③ 问题:在进程管理中,为什么通常用链式结构存储 PCB(进程控制块)?](#③ 问题:在进程管理中,为什么通常用链式结构存储 PCB(进程控制块)?)
[① 进程优先级是什么?](#① 进程优先级是什么?)
[② 为什么要有进程优先级?](#② 为什么要有进程优先级?)
[4、如何理解PRI and NI](#4、如何理解PRI and NI)
[< 进程 nice 值与优先级调整说明 >](#< 进程 nice 值与优先级调整说明 >)
[< top调整进程优先级 >](#< top调整进程优先级 >)
[< 修改NI值的特殊情况 >](#< 修改NI值的特殊情况 >)
早高峰挤公交谁能先窜上去?Linux 里的进程抢 CPU 资源也是这德性 ------ 全靠 "优先级" 当 "插队密码"。这篇就扒明白这些数字咋帮进程 "抢座",还教你咋给进程开 "优先通道"~
1、侵入式链表管理 task_struct
① 传统链表 vs 侵入式链表
传统链表的逻辑是:让数据结构体 "依附" 于链表------ 比如定义一个链表节点,把数据结构体作为节点的 "数据域"(链表是主体,数据是附属)。
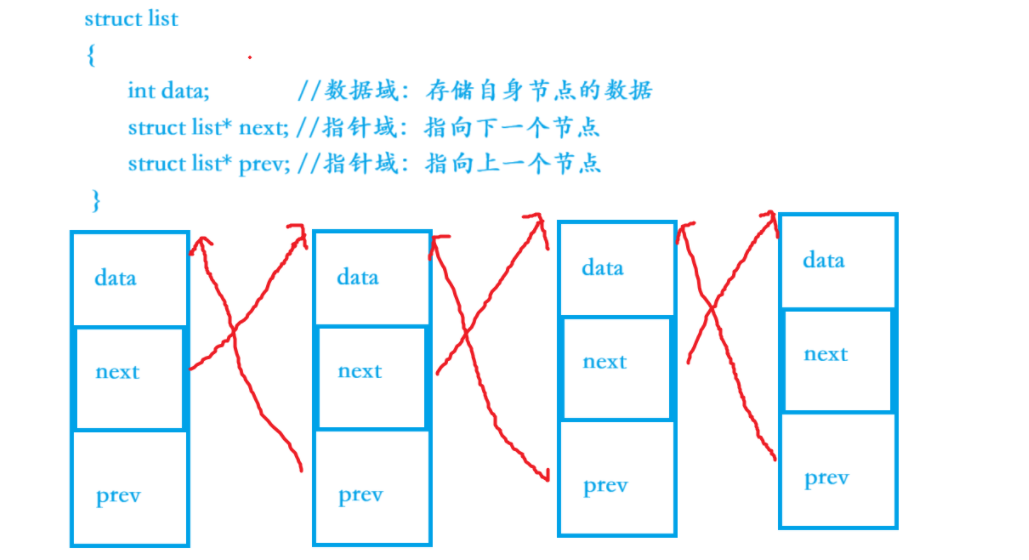
这种方式的核心问题是:数据与链表指针紧耦合,不同结构体要单独写链表逻辑,代码完全无法通用,冗余且维护成本高。
而侵入式链表正好相反:把通用链表节点 "嵌入" 到数据结构体内部------ 数据结构体是主体,链表节点是它的一个 "成员"(链表逻辑通过这个嵌入的节点实现)。
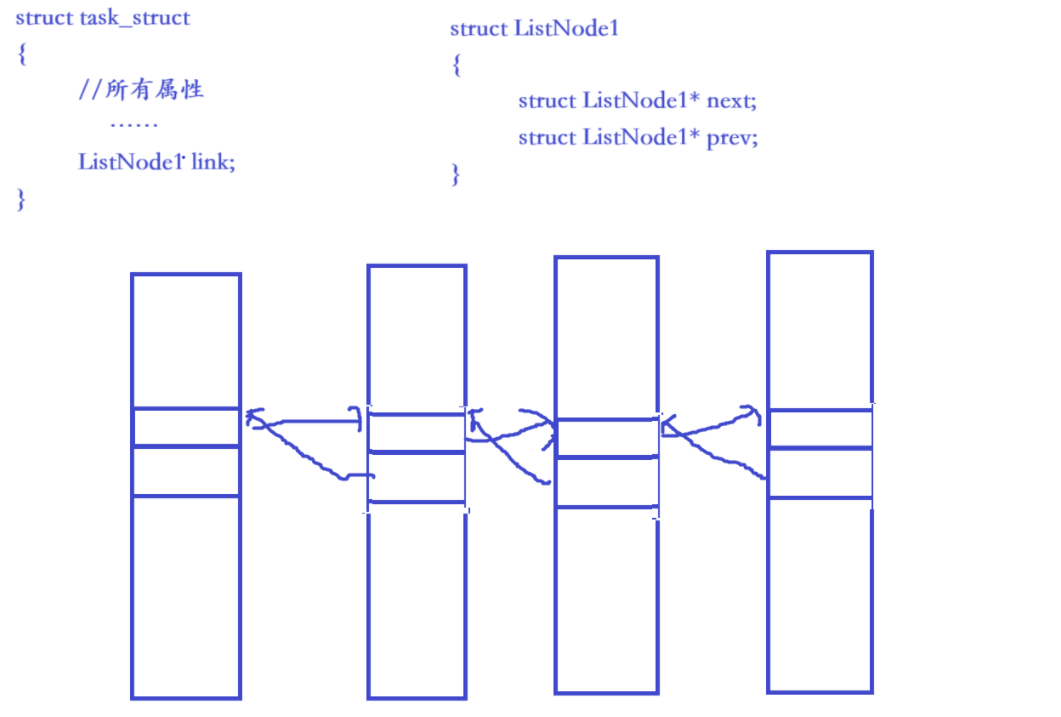
侵入式链表的核心是 "通用链表节点嵌入数据结构体,数据是主体,同一套链表逻辑可复用管理任意结构体,灵活且无冗余"。
② 通过节点指针 + 偏移量计算,反向获取结构体对象
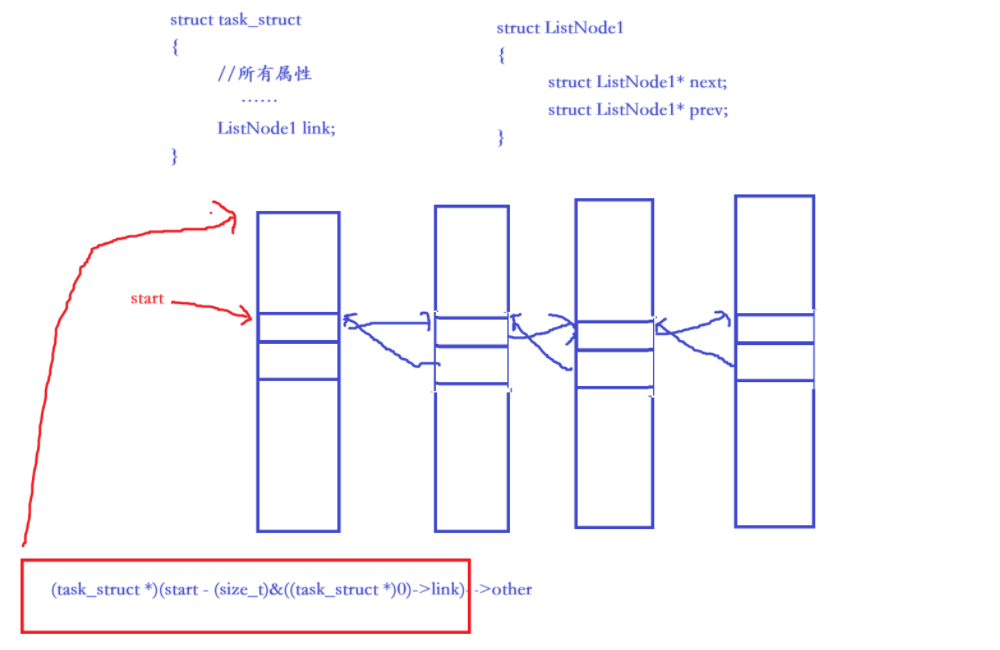
cpp
(task_struct *)(start - (size_t)&((task_struct *)0)->link)->other解析:
(task_struct *)0: 将地址 0 强转为task_struct*,虚拟结构体基址(size_t)&((task_struct *)0)->link: 计算link在结构体中的偏移量(强转size_t确保数值运算)- **
start - (size_t)&((task_struct *)0)->link:**节点地址减偏移量,得结构体起始地址- **
(task_struct *)(...):**将结果强转回task_struct*,最终访问other成员
③ 问题:在进程管理中,为什么通常用链式结构存储 PCB(进程控制块)?
进程管理中选择链式结构存储 PCB,是适配进程动态特性与内核管理需求:
- 适配进程动态生命周期:进程会频繁创建 / 销毁,链式结构增删节点仅需修改指针(时间复杂度 O (1)),无需像数组那样扩容、移动元素;
- 适配内核内存环境:PCB 可分散存储在非连续内存中(内核中大块连续内存稀缺),链式结构靠指针串联节点,无需连续地址空间;
- 支持灵活的进程管理:可轻松实现进程的排序、筛选(如按优先级遍历)、状态切换(如就绪队列 / 阻塞队列的重组),操作成本低;
- 复用通用链表逻辑:通过侵入式链表,一套增删查逻辑可管理 PCB、文件等多种内核对象,减少代码冗余。
2、进程优先级
① 进程优先级是什么?
进程优先级是CPU 调度进程的 "先后规则":系统会给不同进程分配优先级,优先级高的进程能更优先获得 CPU 等资源的访问权(即 "谁先访问、谁后访问")。
它和 "权限" 是不同概念:
- 优先级 → 决定资源访问的顺序(谁先用 CPU);
- 权限 → 决定资源访问的资格(能不能用某个文件 / 设备)。
简单说,进程优先级是 "资源调度的先后顺序规则",用来让系统更高效地分配 CPU 时间。
② 为什么要有进程优先级?
因为资源是有限的,但进程是多个的 ,进程之间天然存在资源竞争关系(竞争性)。
操作系统需要通过 "进程优先级" 实现良性竞争:
- 避免进程长期抢不到 CPU 资源(即 "饥饿问题"),否则进程代码无法推进,在用户层会表现为 "应用无响应";
- 让更重要的进程优先获得资源,提升系统整体的效率与响应性。
3、如何查看进程优先级?
在 linux 或者 unix 系统中,用 ps --l 命令则会类似输出以下几个内容:

我们很容易注意到其中的几个重要信息,有下:
- UID : 代表执行者的身份
- PID : 代表这个进程的标识符
- PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的标识符
- PRI :代表这个进程可被执行的优先级,其值越小越早被执行
- NI :代表这个进程的nice值,会影响进程的优先级(
PRI)
【UID是什么】
在操作系统中,UID(用户标识符)是系统唯一识别用户的标识:
- 昵称(用户名)是给人看的,可能存在重复;
- 但 UID 是系统分配的数字编号(比如 Linux 中 root 的 UID 固定为 0),每个用户的 UID 在系统内是唯一的,不会重复。
所以系统实际是通过 UID 来区分不同用户的,而不是依赖可能重复的用户名。
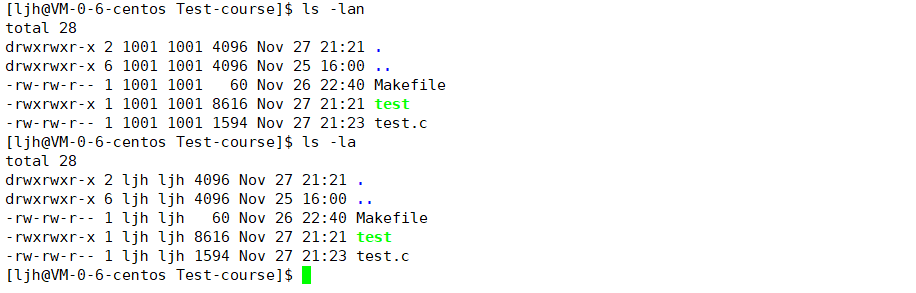
从图中我们可以看到,ls指令加上-n选项后,对应的文件拥有者和文件所属组的位置被1001这样的数字替代了,1001就代表了当前文件拥有者的UID也就是用户的唯一标识符
【UID和PID的区别】
| 维度 | UID(用户标识符) | PID(进程标识符) |
|---|---|---|
| 核心作用 | 唯一标识用户,明确进程 / 文件的所属者 | 唯一标识进程,定位具体运行的进程实例 |
| 对应对象 | 用户(如 Linux 中 root 的 UID 固定为 0) | 进程(每个运行的程序对应至少一个 PID) |
| 唯一性范围 | 系统内用户唯一,不会重复 | 系统内进程唯一,进程结束后 PID 可复用 |
| 典型使用场景 | 1. 控制文件 / 资源的访问权限2. 区分不同用户的进程 | 1. 操作进程(如kill PID终止进程)2. 查看进程状态(如ps -p PID) |
4、如何理解PRI and NI
- PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被 CPU 执行的先后顺序,此值越小进程的优先级别越高
- 那NI呢?就是我们所要说的 nice 值了,其表示进程可被执行的优先级的修正数值
- PRI 值越小越快被执行,那么加入 nice 值后,将会使得 PRI 变为:PRI(new)=PRI(old)+nice(每次调整 old 都是以默认的 80 开始调整)
- 这样,当 nice 值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行
- 所以,调整进程优先级,在 Linux 下,就是调整进程 nice 值
- nice 其取值范围是 -20 至 19,一共 40 个级别
 从图中可以看到进程默认优先级是80,也就代表了我们所能调整的最终优先级范围是60,99
从图中可以看到进程默认优先级是80,也就代表了我们所能调整的最终优先级范围是60,99
< 进程 nice 值与优先级调整说明 >
虽然进程优先级可以通过修改 nice 值调整,但不能无限制提升优先级(比如无法通过 "大幅修改 nice 值" 让进程一直被调度)------ 因为 Linux 对 nice 值的调整范围做了限制,仅允许在
[-20, 19]区间内调整(nice 值越小,进程优先级越高)。这是系统为避免单个进程过度抢占资源、保证整体稳定性而设置的约束,不会开放过度的优先级干预权限。
5、如何修改进程优先级?
< top调整进程优先级 >
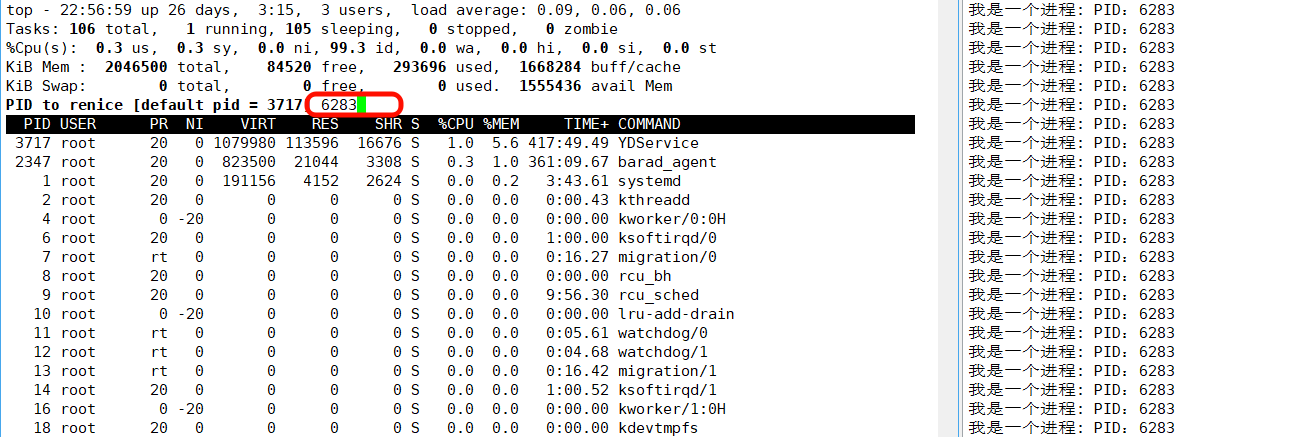
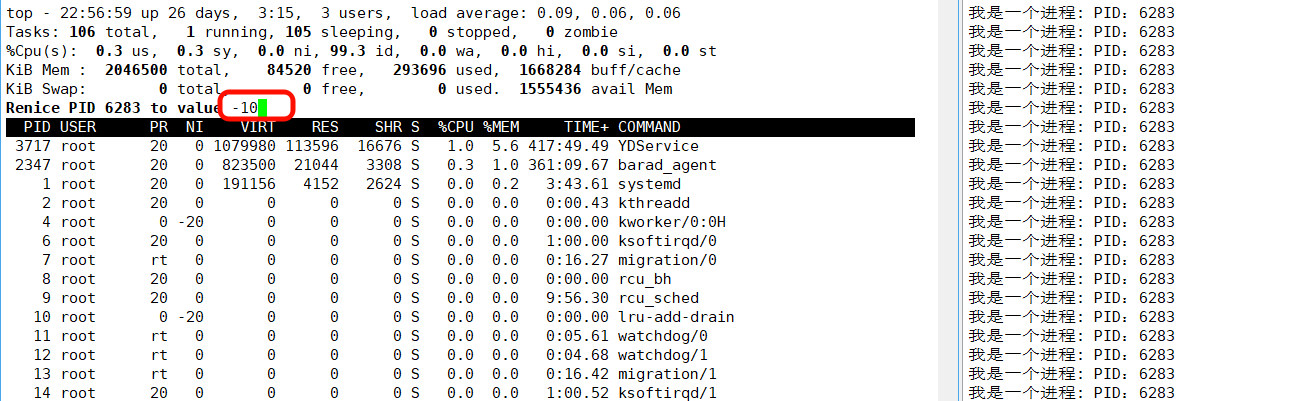
- 启动 top :在终端输入
top,进入进程监控界面;- 进入优先级调整模式 :按下键盘上的
r键(代表 "renice",调整 nice 值);- 输入目标进程的 PID:此时界面会提示 "PID to renice:",输入要调整的进程 PID 后按回车;
- 输入新的 nice 值 :接着提示 "Renice PID 目标 PID to value:",输入想要设置的 nice 值(范围
[-20,19]),按回车完成调整。
【注意事项】:
- 普通用户只能把 nice 值调大(降低进程优先级),只有 root 用户能调小(提高优先级);
- 调整后可以在 top 界面的
NI列,看到该进程的 nice 值已更新。
【修改演示】:

从图中可以看到PRI和NI确实被修改了,有些同学可能疑惑:为啥查进程 PRI 和 NI 时用了ps -la而不是-l选项?这是因为ps -l只显示当前终端下的进程 ------ 哪怕是同一用户,只要进程是在其他终端启动的,ps -l就不会显示;而ps -la的-a参数能显示所有终端的进程,所以能稳定查到目标进程的 PRI 和 NI(图中 test 进程的 PRI、NI 已成功修改)。
< 修改NI值的特殊情况 >
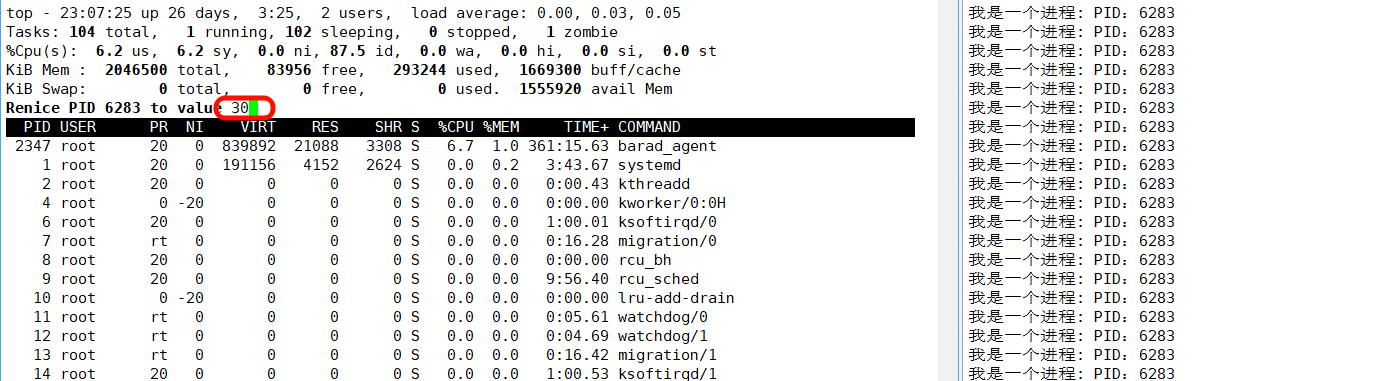
如果我修改的NI超过可修改范围,最终的NI值会是多少呢?

如果修改的 NI 值超出了合法范围(-20,19),系统会自动按边界值生效:比如图中尝试设 NI 为 30,最终会取最大值 19;若设为 - 21,则会取最小值 - 20。
6、进程的竞争性、独立性、并行、并发
竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
- ▶ 比如服务器同时跑着业务程序、日志脚本、备份进程,CPU 只能轮流处理它们,优先级就是 "规则"------ 让核心业务先抢到 CPU,避免卡顿。
**独立性:**多进程运行,需要独享各种资源,多进程运行期间互不干扰
- ▶ 每个进程都有自己的 "独立空间",像你开着的浏览器和音乐播放器,浏览器崩溃不会影响音乐播放,就是独立性在隔离资源。
并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行
- ▶ 如果服务器有 4 个 CPU 核心,进程 A、B、C、D 可以同时在 4 个核心上跑,是真正的 "同时执行",能直接提升整体效率。
**并发:**多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
- ▶ 只有 1 个 CPU 时,系统会快速切换进程(比如先跑进程 A 10ms,再切到进程 B 10ms),宏观上看这些进程像 "同时在跑",但微观是 CPU 在轮流处理。
