1 副作用与同步 (Effects and Synchronization)
问题体现: 状态更新后没有同步到所有依赖方
TypeScript
// 缺失的同步逻辑
useEffect(() => {
// 当elements变化时,同步到editor模块
syncToEditor(elements);
}, [elements]);官方文档重点:
业务逻辑理解:
-
在分布式状态架构中,需要 主动同步机制
-
你的业务场景是 "多客户端同步" 模式
-
需要建立 "状态同步契约"
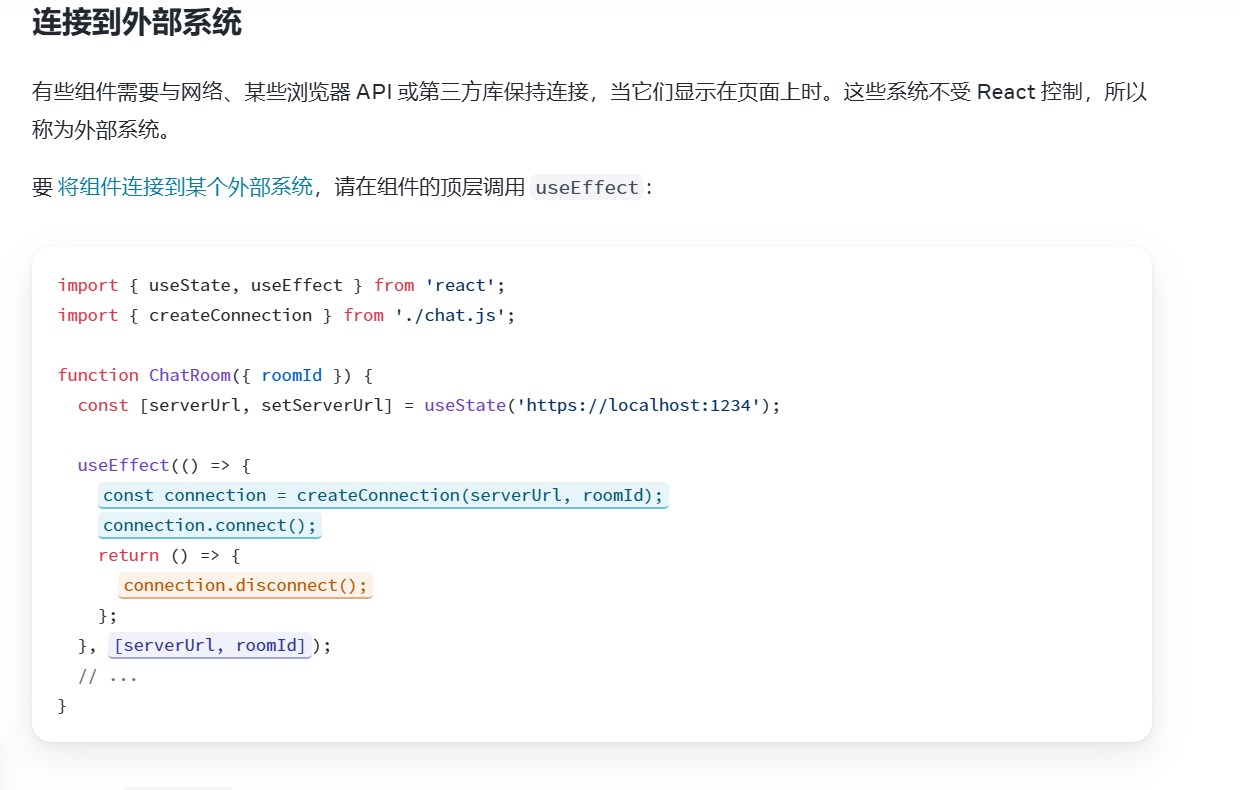


1. 什么是 "多客户端同步" 模式?
在分布式系统中,"多客户端同步" 指多个客户端(比如不同用户的浏览器、不同设备)需要共享同一个 "全局状态"(比如聊天房间的消息、协作文档的内容),且任何一个客户端对状态的修改,都要同步到其他所有客户端。
你提供的ChatRoom组件就是典型场景:多个用户的ChatRoom组件连接到同一个聊天服务端,需要同步聊天消息、在线状态等。
2. 为什么需要 "主动同步机制"?
传统的 "被动同步"(比如客户端定期轮询服务端)效率低、延迟高。而主动同步机制是指:
- 当某一客户端修改了状态,会主动通知服务端 / 其他客户端(而非等待被查询);
- 服务端也会主动推送更新给所有相关客户端,保证状态一致。
对应到你的代码:createConnection建立的连接(比如 WebSocket)就是 "主动同步" 的载体 ------ 客户端通过connect()接入后,服务端可以主动推送新消息,客户端也能主动发送消息到服务端。
3. 什么是 "状态同步契约"?
"状态同步契约" 是客户端与服务端(或客户端之间)约定的 "状态同步规则",用来保证多端状态一致,核心包含 3 部分:
(1)状态结构契约
明确 "要同步的状态是什么样的":
- 比如聊天场景的状态结构:
{ roomId: string, messages: Array<{content: string, sender: string}>, onlineUsers: string[] }; - 所有客户端和服务端必须遵守这个结构,避免解析错误。
(2)同步触发契约
明确 "什么时候触发同步":
- 比如 "客户端发送新消息时,必须主动将消息提交到服务端";
- "服务端收到新消息后,必须主动推送给房间内所有客户端";
- 对应代码中:客户端通过
connection发送消息(触发同步),服务端通过connection推送消息(触发客户端更新)。
(3)冲突解决契约
明确 "当多端同时修改状态时,如何保证最终一致":
- 比如 "以服务端时间戳为准""后提交的修改覆盖先提交的""基于版本号合并";
- 例:两个客户端同时修改同一条消息,服务端以 "谁的请求先到达" 为标准,将最终结果同步给所有客户端。
结合你的代码场景总结
- 你的
ChatRoom组件通过useEffect连接外部系统(聊天服务端),本质是接入 "主动同步机制"(通过长连接主动收发状态); - 而 "状态同步契约" 是这个聊天系统的隐形规则:比如 "消息的格式是什么""什么时候发消息""冲突了听谁的",这些规则保证了多客户端的状态能一致。
2 不可变更新 (Immutability)
问题体现: 正确的更新模式
TypeScript
// 你的正确做法
setElements(prev => prev.map(el =>
el.id === id ? { ...el, ...updates } : el
));官方文档重点:
业务逻辑理解:
-
可视化编辑器的核心就是 "不可变数据流"
-
每次操作都产生新状态,便于 撤销/重做 功能
-
这是图形编辑器的基础架构模式
可视化编辑器的核心是「对 "可编辑内容" 的状态管理与操作抽象」,而不可变数据流是优化这种状态管理的最优解之一(而非唯一解,但几乎是复杂场景的必选解)。
一、先明确:可视化编辑器的核心诉求是什么?
可视化编辑器(比如 Figma、Axure、VS Code 可视化插件、低代码平台编辑器、PPT 在线编辑器)的核心是让用户通过「拖拽、点击、修改属性面板」等可视化操作,生成 / 编辑结构化内容(如组件树、图层、表单配置、页面布局)。其状态管理必须满足以下核心诉求:
- 状态可追溯:支持「撤销 / 重做(Undo/Redo)」------ 用户操作失误后能回滚,这是可视化编辑器的基础体验;
- 操作可预测:用户的每一步操作(如移动组件、修改颜色)都能精准映射到状态变更,不出现 "操作与结果不一致""状态紊乱";
- 性能可控:当编辑内容复杂时(如几百个图层、嵌套组件),避免因状态变更导致的卡顿(如重复渲染、DOM 频繁操作);
- 协作友好:支持多人实时编辑(如 Figma 协同时),需精准合并多用户的操作,避免冲突;
- 状态可调试:开发 / 运维阶段能快速定位 "状态异常"(如组件错位、属性丢失),需清晰的状态变更链路。
这些诉求是可视化编辑器区别于普通表单、列表页的核心 ------ 普通页面的状态变更简单(如输入框值变化),而可视化编辑器的状态是「结构化、嵌套深、变更频繁」的(如一个页面包含 100 个组件,每个组件有 20 个属性,用户可能同时修改多个组件的多个属性)。
二、不可变数据流:如何解决这些核心诉求?
1. 先明确:什么是 "不可变数据流"?
不可变(Immutable)的核心是:状态一旦创建,就不能被直接修改;任何状态变更都会生成一个全新的状态副本,原状态保留不变。
举个例子(可视化编辑器中 "修改组件颜色" 的状态变更):
-
可变数据流(直接修改原状态):
javascript// 原状态:组件列表(直接修改 color 属性) const components = [{ id: 1, name: "按钮", color: "red" }]; components[0].color = "blue"; // 原状态被篡改,无法回滚 -
不可变数据流(生成新状态副本):
javascript// 原状态: immutable 对象(如用 Immer、Immutable.js 实现) const components = [{ id: 1, name: "按钮", color: "red" }]; // 变更后:生成新副本,原状态保留 const newComponents = components.map(comp => comp.id === 1 ? { ...comp, color: "blue" } : comp );
2. 不可变数据流对可视化编辑器的核心价值
(1)天生支持 Undo/Redo,状态追溯零成本
可视化编辑器的「撤销 / 重做」本质是「状态栈的切换」:
- 每一步用户操作(如 "修改颜色""移动组件"),都将「当前新状态」推入一个 "历史状态栈";
- 撤销(Undo):从栈中弹出最新状态,恢复到上一个状态;
- 重做(Redo):将弹出的状态重新推入栈,恢复到最新状态。
如果用可变数据流:原状态被直接修改后,历史状态会丢失,要实现 Undo/Redo 必须手动深拷贝每个历史状态(成本高、性能差,深拷贝大对象会卡顿);
如果用不可变数据流:原状态永远不变,历史状态栈只需存储「每个状态的引用」(无需拷贝完整数据),切换状态时直接复用原状态引用,性能和实现成本都极低。
例:Figma 的 Undo/Redo 能支持上千步操作,核心就是依赖不可变的状态设计 ------ 每一步操作只记录 "状态差异",而非完整状态。
(2)状态变更可预测,避免 "隐式修改" 导致的 Bug
可视化编辑器的状态通常是「嵌套结构化数据」(如 page → section → component → props),可变数据流中容易出现 "隐式修改":
javascript
// 可变数据流:函数内部隐式修改外部状态,导致状态紊乱
function updateComponentColor(components, id, color) {
const comp = components.find(c => c.id === id);
comp.color = color; // 直接修改外部传入的 components,其他依赖该状态的地方会意外变更
}而不可变数据流中,任何状态变更都必须通过 "生成新副本" 实现,外部状态永远不会被隐式修改 ------ 所有状态变更都有明确的 "输入→输出" 链路,调试时能快速定位哪个操作导致了状态异常(比如 "组件错位" 是因为某个操作生成了错误的组件位置副本)。
(3)优化渲染性能:精准定位变更,避免重复渲染
可视化编辑器的 UI 渲染依赖状态(如组件位置、颜色、大小),如果用可变数据流,框架(如 React、Vue)无法判断 "状态是否真的变更"(因为对象引用没变,只是内部属性变了),可能导致整个组件树重新渲染(比如修改一个按钮的颜色,所有组件都重新渲染,卡顿严重)。
不可变数据流中,状态变更会生成新的引用------ 框架只需对比 "状态引用是否变化",就能精准判断是否需要渲染:
- 未变更的部分:引用不变,框架直接复用之前的 DOM / 组件,不重新渲染;
- 变更的部分:引用变化,只重新渲染该部分(如修改按钮颜色,只重新渲染这个按钮,其他组件无感知)。
这对复杂可视化编辑器(如包含几百个组件的低代码平台)至关重要 ------ 直接决定了编辑操作的 "丝滑度"。
(4)友好支持实时协作:基于 "状态差异" 合并操作
多人实时协作(如 Figma 多人同时编辑一个页面)的核心是「合并多用户的操作」:
- 每个用户的操作都会生成 "状态变更增量"(如用户 A 修改组件颜色,用户 B 移动组件位置);
- 服务器需要将这些增量合并为一个 "最终状态",再同步给所有用户。
不可变数据流的「状态不可修改 + 新副本生成」特性,让 "增量合并" 变得简单:
- 每个操作都可以表示为「基于某个基准状态的变更」(如 "基于版本 10 的状态,将组件 1 的颜色改为蓝色");
- 服务器只需判断不同用户的操作是否修改了 "同一部分状态"(如是否都修改组件 1 的颜色),如果不冲突直接合并,冲突则提示用户处理。
如果用可变数据流,合并操作需要手动对比 "原状态→新状态" 的差异(深对比成本高),且容易出现 "覆盖他人操作" 的冲突(如用户 A 和 B 同时修改组件颜色,后提交的会覆盖先提交的)。
(5)状态可调试:完整的变更链路
可视化编辑器的状态异常(如组件突然消失、属性错乱)很难复现,而不可变数据流能记录「每一步状态变更的前后快照」------ 调试时可以像 "播放电影" 一样,一步步回看:
- 操作 1:用户添加组件 → 状态快照 1;
- 操作 2:用户修改组件位置 → 状态快照 2;
- 操作 3:用户删除组件 → 状态快照 3;
如果出现异常,只需对比相邻快照的差异,就能快速定位是哪个操作、哪个代码逻辑导致了问题(比如组件消失是因为删除操作的逻辑错误,误删了不该删的组件)。
三、误区澄清:不可变数据流是 "核心" 吗?有没有替代方案?
1. 不是所有可视化编辑器都必须用不可变数据流 ------ 简单场景可以不用
如果是「极简单的可视化编辑器」(如只有几个固定组件、无需 Undo/Redo、无协作需求),可以用可变数据流,实现成本更低:
- 例:一个简单的 "图片裁剪编辑器"(只有裁剪框拖动、缩放操作),无需 Undo/Redo,直接修改裁剪框的
x/y/width/height属性,也能满足需求。
但这类编辑器本质上是 "单一功能工具",而非通用可视化编辑器 ------ 一旦需要扩展(如添加 Undo/Redo、多图片编辑),可变数据流会迅速暴露出 "状态混乱、难以维护" 的问题,最终还是要重构为不可变数据流。
2. 不可变数据流是 "核心技术手段",而非 "核心目标"
可视化编辑器的「核心目标」是「让用户通过可视化操作高效生成 / 编辑内容」,而不可变数据流是「实现这个目标的最优技术手段」------ 它解决了 "状态管理" 这个最关键的技术痛点,让编辑器的「稳定性、性能、协作性」达到生产级标准。
如果脱离不可变数据流,要实现同样的体验,需要付出数倍的开发成本(如手动实现历史状态深拷贝、手动对比状态差异、手动处理协作冲突),且最终的产品体验很难达标(如 Undo/Redo 卡顿、协作时频繁冲突)。
四、实际工程中的落地:如何实现不可变数据流?
可视化编辑器中,很少手动编写不可变逻辑(如手动 ...spread 拷贝对象),通常使用成熟工具库,兼顾开发效率和性能:
-
Immer :最常用(轻量、易用),通过
produce函数简化不可变状态修改,内部自动生成新副本:javascriptimport { produce } from "immer"; // 原状态(普通数组/对象) const components = [{ id: 1, color: "red" }]; // 生成新状态(原状态不变) const newComponents = produce(components, draft => { const comp = draft.find(c => c.id === 1); comp.color = "blue"; // 看似直接修改,实则操作的是 Immer 生成的草稿,最终返回新副本 }); -
Immutable.js:功能更强(支持复杂数据结构如 Map/List、高效深对比),但有一定学习成本,适合超大型编辑器(如 Figma 早期版本);
-
框架内置能力 :React 18+ 的
useState配合useImmer钩子、Vue 3 的ref/reactive配合immer插件,可无缝集成到框架中。
五、总结
可视化编辑器的核心不是 "不可变数据流" 本身 ,而是「满足用户可视化操作的状态管理能力」------ 但不可变数据流是「实现这种能力的最优解」:
- 对于简单可视化工具,不可变数据流是 "可选优化";
- 对于复杂可视化编辑器(支持 Undo/Redo、多组件、实时协作、高性能),不可变数据流是「必选的技术基石」,没有它几乎无法实现生产级的产品体验。
因此,行业内成熟的可视化编辑器(Figma、Axure、低代码平台如钉钉宜搭、飞书多维表格),无一例外都采用了「不可变数据流」的设计思想 ------ 它不是 "核心目标",但却是 "核心技术支柱"。
3 调试与错误边界
问题体现: 你使用的防御性编程和详细日志
TypeScript
console.log('=== handleUpdateElement with Full Protection ===');
console.log('Target element ID:', id);
console.log('Available elements:', elements.map(el => el.id));官方文档重点:
业务逻辑理解:
-
复杂交互应用需要 "可观测性"
-
状态变更的 "审计追踪" 对调试至关重要
-
这是生产级应用的必要实践
要深入理解这段带完整保护的 handleUpdateElement 调试日志,我们需要从「防御性编程思想」「日志设计目的」「业务逻辑适配」「官方文档核心原则」四个维度展开,结合实际场景说明其价值和背后的思考:
一、先明确核心背景:这段代码的应用场景
假设 handleUpdateElement(id, elements, updateData) 是一个更新页面 / 组件中指定元素状态 的核心函数(比如:更新表格行数据、修改表单字段、刷新组件属性等),其核心逻辑是「根据 id 从 elements 数组中找到目标元素,然后应用 updateData 进行更新」。
而你贴的三行 console.log,是这个函数的「调试与防御性前置逻辑」------ 不是多余的打印,而是防御性编程的具体落地。
二、逐句拆解:日志背后的防御性编程思想
防御性编程的核心是:假设函数可能被错误调用、输入数据可能异常,提前预判风险并留下调试线索,避免程序 "静默失败"(没报错但结果不对,难以排查)。
这三行日志精准命中了这个目标:
1. 标识日志所属场景:console.log('=== handleUpdateElement with Full Protection ===');
- 作用:给日志打「场景标签」,区分其他函数的日志。
- 防御性价值 :当控制台日志刷屏时(比如复杂页面有上百个
console.log),能快速筛选出「handleUpdateElement函数相关的日志」,避免调试时混淆上下文。关键词with Full Protection还能暗示:这个函数内部有完整的参数校验、异常捕获逻辑,日志是配套的调试手段。
2. 打印目标标识:console.log('Target element ID:', id);
- 作用:暴露「要更新的目标元素唯一标识」。
- 防御性价值 :
- 预判风险 1:
id可能是undefined/null/ 空字符串(比如调用方忘记传参、传参错误)。例:如果日志显示Target element ID: undefined,直接定位到「调用方未传id」,无需在函数内部逐行排查。 - 预判风险 2:
id格式错误(比如应该是数字123,但传入了字符串'123a')。例:日志显示Target element ID: '123a',可快速判断「id格式非法,导致后续找不到元素」。
- 预判风险 1:
3. 打印可选范围:console.log('Available elements:', elements.map(el => el.id));
- 作用 :暴露「当前可用的所有元素的
id列表」。 - 防御性价值 :
- 预判风险 1:
elements数组为空(比如接口返回数据为空、初始化未完成)。例:日志显示Available elements: [],直接定位到「无可用元素,更新操作无法执行」。 - 预判风险 2:目标
id不在可用列表中(比如id=456,但可用列表是[123, 789])。例:日志显示Target element ID: 456+Available elements: [123, 789],瞬间明白「找不到目标元素,因为id不存在」。 - 预判风险 3:
elements数组中元素格式异常(比如部分元素没有id属性)。例:日志显示Available elements: [123, undefined, 789],可定位到「elements数组数据不规范,有元素缺失id」。
- 预判风险 1:
三、业务逻辑理解:日志如何适配核心业务
handleUpdateElement 的核心业务逻辑必然是:
javascript
function handleUpdateElement(id, elements, updateData) {
// 1. 日志调试(你贴的代码)
console.log('=== handleUpdateElement with Full Protection ===');
console.log('Target element ID:', id);
console.log('Available elements:', elements.map(el => el.id));
// 2. 防御性校验(日志的配套逻辑,体现 Full Protection)
if (!id) {
console.error('Update failed: Target element ID is missing');
return; // 终止执行,避免后续报错
}
if (!Array.isArray(elements) || elements.length === 0) {
console.error('Update failed: No available elements');
return;
}
// 3. 核心业务:查找目标元素并更新
const targetElement = elements.find(el => el.id === id);
if (!targetElement) {
console.error(`Update failed: Element with ID ${id} not found`);
return;
}
// 执行更新(比如合并数据、修改状态等)
const updatedElement = { ...targetElement, ...updateData };
console.log(`Element ${id} updated successfully:`, updatedElement);
return updatedElement;
}日志与业务的强关联:
- 日志是「业务校验的前置观察口」:在执行校验和核心逻辑前,先把关键数据暴露出来,即使校验没覆盖到所有异常(比如
elements中有id重复),也能通过日志发现问题。 - 日志是「业务故障的溯源依据」:如果更新失败(比如用户反馈 "修改后没生效"),无需重现问题,直接查看控制台日志,就能知道是「
id传错了」「元素不存在」还是「数据格式异常」。
四、官方文档重点(通用前端 / JS 文档核心原则)
这段代码完全契合前端开发中「调试与错误处理」的官方文档核心思想(以 MDN、React 文档为例):
1. MDN 关于「调试」的核心建议:
- 「使用
console.log打印关键数据,帮助定位代码执行流程和数据状态」------ 对应三行日志精准打印「函数标识、目标参数、可选范围」,不冗余不缺失。 - 「提前预判可能的错误输入,避免程序崩溃」------ 日志配套的
id/elements校验,正是这一原则的落地。
2. React 关于「错误边界」的延伸(如果是 React 项目):
- 错误边界的核心是「捕获子组件错误,避免整个应用崩溃」;而这段代码的「Full Protection」是「捕获函数输入错误,避免函数内部逻辑崩溃」,本质都是「分层防御」。
- 文档强调「错误发生时提供清晰的错误信息」------ 这段日志 + 后续的
console.error,正是为了提供「可定位的错误上下文」。
3. 通用「防御性编程」文档原则:
- 「输入校验优先于业务逻辑」:日志是输入校验的 "可视化补充",让校验过程可观察。
- 「失败时提供明确反馈」:日志不仅打印 "做了什么",还能辅助后续打印 "为什么失败",符合「故障可追溯」原则。
五、总结:这段代码的核心价值
它不是简单的「打印日志」,而是「防御性编程 + 可观测性调试」的组合拳:
- 提前暴露风险 :在业务逻辑执行前,把关键数据(目标
id、可用id列表)可视化,避免 "暗箱操作"。 - 降低调试成本 :出现问题时,无需逐行断点调试,通过日志快速定位根因(比如
id错误、数据为空)。 - 保障代码健壮性:配合后续的参数校验,形成「日志观察 + 校验拦截」的双重保护,避免因异常输入导致函数崩溃或产生脏数据。
如果是生产环境,通常会把 console.log 替换为专业日志工具(如 Sentry、LogRocket),但核心思想完全一致:让关键数据可观测,让异常情况可追溯。
4 ESLint
ESLint 是 JavaScript/TypeScript 生态中最核心的代码检查工具,核心作用是「强制代码风格一致性」「提前发现语法错误 / 潜在 Bug」「规范团队协作标准」。
它并非单纯的 "代码格式化工具",而是兼顾「质量检查」和「风格约束」的工程化基石。
一、ESLint 核心定义与官方文档
1. 核心定位
ESLint 是一个 可配置的静态代码分析工具:
- 「静态分析」:不运行代码,仅通过解析代码语法结构,就能发现问题;
- 「可配置」:支持自定义规则、集成第三方规则集(如 Airbnb、Standard),适配不同项目 / 团队需求;
- 「双核心目标」:① 避免语法错误(如
var声明泄漏、未定义变量使用);② 统一代码风格(如缩进、引号、分号)。
2. 官方文档(权威来源)
- 英文官方文档(最新稳定版):ESLint Official Docs
- 中文官方文档(社区翻译,同步及时):ESLint 中文文档
官方文档核心模块:
- 「Getting Started」:快速上手配置;
- 「Rules」:所有内置规则的详细说明(如
no-undef禁止未定义变量、indent控制缩进); - 「Configuration」:配置文件格式(
.eslintrc、eslint.config.js)、规则等级、环境 / 全局变量设置; - 「Integrations」:与编辑器(VS Code)、构建工具(Webpack、Vite)、CI/CD 的集成方案。
二、ESLint 核心特性(为什么工程开发离不开它?)
- 规则覆盖全面 :内置 200+ 规则,涵盖语法错误、代码质量、风格规范、最佳实践(如禁止
eval、强制使用const/let替代var); - 高度可定制:支持启用 / 禁用规则、调整规则严格程度(警告 / 错误)、自定义规则、继承第三方规则集;
- 多场景适配:支持 JavaScript(ES5/ES6+/ESNext)、TypeScript、React/Vue 等框架、Node.js 后端代码;
- 自动化集成:可集成到编辑器(实时校验)、构建流程(打包时校验)、CI/CD(提交 / 合并时强制校验);
- 修复成本低 :支持
--fix自动修复 60%+ 的规则问题(如缩进、引号、分号、空格),无需手动修改。
三、工程开发中的 ESLint 落地:从配置到集成
第一步:项目初始化与核心配置
1. 安装依赖(以 npm 为例)
bash
# 局部安装(推荐,避免全局版本冲突)
npm install eslint --save-dev
# 全局安装(仅用于快速初始化,不推荐工程化项目)
npm install eslint -g2. 初始化配置文件
运行初始化命令,根据终端提示选择项目类型(JS/TS/React/Vue)、模块系统(ESM/CommonJS)、代码风格(默认 / Airbnb/Standard),自动生成配置文件:
bash
npx eslint --init执行后会生成以下之一的配置文件(优先级:.eslintrc.js > .eslintrc.json > .eslintrc.yml):
- 推荐使用
.eslintrc.js(支持注释、动态逻辑),示例如下(React + TypeScript 项目):
javascript
module.exports = {
// 1. 环境:指定代码运行的环境(全局变量自动识别,避免 no-undef 误报)
env: {
browser: true, // 浏览器环境(window、document)
es2021: true, // ES2021 语法支持
node: true // Node.js 环境(require、module)
},
// 2. 继承:复用已有规则集(优先级:后继承的覆盖先继承的)
extends: [
"eslint:recommended", // ESLint 内置推荐规则(核心质量规则,如禁止未定义变量)
"plugin:react/recommended", // React 官方规则集(如禁止未使用的 props)
"plugin:react-hooks/recommended", // React Hooks 规则(如依赖数组完整)
"plugin:@typescript-eslint/recommended", // TS 官方规则集(如类型定义规范)
"prettier" // 关闭 ESLint 中与 Prettier 冲突的规则(后续讲 ESLint + Prettier 配合)
],
// 3. 解析器:指定 ESLint 如何解析代码(TS 项目必须用 @typescript-eslint/parser)
parser: "@typescript-eslint/parser",
// 4. 解析器选项:配置解析器的行为
parserOptions: {
ecmaFeatures: {
jsx: true // 支持 JSX 语法(React 项目必需)
},
ecmaVersion: "latest", // 支持最新 ES 语法
sourceType: "module" // 模块系统(ESM/CommonJS)
},
// 5. 插件:扩展 ESLint 对特定框架/语法的支持(如 React/TS 插件)
plugins: [
"react",
"@typescript-eslint"
],
// 6. 规则:自定义规则(覆盖继承的规则,优先级最高)
// 规则等级:"off"(0) 关闭 → "warn"(1) 警告(不阻断构建)→ "error"(2) 错误(阻断构建)
rules: {
// 关闭 "react/react-in-jsx-scope"(React 17+ 无需手动导入 React)
"react/react-in-jsx-scope": "off",
// 强制使用 const/let,禁止 var
"no-var": "error",
// TS 规则:允许非空断言(!)
"@typescript-eslint/no-non-null-assertion": "off",
// 警告:函数参数未使用
"no-unused-vars": "warn",
// 自动修复:使用单引号
"quotes": ["error", "single", { "allowTemplateLiterals": true }],
// 自动修复:语句末尾加分号
"semi": ["error", "always"]
},
// 7. 全局变量:声明项目中使用的全局变量(避免 no-undef 误报)
globals: {
"React": "writable", // React 是可写全局变量
"axios": "readonly" // axios 是只读全局变量
}
};3. 忽略文件:.eslintignore
指定 ESLint 不需要检查的文件 / 目录(类似 .gitignore),避免校验 node_modules、打包产物等无关文件:
javascript
# .eslintignore
node_modules/
dist/
build/
*.config.js # 忽略配置文件(如 webpack.config.js)
*.d.ts # 忽略 TS 类型声明文件第二步:工程化核心流程集成
ESLint 真正发挥价值的关键是「融入工程流程」,避免 "手动运行校验" 的低效模式,以下是企业级项目的标准集成方案:
1. 脚本配置(package.json)
在 package.json 中添加 lint 和 lint:fix 脚本,方便手动执行校验 / 修复:
bash
{
"scripts": {
"lint": "eslint . --ext .js,.jsx,.ts,.tsx", // 校验所有 JS/JSX/TS/TSX 文件
"lint:fix": "eslint . --ext .js,.jsx,.ts,.tsx --fix" // 自动修复可修复的问题
}
}- 执行命令:
- 校验:
npm run lint→ 输出所有问题(警告 / 错误); - 自动修复:
npm run lint:fix→ 自动修复缩进、引号、分号等规则问题。
- 校验:
2. 编辑器实时校验(开发阶段)
让 ESLint 在编写代码时「实时提示错误」并「保存自动修复」,提升开发效率:
-
以 VS Code 为例:
-
安装 ESLint 插件:ESLint - Visual Studio Marketplace;
-
打开 VS Code 设置(
settings.json),添加配置:{
// 保存时自动修复 ESLint 问题
"editor.codeActionsOnSave": {
"source.fixAll.eslint": true
},
// 启用 ESLint 实时校验
"eslint.validate": [
"javascript",
"javascriptreact",
"typescript",
"typescriptreact"
],
// 禁止 VS Code 内置格式化与 ESLint 冲突
"editor.formatOnSave": false
}
-
-
效果:编写代码时,不符合规则的地方会标红 / 黄线,按
Ctrl+S自动修复(如把双引号改成单引号、补充分号)。
3. 构建工具集成(打包阶段)
在 Webpack/Vite/Rollup 中集成 ESLint,确保「打包时必须通过校验,否则打包失败」,避免不合格代码流入测试 / 生产环境:
-
以 Vite 为例(最常用):
-
安装 Vite ESLint 插件:
npm install vite-plugin-eslint --save-dev
-
配置
vite.config.ts:import { defineConfig } from 'vite';
import eslint from 'vite-plugin-eslint';export default defineConfig({
plugins: [
// 集成 ESLint 插件
eslint({
// 启用缓存(提升构建速度)
cache: true,
// 打包时发现错误则终止打包
failOnError: true,
// 显示警告信息
emitWarnings: true
})
]
});
-
-
效果:运行
npm run build时,如果代码不符合 ESLint 规则(等级为error),打包会直接失败,并在终端输出错误位置和原因,必须修复后才能打包。
4. Git Hooks 集成(提交阶段)
通过 Husky + lint-staged 实现「代码提交前强制校验」,避免不合格代码被提交到 Git 仓库(即使开发者跳过了编辑器 / 构建校验):
-
步骤:
-
安装依赖:
安装 Husky(Git Hooks 工具)
npm install husky --save-dev
安装 lint-staged(只校验暂存区文件,提升效率)
npm install lint-staged --save-dev
-
初始化 Husky:
npx husky install
设置 Git 提交前触发 hook
npx husky add .husky/pre-commit "npx lint-staged"
-
配置
package.json:{
"lint-staged": {
// 只校验暂存区的 JS/JSX/TS/TSX 文件
"*.{js,jsx,ts,tsx}": [
"eslint --fix", // 先自动修复
"eslint" // 再校验,无法修复的则阻止提交
]
}
}
-
-
效果:执行
git commit -m "feat: 新增功能"时,会自动校验暂存区的代码:- 如果有可修复的问题(如引号、缩进),自动修复后提交;
- 如果有无法修复的错误(如未定义变量、函数参数未使用且等级为
error),提交会失败,终端提示错误,必须修复后才能提交。
5. CI/CD 集成(合并阶段)
在 Jenkins/GitHub Actions/GitLab CI 中集成 ESLint,确保「代码合并到主分支前必须通过校验」,是团队协作的最后一道防线:
-
以 GitHub Actions 为例(最常用):
-
在项目根目录创建
.github/workflows/lint.yml文件:name: ESLint Check
触发条件:推送代码到主分支,或创建 PR 到主分支
on:
push:
branches: [main]
pull_request:
branches: [main]jobs:
lint:
runs-on: ubuntu-latest # 运行环境
steps:
# 1. 拉取 Git 代码
- name: Checkout code
uses: actions/checkout@v4# 2. 安装 Node.js - name: Set up Node.js uses: actions/setup-node@v4 with: node-version: 20 # 与项目 Node 版本一致 cache: 'npm' # 缓存依赖,提升速度 # 3. 安装依赖 - name: Install dependencies run: npm install # 4. 执行 ESLint 校验 - name: Run ESLint run: npm run lint
-
-
效果:
- 开发者推送代码到主分支,或创建 PR 到主分支时,GitHub 会自动运行 ESLint 校验;
- 如果校验失败,PR 会显示「校验未通过」,无法合并到主分支,必须修复后重新推送。
第三步:ESLint 与 Prettier 配合(解决风格冲突)
问题背景:
- ESLint 侧重「代码质量检查」(如禁止未定义变量、函数参数未使用)和「部分风格约束」(如引号、分号);
- Prettier 侧重「代码格式化」(如缩进、换行、空格),格式化规则更全面(如对象换行、数组缩进)。
- 两者可能冲突(如 ESLint 要求不加分号,Prettier 要求加分号)。
解决方案:关闭 ESLint 中与 Prettier 冲突的规则,让 Prettier 负责格式化,ESLint 负责质量
-
步骤:
-
安装依赖:
安装 Prettier
npm install prettier --save-dev
安装 eslint-config-prettier(关闭 ESLint 与 Prettier 冲突的规则)
npm install eslint-config-prettier --save-dev
安装 eslint-plugin-prettier(让 Prettier 规则以 ESLint 规则的形式运行,支持自动修复)
npm install eslint-plugin-prettier --save-dev
-
修改
.eslintrc.js:module.exports = {
extends: [
// ... 其他规则集(如 eslint:recommended、react/recommended)
"plugin:prettier/recommended" // 最后继承,覆盖前面的冲突规则
],
rules: {
// 可选:自定义 Prettier 规则(也可单独创建 .prettierrc.js)
"prettier/prettier": ["error", {
singleQuote: true, // 单引号
semi: true, // 分号
tabWidth: 2, // 缩进 2 空格
trailingComma: "es5" // 对象/数组末尾加逗号
}]
}
};
-
-
效果:Prettier 的格式化规则会被当作 ESLint 规则执行,支持「编辑器保存修复」「
lint:fix修复」「Git Hooks 修复」,既保证代码风格统一,又不冲突。
四、工程开发中的关键实践(避坑指南)
1. 规则等级合理设置
error(必须修复):语法错误、潜在 Bug、严重风格问题(如no-var、no-undef、react-hooks/exhaustive-deps);warn(建议修复,不阻断流程):非严重风格问题(如no-unused-vars、prefer-const);off(关闭):团队达成共识无需约束的规则(如@typescript-eslint/no-non-null-assertion)。
2. 团队规则统一
- 初始阶段优先继承成熟规则集(如 Airbnb、Standard),避免从零设计规则(成本高、争议大);
- 团队共同维护
.eslintrc.js,修改规则需团队讨论通过,避免个人随意修改; - 规则变更后,执行
npm run lint:fix批量修复历史代码,确保全项目一致性。
3. 性能优化
- 启用缓存:
eslint --cache(仅校验修改过的文件)、构建工具中开启cache: true; - 使用 lint-staged:只校验暂存区文件,而非全项目(提交时速度提升 10x+);
- 忽略无关文件:通过
.eslintignore排除node_modules、打包产物、配置文件等。
4. 框架 / 语言适配
- React 项目:必装
eslint-plugin-react+eslint-plugin-react-hooks; - TypeScript 项目:必装
@typescript-eslint/parser+@typescript-eslint/eslint-plugin; - Vue 项目:必装
eslint-plugin-vue(Vue 官方规则集)。
5. 生产环境处理
- 开发 / 测试环境:启用所有规则(
warn+error); - 生产环境:可关闭部分
warn规则(减少构建日志冗余),但error规则必须保留; - 禁止生产环境输出
console.log:添加规则"no-console": ["error", { "allow": ["warn", "error"] }](仅允许console.warn/console.error)。
五、常见问题与解决方案
1. ESLint 报错「未定义变量」但变量实际存在?
-
原因:变量是全局变量(如
window.$、第三方库),ESLint 未识别; -
解决方案:在
.eslintrc.js的globals中声明:bashglobals: { "$": "readonly" // 声明 $ 是只读全局变量 }
2. TypeScript 项目中 ESLint 不识别 TS 类型?
- 原因:未使用
@typescript-eslint/parser解析器; - 解决方案:确保
parser和plugins配置正确(参考第一步的配置示例)。
3. Prettier 格式化与 ESLint 冲突?
- 原因:未集成
eslint-config-prettier和eslint-plugin-prettier; - 解决方案:按「第四步」配置,继承
plugin:prettier/recommended。
4. Git Hooks 不生效?
- 原因:Husky 未初始化,或
pre-commit脚本路径错误; - 解决方案:重新执行
npx husky install和npx husky add .husky/pre-commit "npx lint-staged"。
六、总结
ESLint 是工程化开发的「代码质量守护神」,其核心价值在于:
- 统一风格:避免团队成员因编码习惯不同导致的代码混乱(如有的用单引号、有的用双引号);
- 提前排错:在开发 / 提交 / 打包阶段发现潜在 Bug(如未定义变量、数组越界风险),降低线上故障概率;
- 提升效率:自动化修复大部分风格问题,减少人工格式化时间;
- 规范协作:通过强制校验,确保所有代码符合团队标准,降低代码维护成本。
在实际工程中,ESLint 不是孤立使用的,而是与「编辑器、构建工具、Git Hooks、CI/CD」形成闭环,从开发到部署的全流程保障代码质量。
建议所有 JavaScript/TypeScript 项目(无论是前端还是 Node.js 后端)都必须集成 ESLint,并根据团队需求定制规则。