
目录
[2.1 什么是语义分割?](#2.1 什么是语义分割?)
[2.2 语义分割与其他计算机视觉任务的关系](#2.2 语义分割与其他计算机视觉任务的关系)
[2.3 语义分割的关键特点](#2.3 语义分割的关键特点)
[3.1 传统语义分割方法(1980s-2010s)](#3.1 传统语义分割方法(1980s-2010s))
[3.2 深度学习语义分割的兴起(2012年-)](#3.2 深度学习语义分割的兴起(2012年-))
[3.2.1 Fully Convolutional Networks (FCN, 2015)](#3.2.1 Fully Convolutional Networks (FCN, 2015))
[3.2.2 SegNet (2015)](#3.2.2 SegNet (2015))
[3.2.3 U-Net (2015)](#3.2.3 U-Net (2015))
[3.2.4 DeepLab系列 (2016-2020)](#3.2.4 DeepLab系列 (2016-2020))
[3.2.5 HRNet (2019)](#3.2.5 HRNet (2019))
[3.2.6 Transformer在语义分割中的应用 (2021-)](#3.2.6 Transformer在语义分割中的应用 (2021-))
[4.1 卷积神经网络的基础](#4.1 卷积神经网络的基础)
[4.1.1 卷积层](#4.1.1 卷积层)
[4.1.2 池化层](#4.1.2 池化层)
[4.2 语义分割的关键技术](#4.2 语义分割的关键技术)
[4.2.1 编码器-解码器结构](#4.2.1 编码器-解码器结构)
[4.2.2 上采样技术](#4.2.2 上采样技术)
[4.2.3 多尺度特征融合](#4.2.3 多尺度特征融合)
[4.3 典型语义分割模型的工作流程](#4.3 典型语义分割模型的工作流程)
[5.1 FCN (Fully Convolutional Networks)](#5.1 FCN (Fully Convolutional Networks))
[5.2 U-Net](#5.2 U-Net)
[5.3 DeepLab系列](#5.3 DeepLab系列)
[5.4 SegFormer](#5.4 SegFormer)
[6.1 数据准备](#6.1 数据准备)
[6.2 模型选择与训练](#6.2 模型选择与训练)
[6.3 模型推理与后处理](#6.3 模型推理与后处理)
[6.4 模型评估](#6.4 模型评估)
[7.1 自动驾驶](#7.1 自动驾驶)
[7.2 医学影像](#7.2 医学影像)
[7.3 遥感影像分析](#7.3 遥感影像分析)
[7.4 工业检测](#7.4 工业检测)
[7.5 机器人导航](#7.5 机器人导航)
[7.6 增强现实](#7.6 增强现实)
[8.1 使用PyTorch实现简单的语义分割模型](#8.1 使用PyTorch实现简单的语义分割模型)
[8.1.1 安装依赖](#8.1.1 安装依赖)
[8.1.2 定义U-Net模型](#8.1.2 定义U-Net模型)
[8.1.3 数据加载与预处理](#8.1.3 数据加载与预处理)
[8.1.4 训练模型](#8.1.4 训练模型)
[8.1.5 使用模型进行推理](#8.1.5 使用模型进行推理)
[8.2 使用预训练模型](#8.2 使用预训练模型)
[9.1 基本评估指标](#9.1 基本评估指标)
[9.1.1 Pixel Accuracy (PA)](#9.1.1 Pixel Accuracy (PA))
[9.1.2 Mean Pixel Accuracy (MPA)](#9.1.2 Mean Pixel Accuracy (MPA))
[9.1.3 Intersection over Union (IoU)](#9.1.3 Intersection over Union (IoU))
[9.1.4 Mean Intersection over Union (mIoU)](#9.1.4 Mean Intersection over Union (mIoU))
[9.2 高级评估指标](#9.2 高级评估指标)
[9.2.1 Frequency Weighted IoU (FWIoU)](#9.2.1 Frequency Weighted IoU (FWIoU))
[9.2.2 Boundary F1 Score](#9.2.2 Boundary F1 Score)
[9.3 评估实践](#9.3 评估实践)
[10.1 主要挑战](#10.1 主要挑战)
[10.1.1 类别不平衡](#10.1.1 类别不平衡)
[10.1.2 小物体分割](#10.1.2 小物体分割)
[10.1.3 边界模糊](#10.1.3 边界模糊)
[10.1.4 多尺度变化](#10.1.4 多尺度变化)
[10.1.5 计算复杂度](#10.1.5 计算复杂度)
[10.2 解决方案](#10.2 解决方案)
[10.2.1 解决类别不平衡](#10.2.1 解决类别不平衡)
[10.2.2 解决小物体分割](#10.2.2 解决小物体分割)
[10.2.3 解决边界模糊](#10.2.3 解决边界模糊)
[10.2.4 解决多尺度变化](#10.2.4 解决多尺度变化)
[10.2.5 降低计算复杂度](#10.2.5 降低计算复杂度)
[11.1 Transformer的深入应用](#11.1 Transformer的深入应用)
[11.2 自监督学习](#11.2 自监督学习)
[11.3 多任务学习](#11.3 多任务学习)
[11.4 实时语义分割](#11.4 实时语义分割)
[11.5 3D语义分割](#11.5 3D语义分割)
[11.6 可解释性](#11.6 可解释性)
[12.1 从看到理解](#12.1 从看到理解)
[12.2 技术与人类认知的对比](#12.2 技术与人类认知的对比)
[12.3 技术的伦理与责任](#12.3 技术的伦理与责任)
[12.4 技术的未来展望](#12.4 技术的未来展望)
一、保安小王的新需求:从识别目标到理解场景
还记得我们之前提到的小区保安小王吗?自从监控系统升级到实例分割后,他轻松解决了电动车计数的难题。现在,小王又遇到了新的挑战。
物业经理找到小王:"最近小区绿化区域经常被车辆占用,我们需要统计每天不同区域的占用情况,包括道路、绿地、停车场、人行道等。"小王看着监控画面犯了难------虽然系统能识别出车辆和行人,但要区分整个画面中不同类型的区域,这超出了目标检测和实例分割的能力范围。
就在这时,技术人员又带来了好消息:监控系统再次升级,新增了语义分割功能。
"小王,你看,"技术人员指着屏幕说,"现在系统能自动将图像中的每一个像素分类,道路、绿地、建筑、车辆都被标记上了不同的颜色。你可以直接看到哪些区域被占用,哪些区域是空闲的。"
小王看着屏幕上色彩斑斓的图像,惊讶地说:"太厉害了!这不仅能看到单个物体,还能理解整个场景的结构!"
这个升级后的系统使用的就是语义分割技术。如果说图像分类是"认出是什么",目标检测是"认出是什么+在哪里",实例分割是"认出是什么+在哪里+精确轮廓",那么语义分割就是"理解整个场景+像素级分类"。
二、语义分割的基本概念
2.1 什么是语义分割?
语义分割(Semantic Segmentation)是计算机视觉领域的一项核心任务,它的目标是:
- 逐像素分类:将图像中的每个像素分配到对应的语义类别
- 场景理解:理解图像中不同区域的语义含义
- 不区分实例:同一类别的不同实例会被标记为相同的类别(与实例分割的关键区别)
用数学语言来说,语义分割的输出是一个与输入图像大小相同的标签图,其中每个像素的值表示该像素所属的语义类别。例如,在道路场景中,标签可能包括:
- 0:背景
- 1:道路
- 2:行人
- 3:车辆
- 4:绿化
- 5:建筑物
2.2 语义分割与其他计算机视觉任务的关系
为了更好地理解语义分割,我们来对比一下它与其他相关计算机视觉任务的区别:
| 任务 | 核心能力 | 输出 | 示例应用 |
|---|---|---|---|
| 图像分类 | 识别整体内容 | 单个类别标签 | 图片内容识别(猫/狗) |
| 目标检测 | 识别物体位置 | 边界框+类别 | 智能监控(检测行人/车辆) |
| 语义分割 | 像素级场景理解 | 逐像素类别标签 | 自动驾驶(道路/行人/车辆分割) |
| 实例分割 | 像素级物体识别 | 逐像素类别+实例标签 | 工厂质检(缺陷分割) |
2.3 语义分割的关键特点
- 像素级精度:对每个像素进行分类,提供最细粒度的图像理解
- 全局视角:考虑整个图像的上下文信息,理解场景结构
- 类别一致性:同一类别的区域被标记为相同类别,不区分个体
- 密集预测:输出与输入图像大小相同的标签图
三、语义分割的发展历史
语义分割的发展可以追溯到计算机视觉的早期,经历了从传统方法到深度学习方法的革命性转变。
3.1 传统语义分割方法(1980s-2010s)
在深度学习兴起之前,语义分割主要依赖于手工设计的特征和传统机器学习方法:
- 阈值分割:基于像素灰度值进行简单划分,如Otsu算法
- 区域生长:从种子点开始,逐步合并相似像素
- 边缘检测+区域合并:先检测边缘,再合并区域
- 条件随机场(CRF):结合像素特征和空间关系进行分类
这些方法在简单场景下有一定效果,但对于复杂场景(如光照变化、遮挡、纹理变化等)表现不佳。
3.2 深度学习语义分割的兴起(2012年-)
2012年,AlexNet在ImageNet比赛中的突破性表现,标志着深度学习时代的到来。语义分割也随之进入了快速发展期:
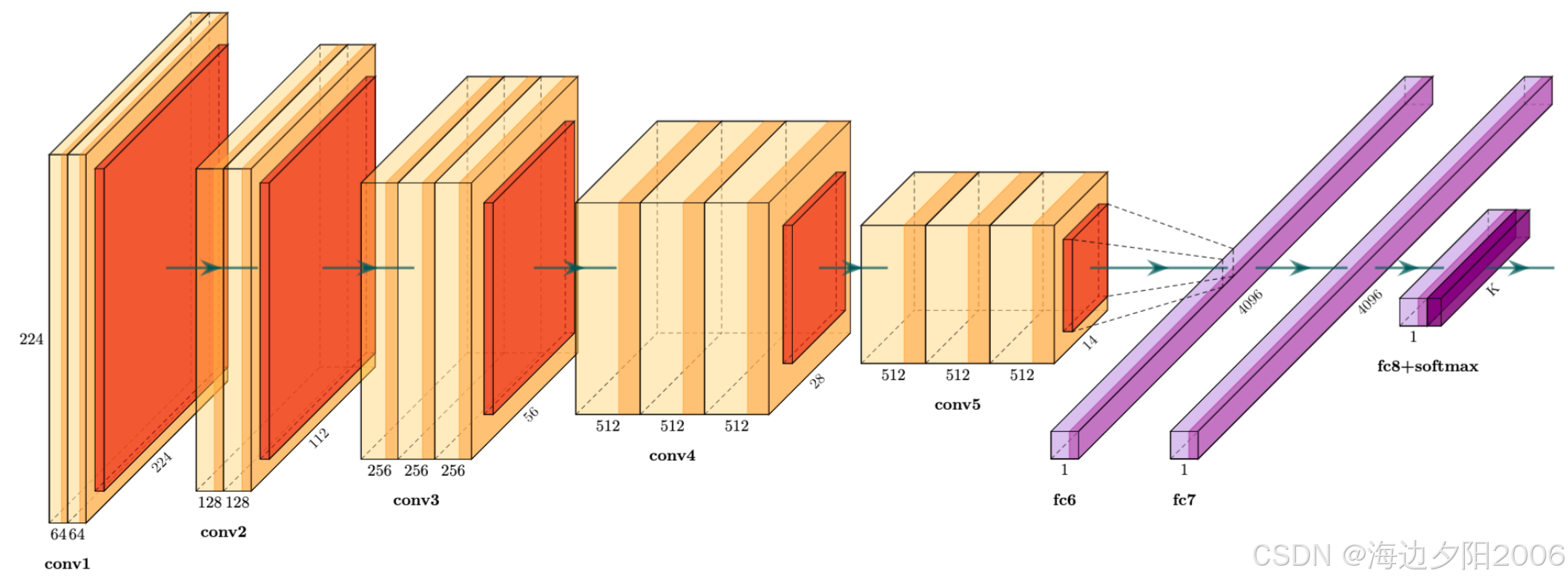
3.2.1 Fully Convolutional Networks (FCN, 2015)
FCN是语义分割领域的里程碑式工作,由Long等人提出。它的核心创新是将传统CNN中的全连接层替换为卷积层,实现了端到端的像素级预测。
- 核心思想:将CNN的分类能力扩展到像素级
- 关键技术 :
- 全卷积层:保持空间信息
- 上采样(转置卷积):恢复图像分辨率
- 跳跃连接:结合高层语义信息和低层细节信息
FCN的出现使得语义分割的性能得到了质的提升,成为后续许多方法的基础。
3.2.2 SegNet (2015)
SegNet由剑桥大学的研究人员提出,在FCN的基础上进行了改进:
- 核心思想:使用编码器-解码器结构,在解码器中保存池化索引用于精确上采样
- 关键改进 :
- 保存池化层的索引信息
- 高效的上采样机制
- 减少了参数量
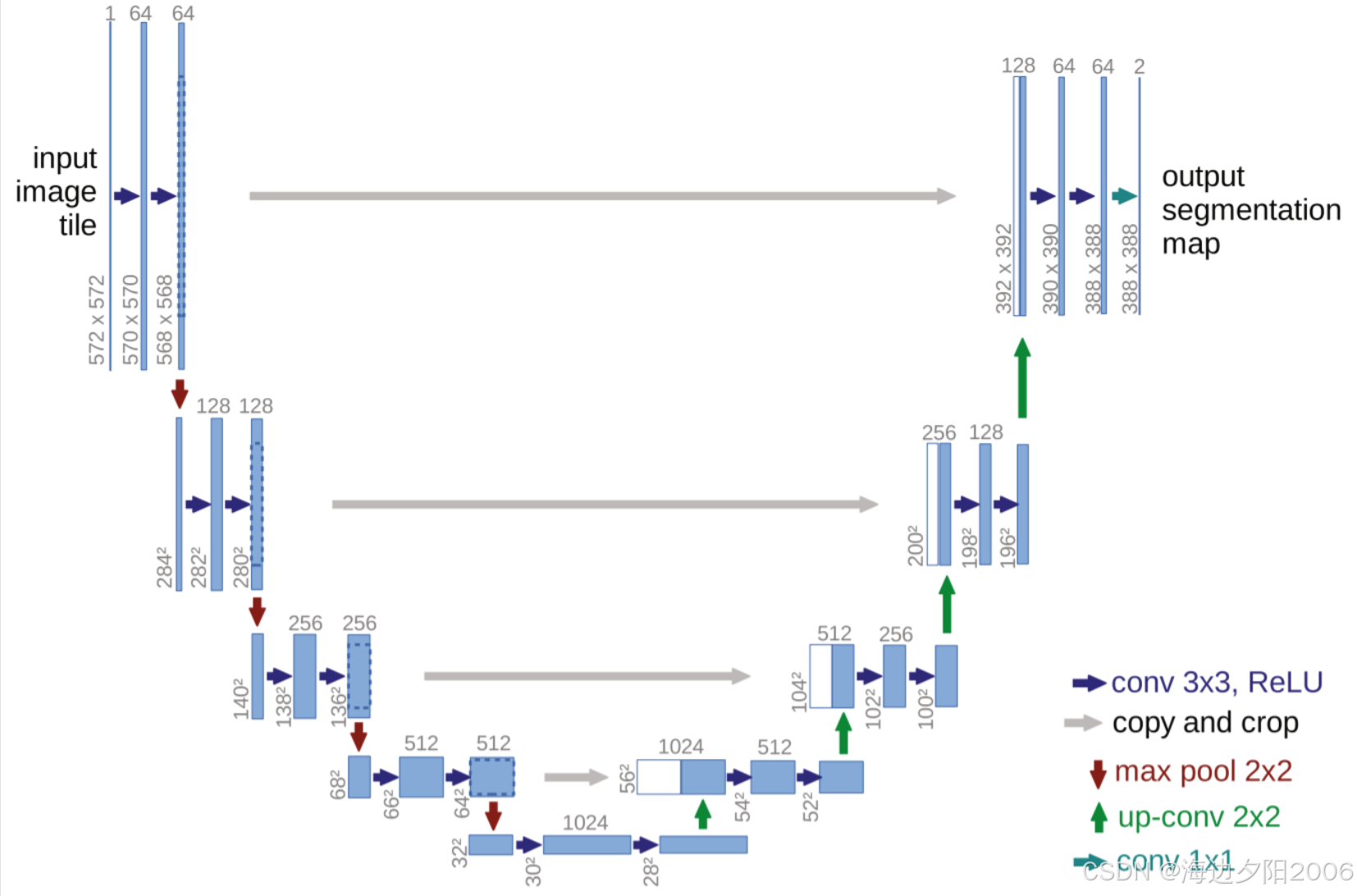
3.2.3 U-Net (2015)
U-Net由Ronneberger等人提出,最初用于医学图像分割:
- 核心思想:编码器-解码器结构+密集跳跃连接
- 关键特点 :
- U形对称结构
- 多尺度特征融合
- 适用于小样本学习
U-Net在医学图像分割领域取得了巨大成功,至今仍被广泛使用。
3.2.4 DeepLab系列 (2016-2020)
DeepLab系列由Google DeepMind提出,是语义分割领域的经典工作:
- DeepLab v1:引入空洞卷积(Dilated Convolution)扩大感受野
- DeepLab v2:加入多尺度空洞空间金字塔池化(ASPP)
- DeepLab v3:改进ASPP模块,使用更大的膨胀率
- DeepLab v3+:结合编码器-解码器结构,引入Xception作为骨干网络
DeepLab系列在多个语义分割基准数据集上取得了领先的性能。
3.2.5 HRNet (2019)
HRNet由微软亚洲研究院提出,采用了创新的高分辨率网络结构:
- 核心思想:保持高分辨率特征图贯穿整个网络
- 关键技术 :
- 并行的多分辨率分支
- 跨分辨率特征融合
- 渐进式特征融合
HRNet在人体姿态估计和语义分割任务中都取得了优秀的成绩。
3.2.6 Transformer在语义分割中的应用 (2021-)
随着Vision Transformer (ViT)的成功,Transformer开始被应用于语义分割领域:
- SETR (2021):将ViT作为编码器,结合转置卷积进行语义分割
- SegFormer (2021):设计了轻量级的分层Transformer,结合MLP解码器
- Mask2Former (2022):统一了实例分割、语义分割和全景分割
Transformer为语义分割带来了新的思路,特别是在处理长距离依赖关系方面表现出色。
四、语义分割的核心原理
4.1 卷积神经网络的基础
语义分割的现代方法主要基于卷积神经网络(CNN)。CNN通过卷积层、池化层和激活函数等组件,能够自动学习图像的特征表示。
4.1.1 卷积层
卷积层是CNN的核心组件,它通过卷积核(Filter)在输入图像上滑动,提取局部特征:
- 卷积操作:输入特征图 × 卷积核 → 输出特征图
- 感受野:卷积层中每个神经元能够看到的输入区域
- 局部连接:每个神经元只连接到输入的局部区域
4.1.2 池化层
池化层用于降低特征图的空间分辨率,减少计算量:
- 最大池化:取局部区域的最大值
- 平均池化:取局部区域的平均值
- 池化的副作用:会丢失空间信息,这是语义分割需要解决的问题
4.2 语义分割的关键技术
4.2.1 编码器-解码器结构
编码器-解码器结构是语义分割的主流框架:
- 编码器:通过卷积和池化操作,提取图像的高层语义特征,同时降低空间分辨率
- 解码器:通过上采样操作,将低分辨率特征图恢复到原始图像大小
- 跳跃连接:将编码器的低层细节特征与解码器的高层语义特征相结合
4.2.2 上采样技术
上采样是语义分割中的关键技术,用于恢复图像分辨率:
-
转置卷积(Transposed Convolution):
- 也称为反卷积(Deconvolution)
- 通过学习的方式进行上采样
- 可能会产生棋盘格效应
-
双线性插值(Bilinear Interpolation):
- 基于相邻像素的线性加权进行上采样
- 计算效率高,但学习能力有限
-
空洞卷积(Dilated Convolution):
- 在不增加参数量的情况下扩大感受野
- 保持空间分辨率
- 广泛应用于DeepLab系列
4.2.3 多尺度特征融合
多尺度特征融合能够提高语义分割的性能:
-
特征金字塔网络(FPN):
- 自上而下的特征融合
- 结合不同尺度的特征
-
空洞空间金字塔池化(ASPP):
- 使用不同膨胀率的空洞卷积
- 捕获多尺度上下文信息
-
注意力机制:
- 自适应地关注重要的特征
- 提高分割精度
4.3 典型语义分割模型的工作流程
以U-Net为例,我们来看看语义分割模型的典型工作流程:
-
输入处理:
- 读取输入图像
- 标准化处理
- 数据增强(可选)
-
编码器阶段:
- 连续的卷积和池化操作
- 提取图像的特征表示
- 空间分辨率逐步降低
-
解码器阶段:
- 连续的上采样和卷积操作
- 恢复图像的空间分辨率
- 通过跳跃连接融合编码器的特征
-
输出阶段:
- 使用1×1卷积将特征映射到类别数
- 应用softmax激活函数获取类别概率
- 生成最终的语义分割标签图
五、语义分割的主要算法
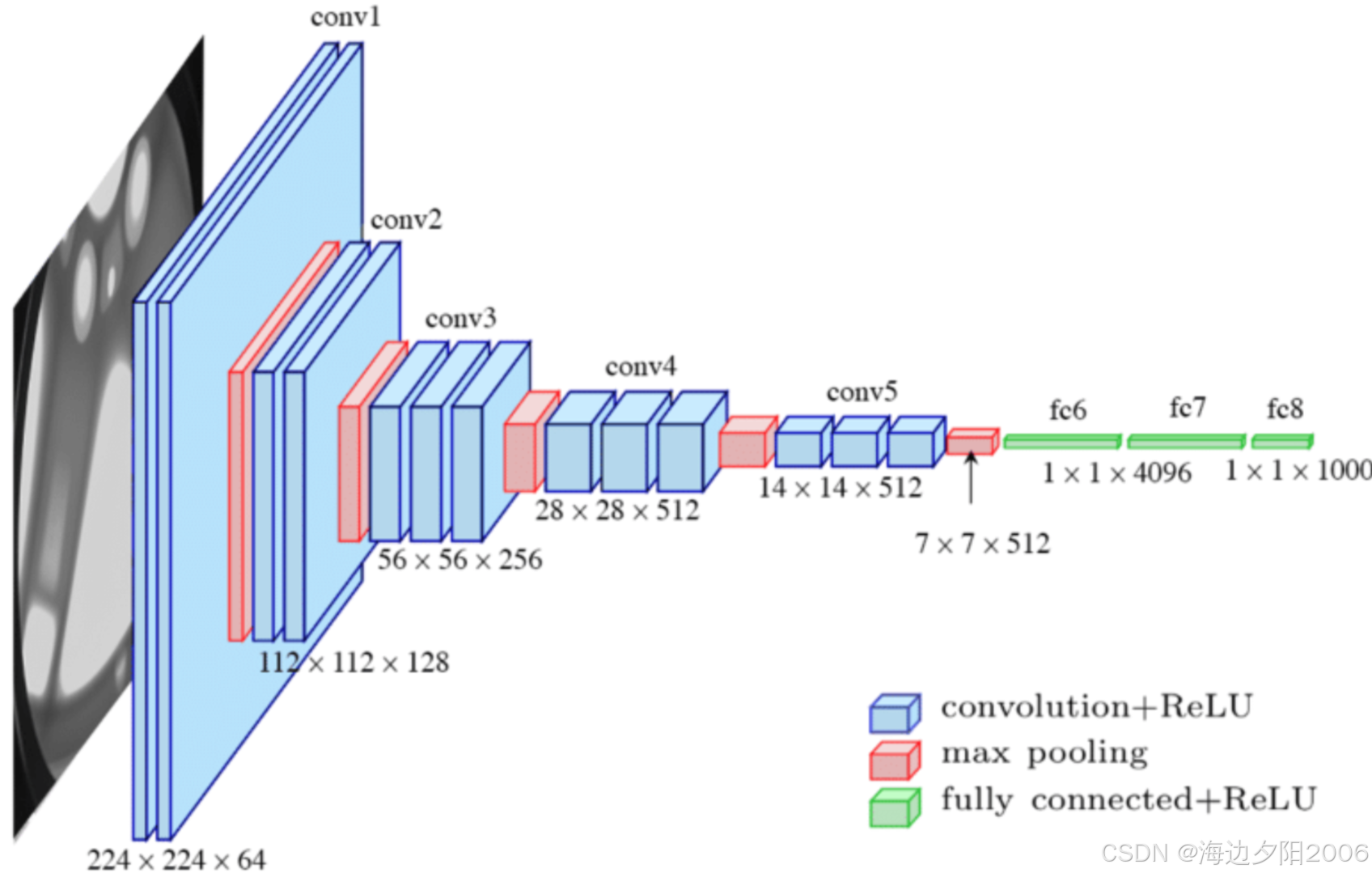
5.1 FCN (Fully Convolutional Networks)
FCN是第一个端到端的深度学习语义分割模型,为后续的研究奠定了基础。
核心特点:
- 用卷积层替换全连接层,实现端到端训练
- 上采样使用转置卷积
- 跳跃连接融合不同层次的特征
网络结构:
- 编码器:基于VGG16或AlexNet
- 解码器:转置卷积层
- 跳跃连接:融合池化层4和池化层3的特征
优缺点:
- 优点:端到端训练,性能显著优于传统方法
- 缺点:上采样质量不高,边界细节处理不够好
5.2 U-Net
U-Net是医学图像分割领域的经典模型,具有U形对称结构。
核心特点:
- 编码器-解码器结构
- 密集的跳跃连接
- 适用于小样本学习
- 数据增强策略
网络结构:
- 编码器:4个卷积块,每个块包含2个卷积层和1个池化层
- 解码器:4个上采样块,每个块包含1个上采样层和2个卷积层
- 跳跃连接:每个解码器块与对应的编码器块连接
应用场景:
- 医学图像分割(如细胞分割、器官分割)
- 遥感图像分析
- 工业检测
5.3 DeepLab系列
DeepLab系列是语义分割领域的重要进展,引入了多项创新技术。
DeepLab v3+的核心特点:
- 空洞卷积扩大感受野
- ASPP模块捕获多尺度信息
- Xception作为骨干网络
- 编码器-解码器结构
ASPP模块:
- 1×1卷积
- 3个不同膨胀率的3×3空洞卷积(6, 12, 18)
- 全局平均池化
优缺点:
- 优点:高性能,在多个数据集上取得SOTA
- 缺点:计算复杂度较高
5.4 SegFormer
SegFormer是基于Transformer的语义分割模型,具有轻量级和高性能的特点。
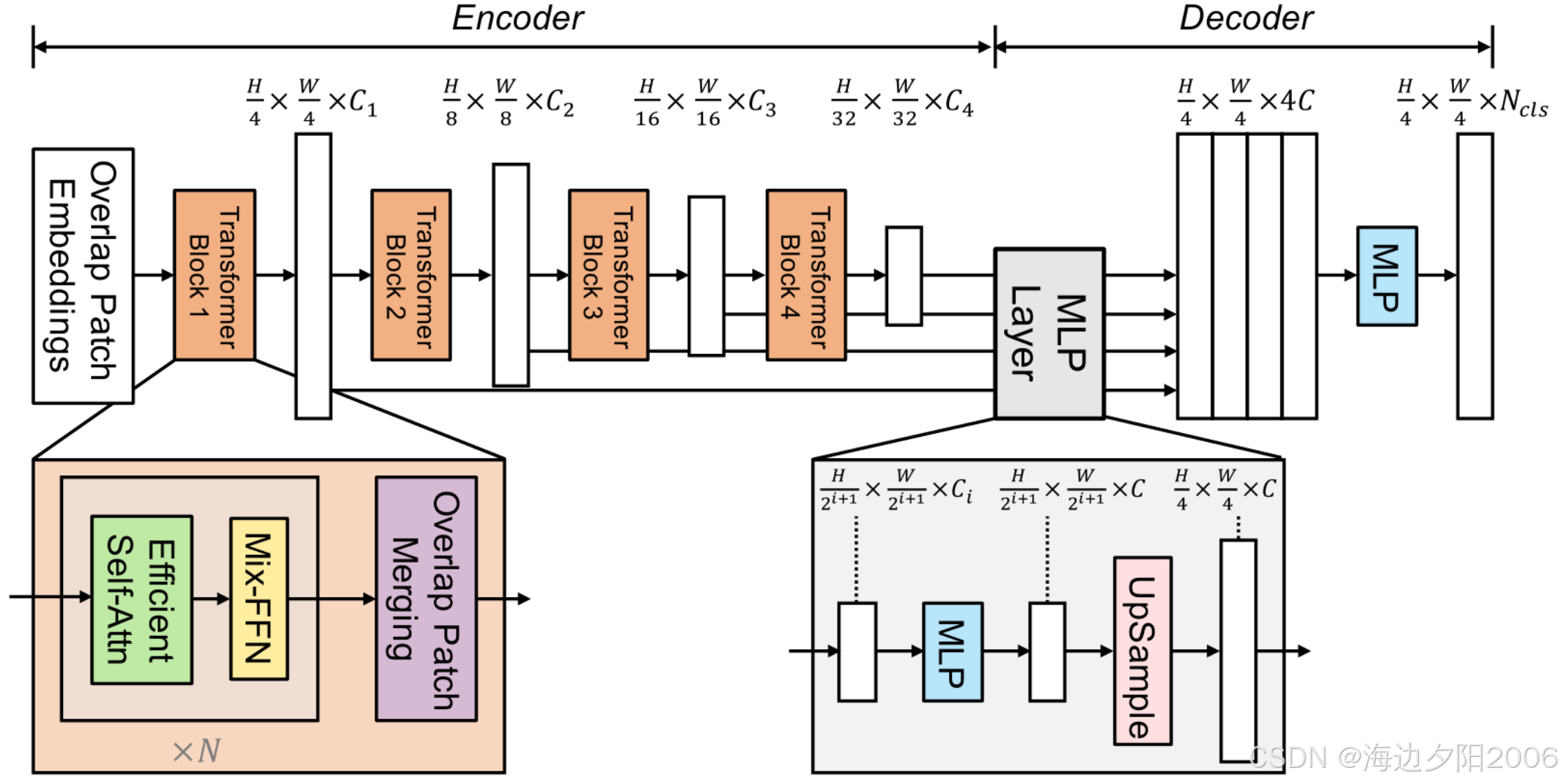
核心特点:
- 分层Transformer编码器
- 轻量级MLP解码器
- 不需要位置编码
- 高效的计算复杂度
网络结构:
- MixVisionTransformer:分层特征提取
- 特征融合模块:融合不同层次的特征
- MLP解码器:生成最终的分割图
优缺点:
- 优点:高精度,低计算量,适合移动端部署
- 缺点:对小物体的分割效果有待提高
六、语义分割的工作流程
6.1 数据准备
语义分割的高质量数据是模型成功的关键:
-
数据集选择:
- Cityscapes:城市道路场景数据集
- PASCAL VOC:通用物体分割数据集
- ADE20K:场景解析数据集
- COCO Stuff:COCO的语义分割扩展
- 自定义数据集
-
数据标注:
- 逐像素标注:工作量大
- 标注工具:Labelme、VGG Image Annotator、CVAT
- 半监督/弱监督方法:减少标注工作量
-
数据增强:
- 几何变换:翻转、旋转、缩放
- 颜色变换:亮度、对比度、饱和度调整
- 随机裁剪:提高模型的鲁棒性
6.2 模型选择与训练
-
模型选择:
- 根据应用场景选择合适的模型
- 考虑计算资源和实时性要求
- 预训练模型的使用
-
损失函数:
- 交叉熵损失(Cross-Entropy Loss):最常用的损失函数
- Dice损失:适用于不平衡数据集
- Focal损失:解决类别不平衡问题
- Lovász-Softmax损失:直接优化IoU
-
训练策略:
- 学习率调度:多阶段学习率衰减
- 优化器:Adam、SGD
- 批量大小:根据GPU内存调整
- 早停策略:防止过拟合
6.3 模型推理与后处理
-
推理过程:
- 图像预处理
- 模型前向传播
- 生成分割结果
-
后处理:
- CRF(条件随机场):平滑分割结果
- 形态学操作:去除噪点
- 连通区域分析:过滤小区域
-
可视化:
- 彩色标签图
- 原图与分割结果叠加
- 混淆矩阵
6.4 模型评估
-
评估指标:
- IoU(Intersection over Union):交并比
- mIoU(mean IoU):所有类别的平均IoU
- Pixel Accuracy:像素准确率
- F1 Score:精确率和召回率的调和平均
-
评估方法:
- 留出验证集
- K折交叉验证
- 测试集评估
七、语义分割的应用场景
语义分割技术在多个领域有着广泛的应用:
7.1 自动驾驶
自动驾驶是语义分割最重要的应用领域之一:
- 道路分割:识别可行驶区域
- 行人检测:分割出路上的行人
- 车辆检测:分割出其他车辆
- 交通标志识别:识别交通标志和信号灯
- 场景理解:理解整体道路场景
7.2 医学影像
语义分割在医学影像领域发挥着重要作用:
- 器官分割:分割出肝脏、心脏等器官
- 肿瘤检测:识别肿瘤区域
- 细胞分割:分析细胞形态
- 病变区域分割:定位病变位置
7.3 遥感影像分析
遥感影像分析需要高精度的语义分割技术:
- 土地利用分类:农田、森林、城市区域等
- 建筑物检测:城市规划和管理
- 道路网络提取:交通规划
- 灾害评估:洪水、火灾等灾害区域分析
7.4 工业检测
工业检测中,语义分割用于质量控制:
- 缺陷检测:识别产品表面缺陷
- 零件分割:自动化组装
- 表面分析:检测表面粗糙度和纹理
7.5 机器人导航
机器人需要理解周围环境才能自主导航:
- 环境感知:识别障碍物和可通行区域
- 物体识别:分割出需要操作的物体
- 场景理解:理解工作环境
7.6 增强现实
增强现实需要精确的场景理解:
- 平面检测:识别放置虚拟物体的平面
- 场景分割:将虚拟物体与真实场景融合
- 遮挡处理:正确处理虚拟物体和真实物体的遮挡关系
八、语义分割的代码实现
8.1 使用PyTorch实现简单的语义分割模型
我们将使用PyTorch实现一个基于U-Net的语义分割模型,用于道路场景分割。
8.1.1 安装依赖
bash
pip install torch torchvision matplotlib numpy pillow8.1.2 定义U-Net模型
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self, in_channels=3, out_channels=2):
super(UNet, self).__init__()
# 编码器
self.enc1 = self.conv_block(in_channels, 64)
self.enc2 = self.conv_block(64, 128)
self.enc3 = self.conv_block(128, 256)
self.enc4 = self.conv_block(256, 512)
# 中间层
self.mid = self.conv_block(512, 1024)
# 解码器
self.up4 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)
self.dec4 = self.conv_block(1024, 512)
self.up3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.dec3 = self.conv_block(512, 256)
self.up2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.dec2 = self.conv_block(256, 128)
self.up1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.dec1 = self.conv_block(128, 64)
# 输出层
self.out = nn.Conv2d(64, out_channels, kernel_size=1)
def conv_block(self, in_channels, out_channels):
"""定义卷积块"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
# 编码器
enc1 = self.enc1(x)
enc2 = self.enc2(F.max_pool2d(enc1, kernel_size=2, stride=2))
enc3 = self.enc3(F.max_pool2d(enc2, kernel_size=2, stride=2))
enc4 = self.enc4(F.max_pool2d(enc3, kernel_size=2, stride=2))
# 中间层
mid = self.mid(F.max_pool2d(enc4, kernel_size=2, stride=2))
# 解码器
dec4 = self.up4(mid)
dec4 = torch.cat((dec4, enc4), dim=1)
dec4 = self.dec4(dec4)
dec3 = self.up3(dec4)
dec3 = torch.cat((dec3, enc3), dim=1)
dec3 = self.dec3(dec3)
dec2 = self.up2(dec3)
dec2 = torch.cat((dec2, enc2), dim=1)
dec2 = self.dec2(dec2)
dec1 = self.up1(dec2)
dec1 = torch.cat((dec1, enc1), dim=1)
dec1 = self.dec1(dec1)
# 输出
out = self.out(dec1)
return out8.1.3 数据加载与预处理
python
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import numpy as np
class RoadDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.images[idx])
mask_path = os.path.join(self.mask_dir, self.images[idx].replace('.jpg', '.png'))
# 加载图像和掩码
image = Image.open(img_path).convert('RGB')
mask = Image.open(mask_path).convert('L') # 灰度图
# 数据预处理
if self.transform:
image = self.transform(image)
mask = self.transform(mask)
# 将掩码转换为标签
mask = mask.squeeze(0).long() # 移除通道维度,转换为长整型
return image, mask
# 定义数据转换
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 创建数据集和数据加载器
train_dataset = RoadDataset(
image_dir='./data/images/train',
mask_dir='./data/masks/train',
transform=transform
)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)8.1.4 训练模型
python
import torch.optim as optim
# 定义设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 创建模型
model = UNet(in_channels=3, out_channels=2).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
epochs = 20
for epoch in range(epochs):
model.train()
running_loss = 0.0
for images, masks in train_loader:
images, masks = images.to(device), masks.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, masks)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
epoch_loss = running_loss / len(train_loader.dataset)
print(f'Epoch {epoch+1}/{epochs}, Loss: {epoch_loss:.4f}')
# 保存模型
torch.save(model.state_dict(), 'unet_road_segmentation.pth')8.1.5 使用模型进行推理
python
import matplotlib.pyplot as plt
# 加载模型
model = UNet(in_channels=3, out_channels=2)
model.load_state_dict(torch.load('unet_road_segmentation.pth'))
model.eval()
# 推理函数
def predict(image_path):
# 加载和预处理图像
image = Image.open(image_path).convert('RGB')
original_size = image.size
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
input_tensor = transform(image).unsqueeze(0) # 添加批量维度
# 模型推理
with torch.no_grad():
output = model(input_tensor)
pred = torch.argmax(output, dim=1).squeeze(0).numpy() # 获取预测结果
# 恢复原始大小
pred_image = Image.fromarray(pred.astype(np.uint8)).resize(original_size)
return image, pred_image
# 测试推理
image_path = './data/images/test/road1.jpg'
original_image, pred_mask = predict(image_path)
# 可视化结果
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.imshow(original_image)
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(pred_mask, cmap='gray')
plt.title('Predicted Segmentation')
plt.axis('off')
plt.show()8.2 使用预训练模型
我们也可以使用PyTorch Hub中的预训练模型进行语义分割:
python
import torch
from PIL import Image
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# 加载预训练模型
model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_resnet101', pretrained=True)
model.eval()
# 定义颜色映射(用于可视化)
def label_to_color_image(label):
colormap = [(0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0),
(0, 0, 128), (128, 0, 128), (0, 128, 128), (128, 128, 128),
(64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0),
(64, 0, 128), (192, 0, 128), (64, 128, 128), (192, 128, 128),
(0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0),
(0, 64, 128)]
return np.array([colormap[l] for l in label.flatten()]).reshape(label.shape + (3,))
# 图像预处理
input_image = Image.open('./data/images/test/city.jpg')
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # 添加批量维度
# 模型推理
with torch.no_grad():
output = model(input_batch)
output_predictions = torch.argmax(output['out'], dim=1).squeeze(0).numpy()
# 可视化结果
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.imshow(input_image)
plt.title('Original Image')
plt.axis('off')
plt.subplot(1, 3, 2)
plt.imshow(output_predictions)
plt.title('Predicted Label Map')
plt.axis('off')
plt.subplot(1, 3, 3)
plt.imshow(label_to_color_image(output_predictions))
plt.title('Colorized Segmentation')
plt.axis('off')
plt.show()九、语义分割的评估指标
9.1 基本评估指标
9.1.1 Pixel Accuracy (PA)
像素准确率是最直观的评估指标,计算正确分类的像素占总像素的比例:
其中,kk是类别数,piipii是正确分类为类别ii的像素数,pijpij是将类别ii错误分类为类别jj的像素数。
9.1.2 Mean Pixel Accuracy (MPA)
平均像素准确率是计算每个类别的像素准确率,然后取平均值:
9.1.3 Intersection over Union (IoU)
交并比是语义分割中最重要的评估指标,计算预测结果与真实标签的交集和并集的比值:
9.1.4 Mean Intersection over Union (mIoU)
平均交并比是计算每个类别的IoU,然后取平均值:
mIoU是语义分割任务中最常用的评估指标,能综合反映模型的分割性能。
9.2 高级评估指标
9.2.1 Frequency Weighted IoU (FWIoU)
频率加权IoU考虑了每个类别的像素频率,对像素数量多的类别给予更大的权重:
9.2.2 Boundary F1 Score
边界F1分数评估模型对物体边界的分割精度:
其中,Precision是预测边界与真实边界的交集与预测边界的比值,Recall是预测边界与真实边界的交集与真实边界的比值。
9.3 评估实践
在实际评估中,我们通常需要考虑以下几点:
- 类别不平衡:语义分割数据集中类别分布往往不平衡,需要选择合适的评估指标
- 小物体:小物体的分割难度较大,需要专门的评估方法
- 边界质量:边界分割质量对视觉效果影响很大
- 速度与精度:在实际应用中,需要权衡模型的推理速度和分割精度
十、语义分割的挑战与解决方案
10.1 主要挑战
10.1.1 类别不平衡
语义分割数据集中,背景类别的像素通常远多于前景类别,导致模型倾向于预测背景类别。
10.1.2 小物体分割
小物体(如远处的行人、车辆)像素数量少,特征不明显,分割难度大。
10.1.3 边界模糊
物体边界的像素往往具有不确定性,模型难以准确分类。
10.1.4 多尺度变化
同一类别的物体在图像中可能有不同的尺度,模型需要适应这种变化。
10.1.5 计算复杂度
语义分割需要逐像素预测,计算量和内存消耗都很大。
10.2 解决方案
10.2.1 解决类别不平衡
- 损失函数调整:使用Dice损失、Focal损失等
- 数据增强:对少数类别进行过采样
- 加权损失:为少数类别分配更大的权重
- OHEM(在线难例挖掘):关注难分类的像素
10.2.2 解决小物体分割
- 多尺度训练:使用不同分辨率的图像进行训练
- 特征融合:融合不同层次的特征
- 注意力机制:关注小物体区域
- 高分辨率网络:保持高分辨率特征图
10.2.3 解决边界模糊
- 边界感知损失:专门优化边界区域
- CRF后处理:平滑分割结果
- 边缘检测辅助:结合边缘检测结果
- 空洞卷积:保持边界细节
10.2.4 解决多尺度变化
- ASPP模块:使用不同膨胀率的卷积
- 特征金字塔:融合不同尺度的特征
- 图像金字塔:在推理时使用多尺度图像
- 自适应感受野:动态调整感受野大小
10.2.5 降低计算复杂度
- 轻量化网络:使用MobileNet、ShuffleNet等
- 模型压缩:剪枝、量化、蒸馏
- 知识蒸馏:将大模型的知识迁移到小模型
- 硬件加速:使用GPU、TPU等加速设备
十一、语义分割的趋势
11.1 Transformer的深入应用
Transformer在语义分割领域的应用将更加广泛:
- 分层Transformer:结合CNN的局部特征提取能力
- 高效Transformer:降低计算复杂度
- 多模态Transformer:融合图像、文本等多模态信息
11.2 自监督学习
自监督学习将减少对标注数据的依赖:
- 预训练任务设计:掩码图像建模、对比学习
- 领域适应:将预训练模型迁移到新领域
- 半监督/弱监督学习:结合少量标注数据和大量无标注数据
11.3 多任务学习
多任务学习将提高模型的泛化能力:
- 联合训练:语义分割与实例分割、深度估计等任务联合训练
- 任务间信息共享:利用任务间的互补信息
- 动态任务权重:自适应调整不同任务的权重
11.4 实时语义分割
实时语义分割将满足实际应用的需求:
- 轻量化模型设计:减少参数量和计算量
- 硬件优化:专用芯片和加速库
- 模型剪枝与量化:进一步压缩模型
11.5 3D语义分割
3D语义分割将成为新的研究热点:
- 点云语义分割:处理LiDAR数据
- 体积分割:处理医学CT、MRI数据
- 视频语义分割:处理时序信息
11.6 可解释性
语义分割模型的可解释性将受到更多关注:
- 注意力可视化:显示模型关注的区域
- 特征归因:解释模型的预测依据
- 因果推理:理解图像元素之间的因果关系
十二、语义分割的哲学思考
12.1 从看到理解
语义分割技术让计算机从"看到图像"升级到"理解图像",这是人工智能视觉领域的重要进步。它不仅能识别单个物体,还能理解物体之间的关系和整个场景的结构。
12.2 技术与人类认知的对比
计算机的语义分割与人类的视觉认知有很大不同:
- 处理方式:计算机逐像素分类,人类通过整体感知
- 上下文理解:计算机依赖训练数据,人类利用常识和经验
- 泛化能力:计算机在陌生场景表现较差,人类具有很强的泛化能力
12.3 技术的伦理与责任
语义分割技术的广泛应用带来了伦理和责任问题:
- 隐私保护:在监控场景中,需要保护个人隐私
- 算法偏见:训练数据的偏见可能导致不公平的分割结果
- 安全风险:在自动驾驶等安全关键领域,分割错误可能导致严重后果
12.4 技术的未来展望
语义分割技术将继续发展,与其他技术(如自然语言处理、机器人技术)深度融合,为人类社会带来更多便利。同时,我们也需要关注技术发展带来的社会影响,确保技术的负责任发展。
附录:语义分割常用数据集
| 数据集 | 图像数量 | 类别数 | 场景类型 | 应用领域 |
|---|---|---|---|---|
| Cityscapes | 5000(精细标注) | 19 | 城市道路 | 自动驾驶 |
| PASCAL VOC | 11530 | 21 | 通用物体 | 通用物体分割 |
| ADE20K | 25000 | 150 | 室内外场景 | 场景解析 |
| COCO Stuff | 164k | 171 | 自然场景 | 自然场景分割 |
| ISPRS Potsdam | 38 | 6 | 遥感影像 | 遥感分析 |
| CamVid | 701 | 32 | 城市道路 | 自动驾驶 |
| SBD | 11355 | 20 | 通用物体 | 通用物体分割 |
| KITTI | 3712 | 9 | 城市道路 | 自动驾驶 |