文章目录
- 1、原理
- [2、Seq2Seq 缺点 - 引入注意力机制](#2、Seq2Seq 缺点 - 引入注意力机制)
- 3、端到端
- [4、训练过程(Teacher Forcing 模型优化方法)](#4、训练过程(Teacher Forcing 模型优化方法))
- [5、Scheduled Sampling(计划采样)](#5、Scheduled Sampling(计划采样))
- 6、非可微采样与梯度截断
- [7、Teacher Forcing 作用于时间步还是整个句子](#7、Teacher Forcing 作用于时间步还是整个句子)
- 8、什么时候添加EOS:训练时添加到目标句末尾
- [9、什么时候添加SOS:看当前 token 是"输入"还是"目标"](#9、什么时候添加SOS:看当前 token 是“输入”还是“目标”)
- 10、预测过程
- 11、什么时候判断EOS结束:推理阶段才需要
- [12、预测时,什么时候结束:最大长度 or EOS](#12、预测时,什么时候结束:最大长度 or EOS)
1、原理
一、为什么叫 "Seq2Seq"?到底是什么意思?
- Seq2Seq = Sequence-to-Sequence
- 字面意思:把一个序列(sequence)映射到另一个序列
- 在机器翻译中:
- 输入序列(Source) :源语言句子,如中文
["欢迎", "来", "北京"] - 输出序列(Target) :目标语言句子,如英文
["Welcome", "to", "Beijing", "."]
- 输入序列(Source) :源语言句子,如中文
- 序列特点:
- 长度可变(输入 3 词,输出 4 词)
- 顺序敏感("北京欢迎你" ≠ "欢迎你北京")
- 语言/符号系统可不同
✅ 所以,"Seq2Seq" 描述的是一类通用任务范式 :变长输入 → 变长输出。
二、Seq2Seq 机器翻译任务是干什么的?
目标:给定一个源语言句子,自动生成其目标语言的流畅、准确翻译。
- 输入:源句 token 序列 x = ( x 1 , x 2 , . . . , x T ) x = (x_1, x_2, ..., x_T) x=(x1,x2,...,xT)
- 输出:目标句 token 序列 y = ( y 1 , y 2 , . . . , y T ′ ) y = (y_1, y_2, ..., y_{T'}) y=(y1,y2,...,yT′)
- 要求: P ( y ∣ x ) P(y \mid x) P(y∣x) 最大化(即生成最可能的翻译)
📌 注意:这是端到端(end-to-end,后面有详情 "端到端" ) 学习------直接从原始词序列映射到翻译结果,无需人工构建词对齐表、短语表、语言模型等传统模块。
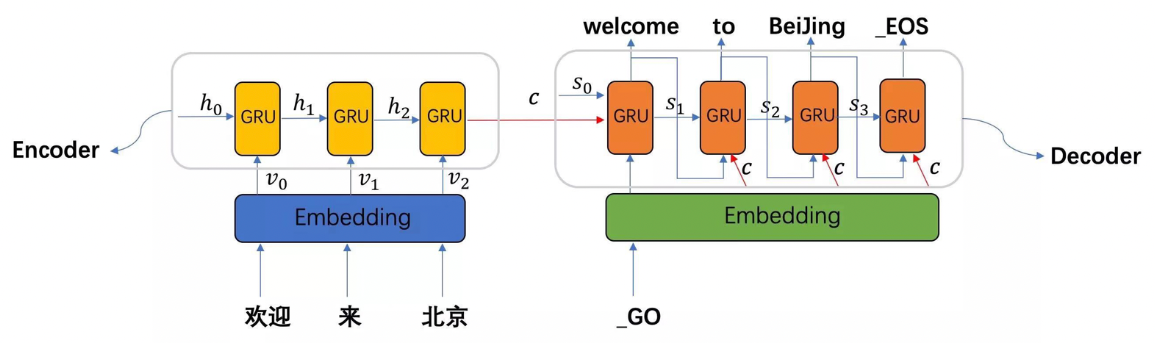
三、整体架构:Encoder-Decoder
不带注意力的 Seq2Seq 采用 Encoder-Decoder 架构,两者通常都是 RNN(或 LSTM/GRU)。
[ Encoder ] [ Decoder ]
x₁ → <sos> →
x₂ → ─── c ───→ y₁ →
x₃ → y₂ →
<eos> → y₃ →
...- Encoder :读取整个源句(含
<eos>),将其压缩为一个固定维度的上下文向量 c - Decoder :以 c 为初始隐藏状态,逐步生成目标句(从
<sos>开始,到<eos>结束)
🔑 核心思想:用一个向量 c "编码"整句语义,再由 Decoder "解码"成翻译。
四、中间张量 c 是什么?由什么构成?
✅ 正确定义(标准做法):
c 是 Encoder RNN(或 LSTM/GRU)在处理完整个输入序列(包括
<eos>)后的最后一个隐藏状态。
具体构成(以 LSTM 为例):
-
假设使用单层 LSTM 作为 Encoder
-
输入:
["欢迎", "来", "北京", "<eos>"]→ 长度 T=4 -
Encoder 依次计算隐藏状态: h_1, h_2, h_3, h_4
-
取 最后一个隐藏状态 :
c = h 4 ∈ R d h \mathbf{c} = \mathbf{h}_4 \in \mathbb{R}^{d_h} c=h4∈Rdh
⚠️ 注意:
- 如果 Encoder 是 LSTM ,其内部状态为 ( h t , c t cell ) (h_t, c_t^{\text{cell}}) (ht,ctcell),但只取 h T h_T hT 作为上下文向量 c c c 传递给 Decoder ;Encoder 的 cell state c T cell c_T^{\text{cell}} cTcell 不会传给 Decoder
- 如果是 GRU 或 RNN ,直接取 h T h_T hT
❌ 常见误解澄清:
- c 不是所有隐藏状态的拼接(维度随输入长度变化,不可行)
- c 不是平均池化或最大池化结果(原始 Seq2Seq 不采用此类聚合)
- c 是一个固定维度的向量(如 512 维),与输入长度无关
✅ c 的作用:充当 Encoder 和 Decoder 之间的"信息桥梁",承载整个源句的语义摘要。
⚠️ 说法:"把 output 里每个时间步的状态拼接起来得到 c"
这个说法不准确,但可能源于对某些变体的误解。我们来澄清:
❌ 错误理解:
"把所有 h 1 , h 2 , . . . , h T h_1, h_2, ..., h_T h1,h2,...,hT 拼成一个超长向量当 c"
这在实际中几乎从不使用,因为:
- 拼接后维度 = T × d(d 是隐藏维),T 不固定 → c 维度不固定
- Decoder 无法处理变长输入向量(RNN 要求固定维)
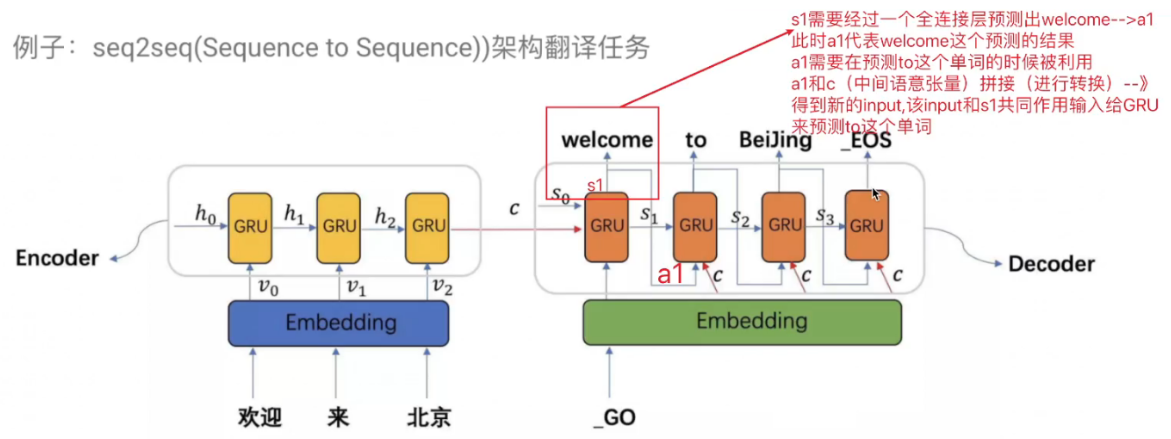
五、Decoder 的输入到底是什么?每步几个?
这是最容易混淆的地方。我们分训练阶段 和推理阶段 说明,但状态输入机制完全一致。
核心原则(适用于 RNN/LSTM/GRU):
Decoder 的初始隐藏状态 = c
之后每一步,只输入"上一时刻的目标词" + "上一隐藏状态"
具体流程(以 LSTM Decoder 为例):
-
初始化:
- h 0 dec = c \mathbf{h}_0^{\text{dec}} = \mathbf{c} h0dec=c(来自 Encoder)
- c 0 dec = 0 \mathbf{c}_0^{\text{dec}} = \mathbf{0} c0dec=0(Decoder 自己的 cell state,通常初始化为零;不继承 Encoder 的 cell state)
-
时间步 t = 1:
- 输入词:
<sos>(start of sentence token) - 输入状态: ( h 0 dec , c 0 dec ) (\mathbf{h}_0^{\text{dec}}, \mathbf{c}_0^{\text{dec}}) (h0dec,c0dec)
- 输出:预测 y 1 y_1 y1(如 "Welcome")
- 输入词:
-
时间步 t = 2:
- 输入词: y 1 y_1 y1(训练时用真实标签,推理时用预测值)
- 输入状态: ( h 1 dec , c 1 dec ) (\mathbf{h}_1^{\text{dec}}, \mathbf{c}_1^{\text{dec}}) (h1dec,c1dec)
- 输出:预测 y 2 y_2 y2(如 "to")
-
...直到预测出
<eos>(end of sentence)
关键澄清:
| 说法 | 是否正确 | 说明 |
|---|---|---|
| "Decoder 每步输入:上一词 + 上一隐藏状态 + c" | ❌ 错误 | c 只在初始化时用一次,之后不再显式输入 |
| "c 会每步传给 Decoder" | ❌ 错误 | c 的信息通过隐藏状态的递归传递隐式保留 |
| "Decoder 每步实际输入 RNN 单元的是两个东西" | ✅ 正确 | 当前词嵌入 + 上一状态(LSTM 是两个向量,GRU/RNN 是一个) |
📌 总结:
- c 不是 Decoder 每步的输入 ,而是初始隐藏状态的设定值
- Decoder 每步的输入逻辑与普通 RNN 完全一致
六、完整示例:"欢迎来北京" → "Welcome to Beijing."
- 数据预处理
- 源句(中文):
["欢迎", "来", "北京", "<eos>"] - 目标句(英文):
["<sos>", "Welcome", "to", "Beijing", ".", "<eos>"]
- Encoder(LSTM)
- 输入嵌入序列 → 逐词处理
- 得到隐藏状态: h 1 , h 2 , h 3 , h 4 h_1, h_2, h_3, h_4 h1,h2,h3,h4
- 取 c = h 4 \mathbf{c} = h_4 c=h4
- Decoder(LSTM)
- 初始化:
h 0 dec = c h_0^{\text{dec}} = c h0dec=c, c 0 dec = 0 c_0^{\text{dec}} = 0 c0dec=0 - t=1:输入
<sos>→ 输出 "Welcome" - t=2:输入 "Welcome" → 输出 "to"
- t=3:输入 "to" → 输出 "Beijing"
- t=4:输入 "Beijing" → 输出 "."
- t=5:输入 "." → 输出
<eos>→ 停止
✅ 全程 没有再次使用 c ,也没有访问 Encoder 的 h 1 , h 2 , h 3 h_1, h_2, h_3 h1,h2,h3
七、训练 vs 推理的区别(仅输入词不同)
| 阶段 | Decoder 每步的"词输入"是什么? |
|---|---|
| 训练(Teacher Forcing) | 使用真实的上一目标词(如 t=2 时输入 "Welcome",即使模型 t=1 预测错了) |
| 推理(Generation) | 使用自己上一步预测的词(错误可能累积) |
但状态输入机制完全相同:都依赖上一隐藏状态(由 c 初始化而来)
八、为什么这个设计有根本缺陷?
- 信息瓶颈 :任意长度的句子被压缩进固定维度的向量 c → 长句信息严重丢失
- Decoder 无法"回看"源句:生成 "Beijing" 时,无法动态参考 "北京" 对应的 Encoder 状态
- 性能随句子长度急剧下降(实验证明)
💡 这正是注意力机制要解决的问题 :让 Decoder 在每一步都能动态关注 Encoder 的所有隐藏状态 { h 1 , . . . , h T } \{h_1, ..., h_T\} {h1,...,hT},并合成一个新的上下文向量 c t c_t ct,从而打破固定 c c c 的限制。
九、总结:无注意力 Seq2Seq 的关键点
| 问题 | 答案 |
|---|---|
| Seq2Seq 是什么? | 序列到序列的端到端映射任务,用于机器翻译等 |
| 中间张量 c 是什么? | Encoder 的最后一个隐藏状态 h T h_T hT,固定维度 |
| c 由什么构成? | 若 Encoder 是 LSTM,c = h T h_T hT(不是 cell state );若是 GRU/RNN,c = h T h_T hT |
| Decoder 每步输入几个东西? | 两个逻辑输入:1. 上一目标词的嵌入 2. 上一隐藏状态(LSTM 含 h 和 c) |
| c 会每步输入 Decoder 吗? | ❌ 不会!只用于初始化 Decoder 的隐藏状态 |
| Encoder 的其他隐藏状态有用吗? | ❌ 在无注意力机制中, h 1 ∼ h T − 1 h_1 \sim h_{T-1} h1∼hT−1 被丢弃 |
你现在对不带注意力机制的 Seq2Seq 模型已经有了精确、无混淆的理解。接下来,当你学习注意力机制时,就能立刻意识到它的突破性:
注意力机制的核心,就是让 Decoder 在每一步都能访问 Encoder 的所有隐藏状态 { h 1 , . . . , h T } \{h_1, ..., h_T\} {h1,...,hT},并动态合成一个新的上下文向量 c t c_t ct,从而打破固定 c c c 的限制。
2、Seq2Seq 缺点 - 引入注意力机制
非常好!你已经扎实掌握了不带注意力机制的 Seq2Seq 模型------包括它的架构、训练(Teacher Forcing)、推理(自回归生成),以及核心组件 上下文向量 c \mathbf{c} c 的作用与局限。
现在,我们来到关键转折点:为什么要引入注意力机制(Attention)?
🎯 一句话回答:
因为原始 Seq2Seq 将任意长度的源句压缩为一个固定维度的上下文向量 c \mathbf{c} c,导致长句信息严重丢失;而注意力机制允许 Decoder 在每一步动态聚焦源句的不同部分,从而突破信息瓶颈。
🔍 详细解释:原始 Seq2Seq 的根本缺陷
- 信息瓶颈(Information Bottleneck)
- Encoder 必须将整句(无论多长)编码进一个固定维度的向量 c = h T enc \mathbf{c} = \mathbf{h}_T^{\text{enc}} c=hTenc
- 例如:50 个中文词 → 512 维向量
→ 相当于要求一个人读完一本小说,只用一句话概括全部内容 - 实验表明:句子越长,翻译质量显著下降(Sutskever et al., 2014)
- Decoder 难以准确关联源词与目标词
- 在生成 "Beijing" 时,Decoder 仅依赖 c \mathbf{c} c 中残存的信息
- 它无法直接知道该词对应源句中的"北京",也难以确认局部上下文
- 所有源句细节都经过一次"有损压缩",关键信息可能被覆盖或稀释
- c \mathbf{c} c 是静态且全局的
- 整个解码过程使用同一个 c \mathbf{c} c
- 但翻译不同目标词时,应关注源句的不同区域:
- 翻译 "Welcome" → 应关注 "欢迎"
- 翻译 "Beijing" → 应关注 "北京"
- 原始模型缺乏这种动态、局部的对齐能力
💡 注意力机制如何解决这些问题?
注意力机制的核心思想是:
不再依赖单一的 c \mathbf{c} c,而是让 Decoder 在每一步 t t t 访问 Encoder 的全部隐藏状态 { h 1 , h 2 , ... , h T } \{\mathbf{h}_1, \mathbf{h}_2, \dots, \mathbf{h}_T\} {h1,h2,...,hT},并计算一个加权上下文向量 c t \mathbf{c}_t ct,作为当前步的输入。
具体改进:
| 原始 Seq2Seq | 带注意力的 Seq2Seq |
|---|---|
| 使用固定 c = h T enc \mathbf{c} = \mathbf{h}_T^{\text{enc}} c=hTenc | 每步生成动态上下文 c t = ∑ i = 1 T α t i h i \mathbf{c}t = \sum{i=1}^T \alpha_{ti} \mathbf{h}_i ct=∑i=1Tαtihi |
| 信息高度压缩、不可逆 | 保留完整源句表示,按需读取 |
| 无法显式对齐源词与目标词 | 自动学习"软对齐"(如 "Beijing" ↔ "北京") |
| 长句性能差 | 长句翻译质量显著提升 |
举个例子:
在生成 "Beijing" 时:
- 注意力机制会自动提高 "北京" 对应的 Encoder 隐藏状态 h 3 \mathbf{h}3 h3 的权重 α t 3 \alpha{t3} αt3
- 生成 "to" 时,可能更关注 "来" 对应的 h 2 \mathbf{h}_2 h2
- 这种对齐是数据驱动、端到端可学习的,无需人工标注对齐表
✅ 注意:注意力机制在训练和推理阶段均生效 ,每一步都重新计算 c t \mathbf{c}_t ct
📈 实证效果
- Bahdanau et al. (2015) 首次将注意力引入 Seq2Seq 机器翻译(称为"Additive Attention")
- 在英法翻译任务上,BLEU 分数大幅提升
- 尤其在长句子上,优势极其明显(原始模型 BLEU 下降 50%,注意力模型几乎持平)
- 注意力权重可视化后,呈现出合理的词对齐模式(如名词对名词、动词对动词),具有可解释性
✅ 总结:为什么需要注意力机制?
| 问题 | 原始 Seq2Seq | 注意力机制的解决方案 |
|---|---|---|
| 信息瓶颈 | ❌ 固定向量 c \mathbf{c} c 无法承载长句信息 | ✅ 每步动态合成上下文 c t \mathbf{c}_t ct |
| 无法回看源句 | ❌ 仅依赖压缩后的 c \mathbf{c} c | ✅ 直接访问所有 Encoder 隐藏状态 |
| 静态上下文 | ❌ 全程用同一个 c \mathbf{c} c | ✅ 每步聚焦不同源词(通过权重 α t i \alpha_{ti} αti) |
| 长句性能差 | ❌ 翻译质量随长度急剧下降 | ✅ 显著改善长句翻译 |
🌟 注意力机制不是锦上添花,而是解决了 Seq2Seq 的根本性缺陷 。
它不仅提升了性能,还引入了可解释的对齐能力,为后来的 Transformer 和大语言模型奠定了基础。
3、端到端
✅ 什么是端到端(end-to-end)学习?
直接从原始输入映射到最终输出,中间不需要人工设计的分步模块或规则。
- "端" = 输入端(原始数据) → 输出端(最终结果)
- "到" = 一个模型、一次训练、自动学习全部中间表示
🌰 举例对比:传统机器翻译 vs 端到端 Seq2Seq
❌ 传统统计机器翻译(SMT)------非端到端
要翻译 "欢迎来北京" → "Welcome to Beijing.",需要多个独立模块:
- 词对齐模型:找出"欢迎" ↔ "Welcome"
- 短语表:存储常见短语翻译
- 语言模型:确保英文句子流畅(如 "to Welcome Beijing" 会被打低分)
- 调序模型:调整词序(中文"北京"在后,英文"Beijing"也在后,但其他语言可能不同)
→ 每个模块单独训练、手工设计、复杂拼接。
✅ 端到端神经机器翻译(NMT,如 Seq2Seq)------端到端
- 输入 :中文词序列
["欢迎", "来", "北京"] - 输出 :英文词序列
["Welcome", "to", "Beijing"] - 中间过程 :一个神经网络(Encoder-Decoder)自动学习如何编码语义、对齐概念、生成语法正确的句子
- 无需 你告诉它"欢迎=Welcome",也无需额外的语言模型
→ 一个模型,搞定全部。
🔑 核心特点
| 特性 | 说明 |
|---|---|
| 输入是原始数据 | 如词序列、像素、语音波形 |
| 输出是最终目标 | 如翻译、分类标签、文本转录 |
| 中间表示自动学习 | 模型自己决定"需要记住什么"、"如何转换" |
| 训练信号直达源头 | 损失函数(如交叉熵)直接反向传播到输入层 |
💡 一句话总结
端到端 = 你只给模型"输入"和"正确答案",它自己学会从头到尾怎么做,不用你拆解步骤。
在 Seq2Seq 中,这意味着:
中文句子进,英文句子出,中间的一切(对齐、语法、词汇选择)都由神经网络隐式学得。
这就是为什么说 Seq2Seq 是"端到端"的------它把复杂的翻译任务,变成了一个单一的、可微的、端到端可训练的函数。
4、训练过程(Teacher Forcing 模型优化方法)
下面是对 不带注意力机制的 Seq2Seq 模型在训练阶段 (Teacher Forcing) 的完整、清晰、无歧义的重新梳理。我们将从数据准备、前向计算到损失计算,一步步讲清楚"为什么能训练""输入是什么""损失怎么算"。
✅ Seq2Seq 训练全流程(以机器翻译为例)
- 准备一对平行句
- 源句(Source) :
["欢迎", "来", "北京", "<eos>"]→ 长度 T = 4 T = 4 T=4 - 目标句(Target) :
["<sos>", "Welcome", "to", "Beijing", ".", "<eos>"]→ 长度 T ′ = 6 T' = 6 T′=6
注意:在训练数据中,目标句人工添加了
<sos>(起始符)和<eos>(结束符),用于标准化 Decoder 的输入与输出边界。
- Encoder 编码源句
-
将源句词嵌入后,逐个输入 Encoder(如 LSTM)
-
Encoder 处理完所有 token(包括
<eos>)后,取最后一个隐藏状态 :
c = h T enc ∈ R d h \mathbf{c} = \mathbf{h}_T^{\text{enc}} \in \mathbb{R}^{d_h} c=hTenc∈Rdh -
这个 c \mathbf{c} c 就是上下文向量,将作为 Decoder 的初始隐藏状态
- Decoder 训练:使用 Teacher Forcing
📌 核心规则:
为了实现"用上一时刻的真实词预测当前词",我们人为构造两个序列:
- Decoder 输入序列 = 目标句去掉最后一个 token
→input_dec = ["<sos>", "Welcome", "to", "Beijing", "."](长度 T ′ − 1 = 5 T' - 1 = 5 T′−1=5) - Decoder 目标序列 = 目标句去掉第一个 token
→target_dec = ["Welcome", "to", "Beijing", ".", "<eos>"](长度 T ′ − 1 = 5 T' - 1 = 5 T′−1=5)
💡 这样,
input_dec[t−1]对应target_dec[t−1]的前一个词,模型在时间步 t t t 的任务是:
基于真实历史 y < t true y_{<t}^{\text{true}} y<ttrue,预测 y t true y_t^{\text{true}} yttrue。
🔁 前向计算(按时间步 t = 1 t = 1 t=1 到 T ′ − 1 T' - 1 T′−1):
| 时间步 t t t | Decoder 输入(来自 input_dect−1) | Decoder 内部状态 | Decoder 实际预测输出(argmax) | 对比目标(target_dect−1) |
|---|---|---|---|---|
| 1 | <sos> |
h 0 = c \mathbf{h}_0 = \mathbf{c} h0=c | "Hi" |
"Welcome" |
| 2 | "Welcome" |
h 1 \mathbf{h}_1 h1 | "in" |
"to" |
| 3 | "to" |
h 2 \mathbf{h}_2 h2 | "Beijing" |
"Beijing" |
| 4 | "Beijing" |
h 3 \mathbf{h}_3 h3 | "!" |
"." |
| 5 | "." |
h 4 \mathbf{h}_4 h4 | <eos> |
<eos> |
✅ 关键:
- 输入始终来自真实目标句(不是模型自己的预测)
- 每一步的预测都与对应位置的真实标签计算损失
- 即使预测错误(如 t=1 输出
"Hi"),损失仍可正常计算
L t = − log P ( y t true ∣ x , y < t true ) \mathcal{L}t = -\log P\big( y_t^{\text{true}} \mid \mathbf{x}, y{<t}^{\text{true}} \big) Lt=−logP(yttrue∣x,y<ttrue) - 总损失通常取平均: L = 1 T ′ − 1 ∑ t = 1 T ′ − 1 L t \mathcal{L} = \frac{1}{T' - 1} \sum_{t=1}^{T' - 1} \mathcal{L}_t L=T′−11t=1∑T′−1Lt > 📌 例如,在 t = 1 t=1 t=1 时,即使模型预测 "Hi",只要知道真实标签是 "Welcome",就能通过 logits 和真实标签计算交叉熵损失,并正常反向传播梯度。
- 损失计算
-
对每个时间步 t = 1 , ... , T ′ − 1 t = 1, \dots, T' - 1 t=1,...,T′−1,计算 交叉熵损失 :
L t = − log P ( y t true ∣ x , y < t true ) \mathcal{L}t = -\log P\big( y_t^{\text{true}} \mid \mathbf{x}, y{<t}^{\text{true}} \big) Lt=−logP(yttrue∣x,y<ttrue) -
总损失通常取平均:
L = 1 T ′ − 1 ∑ t = 1 T ′ − 1 L t \mathcal{L} = \frac{1}{T' - 1} \sum_{t=1}^{T' - 1} \mathcal{L}_t L=T′−11t=1∑T′−1Lt
📌 例如,在 t=1 时,即使模型预测 "Hi",只要知道真实标签是 "Welcome",就能通过 logits 计算交叉熵损失,并反向传播梯度。
- 反向传播与参数更新
- 损失 L \mathcal{L} L 对 整个网络(Encoder + Decoder)求梯度
- 使用优化器(如 Adam)更新所有可训练参数
- 下一个 batch 重复此过程
- 为什么叫 "Teacher Forcing"?
- "老师"(即训练数据中的真实序列)强制提供正确的上一词作为输入
- 防止模型因早期预测错误而导致后续步骤完全偏离
- 相当于:"先学会在正确引导下生成句子,再尝试自主生成"
✅ 总结:训练阶段的关键事实
| 问题 | 答案 |
|---|---|
| Decoder 输入是什么? | 目标句的 前 T ′ − 1 T' - 1 T′−1 个 token (含 <sos>,不含 <eos>) |
| 损失和谁比? | 模型在每步的输出 vs 目标句的 后 T ′ − 1 T' - 1 T′−1 个 token (不含 <sos>,含 <eos>) |
| 需要模型自己生成词吗? | ❌ 不需要!训练时输入完全由真实标签提供 |
| 能计算损失吗? | ✅ 能!每一步都有明确的真实标签作为监督信号 |
| c \mathbf{c} c 在训练中怎么用? | 仅用于初始化 Decoder 的隐藏状态,之后不再显式使用 |
现在你已经彻底明白:Seq2Seq 的训练是完全可行且高效的------它通过 Teacher Forcing 提供稳定监督,通过对齐输入/目标序列实现逐词损失计算,从而端到端地训练整个 Encoder-Decoder 系统。
5、Scheduled Sampling(计划采样)
Scheduled Sampling(计划采样) 是 Teacher Forcing 的一种动态混合策略。
✅ 正确名称:Scheduled Sampling
Scheduled Sampling 是一种在训练过程中以一定概率混合使用真实目标词与模型自身预测词作为解码器输入 的策略,最早由 Bengio 等人在 2015 年提出(论文:Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks)。
python
is_use_tf = True if random.random() < 0.5 else False这属于 固定概率的 Scheduled Sampling(Fixed-Rate Scheduled Sampling) ------ 每次训练 step 以 50% 概率使用真实标签(Teacher Forcing),50% 概率使用模型上一时刻的预测(Free Running)。
💡 注意:Scheduled Sampling 不必然"逐渐过渡";"衰减式"只是其一种调度策略,固定概率同样有效。
🔍 它有什么用?
-
缓解 Exposure Bias(暴露偏差)
- 问题:纯 Teacher Forcing 训练时,解码器始终看到"正确的前序词";但推理时只能依赖"自己预测的前序词"。训练与推理的输入分布不一致 → 模型一旦早期出错,错误会级联放大。
- 解决 :Scheduled Sampling 让模型在训练中偶尔暴露于自己的预测结果,提升对错误输入的鲁棒性。
-
平滑训练到推理的行为差异
- 相比"训练全用 Teacher Forcing,推理突然切换到自生成",Scheduled Sampling 提供了更自然的过渡,减少行为突变。
-
提升长序列生成质量
- 在机器翻译、文本摘要等任务中,适当使用可减少重复、断裂等问题,提高生成流畅性。
📈 更高级的变体:衰减式 Scheduled Sampling
虽然你可以使用固定概率(如 0.5),但更常见的做法是让 Teacher Forcing 概率随训练进程衰减:
python
# 例如:随着 epoch 增加,逐渐减少 Teacher Forcing 的使用
teacher_forcing_ratio = max(0.0, 1.0 - epoch * 0.05) # 线性衰减,下限为 0
use_teacher_forcing = random.random() < teacher_forcing_ratio这样:
- 早期:高概率使用真实标签 → 利于快速收敛;
- 后期:低概率使用真实标签 → 更接近推理模式。
⚠️ 注意事项
-
并非在所有任务中都有效:在语音识别、短句翻译等任务中,Teacher Forcing 已足够稳定,Scheduled Sampling 反而可能引入噪声,导致训练不稳定或性能下降。
-
实现细节 :当
is_use_tf=False时,你需要:- 从 logits 中通过
argmax或采样得到预测词(离散 token),即用torch.argmax(logits, dim=-1)或采样得到预测词;; - 将其作为下一时间步的输入。
- 注意:该路径不参与梯度回传(因离散操作不可微),这是正常现象,称为 "非可微采样" 或 "梯度截断"(后面有详情)
- 从 logits 中通过
✅ 总结对比
| 策略 | 输入来源 | 特点 |
|---|---|---|
| Pure Teacher Forcing | 始终使用真实目标词 | 训练稳定、收敛快,但存在 Exposure Bias |
| Pure Free Running | 始终使用模型上一时刻的预测 | 接近推理行为,但训练困难、易发散 |
| Scheduled Sampling | 按概率混合上述两种方式 | 平衡训练稳定性与推理鲁棒性 |
6、非可微采样与梯度截断
📚 知识点整理:非可微采样与梯度截断(在 Seq2Seq 解码中的应用)
🔹 1. 核心现象
"注意:该路径不参与梯度回传(因离散操作不可微),这是正常现象,称为 '非可微采样' 或 '梯度截断'。"
当你在训练解码器时使用模型自身预测的词 (如通过 argmax 或 topk 选择最可能的 token)作为下一步输入(即非 Teacher Forcing 模式),这条"预测 → 输入"的路径不会将梯度反向传播回之前的网络层。
🔹 2. 通俗解释(为什么?)
在神经网络训练中,梯度必须能从损失函数连续地反向流经每一个参与计算的参数,才能实现有效更新。
但"选词"是一个离散决策过程:
- 比如从 logits
[2.1, -0.5, 3.0]中选出索引2(对应概率最高的词); - 这个
argmax操作是跳跃式、非连续、不可导的。
🌄 比喻理解 :
你在山坡上找最低点(优化目标)。
- 如果每一步都能算出"往哪走坡度最陡"(可微操作),你就能顺利下滑;
- 但如果某一步变成"掷骰子决定方向"(离散选择),你就无法知道"刚才那个骰子结果是因为哪个参数导致的"------梯度在这里断了。
因此:
- 从"预测词"到"生成该预测的 logits"之间没有梯度通路;
- 当这个预测词被用作下一时间步的输入时,该输入被视为"常量",不携带梯度信息。
🔹 3. 技术本质
不可微操作
argmax,topk,sample from categorical等离散选择操作在数学上没有定义导数。
梯度截断(Gradient Stopping)
- 自动微分框架(如 PyTorch)在遇到不可微操作时,自动切断反向传播路径,不会报错,而是静默停止。
.detach() 的作用
-
显式地将张量从计算图中分离,确保其不参与梯度计算。但在
topi = argmax(logits)的情况下,topi本就不在计算图中 ,所以.detach()是冗余但安全的操作。 -
示例验证:
pythontopv, topi = torch.topk(logits, 1) print(topi.requires_grad) # False print(topi.grad_fn) # None → 不在计算图中
术语
- 这种做法被称为 "非可微采样"(Non-differentiable Sampling) 或 "梯度截断输入"(Detached Input)。
🔹 4. 对训练的实际影响
| 方面 | 影响 |
|---|---|
| ✅ 当前时间步训练 | 不受影响。损失函数直接作用于当前 logits,梯度可正常回传至当前解码器参数(甚至编码器,若共享状态)。 |
| ⚠️ 历史预测路径 | 无梯度反馈 。模型无法学习"如果我之前选了另一个词,后续会不会更好"------即缺乏长期信用分配(credit assignment)能力。 |
| 🔁 Scheduled Sampling 的局限性 | 这是 Scheduled Sampling(或自回归训练 without Teacher Forcing)的一个固有缺陷:训练信号只来自"当前预测是否正确",而非"整个生成序列的质量"。 |
| 💡 替代方案(进阶) | 若需让采样路径传递梯度,可使用:• Gumbel-Softmax (可微近似采样)• REINFORCE / Policy Gradient(强化学习)但这些方法更复杂,且各有假设与噪声问题。 |
🔹 5. 最佳实践建议
-
保留
.detach():虽然当前无实质影响,但它是明确意图、防御未来变更的良好习惯。pythondecoder_input = topi.detach() # ✅ 清晰表达"此输入不参与梯度回传" -
理解其必要性 :在标准交叉熵训练中,不需要梯度通过预测词回传,因为监督信号已由真实标签提供(Teacher Forcing 主导)。
-
警惕混合模式:在 Scheduled Sampling 中,部分样本用真实标签(有梯度),部分用预测词(无梯度),需意识到两者训练信号强度不同。
🔚 一句话总结(金句版)
当你用模型自己的预测词作为下一步输入时,由于"选词"是离散操作,梯度无法通过这个输入回传到更早的网络部分------这叫"梯度截断",是 Scheduled Sampling 中的正常现象,不影响当前步的训练,但限制了模型对长期序列质量的感知能力。
7、Teacher Forcing 作用于时间步还是整个句子
✅ 核心答案:
Teacher Forcing 是按「时间步」(token)决定的,不是按「整个句子」决定的。
但在标准实现中,通常对一个训练样本(即一个句子)的所有时间步统一使用或不使用 Teacher Forcing ------ 这是工程惯例,而非方法本质。
🔍 分层次解释
- 方法本质:可以逐时间步独立决定
从理论和计算图角度看,每个时间步 t 都可以独立选择:
- 输入 = 真实目标词
y_{t-1}(Teacher Forcing) - 或输入 = 模型上一时刻预测
ŷ_{t-1}(Free Running)
例如:
text
时间步: t=1 t=2 t=3 t=4
输入: <SOS> y₁ (TF) ŷ₂ (FR) y₃ (TF)这是完全合法的!PyTorch 的自动微分系统会为每个时间步分别构建计算路径。
- 实际训练中的常见做法:按样本统一策略
尽管可以逐 token 混合,但绝大多数代码实现(包括教科书、论文复现)对同一个句子的所有时间步采用相同的策略:
- 要么整句用 Teacher Forcing(最常见)
- 要么整句用 Scheduled Sampling 的混合逻辑 (如你之前写的
is_use_tf = random() < 0.5,然后整句按此布尔值执行)
✅ 为什么这么做?
- 实现简单:只需在解码循环外判断一次;
- 训练稳定:避免同一序列内行为剧烈切换;
- 调度清晰:便于实现"衰减式"Scheduled Sampling(如按 epoch 调整整句的 TF 概率)。
- Scheduled Sampling 的典型实现方式
写法:
python
is_use_tf = random.random() < teacher_forcing_ratio
for t in range(1, tgt_len):
if is_use_tf:
input_token = tgt[:, t-1] # 整句用真实词
else:
input_token = predicted_token # 整句用预测词👉 这就是按样本(句子)决定策略 ,不是逐 token 决定。
📌 注意:也有少数研究尝试逐时间步独立采样(每个 t 单独掷骰子),但这会增加训练噪声,一般不作为默认做法。
🧪 举个对比例子
假设目标句子是 [A, B, C, D](忽略起始/结束符):
| 策略 | 时间步输入序列 |
|---|---|
| 纯 Teacher Forcing | <SOS> → A → B → C |
| 纯 Free Running | <SOS> → ŷ₁ → ŷ₂ → ŷ₃ |
| 按句子混合 | 若 is_use_tf=True:<SOS> → A → B → C若 is_use_tf=False:<SOS> → ŷ₁ → ŷ₂ → ŷ₃ |
| 逐 token 混合(少见) | <SOS> → A → ŷ₂ → C(每个 t 独立决定) |
⚠️ 重要提醒:不要混淆"策略粒度"与"损失计算"
无论用哪种输入策略,每个时间步的 loss 都是独立计算的:
python
total_loss = loss₁ + loss₂ + loss₃ + loss₄- 即使你在 t=3 用了预测词
ŷ₂,loss₃仍然基于logits₃和真实标签C计算; - 梯度依然能正常回传到 t=3 的解码器和编码器(只是不能通过
ŷ₂回传到 t=2 的 logits)。
✅ 总结
| 问题 | 答案 |
|---|---|
| Teacher Forcing 能否只用于部分时间步? | ✅ 理论上可以,计算图支持 |
| 实际中是否这样做? | ❌ 通常不对同一句子混合使用;而是整句统一用 TF 或整句用 FR(或按 Scheduled Sampling 的全局开关) |
Scheduled Sampling 中的 is_use_tf 作用范围? |
一般是整个目标序列,不是单个 token |
所以你之前的理解是正确的:
is_use_tf控制的是当前这个训练样本(句子)是否全程使用 Teacher Forcing。
8、什么时候添加EOS:训练时添加到目标句末尾
🧩 全面解析:什么时候添加 <EOS>?
核心原则 :
<EOS>(End-of-Sequence)是一个特殊的控制 token,它的唯一作用是让模型学会"何时停止生成"。它不是自然语言的一部分,而是一种建模技巧------将"终止决策"转化为一个可学习的分类目标。
一、根本目的:为什么需要 <EOS>?
在序列生成任务(如机器翻译、文本摘要、对话生成)中,输出长度是未知且可变的。这带来一个关键挑战:
模型如何知道"一句话已经说完了"?
如果没有明确信号:
- 模型可能无限生成(如重复 "." 或 "the the the...");
- 或者只能依赖硬性截断(如
MAX_LENGTH=50),但这会截断长句或浪费短句的计算资源。
因此,引入 <EOS> 的根本目的是:
✅ 将"是否结束生成"这一决策,编码为一个标准的 token 预测任务,从而让模型通过监督学习自动掌握终止时机。
换句话说:模型不仅要学会"说什么",还要学会"什么时候说完"。
二、训练阶段:由人类(数据预处理)添加 <EOS>
✅ 1. 谁添加?
- 你(开发者/数据准备者),在构建训练数据时手动添加。
- 通常在
Dataset类的__getitem__方法中完成,或在数据清洗脚本中处理。
✅ 2. 添加位置?
-
加在每条目标序列(target sequence)的末尾,即最后一个自然语言词之后。
-
示例:
text原始目标句: "je vais bien ." 训练用目标序列: ["je", "vais", "bien", ".", "<EOS>"]
✅ 3. 为什么必须加?
- 提供监督信号 :模型在第 t 步的输出应与第 t 个目标 token 对齐。
- 当输入英文
"I'm ok.", - 模型第 1 步应预测
"je", - 第 2 步预测
"vais", - ...
- 最后一步应预测
<EOS>。
- 当输入英文
- 如果不加
<EOS>,模型就永远学不会"结束"这个动作,因为它从未被要求预测它。
✅ 4. 是否也加 <SOS>?
-
通常不在目标序列开头加
<SOS>(尽管有些框架会这么做)。 -
更常见的做法是:
- 解码器初始输入 =
<SOS>(作为起始信号), - 目标序列 = 真实句子 +
<EOS>(不含<SOS>)。
- 解码器初始输入 =
-
这样,输入和目标在时间步上对齐:
解码器输入: [<SOS>, je, vais, bien, . ] 目标输出: [je, vais, bien, ., <EOS>]
🔍 这种"错位对齐"是 Seq2Seq 的标准训练方式,称为 teacher forcing with shifted targets。
三、预测阶段(推理):由模型自己生成 <EOS>
✅ 1. 谁生成?
- 模型自己,在自回归(auto-regressive)生成过程中逐步预测。
✅ 2. 生成过程如何工作?
- 输入源句子 → 编码器 → 得到上下文表示。
- 解码器初始输入 =
<SOS>。 - 循环:
- 模型基于当前输入和历史状态,输出下一个 token 的概率分布;
- 选择最可能的 token(如 argmax 或采样);
- 如果该 token 是
<EOS>,则终止生成; - 否则,将其加入输出列表,并作为下一步输入。
- 最终输出 = 所有非
<EOS>token 组成的序列。
✅ 3. <EOS> 是否出现在最终结果中?
- 绝对不出现。
<EOS>仅作为内部终止信号 ,类似程序中的break语句。- 用户看到的翻译结果必须是干净的自然语言。
✅ 4. 如果模型一直不生成 <EOS> 怎么办?
- 这是实际系统中必须处理的问题。
- 解决方案:设置 最大生成长度(
MAX_LENGTH) 作为安全兜底。- 即使未遇到
<EOS>,达到MAX_LENGTH也强制停止。
- 即使未遇到
- 注意:
MAX_LENGTH是工程保障 ,而<EOS>是语义终止 。理想情况下,模型应在合理长度内输出<EOS>。
四、对比总结:训练 vs 预测
| 维度 | 训练阶段 | 预测阶段 |
|---|---|---|
<EOS> 来源 |
人工添加到目标序列末尾 | 模型自主预测输出 |
| 谁负责添加 | 数据预处理代码(你) | 模型(神经网络) |
| 是否参与损失计算 | 是(作为目标 token 之一) | 否(仅用于触发终止) |
| 是否出现在最终输出 | 否(训练时不展示) | 否(预测后立即丢弃) |
| 目的 | 教模型"何时该停" | 让模型"自己决定停" |
依赖 <SOS> 吗? |
是(通常作为解码器初始输入) | 是(启动生成过程) |
五、常见误区澄清
❌ 误区 1: "预测时我也要给目标句加 <EOS>"
- 错误 !预测时没有"目标句",只有源句。
<EOS>是模型生成的结果,不是输入。
❌ 误区 2: "<EOS> 就是句号 .,所以可以省略"
- 错误 !句号是语言内容,
<EOS>是控制信号。- 有些句子没有句号(如标题、短语);
- 有些句子有多个句号(如省略号 "...");
<EOS>表示"整个输出结束",与标点无关。
❌ 误区 3: "只要设了 MAX_LENGTH,就不需要 <EOS>"
- 不推荐 !
MAX_LENGTH是硬截断,可能导致句子不完整;<EOS>让模型具备语义感知的终止能力,更智能、更高效。
❌ 误区 4: "模型输出 <EOS> 后,我还继续生成几个词"
- 错误 !一旦检测到
<EOS>,必须立即停止。否则会生成无意义后缀。
六、工程实现要点(供参考)
✅ 训练时(数据准备):
python
# 在 Dataset 中
target_tokens = sentence.split()
target_ids = [word2id[w] for w in target_tokens]
target_ids.append(EOS_ID) # ← 关键:人工添加 EOS✅ 预测时(推理循环):
python
output_ids = []
input_token = SOS_ID
for step in range(MAX_LENGTH):
next_id = model.predict(input_token)
if next_id == EOS_ID:
break # ← 遇到 EOS,立即停止
output_ids.append(next_id)
input_token = next_id
# 最终结果:output_ids(不含 EOS)七、延伸思考:其他终止机制?
虽然 <EOS> 是主流方案,但也有替代思路(供进阶了解):
- 隐式终止:某些模型(如 RNN)通过隐藏状态衰减自然停止,但不可控。
- 强化学习奖励:用 RL 训练模型在合适时机停止,但复杂度高。
- 长度预测头:额外预测句子长度,然后生成固定数量词------但灵活性差。
✅ 结论:
<EOS>仍是目前最简单、有效、通用的标准做法。
✅ 终极总结(一句话 + 三要点)
<EOS>只在训练时由人加到目标句尾,教模型"说完要喊停";预测时由模型自己喊"停"(输出<EOS>),我们听到就收工------但"停"字绝不写进答案里。
三个必须记住的要点:
- 训练加,预测不加(由模型生成);
- 生成即停,绝不保留;
- 它是动作,不是词语。
9、什么时候添加SOS:看当前 token 是"输入"还是"目标"
📘 Seq2Seq 解码器训练:输入 vs 目标的本质区别
核心问题 :在训练自回归解码器时,当前遍历的 token 到底是"输入"还是"目标"?
这是理解 Seq2Seq 训练机制的关键!
🧩 共同前提
我们要训练一个 Seq2Seq 解码器,让它学会生成法语句子。
- 真实句子内容 :
[7, 6](例如"je","vais") - 期望模型输出 :
7 → 6 → <EOS>,从<SOS>开始
因此,正确的学习任务是:
| 时间步 | 解码器输入 | 模型应预测的目标 |
|---|---|---|
| t=0 | <SOS> (0) |
7 |
| t=1 | 7 | 6 |
| t=2 | 6 | <EOS> (1) |
✅ 总共 3 个预测步骤 ,输出 3 个 token :7, 6, 1
❌ 不需要预测 "<EOS> 之后是什么"
✅ 方法一:Dataset 不包含 <SOS>(推荐标准做法)
- Dataset 存什么?
python
target = [7, 6, 1] # 内容 + <EOS>,不含 <SOS>👉 这个列表就是模型要"预测出来"的全部内容。
- 训练逻辑【重点】
python
decoder_input = torch.tensor([[special_tokens['START_OF_SENTENCE']]]) # 手动设为 <SOS>
for i in range(len(target)): # i = 0, 1, 2 (共3次)
logits = decoder(decoder_input, ...)
y = target[i] # ← 当前遍历的是【目标】!
loss += criterion(logits, y)
# Teacher Forcing:下一输入 = 真实目标
decoder_input = torch.tensor([[y]])- 关键对应关系
循环变量 i |
decoder_input(输入) |
target[i](目标) |
|---|---|---|
| 0 | 0 (<SOS>) |
7 |
| 1 | 7 | 6 |
| 2 | 6 | 1 (<EOS>) |
✅ 当前遍历的 token 是【目标】
✅ 输入来自上一步(初始为手动设置的 <SOS>)
✅ 方法二:Dataset 包含 <SOS> 和 <EOS>
- Dataset 存什么?
python
full_seq = [0, 7, 6, 1] # <SOS>, 内容, <EOS>👉 这是一个完整序列 ,但不能直接用作 "目标" !因为当前 token 是 "输入"
⚠️ 关键原则 :
<SOS>是控制信号,不是模型要输出的内容;<EOS>是最后一个输出,不应再作为输入。
- 正确训练逻辑【重点】
python
# 注意:只循环到倒数第一个(因为 <EOS> 不作为输入)
for i in range(len(full_seq) - 1): # i = 0, 1, 2 (共3次)
decoder_input = torch.tensor([[full_seq[i]]]) # ← 当前遍历的是【输入】!
y = full_seq[i + 1] # ← 目标是【下一个 token】!
logits = decoder(decoder_input, ...)
loss += criterion(logits, torch.tensor([y]))- 关键对应关系
循环变量 i |
full_seq[i](输入) |
full_seq[i+1](目标) |
|---|---|---|
| 0 | 0 (<SOS>) |
7 |
| 1 | 7 | 6 |
| 2 | 6 | 1 (<EOS>) |
✅ 当前遍历的 token 是【输入】
✅ 目标是序列中的下一个 token
❌ 错误示例:方法二 + 遍历整个序列(4 次)
场景
python
full_seq = [0, 7, 6, 1] # <SOS>, je, vais, <EOS>
# ❌ 错误:遍历整个序列(4 次)
for i in range(len(full_seq)): # i = 0, 1, 2, 3
decoder_input = full_seq[i] # 当前 token 作为【输入】
target = full_seq[i + 1] # ← 试图取下一个作为【目标】逐步分析
| i | 输入 (full_seq[i]) |
目标 (full_seq[i+1]) |
结果 |
|---|---|---|---|
| 0 | 0 (<SOS>) |
7 | ✅ 合理 |
| 1 | 7 | 6 | ✅ 合理 |
| 2 | 6 | 1 (<EOS>) |
✅ 合理 |
| 3 | 1 (<EOS>) |
full_seq[4] → ??? |
💥 IndexError: list index out of range |
根本原因 :
<EOS>是句子终点,没有"下一个 token",因此不能作为输入去预测后续内容。
❌ 更隐蔽的错误:用当前 token 作目标
python
# ❌ 错误:把当前 token 同时当输入和目标
for i in range(len(full_seq)):
decoder_input = full_seq[i]
target = full_seq[i] # ← 逻辑错位!训练过程变成:
| i | 输入 | 目标 | 模型学到什么? |
|---|---|---|---|
| 0 | 0 (<SOS>) |
0 (<SOS>) |
"看到 ? → 输出 <SOS>" ❌ |
| 1 | 7 | 7 | "看到 ? → 输出 7" ❌ |
| 2 | 6 | 6 | "看到 ? → 输出 6" ❌ |
| 3 | 1 (<EOS>) |
1 (<EOS>) |
"看到 ? → 输出 <EOS>" ❌ |
→ 模型学会 "复制输入" ,而非 "预测下一个词",完全违背自回归建模原理。
🎯 关键结论
| 问题 | 答案 |
|---|---|
为什么不能遍历整个 full_seq? |
因为最后一个 token 是 <EOS>,它只能作为目标 ,不能作为输入去预测下一个词(句子已结束) |
| 遍历到最后一个时会发生什么? | 要么 索引越界 (如果取 i+1),要么 监督信号错位 (如果直接用 full_seq[i] 作目标) |
| 当前遍历的 token 在方法二中是什么? | 是输入(input) ,不是目标!目标必须是 下一个 token |
| 正确循环次数是多少? | len(full_seq) - 1 |
💡 记忆口诀
"输入看当前,目标看下一个;
最后一个<EOS>,只配当目标,不当输入!"
🔑 核心对比表
| 项目 | 方法一(推荐) | 方法二(可行) |
|---|---|---|
| Dataset 内容 | [7, 6, 1](目标序列) |
[0, 7, 6, 1](完整序列) |
| 当前遍历的 token 是 | 目标(label) | 输入(input) |
| "目标"如何获取 | target[i] |
full_seq[i + 1] |
| 输入如何获取 | 初始手动设 <SOS>,后续用 target[i](Teacher Forcing) |
full_seq[i] |
| 循环次数 | len(target) |
len(full_seq) - 1 |
| 是否需要切片 | 否 | 否(但需 i+1) |
| 易错点 | 几乎没有 | 容易忘记 -1 或误用 full_seq[i] 作目标 |
| 是否主流 | ✅ 是(PyTorch / TensorFlow / HuggingFace 默认) | ⚠️ 少见 |
✅ 结论与建议
- 两种方法在数学上完全等价,都能正确训练模型。
- 关键区别在于对 Dataset 的语义理解 :
- 方法一:Dataset = "模型应输出的内容"
- 方法二:Dataset = "完整生成序列(含控制符)"
- 方法一更清晰、安全、主流 :
- 语义明确,不易出错
- 无需处理
i+1或边界越界 - 与工业界标准一致
- 方法二可用,但必须严格遵守 :
- 循环
n - 1次 - 输入 =
seq[i] - 目标 =
seq[i + 1]
- 循环
❤️ 最后总结
"当前遍历的 token 到底是输入还是目标?"
这正是理解自回归语言建模(Autoregressive Modeling)的核心!
很多教程对此一笔带过,导致初学者混淆。
无论选择哪种方法,只要明确输入与目标的对应关系,就能写出正确、高效的训练代码。
10、预测过程
非常好的问题!在训练阶段,我们依赖真实标签(Teacher Forcing)来提供 Decoder 的输入;但在预测(推理 / inference)阶段 ,模型必须完全靠自己生成整个目标序列------因为真实翻译是未知的。
下面是对 不带注意力机制的 Seq2Seq 模型在推理阶段(预测过程) 的完整、清晰、逐步讲解。
✅ Seq2Seq 预测(Inference)全流程
- 输入只有源句
- 给定:源语言句子,如
["欢迎", "来", "北京", "<eos>"] - 没有目标句 !唯一可用的目标端 token 是起始符
<sos>(由系统预定义)
- Encoder 编码源句 → 得到上下文向量 c
与训练完全相同:
-
将源句嵌入并输入 Encoder(LSTM/GRU)
-
取最后一个隐藏状态作为上下文向量:
c = h T enc \mathbf{c} = \mathbf{h}_T^{\text{enc}} c=hTenc
- Decoder 自主生成目标序列(逐步进行)
📌 核心规则:
- 起始输入 :固定 token
<sos> - 后续输入 :上一步模型自己预测出的词(通过 argmax 或采样得到)
- 终止条件 :生成
<eos>或达到预设最大长度(如 50)
❗ 注意:每一步的输入都来自模型自身的历史预测,错误一旦发生就会传递下去(称为"误差累积"或 exposure bias)。
🔁 预测步骤详解(以中文 → 英文为例)
| 时间步 t t t | Decoder 输入 | Decoder 状态 | 模型输出(预测词) | 动作 |
|---|---|---|---|---|
| 1 | <sos> |
h 0 = c \mathbf{h}_0 = \mathbf{c} h0=c | "Hi" |
加入输出序列 |
| 2 | "Hi" |
h 1 \mathbf{h}_1 h1(基于 "Hi" 和 h 0 \mathbf{h}_0 h0) |
"to" |
继续生成 |
| 3 | "to" |
h 2 \mathbf{h}_2 h2 | "New" |
... |
| 4 | "New" |
h 3 \mathbf{h}_3 h3 | "York" |
... |
| 5 | "York" |
h 4 \mathbf{h}_4 h4 | "." |
... |
| 6 | "." |
h 5 \mathbf{h}_5 h5 | <eos> |
停止!返回结果 |
最终输出:["Hi", "to", "New", "York", "."] → 这是模型在无外部监督 下的自主生成结果(注意:这不是"无监督学习",而是自回归生成)。
💡 实际中,我们会用:
- 贪心搜索(每步取概率最高的词),或
- 束搜索 (beam search,保留多个候选路径)
来提升生成质量。
- 关键特点 vs 训练阶段
| 方面 | 训练(Teacher Forcing) | 推理(Autoregressive Generation) |
|---|---|---|
| Decoder 输入来源 | 真实目标句(ground truth) | 模型自己上一步的预测 |
| 是否需要目标句 | ✅ 需要(用于监督) | ❌ 不需要 |
| 能否并行计算 | ✅ 可批量处理(因输入已知) | ❌ 必须串行(每步依赖前一步) |
| 错误影响 | 局部(不影响下一步输入) | 全局(错误会累积) |
| 速度 | 快 | 慢(逐词生成) |
- 为什么叫 "自回归"(Autoregressive)?
- 因为模型用自己生成的历史作为未来输入 ,形成递归生成过程:
y t = arg max w ∈ V P ( w ∣ x , y 1 , y 2 , ... , y t − 1 ) y_t = \underset{w \in \mathcal{V}}{\arg\max} \; P(w \mid \mathbf{x}, y_1, y_2, \dots, y_{t-1}) yt=w∈VargmaxP(w∣x,y1,y2,...,yt−1)
其中 V \mathcal{V} V 是目标词表。
- 实际工程中的优化:束搜索(Beam Search)
- 贪心搜索容易陷入局部最优(如选了高概率但语义不通的词)
- 束搜索 :维护 top- k k k 个最可能的部分序列(如 k = 3 k=3 k=3)
- 每步扩展每个候选,重新排序,保留 top- k k k
- 最终选择总得分最高的完整序列
- 这能显著提升翻译质量,是 Seq2Seq 推理的标准做法。
✅ 总结:推理阶段的关键事实
| 问题 | 答案 |
|---|---|
| 输入是什么? | 仅源句 + <sos>(系统预定义) |
| Decoder 每步输入什么? | 上一步自己预测的词 |
| 何时停止? | 生成 <eos> 或达到最大长度 |
| 能并行吗? | ❌ 不能,必须逐词生成 |
| 主要风险? | 误差累积(早期错 → 后面全偏) |
| 如何提升质量? | 使用 束搜索(beam search)代替贪心 |
🔄 对比记忆口诀:
训练时:老师喂饭(真实词输入),只管好好答(预测下一个)
推理时:自己做饭(用自己输出当输入),错一步可能糊一锅
现在你已经完整掌握了 Seq2Seq 的训练 与推理 全过程。这也解释了为什么后来出现了注意力机制 和Transformer------它们不仅缓解了信息瓶颈,还通过更灵活的上下文建模减轻了误差累积问题。
11、什么时候判断EOS结束:推理阶段才需要
📘 Seq2Seq 训练中的关键原则:
不要在训练时因 <EOS> 提前终止!
💡 核心思想 :
训练的目标是教会模型"在每个位置都正确预测",而不是"尽早结束任务"。
✅ 正确行为对比表
| 场景 | 是否检测 <EOS> 并 break? |
原因 |
|---|---|---|
| 训练(Training) | ❌ 不要! 必须遍历完整目标序列 | 确保每个时间步都有损失信号,防止模型"偷懒"过早结束 |
| 推理(Inference / Generation) | ✅ 要! 遇到 <EOS> 立即停止 |
模拟真实生成过程,避免无限输出 |
🔍 为什么训练时不能提前终止?
- 训练目标 ≠ 推理目标
- 训练目标 :最小化 每个时间步 的预测误差,强制模型对齐完整的 ground truth 序列。
- 推理目标 :自主生成一个语义完整、以
<EOS>结尾的句子,长度由模型决定。
📌 在训练中,你拥有完整的标签序列(如
[7, 12, 322, 1]),必须为每一个位置计算 loss,无论模型当前预测是什么。
- 提前终止的危害
假设真实法语句子为:["Je", "suis", "étudiant", "<EOS>"](目标序列长度 = 4)
❌ 错误做法(训练中遇到 <EOS> 就 break):
- 模型在第 2 步预测出
<EOS> - 循环提前退出 → 只计算了前 2 个时间步的 loss
- 后果 :
- 第 3、4 步(对应
"étudiant"和<EOS>)完全没有梯度信号; - 模型无法学习长句结构;
- 模型学会"只要输出
<EOS>就能跳过后续 loss" → 倾向于生成过短句子 (称为 premature termination)。
- 第 3、4 步(对应
✅ 正确做法(强制走完所有时间步):
- 即使模型在第 2 步就输出
<EOS>, - 仍继续执行第 3、4 步的前向和 loss 计算(目标分别是
"étudiant"和<EOS>); - 迫使模型理解 :"只有在正确位置 输出
<EOS>才能最小化总 loss"。
⚠️ 注意:第 3 步的真实标签是
"étudiant"(不是<EOS>)!如果提前终止,模型永远学不到这一点。
- 适用于所有训练模式
无论是否使用 Teacher Forcing(TF),训练循环都必须覆盖整个目标序列长度:
- 使用 TF:每一步的输入是 ground truth token,天然走完全程;
- 不使用 TF :输入是模型上一步的预测,但仍需继续计算后续所有时间步的 loss ,即使预测已偏离或提前输出
<EOS>。
🧠 关键认知:训练是监督学习,不是自由生成。模型没有"决定何时结束"的权利------它必须被监督到序列末尾。
🛠 代码实践建议
❌ 错误写法(训练中因 <EOS> 提前 break)
python
for i in range(target_seq_len): # target_seq_len = ground truth 长度
logits = decoder(...)
loss += criterion(logits, target[i])
if not use_teacher_forcing:
pred = logits.argmax(-1)
if pred.item() == EOS_TOKEN:
break # ⚠️ 严重错误!导致后续 loss 缺失✅ 正确写法(训练中永不 break)
python
for i in range(target_seq_len): # 固定循环:目标序列的真实长度
logits = decoder(decoder_input, ...)
loss += criterion(logits, target[i]) # 总是计算当前步 loss
# 准备下一步输入
if use_teacher_forcing:
decoder_input = target[i].unsqueeze(0) # 使用真实标签
else:
decoder_input = logits.argmax(-1).detach() # 使用预测值(注意 .detach())
# ⚠️ 无 break!即使预测出 <EOS>,也继续后续步骤✅
target_seq_len由数据决定(如fran_sen.size(1)),与模型预测无关。
🧪 推理阶段才需要 <EOS> 检测
在生成函数(如 translate() 或 generate())中:
python
output = []
input_token = SOS_TOKEN
while len(output) < max_len:
logits = decoder(input_token, ...)
pred = logits.argmax(-1).item()
if pred == EOS_TOKEN:
break
output.append(pred)
input_token = pred
# 返回 output✅ 这才是 <EOS> 终止逻辑的正确使用场景 :模型自主决定何时结束。
📌 总结口诀
训练走全程,loss 全算清;
推理遇<EOS>,立刻就停行。
❤️ 为什么这个坑很常见?
- 初学者容易将推理逻辑 ("看到
<EOS>就停")错误地套用到训练循环中; - 直觉上认为"模型都说结束了,还训啥?";
- 但实际上,训练是强监督过程,必须覆盖全部标注位置。
你已经意识到这个问题,说明你对 Seq2Seq 的训练机制有了深刻理解!👏
✅ 记住:训练时,模型没有"自由意志"------它必须被强迫走完每一步,接受每一处监督。
12、预测时,什么时候结束:最大长度 or EOS
✅ 问题核心:
在自回归(auto-regressive)解码过程中,模型如何知道何时停止生成下一个词?
📌 对应知识点整理
- 特殊结束标记(End-of-Sequence Token, EOS)
- 在训练和预测阶段,目标语言句子末尾都会显式添加一个特殊的
<EOS>(在本代码中为END_OF_SENTENCE) 标记。 - 预测时 :一旦模型生成了
<EOS>token,就立即停止解码 ,且不将<EOS>包含在最终输出句子中。
✅ 这是最常用、最标准的终止条件。
在你的代码中:
python
special_tokens = {'START_OF_SENTENCE': 0, 'END_OF_SENTENCE': 1, 'UNK': 2}-
END_OF_SENTENCE(值为 1)就是<EOS>标记。 -
训练时,
MyDataset.__getitem__显式在法语句尾添加了它:pythonfran_sentence.append(special_tokens['END_OF_SENTENCE'])
- 最大长度限制(Max Length / MAX_LENGTH)
- 为防止模型陷入无限循环(例如未学会生成
<EOS>,或反复生成无意义词),需设置最大生成长度。 - 即使未遇到
<EOS>,一旦生成的 token 数达到MAX_LENGTH,也强制停止。
在代码中已定义:
python
MAX_LENGTH = 10 # 每个句子的最大长度(不含 <SOS> 和 <EOS>)💡 注意:
MAX_LENGTH通常指目标句子内容的最大长度 ,不包括<SOS>(仅作输入)和<EOS>(仅作终止信号)。
- 预测流程(自回归生成)
预测时的典型步骤如下:
- 将源语言句子输入编码器,得到上下文表示(如所有隐藏状态和最终隐藏状态)。
- 解码器初始输入为
<SOS>(即START_OF_SENTENCE),初始隐藏状态通常来自编码器。 - 循环执行以下步骤,直到满足终止条件:
- 模型基于当前输入和隐藏状态,输出下一个 token 的 logits;
- 选择概率最高的 token(或通过采样)作为当前预测结果;
- 若该 token 是
<EOS>,则终止生成; - 否则,将该 token 加入输出列表,并作为下一步的输入;
- 同时检查是否已生成
MAX_LENGTH个 token,若是则强制终止。
- 最终输出为
<EOS>之前的所有 token 组成的序列。
- 与训练阶段的区别
| 阶段 | 输入方式 | 终止条件 | 是否使用真实标签 |
|---|---|---|---|
| 训练 | Teacher Forcing :每一步输入的是真实目标序列的当前 token | 固定遍历整个目标序列(包括 <EOS>) |
是 |
| 预测 | 自回归(Autoregressive) :每一步输入的是上一步模型预测出的 token | 遇到 <EOS> 或达到 MAX_LENGTH 时停止 |
否 |
⚠️ 注意:训练时即使模型提前"预测"出
<EOS>,也不会提前终止,而是继续按 ground truth 序列计算损失;但预测时必须在生成<EOS>后立即停止。
✅ 总结:预测何时结束?
预测过程在以下任一条件满足时终止:
- 模型生成了
END_OF_SENTENCE(即<EOS>)token;- 已生成的 token 数量达到预设的
MAX_LENGTH。
这是 Seq2Seq 模型(无论是否带注意力机制)在推理阶段的标准做法,兼顾了正确性 与鲁棒性。
✨ 提示:实际应用中,还可结合束搜索(Beam Search) 等策略提升生成质量,但终止条件逻辑不变。