RynnVLA-002: A Unified Vision-Language-Action and World Model
- 文章概括
- ABSTRACT
- [1 Introduction](#1 Introduction)
- [2 Related Work](#2 Related Work)
-
- [2.1 Vision-Language-Action Models(视觉-语言-动作模型)](#2.1 Vision-Language-Action Models(视觉-语言-动作模型))
-
- [VLM-based VLA](#VLM-based VLA)
- [Visual Generation-based VLA](#Visual Generation-based VLA)
- [2.2 World Models(世界模型)](#2.2 World Models(世界模型))
- [3 Methods](#3 Methods)
-
- [3.1 Overview](#3.1 Overview)
- [3.2 Data Tokenization(数据分词/token化)](#3.2 Data Tokenization(数据分词/token化))
- [3.3 Action Chunk Generation(动作片段生成)](#3.3 Action Chunk Generation(动作片段生成))
- [4 Experiments](#4 Experiments)
-
- [4.1 Simulation Results](#4.1 Simulation Results)
- [4.2 Real-World Robot Results](#4.2 Real-World Robot Results)
- [4.3 Ablation Study](#4.3 Ablation Study)
- [5 Conclusion](#5 Conclusion)
文章概括
引用:
bash
@article{cen2025rynnvla,
title={RynnVLA-002: A Unified Vision-Language-Action and World Model},
author={Cen, Jun and Huang, Siteng and Yuan, Yuqian and Yuan, Hangjie and Yu, Chaohui and Jiang, Yuming and Guo, Jiayan and Li, Kehan and Luo, Hao and Wang, Fan and others},
journal={arXiv preprint arXiv:2511.17502},
year={2025}
}
markup
Cen, J., Huang, S., Yuan, Y., Yuan, H., Yu, C., Jiang, Y., Guo, J., Li, K., Luo, H., Wang, F. and Li, X., 2025. RynnVLA-002: A Unified Vision-Language-Action and World Model. arXiv preprint arXiv:2511.17502.主页:
原文: https://arxiv.org/pdf/2511.17502
代码、数据和视频: https://github.com/alibaba-damo-academy/RynnVLA-002
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
ABSTRACT
我们提出了RynnVLA-002,这是一种将视觉-语言-动作(Vision-Language-Action, VLA)与世界模型统一起来的框架。 其中的世界模型利用动作和视觉输入来预测未来的图像状态,通过学习环境的底层物理规律来改进后续动作的生成。 与之相反,VLA模型则根据图像观测生成后续动作,一方面提升对视觉信息的理解,另一方面为世界模型的图像生成提供支持。 通过这一统一框架,RynnVLA-002能够实现环境动态和动作规划的联合学习。 我们的实验表明,相比单独的VLA模型或单独的世界模型,RynnVLA-002取得了更好的性能,体现出两者在统一框架下的相互促进作用。 我们在仿真环境和真实机器人任务中对RynnVLA-002进行了评估。 在LIBERO仿真基准上,RynnVLA-002在无预训练的情况下就达到了97.4%的成功率;而在真实的LeRobot实验中,其集成的世界模型将整体成功率提升了50%。
1 Introduction
视觉-语言-动作(VLA)模型已成为一种有前景的范式,用于在视觉环境中实现语言条件下的决策,使机器人能够将指令与视觉观测映射到动作上(Zitkovich et al., 2023, 2024)。 这些模型通过在大规模预训练多模态大语言模型(MLLMs)(Liu et al., 2023b; Li et al., 2024a; Zhang et al., 2025a; Bai et al., 2025)上添加动作头或额外的动作专家模块来生成动作。 MLLMs提供了强大的感知与决策能力,使得VLA模型在各种机器人任务中展现出更强的泛化能力(Black et al., 2024; Intelligence et al., 2025)。
然而,标准的VLA架构面临三个根本性缺陷。 第一,它们无法真正理解动作,因为动作仅存在于输出端,模型无法形成对动作动力学的显式内部表征。 第二,它们缺乏"想象力":无法在给定候选动作的情况下预测世界状态将如何变化,妨碍前瞻能力与反事实推理。 第三,它们没有对物理规律的显式理解。缺乏对物理动力学的捕捉,模型无法内化物体间交互、接触或稳定性。 世界模型通过在当前图像和动作条件下预测未来观测来直接解决上述局限,为智能体提供与动作相关的内部状态、想象能力以及具备物理知识的环境动态表示(Ha and Schmidhuber, 2018; Wu et al., 2025a)。 尽管世界模型具备上述优势,但它们无法直接生成动作,这导致其在需要显式动作规划的场景中存在功能缺口。
为解决VLA模型和世界模型的固有局限,我们提出RynnVLA-002,这是一种自回归动作世界模型,实现对动作与图像的统一理解与生成。 如图1所示,RynnVLA-002使用三个独立的tokenizer对图像、文本和动作进行编码。 不同模态的tokens共享同一词表,使得跨模态的理解与生成能够在单一LLM架构中实现统一。 世界模型部分通过基于输入动作生成视觉表征来捕捉环境的底层物理动态。 这种动作解释与物理动态学习过程对于提升VLA模型的决策能力至关重要。 同时,RynnVLA-002中的VLA模型改进了对视觉数据的理解,从而提高了世界模型图像生成的精度。 这种双向增强机制使得模型在动作与图像的理解与生成方面更加稳健和全面。
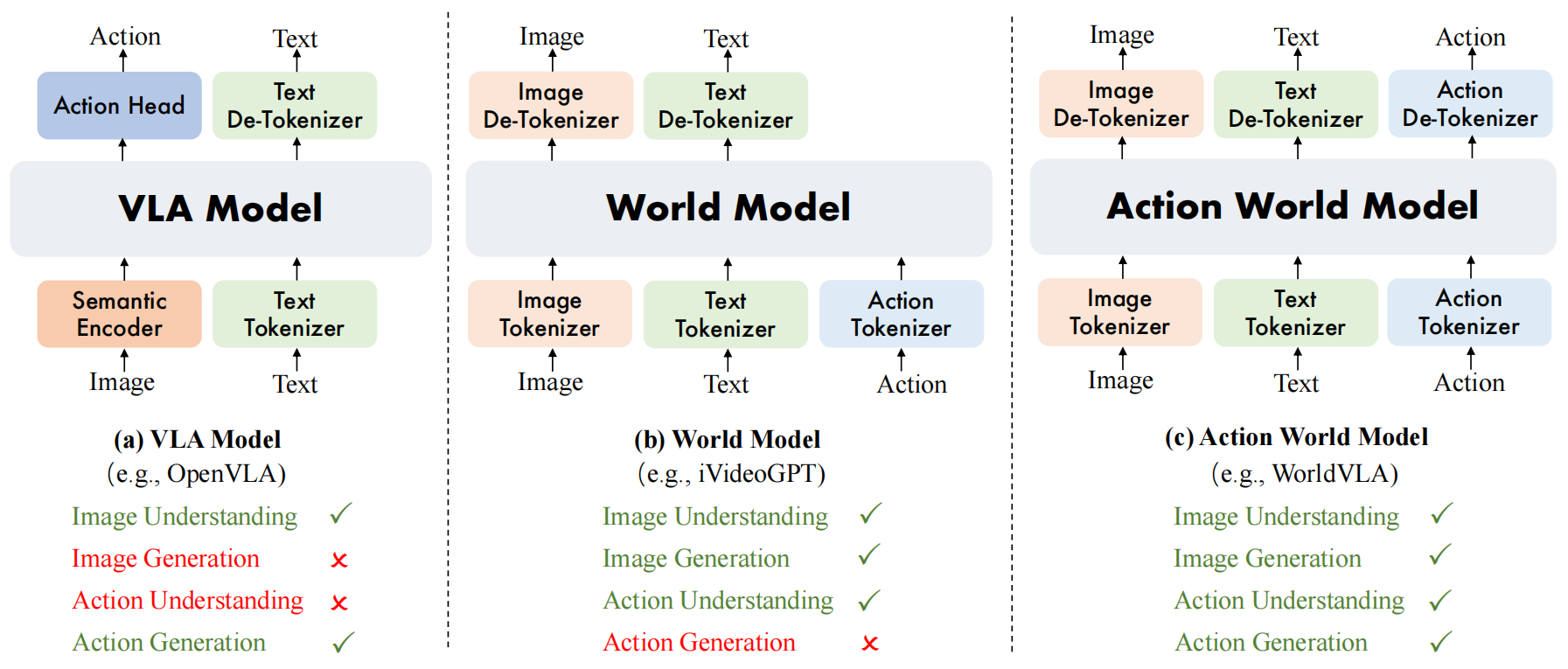 图1(a)VLA模型基于图像理解生成动作; (b)世界模型基于图像与动作理解生成图像; (c)动作世界模型统一图像与动作的理解与生成。
图1(a)VLA模型基于图像理解生成动作; (b)世界模型基于图像与动作理解生成图像; (c)动作世界模型统一图像与动作的理解与生成。
在本研究中,我们探索了不同的动作生成机制。 我们最初的方法(即WorldVLA (Cen et al., 2025))是将动作离散化,并将其与图像和文本tokens统一在同一词表中。 然而,我们发现该方法难以生成连贯的动作片段。 其主要原因在于预训练的多模态语言模型主要见过图像与文本,而非动作,因此动作泛化能力有限。 此外,在自回归模型中,后续动作依赖于先前动作,导致错误传播成为关键问题:早期错误预测会影响后续动作。 为缓解这一问题,我们提出了动作注意力掩码策略,在生成当前动作时选择性地屏蔽先前动作。 该方法有效减少了错误累积,并在仿真中的动作片段生成任务上取得了显著改进。
然而,在真实机器人实验中,这种离散设计表现出泛化能力有限且推理速度较慢的问题。 我们将泛化性能差归因于离散自回归模型对大规模数据的需求(Kaplan et al., 2020),而机器人领域通常难以获取如此大量的数据。 推理缓慢则源于自回归生成过程的顺序特性。 为解决这些问题,我们将架构演化为一种混合模型:既保留原始的离散联合建模,又加入连续的Action Transformer头(Zhao et al., 2023)。 该新动作头显著小于基础LLM,从而减少过拟合并提升泛化能力。 此外,Action Transformer的并行解码与双向注意力机制减少了解码步骤,加速推理并生成更平滑的轨迹。
总而言之,我们的贡献如下:
- 我们提出RynnVLA-002,这是一种在单一框架中统一VLA与世界模型的动作世界模型。
- 我们引入动作注意力掩码策略用于离散动作片段生成,以解决自回归动作序列中的错误累积问题;此外加入连续Action Transformer头,以获得更强泛化能力与更平滑轨迹。
- 我们的实验表明,RynnVLA-002优于单独的VLA模型与世界模型,体现两者的相互增强;此外,它在LIBERO仿真基准上在无预训练情况下达到了97.4%的成功率,并在真实的LeRobot实验中使整体成功率提升了50%。
2 Related Work
2.1 Vision-Language-Action Models(视觉-语言-动作模型)
什么是 VLA / VLM?先把基本角色认清
VLM(Vision-Language Model) 就是"看图+看文字 → 输出文字"的大模型,比如:
输入:一张桌面照片 + 文本指令 "描述一下桌面上有什么?"
输出:一段文字 "桌子上有一个红色杯子,一个手机和一支笔。"
它只管理解和说话,不直接出动作。
VLA(Vision-Language-Action Model) 在 VLM 的基础上,多了一只"手":
输入:图像/视频 + 文本指令
输出:机器人要执行的"动作(action)"。
可以理解为:
- VLM = 会看、会说的人 * VLA = 会看、会说、还能动手的人
VLM-based VLA
基本架构长啥样?
VLM-based VLA 模型的基本套路:
前面一大块:VLM 主干
- 画面进 Vision Encoder(CNN/ViT)。
- 文本指令进 Text/Language Encoder。
- 两者在大模型里融合,形成一个"对当前场景 + 指令都理解了"的隐状态。
后面接一个"动作头(policy head)"
- 用这个隐状态,输出动作(离散token 或 连续向量)。
所以"VLM-based VLA"就是:
先用 VLM 理解,再用一个(或多个)专门的策略头把"理解"变成"动作"。
基于VLM的VLA模型(Brohan et al., 2023; Cheang et al., 2024; Wen et al., 2025b; Li et al., 2023; Huang et al., 2024; Belkhale and Sadigh, 2024; Zhao et al., 2025b; Wang et al., 2025a,b)通过视觉--语言输入映射到动作。 RT-2(Zitkovich et al., 2023)首次在机器人轨迹与大规模视觉-语言数据上联合训练VLM,并将动作表示为离散token。 后续工作(Wu et al., 2023; Zitkovich et al., 2024; Li et al., 2025b; Zhen et al., 2024; Pertsch et al., 2025)进一步扩展了该架构,以提升泛化能力和表示效率。 为解决离散token带来的精度损失,LCB(Shentu et al., 2024)提出了带有连续策略头的双系统,这启发了各种使用不同策略头模型(如扩散Transformer(Peebles and Xie, 2023))的变体,并结合跨多种机器人形态的多样化训练策略(Zhang et al., 2024; Wen et al., 2024, 2025a; Zhou et al., 2025; Li et al., 2024b)。 近期框架如 π 0 π_0 π0(Black et al., 2024)采用条件流匹配(Lipman et al., 2022),开源框架GR00T(Bjorck et al., 2025)将其扩展到复杂的人形控制,而π0.5(Intelligence et al., 2025)通过引入大规模多模态网页数据与跨机器人形态数据进一步提升泛化能力,使模型可在多个机器人平台上直接零样本部署。
RT-2:把动作当成"离散token"的先行者
RT-2 做了两件关键事:
训练数据混在一起喂:
- 一部分是"网页图文/多模态数据"(类似普通 VLM 的训练材料)。
- 一部分是"机器人轨迹数据"(某个视觉观测下,机器人执行了什么动作序列)。
把动作"离散化",变成类似"单词"的 token:
- 比如,原本机器人的关节角是连续数值 ( q 1 , ... , q n ) (q_1,\dots,q_n) (q1,...,qn)。
- RT-2 会把动作量化成若干离散符号,比如"move_arm_left_small""open_gripper"等,就像词表里的单词那样。
好处:
- 可以用完全一样的 Transformer 结构来处理文字 token、视觉 token、动作 token,训练和推理一套逻辑走到底。
- 统一了模态:文字 ↔ 图像 ↔ 动作,全部是"token 序列"。
坏处(文中说的"precision loss 精度损失"):
- 你把连续空间"切块儿成格子",动作就不够细了。
- 比如转 1°、转 2°都归到同一个"动作 token",对精细操作不友好。
LCB:双系统 + 连续策略头,解决"离散不够精"问题
仍然保留一个"离散部分":
- 这个部分继续利用 RT-2 那套思路,让 VLM 能读懂指令、场景,还能粗略地选类别/阶段性的决策(比如:先"抓杯子",再"放到盘子里")。
另外加一个"连续策略头"(continuous policy head):
- 从 VLM 的隐状态出发,直接输出连续向量动作(精确的关节角、末端位姿、速度等)。
所以 LCB 是一个双系统(two-system):
- 符号/语言/离散层面:处理高层语义、任务分解。
- 连续控制层面:输出真正给机器人执行的精细动作。
可以把它想象成:
大脑里有一个"用语言思考"的系统 + 一个"手感很细腻的运动控制"系统,共享同一堆感知与世界理解。
不同策略头:比如 Diffusion Transformer
既然"策略头"只是接在 VLM 后面的一个模块,那它可以是不同的预测模型:
可以是传统 MLP/Transformer 直接输出连续向量。
也可以是 Diffusion Transformer:
- 把动作当成一个"要从噪声中逐步去噪生成"的对象。
- 可以更好地建模多峰分布、复杂动作序列(比如:抓取→移动→放置一长串动作)。
所以:
VLM = 前面的大脑 策略头 = 后面的"动作生成器",可以玩出不同风格(Diffusion, Flow Matching, autoregressive 等)。
多形态机器人训练:一套大脑,多种"身体"
"机器人形态(morphology)" = 不同机体结构,例如:
- UR5+夹爪
- 移动底盘+机械臂
- 双臂机器人
- 人形机器人(humanoid)
这类工作在做的事是:
- 输入端:视觉 + 文本是统一的。
- 中间:共享一个 VLM / VLA 主干。
- 输出端:针对不同机器人形态,用不同的动作空间头;或者设计统一动作参数化(再通过形态映射)。
结果就是:
同一个模型能控制很多种机器人。
π 0 π_0 π0、GR00T、 π 0.5 π_{0.5} π0.5:从 Flow Matching 到大规模泛化
Flow Matching:可以理解为"连续版 diffusion",模型学的是一个"速度场/流场",把一个简单分布(比如高斯)通过一个连续时间的"流"变成目标分布。
在动作建模里面,就是:
从一个简单噪声动作起步,沿着时间连续"流"到真实动作的分布。
条件流匹配(conditional flow matching):
- 条件 = 当前图像、文字指令等
- 模型学的是:在这个条件下,如何把噪声动作流成真实动作。
π 0 π_0 π0 做的就是:
- 用Flow Matching来建模机器人动作分布,而不是传统 diffusion 或直接回归。
- 相当于"用更稳定、更连续的生成过程"来出动作。
开源框架 GR00T 将其扩展到复杂的人形控制......
- GR00T:可以理解为"以 π 0 π_0 π0 为灵感/基础,把这套 Flow Matching + VLA 的思路扩展到人形机器人上",动作空间更高维、约束更复杂。
- 强调的是:同一类生成式策略(Flow-based)不仅能做桌面操作,也能做复杂的 whole-body control。
π 0.5 π_{0.5} π0.5 通过引入大规模多模态网页数据与跨机器人形态数据进一步提升泛化能力,使模型可在多个机器人平台上直接零样本部署。
这里本质上是在说"Scaling Law + Data Mixture":
更多、更杂的训练数据:
- 一边吃网页多模态数据(像普通 VLM 一样,学广泛世界知识、视觉理解)。
- 一边吃多种机器人平台上的轨迹数据(不同形态、不同任务)。
结果:
- 模型不仅能在训练里见过的机器人上工作,
- 甚至可以在 没专门微调过的新机器人平台上直接 zero-shot 控制(当然有前提:动作空间兼容/有统一参数化)。
"基于 VLM 的 VLA" = 大脑是图文大模型,尾巴是各种更强的动作生成器(离散/连续/扩散/流匹配),再加上多机器人、多数据源的大规模训练。
代表作:RT-2 → LCB → π 0 π_0 π0/GR00T/ π 0.5 π_{0.5} π0.5 等。
Visual Generation-based VLA
核心思想:先"想象未来",再决定怎么动
前面 VLM-based VLA 更像是:
看一帧/几帧图 + 文本 → 直接出动作。
而 Visual Generation-based VLA 是:
在出动作之前,模型会"脑补/生成未来的视觉画面",类似一个"以图像为主的世界模型"。
举个极简例子:
当前画面:桌上有杯子和碗。
指令:把杯子放进碗里。
模型可能会:
- 先预测:如果我往杯子方向移动手,会看到什么未来帧?
- 再预测:如果继续抬手,会看到什么画面?
- 根据"这些可能的未来画面",选择一条最合理/最安全/最符合指令的轨迹。
所以这些方法更强调的是:
"预测将会看到什么(未来视频帧)" → 用这个隐含的动态世界理解来指导动作决策。
除了静态感知,基于视觉生成的方法通过预测未来视觉状态来建模环境动态。 UniPi(Du et al., 2023)、DREAMGEN(Jang et al., 2025)和GeVRM(Zhang et al., 2025b)生成未来视觉观测以指导动作生成。 联合框架(Guo et al., 2024; Zheng et al., 2025b; Li et al., 2025a)同时生成未来图像帧与对应动作,从而增强时间一致性与策略学习。 其他方法将未来视频预测作为强大的预训练目标,包括GR-2(Cheang et al., 2024)、VPP(Hu et al., 2024)与RynnVLA-001(Jiang et al., 2025)。 总体来看,这些方法展示了预测视觉建模在连接感知与动作上的潜力,但在视觉保真度、跨域迁移以及计算效率方面仍存在挑战。 我们的RynnVLA-002基于Chameleon(Team, 2024)构建,该模型统一了图像理解与图像生成,因此结合了VLM与视觉生成方法的优势。
两类代表:
1 只预测未来观测,然后单独出动作UniPi、DREAMGEN、GeVRM 生成未来视觉观测以指导动作生成。
套路大致是:
- 有一个视频生成模型,可以从当前和过去观测,生成未来几帧视觉。
- 有一个策略模块,以这些真实+预测的帧为输入,输出动作。
可以理解为:
- 先学一个"会预测未来画面"的大脑(偏感知/生成)。
- 再在这个未来预测的基础上,单独训练一个策略网络。
2 联合生成"未来图像帧 + 对应动作"
联合框架同时生成未来图像帧与对应动作,从而增强时间一致性与策略学习。
这里做的是一步到位:
模型直接学:
未来的观测 o t + 1 : t + H o_{t+1:t+H} ot+1:t+H 和对应的动作 a t + 1 : t + H a_{t+1:t+H} at+1:t+H 是如何联合分布的。
也就是把"视觉变化"和"动作"一起当成一个长序列来生成。
好处:
- 时间一致性更强:同一个生成器负责整个"视频+动作"的连续过程。
- 学到的是"动作→世界变化"的耦合结构,更符合物理直觉。
3 以视频预测作为预训练目标
其他方法将未来视频预测作为强大的预训练目标,包括 GR-2、VPP、RynnVLA-001......
这类做法可以理解为:
先让模型在大量视频/轨迹上做自监督任务:
给你前几帧,预测后几帧(甚至预测一些中间帧)。
这样模型会自动学到:
- 哪些物体在动;
- 合理的运动模式是什么;
- 遮挡前后关系等等。
然后 再 把这个模型拿去做 VLA/控制任务微调。
作用类似于:
"用视频预测训练出来的强大视觉世界模型 → 作为 VLA 的底座。"
4 现有问题 & RynnVLA-002 的位置
文中说这些方法还面临:
- 视觉保真度:预测图像总会糊、错位,有 artifact。
- 跨域迁移:在仿真/特定场景学的预测,到真实世界、到新场景会崩。
- 计算效率:视频生成很吃算力/显存。
然后作者说:
我们的 RynnVLA-002 基于 Chameleon 构建,该模型统一了图像理解与图像生成,因此结合了 VLM 与视觉生成方法的优势。
意思是:
Chameleon 本身是一个"统一多模态"模型:
- 既能像 VLM 一样"理解图像+文本",
- 也能像生成模型一样"生成图像"。
RynnVLA-002 把它当成底座 VLA:
- 一方面:继承了 VLM-based VLA 的优势(强感知、强语言对齐)。
- 另一方面 :也可以用生成端来预测/想象未来画面,类似 Visual Generation-based 路线。
所以:
RynnVLA-002 = 一个"理解+生成统一"的 VLA,大脑就是 Chameleon。
2.2 World Models(世界模型)
世界模型为具身智能提供内部表征(Chen et al., 2022; Robine et al., 2023; Wang et al., 2024)以及对外部世界的预测动态(Hafner et al., 2019, 2021; Okada and Taniguchi, 2022),从而在动态环境中实现与物理一致的交互(Xiang et al., 2023; Mazzaglia et al., 2024; Ha and Schmidhuber, 2018)。 近期研究使用基于Transformer的架构实现了世界模型(Wu et al., 2025b; Robine et al., 2023; Micheli et al., 2022)。 值得注意的是,Google的Genie框架(Bruce et al., 2024)通过大规模自监督视频预训练构建可交互的合成环境。 如今,这类世界模型被广泛用于生成多样化训练数据(Agarwal et al., 2025)、支持基于模型的强化学习算法(Wu et al., 2025a),以及帮助从多个生成的策略中选择最优策略(Li et al., 2025a; Bar et al., 2024)。 在本研究中,我们展示了世界模型与VLA可以相互增强。
1 世界模型的两个核心功能
内部表征(representation): 把原始观测(图片、点云、状态)压缩成一个"紧凑的、包含关键信息的向量/隐变量",类似"机器人脑子里的场景记忆"。
预测动态(dynamics) : 给定当前内部状态 z t z_t zt 和动作 a t a_t at,模型能预测下一个状态 z t + 1 z_{t+1} zt+1 或下一帧观测 o t + 1 o_{t+1} ot+1。 这就是一个"在脑子里跑物理"的过程,可以理解为一个虚拟环境/模拟器。
所以世界模型就是:
"把外部世界搬进模型里,变成一个可以在内部反复推演的小游戏/物理引擎"。
2 用 Transformer 来做世界模型
这很自然,因为:
- 动态过程本质上是一个序列 : ( o 1 , a 1 , o 2 , a 2 , ... ) (o_1,a_1,o_2,a_2,\dots) (o1,a1,o2,a2,...)。
- Transformer 本来就是处理序列的高手。
做法通常是:
- 把观测编码成 token / 向量;
- 把动作也 token 化/向量化;
- 交替堆在一起,喂进 Transformer;
- 让模型预测未来的 token(状态/观测)。
3 Genie:用大规模视频预训练出来的"可玩环境"
Genie 先看大量视频(通常是 2D 游戏/物理环境),做自监督任务(预测下一帧、填补中间帧等等)。
学成之后,你可以在 Genie 里"输入动作指令",它会把后续的视频帧生成出来。
这就变成了一个"可以交互的世界":
- 你按键 → 它显示一个结果画面。
- 这和玩游戏、或者和模拟器交互非常类似,只不过引擎是一个神经网络。
所以 Genie 是一个很典型的 "视频世界模型"。
4 世界模型的三种主要用法(文中点出的)
如今,这类世界模型被广泛用于:
- 生成多样化训练数据;
- 支持基于模型的强化学习;
- 帮助从多个生成的策略中选择最优策略。
逐条解释:
生成多样化训练数据(data generation)
- 有了世界模型,你可以在"脑内环境"里跑非常多的模拟轨迹,不用每次都去真实机器人上采数据。
- 相当于用自己学出来的模拟器给自己造更多数据。
基于模型的强化学习(model-based RL)
传统 RL:在真实环境/仿真环境里滚动 trajectory。
Model-based RL:在世界模型内部滚动 trajectory。
优点:
- 样本效率更高。
- 可以在内部做规划、试错,不伤真机。
策略选择/评估(policy selection)
- 你有多种候选策略 π 1 , π 2 , ... \pi_1,\pi_2,\dots π1,π2,...;
- 可以在世界模型里各自 rollout 一堆 times,让世界模型预测回报/成功率;
- 然后选择表现最好的那一个再部署到真实机器人上。
5 本文的立场:世界模型和 VLA 不是"竞争对手",而是"互补搭档"
- 一边是擅长"感知+指令+动作映射"的 VLA;
- 一边是擅长"内部模拟未来"的世界模型;
结合方式的直觉可以是:
- 世界模型产生/评估"未来场景/数据",喂给 VLA 作为训练数据或辅助信号;
- VLA 在真实环境中采新数据,反过来继续训练/更新世界模型;
- 或者:VLA 先给出候选动作序列,让世界模型模拟结果,再选一个最好的(类似 MPC + learned dynamics)。
论文这里只是说:
我们会展示/主张:如果把 VLA 和 World Model 结合起来,整体能力会比单独用 VLA 或单独用 World Model 更强。
用最简单的话压缩一下:
先说 VLM-based VLA:
- 先有 RT-2:把动作当 token,联合训练图文+机器人轨迹。
- 发现动作离散化不够精,于是 LCB 用了"双系统",加入连续策略头。
- 再往后,有人用 Diffusion Transformer、Flow Matching( π 0 π_0 π0)等更强的动作生成器;
- 又有人(GR00T)把这套架构扩展到人形机器人等复杂形态;
- 再往上 scale( π 0.5 π_{0.5} π0.5),吃更多网页多模态+多机器人数据,实现跨机器人零样本控制。
然后说 Visual Generation-based VLA:
- 不仅看现在,还预测/生成未来画面来帮助控制。
- 有的只预测未来观测,有的把"未来观测+未来动作"一起生成。
- 还有工作把"预测未来视频"当作自监督预训练任务(GR-2, VPP, RynnVLA-001),再做机器人控制。
- 但这些都在视觉质量、域迁移、算力成本上有瓶颈。
- 我们的 RynnVLA-002 基于 Chameleon,这个模型既能理解图像也能生成图像,因此可以同时享受 VLM-based 和 Visual-generation-based 两条路线的优点。
最后说 World Models:
- 世界模型 = 机器人脑子里的"世界模拟器",负责内部表征+预测动态。
- 现在大家用 Transformer、用视频自监督(如 Genie)做世界模型。
- 它们可以用来生成数据、做 model-based RL、做多策略选择。
- 本文会展示:如果让世界模型和 VLA 联手,机器人智能能进一步提升。
3 Methods
3.1 Overview
RynnVLA-002的整体架构如图2所示。 可以看到,我们的RynnVLA-002将具身智能中的两类基础模型统一在一起。
第一类是VLA模型,其中策略 π \pi π 基于语言目标 l l l、本体感受状态 s t − 1 s_{t-1} st−1 以及观测历史 o t − h : t o_{t-h:t} ot−h:t 来生成动作 a t a_t at:
a t ∼ π ( a t ∣ l , s t − 1 , o t − h : t ) . (1) a_t \sim \pi(a_t \mid l,s_{t-1},o_{t-h:t}). \tag{1} at∼π(at∣l,st−1,ot−h:t).(1)
第二类是世界模型,其中模型 f f f根据过去的观测和动作来预测下一时刻的观测 o t o_t ot:
o ^ t ∼ f ( o t ∣ o t − h : t − 1 , a t − h : t − 1 ) . (2) \hat{o}t \sim f(o_t \mid o{t-h:t-1},a_{t-h:t-1}). \tag{2} o^t∼f(ot∣ot−h:t−1,at−h:t−1).(2)
我们将VLA模型的数据与世界模型的数据混合起来,共同训练RynnVLA-002这一集成模型 M ψ M_\psi Mψ,从而统一动作预测与世界建模两方面的能力。 这种"双重属性"体现在:在共享同一组参数 ψ \psi ψ的前提下,该模型既可以作为VLA模型被调用,也可以作为世界模型被调用。
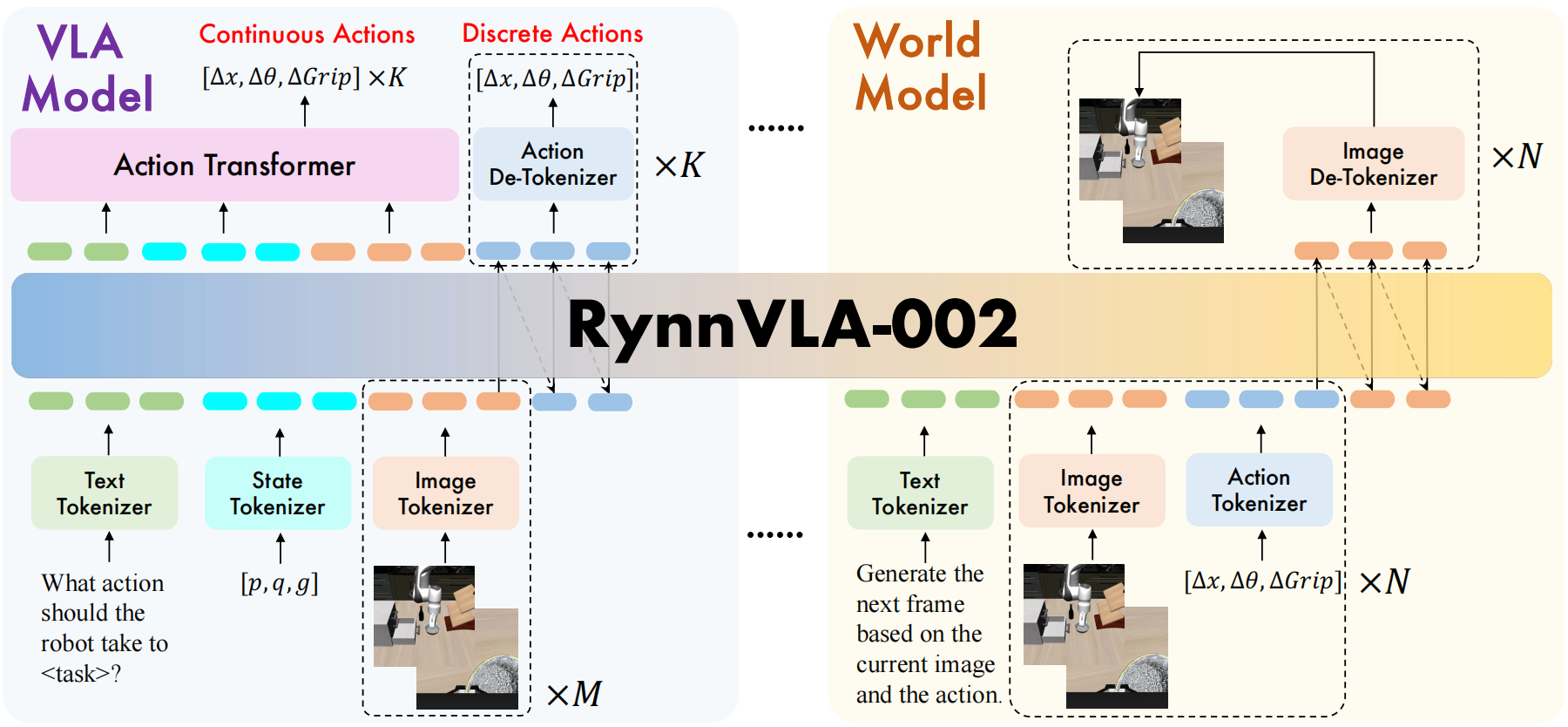 图2 RynnVLA-002整体框架概览。训练过程中同时使用VLA数据和世界模型数据。
图2 RynnVLA-002整体框架概览。训练过程中同时使用VLA数据和世界模型数据。
3.2 Data Tokenization(数据分词/token化)
这一节其实就是在说------怎么把所有东西都"变成字"(token)丢进同一个大脑里训练,以及
- VLA 部分是怎么喂数据、算 loss 的
- World Model 部分是怎么喂数据、算 loss 的
- 最后怎么把两个任务一起训练在一个模型 RynnVLA-002 里
总目标:把所有模态都变成"统一的 token 序列"
RynnVLA-002 的核心大脑是基于 Chameleon 的一个 Transformer,大脑只懂一件事:
"我能处理 一串 token,预测后面的 token。"
所以,图片、文字、机器人状态、动作,都要先被"token 化",也就是变成一串编号(整数)。 这就像:
- 中文 → 拼音/字
- 图片 → 小格子编号
- 动作/状态 → 离散区间编号
然后统一丢进同一个词表(vocabulary),让大脑不管你是图还是字还是动作,都当成"一个 token 序列"来学。
Tokenizers 我们基于Chameleon(Team, 2024)初始化模型,因为它是一个统一的图像理解与图像生成模型。 我们使用四种tokenizer:图像tokenizer、文本tokenizer、状态tokenizer和动作tokenizer。 图像tokenizer采用VQ-GAN模型(Esser et al., 2021),并在特定图像区域(如人脸和显著物体)加入感知损失(Gafni et al., 2022)。 图像tokenizer的压缩比为16,codebook大小为8192。 当输入为256×256图像时会生成256个token;对于512×512图像会生成1024个token。 文本tokenizer是经过训练的BPE tokenizer(Sennrich et al., 2015)。 图像和文本tokenizer均直接继承自Chameleon。 状态与动作tokenizer将连续的机器人本体感受状态与动作的每个维度离散化为256个区间(bin),区间宽度由训练数据的范围决定(Zitkovich et al., 2024, 2023)。 图像、文本、动作与状态token全部共享同一个大小为65536的统一token词表。 由Action Transformer生成的连续动作是未经过token化的原始动作。
四种 tokenizer 都在干嘛?
作者说有四种 tokenizer:
- 图像 tokenizer
- 文本 tokenizer
- 状态 tokenizer
- 动作 tokenizer
最后它们生成的 token 都会被映射到同一个大小为 65536 ( 256 ∗ 256 ) 65536 (256*256) 65536(256∗256) 的 vocabulary(统一词表)。
1 图像 tokenizer:用 VQ-GAN 把图像压成一串离散"图块编号"
用的是 VQ-GAN(Esser et al., 2021) ,这是一个"把图像压缩成离散代码"的模型。
具体做法可以想成:
原图先过一个卷积编码器,变成小得多的特征图(比如 16 × 16\times 16× 压缩)。
每个小格子会被量化(quantize)到 codebook 里的一个"向量编号"。
- codebook 里一共有 8192 8192 8192 个向量(也就是 8192 种"图块类型"),你可以想象成有 8192 种"贴纸"。
整张图就被表示成一个网格上每格一个编号的离散网格。
"压缩比为 16"意思是:
输入图是 H × W H\times W H×W,输出的离散网格是 H 4 × W 4 \frac{H}{4}\times \frac{W}{4} 4H×4W(这里具体 stride 视实现而定,文中给了结果:
- 256 × 256 256\times256 256×256 → 256 256 256 个 token
- 512 × 512 512\times512 512×512 → 1024 1024 1024 个 token
说明压缩后网格尺寸是 16 × 16 16\times16 16×16 或 32 × 32 32\times32 32×32 之类)感知损失(perceptual loss):
- 在人脸或显著物体区域,加一个"看起来更像人看图的损失",比如 LPIPS 那种,让重建图视觉效果更好,防止 VQ-GAN 把重要区域糊掉。
总结下图像 tokenizer 干的事:
输入: 一张图(256×256 或 512×512)
输出: 一串图像 token(256 或 1024 个),每个 token 是 0 ∼ 8191 0\sim8191 0∼8191 之间的一个编号(来自 codebook)。后面 Transformer 就是直接吃这串编号,不再看 raw image。
2 文本 tokenizer:BPE,把句子拆成 subword token
用的是 BPE tokenizer(Sennrich et al., 2015),就是常见的 subword 分词方法。
简单理解:
- 把一句话拆成一堆小片段(subword),高频组合合并成一个 token。
- 这样既不会每个字母一个 token(太长),也不会每个词都当一个独立 token(词表太大)。
这部分直接继承 Chameleon,也就是说:
文本 → BPE tokenizer → 一串 text tokens → 喂给统一大脑。
3 状态 & 动作 tokenizer:连续值离散成 256 个 bin
这部分是关键,你论文里有真实的机器人本体状态(joint angles、eef pose 等)和动作(比如 6 6 6 维、 7 7 7 维、 n n n 维连续向量)。
论文做法是:
- 对每一个维度单独处理,比如关节 1 的角度就是一维,末端 z 方向速度是一维,等等。
- 对这一维在训练数据里统计最小值、最大值,得到一个区间 x min , x max x_{\\min}, x_{\\max} xmin,xmax。
- 把这个区间均匀切成 256 256 256 份(bins)。
- 对于某个具体数值 x x x,看它落在哪一个 bin 里,就用这个 bin 的编号( 0 ∼ 255 0\sim255 0∼255)来当作这个维度的"token"。
这样:
- 原本连续的状态/动作 → 一串离散 token。
- 这跟 RT-2 一支线的做法一致(Zitkovich et al., 2023, 2024)。
注意一点:
- 这个状态/动作 token 只是为了让"统一大脑"能用"语言模型那套 cross-entropy"来学离散分布。
- 但论文也说了:真正最后给机器人执行的动作,是由 Action Transformer 输出的连续动作(未 token 化),离散动作 token 只是 VLA 主干训练中的一条支路/一个头。
4 统一词表:所有 token 共享一个大小为 65536 65536 65536 的 vocab
这句话的含义是:
不管你是图像 token、文本 token、状态 token、动作 token,最后都会被映射到同一个整数 ID 空间 ( 0 ∼ 65535 0 \sim 65535 0∼65535)。
这意味着:
- 只有一套 embedding 矩阵;
- 模型可以自然地在"图像 token 前面接文本 token,后面接动作 token"等各种混合序列上训练。
直觉上就是:
把图像块编号、字词编号、状态编号、动作编号,全都当成"同一种语言里的不同单词",让 Transformer 一起学习。
5 连续动作头(Action Transformer)没有 token 化
"由 Action Transformer 生成的连续动作是未经过 token 化的原始动作。"
这一句非常重要:
虽然前面介绍的动作 tokenizer 会生成"离散动作 token",
但真正用于控制机器人的动作输出,是另外一个连续头(Action Transformer)给出的:
- 输入:VLA 主干的隐状态(对图像+文本+历史等理解之后的表示)
- 输出:连续动作向量(不再是 token,直接是实数)
所以,模型同时具备:
- 一个"离散动作头",用 token + cross-entropy 训练( L d i s a c t i o n \mathcal{L}_{dis_action} Ldisaction)。
- 一个"连续动作头",生成最终执行的连续动作(原始动作空间)。
离散那条主要是为了和文本、图像的离散训练方式统一,更好地用语言模型式训练框架;连续那条是为了保持动作精度。
VLA Model Data VLA模型数据的整体token序列如下:
{ t e x t } { s t a t e } { i m a g e − f r o n t − w r i s t } ⏟ × M { a c t i o n } ⏟ × K ⏞ L d i s _ a c t i o n \{\mathtt{text}\}\ \{\mathtt{state}\}\ \underbrace{\{\mathtt{image-front-wrist}\}}{\times M}\ \overbrace{\underbrace{\{\mathtt{action}\}}{\times K}}^{\mathcal{L}_{{dis\_action}}} {text} {state} ×M {image−front−wrist} ×K {action} Ldis_action
VLA模型在语言指令、本体感受状态以及 M M M 段历史图像观测的基础上生成 K K K 个动作。 文本输入形式为: " W h a t a c t i o n s h o u l d t h e r o b o t t a k e t o + < t a s k > + ? " "What\ action\ should\ the\ robot\ take\ to\ +\ <task>\ +\ ?" "What action should the robot take to + <task> + ?"。 L d i s _ a c t i o n \mathcal{L}_{{dis\_action}} Ldis_action 表示离散动作token的交叉熵损失。
可以把这个当成一串 token 块拼接的顺序:
t e x t {\mathtt{text}} text:
文本 token 序列,对应提示:
" W h a t a c t i o n s h o u l d t h e r o b o t t a k e t o + < t a s k > + ? " "What\ action\ should\ the\ robot\ take\ to\ +\ <task>\ +\ ?" "What action should the robot take to + <task> + ?"
举例:
"What action should the robot take to place the red cup into the blue bowl?"
s t a t e {\mathtt{state}} state:
- 机器人当前本体感受状态(joint angles、EEF pose 等),先用状态 tokenizer 离散化 → 一串 state tokens。
i m a g e − f r o n t − w r i s t × M {\mathtt{image-front-wrist}}_{\times M} image−front−wrist×M:
- M M M 段历史图像观测,比如过去 M M M 帧"front+腕部相机"的图像。
- 每张图先过 VQ-GAN → 图像 token 网格 → flatten 一串 tokens。
a c t i o n × K {\mathtt{action}}_{\times K} action×K:
接下来是 K K K 步的动作序列,每个动作被 token 化成若干 tokens(取决于动作维度)。
模型在训练时要自回归地预测这些动作 token,也就是:
给你前面的 text+state+history images,预测接下来的离散动作 tokens。
上面动作 token 的预测会算一个交叉熵损失,记为:
L d i s _ a c t i o n \mathcal{L}_{dis\_action} Ldis_action:
- 和语言模型一样,用 cross-entropy 比较 "模型预测的动作 token 概率分布" 和 "真实动作 token"。
一句话:
在 VLA 任务上,大脑看到指令 + 当前状态 + M M M 帧历史图像, 然后要生成 K K K 步动作的离散 token 序列,这些 token 要用 L d i s a c t i o n \mathcal{L}_{dis_action} Ldisaction 来训练。
同时,并行的连续动作头也会从这些隐状态输出连续动作(用于真实控制),但这里的公式重点讲的是离散 token 部分。
World Model Data 世界模型在给定当前图像观测和动作的情况下生成下一帧图像。其token序列如下:
{ t e x t } { i m a g e s − f r o n t − w r i s t } { a c t i o n } { i m a g e s − f r o n t − w r i s t } ⏞ L i m g ⏟ × N \{\mathtt{text}\}\ \underbrace{\{\mathtt{images-front-wrist}\}\ \{\mathtt{action}\}\ \overbrace{\{\mathtt{images-front-wrist}\}}^{\mathcal{L}{{img}}}}{\times N} {text} ×N {images−front−wrist} {action} {images−front−wrist} Limg
世界模型的所有训练样本都具有相同的文本前缀: " G e n e r a t e t h e n e x t f r a m e b a s e d o n t h e c u r r e n t i m a g e a n d t h e a c t i o n . " "Generate\ the\ next\ frame\ based\ on\ the\ current\ image\ and\ the\ action." "Generate the next frame based on the current image and the action." 且不再提供任何额外任务指令,因为动作本身即可完全决定世界的下一状态。 整个生成过程可以以自回归方式重复N次。 L img \mathcal{L}_{\text{img}} Limg表示离散图像token的交叉熵损失。
世界模型的训练输入是一串"当前图像+动作→下一帧图像"的重复模式,一共重复 N N N 次。
具体展开看一段:
t e x t {\mathtt{text}} text:
文本前缀是固定的一句话:
" G e n e r a t e t h e n e x t f r a m e b a s e d o n t h e c u r r e n t i m a g e a n d t h e a c t i o n . " "Generate\ the\ next\ frame\ based\ on\ the\ current\ image\ and\ the\ action." "Generate the next frame based on the current image and the action."
这是在告诉模型:"你现在不是在做任务规划,而是在做 下一帧预测。"
然后,每一个时间步(共 N N N 次)包含:
i m a g e s − f r o n t − w r i s t {\mathtt{images-front-wrist}} images−front−wrist:
- 当前时刻的图像 tokens(front+腕部相机)。
a c t i o n {\mathtt{action}} action:
- 当前时刻的动作 tokens(离散化后的动作)。
接着要预测的 i m a g e s − f r o n t − w r i s t {\mathtt{images-front-wrist}} images−front−wrist:
- 下一帧图像 tokens,这一段的 token 预测会计算一个图像 token 的交叉熵损失 : L i m g \mathcal{L}_{img} Limg。
训练方式:自回归重复 N N N 次
"自回归"就是:每次用之前已经生成/给定的东西,预测下一段 token。
对世界模型来说,就是重复如下过程 N N N 次:
- 输入:文本前缀 + 之前所有 ( image , action ) (\text{image}, \text{action}) (image,action) 对。
- 预测下一帧的图像 token。
- 把预测出的/真实的图像 token 接着放入序列,再预测再下一帧,如此循环。
关键点:
世界模型这边不再给任务指令,只有固定前缀:
- 因为对下一帧来说,"当前图像 + 动作"已经完全决定了下一状态,不需要额外 task prompt。
L i m g \mathcal{L}_{img} Limg:
- 和语言建模一样,对每个图像 token 做 cross-entropy,让模型学会生成正确的下一帧图像。
Training Objective 我们将VLA模型数据与世界模型数据混合用于训练RynnVLA-002。 整体损失函数为: L d i s = L d i s _ a c t i o n + L i m g . \mathcal{L}{{dis}} = \mathcal{L}{{dis\action}} + \mathcal{L}{{img}}. Ldis=Ldis_action+Limg. 通过这种方式,RynnVLA-002可以根据用户的输入表现为VLA模型或世界模型。
训练数据中有两种样本:
VLA 样本:指令 + 状态 + 历史图像 → 动作 tokens
- 对这些样本只会产生 L d i s _ a c t i o n \mathcal{L}_{dis\_action} Ldis_action(动作 token 的 cross-entropy)。
World Model 样本 :固定文本前缀 + ( image , action ) (\text{image}, \text{action}) (image,action) 序列 → 下一帧图像 tokens
- 对这些样本只会产生 L i m g \mathcal{L}_{img} Limg(图像 token 的 cross-entropy)。
训练时直接把两个任务的数据混在一起,让同一个 Transformer:
- 有时候在做"给定指令 → 出动作"(VLA 角色);
- 有时候在做"给定当前图像+动作 → 预测下一帧图像"(世界模型角色)。
总损失就是两者相加:
L d i s = L d i s _ a c t i o n + L i m g \mathcal{L}{dis} = \mathcal{L}{dis\action} + \mathcal{L}{img} Ldis=Ldis_action+Limg
最后,也就是说:
如果你给的 prompt 是那种:"What action should the robot take to ... ?" → 模型就会走 VLA 模式:想办法生成后续的动作 token / 连续动作。
如果你给的是:"Generate the next frame based on the current image and the action." 外加一串 ( image , action ) (\text{image}, \text{action}) (image,action) → 模型就会走 World Model 模式:预测后续图像 tokens(下一帧画面)。
本质上:
同一个大脑,靠"不同的文本前缀 + 不同的数据格式"来切换自己扮演的角色(VLA vs World Model),而且这两个角色是一起联合训练出来的,所以它的大脑里自然融合了"怎么动手"和"世界会如何变化"两种知识。
3.3 Action Chunk Generation(动作片段生成)
这一节在说两件事:
1)怎么设计注意力掩码,让一次生成多步动作时不"越错越离谱";
2)为什么仅靠离散动作不够用,于是再加一个专门的 Action Transformer 来一次性生成连续的动作片段,并且怎么训练这个东西。
Attention Mask for Discrete Action Chunk(离散动作片段的注意力掩码) 生成多个动作用于执行对提升效率和成功率至关重要(Kim et al., 2025)。 然而,我们发现,在自回归模型中直接顺序生成多个动作会导致性能下降。 尽管基础的多模态大语言模型(MLLM)在图像和文本领域具有强大的泛化能力,但其在动作领域的泛化能力相对有限。 因此,在默认的因果注意力掩码下,早期动作产生的错误会传播到后续动作,从而进一步降低性能。 为解决这一问题,我们提出了专为动作生成设计的另一种注意力掩码,如图3(b)所示。 这一改进的掩码使得当前动作只能依赖文本和视觉输入,而不能访问之前生成的动作。 这样的设计使自回归框架可以"独立地"生成多个动作,从而缓解错误累积的问题。 世界模型部分则继续采用常规的注意力掩码,如图3(c)所示。
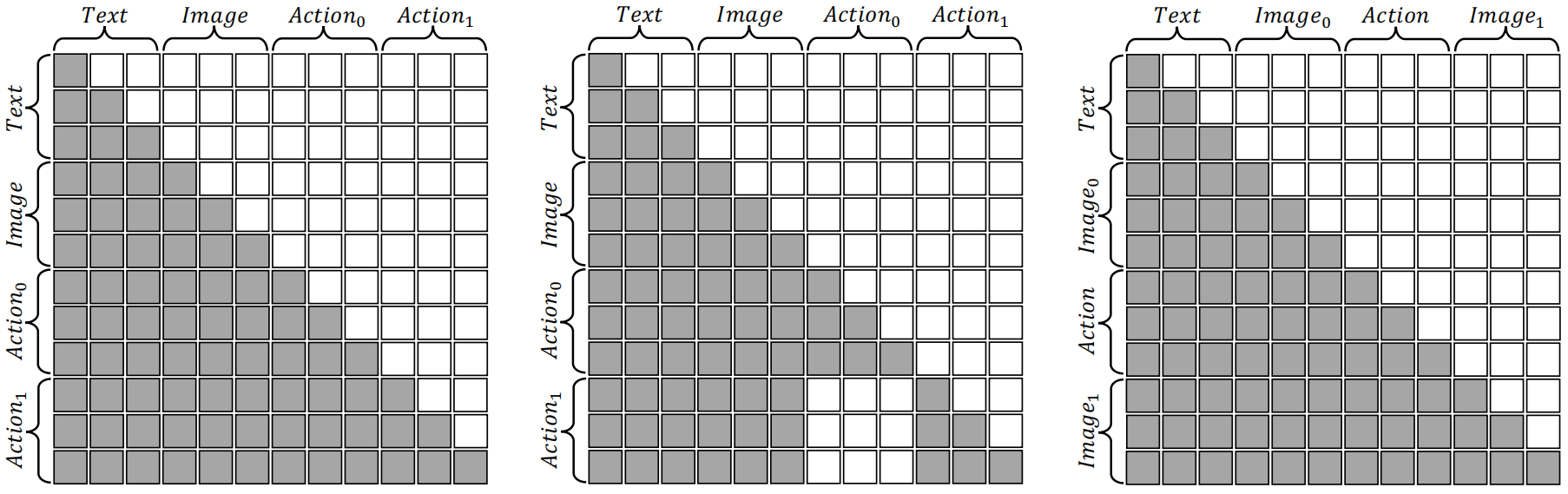 图3:注意力掩码示例,(a)默认VLA模型,(b)我们提出的VLA模型,(c)世界模型。
图3:注意力掩码示例,(a)默认VLA模型,(b)我们提出的VLA模型,(c)世界模型。
一、先搞清楚:attention mask 在这里干嘛
Transformer 里,每个 token 都可以"看"别的 token,这就是 attention 。 但是不是想看谁就能看谁,要靠一个矩阵来控制------这就是 attention mask。
一张 n × n n\times n n×n 的表:
- 行 = 当前在"思考"的 token(query)
- 列 = 它可以看的 token(key)
- 深色格子 = 可以看(attention allowed)
- 白色格子 = 被屏蔽(mask 掉)
在本文里,一串序列是这样排的:
- VLA: Text , Image , Action 0 , Action 1 , ... {\text{Text}}, {\text{Image}}, {\text{Action}_0}, {\text{Action}_1}, \dots Text,Image,Action0,Action1,...
- World Model: Text , Image 0 , Action , Image 1 {\text{Text}}, {\text{Image}_0}, {\text{Action}}, {\text{Image}_1} Text,Image0,Action,Image1
Figure 3 里三个小图就是三种 attention mask:
- (a) 默认 VLA
- (b) 他们改进后的 VLA
- (c) 世界模型
二、为什么要"一次生成一段动作"(action chunk)
机器人执行任务时,一次只出一步动作 很慢、也不稳定。 所以大家会尝试:
一次生成 K K K 步动作,叫一个 动作片段(action chunk)。
这样可以:
- 提速(少打交道/通讯)
- 让规划更长远一点、动作更稳定(Kim et al., 2025)
他们也是这么做的------每次要生成一个长度为 K K K 的 action chunk。
问题:自回归顺序生成多步动作会"错误滚雪球"
自回归 = 像语言模型那样,一个 token 接着一个 token 出:
- 生成 Action 0 \text{Action}_0 Action0 时,看 Text + Image;
- 生成 Action 1 \text{Action}_1 Action1 时,会看 Text + Image + 已经生成的 Action 0 \text{Action}_0 Action0;
- 生成 Action 2 \text{Action}_2 Action2 时,又会看前面所有 action......
如果 Action 0 \text{Action}_0 Action0 一开始就错了:
Action 1 \text{Action}_1 Action1 会在"错误的前提"上继续推理 → 更错
后面每一步都在用前面的错误当"依据"
这就是他们说的:
"在默认因果 mask 下,早期动作的错误会传播到后续动作。"
根源是:
- MLLM 在图像+文本上泛化很好,
- 但在 动作空间 的泛化还不够强,
- 让它自己用"之前生成的动作"当条件,就容易一路越偏越大。
三、Figure 3(a):默认 VLA 的注意力掩码长啥样?
看左边图 (a):
- 上面一排是列:Text, Image, Action₀, Action₁
- 左边一列是行:Text, Image, Action₀, Action₁
深色部分是"可以看"的地方,你会发现这是个标准下三角:
- Text 行:只能看自己前面的 Text(语言自回归,正常)
- Image 行:可以看 Text+之前的 Image
- Action₀ 行:可以看 Text+Image+之前的 Action(如果片段更长,就能看前面所有动作)
- Action₁ 行:可以看 Text+Image+Action₀+之前的 Action₁......
这就对应上面说的:
每个动作都能看到 之前生成的动作 token,错误会一步步传下去。
四、他们的改动:让"每个动作只看场景和指令,不看其他动作"
为了解决"错误滚雪球",他们在 Figure 3(b) 里重新设计了 VLA 的注意力掩码:
当前动作 token 只能看 Text + Image,完全看不到之前生成的动作。
从图 (b) 里可以看到:
在 "Action₀ 行 / Action₁ 行":
- Text 列 & Image 列 都是深色(可以看)
- 所有 Action 列基本全是白色(被屏蔽)
这就意味着:
生成 Action 0 \text{Action}_0 Action0:
- 只能根据"任务指令 + 当前图像"来决定;
生成 Action 1 \text{Action}_1 Action1:
- 也只能根据"任务指令 + 当前图像",
- 完全忽略 Action 0 \text{Action}_0 Action0 长什么样。
所以在这个掩码下:
每一步动作在逻辑上是"独立"的:
"我只看场景和任务自己决定动作,不管别人刚才猜了什么。"
好处:
- 即使前面某一步动作错了,也不会被后面的动作继续引用。
- 错误不会积累;自回归序列里每个 action 的条件信息都是"干净的 Text+Image"。
坏处:
你已经感觉到了:
每个动作互相"看不到对方",就很难保证整条轨迹是连续、顺滑的一条线。
这在后面"连续动作片段"那一段会正式被点出来。
五、World Model 的 attention mask:保持常规的因果结构
再看 Figure 3(c):
序列是:Text, Image₀, Action, Image₁
这是世界模型的输入输出结构:
- 给你当前图像 I m a g e 0 Image_0 Image0 和动作 A c t i o n Action Action,
- 预测下一帧图像 I m a g e 1 Image_1 Image1。
这里 mask 的设计是 常规的自回归:
预测 I m a g e 1 Image_1 Image1 的 tokens 时:
- 可以看见 Text + I m a g e 0 Image_0 Image0 + Action + 之前已生成的 I m a g e 1 Image_1 Image1 tokens,
- 不能看见未来还没生成的 token。
原因很简单:
- 世界模型任务是:图像+动作 → 下一帧图像
- 动作就是"当前帧和下一帧之间的桥梁",
- 让下一帧图像看见动作是必须的;
- 而"错误滚雪球"的问题在图像预测里没那么严重,而且这里他们没有特地改。
Action Transformer for Continuous Action Chunk(连续动作片段的Action Transformer) 尽管我们的离散动作片段模型在仿真中表现良好,但在真实机器人实验中却几乎无法成功。 这种差异的根源在于真实世界需要更强的泛化能力来处理光照、物体位置等变化,而模拟环境无法完全覆盖这些因素。 离散模型失败主要源于两个关键问题。 第一,其庞大的自回归架构在真实数据较少时容易严重过拟合,导致泛化能力不足。 第二,我们设计的注意力掩码使自回归模型必须"独立地"生成片段中的每个动作,从而无法保证轨迹的连续性,导致严重的抖动和不平滑动作,从而大幅降低成功率。
六、离散动作片段在真实机器人上的两个大问题
虽然上面的"离散动作片段+特殊 mask"在仿真里很好用,但上真机器人就炸了。
他们总结了两个关键原因:
6.1 过拟合:大模型 + 真实数据少 → 泛化差
离散动作片段模型是一个"很大的自回归架构"(前面是统一大模型);
仿真环境里数据很多,它学得挺开心;
真实机器人数据少很多 → 大模型很容易记住训练集,
- 在新光照、新物体位置等变化下就不行了。
这就是第一个原因:
模型太大 + 真机数据太少 → 严重过拟合,真实世界泛化差。
6.2 轨迹不连续:动作之间"独立",导致抖动
还记得上面的新 mask 吗?
每个动作只能看 Text+Image,不能看其他动作。
这意味着:
片段里的每一个动作,都是"单点决策",并没有强约束让它们排成一条平滑轨迹。
结果就是:
生成出来的动作序列 容易前后不连贯:
- 第一步往右一点,
- 第二步突然往左一点,
- 第三步又往右......
在物理世界里,这就表现为:
手抖、轨迹折线很多、不平滑 → 成功率大幅下降。
这就是第二个原因:
注意力掩码让动作"独立生成",破坏了动作之间的平滑性和一致性。
为解决这些问题,我们在架构中引入一个专门的Action Transformer,用于生成连续的动作序列(Zhao et al., 2023)。 该模块会处理完整上下文(包括语言、图像和状态token),并使用可学习的动作查询(action queries)一次性并行输出整个动作片段。 这种设计带来了两个显著优势。 首先,Action Transformer结构更加紧凑,不易在小数据上过拟合,从而提升泛化能力并生成更加流畅、稳定的动作。 其次,通过一次性并行生成所有动作,其推理速度远快于逐步生成动作的自回归模型。 我们使用 L1 回归损失 L c o n t i _ a c t i o n \mathcal{L}_{{conti\_action}} Lconti_action来监督Action Transformer。 整体损失函数为:
L = L d i s + α L c o n t i = L d i s _ a c t i o n + L i m g + α L c o n t i _ a c t i o n . \mathcal{L} = \mathcal{L}{{dis}} + \alpha \mathcal{L}{{conti}} = \mathcal{L}{{dis\action}} + \mathcal{L}{{img}} + \alpha \mathcal{L}{{conti\_action}}. L=Ldis+αLconti=Ldis_action+Limg+αLconti_action.
七、Action Transformer:专门为"连续动作片段"设计的模块
为了解决这两个问题,他们引入了一个独立的模块:
Action Transformer:一次性并行生成整个连续动作片段。(参考 Zhao et al., 2023)
你可以把它理解为:
前面大模型负责"理解上下文":
- 把 Text、Image、State 等 token 变成一堆隐表示。
然后单独开一个较小的 Transformer 模块,只做一件事:
根据这些上下文,吐出 K K K 步的连续动作向量。
7.1 具体结构(逻辑层面)
输入:完整上下文的隐状态
- 包括:语言、图像、本体状态 token 的 encoder 输出。
- 注意:这里已经不再用离散动作 token,而是用 continuous head。
动作查询(action queries)
为片段里的每一个时间步准备一个"可学习的 query 向量":
- 比如片段长度 K = 10 K=10 K=10,就有 10 个 action queries。
这些 queries 会去 attend 上下文,
- 每个 query 对应将要生成的 t t t 时刻动作。
一次性并行生成整个片段
- 所有 action queries 一起喂进这个 Action Transformer,
- 它会并行输出 K K K 个连续动作向量:
a ^ 0 , a ^ 1 , ... , a ^ K − 1 \hat{a}_0, \hat{a}1, \dots, \hat{a}{K-1} a^0,a^1,...,a^K−1注意:
- 这里不再是"自回归 token-by-token 输出动作",
- 而是类似 DETR 那种"query→一次性输出全套结果"的风格。
7.2 这样做带来的两个好处(对应前面的两个问题)
结构更紧凑,不容易在小数据上过拟合
和前面的巨大多模态 LLM 相比,
- Action Transformer 是一个规模更小、专门做动作的模块。
它只负责"在已经抽好的上下文特征上做 mapping",
- 参数更少,
- 不容易在少量真机数据上完全记住训练集。
泛化能力会更好,动作更稳定。
轨迹更连续、更光滑
K K K 个 action 是通过同一个 Transformer 和一组互相关联的 queries 并行生成的,
模块内部可以轻松学到:
"第 1 步末端在这里,第 2 步应该在附近,第 3 步继续往前走......"
不再像之前那样,每个动作"互相看不到对方"。
所以连续性和轨迹平滑性自然就出来了 → 减少抖动,提升成功率。
推理速度更快
- 自回归:每一步都要跑一遍大模型, K K K 步就跑 K K K 次。
- 并行生成:一次前向就得到 K K K 步动作。
- 在实际机器人上,这直接换成更快的控制频率和响应。
八、Action Transformer 怎么训练?------L1 回归损失
他们对 Action Transformer 的训练很简单直接:
- 真值动作片段: a 0 , a 1 , ... , a K − 1 a_0, a_1, \dots, a_{K-1} a0,a1,...,aK−1(连续向量)
- 预测动作片段: a ^ 0 , a ^ 1 , ... , a ^ K − 1 \hat{a}_0, \hat{a}1, \dots, \hat{a}{K-1} a^0,a^1,...,a^K−1
用 L1 损失:
L c o n t i _ a c t i o n = 1 K ∑ t = 0 K − 1 ∥ a ^ t − a t ∥ 1 \mathcal{L}_{conti\action} = \frac{1}{K} \sum{t=0}^{K-1} \lVert \hat{a}_t - a_t \rVert_1 Lconti_action=K1t=0∑K−1∥a^t−at∥1
也就是对每个时间步、每个动作维度,算绝对误差,然后平均。
九、最后的总损失:离散 + 图像 + 连续动作,一起学
前面 3.2 里已经有:
- L d i s _ a c t i o n \mathcal{L}_{dis\_action} Ldis_action:离散动作 token 的交叉熵(VLA 部分)
- L i m g \mathcal{L}_{img} Limg:世界模型部分,图像 token 的交叉熵
- 合在一起: L d i s = L d i s _ a c t i o n + L i m g \mathcal{L}{dis} = \mathcal{L}{dis\action} + \mathcal{L}{img} Ldis=Ldis_action+Limg
现在再加上连续动作片段的监督:
- L c o n t i _ a c t i o n \mathcal{L}_{conti\_action} Lconti_action:Action Transformer 的 L1 损失
- 用一个权重 α \alpha α 控制它的重要性
最终总损失:
L = L d i s + α L c o n t i = L d i s _ a c t i o n + L i m g + α L c o n t i _ a c t i o n . \mathcal{L} = \mathcal{L}{{dis}} + \alpha \mathcal{L}{{conti}} = \mathcal{L}{{dis\action}} + \mathcal{L}{{img}} + \alpha \mathcal{L}{{conti\_action}}. L=Ldis+αLconti=Ldis_action+Limg+αLconti_action.
含义就是:
让同一个大模型 同时 学会:
像语言模型那样,用离散 token 做:
- 文本理解
- 图像预测(世界模型)
- 离散动作建模(辅助 / 统一训练)
用 Action Transformer 头,输出真实要执行的 连续动作片段,保证平滑与泛化。
4 Experiments
4.1 Simulation Results
Benchmark. 我们在 LIBERO 基准(Liu et al., 2023a)上评估我们的方法。 该基准由四个不同子集组成,用于测试不同的机器人能力: (1) LIBERO-Spatial 测试空间关系任务,例如要求机器人将碗放置到不同位置。 (2) LIBERO-Object 强调物体识别与操作,涉及具有独特特征的物体。 (3) LIBERO-Goal 通过改变任务目标(但物体固定)来测试程序化学习能力。 (4) LIBERO-Long 包含 10 个复杂的长时间跨度操作任务。
Dataset and Preprocessing. 我们首先对数据集进行清洗:移除失败轨迹并过滤掉"无操作"动作,这一过程也被 OpenVLA(Zitkovich et al., 2024)采用。 对于依赖真实视频-动作对的世界模型评估,我们将清洗后的数据划分为 90% 的训练集与 10% 的验证集。
Hyperparameter Settings. VLA 模型使用 M = 2 M = 2 M=2 帧历史图像作为输入。 我们为更长的任务(LIBERO-Long 和 LIBERO-Spatial)设置动作片段大小 K = 10 K = 10 K=10,而对较短任务(LIBERO-Object 和 LIBERO-Goal)设置 K = 5 K = 5 K=5。 世界模型使用单轮预测( N = 1 N = 1 N=1),以保持计算效率。 损失加权系数设为 α = 10 \alpha = 10 α=10。
Metrics. 我们的评估分为两个部分。 为了评估 VLA 模型,我们在每个任务上运行 50 次部署测试,每次从不同初始状态开始,以测量成功率。 为了评估世界模型,我们在验证集上使用四种标准视频预测指标:Fréchet Video Distance(FVD)、峰值信噪比(PSNR)、结构相似度(SSIM)与感知图像块相似度(LPIPS)。
Benchmark Results. 我们分别评估离散动作与连续动作的性能。 如表1所示,RynnVLA-002 在离散动作上达到 93.3% 成功率,在连续动作上达到 97.4% 成功率,证明其核心设计原则有效:联合学习 VLA 与世界模型、用于离散动作的注意力掩码机制,以及额外的连续 Action Transformer。 令人惊讶的是,即使没有进行任何预训练,RynnVLA-002 依然能与基于 LIBERO-90 或大规模真实机器人数据预训练的强力基线模型(Tian et al., 2024; Bu et al., 2025; Kim et al., 2025)表现相当。
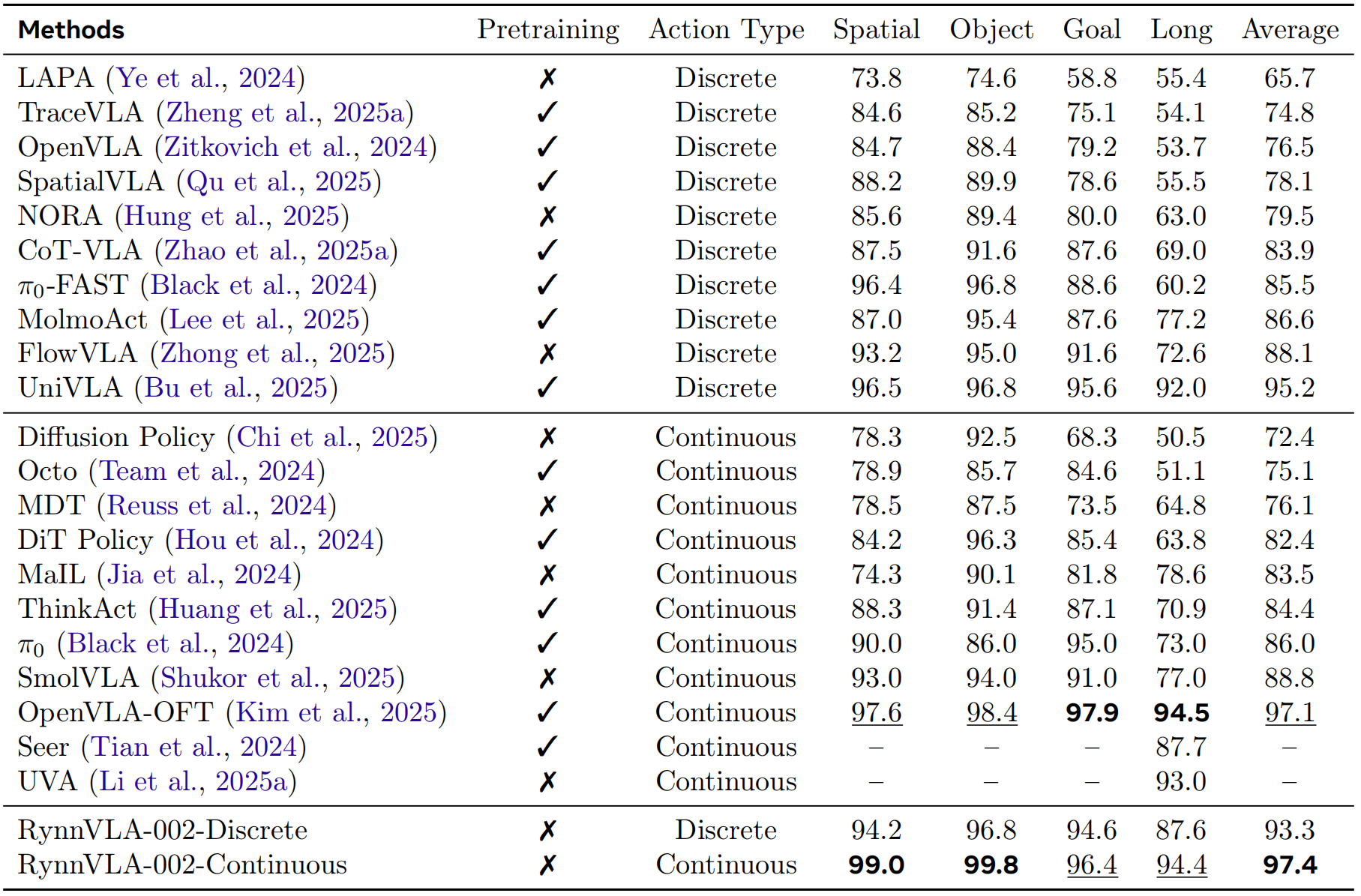 表1:在LIBERO基准上的评估结果。Pretraining表示模型在大规模机器人操作数据上进行了预训练。
表1:在LIBERO基准上的评估结果。Pretraining表示模型在大规模机器人操作数据上进行了预训练。
4.2 Real-World Robot Results
Datasets. 数据集。我们构建了一个新的真实世界操作数据集,使用 LeRobot SO100 机械臂采集得到(Cadene et al., 2024)。 所有轨迹都是通过人工遥操作获得的专家示范。 我们定义了两个"抓取---放置"任务用于评估。 (1) Place the block inside the circle:强调基础物体检测与抓取执行,共 248 条示范轨迹; (2) Place strawberries in the cup:需要精细定位与抓取点预测,共 249 条示范轨迹。
Baselines. 基线方法。我们与两个强有力的开源基线进行比较:GR00T N1.5(Bjorck et al., 2025)和 π0(Black et al., 2024)。 对于这两种方法,我们均从官方预训练检查点开始,并在与我们模型相同的 SO100 数据集上进行微调。 微调过程严格遵循这些基线官方代码库中提供的训练配置与流程。
Evaluation. 评估。如图4所示,我们在三种场景下对模型进行评估: (1) 单目标操作:桌面上只有一个目标物体; (2) 多目标操作:桌面上存在多个目标物体; (3) 含干扰物的指令跟随任务:桌面同时存在目标物体与干扰物体。 如果机器人在预设时间预算内将至少一个目标物体放入指定位置,则该次试验被视为成功。 若出现以下任一情况,则该次试验被判定为失败:(1)超出时间上限;(2)对同一目标物体连续抓取失败次数超过 5 次;(3)在含干扰物的指令跟随任务中,智能体尝试操作任意干扰物体。 每个任务均重复测试 10 次,并报告其成功率。
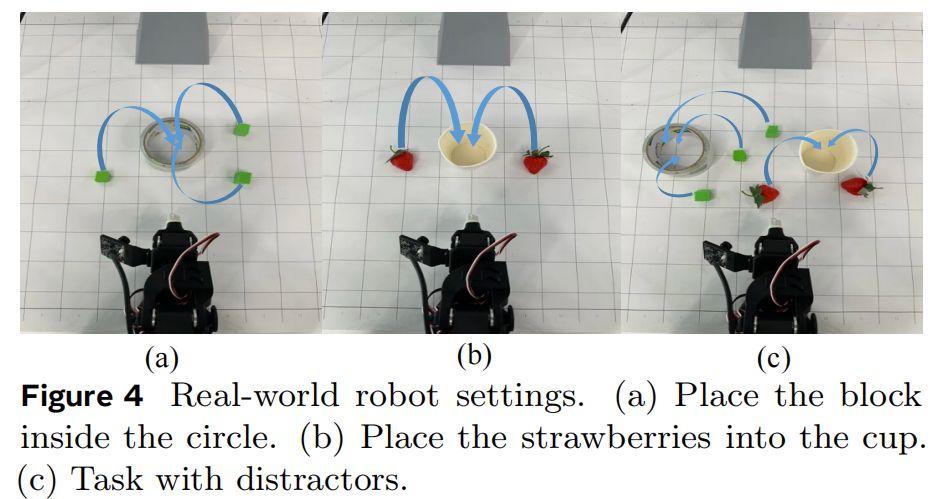 图4:真实机器人任务设置。(a)将积木放入圆圈内。(b)将草莓放入杯中。(c)包含干扰物的任务。
图4:真实机器人任务设置。(a)将积木放入圆圈内。(b)将草莓放入杯中。(c)包含干扰物的任务。
Results. 结果。表2给出了真实机器人实验的结果。 在未进行任何预训练的情况下,RynnVLA-002 仍然取得了与 GR00T N1.5(Bjorck et al., 2025)和 π0(Black et al., 2024)相当的表现。 值得注意的是,在杂乱场景中,RynnVLA-002 的表现优于这些基线模型。 例如,在"Place the block"任务中,RynnVLA-002 在多目标场景和含干扰物场景下的成功率均超过 80%,比基线模型高出 10%--30%。
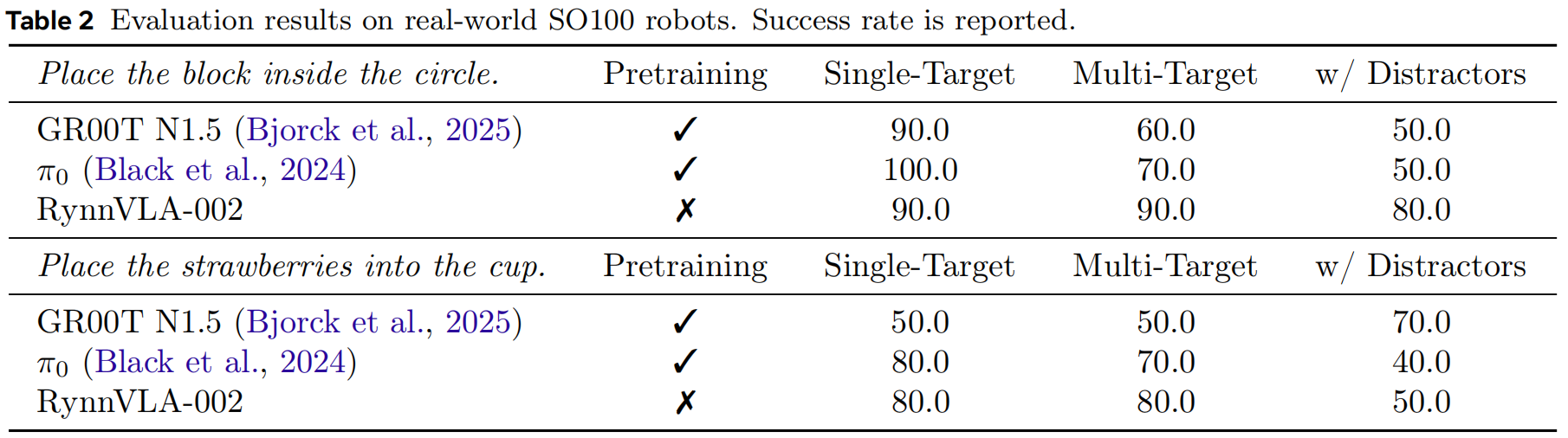 表2:在真实世界 SO100 机器人上的评估结果(报告成功率)。
表2:在真实世界 SO100 机器人上的评估结果(报告成功率)。
4.3 Ablation Study
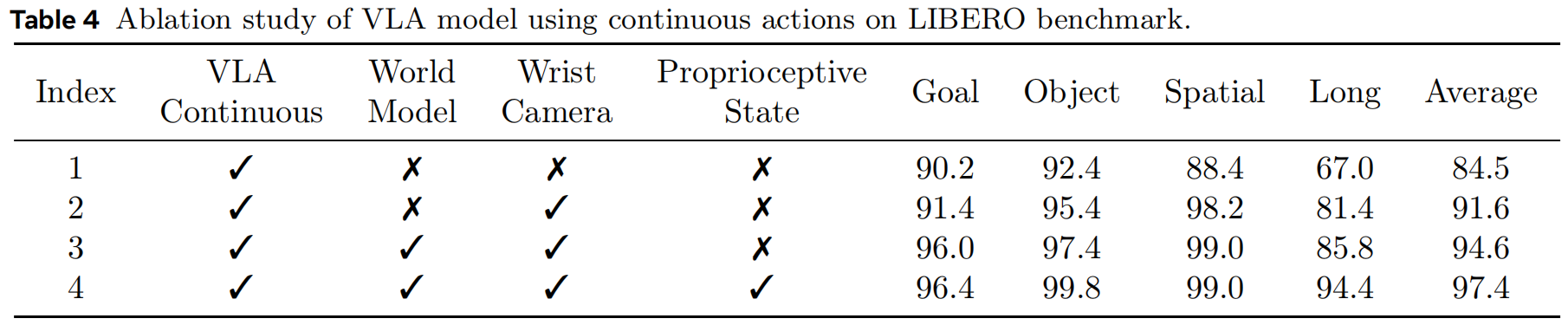
World Model Benefits the VLA Model. 在 LIBERO 仿真基准上,将世界模型数据纳入训练可以持续提升性能。 具体来说,如表3所示,离散动作的成功率从 62.8%(第1行)提升到 67.8%(第2行),并从 76.6%(第4行)提升到 78.1%(第5行)。 对于连续动作,在表4中也可观察到类似趋势,成功率从 91.6%(第2行)提升至 94.6%(第3行)。 在真实机器人实验中,世界模型数据的益处更加显著。 如表5第4行所示,在未使用世界模型数据的情况下训练的模型在真实任务中的成功率非常低,不足 30%。 相比之下,加入世界模型训练后,成功率显著提升到 80% 以上。 图5显示,没有世界模型数据训练的模型会直接移动到目标位置,但无法成功抓起奶酪或瓶子, 而与世界模型联合训练的模型在遇到失败时会持续尝试抓取目标物体。 这种行为表明,世界模型数据使 VLA 模型更关注被操作的物体------因为世界模型的训练目标要求精确预测物体运动,从而强化其对物体交互动态的关注。


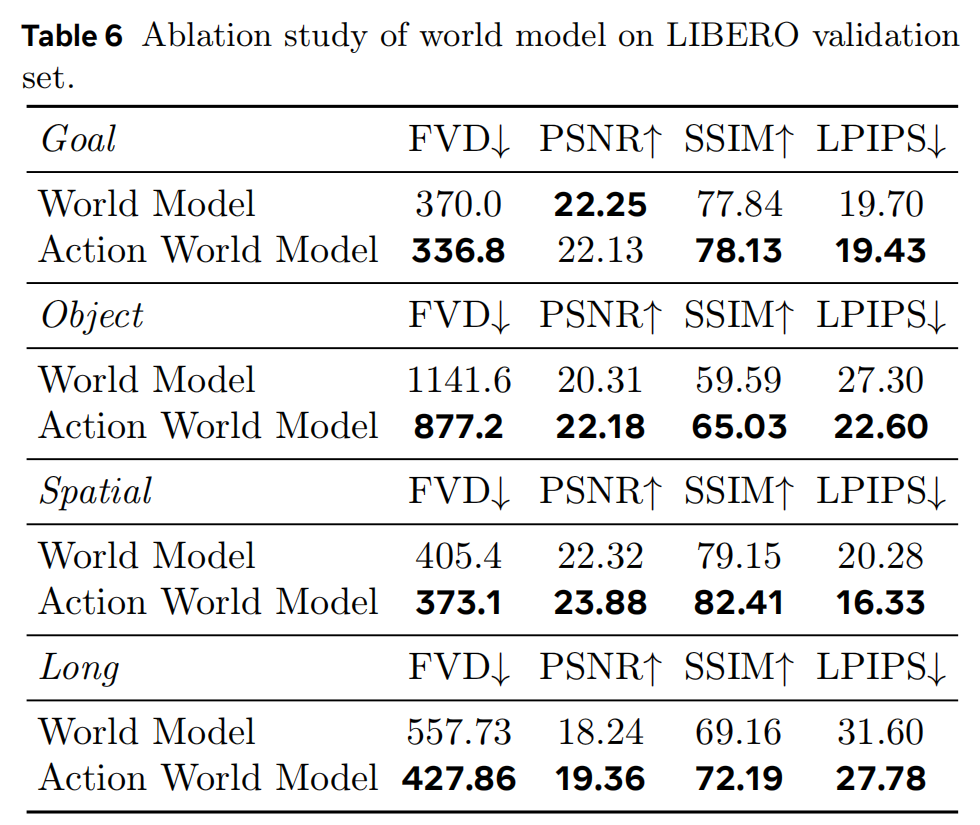
VLA Model Enhances the World Model. 如表6所示,使用 VLA 数据和世界模型数据混合训练的模型,其生成结果与仅使用世界模型数据训练的模型相当或更好。 此外,图7比较了我们的动作世界模型与未使用 VLA 数据训练的基线世界模型的视频生成结果。 基线世界模型在两个示例中均未能从前视相机角度预测出成功抓取碗的画面。 相比之下,我们的动作世界模型始终生成描绘成功抓取的正确视频。 值得注意的是,基线世界模型还表现出明显的不一致性:如图7(a)所示,前视相机显示抓取失败,而腕部相机却显示成功。 这突出了该模型在不同视角预测之间存在严重不一致。 可视化结果验证了:从 VLA 模型继承的图像理解能力提升了世界模型的生成质量。

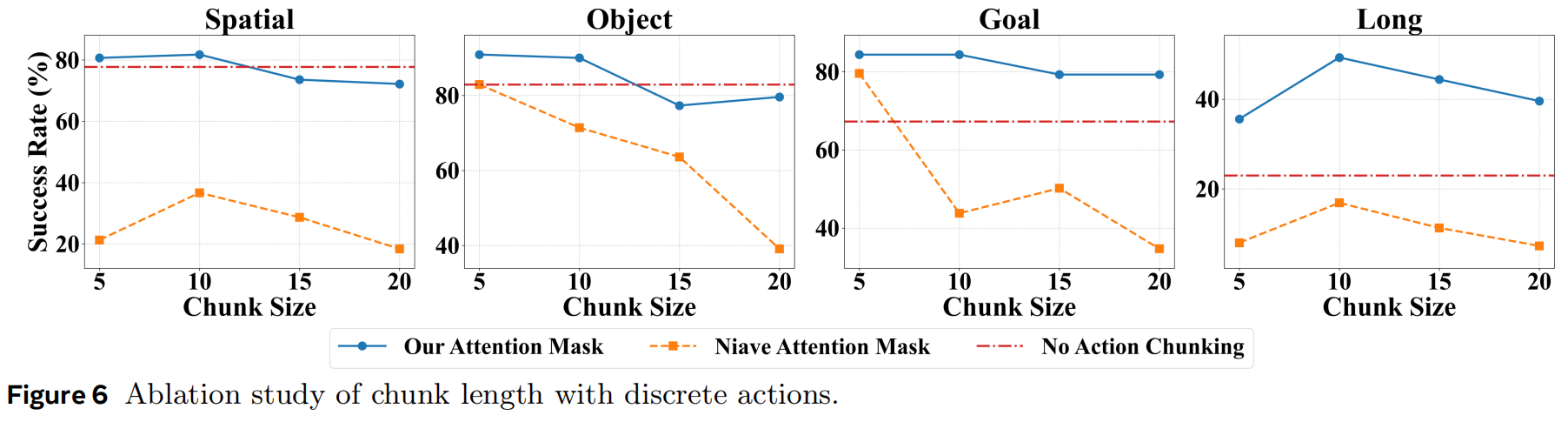
Attention Mask for Discrete Action Chunk Generation. 同时生成多个动作对于实现高效且稳定的抓取至关重要。 然而,我们观察到传统的自回归方法(按顺序逐个生成动作)会降低性能,如表3第3行和图6所示。 当动作片段更长时,抓取成功率会逐渐下降。 性能下降的原因在于:后续动作过度依赖之前的动作(在同一空间中"串联"),而不是基于图像输入这种独立模态。 由于动作模态在 MLLM 预训练中没有参与,其泛化能力较弱。 因此,随着动作序列变长,错误会不断累积。 我们提出的注意力掩码机制确保每个动作独立生成,并仅由视觉输入决定,从而大幅减少动作序列中的错误传播。 如图6所示,使用我们注意力掩码机制的模型在长动作片段条件下表现显著优于默认注意力掩码。 这证明了该掩码机制的有效性。 但如果动作片段过长,机器人无法及时调整策略,仍会导致性能下降。
Discrete Actions Accelerate the Convergence. 我们在训练中同时保留离散动作与连续 Action Transformer,因为我们发现这种混合方式不仅加快了 VLA 的收敛速度,还提升了最终成功率。 如图8所示,使用离散动作 token 训练的模型比不使用的模型具有显著更高的成功率,尤其在训练初期优势最为明显。

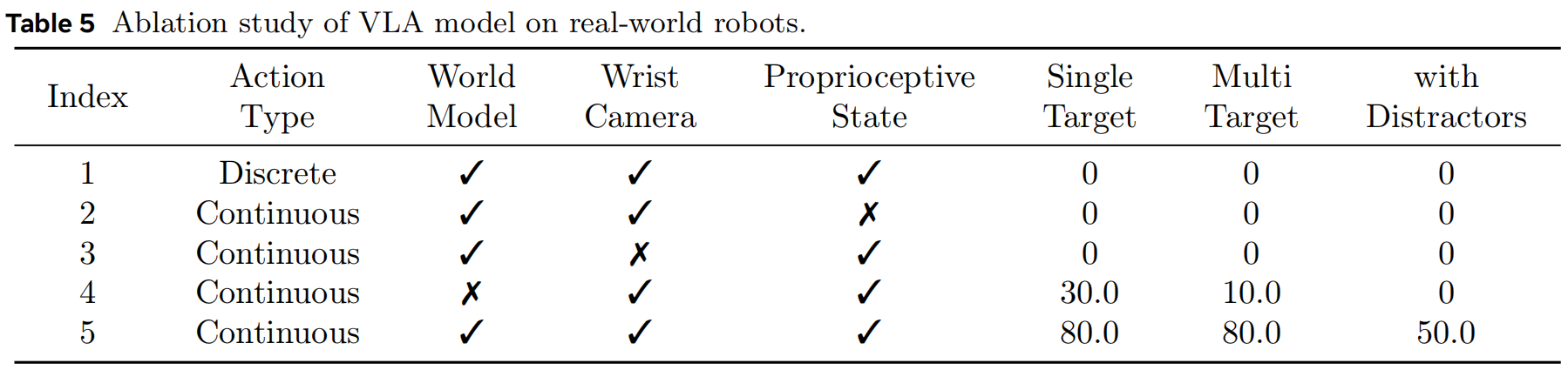
Ablation Study of Wrist Camera and Proprioceptive State. 如表4第1行所示,在 LIBERO 仿真基准上,即使没有腕部相机或本体感受状态,我们的模型仍可达到较合理表现。 加入这两个信息来源后,性能进一步提升(见表4第2行与第4行)。 但在真实实验中(表5第2行和第3行),当缺少腕部相机或本体状态时,机器人会持续失败。 一方面,腕部相机提供夹爪与物体之间相对姿态的关键视觉反馈,尤其在机器人超出前视相机视野时。 另一方面,本体感受状态对于精确把握抓取闭合时机与物体提升过程也至关重要。
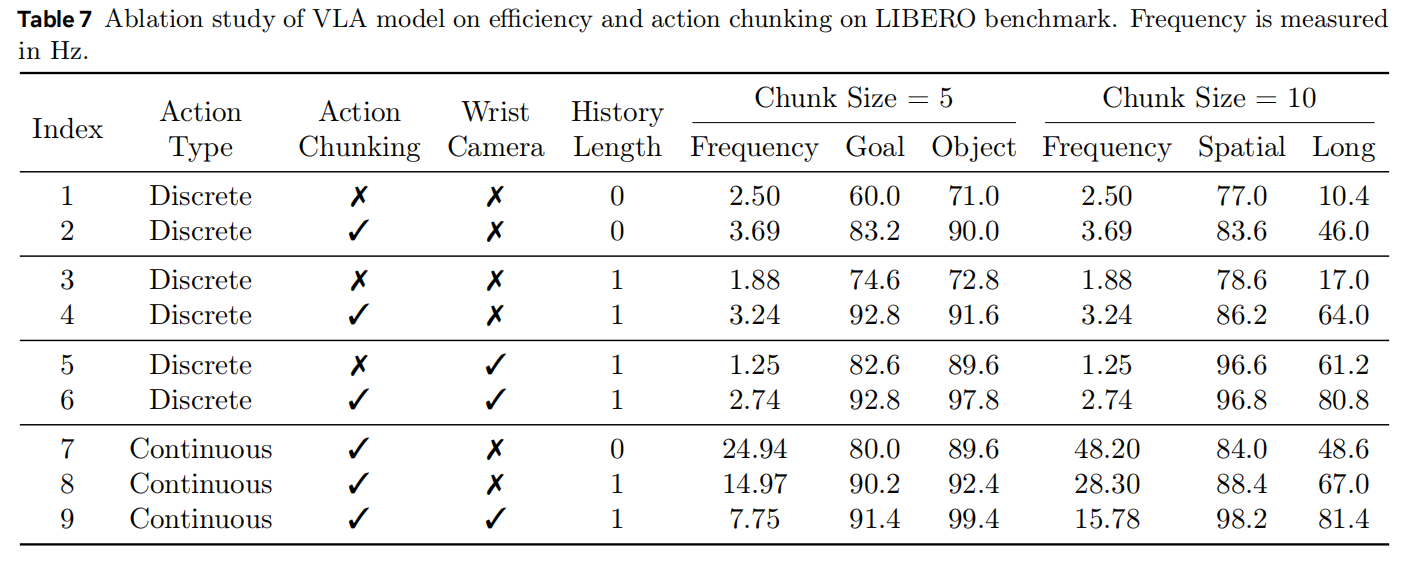
Efficiency Analysis. 如表7所示,加入更多图像输入(如腕部相机图像或历史帧)会提高性能,但降低速度。 对于离散动作,与每次仅生成一个动作相比,动作片段生成同时带来更高的推理速度与更好表现。 连续动作生成由于是并行生成,其速度显著更快,并且随动作片段大小几乎线性扩展,因为生成额外动作几乎无需额外开销。
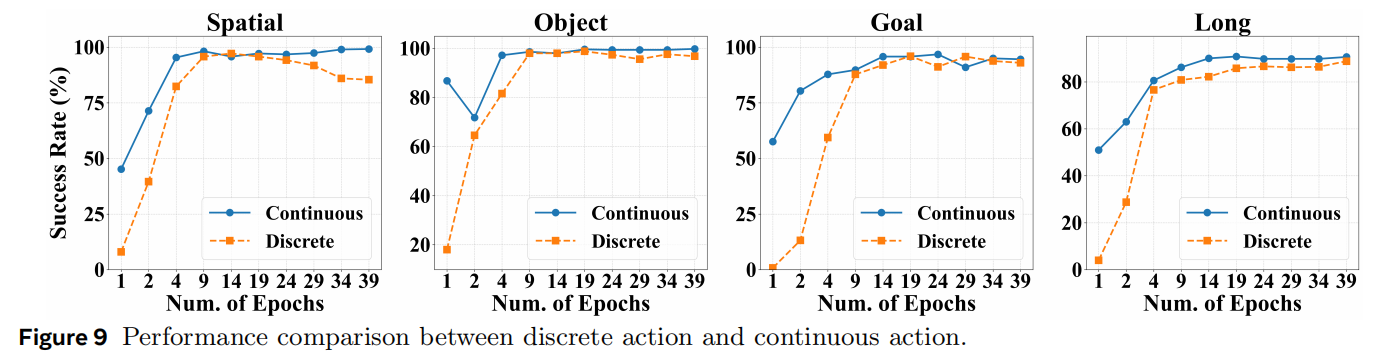
Discrete Action and Continuous Action. 我们的模型同时支持离散与连续动作生成,而实验结果明确显示连续动作具有明显优势。 具体而言,在 LIBERO 仿真基准中,连续动作使训练收敛速度显著加快(图9)。 尽管两者在仿真中的最终表现相当,但在真实机器人实验中差距明显扩大。 如表5所示,真实机器人实验中连续动作相比离散动作带来了更大的性能提升。
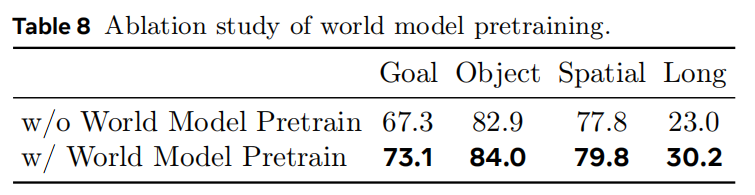
World Model Pretraining for VLA Model. 我们的 RynnVLA-002 将 VLA 模型与世界模型统一到一个训练阶段中。 我们进一步研究使用世界模型预训练来"冷启动"VLA 模型的可能性。 这种预训练要求模型学习理解视觉输入、动作以及控制状态转移的物理动态。 我们使用与 VLA 模型相同的数据源进行世界模型预训练。 如表8所示,采用世界模型进行预训练显著提升了抓取性能。 这些发现表明,世界模型预训练在机器人应用中具有巨大潜力,尤其是在通过提前学习世界知识来提升任务特定性能方面。
5 Conclusion
在本研究中,我们提出了 RynnVLA-002,这一统一框架将 VLA 模型与世界模型结合起来,并证明它们可以相互增强。 通过这一贡献,我们希望为具身智能研究社区提供一套具体的方法论,用于实现 VLA 模型与世界模型之间的协同作用。 此外,我们认为本工作有助于为跨文本、视觉与动作的多模态理解与生成构建统一的基础。