背景
LLM 能力强,但会"幻觉":大语言模型虽然表现优异,但经常生成听起来合理却事实错误的内容,这被称为"幻觉"(hallucination)。
风险高:在企业或关键应用中,这种错误可能带来严重后果。
研究目标
开发一个集成检测与修正的系统,不依赖外部知识源(如搜索引擎或数据库),就能识别并修正幻觉内容。
方法
他们提出了一个叫做 FINCH-ZK 的黑箱框架,核心有两个创新点:
- 跨模型一致性检查(Cross-model consistency):
用多个不同的模型生成对同一问题的回答。
比较这些回答之间的差异,找出不一致的地方,从而识别可能的幻觉。 - 精准修正(Targeted mitigation):
不整段重写回答,而是只修改有问题的部分。
保持正确内容不变,提升整体准确性。
对方法的具体解释
1. 跨模型一致性检查
-
生成 prompt 变体:
原 prompt → 改写/扩写/拆解成 7 条语义等价但措辞不同的 prompt
【补充解释】"专用廉价模型" 一次性离线生成,不再经过 Claude / Llama / DeepSeek 这些"考生模型"。
-
交叉采样:
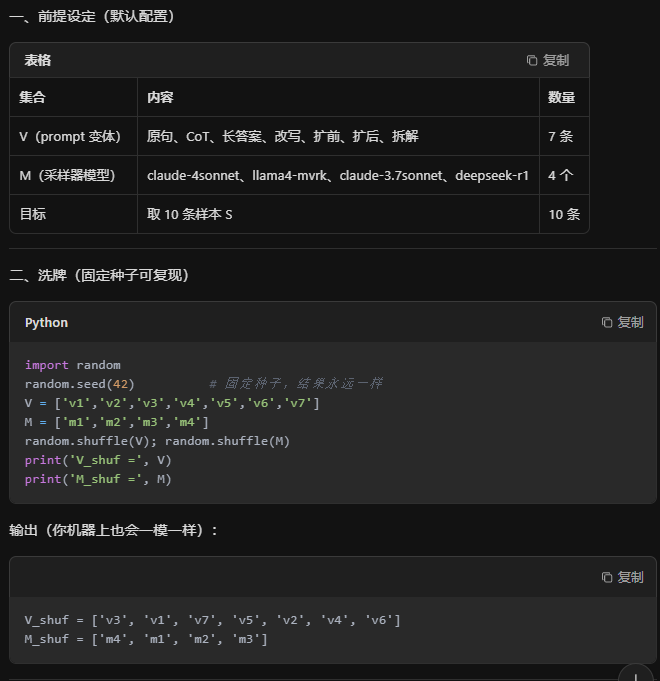
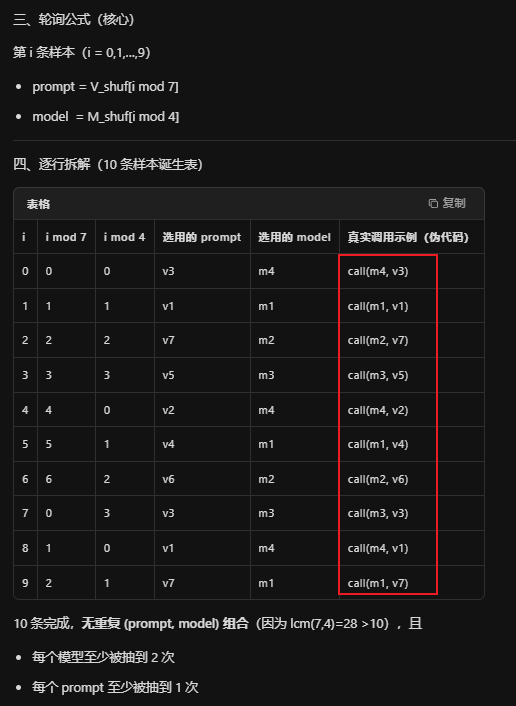
相同的种子数,就会得到相同的十对数据4 个模型 × 7 条 prompt → 最多 28 条回答,轮询顺序取 10 条作为样本集 S
【补充解释】4*7=28条,取其中的10条,这10条怎么得来的?固定随机数种子,用固定的算法得到
【"轮询顺序"就是:洗牌一次,然后按序号循环拿 prompt 和模型,10 行代码就能跑出永远相同的 10 条样本集 S】
- 解释1:
4个模型是什么?4个模型是采样器,可以包括考生模型 - 解释2:
10条怎么得来的?
如图
- 分块:
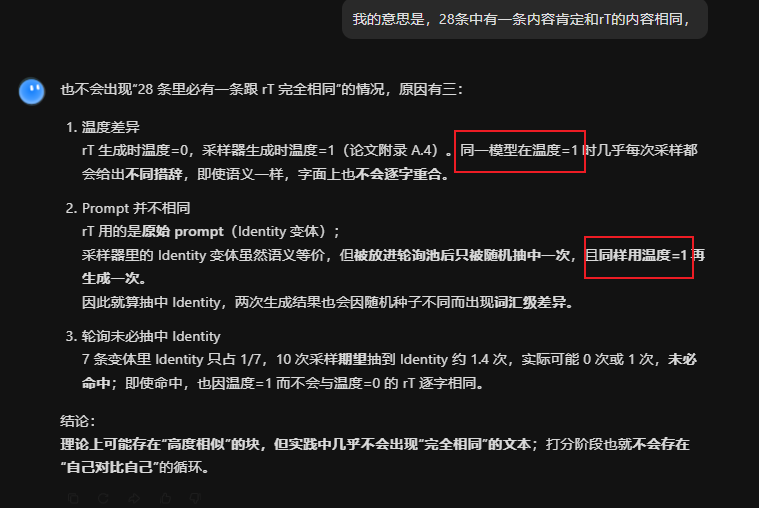
把目标模型(例如 Claude 4)的回答 rT 按句子切成块 B = {b1,...,b11}
【补充解释】

-
打擂台:
对每个块 bi,让"评委模型"J(便宜快速的 Claude 3-Haiku)把它与 10 条样本逐块对比,输出ACCURATE / NEUTRAL / CONTRADICTION
【补充解释】
-
加权投票:
给 CONTRADICTION 权重 4,ACCURATE 权重 2,NEUTRAL 权重 1,算出 bi 的幻觉分数。
分数 > 0.67 就标为"幻觉块",并生成一句错误摘要 ei
【补充解释】
结论
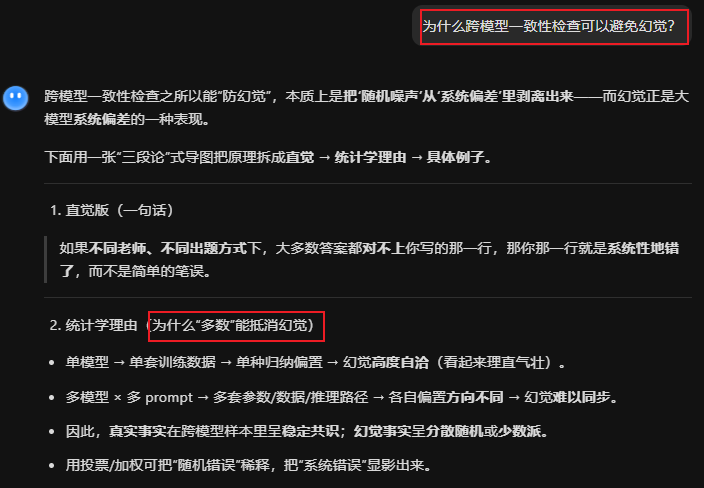
多数可以抵消幻觉
2. 精准修正(Targeted mitigation)方法
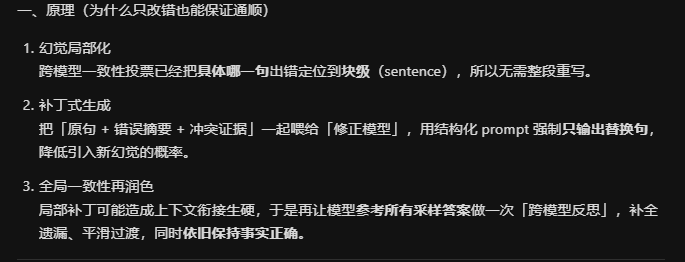
目标回答 rT
↓ 句子切分
{b1,b2...bk}
↓ 逐块 vs 样本集 S 投票
标记幻觉块 bi
↓ 1. 块级修正
生成 bi′
↓ 2. 拼接
得到 r′
↓ 3. 跨模型润色
参考 S 生成最终 r″