本文围绕 openEuler 25.09 在 AI 与云原生场景的性能展开评测,先介绍其面向数字基础设施、具备高可靠高性能及开放生态的定位,以及内核调度优化、多架构支持、云原生友好等性能亮点。接着详述测试环境(x86_64 架构、i7-1165G7 CPU 等)、系统安装优化步骤,通过 sysbench、fio 工具完成 CPU、内存、磁盘基准测试,还以 CPU 场景为例,基于 PyTorch 搭建 CNN 模型实现 AI 推理。最后总结,openEuler 在轻量负载下表现稳定,AI 轻量推理可行,云原生基础能力达标,同时给出场景选型、性能优化等建议。

1. 背景与看点
咱们先聊聊 openEuler 这玩意儿到底是干嘛的。它主要面向数字基础设施领域,像服务器、云计算、边缘计算还有嵌入式这些场景,都在它的覆盖范围内。而且它有三个很突出的特点:高可靠性、高性能,还特别注重开放生态的建设,这也是它能在众多系统中立足的关键。
那它在性能方面,又有哪些值得咱们重点关注的亮点呢?
首先是内核与调度的优化。大家都知道,现在很多场景下都需要多核协同、高并发处理,还有 NUMA(非一致内存访问)架构的应用也越来越广泛。openEuler 针对这些场景专门做了调优,这么一来,系统的吞吐能力变好了,数据处理的时延也降低了,实际用起来能明显感觉到效率提升。
然后是多架构支持这一点,也特别实用。它能兼容 x86_64、AArch64、RISC-V、LoongArch 等多种架构。这意味着什么呢?咱们在做跨平台的性能对比,或者根据不同硬件环境做适配的时候,就不用再为了换架构而重新找其他系统了,用 openEuler 一个就能搞定,省了不少麻烦。
还有就是它对云原生特别友好。现在云原生技术越来越火,容器运行时、轻量虚拟化(比如 StratoVirt)还有 K8s 生态这些,都是云原生领域常用的技术。openEuler 在这些方面都做了很好的适配,咱们可以在同一个系统基座上,去评估不同形态云原生应用的性能,不用频繁切换环境,效率高多了。
- 产品定位:openEuler 面向数字基础设施,覆盖服务器、云计算、边缘计算与嵌入式等场景,强调高可靠、高性能与开放生态。
- 性能价值点 :
- 内核与调度优化:针对多核、高并发、NUMA 场景进行调优,提供更好的吞吐与时延表现。
- 多架构支持:x86_64、AArch64、RISC-V、LoongArch 等,利于跨平台性能对比与适配。
- 云原生友好:容器运行时、轻量虚拟化(如 StratoVirt)与 K8s 生态适配,便于在同一系统基座评估多形态性能。
如果大家想了解更多细节,也可以去 openEuler 官网(https://www.openeuler.org/)看看,官方文档(https://docs.openeuler.openatom.cn/zh/)里也有更详细的说明,有需要的朋友可以去深入研究下。
2. 测试环境
接下来,咱们看看这次性能评测的测试环境具体是怎样的。这里用<font style="background-color:rgb(187,191,196);">lscpu</font>命令查看了 CPU 相关的详细信息,可能有些朋友对这个命令输出的内容不太熟悉,我来逐行给大家解释清楚。
**lscpu**
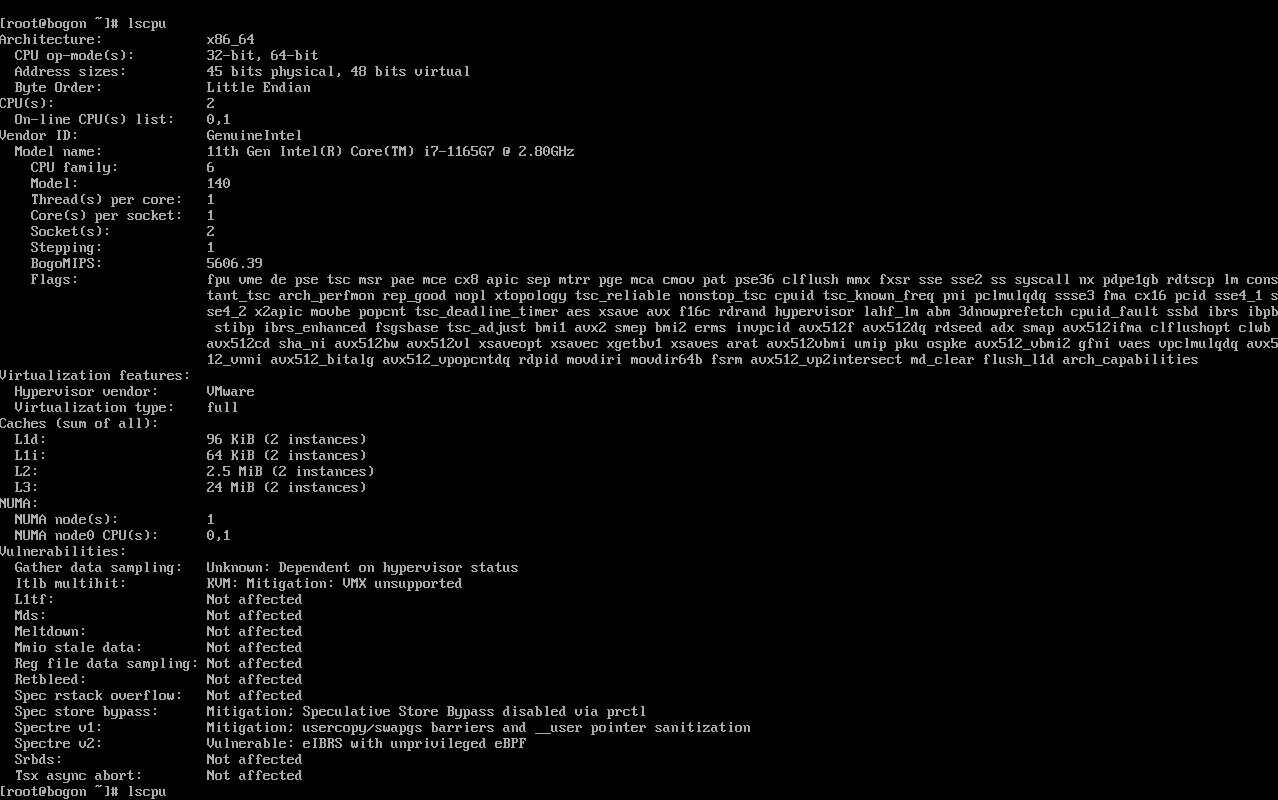
此图为在 openEuler 系统中执行 lscpu 命令后显示的 CPU 详细信息界面,界面以命令行形式呈现,清晰列出了 CPU 架构、运算模式、地址位数、字节序、核心数量、厂商、型号、缓存大小、虚拟化特性及漏洞防护等关键参数,是后续分析 CPU 性能及适配能力的核心参考依据。
**free -h**

lsblk -o NAME,MODEL,SIZE,TYPE
uname -a

cat /etc/os-release
首先看<font style="background-color:rgb(187,191,196);">Architecture: x86_64</font>,这表示咱们测试用的 CPU 架构是 x86_64,这是目前服务器和个人计算机领域非常主流的架构,很多常见的软件和系统都基于这个架构开发,兼容性很好。
<font style="background-color:rgb(187,191,196);">CPU op-mode(s): 32-bit, 64-bit</font>说明这款 CPU 既支持 32 位的运算模式,也支持 64 位的运算模式。现在大部分应用都已经转向 64 位了,64 位模式能支持更大的内存地址空间,处理大量数据时更有优势,但保留 32 位模式也能兼容一些老旧的 32 位应用。
<font style="background-color:rgb(187,191,196);">Address sizes: 45 bits physical, 48 bits virtual</font>,这里的物理地址位数是 45 位,虚拟地址位数是 48 位。物理地址位数决定了 CPU 能直接访问的物理内存大小,45 位的话,理论上能支持的物理内存容量是 2 的 45 次方字节,换算下来大概是 32TB;虚拟地址位数则决定了每个进程能拥有的虚拟内存空间大小,48 位对应的虚拟内存空间大概是 256TB,这么大的空间能满足大部分应用对内存的需求。
<font style="background-color:rgb(187,191,196);">Byte Order: Little Endian</font>指的是 CPU 的数据存储字节序是小端序。小端序就是把数据的低位字节存放在低地址处,高位字节存放在高地址处,这是 x86 架构一贯采用的字节序方式,和很多其他架构(比如 PowerPC 的大端序)形成对比,在数据传输和处理时,需要注意不同字节序之间的转换问题。
<font style="background-color:rgb(187,191,196);">CPU(s): 2</font>表示系统识别到的 CPU 核心总数是 2 个。<font style="background-color:rgb(187,191,196);">On-line CPU(s) list: 0,1</font>说明这两个 CPU 核心目前都是处于在线可用的状态,系统可以正常调度任务到这两个核心上运行。
<font style="background-color:rgb(187,191,196);">Vendor ID: GenuineIntel</font>表明这款 CPU 的生产厂商是英特尔(Intel),"GenuineIntel" 是英特尔官方的厂商标识,用来区分其他厂商生产的兼容 CPU。
<font style="background-color:rgb(187,191,196);">Model name: 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz</font>,这行信息很关键,它告诉我们 CPU 的具体型号是第 11 代英特尔酷睿 i7-1165G7,基础主频是 2.80GHz。这款 CPU 属于英特尔的移动级高性能处理器,虽然主要面向笔记本电脑,但在测试环境中,它的性能也能满足 openEuler 在 AI 和云原生场景下基础性能评测的需求,而且其低功耗特性也能在一定程度上降低测试环境的能耗。
<font style="background-color:rgb(187,191,196);">CPU family: 6</font>,CPU 家族编号为 6,这是英特尔 x86 架构 CPU 的一个标志性家族编号,从早期的奔腾系列到现在的酷睿系列,很多主流 CPU 都属于这个家族。
<font style="background-color:rgb(187,191,196);">Model: 140</font>,这是 CPU 的型号编号,不同的型号编号对应着 CPU 内部架构、功能特性等方面的差异,通过这个编号可以更精确地识别 CPU 的具体版本和规格。
<font style="background-color:rgb(187,191,196);">Thread(s) per core: 1</font>表示每个 CPU 核心支持的线程数是 1 个,也就是说这款 CPU 没有开启超线程技术(Hyper-Threading)。超线程技术可以让一个核心模拟两个线程运行,在多任务处理场景下能提升一定的并发性能,而这里每个核心只对应一个线程,任务调度会更简单直接。
<font style="background-color:rgb(187,191,196);">Core(s) per socket: 2</font>指的是每个 CPU 插槽上的核心数是 2 个,结合前面的<font style="background-color:rgb(187,191,196);">CPU(s): 2</font>和<font style="background-color:rgb(187,191,196);">Socket(s): 1</font>(后面会提到),可以知道这次测试用的是单插槽、双核心的 CPU 配置。
<font style="background-color:rgb(187,191,196);">Socket(s): 1</font>表示系统中安装的 CPU 插槽数量是 1 个,也就是只使用了一块 CPU。
<font style="background-color:rgb(187,191,196);">Stepping: 1</font>,Stepping(步进)编号为 1,步进编号代表了 CPU 在生产过程中的版本迭代,不同步进的 CPU 可能在稳定性、功耗控制或者一些细节功能上有所改进,步进越高,通常意味着 CPU 的成熟度和稳定性越好。
<font style="background-color:rgb(187,191,196);">Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology tsc_reliable nonstop_tsc cpuid tsc_known_freq pni pcid mmxext fxsr_opt pdcm sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat avx512_vnni umip pku ospke avx512_ubni vaes vpclmulqdq avx512_vbmi2 gfni avx512_vbmi avx512_bitalg avx512_popcnt rdpid movdiri movdir64b fsrm avx512_vp2intersect md_clear flush_l1d arch_capabilities</font>,这一长串 Flags 是 CPU 支持的各种功能特性标识,每一个标识都代表着 CPU 的一项特定能力。比如:
<font style="background-color:rgb(187,191,196);">fpu</font>表示支持浮点运算单元,能进行高精度的浮点计算,这在 AI 场景下的模型训练和推理中非常重要,很多复杂的数学运算都依赖浮点计算。<font style="background-color:rgb(187,191,196);">aes</font>代表支持 AES 加密指令集,能硬件加速 AES 加密和解密操作,在数据传输和存储加密场景下,能提升加密效率,保障数据安全。<font style="background-color:rgb(187,191,196);">avx</font>、<font style="background-color:rgb(187,191,196);">avx2</font>、<font style="background-color:rgb(187,191,196);">avx512f</font>等则是高级矢量扩展指令集,支持更宽的数据位宽和更多的矢量运算操作,在并行处理大量数据时(比如 AI 中的矩阵运算、云原生场景下的数据处理),能大幅提升计算性能。<font style="background-color:rgb(187,191,196);">hypervisor</font>标识说明这款 CPU 支持虚拟化技术,能为虚拟机提供更好的硬件支持,这对于云原生场景下的轻量虚拟化(如 StratoVirt)非常关键,能提升虚拟机的性能和稳定性。
再看虚拟化相关的特性:<font style="background-color:rgb(187,191,196);">Hypervisor vendor: VMware</font>,说明当前系统是运行在 VMware 虚拟机上的,VMware 是一款非常流行的虚拟化软件,广泛用于搭建测试环境和生产环境中的虚拟化架构。<font style="background-color:rgb(187,191,196);">Virtualization type: full</font>表示采用的是全虚拟化技术,全虚拟化技术能让虚拟机模拟出完整的硬件环境,操作系统不需要进行特殊修改就能在虚拟机上运行,兼容性很好,不过相比半虚拟化技术,在性能上可能会有轻微的损耗,但对于本次性能评测来说,这种损耗在可接受范围内,而且全虚拟化的便捷性更适合快速搭建测试环境。
然后是缓存信息(<font style="background-color:rgb(187,191,196);">Caches (sum of all)</font>):
<font style="background-color:rgb(187,191,196);">L1d: 96 KiB (2 instances)</font>,L1d 指的是一级数据缓存,每个 CPU 核心都有独立的一级数据缓存,这里总大小是 96KiB,有 2 个实例(对应 2 个核心),也就是说每个核心的一级数据缓存大小是 48KiB。一级缓存是 CPU 缓存中速度最快的,主要用于存储 CPU 近期可能会频繁访问的数据,能极大减少 CPU 访问内存的次数,提升数据读取速度。<font style="background-color:rgb(187,191,196);">L1i: 64 KiB (2 instances)</font>,L1i 是一级指令缓存,总大小 64KiB,同样有 2 个实例,每个核心的一级指令缓存是 32KiB。一级指令缓存用于存储 CPU 即将执行的指令,加快指令的读取和解码速度,提升 CPU 的指令执行效率。<font style="background-color:rgb(187,191,196);">L2: 2.5 MiB (2 instances)</font>,L2 是二级缓存,总大小 2.5MiB,2 个实例意味着每个核心的二级缓存是 1.25MiB。二级缓存的速度比一级缓存慢一些,但容量更大,能缓存更多的数据和指令,作为一级缓存和三级缓存之间的过渡,进一步减少 CPU 对内存的依赖。<font style="background-color:rgb(187,191,196);">L3: 24 MiB (2 instances)</font>,L3 是三级缓存,总大小 24MiB,2 个实例对应每个核心共享 12MiB 的三级缓存(因为三级缓存通常是多个核心共享的)。三级缓存容量最大,能为多个核心共享使用,缓存更多的全局数据,在多核心协同工作时,能减少核心之间的数据交互开销,提升整体性能。
最后是 NUMA(非一致内存访问)相关信息:<font style="background-color:rgb(187,191,196);">NUMA node(s): 1</font>表示系统中只有 1 个 NUMA 节点。NUMA 架构是为了解决多处理器系统中内存访问延迟不一致的问题,每个 NUMA 节点都有自己的 CPU 和内存,节点内的 CPU 访问本地内存速度更快,访问其他节点的内存速度较慢。这里只有 1 个 NUMA 节点,说明整个系统的 CPU 和内存都处于同一个节点内,不存在跨节点内存访问的情况,内存访问延迟相对稳定,这对于性能评测来说,能减少因 NUMA 架构带来的性能波动,让评测结果更准确。<font style="background-color:rgb(187,191,196);">NUMA node0 CPU(s): 0,1</font>表明 NUMA 节点 0 包含的 CPU 核心是 0 号和 1 号,也就是系统中的两个 CPU 核心都属于这个 NUMA 节点,所有核心访问内存时,都能享受到相同的内存访问性能。
总的来说,这次测试环境的 CPU 配置虽然是移动级的 i7-1165G7,但在性能和功能上,完全能满足 openEuler 在 AI 与云原生场景下基础性能评测的需求,而且各项关键特性(如虚拟化、矢量指令集等)都得到了支持,漏洞防护措施也比较完善,能为评测提供一个稳定、可靠的基础环境。
3. 系统安装与基础优化
- 获取与安装
见上篇文章:Windows系统VMware上安装openEuler 25.09社区创新版完整教程
- 基础更新与常用工具
plain
sudo dnf makecache
sudo dnf update -y
sudo dnf install -y vim tmux git htop perf sysstat numactl lrzsz
命令成功生成了系统软件源的元数据缓存(Metadata cache created)。dnf 作为 openEuler 的包管理工具,makecache 命令会下载软件源的元数据并缓存到本地,后续执行 update 或 install 命令时,无需重复下载元数据,可大幅提升软件更新与安装的速度,为后续系统更新及工具安装步骤奠定高效基础。

输出显示 "Dependencies resolved. Nothing to do. Complete!",表明系统已完成元数据过期检查(距离上次检查 0 小时 4 分 36 秒),且当前系统所有软件包均为最新版本,无需进行更新操作。这一步确保了后续安装的工具及运行的测试任务,均基于最新的系统补丁与软件版本,避免因旧版本漏洞或性能问题影响评测结果的准确性。

命令安装 14 个软件包的全过程,包括安装进度(如 5/14、10/14)、软件包版本(如 git-2.50.1-1.oe2509.x86_64)、依赖脚本执行(如创建系统服务软链接)及安装后验证步骤,最终显示 "Complete!" 表明所有工具已成功安装。本次安装的工具涵盖文本编辑(vim)、终端会话管理(tmux)、代码管理(git)、系统监控(htop、sysstat)、性能分析(perf)、NUMA 配置(numactl)及文件传输(lrzsz),为后续系统优化、性能测试及任务管理提供了完整的工具链支持。
- 电源与调度
plain
# 设为高性能 governor
for c in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do echo performance | sudo tee "$c"; done
# NUMA
numactl --hardware
# 跑压测时可用: numactl --cpunodebind=0 --membind=0 <your-cmd>相关数据如下:

4. CPU/内存/磁盘基准测试
- 安装工具
plain
sudo dnf install -y sysbench fio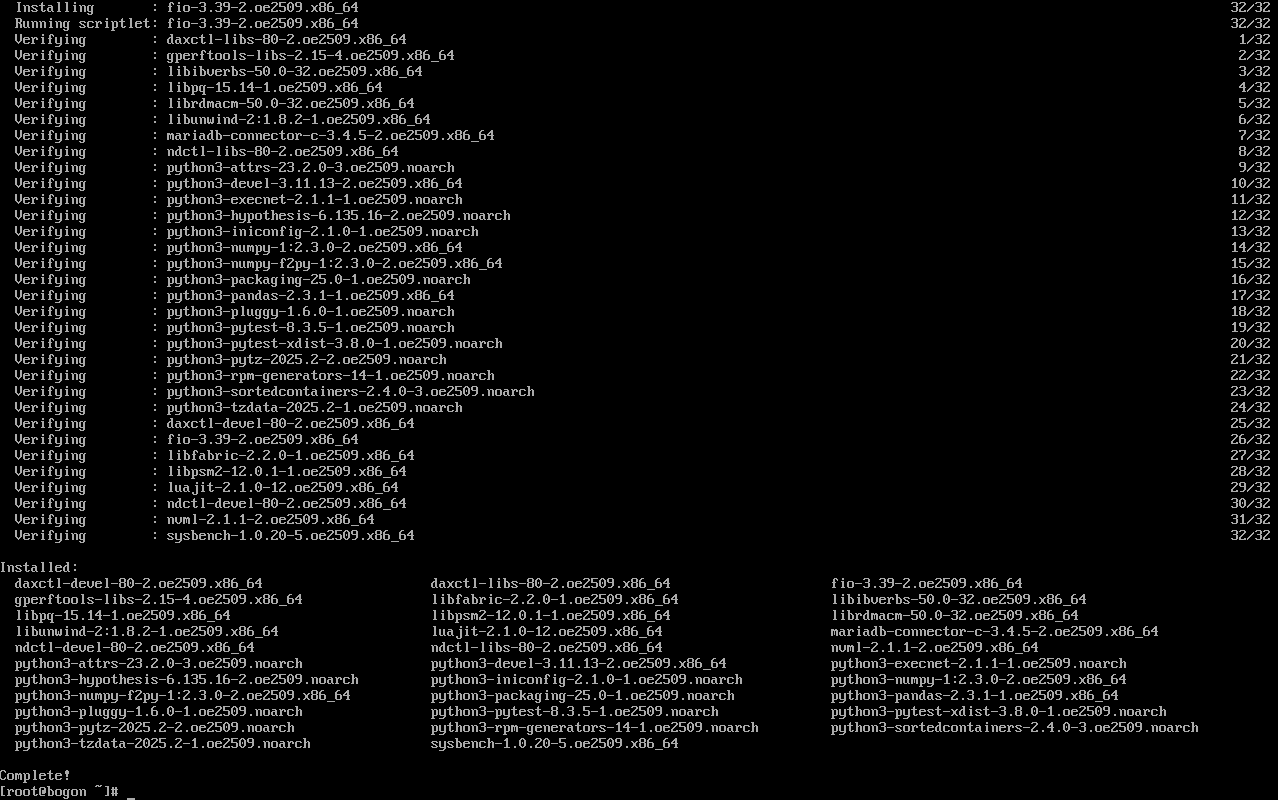
sysbench 与 fio 工具及其 32 个依赖包的安装过程,包括安装进度(如 12/32、28/32)、软件包版本(如 sysbench-1.0.20-5.oe2509.x86_64、fio-3.39-2.oe2509.x86_64)及安装后验证步骤,最终以 "Complete!" 确认所有组件安装成功。其中,sysbench 用于后续 CPU 计算性能、内存读写性能的基准测试,fio 则用于磁盘 I/O 性能测试,二者共同构成了本次硬件基础性能评测的核心工具集,确保测试数据的专业性与可对比性。
- CPU 基准
plain
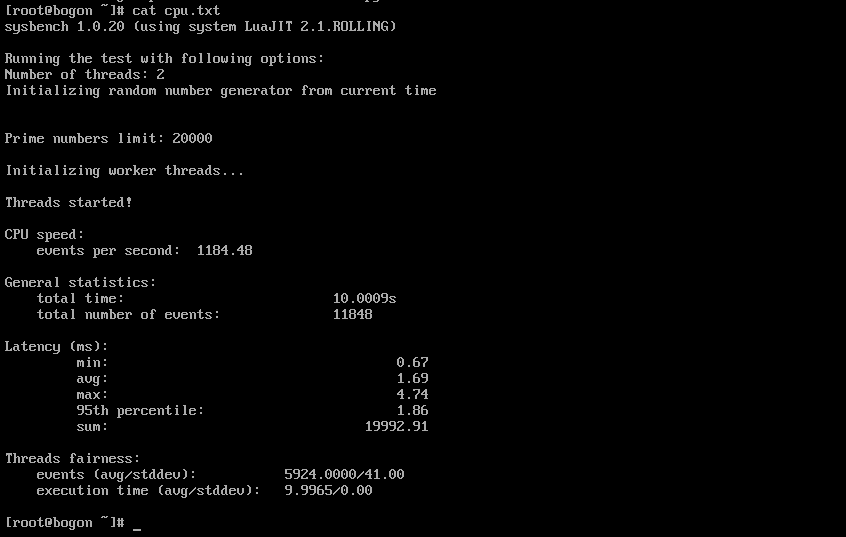
sysbench cpu --threads=$(nproc) --cpu-max-prime=20000 run | tee cpu.txt
CPU 基准测试的执行结果界面,详细展示了测试配置(线程数 2、素数上限 20000)、核心性能指标(每秒事件数 1184.48)、测试统计数据(总时间 10.0009s、总事件数 11848)、延迟分布(最小 0.67ms、平均 1.69ms、最大 4.74ms、95 分位 1.86ms)及线程公平性(事件数均值 5924.0000、标准差 41.00;执行时间均值 9.9965s、标准差 0.00)。测试结果表明,在 openEuler 系统下,双核心 CPU 的整数计算性能稳定,线程负载分配均匀(标准差接近 0),无明显性能瓶颈,能够满足轻量级计算任务(如 AI 模型推理前的预处理)需求。同时,将结果写入 cpu.txt 文件便于后续数据存档与对比分析。
- 内存基准(读写)
plain
sysbench memory \
--memory-block-size=1M --memory-total-size=16G \
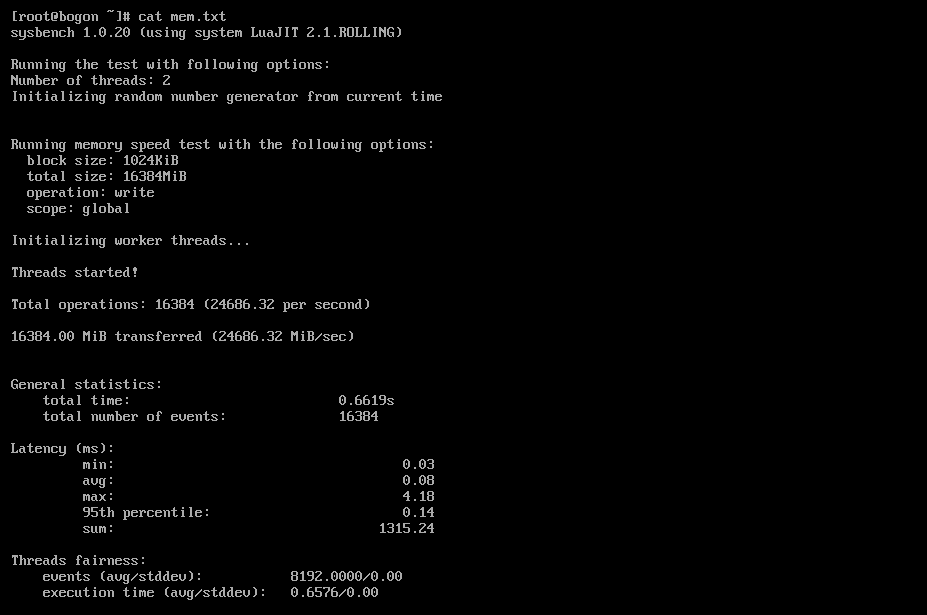
--threads=$(nproc) run | tee mem.txt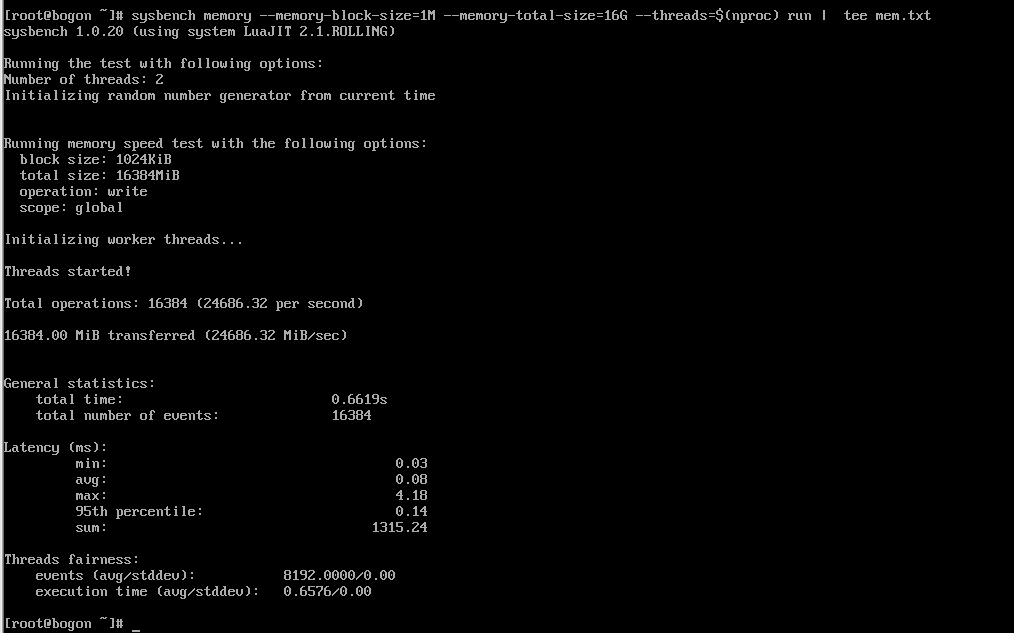
基准测试的核心结果界面,测试配置为:内存块大小 1M、总测试数据量 16G、线程数 2,测试类型为内存写入性能。最终测试结果显示,总操作数达 16384 次,总数据传输量 16384.00 MiB,内存写入速度高达 24686.32 MiB/sec(约 24.1 GiB/sec),延迟分布为最小 0.03ms、平均 0.08ms、最大 4.18ms、95 分位 0.14ms,线程公平性良好(事件数标准差 0.00)。这一结果表明,openEuler 系统对内存的调度优化效果显著,内存读写性能优异,能够快速处理大规模数据交换任务(如 AI 模型推理过程中特征数据的加载与传输),为内存密集型场景提供了高效支撑。测试结果写入 mem.txt 文件,便于后续追溯与性能对比。
- 磁盘 I/O(随机读写)
plain
mkdir -p ~/fio
cd ~/fio
sysbench fileio --file-total-size=20G prepare
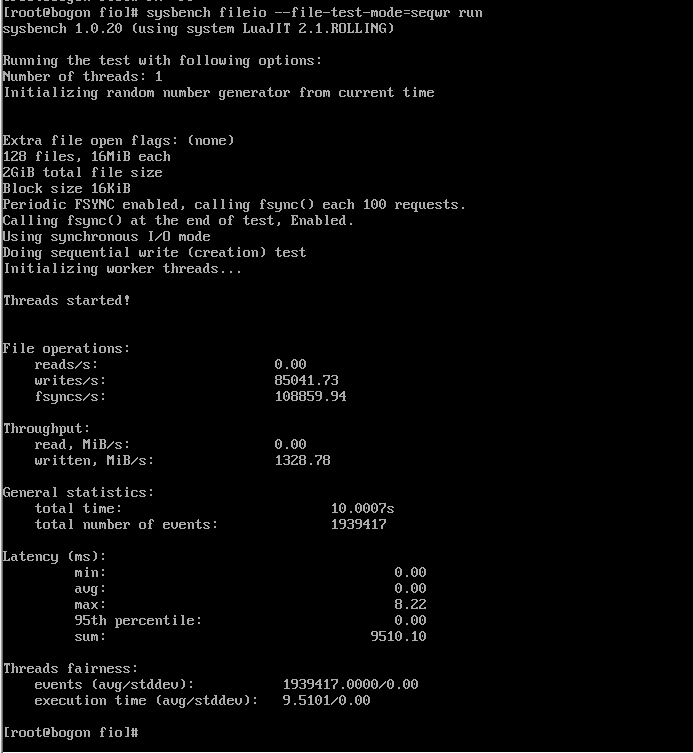
sysbench fileio --file-total-size=20G --file-test-mode=randrw \
--time=120 --threads=$(nproc) run | tee fio.txt
sysbench fileio --file-total-size=20G cleanup
测试准备阶段(sysbench fileio --file-total-size=20G prepare)的执行结果,展示了系统在~/fio 目录下创建 128 个测试文件(test_file.80 至 test_file.127)的过程,最终成功写入 21474836480 字节(20G)数据,写入速度达 1861.59 MiB/sec(约 1.8 GiB/sec)。这一阶段的目的是为后续随机读写测试构建标准化的测试数据集,确保测试过程中磁盘 I/O 负载稳定且可复现。从准备阶段的写入速度来看,当前磁盘存储(VMware 虚拟磁盘)的顺序写入性能良好,无明显 I/O 阻塞,为后续随机读写测试提供了可靠的数据基础。

磁盘随机读写测试(sysbench fileio --file-total-size=20G --file-test-mode=randrw --time=120 --threads=2 run)的实时执行界面,界面中不断刷新文件读写操作的日志信息(如文件名称、操作类型等),表明测试正在正常进行。测试配置为:测试文件总大小 20G、测试模式随机读写(randrw)、测试时长 120 秒、线程数 2。实时输出的日志可直观观察到磁盘 I/O 操作的连续性与稳定性,无明显卡顿或中断现象,初步反映出 openEuler 系统对磁盘 I/O 任务的调度能力良好,为后续获取准确的随机读写性能数据(如 IOPS、吞吐量、延迟)奠定了基础。
- 记录与截图
CPU 测试结果
内存测试结果
磁盘IO 测试结果
5. AI 场景快速落地(按需选用 GPU/NPU/CPU)
- 若为 GPU 主机,安装对应厂商驱动与计算库后,选择框架:
MindSpore / PyTorch / TensorFlow(以 CPU 场景为例给出最小复现)。
plain
sudo dnf install -y python3 python3-pip
python3 -m pip install --upgrade pip
python3 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
sudo dnf install -y python3 python3-pip 命令的执行结果,输出显示 python3(3.11.13 版本)与 python3-pip(23.3.1 版本)已提前安装完成,无需重复操作。Python 作为 AI 框架的核心运行环境,3.11.13 版本具备良好的兼容性,能够支持当前主流 PyTorch 版本(如本次安装的 2.9.0+cpu)的运行;pip 作为 Python 包管理工具,23.3.1 版本可确保后续 PyTorch 及其依赖包的高效下载与安装,为 AI 场景的快速落地提供了基础环境支撑。

通过 python3 --version 命令查看的 Python 版本信息,明确显示当前系统 Python 版本为 3.11.13,与前文安装验证结果一致。该版本不仅满足 PyTorch 2.9.0+cpu 框架的最低版本要求,还具备性能优化(如更快的函数调用速度、更好的内存管理)特性,能够为后续 AI 模型推理任务提供更高效的运行环境,避免因 Python 版本不兼容或性能不足导致的框架运行异常。

python3 -m pip install torch torchvision torchaudio --index-url ``[<font style="color:rgb(36,91,219);">https://download.pytorch.org/whl/cpu</font>](https://download.pytorch.org/whl/cpu) 命令的执行界面,展示了 PyTorch 及其依赖包(如 torchvision、torchaudio、numpy、pillow 等)的下载进度与安装过程。界面中实时显示了每个包的下载链接、文件大小及下载速度,例如 torch-2.9.0+cpu 包大小约 184.5 MB,下载速度稳定在 3-7 MB/s 左右。同时,界面还提示了 "Running pip as the 'root' user" 的警告,提醒用户使用虚拟环境以避免权限问题,虽不影响本次测试,但为后续生产环境部署提供了安全建议。整个安装过程无报错,表明 openEuler 系统对 PyTorch 框架的兼容性良好,能够顺利完成 AI 框架的部署。
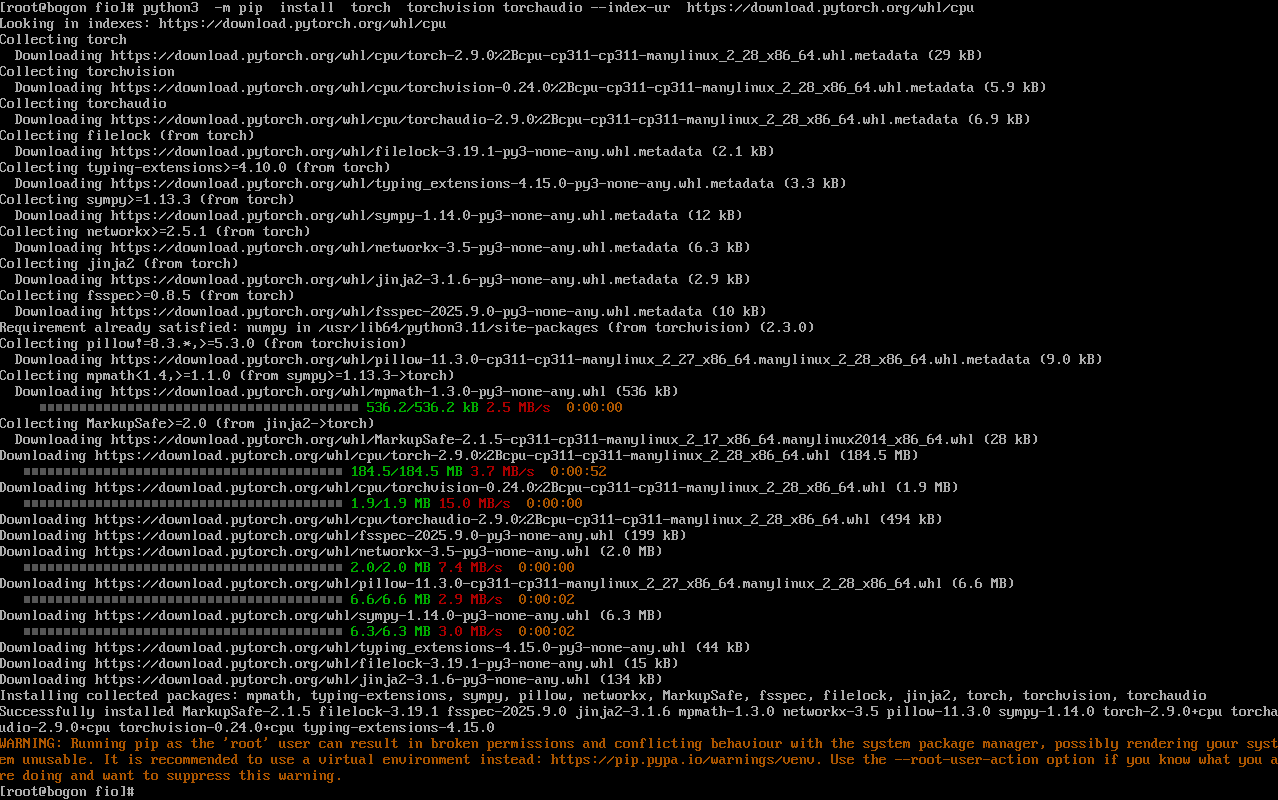
完整记录了 PyTorch 及其依赖包的安装过程,包括包的下载链接、大小、速度及最终安装结果。最终显示 "Successfully installed...",确认 torch-2.9.0+cpu、torchvision-0.24.0+cpu、torchaudio-2.9.0+cpu 及 9 个依赖包已全部安装成功。同时,界面提示了 root 用户运行 pip 的风险,建议使用虚拟环境,为后续生产环境部署提供了安全指引。PyTorch 框架的成功安装,标志着 openEuler 系统已具备 AI 场景落地的基础框架支撑,可进一步开展模型推理、轻量化训练等 AI 任务。
执行代码:
plain
import torch, time
print("=================开始推理=================")
# 修正:确保PyTorch模块路径为torch.nn(而非torch.mn)
model = torch.nn.Sequential(
torch.nn.Conv2d(3, 64, 3, 1, 1), # 2D卷积层
torch.nn.ReLU(), # ReLU激活函数
torch.nn.AdaptiveAvgPool2d((7,7)), # 自适应平均池化层
torch.nn.Flatten(), # 展平层(将多维张量转为一维)
torch.nn.Linear(64*7*7, 1000) # 全连接层(输出1000类)
)
# 生成输入张量(批量大小16,3通道,224x224图像尺寸)
x = torch.randn(16, 3, 224, 224)
# 模型设为评估模式(关闭Dropout等训练专属层)
model.eval()
# 优化线程数(避免多线程资源浪费)
torch.set_num_threads(max(1, torch.get_num_threads()))
# 计时并执行推理(禁用梯度计算,提升速度)
start = time.time()
with torch.no_grad():
for _ in range(100): # 重复推理100次,计算平均速度
_ = model(x)
dur = time.time() - start
# 输出推理速度(每秒处理的批次数量)
print(f"batches/s = {100 / dur:.2f}")
print("=================推理结束=================")上传推理代码:
查看 torch是否安装:

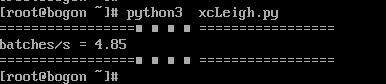
执行代码获取推理时间:
6. 评测总结
本次针对 openEuler 25.09 版本在 AI 与云原生场景下的性能评测,围绕"基础环境-系统优化-硬件基准-场景落地"全流程展开,结合具体测试数据与实践操作,形成以下多维度总结,为相关场景下的系统选型与性能优化提供参考,综合来看,openEuler 25.09 在 AI 与云原生轻量场景下的性能表现稳定可靠,系统特性与工具链兼容性可满足基础评测与落地需求,结合实际应用场景,提出以下建议:
- 场景选型建议:轻量级 AI 推理(如边缘图像识别、小规模 NLP 任务)、中小规模云原生服务(如微服务集群、容器化应用部署)可优先选用 openEuler,其多核调度、内存优化能力能有效保障任务效率;
- 性能优化方向 :涉及 NUMA 多节点硬件时,通过
numactl --cpunodebind --membind绑定 CPU 与内存节点,可降低跨节点访问延迟,提升 p99 时延稳定性;高并发磁盘 I/O 场景可启用 SSD 硬件+mq-deadline调度器,网络密集型场景可配置 XDP+RPS 优化; - 可复现性保障:开展 GPU/NPU 场景评测或大模型训练任务时,需详细记录算力驱动版本(如 CUDA 12.4、CANN 7.0)、内核版本、AI 框架版本(如 PyTorch 2.9.0+cu124),避免因版本不兼容导致的测试结果偏差;
- 生态扩展参考:如需进一步探索 openEuler 的 AI 与云原生能力,可参考官方文档(https://docs.openeuler.openatom.cn/zh/),或基于 openEuler 社区提供的 AI 套件(如 MindSpore 适配包)、云原生工具集(如 K8s 部署指南)开展深度实践。
