原文链接:https://arxiv.org/pdf/2112.11790
代码链接:https://github.com/HuangJunJie2017/BEVDet
沐小含持续分享前沿算法论文,欢迎关注...
一、引言
在自动驾驶领域,环境感知是决策系统的核心支撑,而 3D 目标检测作为感知任务的关键环节,直接影响自动驾驶系统对周围物体位置、尺度、姿态和速度的判断精度。随着 2D 视觉感知技术的飞速发展,Mask R-CNN 等高性能、可扩展且支持多任务的范式层出不穷,但在自动驾驶场景中,3D 目标检测与鸟瞰图(BEV)语义分割等核心任务仍采用不同的技术范式,难以兼顾精度与效率,也限制了多任务学习的落地。
当前主流的多相机 3D 目标检测方法(如 FCOS3D、PGD)多基于图像视角进行感知,虽在部分指标上表现尚可,但在目标平移、速度和姿态估计等方面存在明显短板;而 BEV 语义分割任务则被基于 BEV 视角的方法(如 PON、Lift-Splat-Shoot)主导。这引发了一个关键问题:哪种视角空间更适合自动驾驶感知任务?能否构建一个统一框架同时处理这些任务?
为解决上述问题,本文提出了BEVDet范式,首次将 BEV 视角应用于多相机 3D 目标检测,通过模块化设计复用现有成熟组件,并针对 BEV 空间的特性优化数据增强策略和非极大值抑制(NMS)算法,实现了精度与效率的优异平衡。实验表明,BEVDet-Tiny 版本在 nuScenes 验证集上达到 31.2% mAP 和 39.2% NDS,仅需 215.3 GFLOPs 的计算量(为 FCOS3D 的 11%),推理速度达 15.6 FPS(是 FCOS3D 的 9.2 倍);高精度版本 BEVDet-Base 更是以 39.3% mAP 和 47.2% NDS 的成绩大幅超越现有方法,为自动驾驶 3D 感知提供了全新的高效解决方案。
二、相关工作综述
2.1 基于视觉的 2D 感知
2D 视觉感知的复兴始于 AlexNet 在图像分类任务的突破,随后残差网络(ResNet)、高分辨率网络(HRNet)、注意力机制网络(如 Vision Transformer)等结构不断刷新图像编码器的性能上限,进而推动了目标检测、语义分割、人体姿态估计等复杂任务的发展。
在目标检测领域,两阶段方法(如 Faster R-CNN)、单阶段方法(如 RetinaNet)及其衍生模型长期占据主导地位。受 Mask R-CNN 启发,多任务学习凭借共享骨干网络节省计算资源、联合训练提升任务性能的优势,成为科研与工业界的研究热点。2D 感知领域的范式创新,为自动驾驶场景中更复杂的多任务感知提供了重要启发。
2.2 鸟瞰图语义分割
自动驾驶中的环境地图重建任务,可通过 BEV 语义分割实现(如可行驶区域、车道线、停车区等目标的分割)。当前主流的 BEV 语义分割方法采用统一的模块化框架:图像视角编码器(提取图像特征)→视角转换器(将图像特征转换为 BEV 特征)→BEV 编码器(优化 BEV 特征)→分割头(像素级分类)。
该框架在 BEV 语义分割任务中的成功,验证了 BEV 视角在捕捉空间关系、尺度信息上的优势,也为本文将其扩展到 3D 目标检测任务提供了理论基础 ------ 期望 BEV 空间的特征能更好地建模 3D 目标的尺度、姿态和速度等关键信息,同时为多任务学习(3D 检测 + BEV 分割)提供统一范式。
2.3 基于视觉的 3D 目标检测
早期 3D 目标检测研究主要依赖 KITTI 数据集,但单视角、小样本的局限性限制了复杂任务的发展。近年来,nuScenes、Waymo Open Dataset 等大规模多相机数据集的发布,推动了多相机 3D 目标检测范式的革新,主流方法可分为三类:
- 图像视角主导方法:如 FCOS3D 将 3D 检测转化为 2D 检测任务,利用图像外观与目标属性的空间相关性实现高效推理,但在平移、速度和姿态估计上表现较差;PGD 通过优化深度预测提升精度,但代价是计算量和 latency 增加。
- Transformer-based 方法:如 DETR3D 采用注意力机制进行 3D 检测,计算量仅为 FCOS3D 的一半,但复杂的计算流程导致推理速度未能提升。
- BEV 视角探索方法:部分先驱工作(如 Categorical Depth Distribution Network)尝试将 BEV 视角应用于单目 3D 检测,但依赖激光雷达(LiDAR)进行深度监督,实用性受限;并发工作 DD3D 虽不依赖 LiDAR,但未针对 BEV 空间的特性设计专门的优化策略。
现有方法在精度与效率的平衡上存在明显瓶颈,而 BEVDet 通过定制化数据增强和 NMS 优化,首次实现了不依赖 LiDAR 的高性能多相机 BEV 3D 检测,填补了该领域的空白。
三、BEVDet 核心技术详解
3.1 网络结构设计
BEVDet 采用模块化设计,整体框架与 BEV 语义分割方法一脉相承,但针对 3D 目标检测任务优化了各组件的参数和交互逻辑。其结构由四大核心模块组成,如图 1 所示:
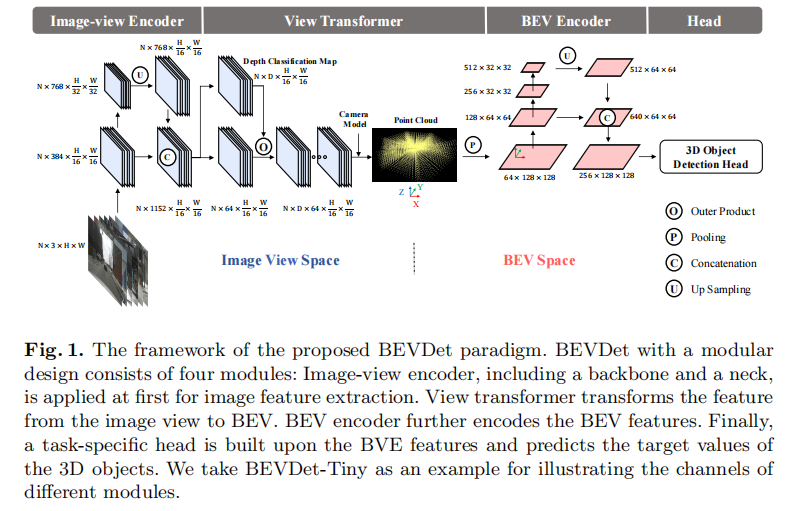
3.1.1 图像视角编码器(Image-view Encoder)
负责将多相机输入图像编码为高维特征,由骨干网络(Backbone) 和颈部网络(Neck) 组成:
- 骨干网络:默认采用 ResNet 和 SwinTransformer(如 BEVDet-Tiny 用 SwinTransformer-Tiny,BEVDet-R50 用 ResNet-50),也支持 DenseNet、HRNet 等替代结构,用于提取图像的高级语义特征。
- 颈部网络:采用 FPN(Feature Pyramid Network)或 FPN-LSS(Lift-Splat-Shoot 中提出的 FPN 变体),其中 FPN-LSS 通过将 1/32 分辨率的特征上采样至 1/16,并与骨干网络生成的 1/16 分辨率特征拼接,实现多尺度特征融合。
以 BEVDet-Tiny 为例,输入图像经过编码器后,输出特征维度为 N×768×(H/16)×(W/16)(N 为相机数量,H、W 为输入图像高度和宽度)。
3.1.2 视角转换器(View Transformer)
核心功能是将图像视角特征转换为 BEV 空间特征,采用 Lift-Splat-Shoot 提出的实现方案,具体流程如下:
- 深度分类:对图像特征进行密集深度预测,输出深度分类图(N×D×(H/16)×(W/16),D 为深度区间数量);
- 3D 点云渲染:结合相机内参矩阵,将图像像素映射到 3D 空间(公式 1 ),并利用深度分类分数和图像特征渲染预定义点云;
- BEV 特征生成:沿垂直方向(Z 轴)对 3D 点云特征进行池化操作,得到 BEV 特征图。
BEVDet 扩展了默认的深度预测范围至 1, 60 米,深度区间间隔为 1.25×r(r 为 BEV 输出分辨率),确保对不同距离目标的覆盖。
3.1.3 BEV 编码器(BEV Encoder)
对视角转换器输出的 BEV 特征进行进一步优化,结构与图像视角编码器类似(骨干网络 + 颈部网络):
- 骨干网络:采用 ResNet 的经典残差块,如 BEVDet-Tiny 使用 2×Basic-128 结构(2 个残差块,输出通道数 128);
- 颈部网络:同样采用 FPN-LSS,实现 BEV 空间多尺度特征融合,增强对不同尺度目标的感知能力。
BEV 编码器的关键优势在于,其直接在 BEV 空间建模,而 3D 目标的尺度、姿态、速度等属性在 BEV 空间中定义更直观,因此能更精准地捕捉这些关键信息。
3.1.4 任务特定头(Task-specific Head)
基于优化后的 BEV 特征进行 3D 目标检测,直接复用 CenterPoint 第一阶段的检测头,无需修改即可输出目标的位置、尺度、姿态、速度等预测结果,便于与 LiDAR-based 方法(如 PointPillar、VoxelNet)进行公平对比。
各模块的详细参数配置如表 1 所示,不同版本(Tiny/Base/R50/R101)通过调整骨干网络类型、通道数、输入分辨率等参数,实现精度与效率的不同权衡。
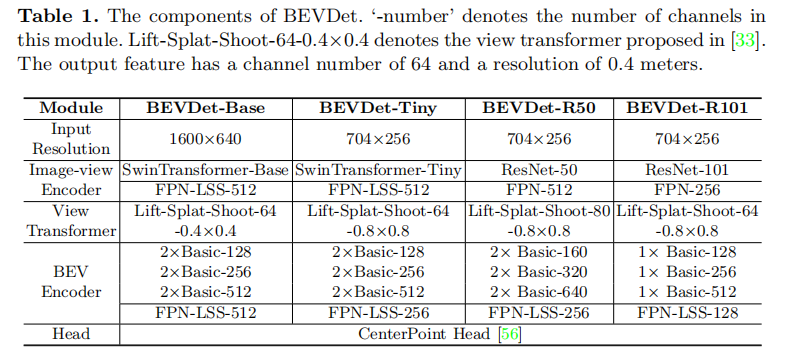
注:"-number" 表示模块通道数;Lift-Splat-Shoot-64-0.4×0.4 表示输出通道数 64,BEV 分辨率 0.4 米 / 像素。
3.2 定制化数据增强策略
BEVDet 在训练过程中面临一个关键问题:BEV 空间的过拟合。其根源在于:
- 视角转换器以像素级方式将图像特征映射到 BEV 空间,导致图像视角的数据增强无法对 BEV 编码器和检测头产生正则化效果;
- 每个训练样本包含多个相机图像(如 nuScenes 数据集每个样本含 6 张图),BEV 空间的有效训练数据量远少于图像视角。
为解决该问题,BEVDet 提出双空间数据增强策略,分别在图像视角和 BEV 视角进行增强,确保模型的泛化能力。
3.2.1 图像视角数据增强(IDA)
由于视角转换器的像素级映射特性,图像视角的增强操作(如翻转、裁剪、旋转)可通过逆变换矩阵保持 BEV 空间的特征与目标空间一致性(公式 2)。具体来说,若图像像素经过变换矩阵 A 处理(),则在 3D 映射时引入逆矩阵
,可确保 3D 坐标不变(
)。
公式 1:3D 空间坐标映射( 为 3×3 相机内参矩阵,
为像素深度)
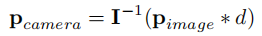
公式 2:增强后的空间一致性保持
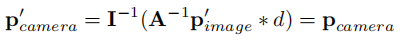
IDA 的主要作用是增强图像特征的多样性,但实验表明,仅当 BEV 编码器不存在时,IDA 才能带来正向收益;当 BEV 编码器存在时,IDA 需与 BEV 视角增强配合才能发挥作用。
3.2.2 BEV 视角数据增强(BDA)
针对 BEV 空间数据量不足的问题,借鉴 LiDAR-based 方法的增强策略,对 BEV 特征和 3D 检测目标同时进行翻转、缩放、旋转操作,确保增强后的数据仍保持空间一致性。具体参数:
- 旋转范围:-22.5°, 22.5°
- 缩放范围:0.95, 1.05
- 翻转:随机水平 / 垂直翻转
BDA 是解决 BEV 空间过拟合的核心,实验证明其能显著提升模型的峰值性能和训练稳定性。
3.3 Scale-NMS:适配 BEV 空间的非极大值抑制
经典 NMS 算法基于交并比(IOU)筛选预测框,适用于图像视角(所有类别目标的空间分布相似),但在 BEV 空间中存在明显缺陷:
- BEV 空间中不同类别目标的占据面积差异极大(如行人、交通锥的面积远小于车辆);
- 小目标的预测框可能与真实框无交叠(IOU=0),导致经典 NMS 无法区分真阳性和假阳性预测,从而保留冗余结果。
为解决该问题,BEVDet 提出Scale-NMS,核心思想是:在执行 NMS 前,根据目标类别对预测框进行尺度缩放,使不同类别目标的 IOU 分布与经典 NMS 的假设匹配。具体流程如图 2 所示:
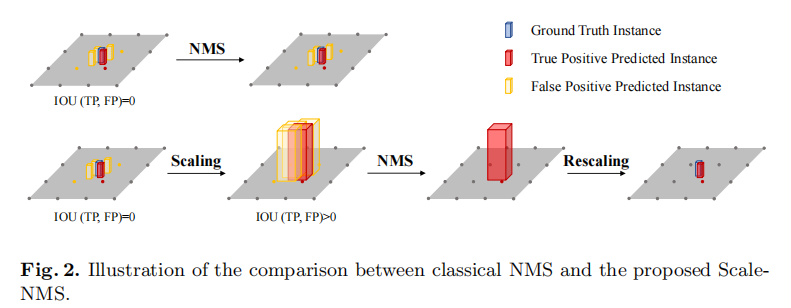
- 对于行人、交通锥等小目标:放大预测框,使冗余预测与真实框产生交叠(IOU>0),便于 NMS 筛选;
- 对于车辆、巴士等大目标:适当缩放预测框,保持 IOU 分布合理性;
- 屏障(barrier)类别:因尺寸差异大,不进行缩放。
缩放因子通过在验证集上进行超参数搜索确定,确保对每个类别最优。
四、实验验证与分析
4.1 实验设置
4.1.1 数据集与评价指标
- 数据集:采用 nuScenes 数据集,包含 1000 个场景(700 训练 / 150 验证 / 150 测试),6 个相机视角,1.4M 个 3D 标注框(10 个类别);感兴趣区域(ROI)为地面 51.2 米范围内,默认分辨率 0.8 米 / 像素。
- 评价指标:采用 nuScenes 官方指标,包括平均精度(mAP)、NuScenes 检测分数(NDS,综合翻译误差 ATE、尺度误差 ASE、姿态误差 AOE 等指标),以及各分项误差(ATE/ASE/AOE/AVE/AAE)。
4.1.2 训练与推理配置
- 训练参数:AdamW 优化器,梯度裁剪;ResNet 骨干网络采用阶梯学习率(epoch 17、20 时衰减 0.1),SwinTransformer 采用循环学习率(前 40% 线性上升至 1e-3,后 60% 线性下降至 0);总 epoch=20,批量大小 = 64(8 张 RTX 3090 GPU)。
- 数据处理:训练时图像视角采用随机翻转、缩放(s∈W_in/1600-0.06, W_in/1600+0.11)、旋转(r∈-5.4°,5.4°)和裁剪;BEV 视角采用翻转、旋转、缩放增强;测试时图像缩放因子 s=W_in/1600+0.04,固定区域裁剪。
- 推理速度:基于 MMDetection3D 框架,所有速度和计算量测试均关闭数据增强;单目方法(如 FCOS3D)的速度需除以 6(相机数量)以公平对比。
4.2 基准测试结果
4.2.1 nuScenes 验证集结果
BEVDet 的两个版本(Tiny/Base)与主流方法的对比如表 2 所示,核心优势体现在:
- 效率领先:BEVDet-Tiny 输入分辨率仅 704×256(为 FCOS3D 的 1/8),计算量 215.3 GFLOPs(FCOS3D 的 11%),推理速度 15.6 FPS(FCOS3D 的 9.2 倍),但 mAP(31.2%)和 NDS(39.2%)均超越 FCOS3D(29.5% mAP、37.2% NDS)和 DETR3D(30.3% mAP、37.4% NDS)。
- 精度顶尖:BEVDet-Base 输入分辨率 1600×640,mAP 达 39.3%,NDS 达 47.2%,大幅超越 PGD(33.5% mAP、40.9% NDS),即使计算量较高(2962.6 GFLOPs),推理速度仍达 1.9 FPS(与 DETR3D 相当)。
- 分项误差优异:BEVDet 在 ATE(翻译误差)、AOE(姿态误差)、AVE(速度误差)上表现突出,验证了 BEV 视角对空间属性建模的优势;但 AAE(属性误差)略逊于图像视角方法(如 FCOS3D),推测因属性判断依赖图像外观特征。
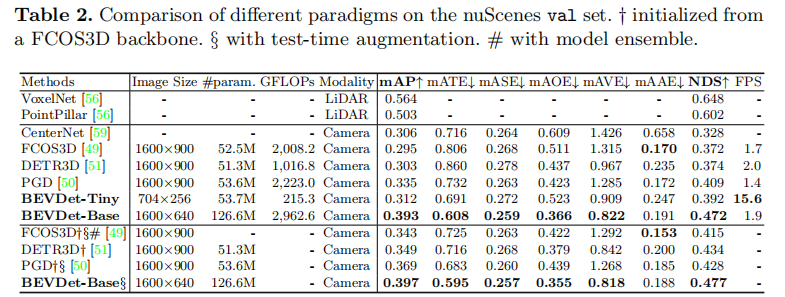
注:†表示基于 FCOS3D 骨干网络初始化;§ 表示测试时增强;# 表示模型集成。
4.2.2 nuScenes 测试集结果
BEVDet-Base 在训练集 + 验证集上训练,结合测试时增强(TTA),在测试集上取得 42.2% mAP 和 48.2% NDS,排名 nuScenes 视觉 3D 检测榜单第一,超越 PGD(38.6% mAP、44.8% NDS)+3.6% mAP 和 + 3.4% NDS,与依赖 LiDAR 预训练的 DD3D(41.8% mAP)、DETR3D†(38.6% mAP)性能相当,甚至接近经典 LiDAR-based 方法 PointPillars(30.5% mAP、45.3% NDS),验证了纯视觉 BEV 3D 检测的巨大潜力。
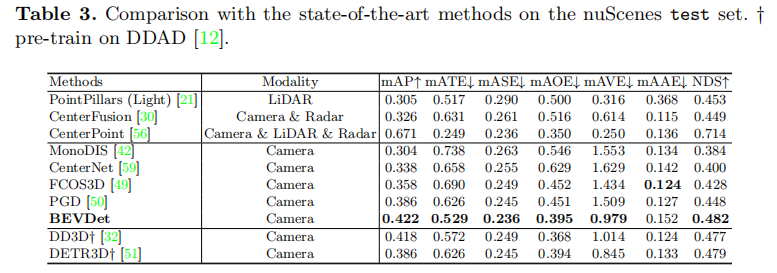
注:†表示在 DDAD 数据集上预训练。
4.3 消融实验分析
为验证各核心组件的有效性,作者进行了全面的消融实验,所有实验基于 BEVDet-Tiny 配置。
4.3.1 数据增强策略的影响
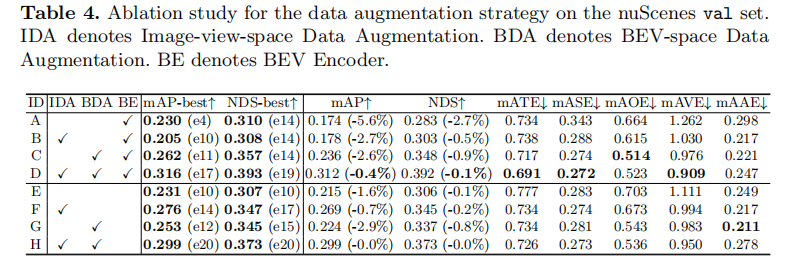
实验设计了 8 种配置(A-H),分别组合图像视角增强(IDA)、BEV 视角增强(BDA)和 BEV 编码器(BE),结果如表 4 所示:
- 基线(A):无任何增强 + BE 存在,模型在 epoch 4 就达到 23.0% mAP 的峰值,随后过拟合严重,最终 epoch 20 仅 17.4% mAP,验证了 BEV 空间过拟合的严重性。
- BDA 的关键作用:仅添加 BDA(配置 C),峰值 mAP 提升至 26.2%,最终 mAP 23.6%,过拟合缓解(下降 2.6%);而仅添加 IDA(配置 B),峰值 mAP 反而降至 20.5%,说明单独 IDA 对 BEV 空间训练有害。
- 双增强协同作用:IDA+BDA(配置 D)实现最优性能,峰值 mAP 31.6%,最终 mAP 31.2%,过拟合仅下降 0.4%,证明双空间增强能充分抑制过拟合。
- BEV 编码器的贡献:对比配置 D(有 BE)和 H(无 BE),mAP 提升 1.7%,说明 BEV 编码器对优化 BEV 特征、提升检测精度至关重要;且当 BE 存在时,IDA 仅在 BDA 配合下才有效(配置 B vs D)。
4.3.2 Scale-NMS 的有效性
对比经典 NMS、Circular-NMS(CenterPoint 提出)和 Scale-NMS 的性能,结果如表 5 所示:
- Scale-NMS 对小目标提升显著:行人 AP 提升 4.8%,交通锥 AP 提升 7.5%,解决了小目标预测框无交叠导致的 NMS 失效问题;
- 大目标也受益:巴士(+0.8% AP)、卡车(+0.3% AP)、拖车(+0.7% AP)等类别性能略有提升;
- 整体性能:mAP 从 29.5% 提升至 31.2%,增幅 1.7%,验证了 Scale-NMS 对 BEV 空间检测的适配性。

4.3.3 分辨率的影响
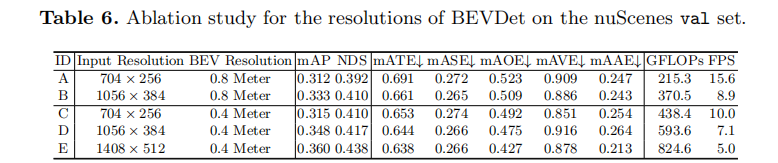
实验研究了输入图像分辨率和 BEV 特征分辨率对性能的影响,结果如表 6 所示:
- 输入图像分辨率:分辨率越高,性能提升越明显。例如,1408×512(配置 E)比 704×256(配置 C)mAP 提升 4.5%,且 ATE、AOE 等分项误差持续优化;同时,输入分辨率提升对计算量的增加影响有限(因 BEV 编码器和检测头的计算量固定)。
- BEV 特征分辨率:BEV 分辨率越高(voxel 尺寸越小),精度越好。例如,0.4 米 / 像素(配置 C)比 0.8 米 / 像素(配置 A)mAP 提升 0.3%,ATE 和 AOE 显著降低,但计算量从 215.3 GFLOPs 增至 438.4 GFLOPs,推理速度从 15.6 FPS 降至 10.0 FPS,需在精度与效率间权衡。
4.3.4 图像视角编码器骨干网络的影响
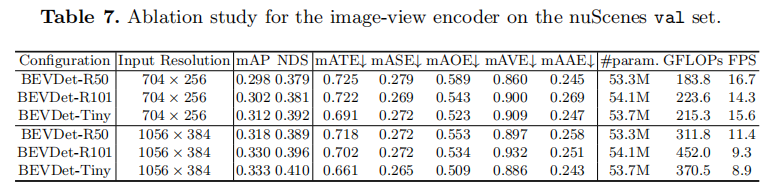
对比 ResNet-50、ResNet-101 和 SwinTransformer-Tiny 三种骨干网络(参数量相当),结果如表 7 所示:
- SwinTransformer-Tiny 表现最优:在 704×256 分辨率下,mAP 达 31.2%,NDS 达 39.2%,比 ResNet-50(29.8% mAP、37.9% NDS)提升 1.4% mAP 和 1.3% NDS,且在翻译误差(ATE)和姿态误差(AOE)上更优;
- ResNet-101 增益有限:在小分辨率(704×256)下,仅比 ResNet-50 提升 0.4% mAP,但在大分辨率(1056×384)下,mAP 提升 1.2%,推测大 receptive field 更适配高分辨率输入;
- 速度权衡:ResNet-50 速度最快(16.7 FPS),SwinTransformer-Tiny 次之(15.6 FPS),ResNet-101 最慢(14.3 FPS),需根据精度需求选择骨干网络。
4.3.5 推理加速优化
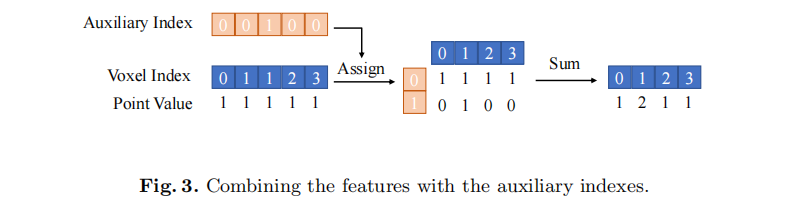
视角转换器中的 "累积和" 操作(用于合并同一 voxel 内的特征)推理 latency 与点云数量成正比,BEVDet 通过引入辅助索引优化该操作:
- 初始化阶段计算每个 voxel 的辅助索引(记录该 voxel 被访问的次数);
- 推理时,根据 voxel 索引和辅助索引将点云特征分配到 2D 矩阵,沿辅助轴直接求和,替代累积和操作。
该优化使 BEVDet-Tiny 的推理 latency 从 137 毫秒降至 64 毫秒(提速 53.3%),且通过限制辅助索引最大值为 300(丢弃超出点),对精度的影响可忽略不计。
五、结论与未来工作
BEVDet 首次提出了基于 BEV 视角的多相机 3D 目标检测范式,通过模块化设计复用现有组件,结合双空间数据增强策略和 Scale-NMS 算法,实现了精度与效率的突破。在 nuScenes 数据集上,BEVDet 不仅刷新了纯视觉 3D 检测的性能纪录,还验证了 BEV 视角在建模目标平移、尺度、姿态和速度上的天然优势,为自动驾驶多任务感知(3D 检测 + BEV 分割)提供了统一框架。
未来工作方向
- 提升属性预测精度:当前 BEVDet 在目标属性判断上略逊于图像视角方法,未来将探索图像特征与 BEV 特征的融合方案,兼顾空间属性和外观特征;
- 多任务学习扩展:基于 BEVDet 的统一框架,将 3D 目标检测与 BEV 语义分割、目标跟踪等任务结合,进一步提升感知系统的集成度和效率;
- 模型轻量化:在保持精度的前提下,优化网络结构和参数,降低计算量和 latency,适配边缘计算设备。
BEVDet 的开源代码(https://github.com/HuangJunJie2017/BEVDet)为后续研究提供了重要参考,有望推动 BEV 视角成为自动驾驶视觉感知的主流范式。