在数字经济加速渗透的今天,数据已成为企业核心竞争力的关键载体。然而,企业在数据处理过程中始终面临着一个核心抉择:是选择实时 ETL满足即时决策需求,还是依赖批处理保障海量数据高效处理?两种模式看似对立,实则各有适配场景 ------ 实时处理擅长低延迟响应,批处理则在高吞吐量、低成本运算中占据优势。如何打破模式壁垒,实现 "鱼与熊掌兼得" 的混合架构部署?下面将演示使用ETLCLoud的实时监听多表同步的案例。
一、数据源准备
在数据源列表中点击新建数据源。
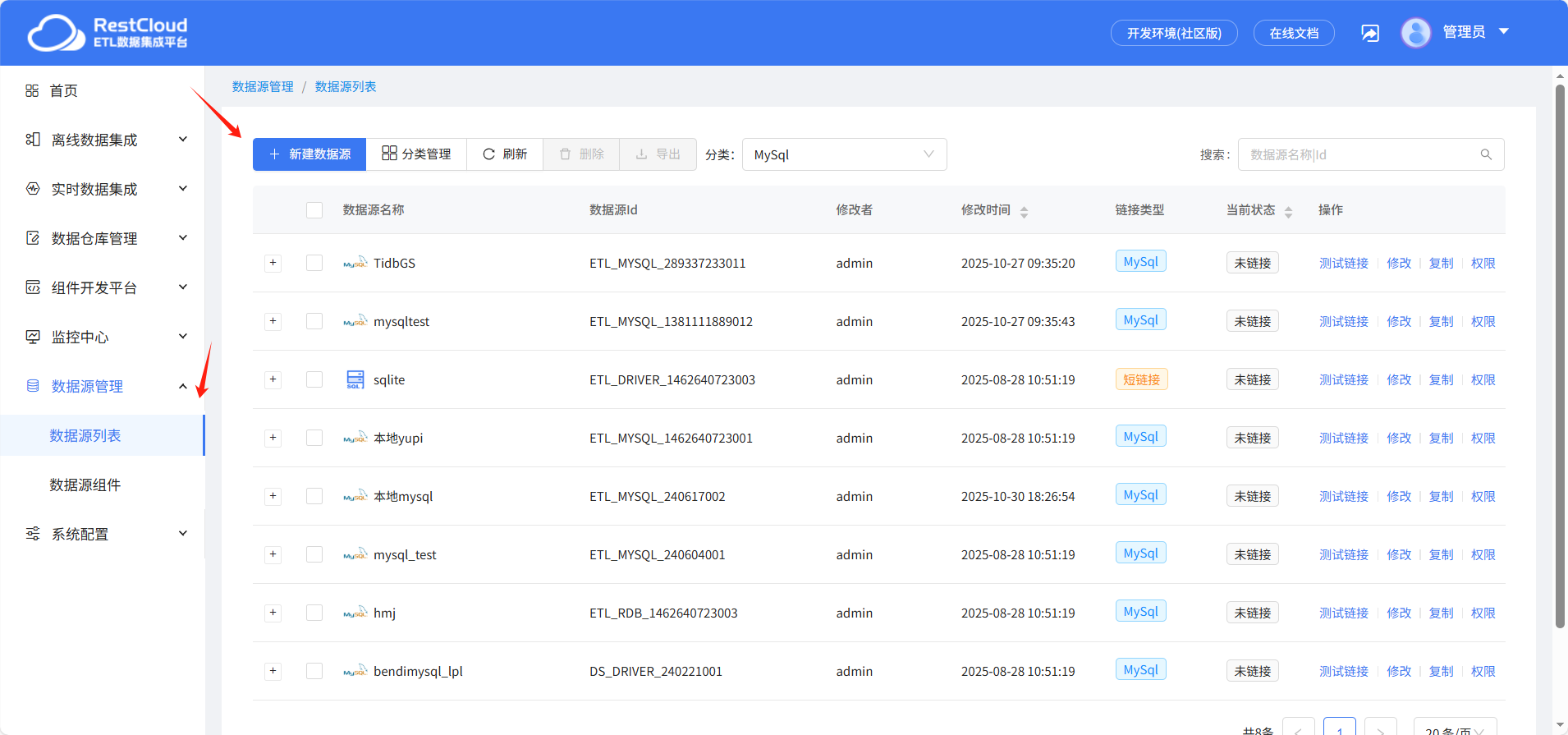
里面提供了大量的数据源模板,这里选择MySQL模板进行创建

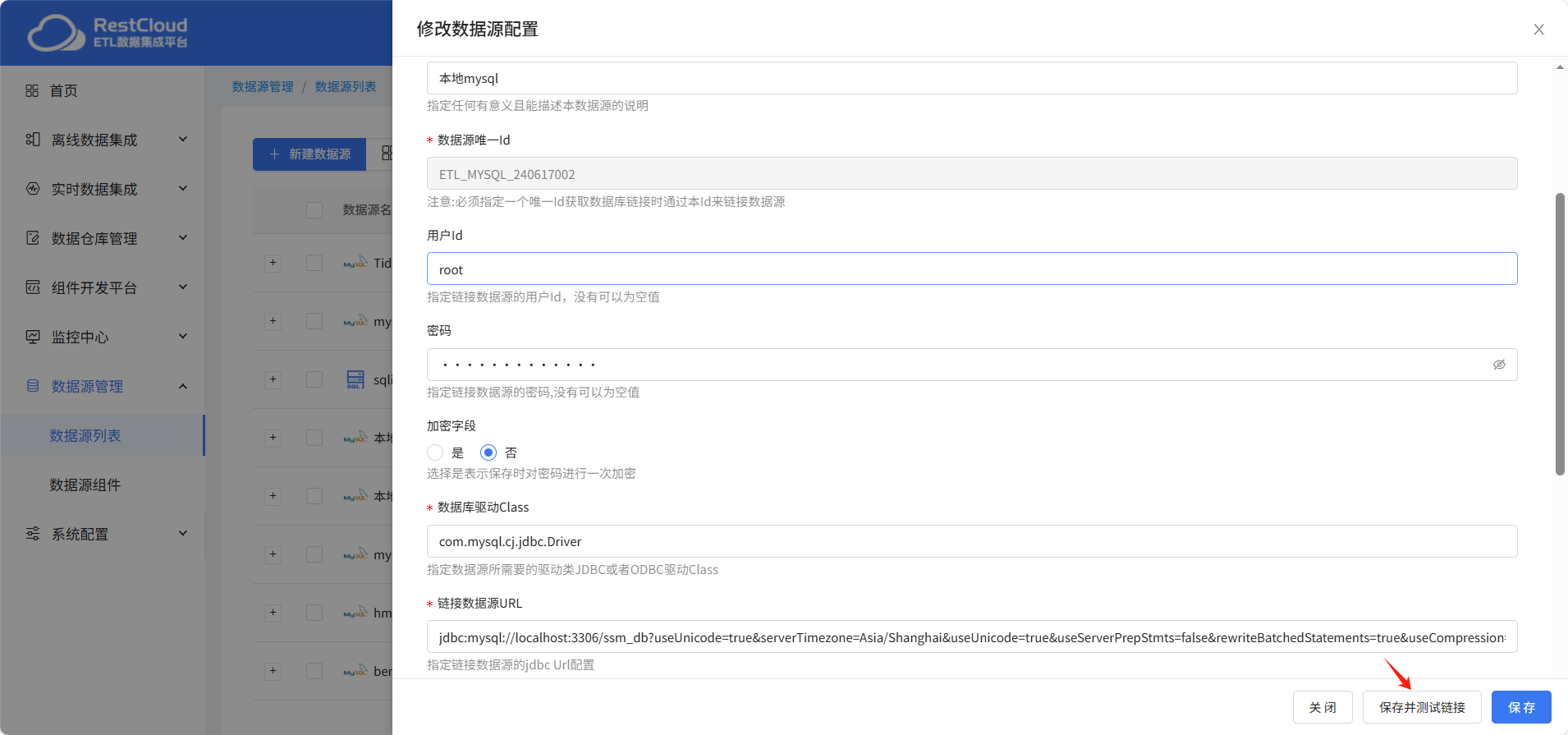
填写对应的链接配置之后,点击保存并测试。
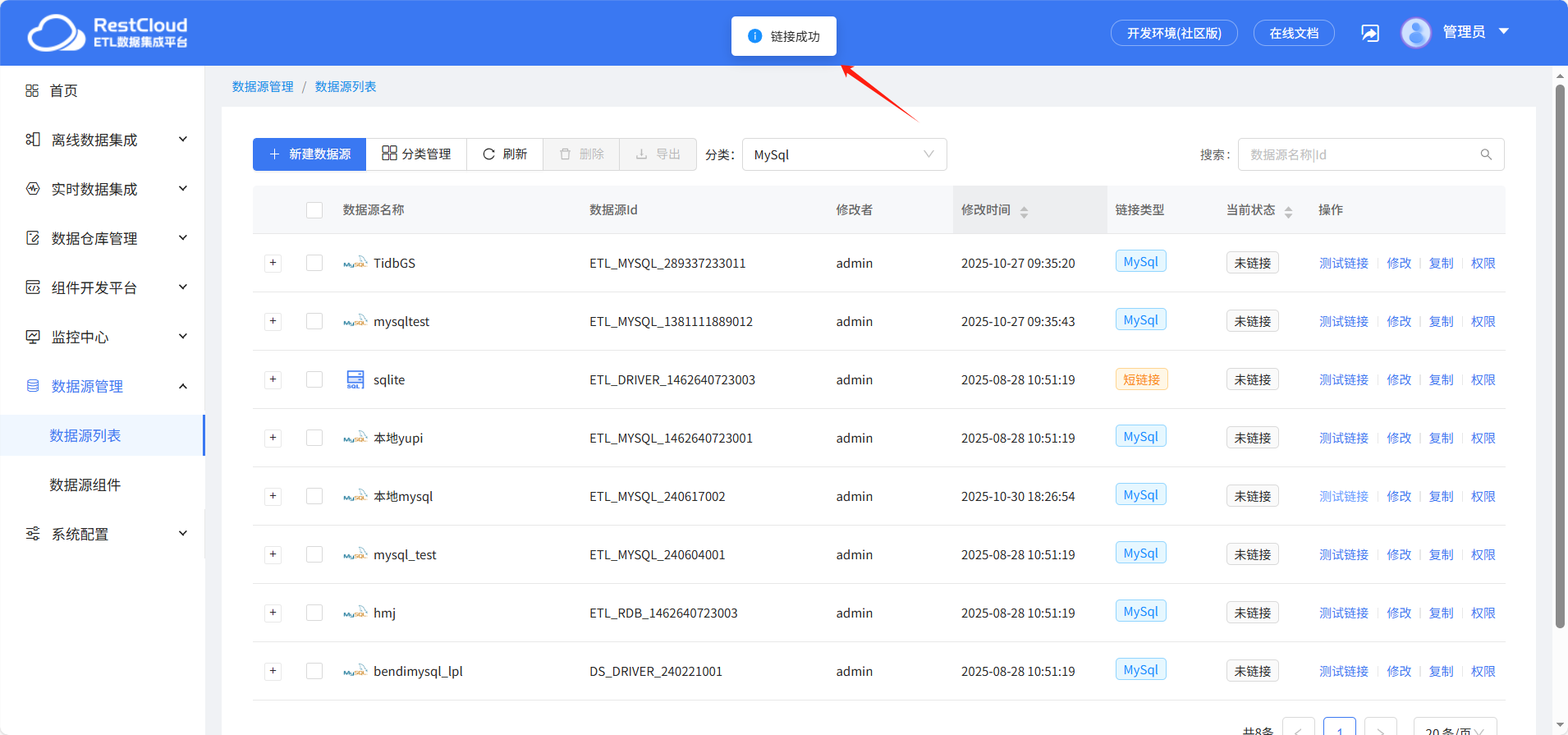
提示链接成功即可正常使用。
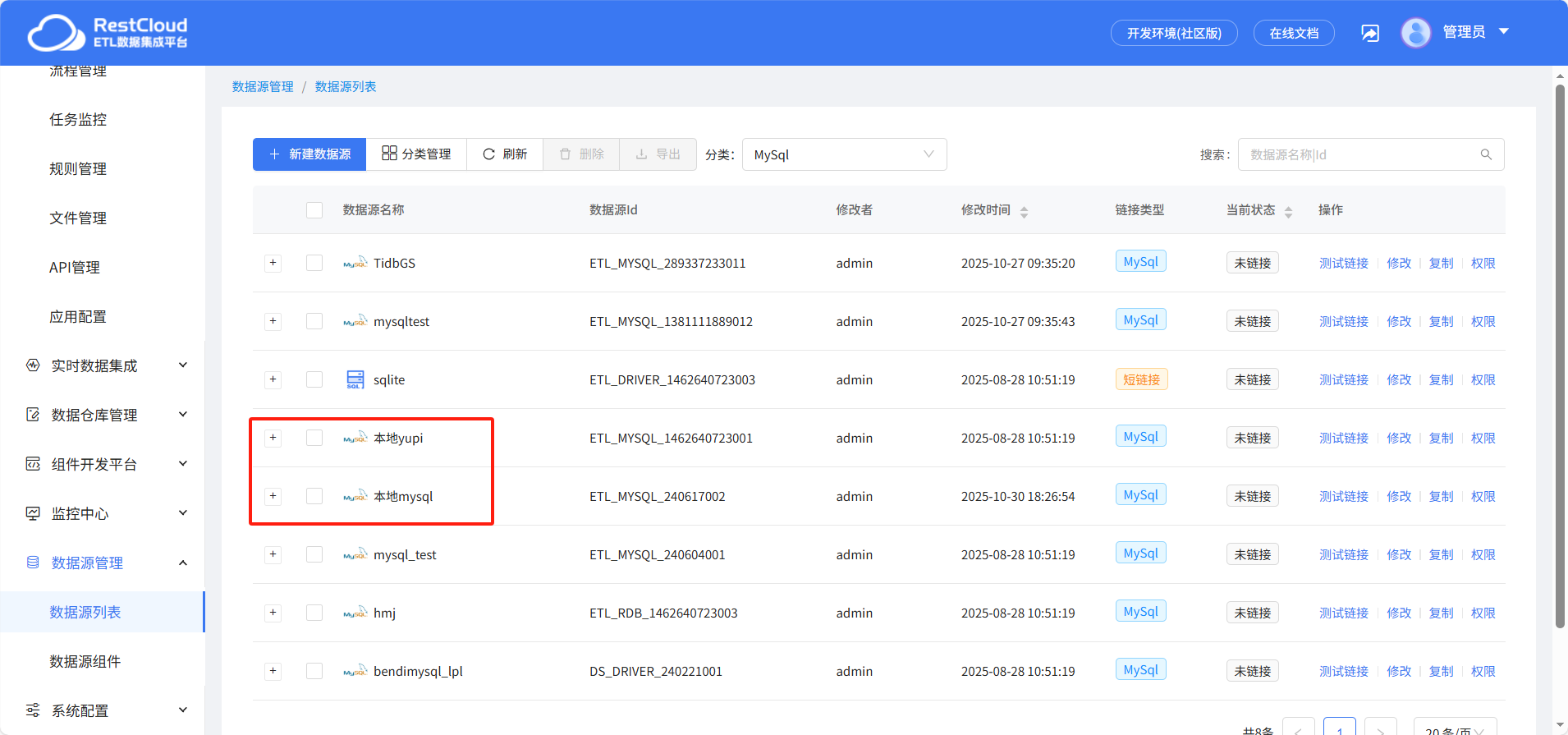
按照同样的步骤创建另一个MySQL数据源
二、数据处理流程
来到离线数据集成的流程管理,点击新增流程。这里已经提前建好了CDC同步的流程,然后打开流程设计。
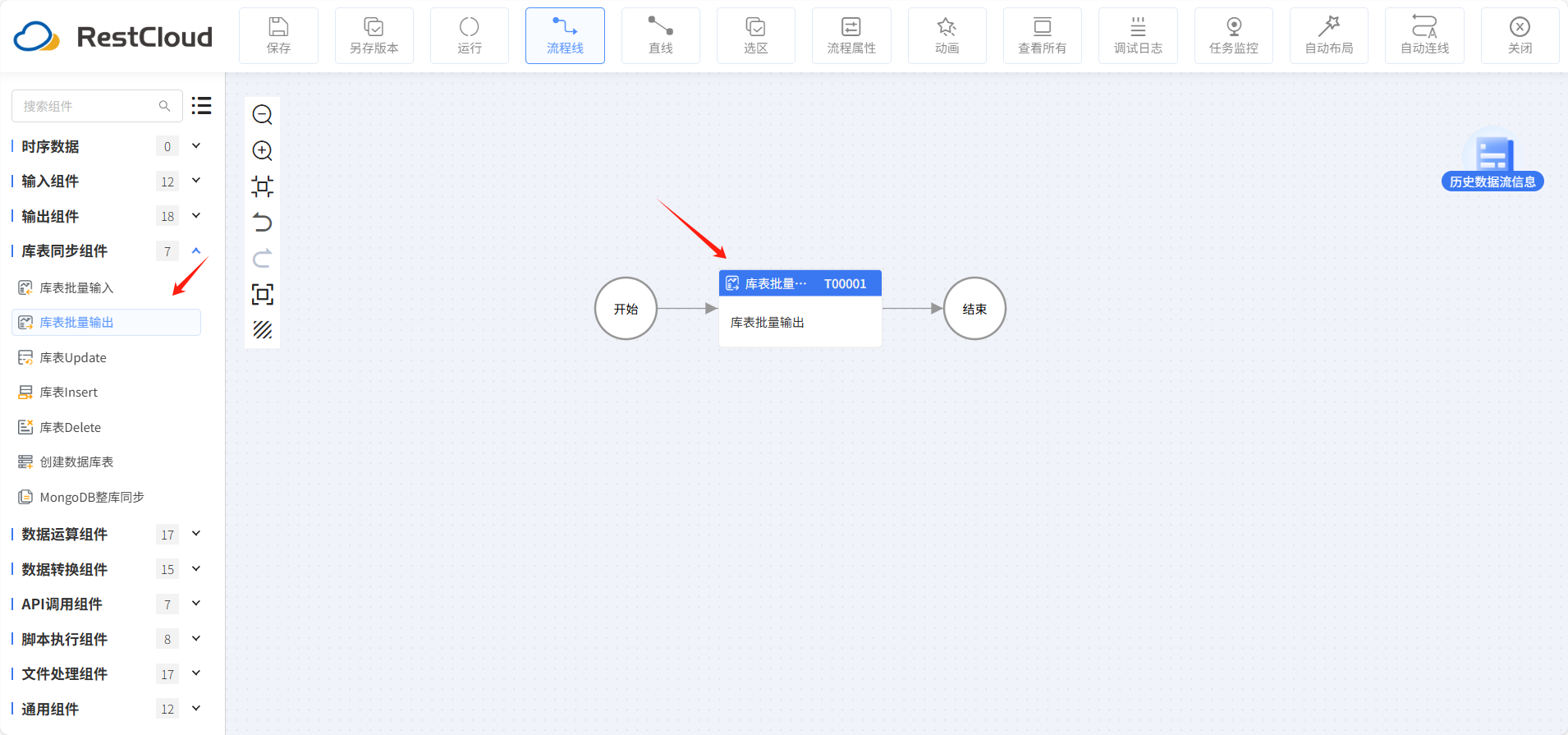
从组件列表中拉取库表批量输出组件。
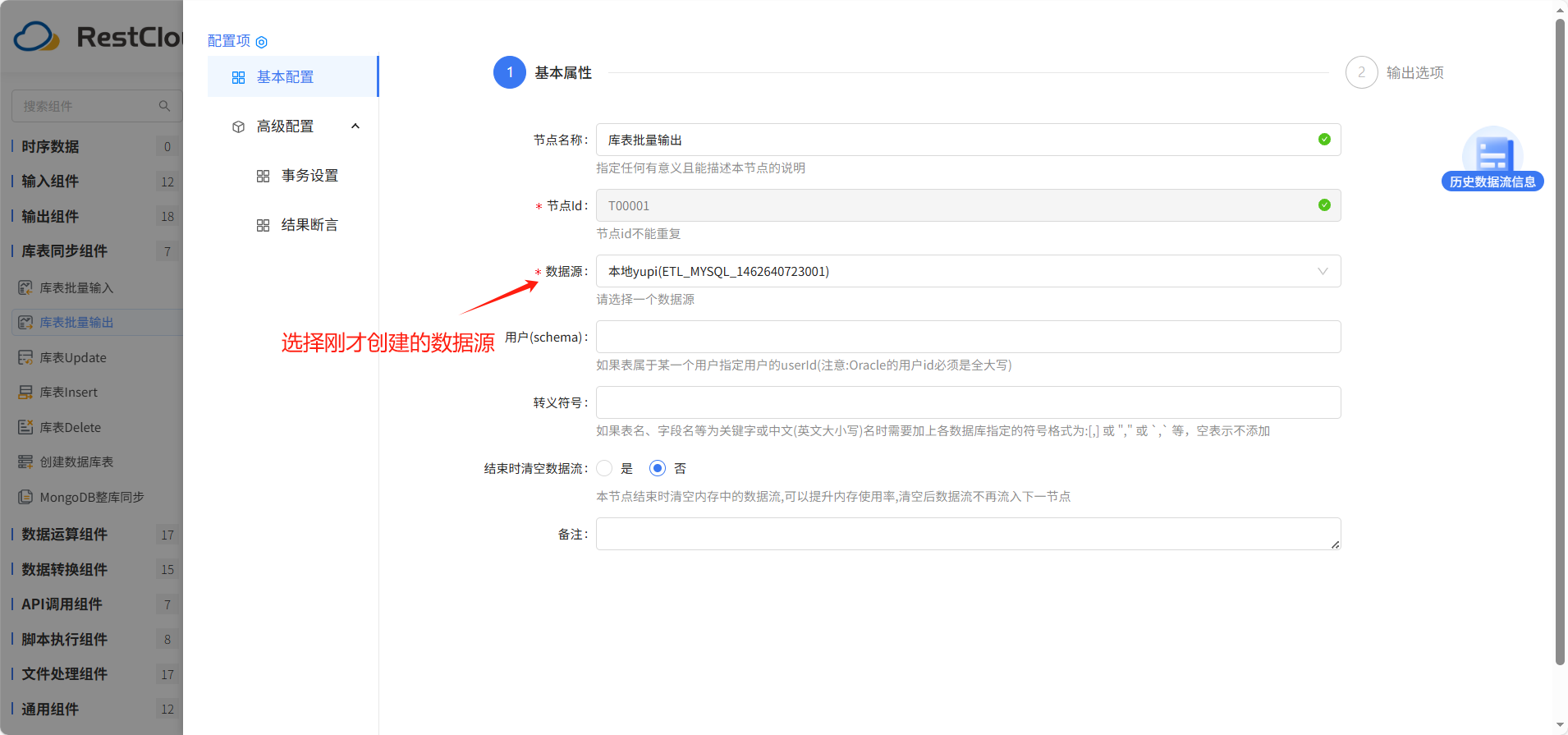
库表批量输出组件配置:
在基本属性配置里面选择刚才创建的数据源,其他配置默认。
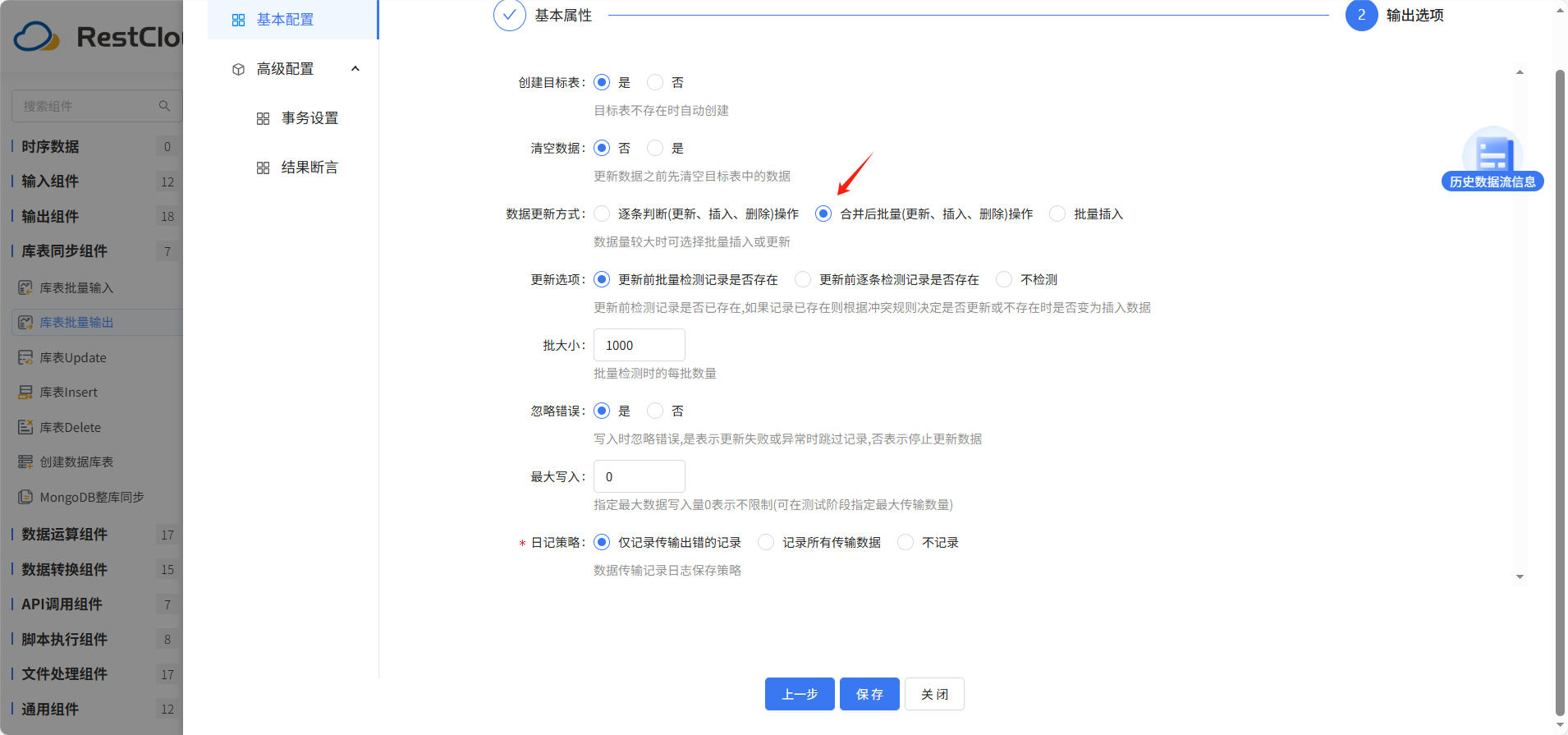
输出选项的数据更新方式选择合并后批量。其他配置默认,然后点击保存。
三、监听器配置
在实时数据集成界面切换至数据库监听器模块,点击新增监听器创建监听器。
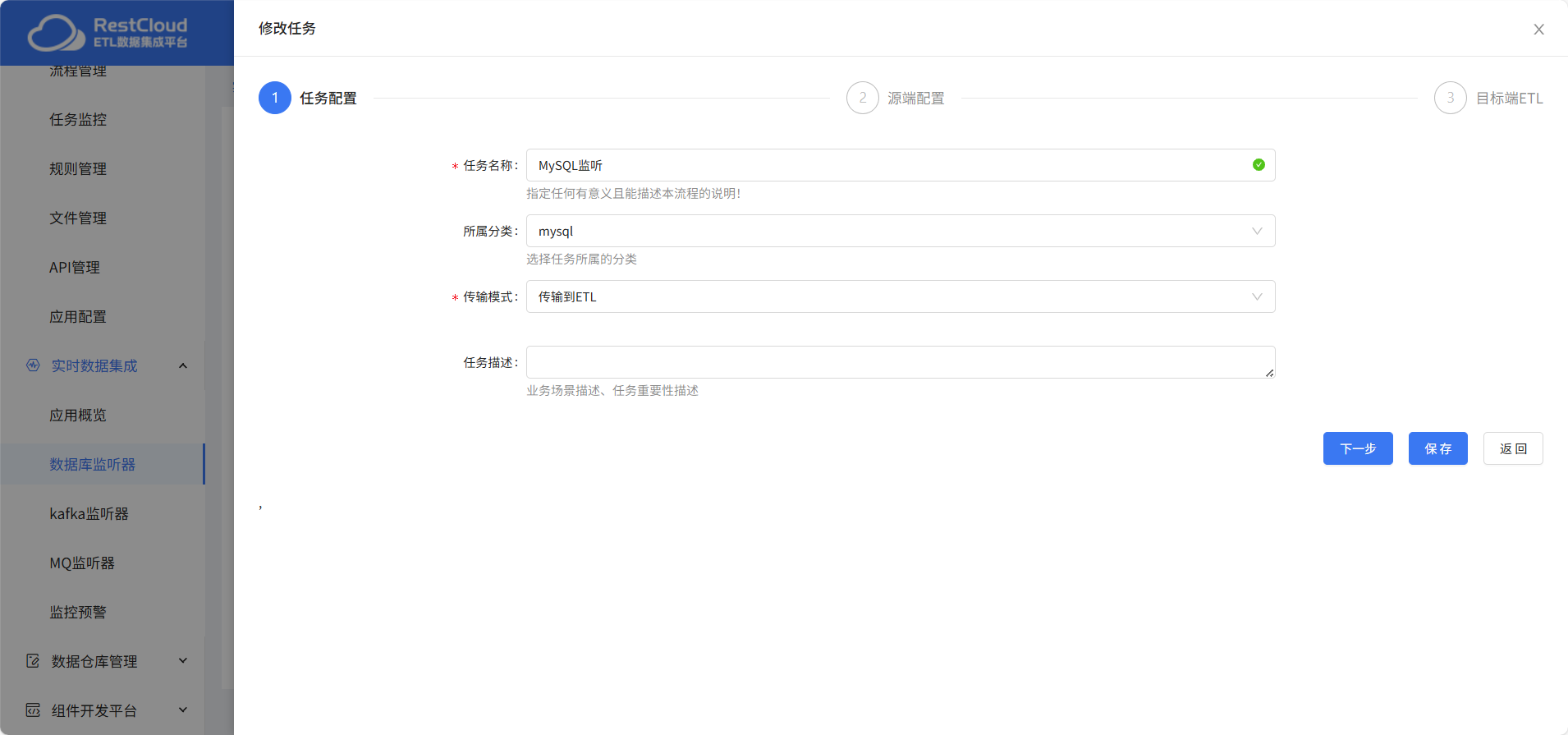
任务配置:
任务名称和所属分类根据需要填写,所属分类可以在分类管理里创建。支持多种传输模式,这里选择传输到ETL。
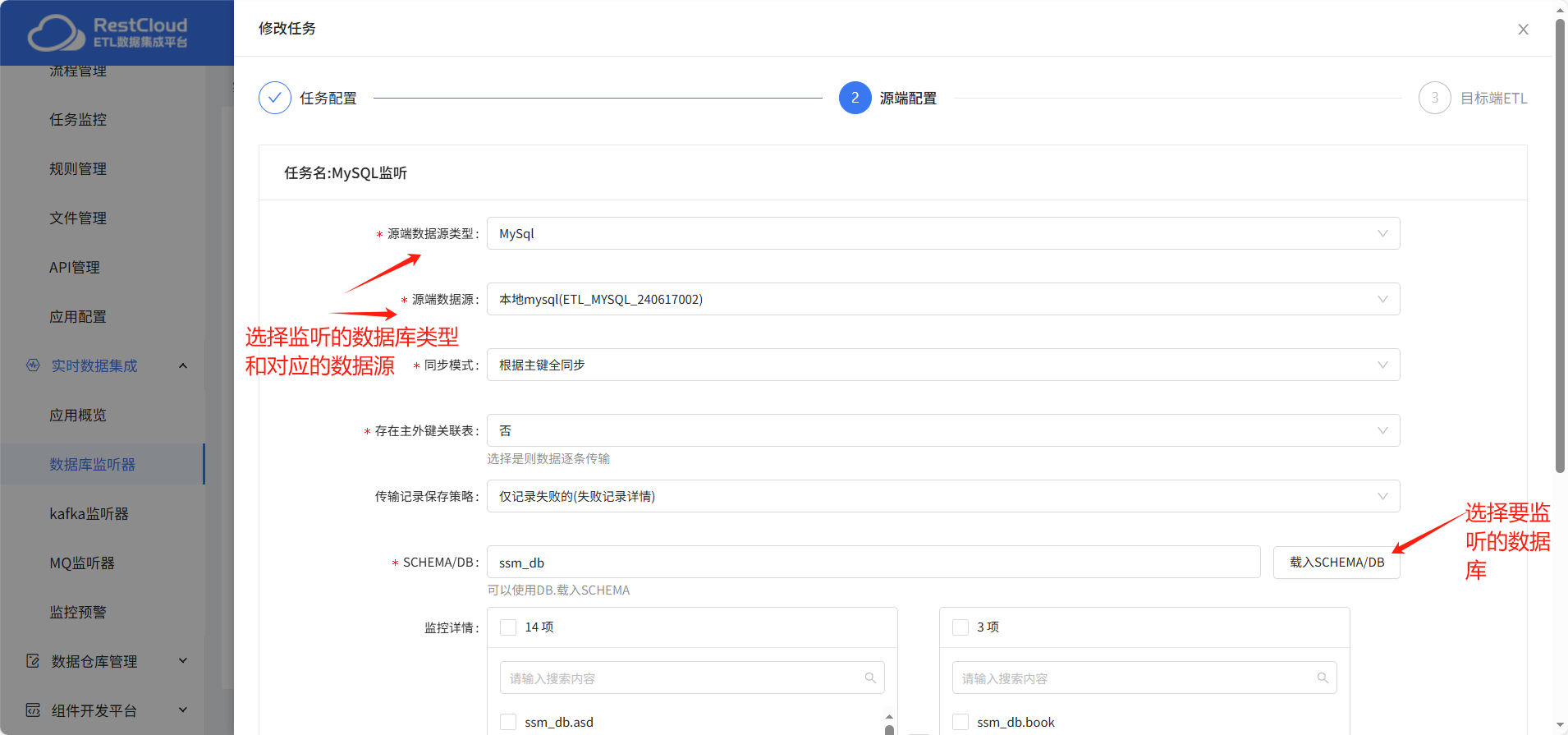
源端配置:
主要选择源端数据源类型、数据源和要监听的数据库和表。其他的配置默认。
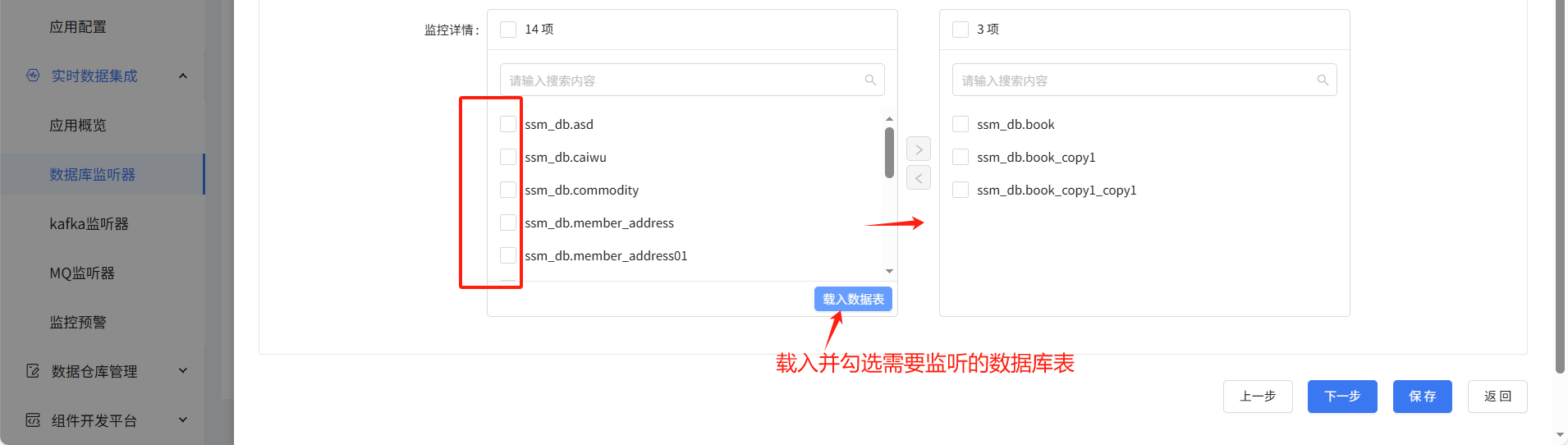
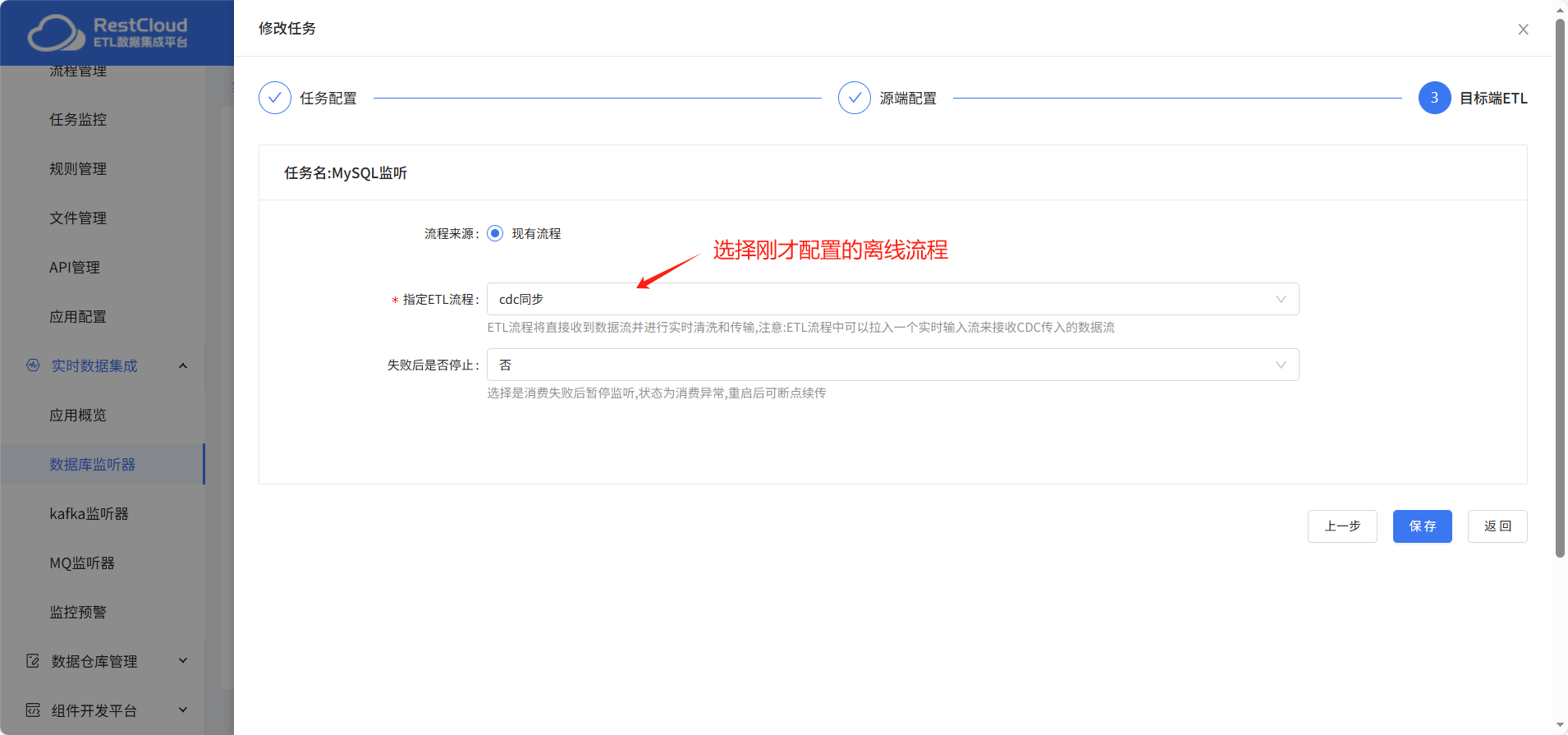
目标端ETL:
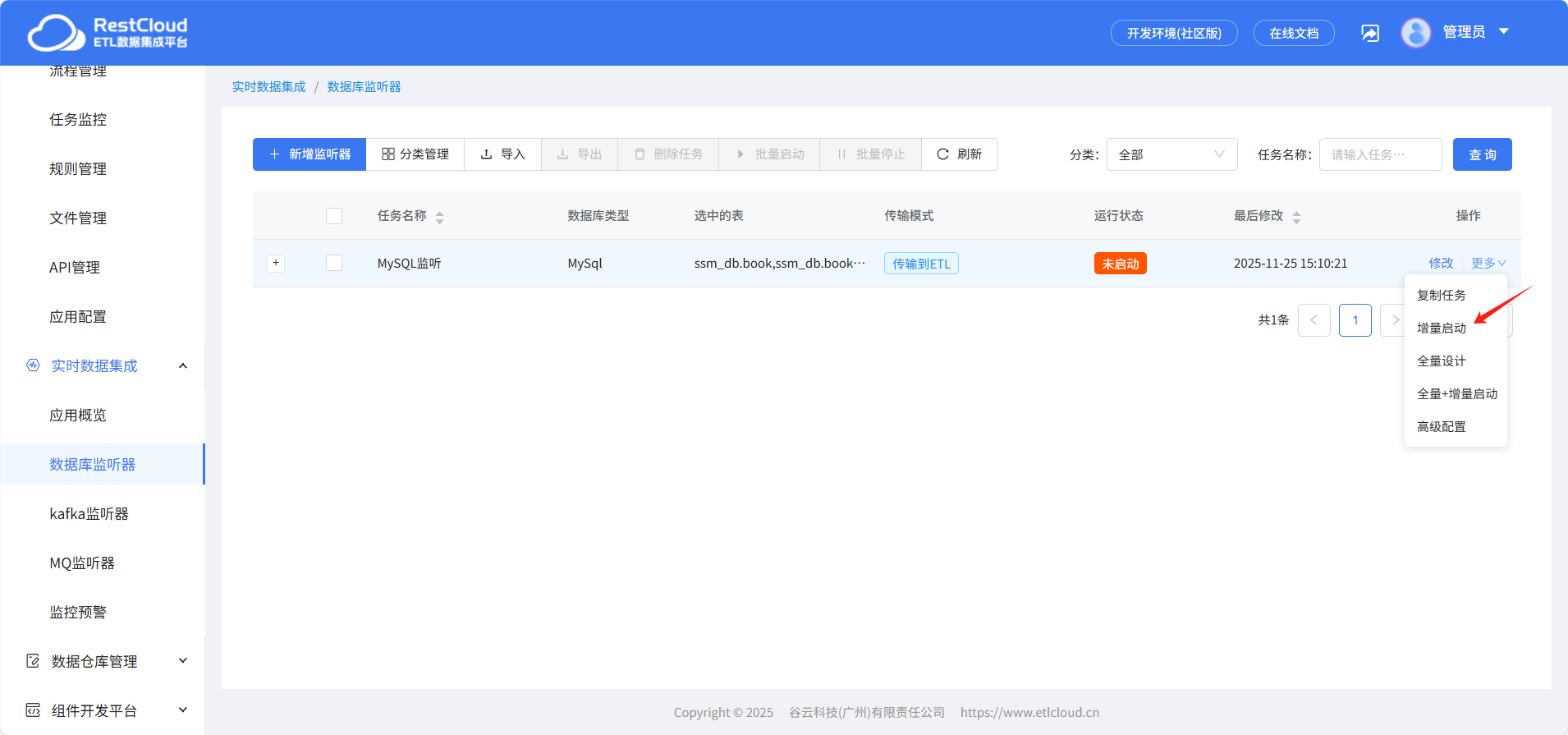
启动监听器
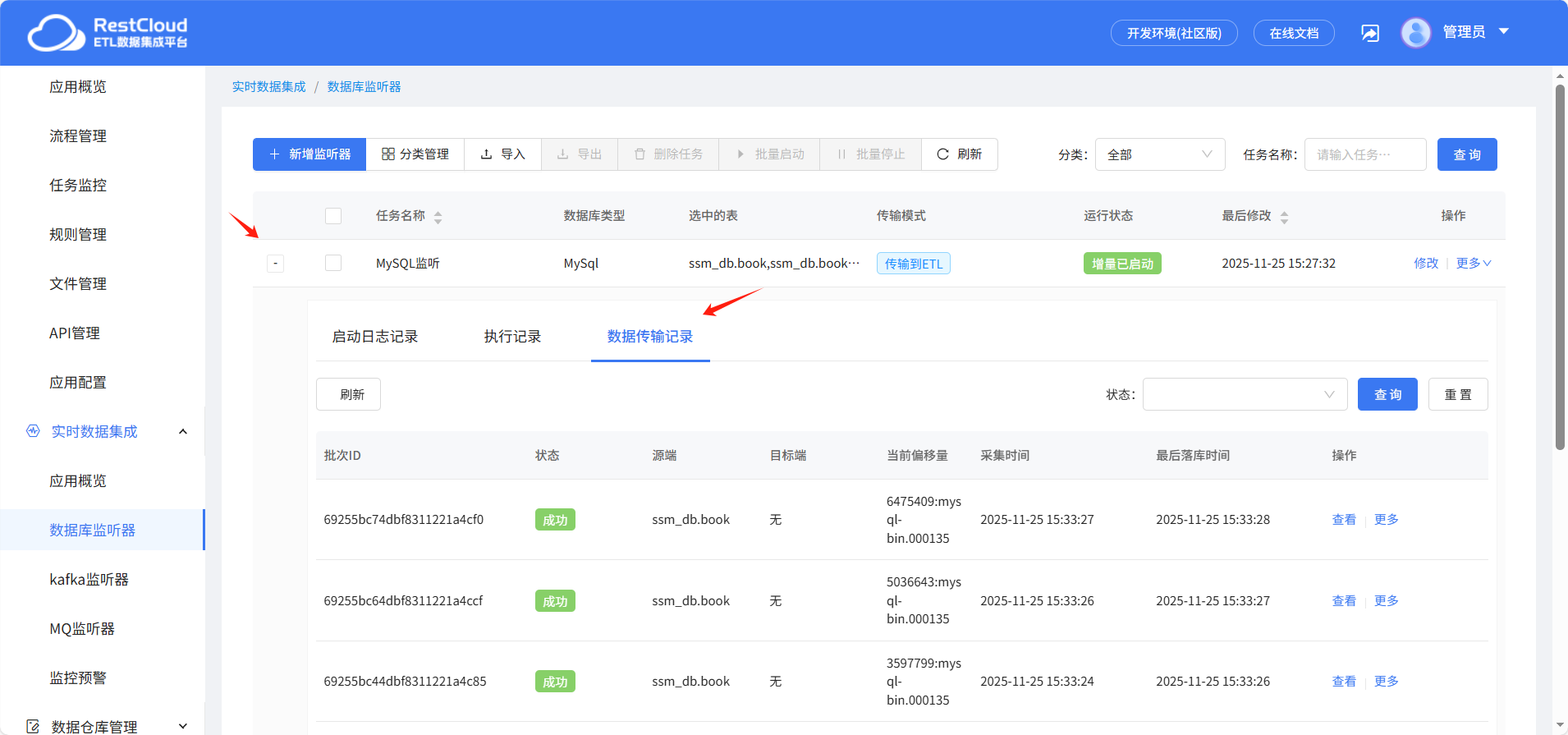
触发数据变动,查看数据传输情况,可以看到数据监听并同步成功。
四、最后
在数据量爆炸式增长、业务场景日益复杂的今天,单一的数据处理模式已无法满足企业多元化需求。ETLCloud 将实时处理的敏捷性与批处理的高效性完美融合,不仅解决了企业数据处理的 "两难困境",更通过技术创新构建起灵活、高效、安全的数据集成体系。未来,ETLCloud 将持续深耕混合架构技术研发,推出更多智能化功能,助力企业在数据驱动的浪潮中抢占先机,实现从 "数据可用" 到 "数据好用" 的价值跃迁,让每一份数据都能精准赋能业务增长。