摘要
本文面向 Java 微服务开发者与初级架构师,基于 11 年 Java 后端 + 大数据开发实战经验,聚焦「可观测性」核心需求,提供一套从 0 到 1 的 Prometheus+Grafana 指标监控落地方案。内容涵盖 Docker Compose 快速部署监控组件、Spring Boot 应用集成 Micrometer 埋点,以及 Grafana 可视化面板配置与企业微信告警设置。方案兼顾「测试环境快速验证」与「生产环境高可用扩展」,详细拆解部署步骤、避坑指南,帮助读者 1 小时内搭建覆盖「JVM + 接口 + 数据库」的全链路指标监控体系,同时提供 K8s+Thanos 生产级优化方案,助力系统实现「事前预警、事后快速排查」的高可用目标。
一、架构痛点:为什么 Prometheus 是微服务监控的首选?
在 Java 微服务或大数据架构设计中,「可观测性」是保障系统高可用的核心支柱。行业内公认的「可观测性三驾马车」------ 链路追踪(如 SkyWalking)解决「哪里慢」,日志分析(如 ELK)解决「发生了什么」,而指标监控(如 Prometheus)解决「整体是否健康」。
作为拥有 11 年 Java 后端与大数据开发经验的开发者,我在主导项目时,曾深刻体会到指标监控的重要性:早期因缺少完善的指标监控,OOM 故障未能提前预警,导致线上服务中断 15 分钟;后续引入 Prometheus 搭建监控体系后,通过预设的 JVM 内存、接口错误率等指标告警,提前规避了潜在的生产故障。
对比传统监控工具(如 Zabbix),Prometheus 具备三大核心优势,使其成为微服务架构的首选:
- 轻量可扩展:无依赖分布式存储,单节点可支撑万级指标采集,集群模式可横向扩展;
- 易集成:原生支持 Java(Micrometer)、Go、Python 等主流语言,对接中间件(MySQL、Redis、Kafka)简单;
- 灵活查询:PromQL 查询语言支持复杂的指标聚合分析,可快速定位问题。
本文不纠结底层原理,聚焦架构师最关心的「落地实践」------ 如何用 1 小时搭建覆盖「JVM + 接口 + 中间件」的企业级监控方案,且支持从测试环境平滑迁移到生产环境。
二、方案设计:架构师视角的监控方案选型
1. 技术栈选型逻辑
|----------------|-------------|---------------------------------------------|
| 组件 | 作用 | 选型理由 |
| Prometheus | 指标采集与存储 | 轻量无依赖,支持 Pull/Push 模式,PromQL 查询灵活,适配微服务动态环境 |
| Grafana | 指标可视化 | 开源可视化工具,拥有丰富的现成面板模板,支持自定义告警,操作门槛低 |
| Micrometer | Java 应用指标埋点 | Spring Boot 官方推荐,无缝集成 Actuator,无需大量自定义埋点代码 |
| Docker Compose | 环境部署 | 快速启动多关联服务(Prometheus+Grafana),配置即代码,读者可一键复现 |
2. 部署模式规划
- 测试 / 学习环境:Docker Compose 单机部署(成本低、部署快,适合快速验证方案);
- 生产环境:K8s + Helm Charts 部署 Prometheus Operator(官方维护,支持高可用、自动扩缩容)。
3. 核心监控范围
本文聚焦 Java 微服务核心指标,后续可无缝扩展到中间件和大数据组件:
- JVM 指标:堆内存 / 非堆内存使用量、GC 次数 / 停顿时间、线程数 / 线程状态;
- 应用指标:接口 QPS、响应延迟、错误率(4xx/5xx 状态码);
- 系统指标:CPU 利用率、内存使用率、磁盘 I/O(后续扩展)。
三、实战落地:1 小时搭建监控体系(Mac 环境适配)
前置环境
- 操作系统:Mac(Intel i7 六核,其他系统步骤通用);
- 开发环境:IDEA + Java 8+ + Spring Boot 2.7+;
- 容器工具:Docker Desktop(已安装可跳过)。
1. 安装 Docker Desktop(Mac Intel 版)
步骤 1:下载安装包
访问 Docker 官网,选择「Mac with Intel chip」版本下载:https://www.docker.com/products/docker-desktop/
步骤 2:安装与验证
- 打开 .dmg 文件,将「Docker」拖拽到「Applications」文件夹;
- 启动 Docker,等待状态栏鲸鱼图标稳定(约 30 秒);
- 打开终端,执行以下命令验证安装成功:
bash
docker --version # 示例输出:Docker version 29.0.1, build 2ae903e
docker compose version # 示例输出:Docker Compose version v2.40.3-desktop.12. Docker Compose 部署 Prometheus+Grafana
步骤 1:创建部署目录
终端执行命令,统一管理配置文件:
bash
mkdir -p ~/monitor-demo # 创建目录
cd ~/monitor-demo # 进入目录(后续操作均在此目录)步骤 2:编写 docker-compose.yml
创建 docker-compose.yml 文件,复制以下内容(含详细注释):
java
# 极简版 docker-compose.yml(无冗余配置,确保启动)
services:
prometheus:
image: prom/prometheus:latest # 明确版本,和本地镜像一致
ports:
- "9090:9090"
volumes:
# 挂载本地 prometheus.yml 到容器(路径必须正确)
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
restart: always
# 简化网络配置(用默认桥接网络,避免自定义网络冲突)
networks:
- monitoring
grafana:
image: grafana/grafana:latest # 轻量版,确保本地有该镜像
ports:
- "3000:3000"
volumes:
- grafana-data:/var/lib/grafana
restart: always
environment:
- GF_SECURITY_ADMIN_PASSWORD=123456
- DOCKER_CLIENT_TIMEOUT=480
- COMPOSE_HTTP_TIMEOUT=480
depends_on:
- prometheus # 确保 Prometheus 先启动
networks:
- monitoring
volumes:
prometheus-data:
grafana-data:
networks:
monitoring:
driver: bridge步骤 3:编写 prometheus.yml 采集配置
创建 prometheus.yml 文件,配置指标采集规则:
java
# 极简 Prometheus 配置(仅保留核心,确保启动成功)
global:
scrape_interval: 15s # 每隔15秒采集一次指标
scrape_configs:
# 采集 Prometheus 自身指标(默认配置,必选)
- job_name: 'prometheus'
static_configs:
- targets: ['prometheus:9090']
# 采集本地 Java 应用指标(核心配置)
- job_name: 'java-app'
metrics_path: '/actuator/prometheus' # Spring Boot + Micrometer 默认端点
static_configs:
# Mac 下用 host.docker.internal 直接访问宿主机 8080 端口(无需查本机 IP)
- targets: [ 'host.docker.internal:8080' ]步骤 4:启动服务
终端执行以下命令,一键启动 Prometheus 和 Grafana:
bash
docker compose up -d # -d 表示后台运行,不占用终端步骤 5:验证启动状态
执行 docker compose ps,若两个服务的 STATE 均为 Up,则启动成功:

访问测试:
- Prometheus:http://localhost:9090(出现 Prometheus 首页);
- Grafana:http://localhost:3000(登录页,用户名 admin,密码 123456)。
3. Java 应用集成 Micrometer 埋点
架构师选型思考:
有同学会问:为什么不用手写接口暴露指标,非要引入 Actuator+Micrometer?
我们的核心目标是「用最低成本搭建可扩展的体系」:Actuator 解决了「监控端点标准化、安全化」的问题,Micrometer 解决了「指标采集标准化、低成本」的问题 ------ 两者结合,能让我们快速完成一个 Java 微服务的指标暴露,且所有应用的指标格式统一,后续 Grafana 面板、告警规则都能复用,这是手写接口无法比拟的工程价值。
步骤 1:添加依赖(Maven)
在 Spring Boot 项目(可新建项目)的 pom.xml 中添加以下依赖:
XML
<!-- 暴露监控端点(如 /actuator/prometheus) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- 对接 Prometheus 指标采集 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<!-- Web 依赖(已有则无需重复添加) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>步骤 2:配置 application.yml
在 src/main/resources/application.yml 中添加配置,暴露指标端点:
java
spring:
application:
name: java-app # 应用名称,作为指标标签(方便多应用区分)
management:
endpoints:
web:
exposure:
include: prometheus # 仅暴露 prometheus 端点,兼顾安全和需求
metrics:
tags:
application: ${spring.application.name} # 指标添加应用名标签,便于聚合分析
endpoint:
health:
show-details: always # 可选:暴露健康检查详情(http://localhost:8080/actuator/health)步骤 3:添加测试接口(生成指标)
新建 TestController,用于触发接口指标:
java
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestController {
// 访问 http://localhost:8080/test,触发接口调用指标
@GetMapping("/test")
public String test() {
return "Hello Prometheus! 接口调用成功";
}
// 访问 http://localhost:8080/test/error,触发接口错误指标
@GetMapping("/test/error")
public String testError() {
throw new RuntimeException("模拟接口异常");
}
}步骤 4:验证指标暴露
启动 Spring Boot 项目,访问 http://localhost:8080/actuator/prometheus,若页面输出大量以 # HELP 开头的指标数据(如 jvm_memory_used_bytes、http_server_requests_seconds_count),则埋点成功。
4. Prometheus 指标采集验证
- 访问 http://localhost:9090,点击顶部「Status」→「Targets」;
- 若显示 prometheus 和 java-app 两个任务,且 State 均为 UP,说明采集正常;
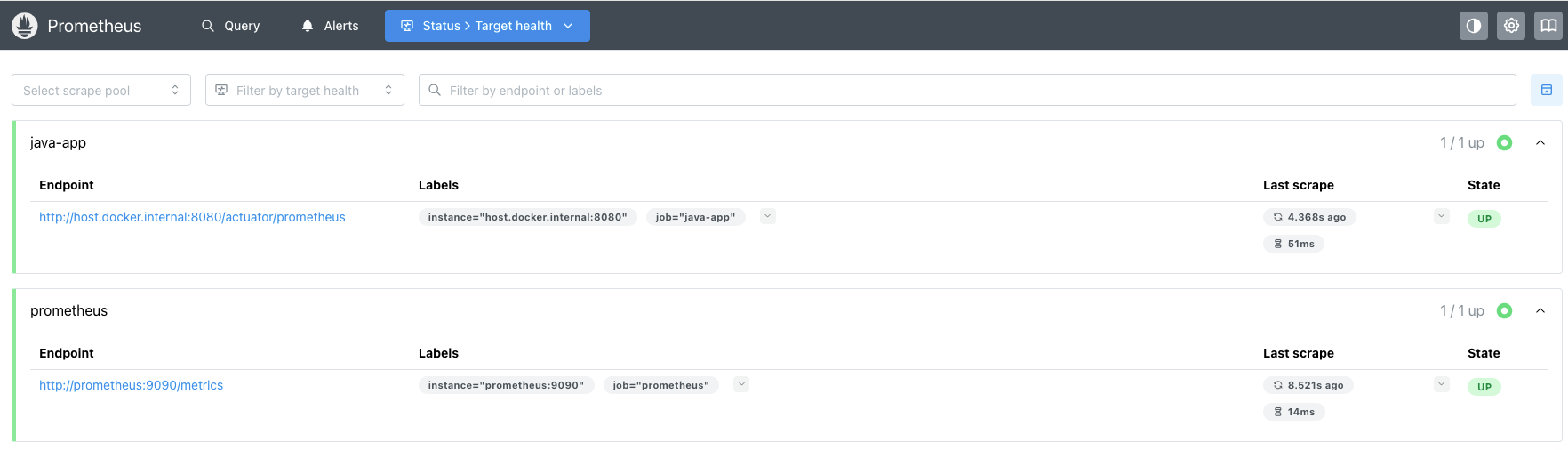
- 测试 PromQL 查询:
- 输入 jvm_memory_used_bytes(JVM 已用内存),点击「Execute」,出现折线图;
- 访问几次 /test 接口后,输入 http_server_requests_seconds_count(接口调用次数),可看到统计数据。
5. Grafana 可视化配置
步骤 1:添加 Prometheus 数据源
- 登录 Grafana(http://localhost:3000),用户名 admin,密码 123456;
- 左侧点击「📊 Dashboards」→「Data Sources」→「Add data source」;
- 搜索「Prometheus」,进入配置页;
- 「HTTP」→「URL」输入 http://prometheus:9090(Docker 内部用服务名访问);
- 点击「Save & test」,提示「Data source is working」即成功。
步骤 2:导入 Java 应用监控面板
- 左侧点击「📊 Dashboards」→「Import」;
- 「Import via grafana.com」输入模板 ID:4701(Spring Boot 官方推荐模板),点击「Load」;
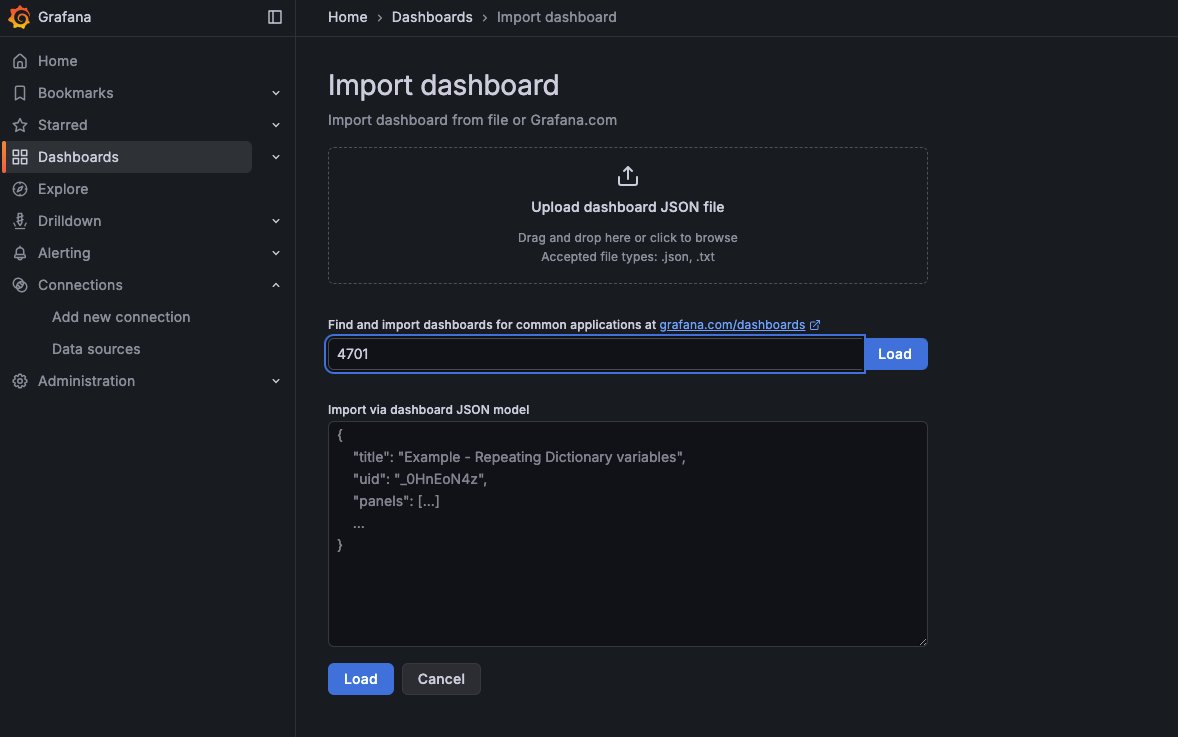
- 「Name」自定义为「Java 微服务监控面板」,「Data source」选择刚添加的 Prometheus;
- 点击「Import」,生成完整监控面板。
步骤 3:验证面板数据
面板包含 8 大模块,核心数据验证:
| 面板模块 | 核心指标示例 | 验证方法 | 正常表现 |
|---|---|---|---|
| Quick Facts | 应用运行时长、堆内存使用量 | 等待 1 个采集周期(15 秒),刷新面板 | 显示具体数值(非 N/A) |
| I/O Overview | 接口 QPS、响应延迟、错误数 | 访问/test接口 5 次,访问/test/error2 次 |
QPS>0、延迟显示具体数值、错误数 > 0 |
| JVM Memory | 堆内存 / 非堆内存使用趋势 | 观察面板曲线 | 曲线随时间波动(非平线) |
| JVM Misc | CPU 使用率、线程数 | 打开 IDEA 运行 Java 应用,触发接口请求 | CPU 使用率 > 0%、线程数 > 10 |
| JVM Memory Pools | 元空间、压缩类空间使用量 | 应用启动后加载类资源 | 元空间使用量随类加载逐步上升 |
| Garbage Collection | GC 次数、GC 停顿时间 | IDEA 中手动触发 GC(Profiler→GC) | GC 次数 + 1、停顿时间显示具体数值 |
| Classloading | 已加载类数量 | 应用启动后等待 1 分钟 | 类数量稳定在几百~几千(依应用规模) |
| Buffer Pools | 直接缓冲池使用量 | 访问接口触发网络 I/O | 缓冲池使用量 > 0 |
6. 配置企业微信告警(可选)
步骤 1:获取企业微信 Webhook
- 企业微信管理后台→应用管理→创建应用;
- 记录「AgentId」「Secret」「企业 ID」,生成 Webhook 地址。
步骤 2:配置 Grafana 告警通道
- 左侧「Alerting」→「Notification channels」→「Add channel」;
- 「Name」填写「企业微信告警」,「Type」选择「Webhook」;
- 「URL」粘贴企业微信 Webhook 地址,点击「Test」,收到测试消息即成功。
步骤 3:创建告警规则
- 打开 Grafana 面板,找到「JVM Memory」→「Heap Used」卡片,点击右上角「Edit」;
- 「Alert」→「Create Alert」,配置规则:
- Condition:avg() of query(A, 5m) > 80%(5 分钟内堆内存使用率超 80%);
- Evaluate every:15s;
- For:1m(持续 1 分钟触发告警);
- Notifications:选择「企业微信告警」;
- 点击「Save」,告警规则生效。
四、深度扩展:从测试环境到生产环境的优化
1. 部署模式升级:K8s + Helm 部署
生产环境需高可用和自动扩缩容,推荐用 Prometheus Operator:
bash
# 添加 Helm 仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 部署 Prometheus Operator
helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring --create-namespace核心优化点:
- 高可用:Prometheus 联邦集群,避免单点故障;
- 服务发现:用 ServiceMonitor 自动发现微服务,无需手动配置 targets;
- 配置管理:通过 ConfigMap 管理采集规则,Secret 存储告警密钥。
2. 存储扩展:长期存储方案
Prometheus 本地存储仅支持 15 天数据,生产环境需对接长期存储:
- 方案:Prometheus + Thanos + S3(对象存储);
- 优势:支持 PB 级指标存储,历史数据查询无压力,支持跨集群指标聚合。
3. 告警优化:Alertmanager 配置
生产环境需避免告警风暴,用 Alertmanager 管理告警:
- 分组:按应用、集群分组告警,避免重复告警;
- 抑制:高优先级告警触发时,抑制低优先级告警;
- 静默:手动静默临时故障告警,避免打扰。
4. 监控范围扩展
本文方案可无缝扩展到中间件和大数据组件:
- MySQL:集成 prometheus-mysql-exporter,监控连接数、查询延迟;
- Redis:集成 redis_exporter,监控内存使用率、命中率;
- Flink:开启 Flink 原生 Prometheus 指标,监控任务并行度、Checkpoint 成功率。
五**、避坑指南:新手常见问题及解决方案**
**1.**Docker 拉取镜像超时(context deadline exceeded)
- 原因:Docker 连接国外仓库超时;
- 解决:配置 Docker 国内镜像源;
XML
"registry-mirrors": [
"https://docker.hpcloud.cloud",
"https://docker.m.daocloud.io",
"https://docker.unsee.tech",
"https://docker.1panel.live",
"http://mirrors.ustc.edu.cn",
"https://docker.chenby.cn",
"http://mirror.azure.cn",
"https://dockerpull.org",
"https://dockerhub.icu",
"https://hub.rat.dev",
"https://proxy.1panel.live",
"https://docker.1panel.top",
"https://docker.m.daocloud.io",
"https://docker.1ms.run",
"https://docker.ketches.cn"
]2**. Prometheus 找不到 java-app 采集目标**
- 原因 1:prometheus.yml 未正确挂载(Docker Compose 中 volumes 配置错误);
- 解决:检查 docker-compose.yml 中 Prometheus 的 volumes 配置,重启服务:docker compose restart prometheus;
- 原因 2:Java 应用未暴露 /actuator/prometheus 端点;
- 解决:检查 application.yml 中 management.endpoints.web.exposure.include 是否包含 prometheus,重启 Java 应用;
- 原因 3:Mac 下 host.docker.internal 失效;
- 解决:终端执行 ifconfig en0 获取本机 IP,替换 prometheus.yml 中的 targets。
3**. Grafana 10.x 找不到 Import 入口**
- 解决:左侧「📊 Dashboards」→「Import」(10.x 版本菜单调整,替代旧版本的 Create 图标)。
4**. Grafana 面板无数据**
- 原因 1:数据源配置错误;
- 解决:确保 Grafana 数据源 URL 为 http://prometheus:9090(而非 localhost:9090);
- 原因 2:未触发对应指标;
- 解决:多访问 Java 应用接口,或手动触发 GC。
六**、总结:指标监控的核心价值**
我们设计监控体系的核心目标不是「事后排查问题」,而是「事前预警故障」。Prometheus+Grafana 方案以其轻量、易扩展、易集成的特点,成为 Java 微服务架构的最优解之一。
本文从架构痛点出发,通过「方案设计→实战落地→生产扩展」的逻辑,提供了一套可直接复用的监控方案。后续可进一步集成链路追踪(SkyWalking)和日志分析(ELK),实现「指标 + 链路 + 日志」的全链路可观测性,为系统高可用保驾护航。
如果你在落地过程中遇到问题,欢迎在评论区交流~ 觉得有用的话,点赞 + 收藏 + 转发支持一下!