前言
学习机器学习的过程中,我逐渐意识到:
如果只有代码,而没有理论,就很难真正理解模型在做什么
如果只有概念,而缺少一个系统框架,又难以把知识串成体系
《统计学习方法》正好提供了这样一个结构清晰的入口------它把机器学习的核心思想和经典算法用统计学的语言表达出来,帮助我们理解算法背后的原理。

因此,我决定开启这个专栏,用自己的方式整理学习笔记。主要目标是:
- 用更直白的语言梳理书中的概念
- 把知识点整理成便于查阅和复习的形式
- 记录自己的理解和思考过程
这些笔记主要是我个人的学习记录,如果恰好对你也有帮助,那就更好了。希望通过这个过程,能让自己对机器学习的理论基础有更扎实的理解。
第5章------决策树(下)
本章先介绍决策树的基本概念,然后通过 ID3 和 C4.5 介绍特征的选择、决策树的生成以及决策树的修剪,最后介绍 CART 算法。
5.4 决策树的剪枝
剪枝目标:解决过拟合问题,提升模型泛化能力。
在构建决策树的过程中,算法会不断递归划分数据,直到无法继续分裂为止。这样生成的模型通常能在训练集 上达到很高的分类准确率,但在测试集 上表现却未必理想,即可能出现 "过拟合" :模型为了追求训练数据的完美分类,学到了过多细节和噪声,结构变得过于复杂。
为减轻过拟合,需要在树生成后对其结构进行适当的简化,这个过程称为 剪枝(pruning)。
⭐️剪枝的核心思想是:
从已经生长完成的决策树中去掉某些子树或叶结点,用它们的父结点直接作为新的叶结点,从而让模型更简单、更具泛化能力。
5.4.1 预剪枝
核心思想: 在树生成过程中提前停止。
操作方式: 在每个结点划分前进行评估,若当前划分不能提升泛化能力,则停止分裂,直接将当前结点标记为叶结点。
特点: 预剪枝降低了过拟合风险,减少了训练时间和测试时间,但可能导致欠拟合,因为有些分支被提前截断。
常见的预剪枝方法:
- 限定决策树的深度
- 设定一个阈值
- 设置某个指标,比较结点划分前后的泛化能力
5.4.2 后剪枝
核心思想 :先生成完整树,再自底向上修剪。
操作方式:先生成一棵完整的决策树,然后从底部向上考察每个内部结点。若将内部结点替换为叶结点能提升泛化能力,则执行替换。
特点:后剪枝的泛化性能通常优于预剪枝,但训练时间开销较大,因为需要先生成完整的树。
常见的后剪枝方法:
- 降低错误剪枝 Reduce Error Pruning
- 悲观错误剪枝 Pessimistic Error Pruning
- 最小误差剪枝 Minimum Error Pruning
- 基于错误的剪枝 Error Based Pruning
- 代价复杂度剪枝 Cost-Complexity Pruning
☘️剪枝算法:
决策树剪枝的核心思想,就是给每一棵树计算一个"综合 cost",这个 cost 同时考虑两件事:
- 树对训练数据的拟合好不好
- 树复杂不复杂
这两部分一起构成下面的损失函数:
Cα(T)=∑t=1∣T∣NtHt(T)+α∣T∣ C_\alpha(T) = \sum_{t=1}^{|T|} N_t H_t(T) + \alpha|T| Cα(T)=t=1∑∣T∣NtHt(T)+α∣T∣
其中:
-
第一项
C(T)=∑t=1∣T∣NtHt(T) C(T)=\sum_{t=1}^{|T|} N_t H_t(T) C(T)=t=1∑∣T∣NtHt(T)衡量模型对训练数据的错误程度,越小越说明树拟合得越好。
-
第二项
α∣T∣ \alpha |T| α∣T∣用来惩罚树过于复杂。叶子越多、模型越复杂,惩罚越大。
经验熵用来计算叶结点的纯度:
Ht(T)=−∑kNtkNtlogNtkNt H_t(T) = -\sum_k \frac{N_{tk}}{N_t} \log \frac{N_{tk}}{N_t} Ht(T)=−k∑NtNtklogNtNtk
同时参数 α≥0\alpha \ge 0α≥0 控制"拟合好"和"模型简单"之间的权衡:
- α 小 → 更看重拟合 → 倾向选择更大、更复杂的树
- α 大 → 更看重简化 → 倾向选择更小、更简单的树
- α = 0 → 完全不考虑复杂度,只追求把训练数据分得更准确
所以,剪枝的目标就是:在给定 α 的情况下,找到使损失函数 Cα(T)C_\alpha(T)Cα(T) 最小的那棵子树。 树越大,拟合通常更好但复杂度高;树越小,简单但可能拟合不足。损失函数正是用来在两者之间做平衡的。
☘️剪枝算法步骤:
输入: 由生成算法得到的完整决策树 TTT ,以及参数 α\alphaα
输出: 剪枝后的子树 TαT_\alphaTα
(1) 计算每个结点的经验熵。
这是为了后续计算每个子树的损失函数做准备。
(2) 从底向上检查是否需要剪枝。
也就是从叶结点开始往上回缩。
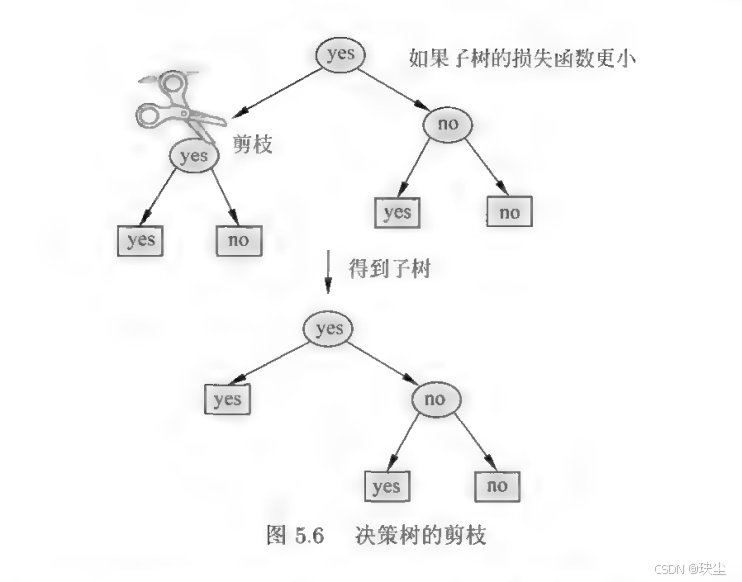
假设某一组叶结点在剪枝前的整棵树为 TBT_BTB,剪枝后(父结点变成叶结点)的树为 TAT_ATA。
分别计算它们的损失函数:
- Cα(TB)C_\alpha(T_B)Cα(TB):不剪枝的情况
- Cα(TA)C_\alpha(T_A)Cα(TA):剪枝后的情况
如果满足条件:
Cα(TA)≤Cα(TB) C_\alpha(T_A) \le C_\alpha(T_B) Cα(TA)≤Cα(TB)
说明剪枝后更优(损失更小),那么就把父结点变成一个新的叶子,也就是执行剪枝。
(3) 重复上述过程,直到无法再剪。
最终得到损失函数最小的子树 TαT_\alphaTα。
5.5 CART算法
CART 是机器学习中的经典算法,全称为 Classification and Regression Tree ,即分类与回归树。它使用树状结构来处理两类任务:
- 输出是离散值 → 这是一个分类问题
- 输出是连续值 → 这是一个回归问题
CART 的整体流程可以理解为"三步走":
-
选择特征
根据数据挑选最能分裂样本的特征。
-
生成决策树
按照特征不断分裂数据,长出一棵完整的树。
-
剪枝
对生成的树进行简化,去掉不必要的分支,以防过拟合。
5.5.1 CART生成
决策树的生成就是递归地构建二叉决策树的过程。对回归树用平方误差最小化准则,对分类树用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树。
1. 回归树的生成
假设输入变量为 XXX,输出变量为 YYY,并且 YYY 是连续变量。给定训练数据集:
D=(x1,y1),(x2,y2),...,(xN,yN) D = {(x_1,y_1),(x_2,y_2),\ldots,(x_N,y_N)} D=(x1,y1),(x2,y2),...,(xN,yN)
我们的目标是根据数据生成一棵 回归树,用于预测连续输出。可以把回归树理解为:
🌱 把输入空间划分成多个区域,每个区域对应一个固定的预测值。
假设输入空间被划成 MMM 个互不重叠的区域:
R1,R2,...,RM R_1, R_2,\ldots,R_M R1,R2,...,RM
并且每个区域都有一个固定输出值 cmc_mcm。那么回归树最终的模型就可以写成:
f(x)=∑m=1McmI(x∈Rm) f(x)=\sum_{m=1}^M c_m I(x\in R_m) f(x)=m=1∑McmI(x∈Rm)
其中 I(⋅)I(\cdot)I(⋅) 是指示函数:当 xxx 落在区域 RmR_mRm 中时取1,否则取0。
最优区域输出值的确定
区域划分已经确定的情况下,我们希望让预测误差最小。采用平方误差:
∑xi∈Rm(yi−f(xi))2 \sum_{x_i\in R_m}(y_i - f(x_i))^2 xi∈Rm∑(yi−f(xi))2
这个式子等价于:每个区域的最优输出值就是该区域内所有样本的平均值:
c^m=ave(yi∣xi∈Rm) \hat c_m = \operatorname{ave}(y_i \mid x_i\in R_m) c^m=ave(yi∣xi∈Rm)
也就是说:区域内的所有点输出一个平均值,就是最好的常数预测。
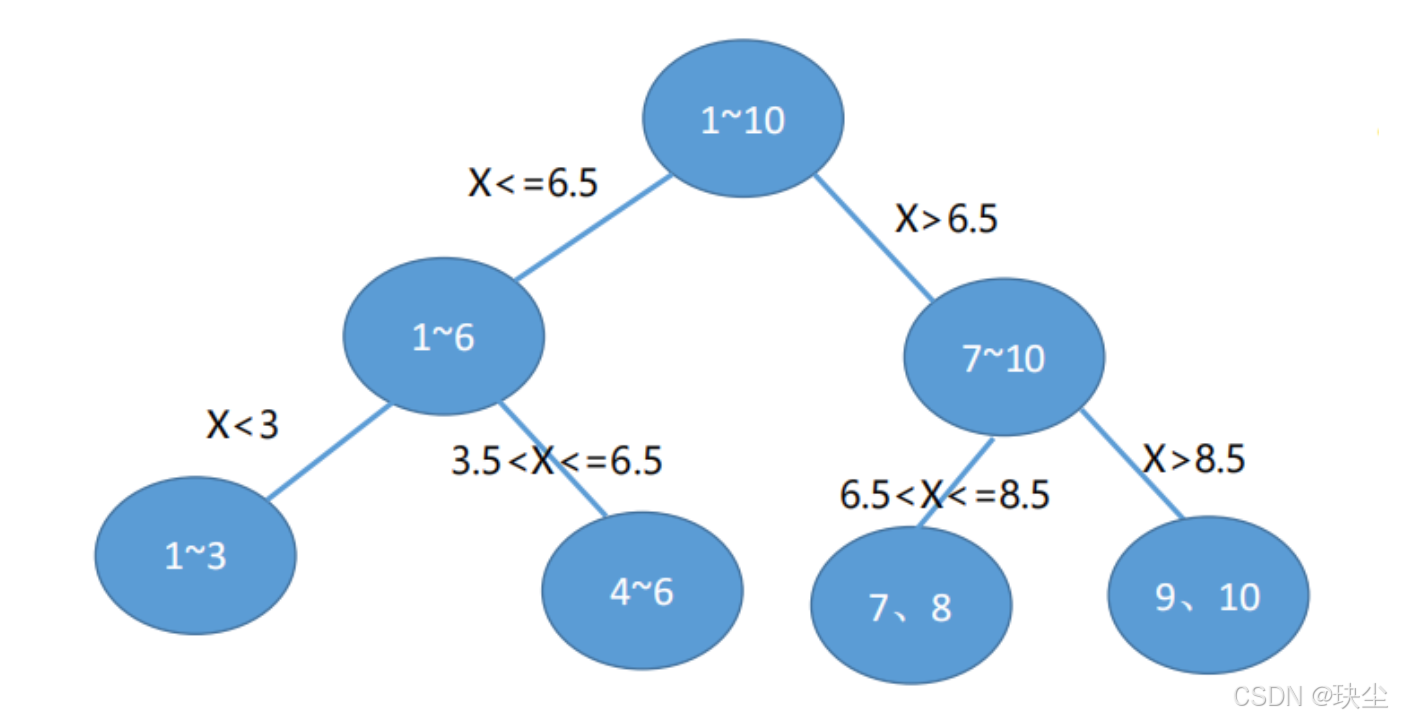
如何划分输入空间?(回归树的关键步骤)
回归树通过"二分法"划分输入空间。
做法如下:
对每一个输入变量 x(j)x^{(j)}x(j)(即第 jjj 个特征),以及它可能的取值 sss,把输入空间分成两个区域:
R1(j,s)=x∣x(j)≤s,R2(j,s)=x∣x(j)>s R_1(j,s)={x \mid x^{(j)}\le s},\quad R_2(j,s)={x \mid x^{(j)}>s} R1(j,s)=x∣x(j)≤s,R2(j,s)=x∣x(j)>s
然后我们寻找"最好的"特征 jjj 和切分点 sss。具体做法:
minj,sminc1∑xi∈R1(j,s)(yi−c1)2+minc2∑xi∈R2(j,s)(yi−c2)2 \min_{j,s}\left \\min_{c_1}\\sum_{x_i\\in R_1(j,s)}(y_i - c_1)\^2 + \\min_{c_2}\\sum_{x_i\\in R_2(j,s)}(y_i - c_2)\^2 \\right j,smin c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2
其中两个区域的最优输出仍然是平均值:
c1=ave(yi∣xi∈R1(j,s)) c_1=\operatorname{ave}(y_i\mid x_i\in R_1(j,s)) c1=ave(yi∣xi∈R1(j,s))
c2=ave(yi∣xi∈R2(j,s)) c_2=\operatorname{ave}(y_i\mid x_i\in R_2(j,s)) c2=ave(yi∣xi∈R2(j,s))
于是对于每个特征、每个可能的切分点,只要计算上述误差并取最小即可。最后得到那个让误差最小的 j,sj, sj,s,就是最优划分方式。
找到最优划分后,把输入空间分成两部分,并继续对两个子区域重复上述步骤:
- 在每个子区域内继续寻找最佳特征与最佳切分点
- 二分 → 再二分 → 再二分
- 直到满足停止条件(区域足够纯、样本足够少、误差足够小......)
最终得到的结构就是一棵完整的回归树,也叫:🌳 最小二乘回归树
⭐️CART最小二乘回归树生成算法
输入: 训练数据集 DDD
输出: 回归树 f(x)f(x)f(x)
Step 1:在所有特征和所有可能切分点中寻找最优划分
求解:
minj,sminc1∑xi∈R1(j,s)(yi−c1)2+minc2∑xi∈R2(j,s)(yi−c2)2 \min_{j,s} \left \\min_{c_1}\\sum_{x_i\\in R_1(j,s)}(y_i - c_1)\^2 + \\min_{c_2}\\sum_{x_i\\in R_2(j,s)}(y_i - c_2)\^2 \\right j,smin c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2
根据固定特征 jjj,遍历所有切分点 sss,找到最优的组合 (j,s)(j,s)(j,s)。
Step 2:用最优的 (j,s) 划分区域,并求区域输出值
R1(j,s)=x∣x(j)≤s,R2(j,s)=x∣x(j)>s R_1(j,s)={x \mid x^{(j)}\le s},\qquad R_2(j,s)={x \mid x^{(j)}>s} R1(j,s)=x∣x(j)≤s,R2(j,s)=x∣x(j)>s
区域输出为:
c^m=1∣Rm∣∑xi∈Rmyi,m=1,2 \hat c_m = \frac{1}{|R_m|}\sum_{x_i \in R_m} y_i,\quad m=1,2 c^m=∣Rm∣1xi∈Rm∑yi,m=1,2
Step 3:对子区域重复执行步骤 (1)(2)
不断递归,直到满足预设停止条件(例如:样本太少或误差足够小)。
Step 4:最终将输入空间划分为多个区域
得到区域 R1,R2,...,RMR_1,R_2,\ldots,R_MR1,R2,...,RM,并形成最终回归树:
f(x)=∑m=1Mc^mI(x∈Rm) f(x)=\sum_{m=1}^{M} \hat c_m I(x\in R_m) f(x)=m=1∑Mc^mI(x∈Rm)
2. 分类树的生成
核心思想:CART算法使用基尼指数选择最优特征,同时决定该特征的最优二值切分点。
在生成一棵决策树时,第一步永远是:选特征 。
不同算法的选特征方式不同:
-
ID3:看谁的信息增益最大
-
C4.5:看谁的信息增益比最大
-
CART:看谁的基尼指数最小
基尼指数定义
在分类问题中,假设有K个类,样本点属于第k类的概率为pkp_kpk,则概率分布的基尼指数定义为:
Gini(p)=∑k=1Kpk(1−pk)=1−∑k=1Kpk2\text{Gini}(p) = \sum_{k=1}^{K} p_k(1-p_k) = 1 - \sum_{k=1}^{K} p_k^2Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
二分类时更简单,如果第一类的概率为 ppp,则:
Gini(p)=2p(1−p)\text{Gini}(p) = 2p(1-p)Gini(p)=2p(1−p)
给定一个样本集合 DDD,它的基尼指数为:
Gini(D)=1−∑k=1K(∣Ck∣∣D∣)2\text{Gini}(D) = 1 - \sum_{k=1}^{K} \left(\frac{|C_k|}{|D|}\right)^2Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
这里,CkC_kCk是D中属于第k类的样本子集,K是类的个数。
基尼指数越大,集合越"杂乱";越小,集合越"纯净"。
特征条件下的基尼指数
当特征 AAA 取某个值 aaa 时,将集合 DDD 划分成两部分:
D1={(x,y)∈D∣A(x)=a},D2=D−D1D_1 = \{(x,y) \in D | A(x) = a\}, \quad D_2 = D - D_1D1={(x,y)∈D∣A(x)=a},D2=D−D1
分割后的不确定性为:
Gini(D,A)=∣D1∣∣D∣Gini(D1)+∣D2∣∣D∣Gini(D2)\text{Gini}(D, A) = \frac{|D_1|}{|D|}\text{Gini}(D_1) + \frac{|D_2|}{|D|}\text{Gini}(D_2)Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
CART 就是通过对所有特征、所有可能切分点计算这个量,选择最小的那个。基尼指数值越大,样本集合的不确定性也就越大,这一点与熵相似。
⭐️CART分类树生成算法
输入 :数据集 DDD,特征集 AAA ,停止条件阈值 εεε
输出:CART分类决策树
Step 1 从根节点出发,构建二叉树
Step 2 选择最优特征 + 最优切分点(CART 的关键)
对于特征集 AAA 中的每个特征
- 枚举其所有可能的取值
- 每取一个值 aaa,将数据集切分为 D1D_1D1和 D2D_2D2
- 计算对应的 Gini(D,A)Gini(D,A)Gini(D,A)
- 找到该特征下的最优切分点(基尼指数最小)
最后,再从所有特征中选出
- 最优特征 = 基尼指数最小的特征
- 最优切分点 = 对应的最优二值划分
这就是 CART 的第一步------通过基尼指数完成特征选择。
Step 3 按最优切分点将数据集二分,生成左右子节点
数据更"干净"的那一边会更快变成叶结点。
Step 4 对子节点递归重复步骤 2--3
直到满足停止条件:
- 基尼指数已经很小,样本几乎属于同一类
- 或者没有可分的特征了
到这里,一棵完整的 CART 分类树就生成了。
5.5.2 CART剪枝
决策树容易过拟合,剪枝是解决这个问题的关键技术。CART使用代价复杂度剪枝(Cost-Complexity Pruning),通过平衡模型复杂度和预测准确度来获得最优决策树。
1. 损失函数
CART剪枝的核心是损失函数,它用来衡量模型的整体性能:
Cα=C(T)+α∣T∣C_\alpha = C(T) + \alpha|T|Cα=C(T)+α∣T∣
这个公式包含两个部分:
- C(T)C(T)C(T) :反映模型的拟合能力,表示对训练数据的预测误差(比如基尼指数)
- ∣T∣|T|∣T∣ :反映模型的复杂度,表示树上叶子节点的个数。叶子结点越多,模型越复杂
α\alphaα 的作用:
- 当 α=0\alpha = 0α=0 时,模型仅由拟合决定,不考虑对未知数据的预测能力,得到的是一棵最完整的决策树,泛化能力弱
- 当 α=+∞\alpha = +\inftyα=+∞ 时,得到的是单结点树,对于任何数据的泛化能力很强,但拟合效果差
☘️原理: 根据剪枝前后的损失函数来决定是否剪枝。剪枝后,如果损失函数减小,则意味着可以剪枝。
2. 参数选择
如何选择合适的 α\alphaα 呢?我们将 α\alphaα 从 0 到 +∞+\infty+∞ 划分成多个小区间:
0≤α0<α1<α2⋯<αn<αn+1<+∞0 \leq \alpha_0 < \alpha_1 < \alpha_2 \cdots < \alpha_n < \alpha_{n+1} < +\infty0≤α0<α1<α2⋯<αn<αn+1<+∞
每一个 α\alphaα 对应一棵决策树。然后把这些 α\alphaα 按照"左闭右开"的形式划分小区间:
[α1,α2),[α2,α3),⋯[αn,αn+1)[\alpha_1, \alpha_2), [\alpha_2, \alpha_3), \cdots [\alpha_n, \alpha_{n+1})[α1,α2),[α2,α3),⋯[αn,αn+1)
总共有 nnn 个区间,每个小区间都对应着一个决策树,我们可以记成:
T0,T1,T2,⋯TnT_0, T_1, T_2, \cdots T_nT0,T1,T2,⋯Tn
这里 T0T_0T0 代表 α=0\alpha = 0α=0 时的完整决策树,意味着没有剪枝。
核心思想: 我们要从这些决策树里,找到最优的决策树。
假设现在我们有这么一棵子树 TiT_iTi。
剪枝前的损失函数可以写成:
Cα(Tt)=C(Tt)+α∣Tt∣C_\alpha(T_t) = C(T_t) + \alpha|T_t|Cα(Tt)=C(Tt)+α∣Tt∣
剪枝后变成了一个叶子结点,此时 ∣T∣=1|T| = 1∣T∣=1,损失函数可以写成:
Cα(Tt)=C(t)+αC_\alpha(T_t) = C(t) + \alphaCα(Tt)=C(t)+α
随着 α\alphaα 从 0 逐渐变大到 +∞+\infty+∞,意味着从高度拟合到高度泛化的变化趋势。可以得出在高度拟合和高度泛化时,所对应的损失函数都是非常大的。
而在这变化过程中,意味着剪枝前和剪枝后的会有一个临界值 α\alphaα,在这个临界值处,拟合 和泛化的损失函数为最小。
这个值可以联立两个方程求解:
α=Cα(Tt)−C(t)\alpha = C_\alpha(T_t) - C(t)α=Cα(Tt)−C(t)
=C(Tt)+α∣Tt∣−C(t)= C(T_t) + \alpha|T_t| - C(t)=C(Tt)+α∣Tt∣−C(t)
移项后:
α=C(t)−C(Tt)∣Tt∣−1\alpha = \frac{C(t) - C(T_t)}{|T_t| - 1}α=∣Tt∣−1C(t)−C(Tt)
接着我们就来看看这个值该怎么用。
3. 剪枝步骤
输入: CART算法生成的完整决策树
输出: 最优决策树 TαT_\alphaTα
Step1 设 k=0,T=T0k = 0, T = T_0k=0,T=T0,也就是从完整的决策树出发
kkk 代表的是迭代的次数,这里从 0 开始,也就意味着还没开始迭代,那么树也是完整的,从这里开始出发。
Step2 设 α=+∞\alpha = +\inftyα=+∞,因为后面我们要比较大小,当损失函数小的时候可以剪枝
相当于由大至小开始比较。
Step3 自下而上的对各内部结点 ttt 计算 C(Tt),∣Tt∣C(T_t), |T_t|C(Tt),∣Tt∣,以及
g(t)=C(t)−C(Tt)∣Tt∣−1,α=min(α,g(t))g(t) = \frac{C(t) - C(T_t)}{|T_t| - 1}, \quad \alpha = min(\alpha, g(t))g(t)=∣Tt∣−1C(t)−C(Tt),α=min(α,g(t))
这里的 g(t)g(t)g(t) 代表了在这个结点对应的 α\alphaα 值。
- C(t)C(t)C(t) 代表了单结点时的预测误差
- C(Tt)C(T_t)C(Tt) 代表了子树时的预测误差
注意: 此处的预测误差与我们之前所介绍的预测错误率不同,它还可以包括平方损失、基尼指数等。
Step4 自上而下访问内部结点 ttt,如果有 g(t)=αg(t) = \alphag(t)=α,则进行剪枝,并对叶结点 ttt 以多数表决法决定类,得到树 TTT
Step5 接着增加迭代次数,继续调用,最终采用交叉验证法在子树 T0,T1,T2,⋯TnT_0, T_1, T_2, \cdots T_nT0,T1,T2,⋯Tn 中选取最优子树 TαT_\alphaTα
本章概要
-
分类决策树是基于特征对实例进行分类的树形结构,可转换为if-then规则集合,表示特征空间划分上的类条件概率分布。
-
决策树学习旨在构建一个与训练数据拟合好且复杂度小的决策树。直接选取最优决策树是NP完全问题,现实采用启发式方法学习次优决策树。决策树学习包括三部分:特征选择 、决策树的生成 和决策树的剪枝。常用算法有ID3、C4.5和CART。
-
特征选择准则:
(1) 信息增益 (ID3)
g(D,A)=H(D)−H(D∣A)g(D, A) = H(D) - H(D|A)g(D,A)=H(D)−H(D∣A)
H(D)=−∑k=1K∣Ck∣∣D∣log2∣Ck∣∣D∣H(D) = -\sum_{k=1}^{K} \frac{|C_k|}{|D|} \log_2 \frac{|C_k|}{|D|}H(D)=−k=1∑K∣D∣∣Ck∣log2∣D∣∣Ck∣
H(D∣A)=∑i=1n∣Di∣∣D∣H(Di)H(D|A) = \sum_{i=1}^{n} \frac{|D_i|}{|D|} H(D_i)H(D∣A)=i=1∑n∣D∣∣Di∣H(Di)
(2) 信息增益比 (C4.5)
gR(D,A)=g(D,A)HA(D)g_R(D, A) = \frac{g(D, A)}{H_A(D)}gR(D,A)=HA(D)g(D,A)
(3) 基尼指数 (CART)
Gini(D)=1−∑k=1K(∣Ck∣∣D∣)2\text{Gini}(D) = 1 - \sum_{k=1}^{K} \left(\frac{|C_k|}{|D|}\right)^2Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
Gini(D,A)=∣D1∣∣D∣Gini(D1)+∣D2∣∣D∣Gini(D2)\text{Gini}(D, A) = \frac{|D_1|}{|D|}\text{Gini}(D_1) + \frac{|D_2|}{|D|}\text{Gini}(D_2)Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
-
决策树的生成。从根节点开始,通过计算信息增益等指标递归选择最优特征进行分裂,将训练集分割为能够基本正确分类的子集。
-
决策树的剪枝。生成的决策树存在过拟合问题,需要剪枝简化。从已生成的树上剪掉一些叶结点或叶结点以上的子树,将其父结点或根结点作为新的叶结点,从而简化决策树。