几何解释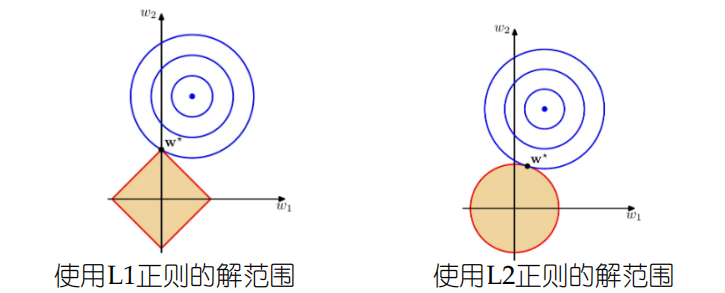
等高线:表示原始的损失函数,同心椭圆的中心是原始模型的最优解(不考虑正则化)。
约束区域:正则化项对权重向量的取值范围施加了限制
L1(菱形):菱形的顶点在坐标轴上。当等高线与菱形边界相交时,交点(即新的最优解)有极大的概率落在菱形的顶点上,而顶点所在的坐标轴意味着另一个特征对应的权重为0。
L2(圆形):圆形没有尖尖的角。等高线与圆形边界相切的点(即新的最优解)几乎不可能落在坐标轴上,所以所有权重都会被保留,只是被缩小了。
稀疏性与平滑性
L1正则化产生稀疏性:"稀疏"指的是权重向量 w中会有很多值为0。L1正则化倾向于将一些不重要的特征所对应的权重完全压缩到0。这意味着模型在训练后会自动进行特征选择,只保留那些对预测目标最重要的特征。
好处:模型更简单、可解释性更强。对于高维数据(特征非常多),能有效降低维度。
L2正则化使权重均匀缩小:L2正则化不会把任何权重强制设为0,而是将所有的权重以同等比例向零缩小。对于贡献大的特征,权重值依然较大;对于贡献小的特征,权重值会变得很小,但不会是零。
好处:模型更平滑、稳定。能处理特征之间存在多重共线性(高度相关)的情况。
附:
