Elasticsearch
-
Elasticsearch是一款非常强大的开源分布式搜索和分析引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
-
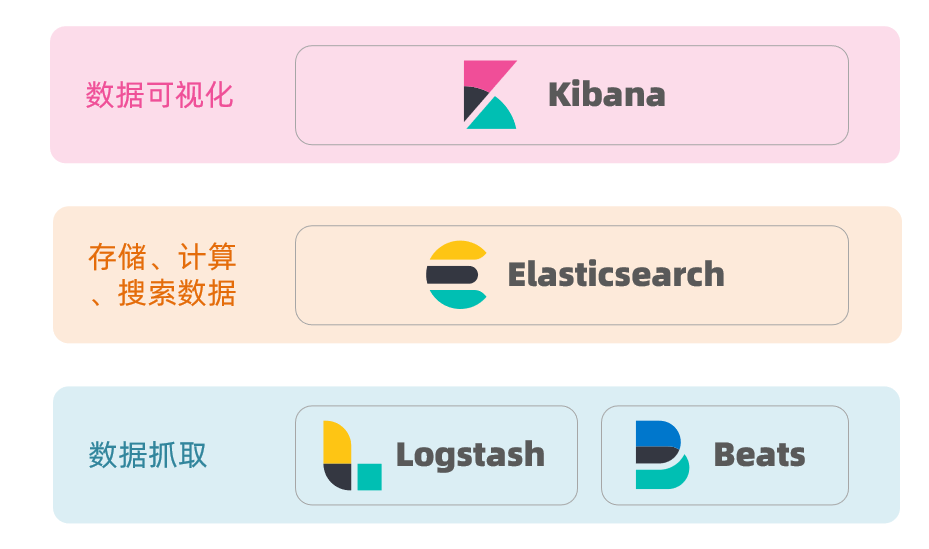
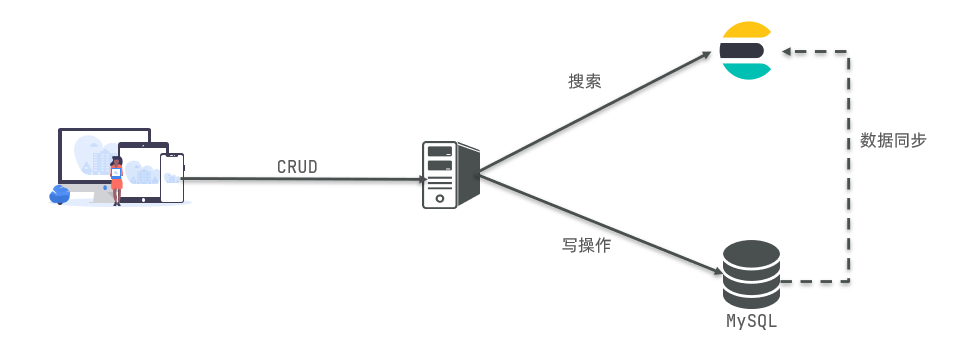
Elasticsearch结合Kibana、Logstash、Beats,也就是Elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域:
-
Elastic stack架构
- Elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
- 除了Elasticsearch外,其余两个层级架构中用到的技术都是可替换的
-
-
Elasticsearch底层是基于lucene来实现的。
-
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/
- 优势
- 易拓展
- 高性能(Lucene底层基于倒排索引实现)
- 劣势
- 仅限于Java语言开发
- 不支持水平扩展
- 学习曲线陡峭
- 优势
-
Shay Banon在2004年基于Lucene开发了Compass;2010年又重写了Compass,取名为Elasticsearch。官网地址:https://www.elastic.co/cn/
- 优势
- 支持分布式,可水平扩展
- 提供Restful接口,可被任何语言调用
- 优势
-
正向索引和倒排索引
-
正向索引:数据库表一般情况下都会基于id创建索引,此时若根据id查询,由于会直接走索引,所以查询速度会非常快,这就是正向索引
-
劣势:如果用户在查询时并未基于id查询,而是基于其它未创建索引的字段进行
like模糊查询,此时就需要逐行扫描数据来判断是否包含模糊查询中的条件。若不包含则丢弃,若包含则存入结果集中,然后继续向后扫描。此时若表中数据过多,就会影响效率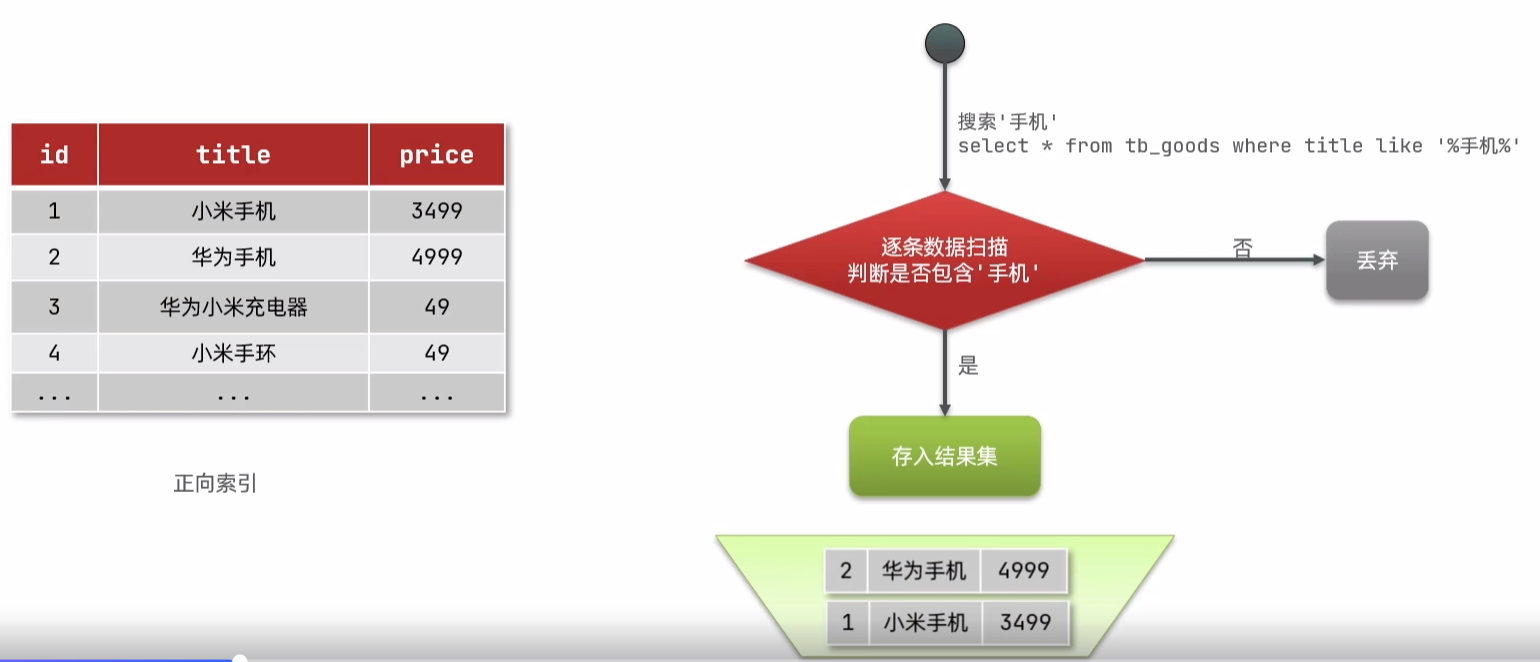
-
-
倒排索引是对正向索引的一种特殊处理,它有两个非常重要的概念

- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
- 文档(
-
倒排索引的搜索流程如下(以搜索"华为手机"为例):
- 用户输入条件
"华为手机"进行搜索。 - 对用户输入内容分词 ,得到词条:
华为、手机。 - 拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
- 拿着文档id到正向索引中查找具体文档。
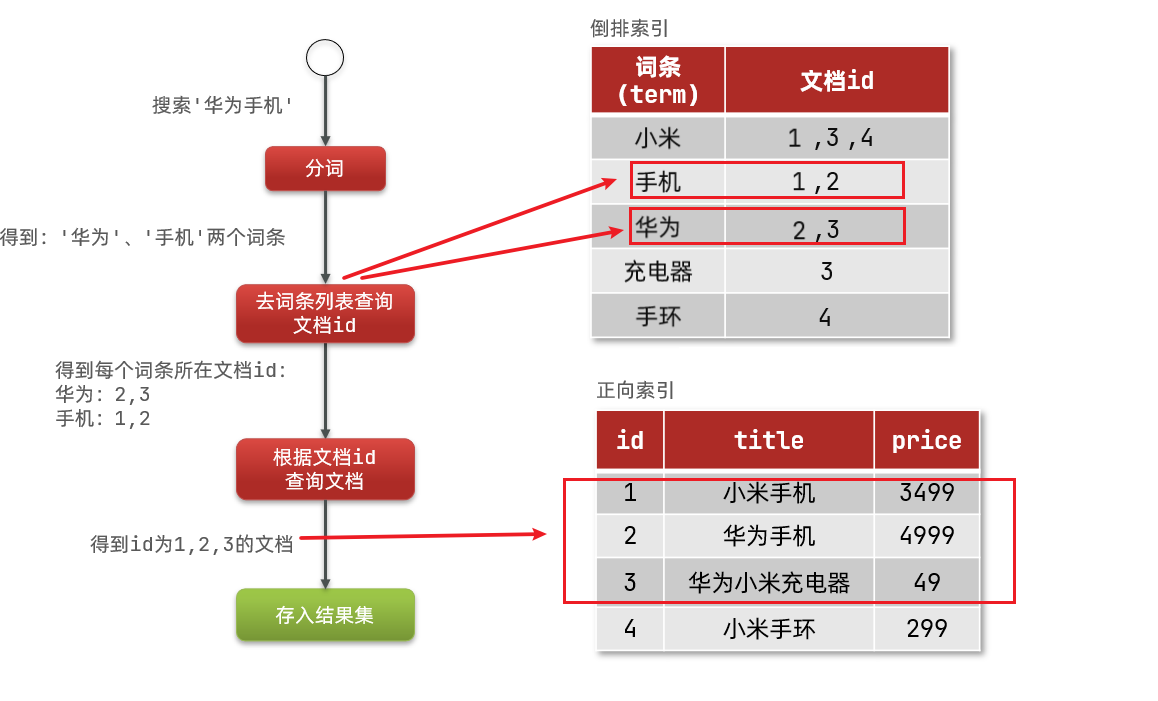
- 用户输入条件
-
注意:使用倒排索引时虽然要先查询倒排索引,再查询倒排索引,但是 词条和文档id都建立了索引 ,所以查询速度非常快,无需全表扫描。
-
正向索引和倒排索引优缺点
- 正向索引
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描
- 优点:
- 倒排索引
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
- 优点:
- 正向索引
ES基础概念
-
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中
- Json文档中往往包含很多的字段(Field),类似于数据库中的列。

索引和映射
-
ES中的索引就是相同类型的文档的集合。因此,可以把索引当做数据库中的表(因为数据库表中存储的都是同一类型的数据)
-
示例:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

-
-
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
ES与MySQL对比
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
-
ES与MySQL使用场景
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性。适用于对安全性要求较高的写操作
- Elasticsearch:擅长海量数据的搜索、分析、计算。适用于对查询性能要求较高的搜索需求
-
MySQL会基于某种方式将数据同步给ES,保证数据一致性
ES安装
Linux部署单点ES
-
Step1: 创建es网络
由于后续需要部署Kibana容器,让ES与Kibana实现容器互联从而使数据可视化,因此需要先创建一个网络
shdocker network create es-net -
Step2: 查看Docker库是否有对应版本的ES镜像并拉取镜像(博主采用7.12.1版本)
shdocker search elasticsearch docker pull elasticsearch:7.12.1注意:
由于elasticsearch较大,不建议使用docker pull从官网拉取,可将镜像包es.tar传到Linux中,然后利用
docker load -i es.tar命令来加载镜像到本地 -
Step3: 创建并运行ES容器,同时设置端口映射、目录映射等
shdocker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xms512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.1注意:创建并运行容器时的配置参数可详见Docker部分内容,此处只针对特殊参数进行说明:
-
-e "ES_JAVA_OPTS=-Xms512m -Xms512m":设置JVM的堆内存大小为512M -
-e "discovery.type=single-node":设置ES为单点运行模式 -
-v es-data:/usr/share/elasticsearch/data:ES数据保存目录 -
-v es-plugins:/usr/share/elasticsearch/plugins:ES插件目录,主要用于对ES的扩展 -
--privileged=true:让ES容器获取宿主机的几乎所有权限;若不添加则无法访问ES -
-p 9200:9200:暴露给用户的Http协议端口,供用户访问 -
-p 9300:9300:ES容器内各个节点之间互联的端口
-
-
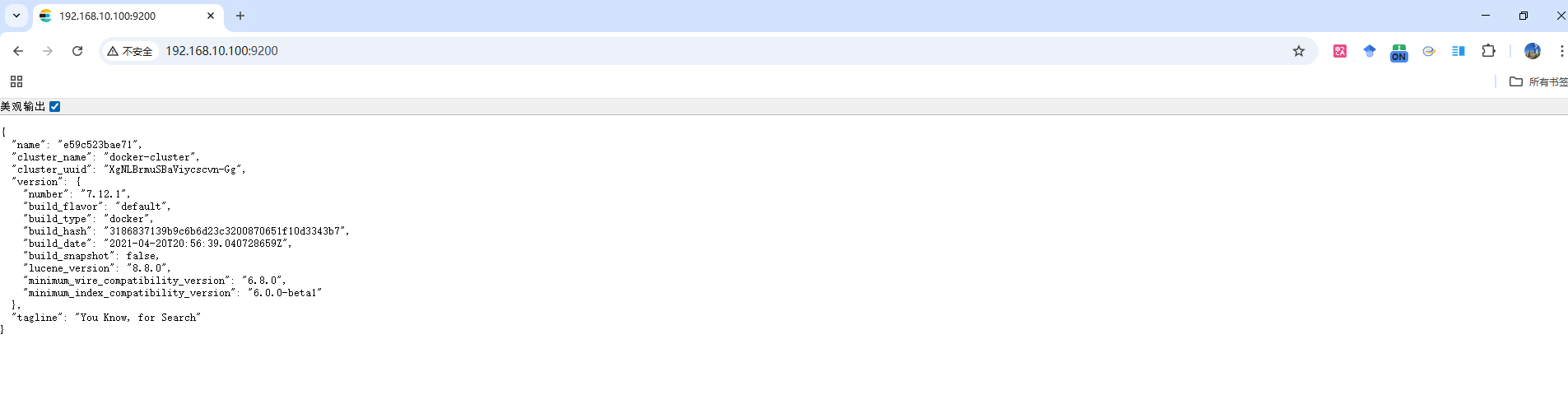
Step4: ES容器创建并启动成功后,在浏览器输入
所使用虚拟机的ip地址:9200即可访问,如下图所示。注意:由于ES是纯JSON形式显示,数据不够直观,所以为了方便用户需进行图形化展示,因此还需步骤Kibana
Kibana安装
-
Step1: 查看Docker库是否有对应版本的Kibana镜像并拉取镜像(博主采用7.12.1版本)
shdocker search kibana docker pull kibana:7.12.1注意:
-
由于kibana较大,不建议使用docker pull从官网拉取,可将镜像包kibana.tar传到Linux中,然后利用
docker load -i kibana.tar命令来加载镜像到本地 -
Kibana版本要与ES版本保持一致
-
-
Step2: 创建并运行Kibana容器
shdocker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network es-net \ -p 5601:5601 \ kibana:7.12.1-e ELASTICSEARCH_HOSTS=http://es:9200:配置ES的地址- 由于Kibana和ES处于同一个网络es-net中,所以Kibana可直接使用ES的容器名es来直接访问ES
-p 5601:5601:暴露给用户的Http协议端口,供用户访问
-
Step3: 由于Kibana容器启动较慢,所以可利用
docker logs -f kibana来查询Kibana容器启动日志,若出现如图所示红框内容,则代表Kibana容器启动成功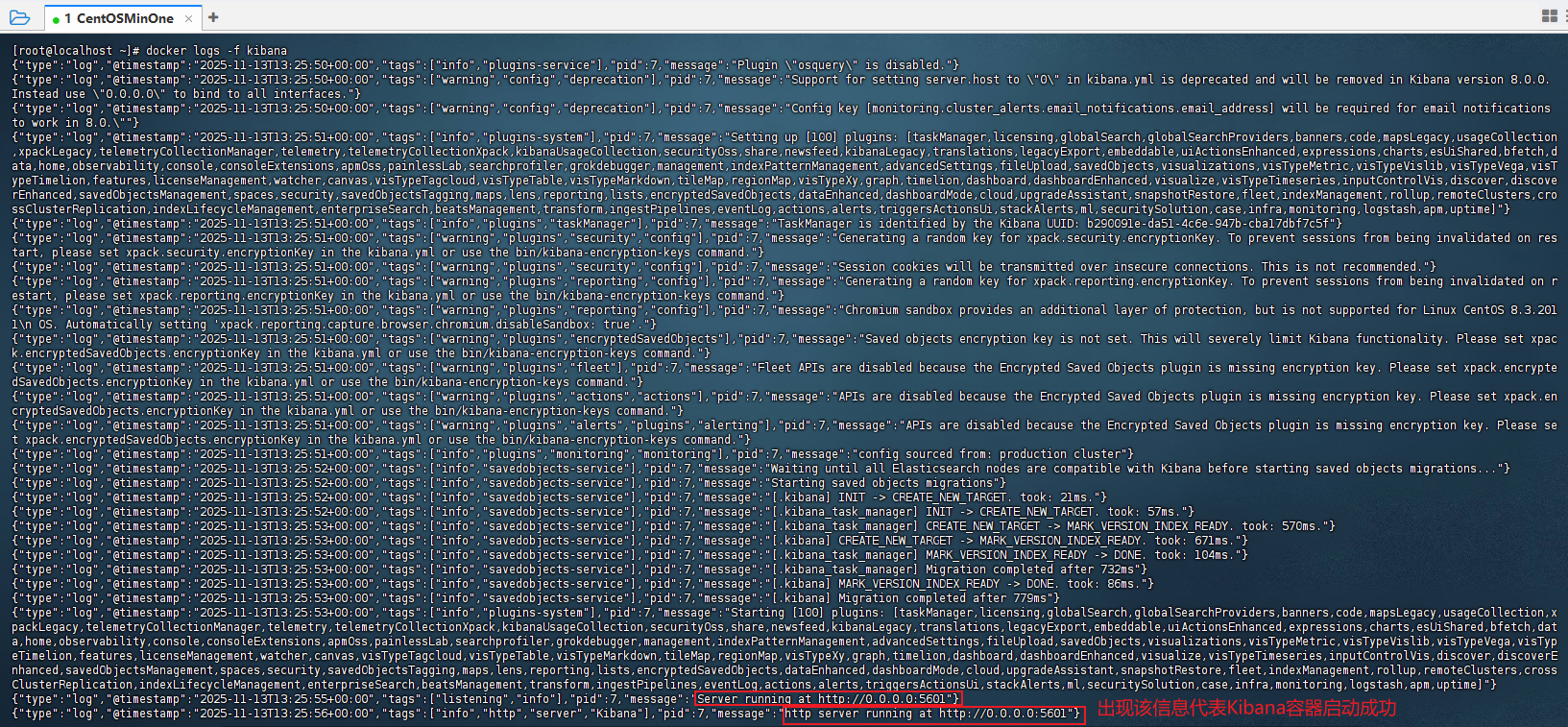
-
Step4: Kibana容器创建并启动成功后,在浏览器输入
所使用虚拟机的ip地址:5601即可访问,初始界面如下图所示。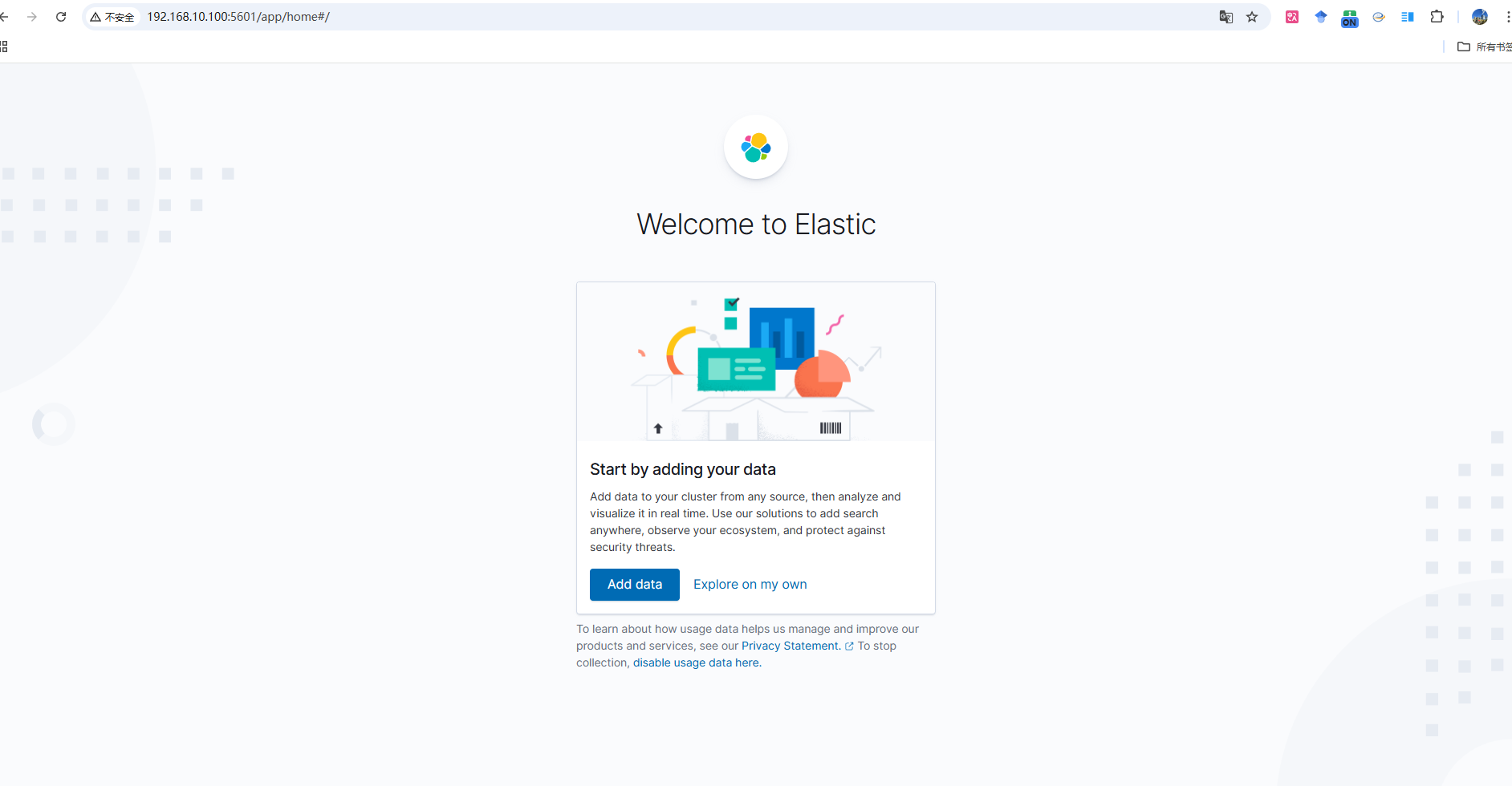
DSL控制台
单击初始界面
Explore on my own即可进入Home界面,然后在单击右上角的 Dev tools 即可进入DSL控制台发送DSL请求
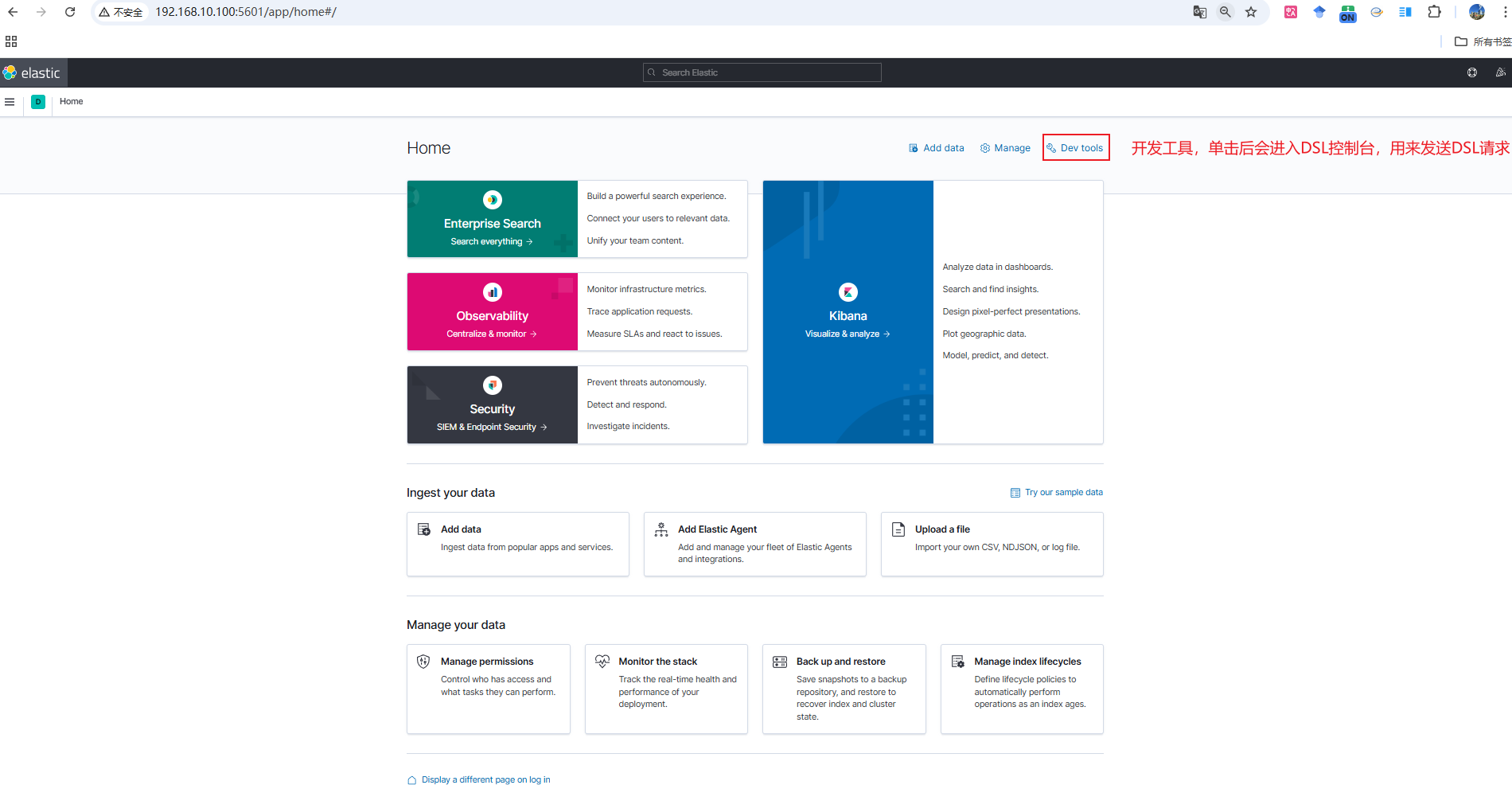
-
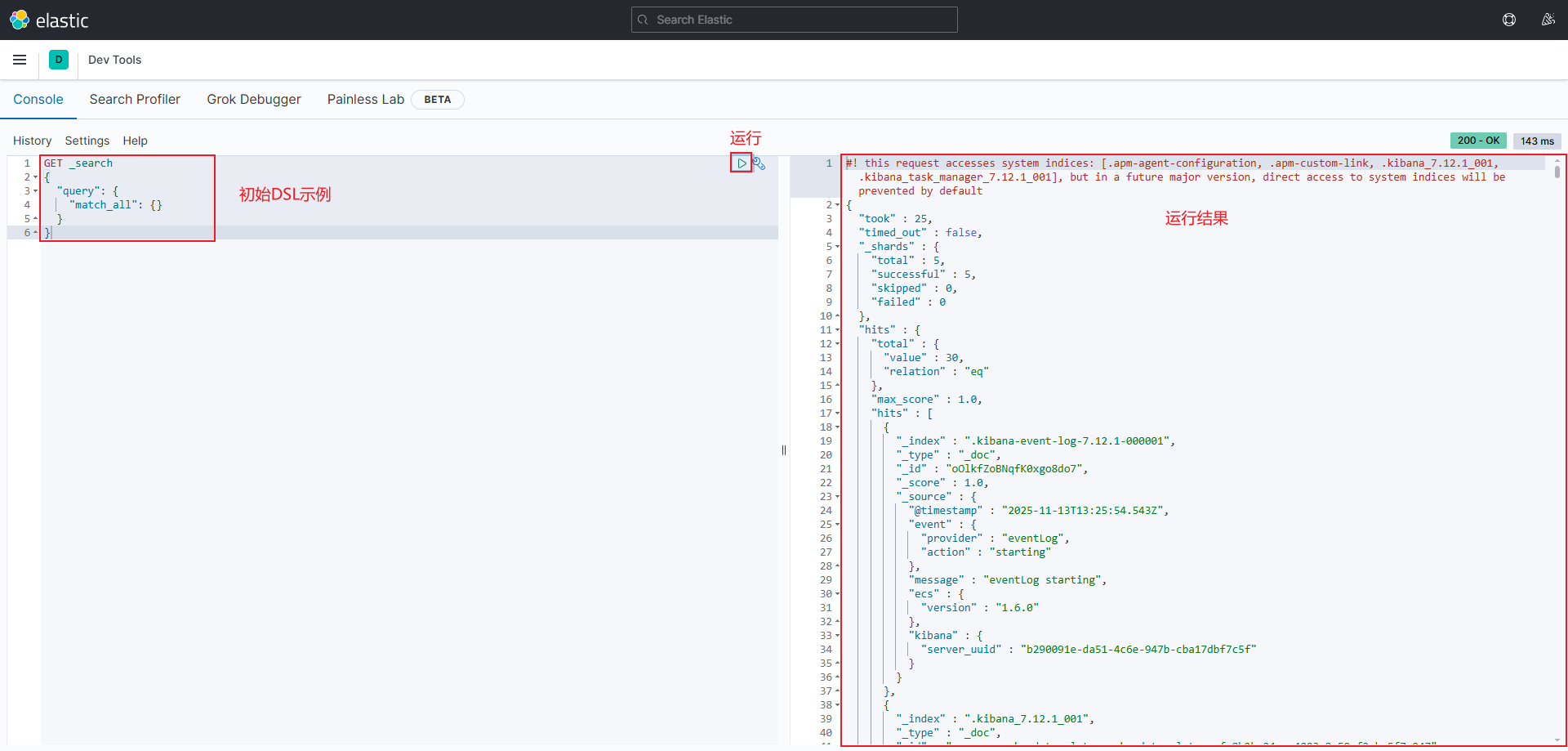
进入DSL控制台界面后会有一个初始示例,单击运行图标按钮即可运行
- 注意:由于在创建Kibana容器时已经制定了ES的容器地址,并且Kibana与ES处于同一个网络下,所以在Kibana图形化界面的DSL控制台中就会自动将DSL语句发送到ES进行请求
- 本质:向ES发送了一个RestFul请求
- 注意:由于在创建Kibana容器时已经制定了ES的容器地址,并且Kibana与ES处于同一个网络下,所以在Kibana图形化界面的DSL控制台中就会自动将DSL语句发送到ES进行请求
-
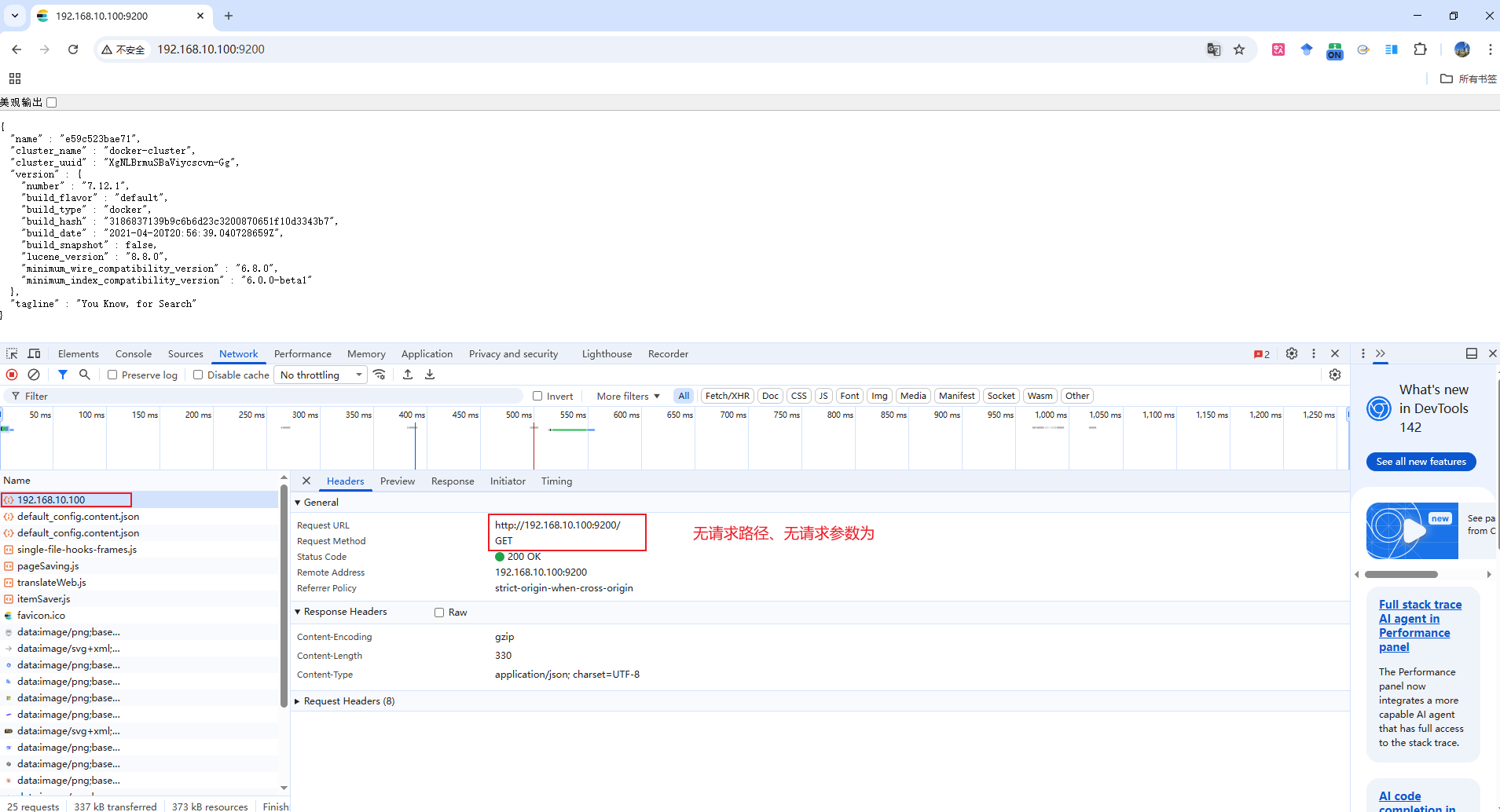
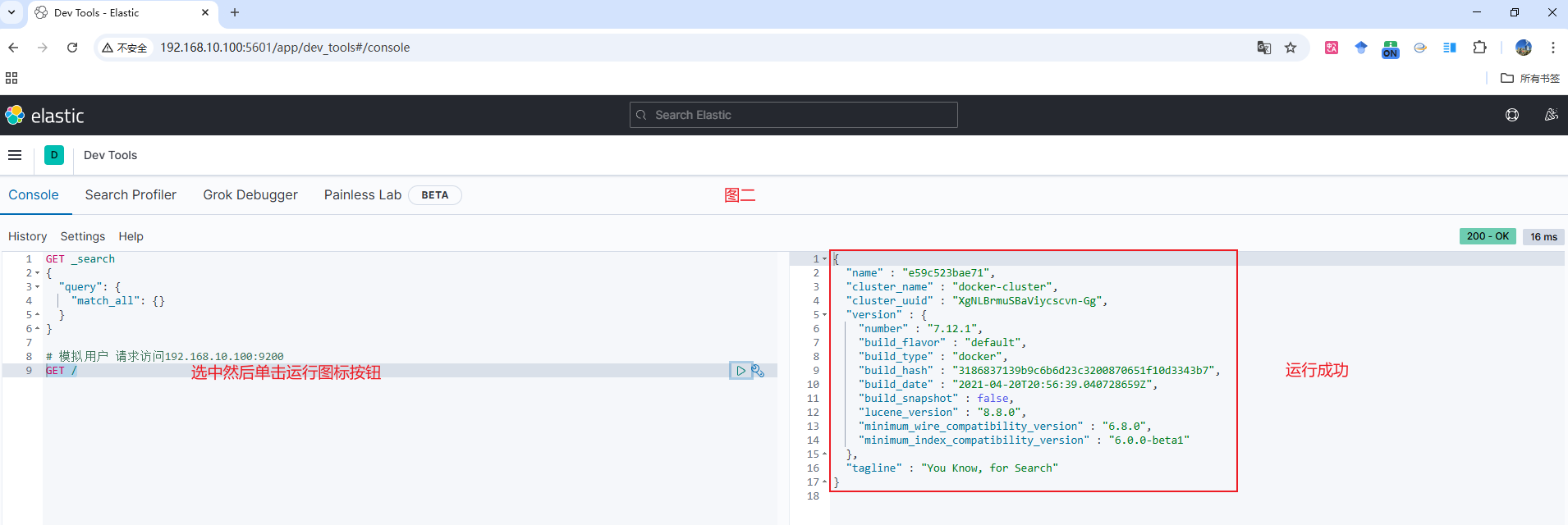
ES容器创建并启动成功后,在浏览器输入的
所使用虚拟机的ip地址:9200也是一个RestFul请求(因为访问到了JSON数据),只是说该请求的请求路径为空,且无参数(如图一所示),所以我们可以将其在Kibana图形化界面的DSL控制台中复现,如图二所示- 后续在在Kibana图形化界面的DSL控制台进行复杂请求时,即可省略
所使用虚拟机的ip地址:9200,直接请求方式 /请求路径即可,示例可详见 分词语法格式说明 部分内容
- 后续在在Kibana图形化界面的DSL控制台进行复杂请求时,即可省略
IK分词器安装
- ES分词情况/作用:
- ES在创建倒排索引时会对文档进行分词
- 在搜索时,ES会对用户输入的内容进行分词
- 注意
- ES默认的分词规则无法对中文进行详细且正确分词,因此需借助IK分词器进行分词
- IK分词器版本要与ES版本保持一致
在线安装
注意:IK分词器在线安装较慢,不建议使用
-
Step1: 进入ES容器内部
shdocker exec -it elasticsearch /bin/bash -
Step2: 在线下载IK分词器并安装
sh./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip -
Step3: 利用
exit退出ES容器 -
Step4: 重启ES容器
docker restart elasticsearch
离线安装
-
Step1: 查看之前安装的ES容器的plugins数据卷目录
shdocker volume inspect es-plugins结果如图所示,可看到plugins目录被挂在到了
/var/lib/docker/volumes/es-plugins/_data目录中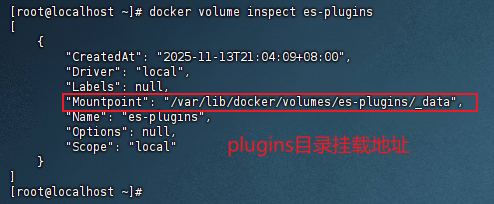
-
Step2: 将IK分词器压缩包解压并命名为ik,然后
-
Step3: 进入到
/var/lib/docker/volumes/es-plugins/_data目录中,进入步骤如图所示
-
Step4: 将解压后获取的ik目录上传到Linux的
/var/lib/docker/volumes/es-plugins/_data目录中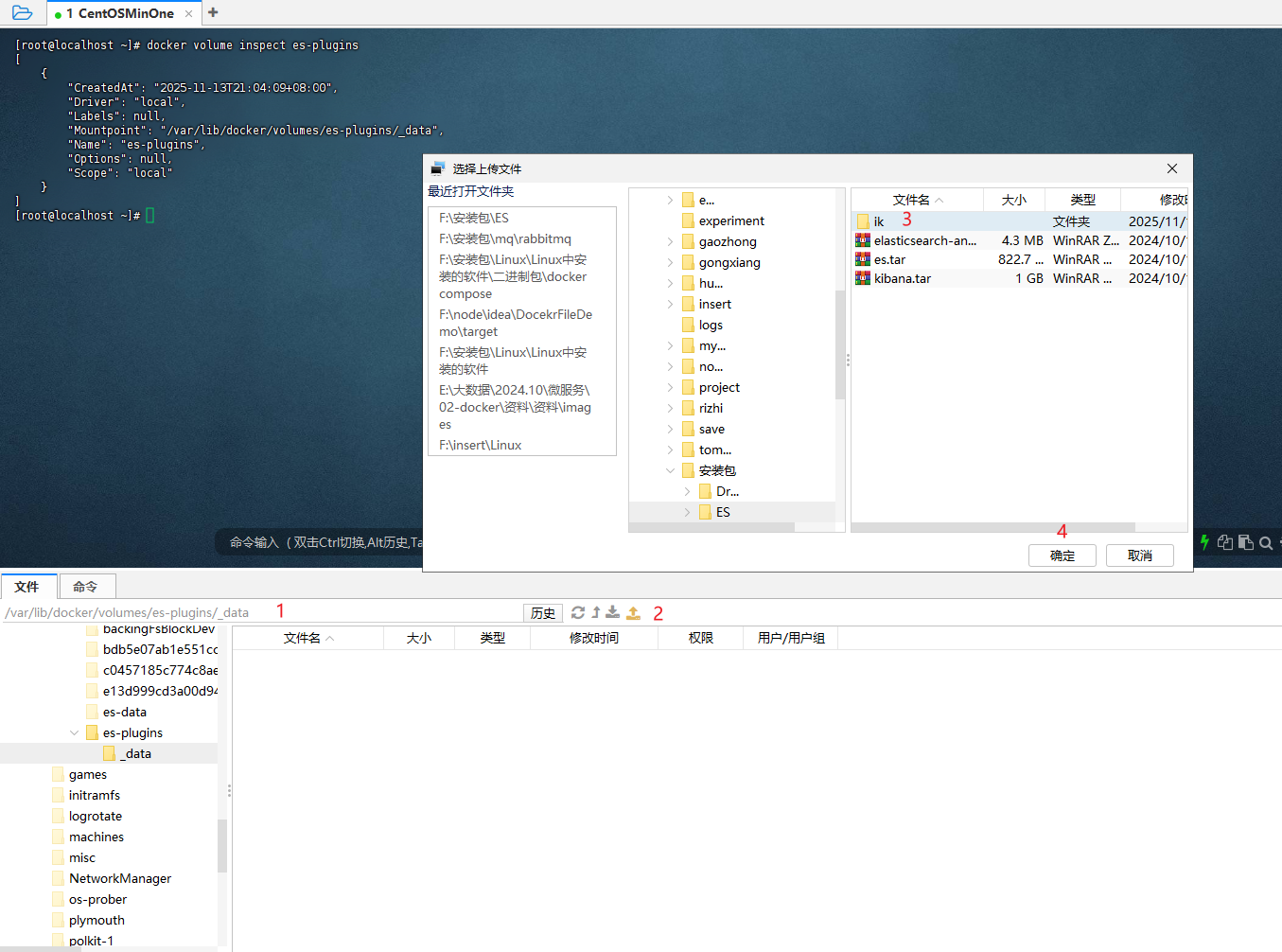
-
Step5: 利用
docker restart es重启ES容器 -
Step6: 利用
docker logs -f es查看ES日志,若看到loaded plugin [analysis-ik],则说明IK安装成功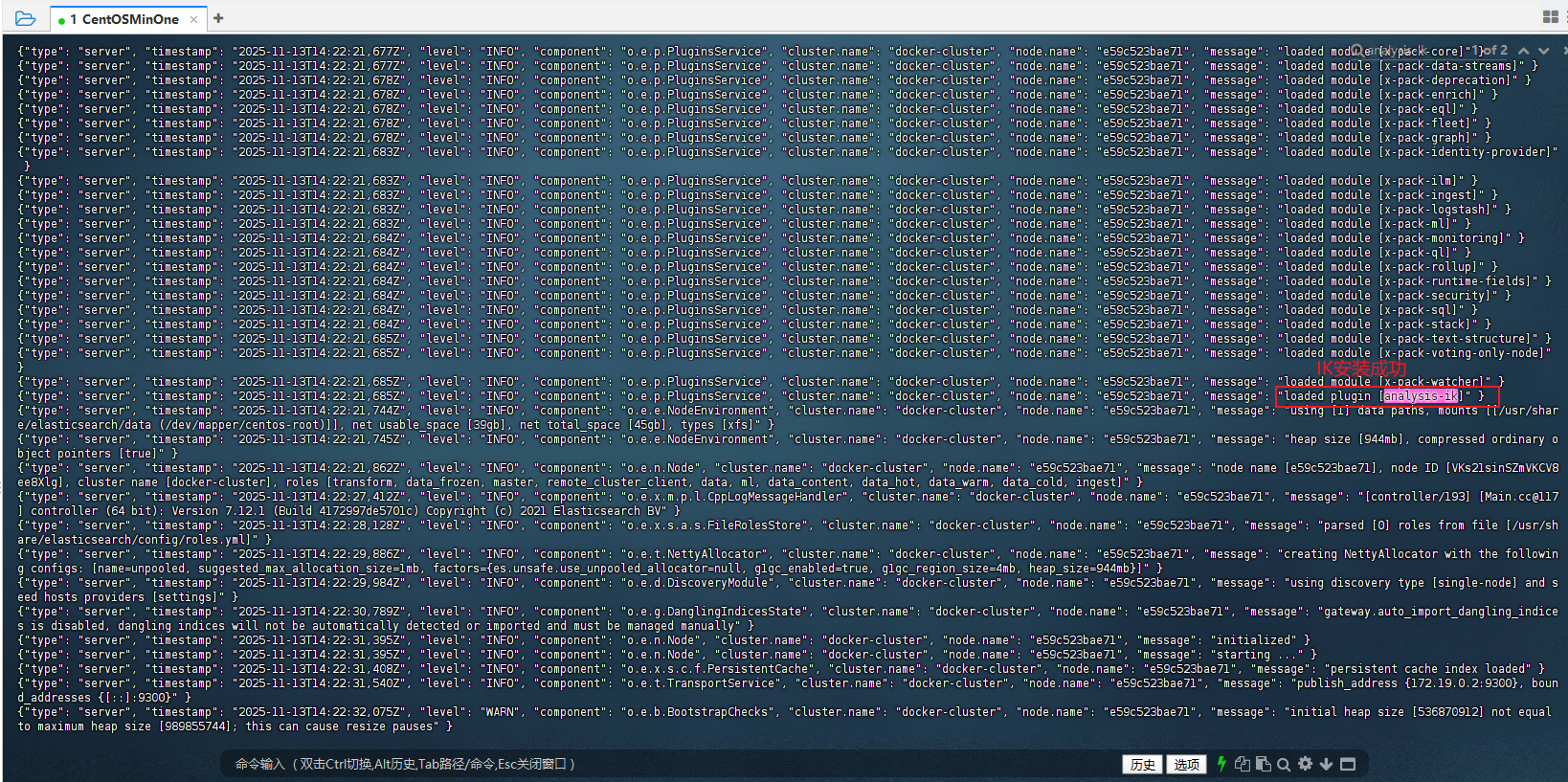
ES与IK分词器对比示例
-
ES自带分词器有多种,如下表格所示为部分分词器
分词器 特点 使用场景 standard 默认、通用 英文文本 simple 按非字母分割 英文简单应用 whitespace 按空格分割 保留格式 stop 移除停用词 搜索优化 keyword 不分词 ID/关键字字段 pattern 正则分割 自定义规则 fingerprint 去重、排序 标签/关键词处理 english 停用词、词干化(Porter) 英文文本 chinese 中文分词(基础) 中文文本(默认单字分词) -
IK分词器包含两种模式:
ik_smart:智能切分,粗粒度ik_max_word:最细切分,细粒度
注意:
- 博主将在Kibana图形化界面的DSL控制台中对ES自带分词器以及IK分词器进行对比演示
- 由于ES自带分词器有多种,因此只对ES自带的standard、english、chinese进行演示
-
ES分词器示例
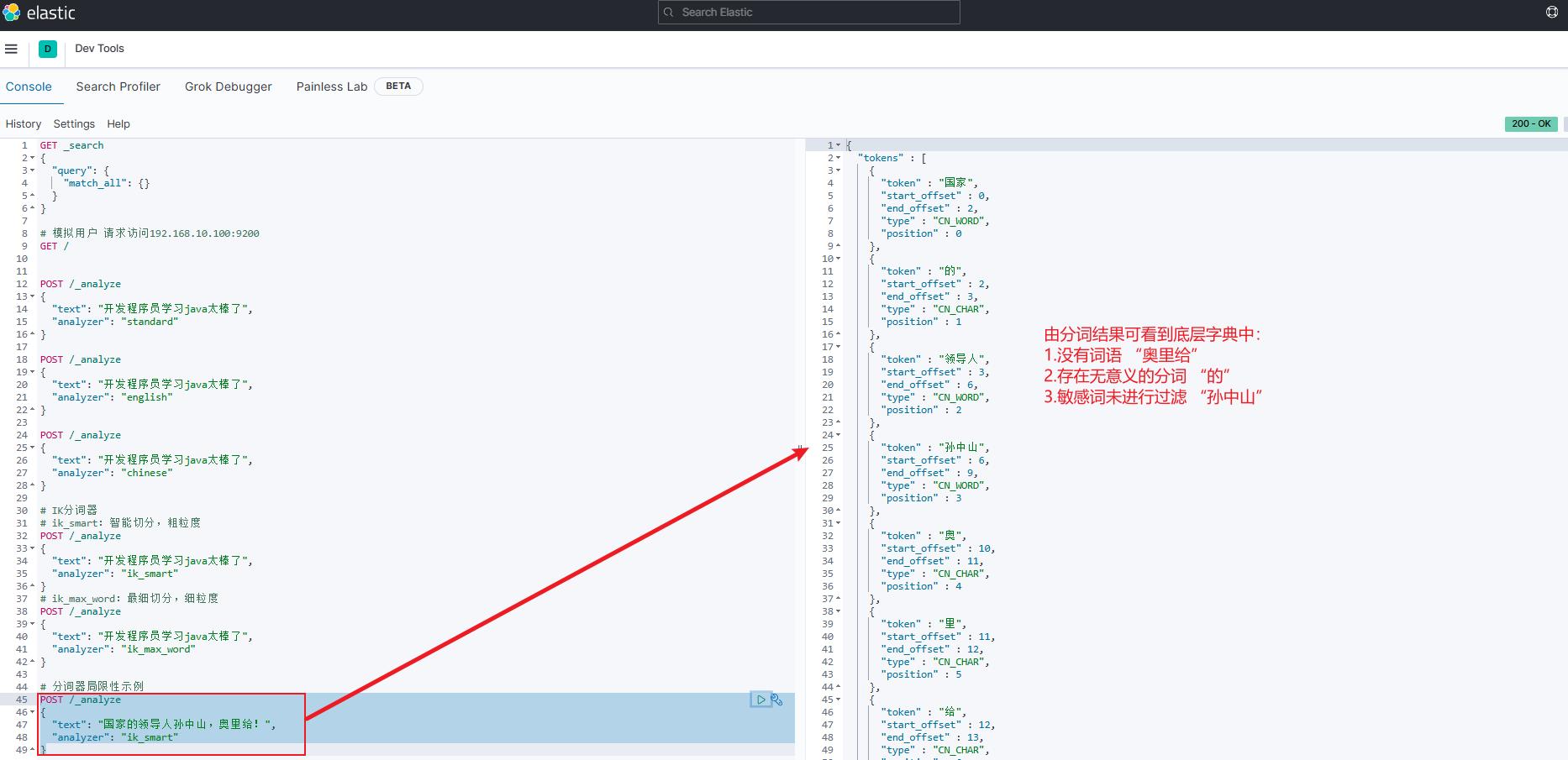
json# standard POST /_analyze { "text": "开发程序员学习java太棒了", "analyzer": "standard" } # english POST /_analyze { "text": "开发程序员学习java太棒了", "analyzer": "english" } # chinese POST /_analyze { "text": "开发程序员学习java太棒了", "analyzer": "chinese" }-
以上三种分词器分别运行后对中文的分词结果一样,均为以下形式
- 由此可见,ES自带分词器对中文分词不友好
json{ "tokens" : [ { "token" : "开", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "发", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "程", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "序", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "<IDEOGRAPHIC>", "position" : 4 }, { "token" : "学", "start_offset" : 5, "end_offset" : 6, "type" : "<IDEOGRAPHIC>", "position" : 5 }, { "token" : "习", "start_offset" : 6, "end_offset" : 7, "type" : "<IDEOGRAPHIC>", "position" : 6 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "太", "start_offset" : 11, "end_offset" : 12, "type" : "<IDEOGRAPHIC>", "position" : 8 }, { "token" : "棒", "start_offset" : 12, "end_offset" : 13, "type" : "<IDEOGRAPHIC>", "position" : 9 }, { "token" : "了", "start_offset" : 13, "end_offset" : 14, "type" : "<IDEOGRAPHIC>", "position" : 10 } ] }
-
-
IK分词器示例
json# ik_smart:智能切分,粗粒度 POST /_analyze { "text": "开发程序员学习java太棒了", "analyzer": "ik_smart" } # ik_max_word:最细切分,细粒度 POST /_analyze { "text": "开发程序员学习java太棒了", "analyzer": "ik_max_word" }-
ik_smart结果如下:json{ "tokens" : [ { "token" : "开发", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "学习", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 2 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "ENGLISH", "position" : 3 }, { "token" : "太棒了", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 4 } ] } -
ik_max_word分词结果如下json{ "tokens" : [ { "token" : "开发", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "程序员", "start_offset" : 2, "end_offset" : 5, "type" : "CN_WORD", "position" : 1 }, { "token" : "程序", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "员", "start_offset" : 4, "end_offset" : 5, "type" : "CN_CHAR", "position" : 3 }, { "token" : "学习", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 4 }, { "token" : "java", "start_offset" : 7, "end_offset" : 11, "type" : "ENGLISH", "position" : 5 }, { "token" : "太棒了", "start_offset" : 11, "end_offset" : 14, "type" : "CN_WORD", "position" : 6 }, { "token" : "太棒", "start_offset" : 11, "end_offset" : 13, "type" : "CN_WORD", "position" : 7 }, { "token" : "了", "start_offset" : 13, "end_offset" : 14, "type" : "CN_CHAR", "position" : 8 } ] }
-
分词语法格式说明
json
POST /_analyze
{
"text": "开发程序员学习java太棒了",
"analyzer": "ik_smart"
}POST:请求方式/_analyze:请求路径,此处省略了http://192.168.10.100:9200,Kibana会自动进行补充- 相当于:
http://192.168.10.100:9200/_analyze
- 相当于:
- {}内为JSON风格请求参数
text:分词内容analyzer:分词器类型
IK分词器拓展和停用词典
-
ES自带分词器以及IK分词器底层原理:
- 底层均有一个字典,字典中包含各种各样的词语,在分词时会根据字典中的词语进行分词
-
分词器字典中并不是包含所有词语,并且词语会不断的增加,因此字典仍具有局限性,示例如下图所示
为了减少字典的局限性,拓展IK分词器的词库,就需要通过配置IK分词器目录中的config目录下的 IKAnalyzer.cfg.xml 文件来实现,步骤如下:
-
Step1: 通过
/var/lib/docker/volumes/es-plugins/_data/ik/config打开es中插件的挂载目录中IK分词器config目录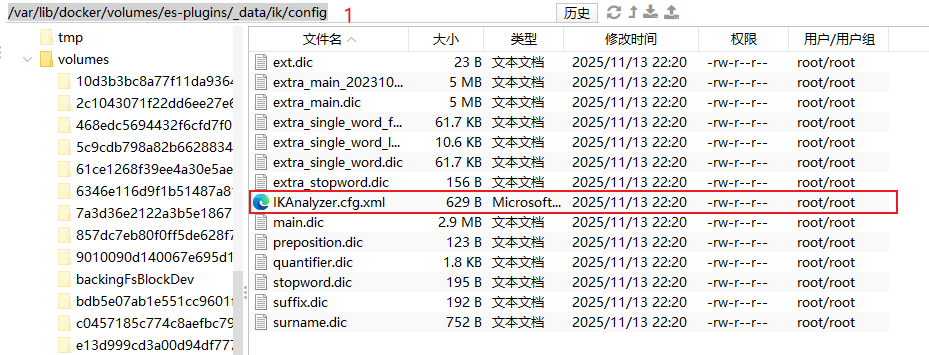
-
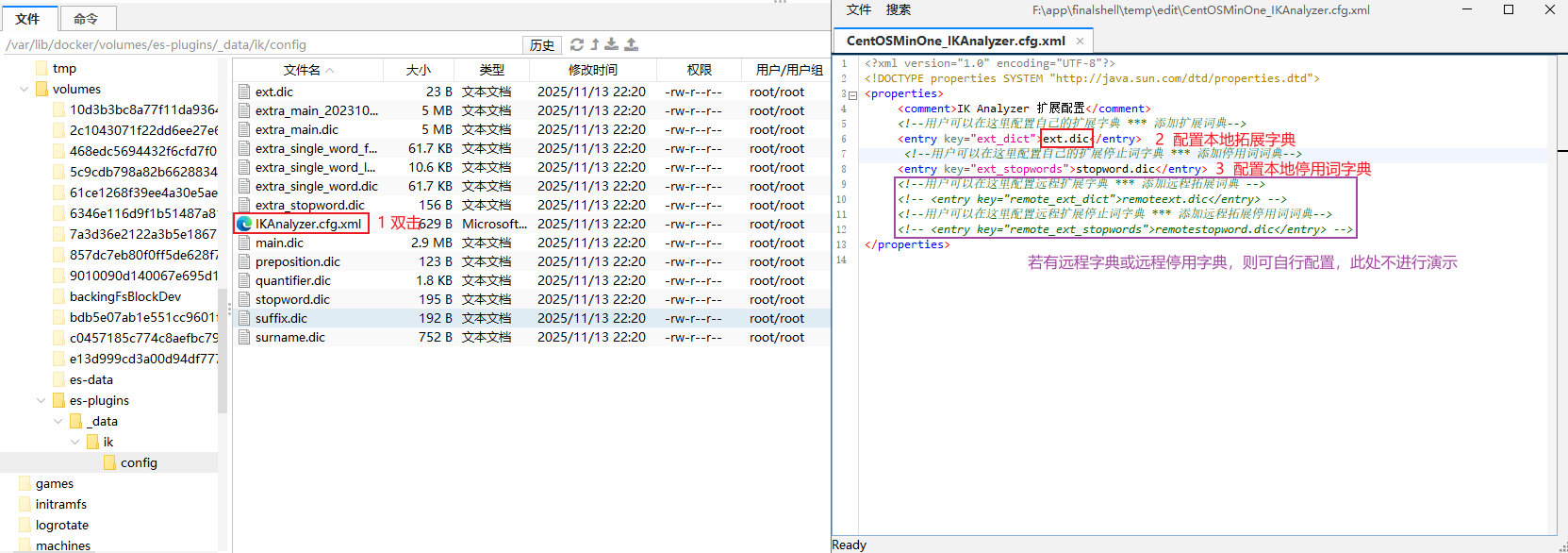
Step2: 双击打开 IKAnalyzer.cfg.xml 配置文件并在其中内容添加如下内容,然后保存并退出即可
 xml
xml<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--> <entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--> <entry key="ext_stopwords">stopword.dic</entry> <!--用户可以在这里配置远程扩展字典 *** 添加远程拓展词典 --> <!-- <entry key="remote_ext_dict">remoteext.dic</entry> --> <!--用户可以在这里配置远程扩展停止词字典 *** 添加远程拓展停用词词典--> <!-- <entry key="remote_ext_stopwords">remotestopword.dic</entry> --> </properties> -
Step3: 在IK分词器的config目录中新建文件
ext.dic和stopword.dic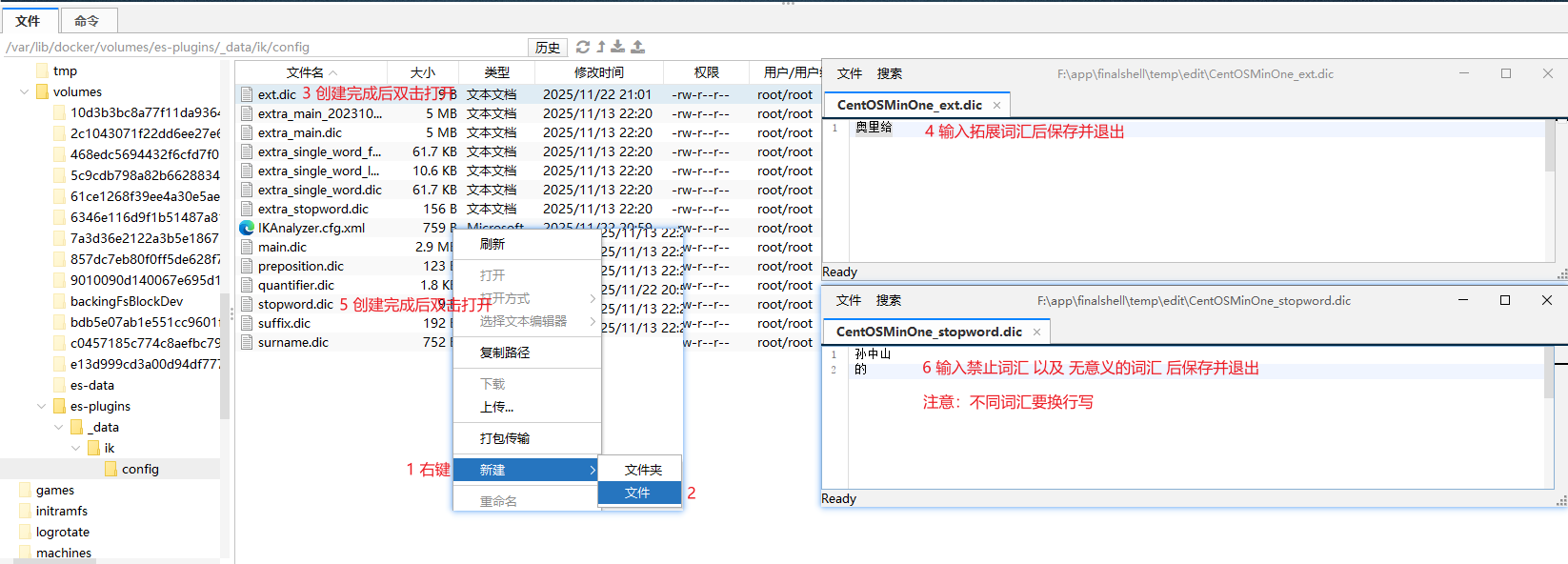
-
Step3-1: 双击
ext.dic并在其中写出要生成的拓展词汇Plain奥里给 -
Step3-2: 双击
stopword.dic并在中写出要禁止的词汇Plain孙中山
-
-
Step4: 利用
docker restart es重启ES -
Step5: 再次测试即可发现已正确分词并排除敏感词汇
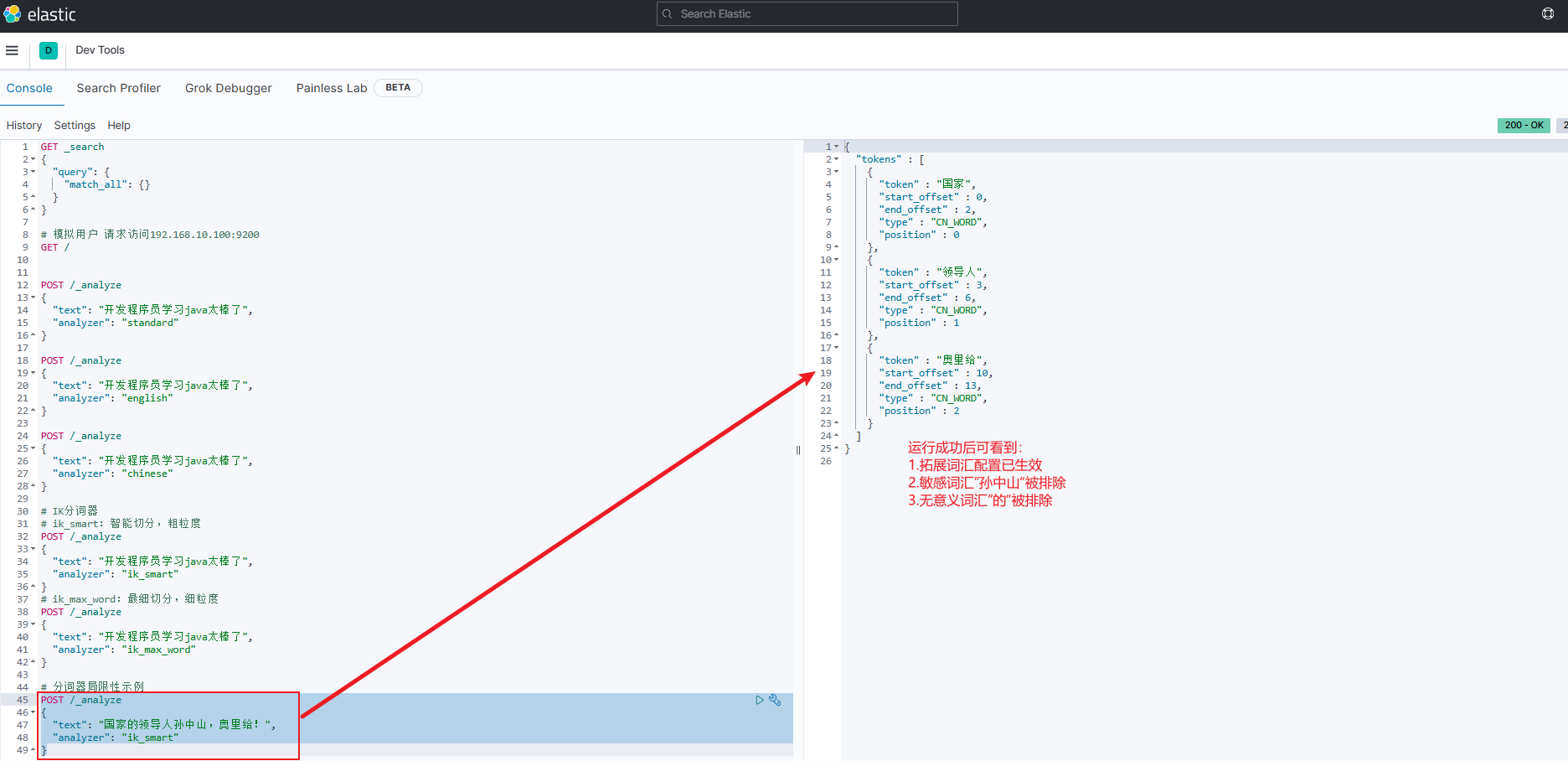
索引库操作
索引(index)就是文档的集合,类似数据库的表(table)
映射(Mapping)是索引中文档的约束,类似数据库的表结构(Schema)
我们要向es中存储数据,就必须先创建索引和映射。
Mapping映射属性
-
常见的映射(Mapping)属性如下:
注意:
- 由于映射(Mapping)是索引中文档的约束,而ES中文档是以JSON风格呈现的,所以对JSON文档进行约束时,映射(Mapping)可以对文档约束的属性如下
- 此处只列举常见的属性,其余属性可自行查阅官方文档
属性 解释 备注 type字段数据类型。常见简单类型有: - 字符串(两种): text(可分词的文本)和keyword(精确值,例如:姓名、品牌、国家、ip地址等) - 数值:long、integer、short、byte、double、float- 布尔:boolean- 日期:date- 对象:objecttext:由多个词语组成的可分词文本keyword:作为一个整体才有意义,分开后就没有意义的文本,比如:孙中山、中国、耐克、192.168.10.100、zy@itcast.cn等文本,若通过分词拆开后就没有意义index是否创建倒排索引,以便于未来搜索 默认为 true,若某字段不参与搜索,则需将该属性值改为falseanalyzer使用哪种分词器 ES分词器及IK分词器可详见 ES与IK分词器对比示例 部分内容, analyzer与text结合使用,因为其它数据类型都不需要进行分词properties该字段的子字段 可见以下JSON示例中,类型为object的name字段有两个子字段, properties就可为其指定子属性json{ "age": 21, "weight": 52.1, "isMarried": false, "info": "开发程序员Java讲师", "email": "zy@itcast.cn", "score": [99.1, 99.5, 98.9], "name": { "firstName": "云", "lastName": "赵" } }- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
创建索引库和映射
-
ES是通过Restful请求操作索引库、文档,请求内容需用DSL语句表示。
-
创建索引库和映射(Mapping)的DSL语法格式如下:
jsonPUT /{索引库名} { "mappings": { "properties": { "字段名":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": "false" }, "字段名3":{ "properties": { "子字段": { "type": "keyword" } } }, // ...略 } } } -
示例代码如下:
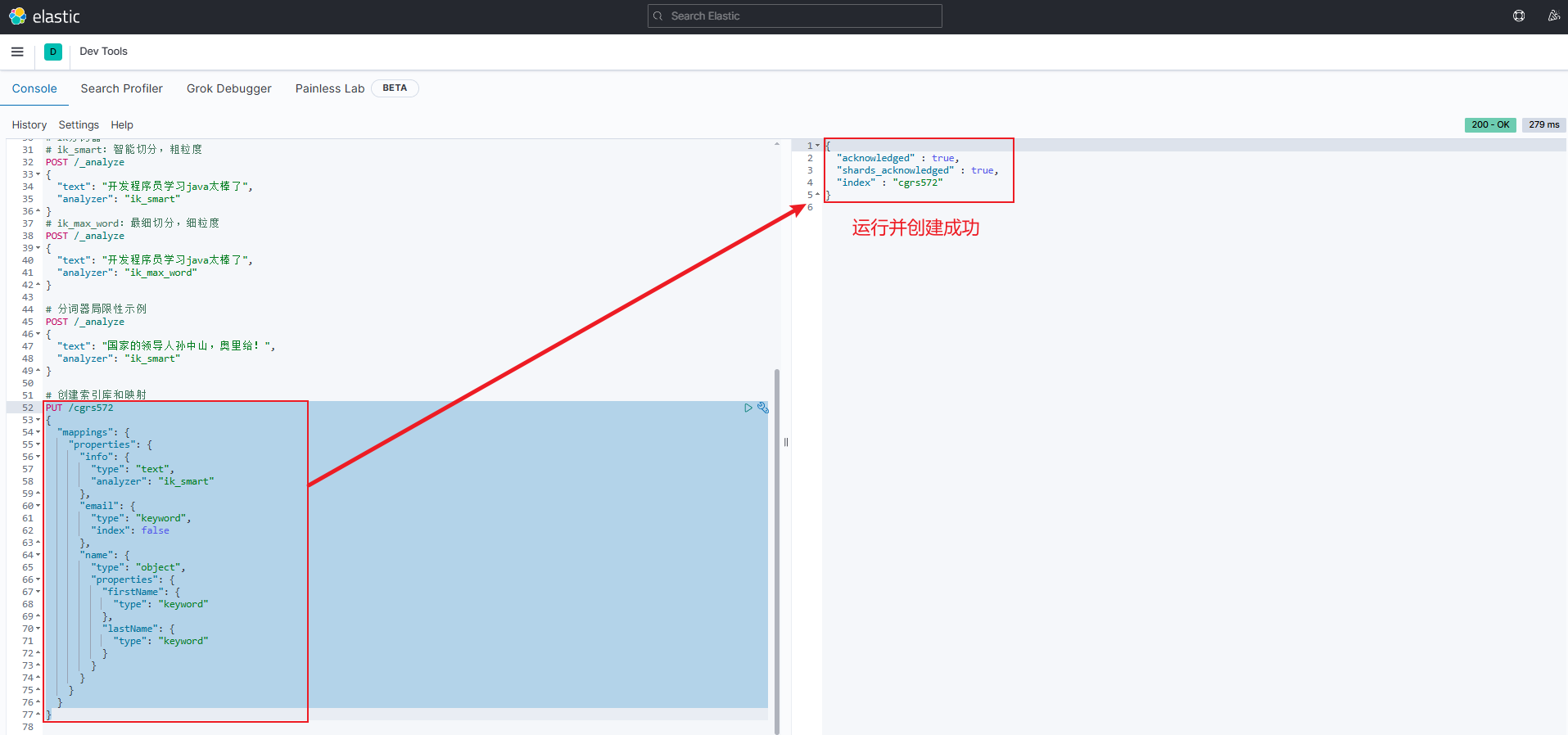 json
jsonPUT /cgrs572 { "mappings": { "properties": { "info": { "type": "text", "analyzer": "ik_smart" }, "email": { "type": "keyword", "index": false }, "name": { "type": "object", "properties": { "firstName": { "type": "keyword" }, "lastName": { "type": "keyword" } } } } } }cgrs572:索引库名称mappings:创建映射info:第一个字段,假设未来要给这个字段中的文本进行分词,则需要type属性值为text,并且利用analyzer指定分词器email:第二个字段,假设该字段的文本分词后无意义,也就是说不需要分词,所以就不需要analyzer,只需要设置type属性值为keyword- 假设该字段将来不参与搜索,所以就需要设置
index属性值为false
- 假设该字段将来不参与搜索,所以就需要设置
name:第三个字段,假设该字段有两个子字段firstName和lastName,因此就需要利用firstName来为name配置子字段firstName:name子字段,假设该字段的文本分词后无意义,也就是说不需要分词,所以就不需要analyzer,只需要设置type属性值为keyword。又因为该字段以后参与搜索,而index属性值默认为true,所以就可省略对index属性值的设置lastName:name子字段,其与firstName同理。
查询、删除、修改索引库
-
查询索引库 :
GET /索引库名-
示例:
GET /cgrs572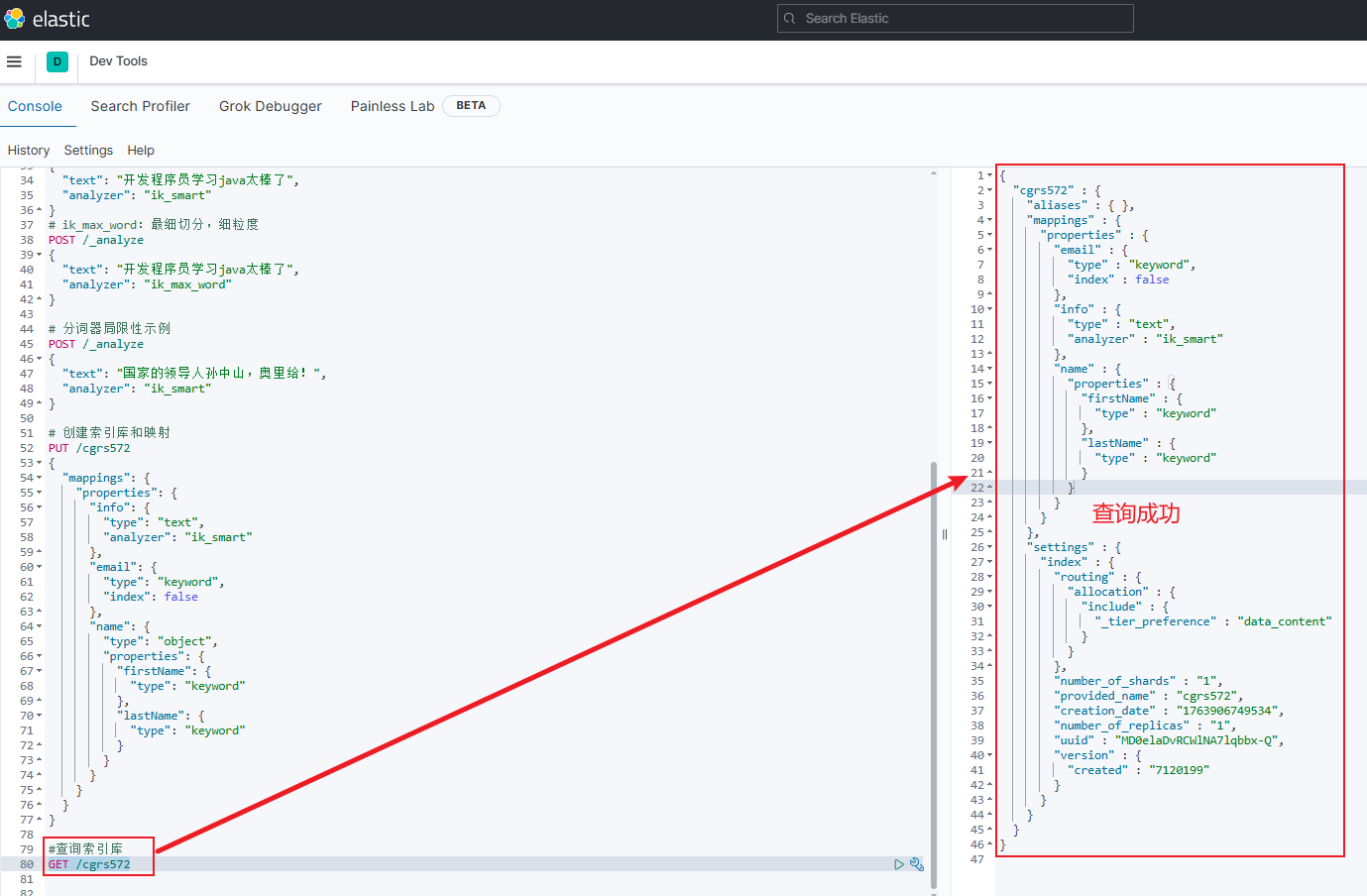
-
-
ES中,索引库一旦被创建,就不允许被修改
-
原因:索引库创建完成后,数据结构(即Mapping映射)就已定义好,ES会基于映射(Mapping)去创建倒排索引,若修改某个字段就会导致原有的倒排索引失效,因此就不允许修改索引库
-
注意:虽然无法修改映射(Mapping)中已有的字段,但允许添加新的字段到mapping中,因为不会对倒排索引产生影响。新增字段示例如下:
注意:若新字段名与索引库中已有字段名重复则会被认为是在修改索引库,就会报错
jsonPUT /{索引库名}/_mapping { "properties": { "新字段名": { "type": "integer" } } }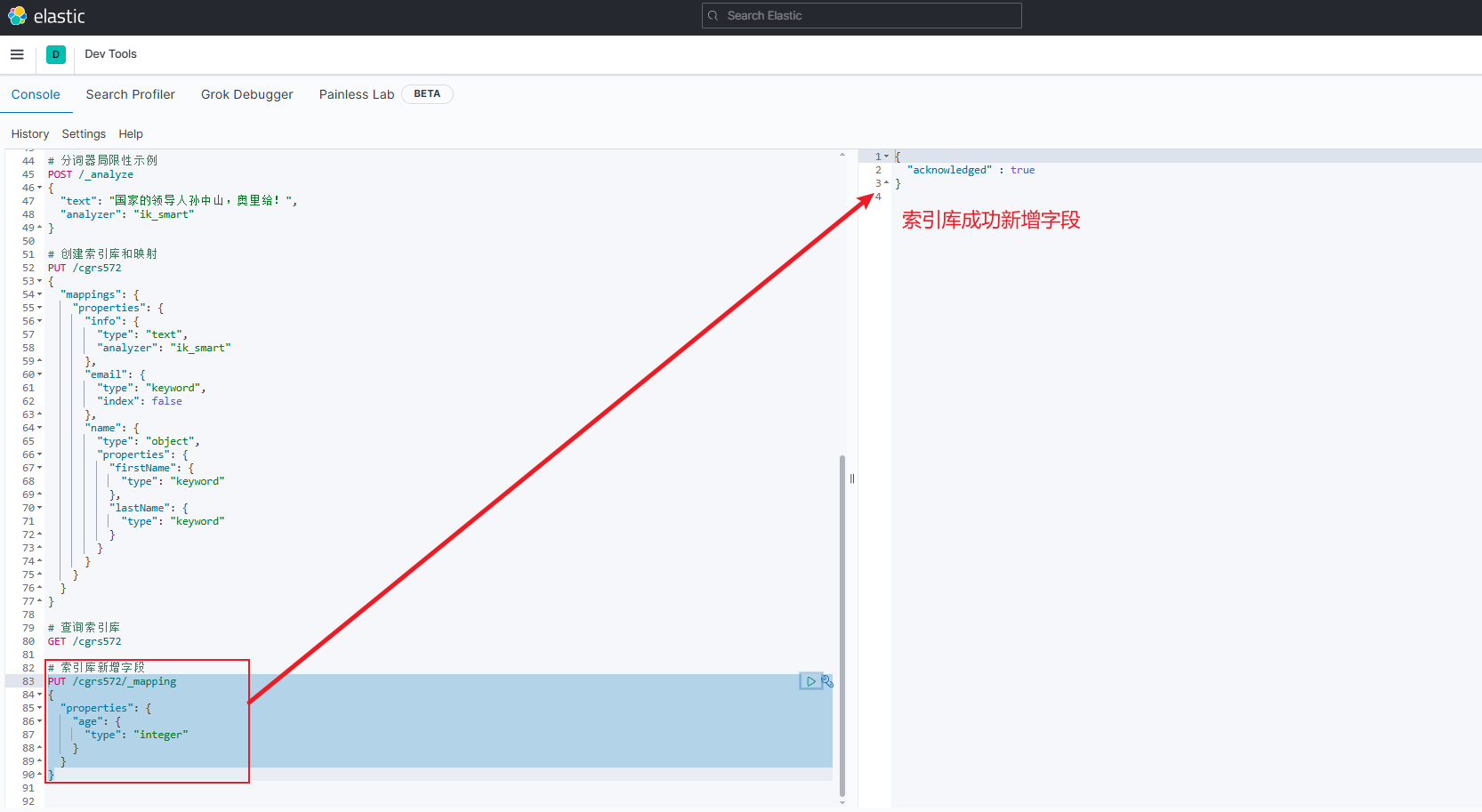
-
-
删除索引库 :
DELETE /{索引库名}-
示例:
DELETE /cgrs572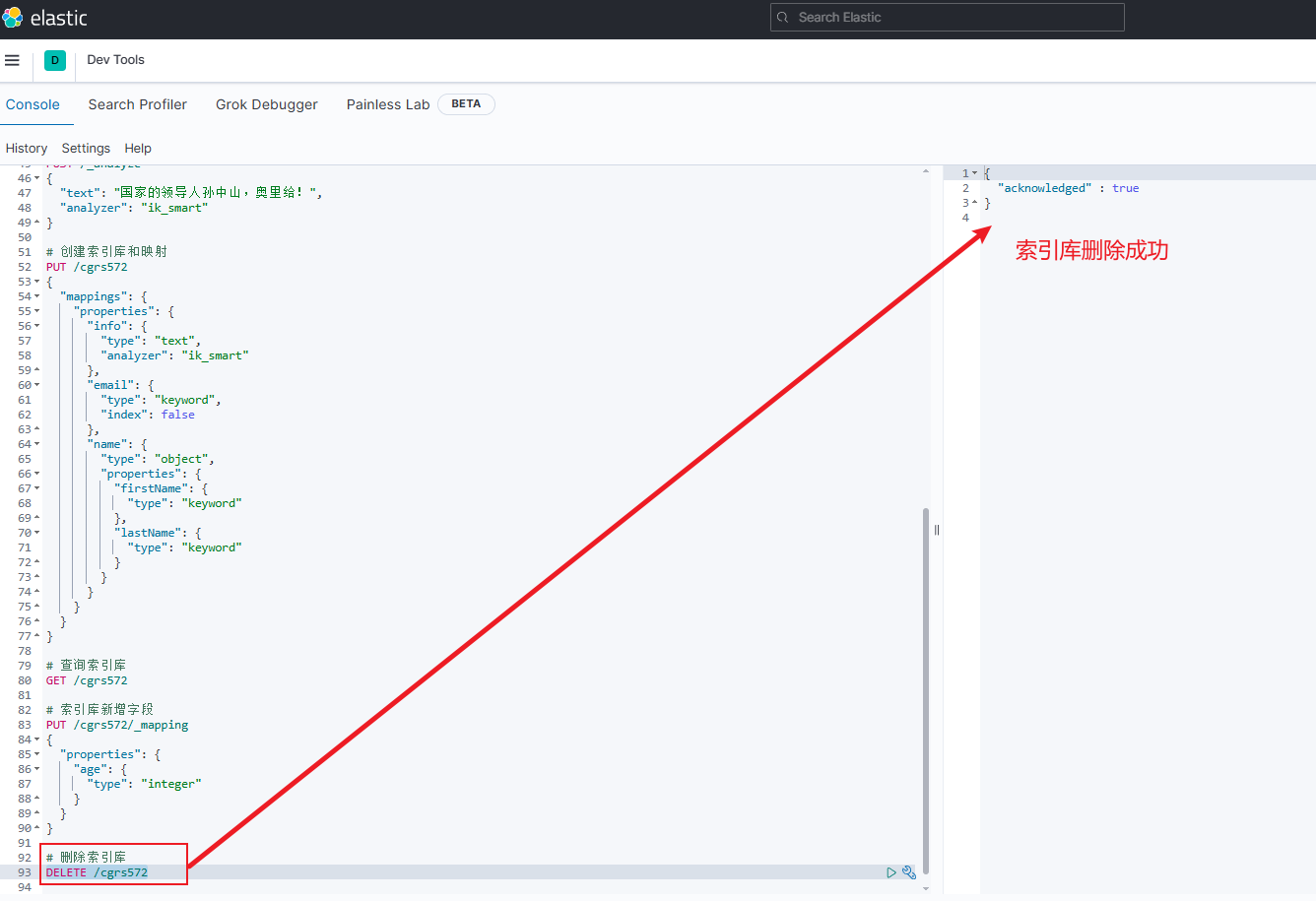
-
文档操作
新增文档
-
新增文档的DSL语法格式如下:
jsonPOST /{索引库名}/_doc/文档id { "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" }, // ... }-
文档id必须有,若不加,ES就会认为该文档没有id,从而随机生成一个文档id
-
示例如下
jsonPOST /cgrs572/_doc/1 { "info": "java开发程序员", "email": "cgrs572@163.cn", "name": { "firstName": "云", "lastName": "赵" } }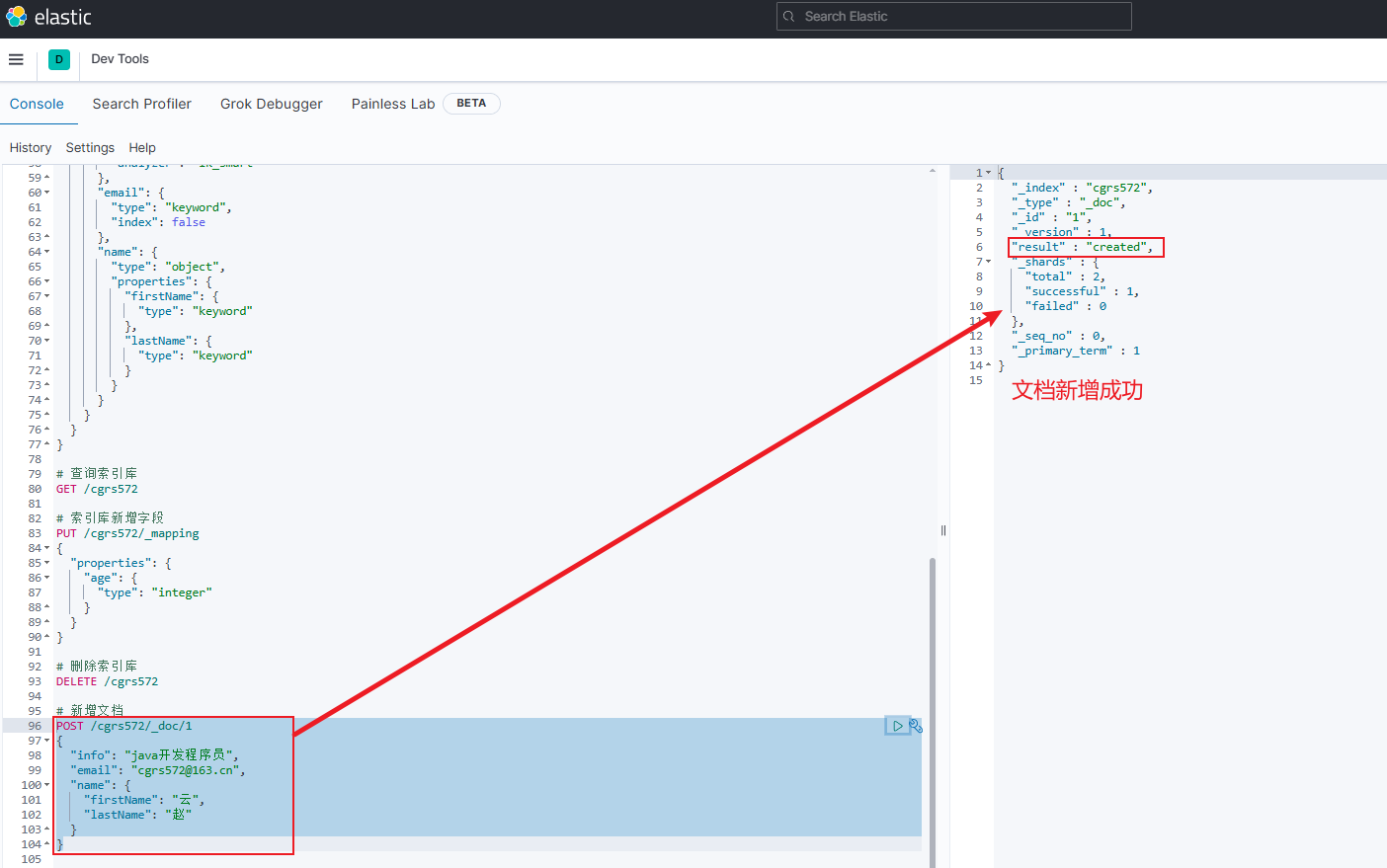
-
查询、删除文档
-
查询文档:
GET /{索引库名}/_doc/文档id- 由图示可知查询成功,
"_source"即为新增的原始文档
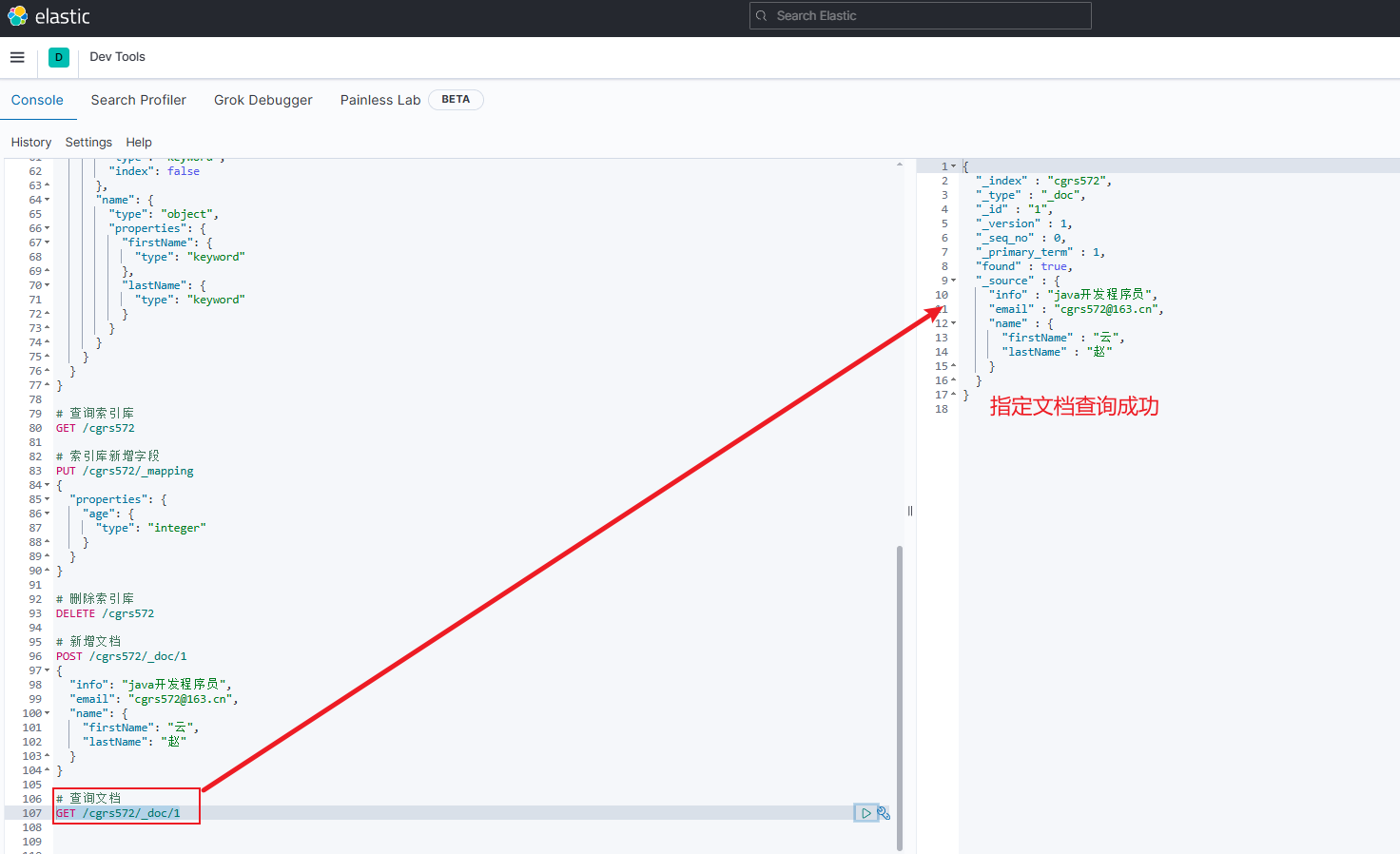
- 由图示可知查询成功,
-
删除文档:
DELETE /{索引库名}/_doc/文档id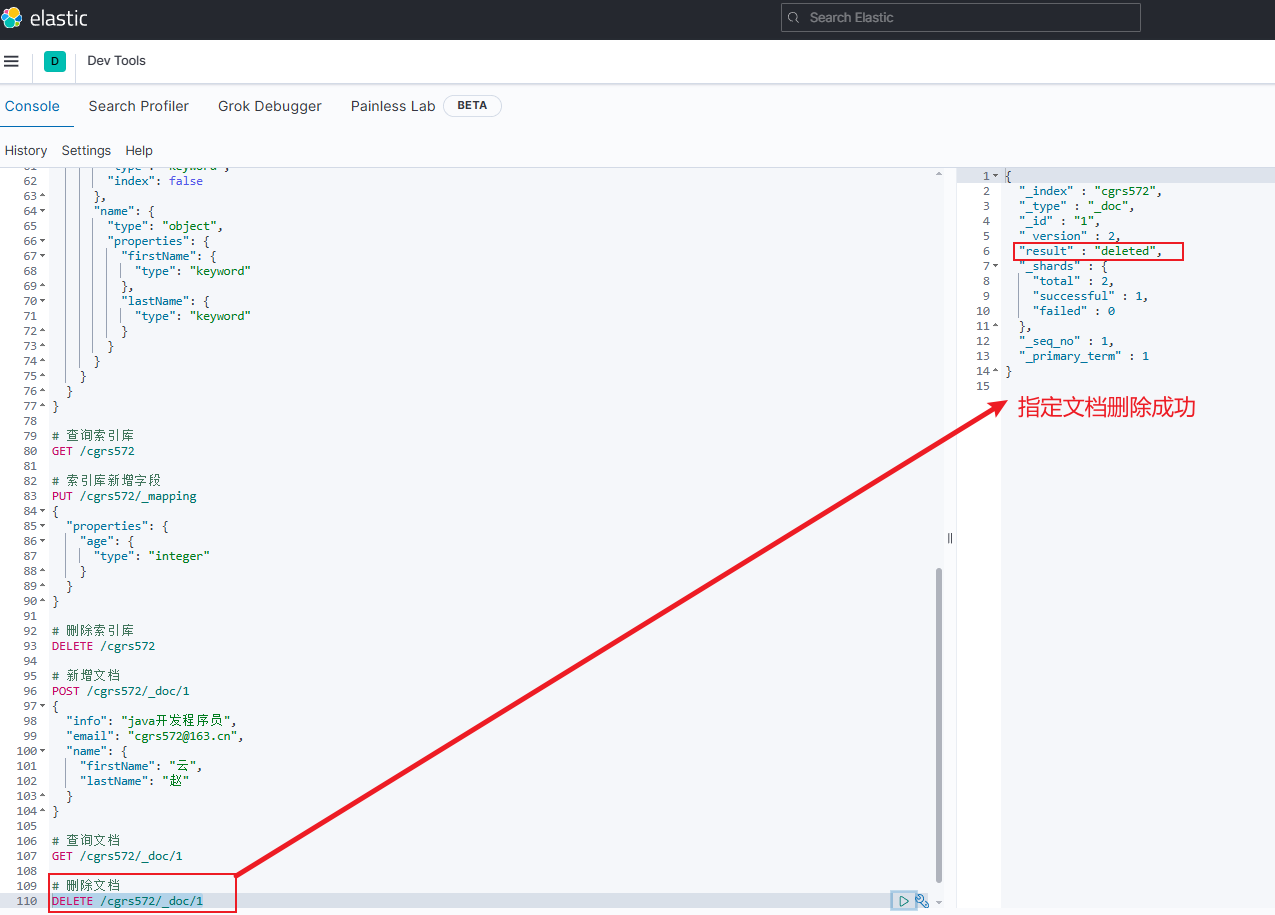
修改文档
-
修改文档有两种方式:全量修改和增量修改
- 修改内容比较多则使用全量修改,反之则使用增量修改
-
全量修改: 直接覆盖原来的文档。本质是根据指定的id删除旧文档后,在新增一个相同id的文档
注意:若在根据指定的id删除旧文档时,指定的id不存在,则此时会从修改变为新增操作(即新增文档)
jsonPUT /{索引库名}/_doc/文档id { "字段1": "新值", "字段2": "新值", // ... 略 }-
示例1:指定的id存在,则为修改操作
jsonPUT /cgrs572/_doc/1 { "info" : "java开发程序员", "email" : "eiyoyo@163.cn", "name" : { "firstName" : "三", "lastName" : "张" } }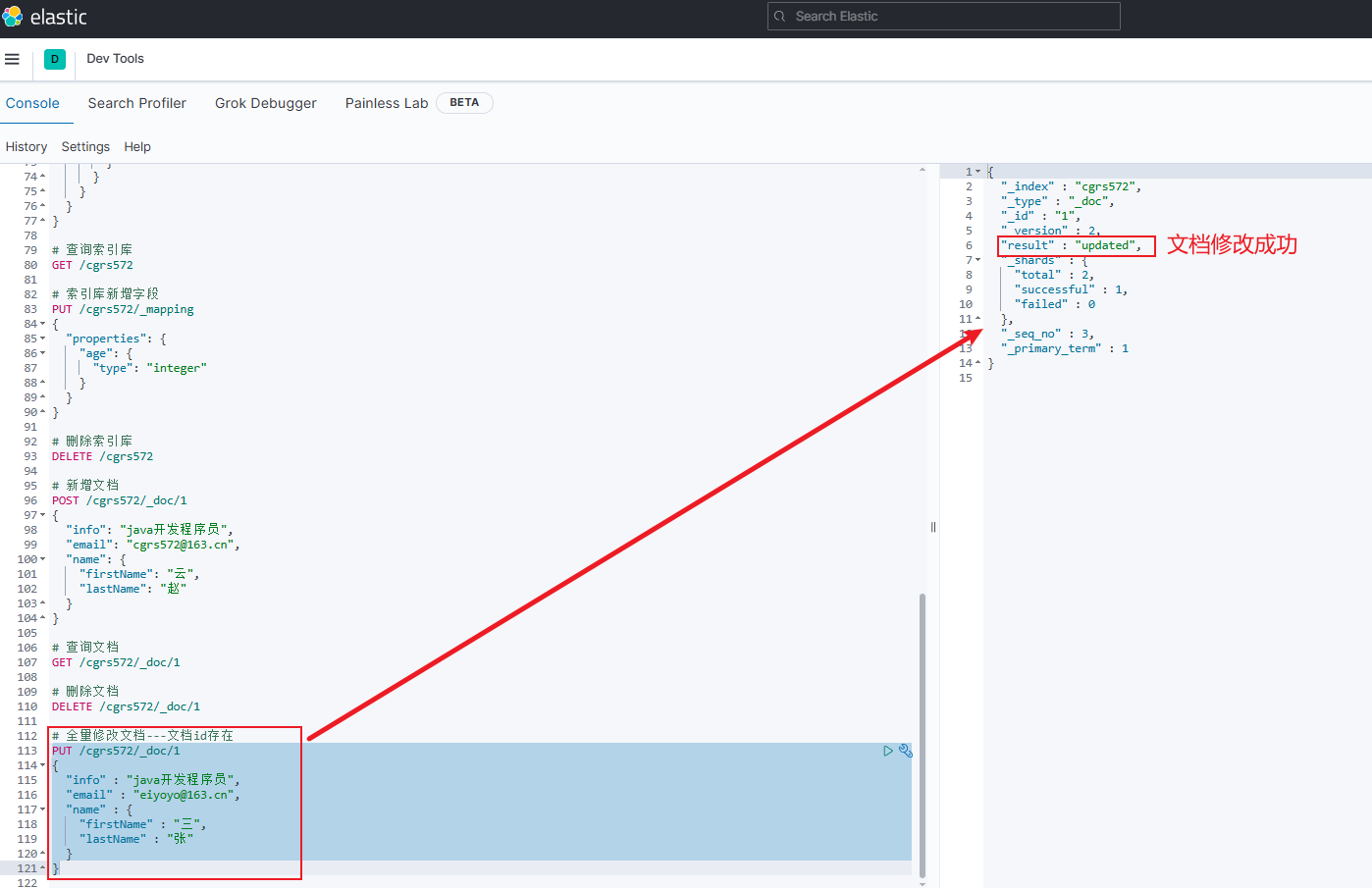
-
示例2:指定的id不存在,则修改会变为新增操作
bashPUT /cgrs572/_doc/3 { "info" : "java开发程序员", "email" : "yiayia@163.cn", "name" : { "firstName" : "四", "lastName" : "李" } }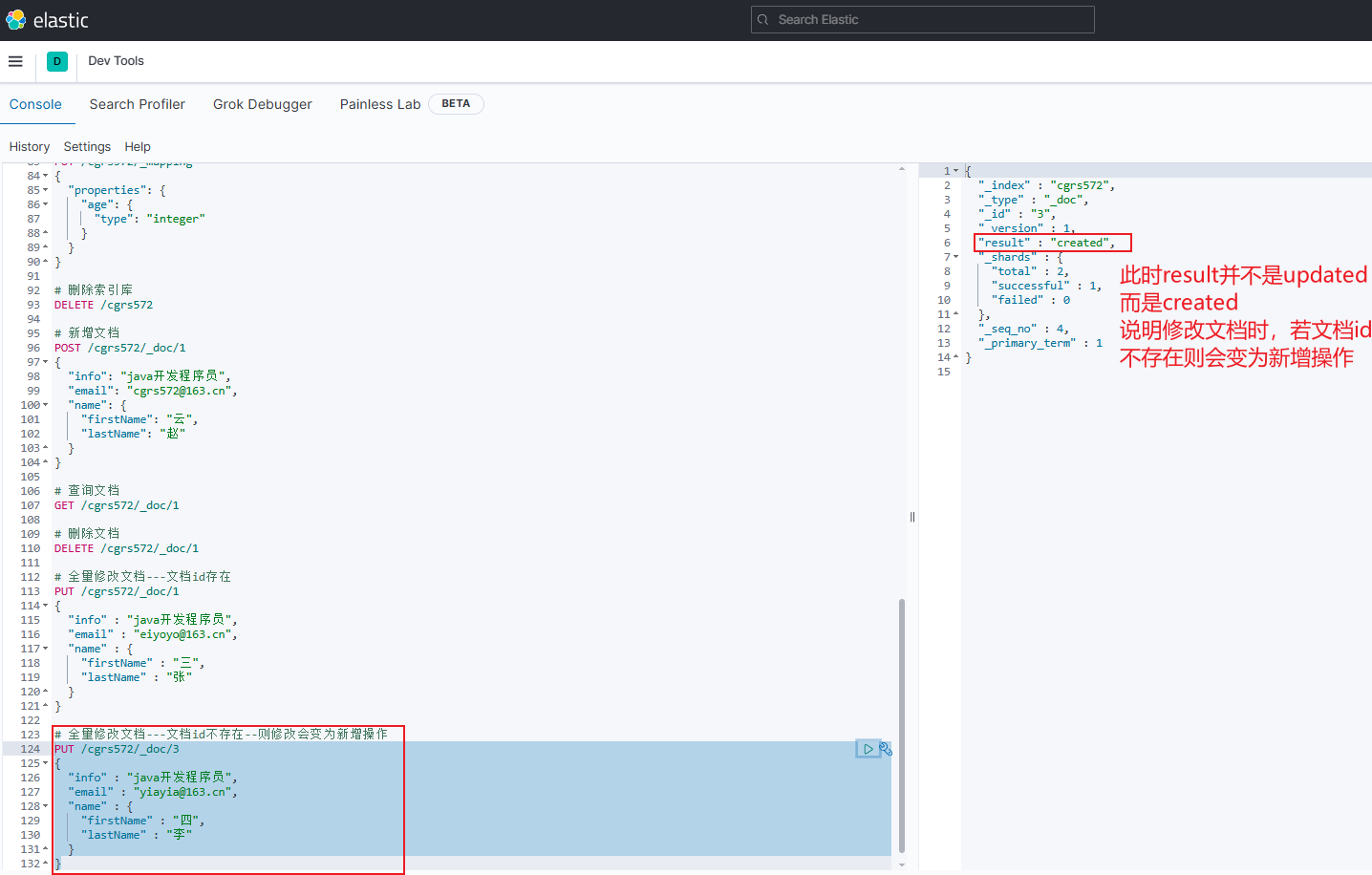
-
-
增量修改: 只修改指定id匹配的文档中的部分字段
- 注意:若指定id文档不存在或未匹配到,则会修改失败直接报错。原因:
doc_as_upsert默认为false,若想要其不报错,则需将doc_as_upsert的值设为true
jsonPOST /{索引库名}/_update/文档id { "doc": { "字段名": "新值" }, "doc_as_upsert": false }-
示例
jsonPOST /cgrs572/_update/1 { "doc": { "email": "zhangsan@163.com" } }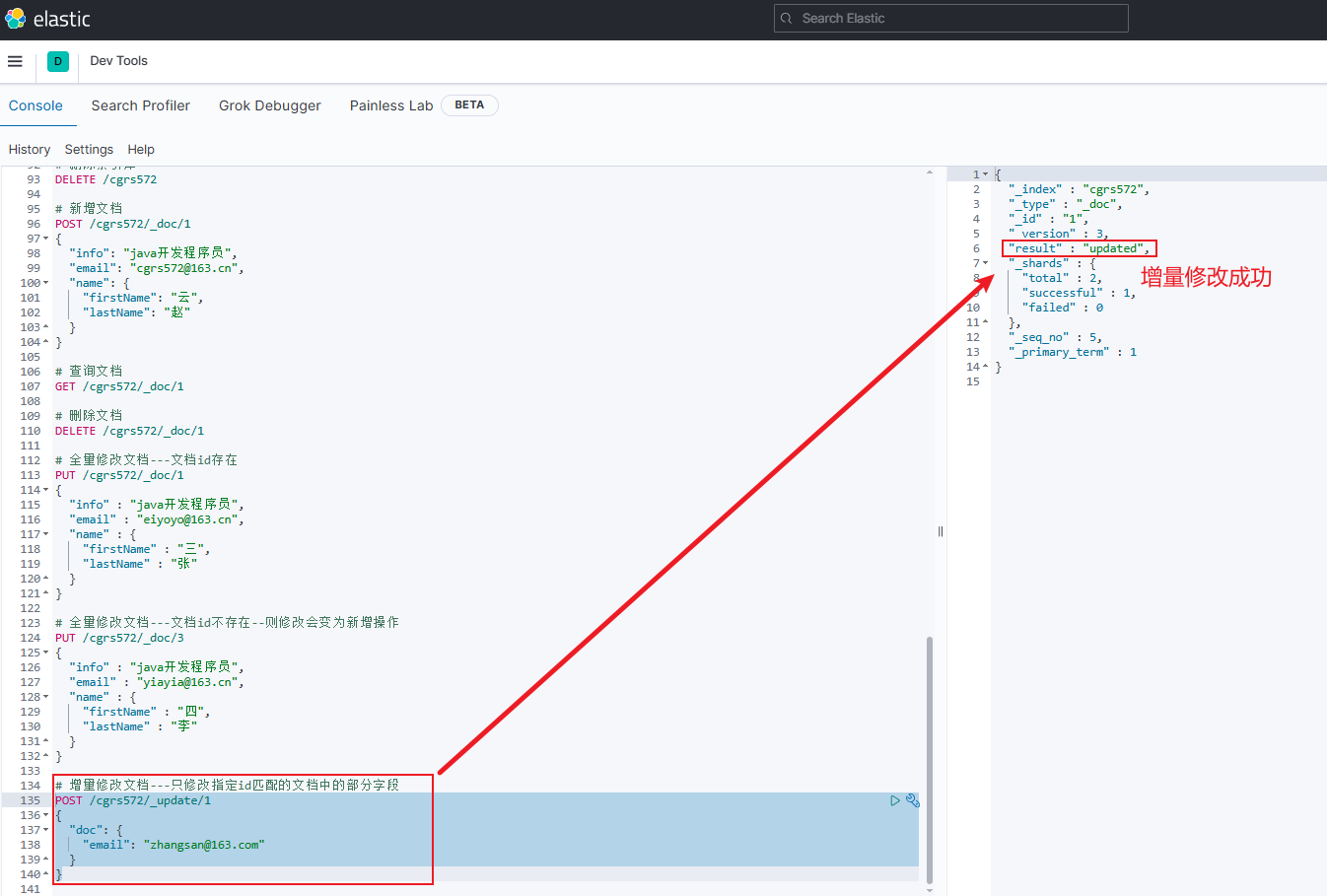
- 注意:若指定id文档不存在或未匹配到,则会修改失败直接报错。原因:
批处理
-
文档批量新增
-
格式一: 若指定的文档id存在则会覆盖旧文档数据
jsonPOST _bulk {"index": {"_index": "索引库名", "_id": 文档id}} {"字段名1": "值", "字段名2": "值", ...} {"index": {"_index": "索引库名", "_id": 文档id}} {"字段名1": "值", "字段名2": "值", ...}-
示例
jsonPOST /_bulk {"index": {"_index": "cgrs572", "_id": 2}} {"info": "程序员C++讲师", "email": "ww@163.cn", "name": {"firstName": "王", "lastName":"五"}} {"index": {"_index": "cgrs572", "_id": 4}} {"info": "程序员鸿蒙讲师", "email": "zs@163.cn", "name": {"firstName": "张", "lastName": "六"}}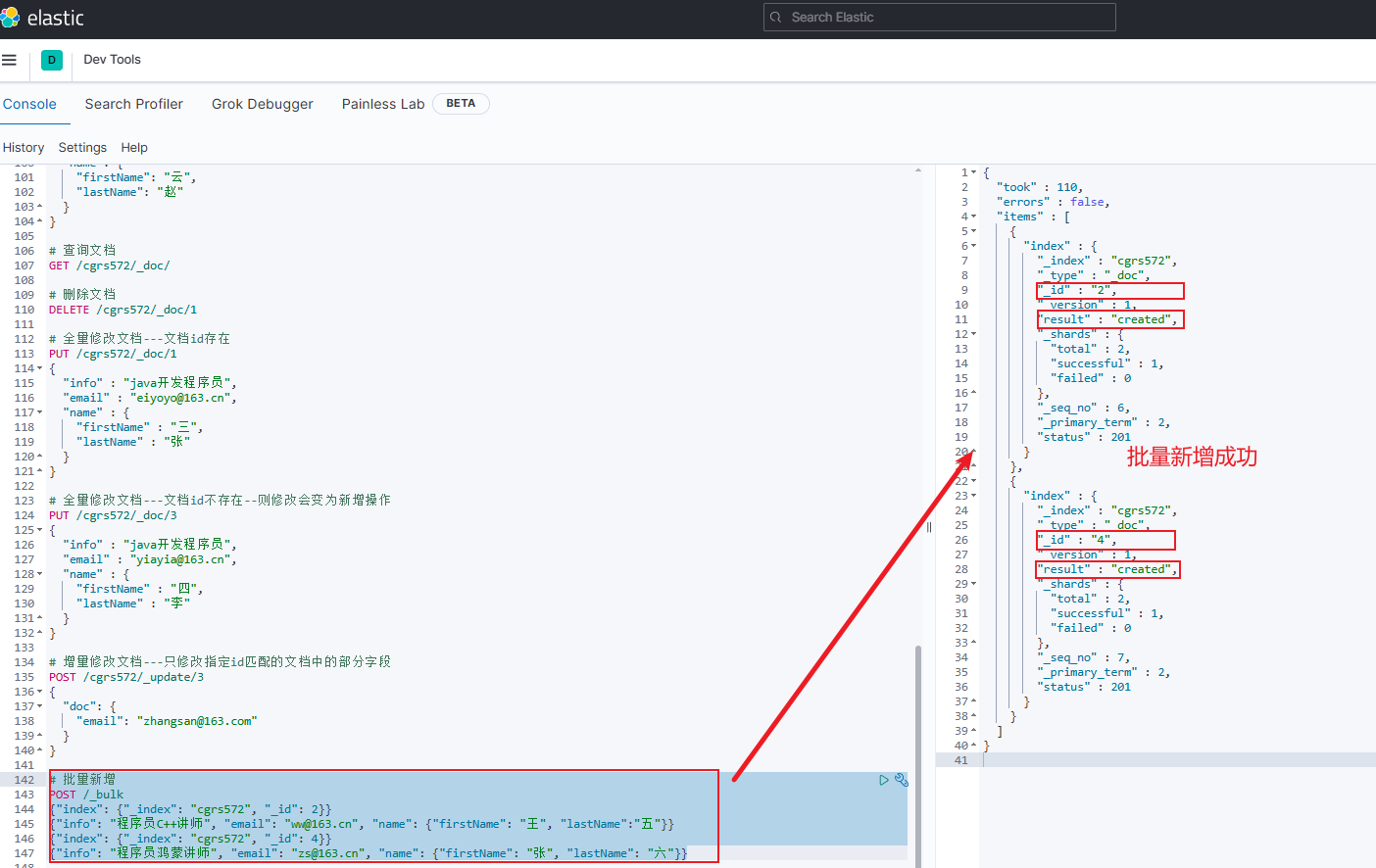
-
-
格式二: 若指定的文档id存在则会直接报错,并不会覆盖已有文档数据
jsonPOST _bulk {"create": {"_index": "索引库名", "_id": "文档id"}} {"字段名1": "值", "字段名2": "值", ...} {"create": {"_index": "索引库名", "_id": "文档id"}} {"字段名1": "值", "字段名2": "值", ...}-
示例
jsonPOST /_bulk {"create": {"_index": "cgrs572", "_id": 2}} {"info": "程序员C++讲师", "email": "ww@163.cn", "name": {"firstName": "王", "lastName":"五"}} {"create": {"_index": "cgrs572", "_id": 4}} {"info": "程序员鸿蒙讲师", "email": "zs@163.cn", "name": {"firstName": "张", "lastName": "六"}}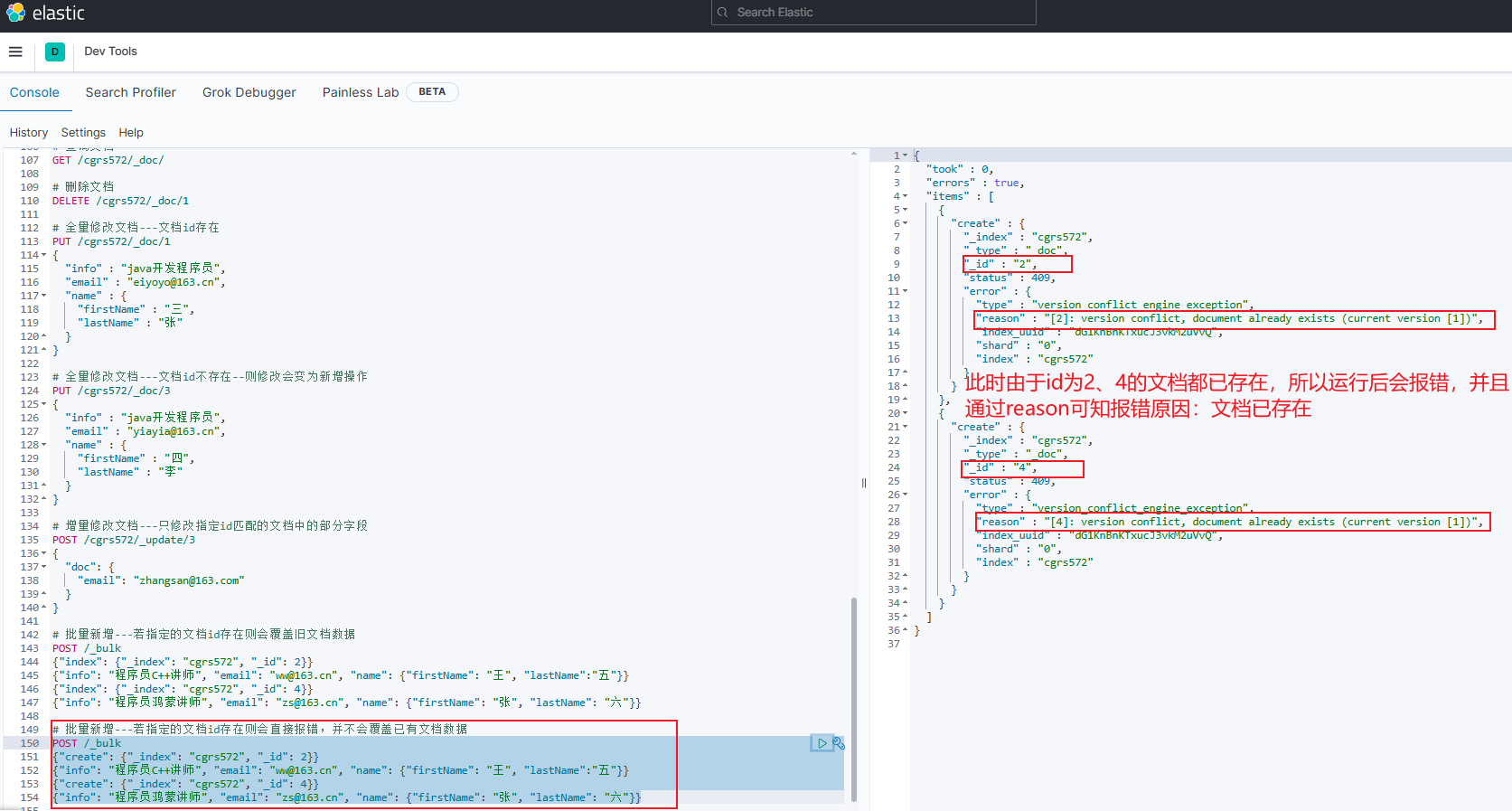
-
-
-
文档批量删除
jsonPOST /_bulk {"delete": {"_index": "索引库名", "_id": 文档id}} {"delete": {"_index": "索引库名", "_id": 文档id}}-
示例
jsonPOST /_bulk {"delete": {"_index": "cgrs572", "_id": 2}} {"delete": {"_index": "cgrs572", "_id": 3}}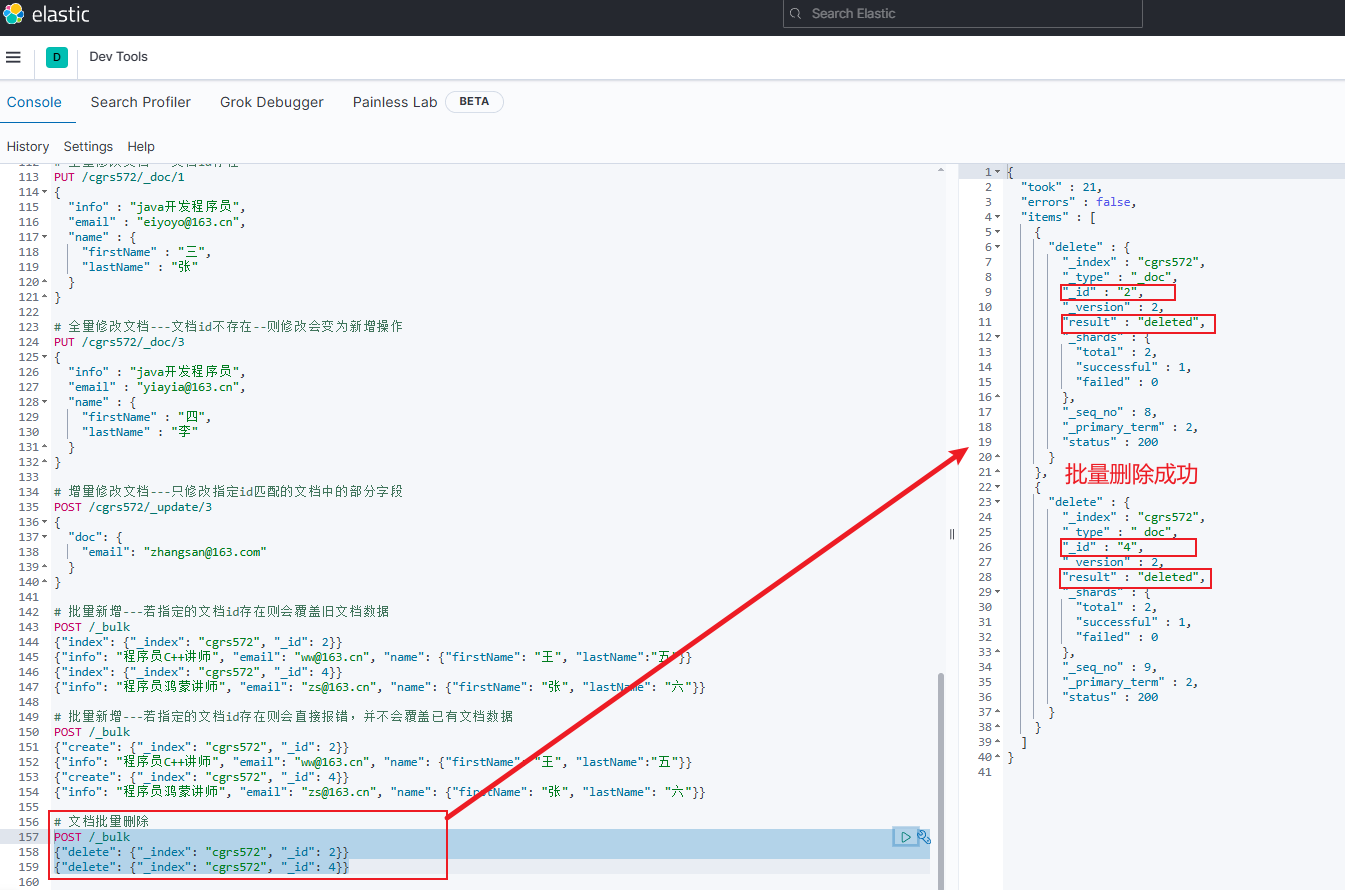
-
-
文档增量批量修改
jsonPOST _bulk {"update": {"_index": "索引库名", "_id": "文档id"}} {"doc": {"字段名1": "新值", "字段名2": "新值", ...}, "doc_as_upsert": false} {"update": {"_index": "索引库名", "_id": "文档id"}} {"doc": {"字段名1": "新值", "字段名2": "新值", ...}, "doc_as_upsert": false}-
doc_as_upsert:代表在进行增量批量修改时,若指定id文档不存在,则是否新增对应文档,默认为false(此时若指定文档id不存在,则在增量修改时会报错,除非将其设置为true) -
示例(只演示
doc_as_upsert为false的情况):jsonPOST _bulk {"update": {"_index": "cgrs572", "_id": "1"}} {"doc": {"info": "C++开发程序员", "email": "c++@163.com"}} {"update": {"_index": "cgrs572", "_id": "3"}} {"doc": {"info": "Python开发程序员", "email": "python@163.com"}}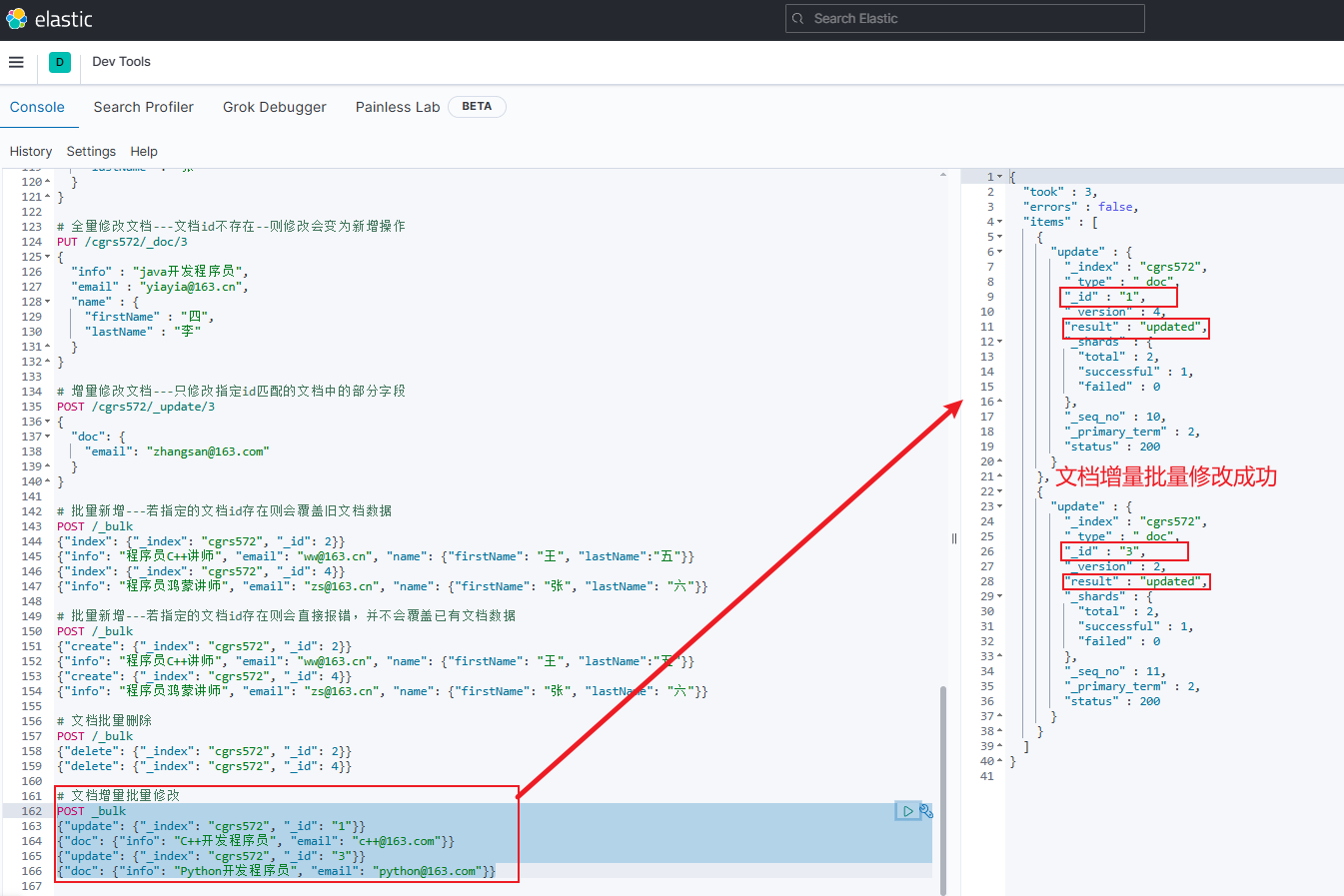
-
-
根据文档id批量查询
-
查询时,
文档id是否添加双引号均可jsonGET /{索引库名}/_mget { "ids": ["文档id", "文档id", ...] } -
示例
jsonGET /cgrs572/_mget { "ids": ["1", "3"] }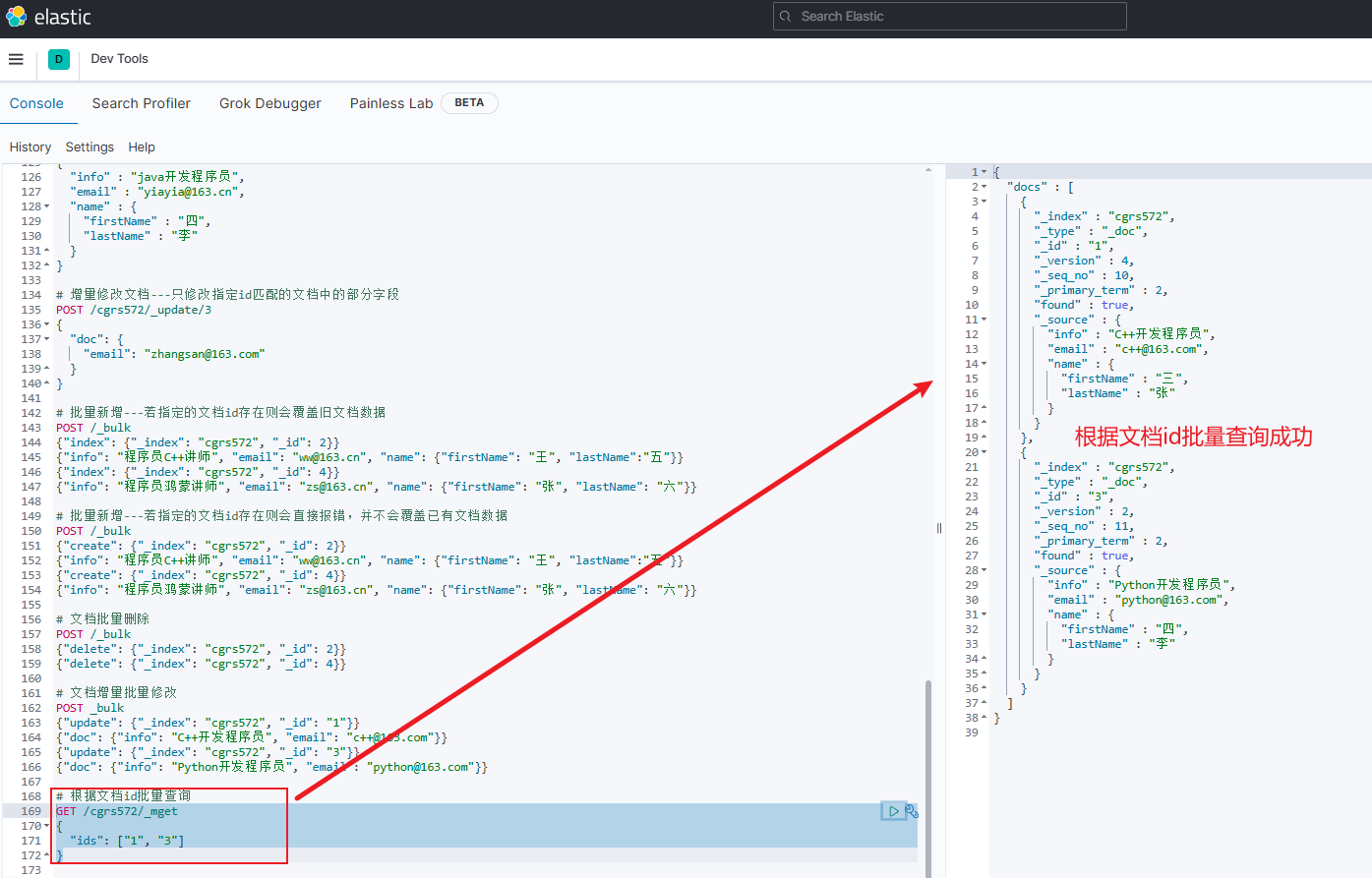
-
DSL文档查询
- Elasticsearch提供了基于JSON的DSL(Domain Specific Language)语句来定义查询条件,具体分为两大类:
- 叶子查询(Leaf query clauses) :一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。此处只列举常见的查询类型,其它类型查询及相关语法可自行参考官方文档
- 查询所有:查询出所有数据,一般在测试时使用。例如:
match_all - 全文检索查询(Full Text Queries):利用分词器对用户输入的内容分词,然后去倒排索引库中匹配。例如:
match、match_query、multi_match_query - 精确查询(Term-level Queries):不会对用户输入的内容进行分词,而是直接将其作为一个词条与搜索的字段内容进行精确匹配。一般用来查询
keyword、数值、日期、boolean等类型字段(即作为一个整体才有含义的字段)。例如:ids、range、term - 地理坐标查询(Geo Queries):根据经纬度查询。例如:
geo_distance、geo_bounding_box
- 查询所有:查询出所有数据,一般在测试时使用。例如:
- 复合查询(Compound query clauses) :以逻辑方式将多个叶子查询组合或者更改叶子查询的行为方式,以此来构成查询条件。主要分为两类
- 第一类:基于逻辑运算组合叶子查询,实现组合条件。例如:
bool - 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
function_score、dis_max - 其它复合查询及相关语法可自行参考官方文档
- 第一类:基于逻辑运算组合叶子查询,实现组合条件。例如:
- 叶子查询(Leaf query clauses) :一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。此处只列举常见的查询类型,其它类型查询及相关语法可自行参考官方文档
- 注意:DSL文档查询时,参与查询的字段的
index属性值是否必须均为true,即参与搜索,否则会查询失败详见全文检索查询示例
叶子查询
-
叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
-
查询基本语法格式如下:
jsonGET /{索引库名}/_search { "query": { "查询类型": { "查询条件": "条件值" } } }
查询所有
-
查询所有:查询出所有数据,一般在测试时使用。例如:
match_all -
由于 查询所有 是不需要查询条件的,所以最终语法格式如下:
jsonGET /索引库名/_search { "query": { "match_all": { } } } -
示例
jsonGET /cgrs572/_search { "query": { "match_all": { } } }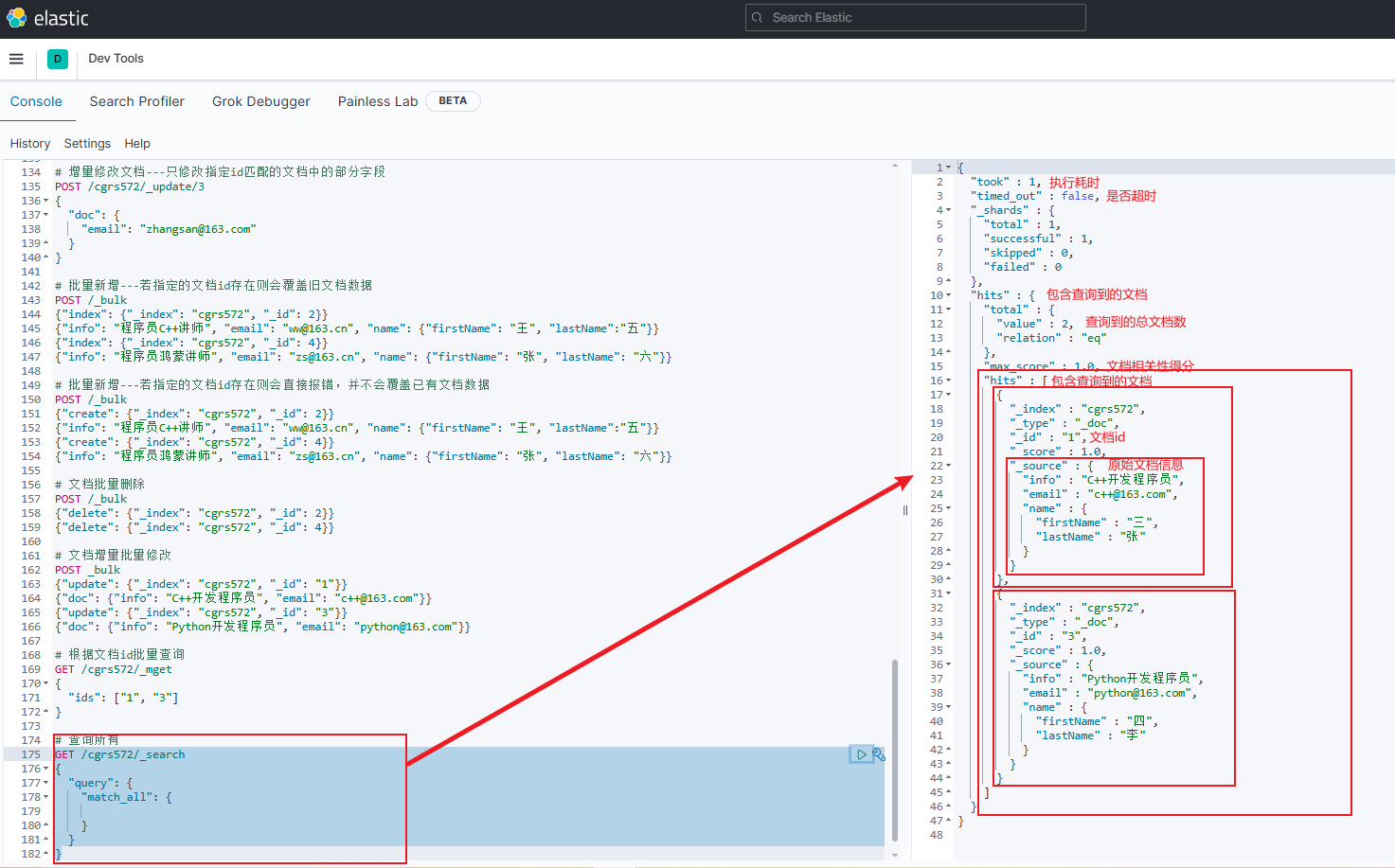
-
注意:
- 若索引库中文档较多,则ES默认情况下只会返回10条左右的数据,避免对内存造成压力
- 查询出来的结果总包含一个文档相关性得分字段
max_score,得分越高则匹配度越高
全文检索查询
-
全文检索查询(Full Text Queries):利用分词器对用户输入的内容分词,然后去倒排索引库中匹配。例如:
match、match_query、multi_match_query- 全文检索的种类很多,具体可自行参考官方文档
-
match类型全文检索的语法格式如下:- 注意:
match类型全文检索一次只能查询一个字段
jsonGET /{索引库名}/_search { "query": { "match": { "字段名": "用户输入内容" } } }-
示例
jsonGET /cgrs572/_search { "query": { "match": { "info": "他是一个c++" } } }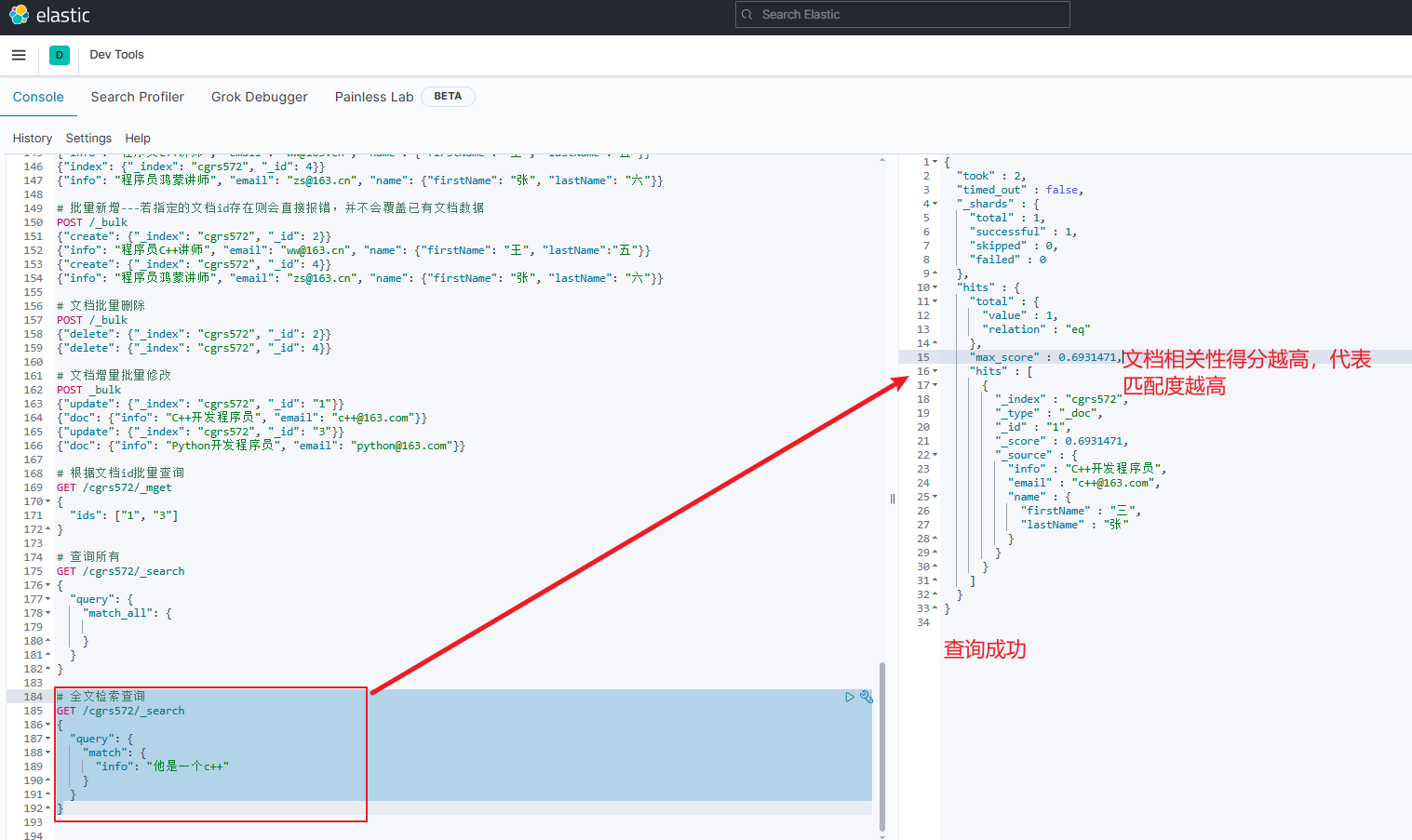
- 注意:
-
multi_match类型全文检索的语法格式如下:- 注意:
multi_match类型全文检索允许同时查询多个字段
jsonGET /{索引库名}/_search { "query": { "multi_match": { "query": "用户输入内容", "fields": ["字段名1", "字段名2", ...] } } }-
错误示例
jsonGET /cgrs572/_search { "query": { "multi_match": { "query": "程序员", "fields": ["info", "email"] } } }注意:由于在创建索引库和映射时,字段
email的index属性值为false,即不参与搜索,所以此时会报错:failed to create query: Cannot search on field [email] since it is not indexed.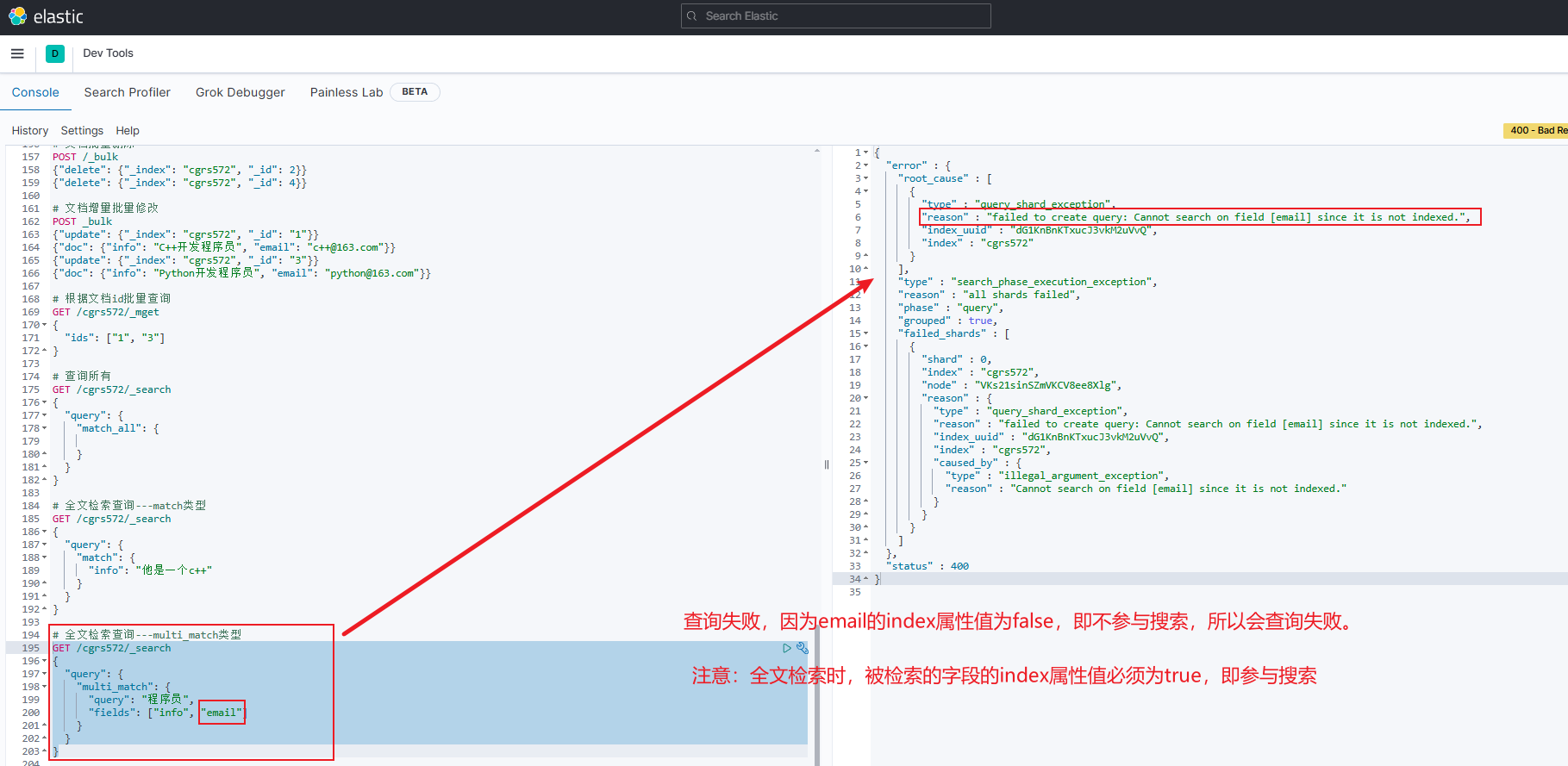
-
正确示例
GET /cgrs572/_search { "query": { "multi_match": { "query": "程序员", "fields": ["info", "name.firstName"] } } }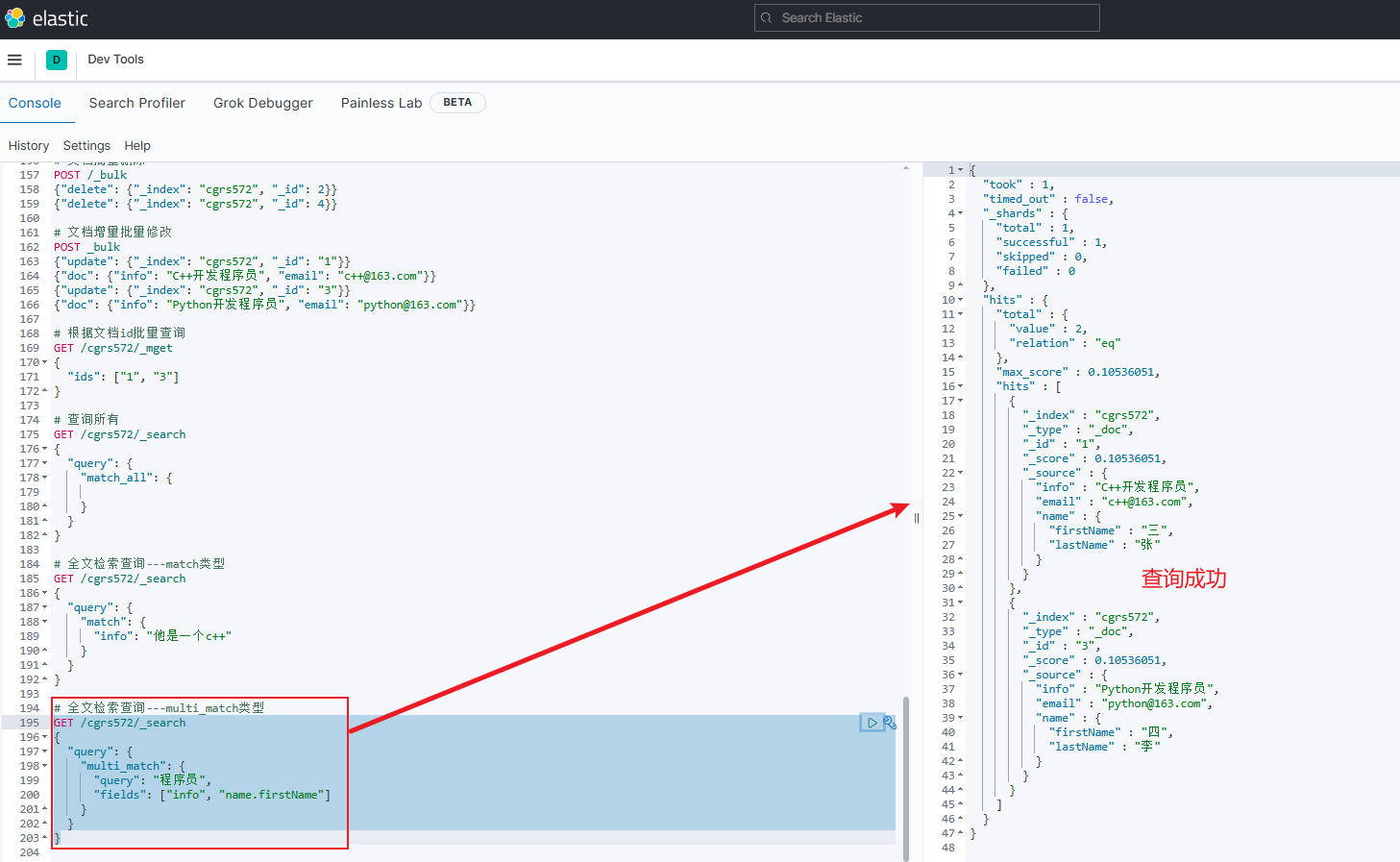
- 注意:
-
注意:
- 参与查询的字段越多,查询的效率就越低,性能就越差,因此可将多个字段的内容写到一个特定字段中,最终借助该特定字段来查询,因此更推荐
match类型全文检索
- 参与查询的字段越多,查询的效率就越低,性能就越差,因此可将多个字段的内容写到一个特定字段中,最终借助该特定字段来查询,因此更推荐
精确查询
-
精确查询(Term-level Queries):不会对用户输入的内容进行分词,而是直接将其作为一个词条与搜索的字段内容进行 精确匹配(即完全匹配) 。一般用来查询
keyword、数值、日期、boolean等类型字段(即作为一个整体才有含义的字段)。常见的查询类型有:注意:被查询字段的数据类型不能为
text(即可分词的文本)-
term:根据词条精确值查询 -
ids:根据文档id查询一个或多个文档 -
range:根据值的范围查询
-
-
term类型精确查询的语法格式如下:jsonGET /{索引库名}/_search { "query": { "term": { "字段名": { "value": "用户输入内容" } } } }-
错误示例
在该示例中由于被查询的字段
info的数据类型为text(即可分词的文本),所以即使查询成功,也不会有任何文档数据返回jsonGET /cgrs572/_search { "query": { "term": { "info": { "value": "C++程序员" } } } }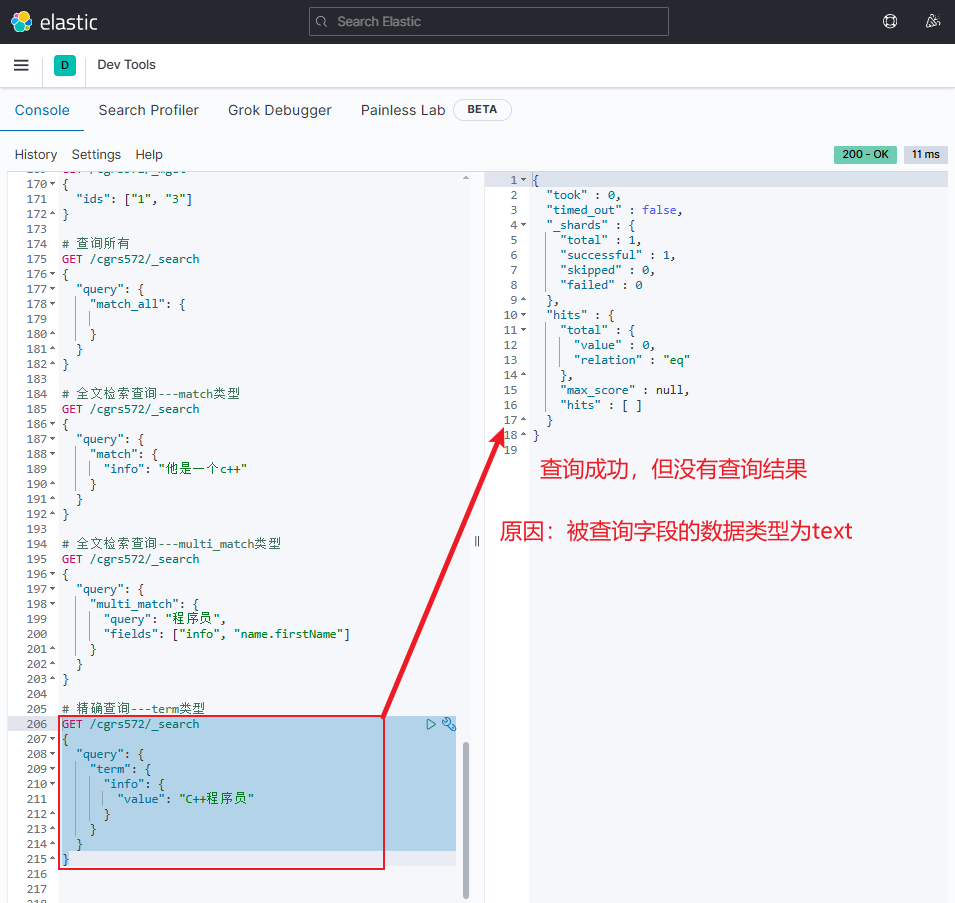
-
正确示例
jsonGET /cgrs572/_search { "query": { "term": { "name.lastName": { "value": "张" } } } }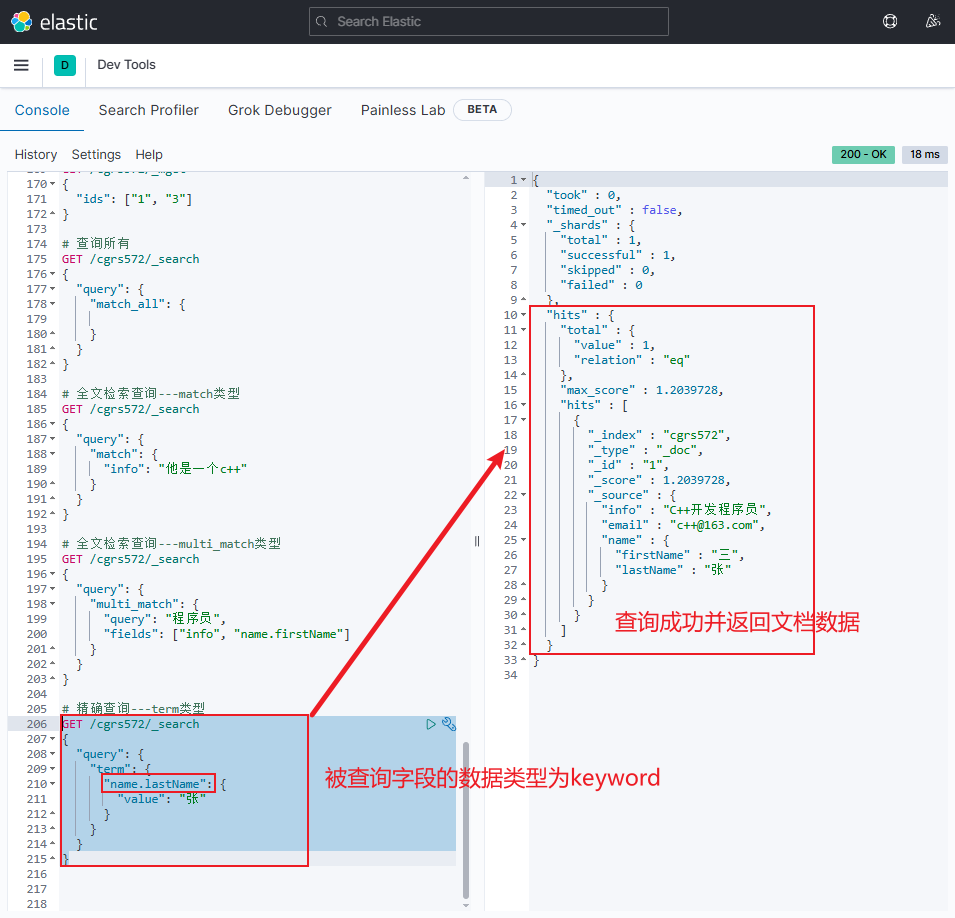
-
-
ids类型精确查询的语法格式如下:jsonGET /{索引库名}/_search { "query": { "ids": { "values": ["文档id", "文档id", ...] } } }-
示例
jsonGET /cgrs572/_search { "query": { "ids": { "values": ["1", "3"] } } }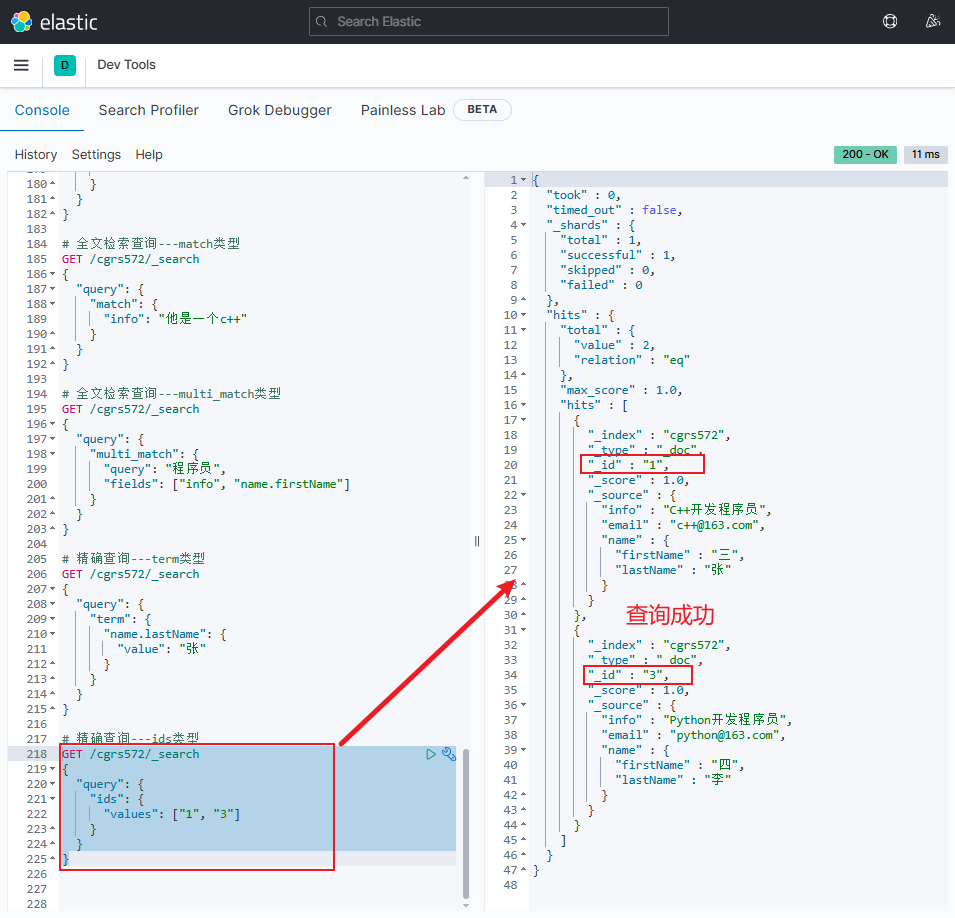
-
-
range类型精确查询的语法格式如下:gt:>gte:≥lt:<lte:≤
jsonGET /{索引库名}/_search { "query": { "range": { "字段名": { "gte": "上限", "lte": "下限" } } } }注意:
-
博主已创建的索引库和映射中无法写出该查询的示例以及后续内容的示例,因此给已有索引库
cgrs572添加新的字段到mapping中,最终创建该索引库和映射的完整代码如下: -
"type": "integer":数值类型 -
"type": "geo_point":存储地理坐标
jsonPUT /cgrs572 { "mappings": { "properties": { "info": { "type": "text", "analyzer": "ik_smart" }, "email": { "type": "keyword", "index": false }, "value": { "type": "integer" }, "location": { "type": "geo_point" }, "name": { "type": "object", "properties": { "firstName": { "type": "keyword" }, "lastName": { "type": "keyword" } } } } } }新增文档代码如下:
jsonPOST /cgrs572/_doc/1 { "info": "C++开发程序员", "email": "c++@163.com", "value": 25, "location": { "lat": 31.2326, "lon": 121.4737 }, "name": { "firstName": "三", "lastName": "张" } } POST /cgrs572/_doc/3 { "info": "Python开发程序员", "email": "python@163.com", "value": 30, "location": { "lat": 31.244288, "lon": 121.422419 }, "name": { "firstName": "四", "lastName": "李" } }-
range类型精确查询示例jsonGET /cgrs572/_search { "query": { "range": { "value": { "gte": 10, "lte": 28 } } } }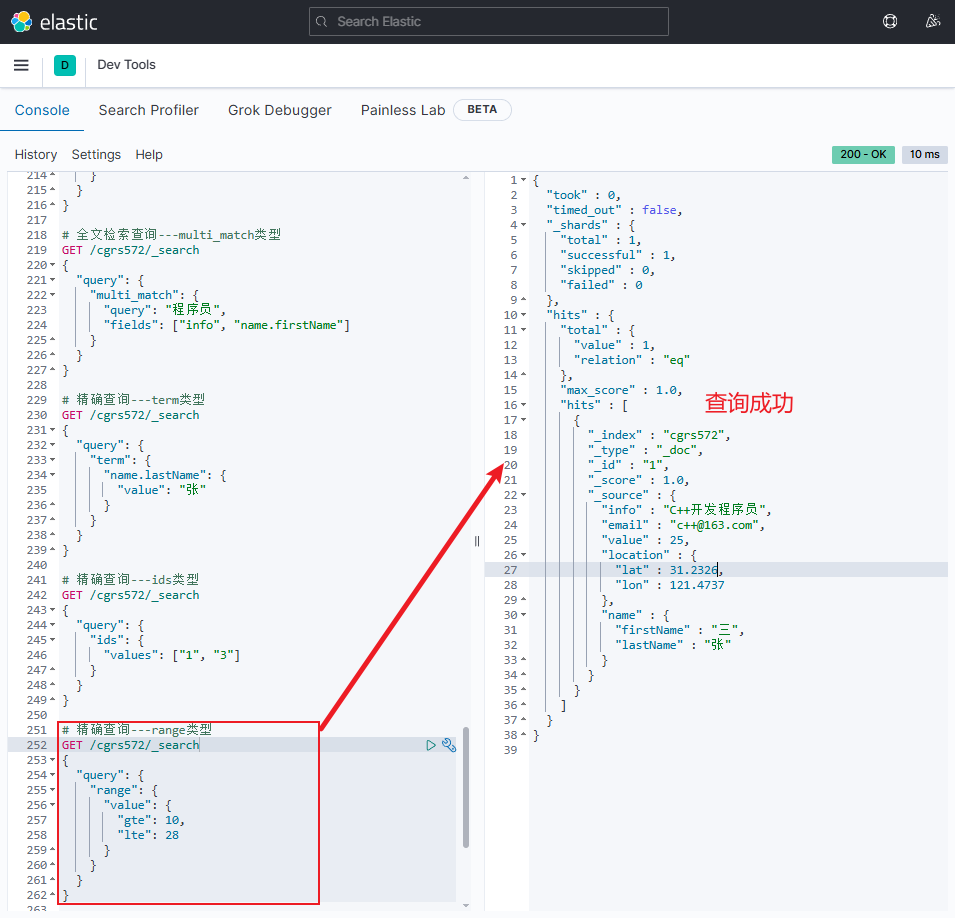
地理查询
-
地理坐标查询(Geo Queries):根据经纬度查询。
-
常见使用场景:滴滴搜索附近出租车、美团搜索附近酒店等
-
常见查询类型:
-
geo_bounding_box:根据geo_point值落在某个矩形范围内的所有文档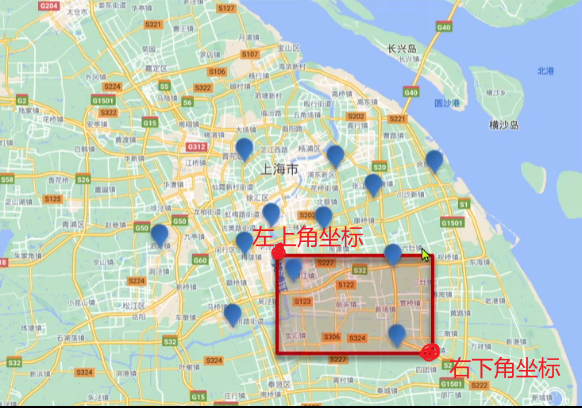
-
geo_distance:查询到指定中心点小于某个距离值的所有文档(即查询以指定中心点为半径区域内的所有文档)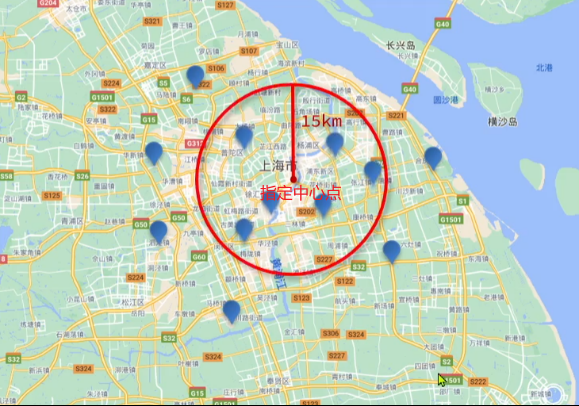
-
-
-
geo_bounding_box类型地理查询的语法格式如下:jsonGET /{索引库名}/_search { "query": { "geo_bounding_box": { "字段名": { "top_left": { "lat": 纬度值, "lon": 经度值 }, "bottom_right": { "lat": 纬度值, "lon": 经度值 } } } } }-
示例
jsonGET /cgrs572/_search { "query": { "geo_bounding_box": { "location": { "top_left": { "lat": 31.3, "lon": 121.3 }, "bottom_right": { "lat": 31.1, "lon": 121.7 } } } } }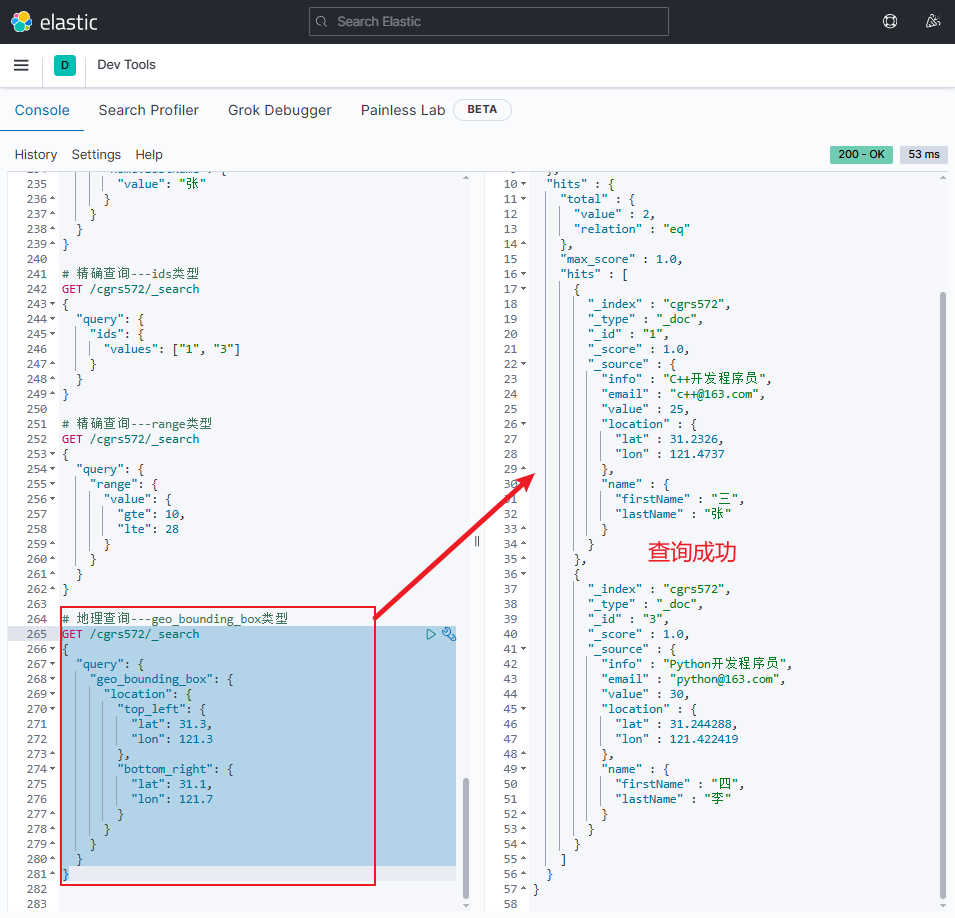
-
-
geo_distance类型地理查询的语法格式如下:jsonGET /{索引库名}/_search { "query": { "geo_distance": { "distance": "距离", "字段名": "纬度值, 经度值" } } }-
示例
jsonGET /cgrs572/_search { "query": { "geo_distance": { "distance": "5km", "location": "31.21, 121.5" } } }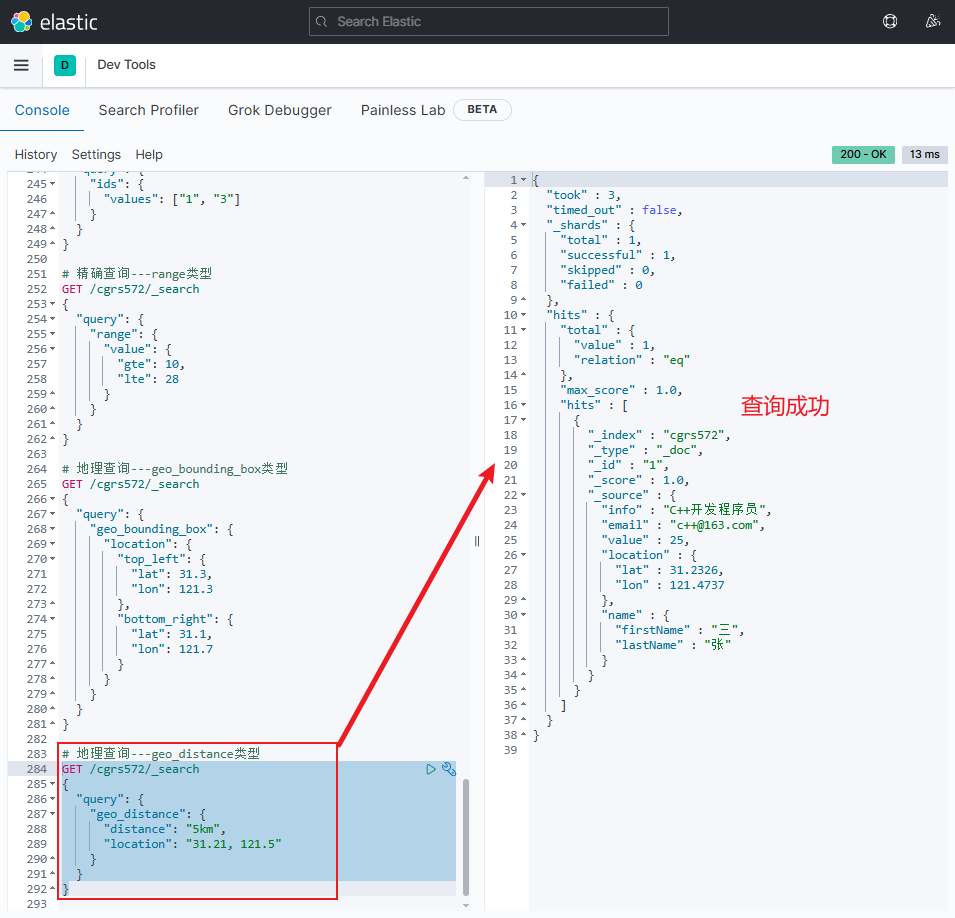
-
复合查询
-
复合查询(Compound query clauses):以逻辑方式将多个叶子查询组合或者更改叶子查询的行为方式,以此来构成查询条件。主要分为两类
- 第一类:基于逻辑运算组合叶子查询,实现组合条件。例如:
bool - 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
function_score、dis_max - 其它复合查询及相关语法可自行参考官方文档
- 第一类:基于逻辑运算组合叶子查询,实现组合条件。例如:
-
注意:利用match查询时,文档结果会根据与搜索词条的关联度打分 (_score),返回结果时按照分值降序排列。
-
采用的相关性打分算法有
-
ES5.1之前:采用TF-IDF算法(会随着词频的增加而越来越大)

-
ES5.1开始:采用的是BM25算法(会随着词频的增加而增大,但增长曲线会趋于水平)

-
-
Function Score Query
-
Function Score Query可修改文档的相关性算分(Query Score),获取新的算分排序,常见场景:百度搜索出来的广告推广,付钱越多,广告信息越靠前
-
语法格式如下:
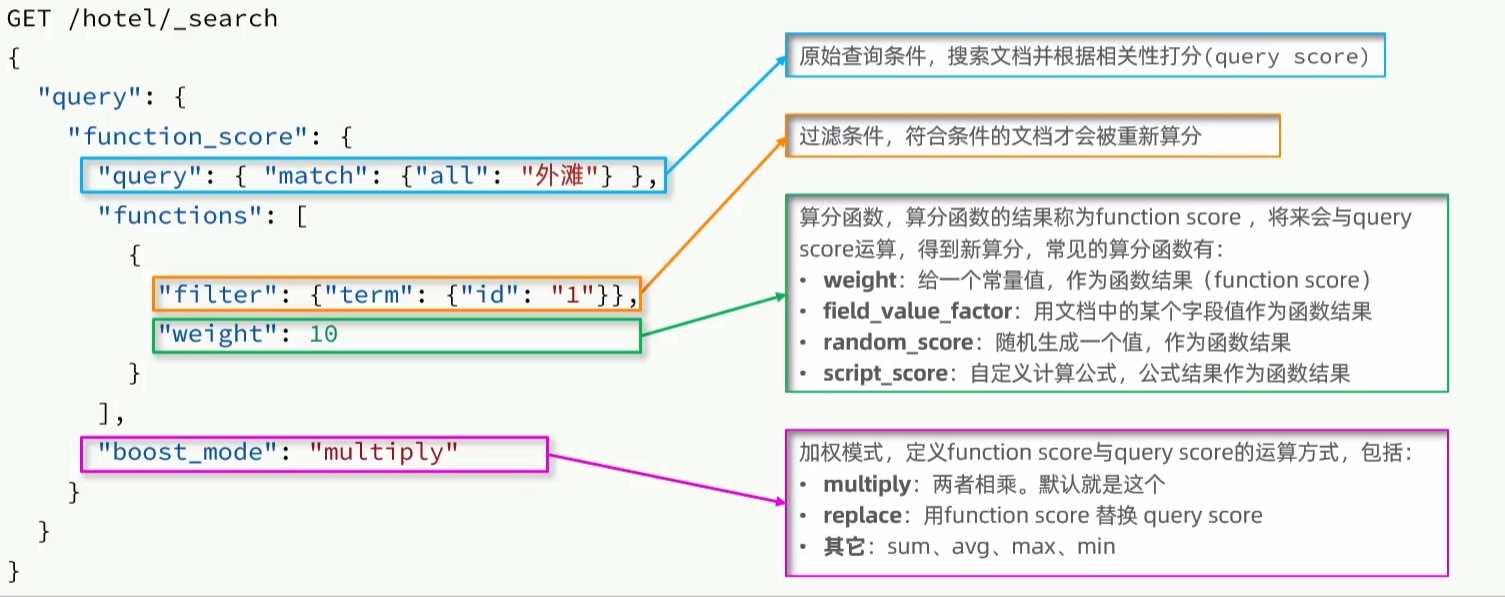 json
jsonGET /{索引库名}/_search { "query": { "function_score": { "query": { .... }, // 原始查询条件 "functions": [ // 算分函数 { "filter": { // 满足的条件 "term": { // 精确查询 "字段名": "字段值" } }, "weight": 10 // 算分权重为2 } ], "boost_mode": "multipy" // 加权模式,求乘积 } } }- Function Score 查询中包含四部分内容:
- 原始查询 条件:query部分,搜索出所有符合这个条件的文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数 :符合filter条件的文档要根据这个函数做运算,得到的函数算分 (function score),有四种函数:
- weight:给一个常量值,作为函数结果(function score)
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:随机生成一个值作为函数结果
- script_score:自定义计算公式,公式结果作为函数结果
- 运算模式 :算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
- Function Score 查询中包含四部分内容:
-
Function Score运行流程:
- Step1:根据原始条件 查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- Step2:根据过滤条件,过滤文档
- Step3:符合过滤条件 的文档,基于算分函数 运算,得到函数算分(function score)
- Step4:将原始算分 (query score)和函数算分 (function score)基于运算模式做运算,得到最终结果,作为相关性算分。
示例:让 Python开发程序员 靠前一点
-
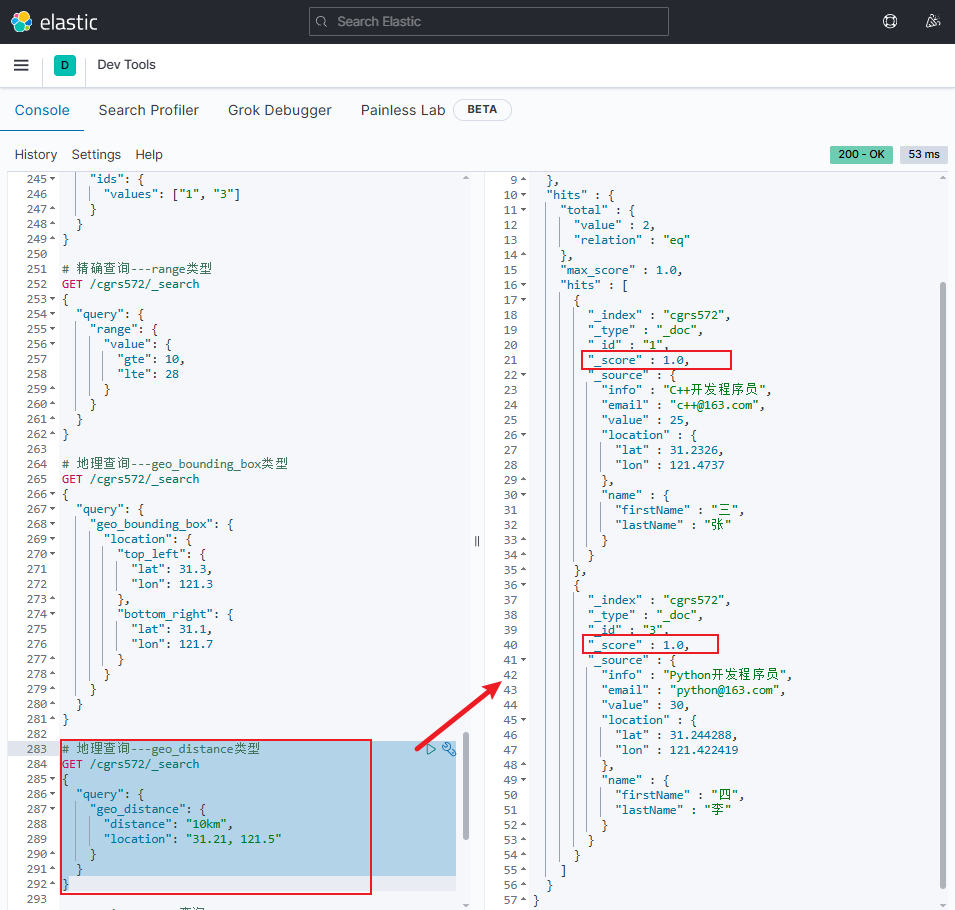
原始地理查询查询10km半径范围内的文档时,结果如下所示,可知查询出的文档数据的得分均为1,且 Python开发程序员 靠后
-
Function Score 查询代码示例
jsonGET /cgrs572/_search { "query": { "function_score": { "query": { "geo_distance": { "distance": "10km", "location": "31.21, 121.5" } } , "functions": [ { "filter": { "term": { "name.lastName": "李" } }, "weight": 10 } ], "boost_mode": "sum" } } }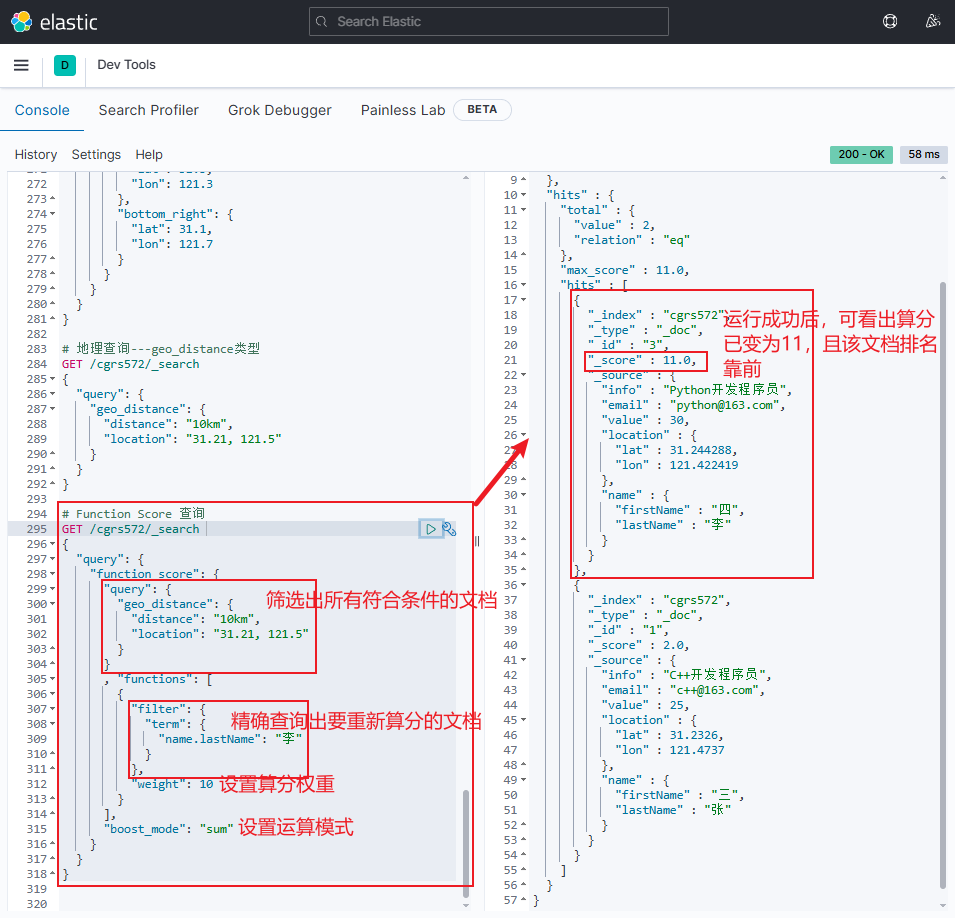
Boolean Query
-
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
- must:必须匹配每个子查询,类似"与"
- should:选择性匹配子查询,类似"或"
- must_not:必须不匹配,不参与算分,类似"非"
- filter:必须匹配,不参与算分
- 注意:与搜索关键字无关的查询尽量采用
must_not或filter逻辑运算,避免参与相关性算分,提升性能
-
注意:页面商品搜索时,输入框的搜索条件需要参与相关性算分,可以采用match。但是价格范围过滤、品牌过滤、分类过滤等尽量采用filter,不要参与相关性算分。

-
示例:输入框搜索
手机,但品牌必须是华为,价格必须是900~1599jsonGET /cgrs572/_search { "query": { "bool": { "must": [ {"match": {"name": "手机"}} ], "filter": [ {"term": {"brand": { "value": "华为" }}}, {"range": {"price": {"gte": 90000, "lt": 159900}}} ] } } }