纯手打,代码整理中......
序号沿用总结三
8、归一化 (Normalization):MinMaxScaler
不同特征可能有不同的量纲和范围(如身高、体重、年龄),归一化使各特征在相同尺度上进行比较, 避免某些特征因数值较大而主导模型。
我们将特征缩放至一个特定的范围(默认是 0, 1)。 归一化(Normalization)公式,也称为最小-最大归一化(Min-Max Normalization)
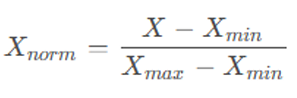
这个公式将原始数据 X 从其原始范围转换到 0,1 的范围内。 公式各部分解释
- X:原始数据值(待处理的单个数据点)
- Xmin:整个数据集中该特征的最小值
- Xmax:整个数据集中该特征的最大值
- Xnorm:经过 Min-Max 归一化后的数据值
工作原理:该过程分为两步:
-
数据平移 :通过计算 X −Xmin,将原始数据的最小值调整为 0,使所有数据的取值起点统一。
-
数据缩放 :将平移后的数据除以数据的范围(Xmax −Xmin),从而将数据压缩到 0,1 区间内。
特点:
-
归一化后的数据范围是 0,1
-
原始数据中的最小值 Xmin 被映射为 0
-
原始数据中的最大值 Xmax 被映射为 1
-
保持了原始数据的分布形状,只是缩放了范围
应用场景 归一化在机器学习和数据挖掘中非常常用,特别是:
-
特征缩放,使不同量纲的特征可比较
-
梯度下降算法中加速收敛
-
神经网络中防止梯度消失或爆炸
-
图像处理中的像素值标准化
在Scikit-learn中,使用MinMaxScaler 进行归一化操作。在初始化MinMaxScaler 对象时,最重要的参数是:
-
feature_range: tuple (min, max), 默认=(0, 1)
-
作用:指定你想要将数据缩放到的目标范围。
-
示例:如果想缩放到 -1, 1,则设置 feature_range=(-1, 1) 。
我们看一个示例:
python
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
# ===================== 1. 创建示例数据集 =====================
# 数据说明:包含数值型(带缺失值)和分类型特征
data = {
'age': [25, 30, np.nan, 45, 60, 30, 15], # 数值型,含缺失值
'salary': [50000, 54000, 60000, np.nan, 100000, 40000, 20000], # 数值型,尺度差异大,含缺失值
'country': ['USA', 'UK', 'China', 'USA', 'India', 'China', 'UK'], # 分类型
'gender': ['M', 'F', 'F', 'M', 'M', 'F', 'F'] # 分类型
}
# 转换为DataFrame
df = pd.DataFrame(data)
print("=" * 40)
print("原始数据:")
print("=" * 40)
print(df)
# ===================== 2. 处理数值型特征缺失值 =====================
# 定义数值型特征列表
numeric_features = ['age', 'salary']
# 创建缺失值填充器(使用均值填充)
# 可选策略:mean(均值)/median(中位数)/most_frequent(众数)/constant(固定值)
imputer = SimpleImputer(strategy='mean')
# 拟合并转换数值型特征(填充缺失值)
df[numeric_features] = imputer.fit_transform(df[numeric_features])
print("\n" + "=" * 40)
print("处理缺失值后的数据:")
print("=" * 40)
print(df)
# ===================== 3. 数值特征归一化(Min-Max) =====================
# 创建MinMaxScaler实例(将数据缩放到[0,1]区间)
minmax_scaler = MinMaxScaler()
# 对数值特征进行归一化
df_normalized = minmax_scaler.fit_transform(df[numeric_features])
# 转换为DataFrame便于查看
df_normalized_df = pd.DataFrame(
df_normalized,
columns=[f'{col}_normalized' for col in numeric_features],
index=df.index
)
print("\n" + "=" * 40)
print("归一化后的数值特征(范围[0,1]):")
print("=" * 40)
print(df_normalized_df)
# 可选:合并归一化后的数据到原DataFrame
df_combined = pd.concat([df, df_normalized_df], axis=1)
print("\n" + "=" * 40)
print("合并所有数据后的完整结果:")
print("=" * 40)
print(df_combined)输出:
python
========================================
原始数据:
========================================
age salary country gender
0 25.0 50000.0 USA M
1 30.0 54000.0 UK F
2 NaN 60000.0 China F
3 45.0 NaN USA M
4 60.0 100000.0 India M
5 30.0 40000.0 China F
6 15.0 20000.0 UK F
========================================
处理缺失值后的数据:
========================================
age salary country gender
0 25.000000 50000.0 USA M
1 30.000000 54000.0 UK F
2 34.166667 60000.0 China F
3 45.000000 54000.0 USA M
4 60.000000 100000.0 India M
5 30.000000 40000.0 China F
6 15.000000 20000.0 UK F
========================================
归一化后的数值特征(范围[0,1]):
========================================
age_normalized salary_normalized
0 0.222222 0.375
1 0.333333 0.425
2 0.425926 0.500
3 0.666667 0.425
4 1.000000 1.000
5 0.333333 0.250
6 0.000000 0.000
========================================
合并所有数据后的完整结果:
========================================
age salary country gender age_normalized salary_normalized
0 25.000000 50000.0 USA M 0.222222 0.375
1 30.000000 54000.0 UK F 0.333333 0.425
2 34.166667 60000.0 China F 0.425926 0.500
3 45.000000 54000.0 USA M 0.666667 0.425
4 60.000000 100000.0 India M 1.000000 1.000
5 30.000000 40000.0 China F 0.333333 0.250
6 15.000000 20000.0 UK F 0.000000 0.000输出归一化后的数值特征(age 和 salary 缩放到 0-1 区间)
9、标准化 (Standardization):StandardScaler
归一化是基于最大值和最小值的,因此异常值(outliers)会对归一化的结果产生较大影响。极端情况下,一个异常值可能会将整个特征的范围压缩到很小的范围,从而导致其他正常数据的表示能力下降。 所以我们引入能够尽可能降低异常值对数据处理结果影响的标准化计算操作。将特征缩放为均值为 0, 方差为1的标准正态分布。
标准化(Standardization)公式是:
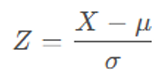
公式中,
-
Z(Z-score):标准化后的值,代表数据点偏离平均值的标准差单位数
-
X:原始数据点的值
-
μ(mu):数据集的平均值(mean)
-
σ( sigma ):数据集的标准差(standard deviation)
主要流程
标准化将原始数据转换为均值为 0、 标准差 为 1的标准正态分布,步骤为:
-
计算数据点与均值的差值:X −μ(表示数据点偏离中心的距离)
-
将差值除以标准差σ,把偏离程度转化为 "标准差单位"
标准化的意义
-
统一 量纲:把不同量纲、不同范围的特征转换到同一尺度
-
中心化:转换后数据分布的中心在 0 点
-
标准化尺度:转换后的值代表 "偏离平均值多少个标准差",例如:
-
Z=0:数据点等于均值
-
Z=1:数据点比均值高 1 个标准差
-
Z=−2:数据点比均值低 2 个标准差
-
在Scikit-learn中,使用 StandardScaler 进行标准化操作。代码示例如下:
python
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
# 创建示例数据,包含不同类型的问题
data = {
'age': [25, 30, np.nan, 45, 60, 30, 15], # 数值,含缺失值
'salary': [50000, 54000, 60000, np.nan, 100000, 40000, 20000], # 数值,尺度大,含缺失值
'country': ['USA', 'UK', 'China', 'USA', 'India', 'China', 'UK'], # 分类型
'gender': ['M', 'F', 'F', 'M', 'M', 'F', 'F'] # 分类型
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
# 策略通常为 mean(均值), median(中位数), most_frequent(众数), constant(固定值)
imputer = SimpleImputer(strategy='mean')
# 我们只对数值列进行填充
numeric_features = ['age', 'salary']
df_numeric = df[numeric_features]
# fit 计算用于填充的值(这里是均值),transform 应用填充
imputer.fit(df_numeric)
df[numeric_features] = imputer.transform(df_numeric)
print("\n处理缺失值后:")
print(df)
standard_scaler = StandardScaler()
df_numeric = df[['age', 'salary']]
# 根据数据训练生成模型
standard_scaler.fit(df_numeric)
# 根据模型训练数据
df_standardized = standard_scaler.transform(df_numeric)
print("\n标准化后的数值特征:")
print(df_standardized)
print(f"标准化后的方差:{df_standardized.std()}")输出
python
原始数据:
age salary country gender
0 25.0 50000.0 USA M
1 30.0 54000.0 UK F
2 NaN 60000.0 China F
3 45.0 NaN USA M
4 60.0 100000.0 India M
5 30.0 40000.0 China F
6 15.0 20000.0 UK F
处理缺失值后:
age salary country gender
0 25.000000 50000.0 USA M
1 30.000000 54000.0 UK F
2 34.166667 60000.0 China F
3 45.000000 54000.0 USA M
4 60.000000 100000.0 India M
5 30.000000 40000.0 China F
6 15.000000 20000.0 UK F
标准化后的数值特征:
[[-0.68032458 -0.17837652]
[-0.30923844 0. ]
[ 0. 0.26756478]
[ 0.80401995 0. ]
[ 1.91727835 2.05132995]
[-0.30923844 -0.62431781]
[-1.42249684 -1.51620039]]
标准化后的方差:1.0===初始化参数详细解释:
初始化StandardScaler对象时,可配置以下参数(均为布尔类型,默认 True):
-
with_mean
-
作用:是否对数据做 "居中"(减去均值)。
-
补充:若设为 False,计算逻辑变为
x / σ;对于稀疏矩阵,推荐设为 False(居中会破坏稀疏性)。
-
-
with_std
-
作用:是否将数据缩放到 "单位方差"(除以标准差)。
-
补充:若设为 False,计算逻辑变为
x - μ,仅做居中处理。
-
===训练后(fit/fit_transform)的属性
调用训练方法后,StandardScaler对象会生成以下属性:
-
mean_ :每个特征在训练数据中的均值(对应公式中的μ)。
-
var_:每个特征在训练数据中的方差。
-
scale_ :每个特征在训练数据中的标准差(对应公式中的σ),是 transform 时的缩放比例。
-
n_samples_seen_:每个特征中处理过的样本数(用于在线计算均值 / 方差)。
-
n_features_in_:训练时使用的特征数量。
-
feature_names_in_:训练时使用的特征名称(若输入是 Pandas DataFrame)。