《Cooperative UAV Trajectory Design for Disaster Area Emergency Communications: A Multiagent PPO Method》发表于IEEE Internet of Things Journal
一、背景、问题与核心优势
1. 研究背景
在重大自然灾害(如地震、洪水)或人为灾难发生后,地面通信基础设施(如蜂窝基站)往往是首批遭受严重破坏的公共设施之一。通信中断不仅阻碍了救援力量的指挥调度,更使受灾群众陷入信息孤岛,加剧社会恐慌并延误自救互救。因此,快速建立临时、可靠、广覆盖的应急通信网络成为灾后"黄金72小时"救援的关键任务。
近年来,无人机因其卓越的机动性、快速部署能力和灵活的视距通信链路,被视为构建"空中基站"或"空中中继"的理想平台。特别是搭载了射频与自由空间光混合通信模块的无人机,能够利用RF链路服务地面用户,同时通过高带宽、远距离的FSO链路与远端完好的地面基站相连,形成完整的"用户-无人机-地面基站"通信回路。
2. 待解决的核心问题
尽管前景广阔,但在真实的动态灾难场景中,多无人机协同通信面临一个高维、动态、分布式的核心优化难题。具体挑战包括:
动态环境:受灾群众的分布与移动(移动用户, MUs)是不可预测且不规则的,传统静态或规则移动模型不适用。
高维状态空间:系统状态包含所有无人机、用户的位置、速度、信道条件(如视距概率、信噪比、干扰),维度极高,传统优化方法难以处理。
分布式协同决策:灾难现场难以部署集中控制器,且集中式方案存在单点故障风险。多架无人机必须基于各自的局部观测,进行分布式决策,同时又要相互协作,避免相互干扰,共同实现全局最优的通信覆盖与容量目标。
混合链路耦合:RF链路容量受距离和无人机间同频干扰制约;FSO回传链路对传输距离和大气能见度极为敏感。两条链路需协同优化,任何一环的瓶颈都将限制整体性能。
3. 论文方法(KMAPPO)概述
论文提出了一种名为 KMAPPO 的创新算法,旨在高效解决上述难题。其核心思想是将经典聚类算法的先验知识与先进的多智能体深度强化学习相结合。
KMAPPO方法相较于已有研究(如传统优化、单智能体DRL、基础多智能体DRL)具备显著优势:
在环境适应性方面,KMAPPO引入了统计物理学中的麦克斯韦-玻尔兹曼分布来模拟灾难现场人群的运动模式。
在问题建模方面,论文将将问题形式化为一个去中心化的部分可观察马尔可夫决策过程。
在算法启动与收敛效率方面,KMAPPO的创新性在于其增强的K-means初始化阶段。
在多智能体协同与训练稳定性方面,KMAPPO基于MAPPO框架,采用了"集中式训练,分布式执行"的范式,并融合了PPO-Clip这一先进的策略优化机制。
在混合通信链路协同优化方面,KMAPPO通过精心设计的复合奖励函数,首次在DRL框架内实现了对RF/FSO混合链路的联合优化。
二、具体方法详述
1. 系统建模与问题形式化
混合通信信道建模
射频信道模型 :
无人机与地面用户间的信道为概率视距信道。路径损耗分视距与非视距两种情况建模:
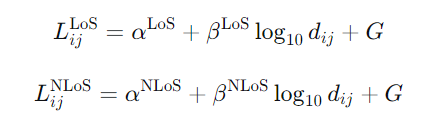
其中,dij 是无人机 i与用户 j的欧氏距离,α,β 为环境相关的路径损耗参数,G为零均值高斯随机变量(阴影衰落)。
视距概率采用与仰角 φij相关的S型函数:
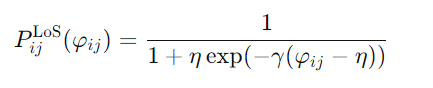
平均路径损耗 及信噪比计算如下:
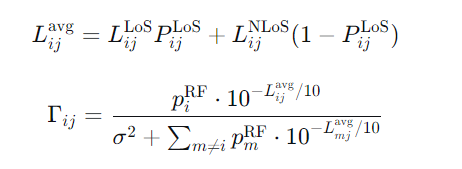
FSO回传信道模型 :
FSO链路容量(回传速率)主要受限于大气衰减和几何损耗:
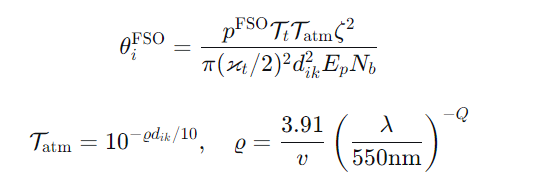
其中 dik为无人机与地面基站距离,ϱ为大气衰减系数,与能见度 v和波长 λ相关,Q为环境质量因子。
用户移动性建模:麦克斯韦-玻尔兹曼分布
论文创新性地借用统计物理学中的麦克斯韦-玻尔兹曼分布来描述灾难现场人群的无序运动。用户速度分量 Vx的概率密度函数为:
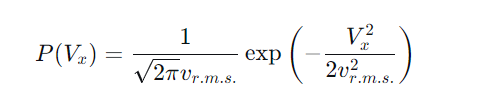
二维联合分布为
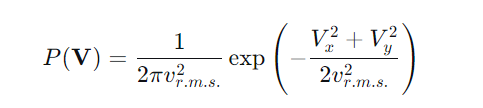
其中 为均方根速度。该模型成功捕捉了人群运动的随机性与各向同性,比简单随机游走模型更贴近实际观测数据。
优化问题形式化
目标是在满足各种约束下,最大化所有被服务用户的总射频吞吐量:
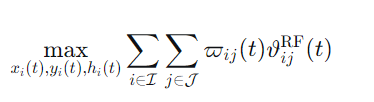
约束条件包括:
每个用户最多连接一架无人机:
通信信噪比不低于阈值 :
无人机总带宽和FSO回传速率限制:
无人机三维飞行范围限制。
2. KMAPPO算法核心机制
决策模型:DEC-POMDP
论文将上述问题定义为去中心化部分可观察马尔可夫决策过程,这是建模分布式协同决策的标准框架。
智能体:每架无人机。
局部观察 :包括自身及有限观测范围内的用户和基站的位置与速度信息。
全局状态 :所有无人机、用户、基站的完整信息(训练时可用,执行时不可知)。
动作 :定义为极坐标下的飞行指令,即归一化的飞行半径 ξi∈0,1ξi∈0,1 和飞行角度
奖励函数 R(t):精心设计以驱动协同优化。
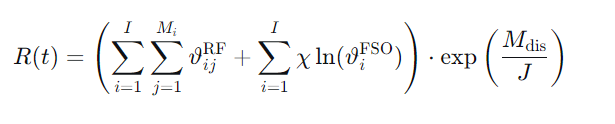
该函数包含三部分:
RF总吞吐量:鼓励高效服务用户。
FSO回传速率对数项(为平衡系数):鼓励维持高质量回传链路,对数形式防止其数值差异过大。
未连接用户指数惩罚项:为未连接用户数。此项是关键,它能强有力地驱使无人机群优先保障通信覆盖,避免任何用户被遗漏,因为惩罚随未连接用户数呈指数增长。
阶段一:增强K-means初始化
为了给强化学习提供一个高质量的起点,避免耗时的随机探索,KMAPPO首先运行一个增强的K-means算法。
输入:当前所有用户的位置 。
约束:考虑无人机实际观测距离限制如果一个用户与所有初始聚类中心的距离都大于
,则该轮迭代中不将其分配给任何类
目标:最小化所有用户到其所属聚类中心的距离平方和。
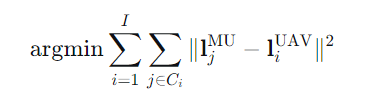
输出:迭代收敛后的个聚类中心,作为
架无人机的初始部署位置。
增强点与作用:引入观测距离约束使初始化更符合物理现实。这相当于为无人机群提供了"空间直觉",使其一开始就近似均匀分布在用户聚集区上空,极大缩短了后续强化学习的探索阶段。
阶段二:基于MAPPO的多智能体强化学习
在获得优质初始位置后,无人机群进入基于 MAPPO 的训练循环,采用"集中式训练,分布式执行"范式。
1. 网络架构 :
每个无人机智能体拥有两部分神经网络:
Actor网络(策略网络):输入局部观察,输出动作的概率分布。负责执行阶段的分布式决策。
Critic网络(价值网络 ):在训练阶段,一个集中式的Critic网络被使用。它可以访问全局状态,用于评估当前联合状态的价值,为各个Actor的策略更新提供更准确的全局指导。
2. 核心优化:PPO-Clip 算法
PPO通过一个裁剪的替代目标函数 来稳定策略更新,这是其成功的关键。
目标函数如下:
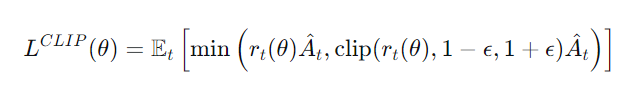
其中:
是新旧策略的概率比。
是优势函数估计,表示当前动作比平均表现好多少(通过Critic网络计算)。
clip(⋅) 函数将限制在
内,
是一个小超参(如0.2)。
当 (动作好),我们希望增加该动作概率,但裁剪防止
过大(即策略更新过猛),避免性能崩溃。
当 (动作差),我们希望减少该动作概率,同样裁剪防止更新过度。
这种简单的一阶优化机制,实现了与复杂二阶方法TRPO相当的稳定性。
3. 训练与执行流程:
集中训练:智能体与环境交互产生轨迹数据。利用全局数据训练集中Critic网络。然后,使用上述PPO-Clip目标函数,并行更新所有Actor网络参数 θ,使策略朝提升全局奖励的方向稳步进化。
分布式执行:训练完成后,每架无人机仅依靠自身的Actor网络和本地观察,即可实时做出飞行决策,无需与其他无人机或中央控制器通信,完美契合灾难现场分布式、高鲁棒性的需求。
三、论文实验结果
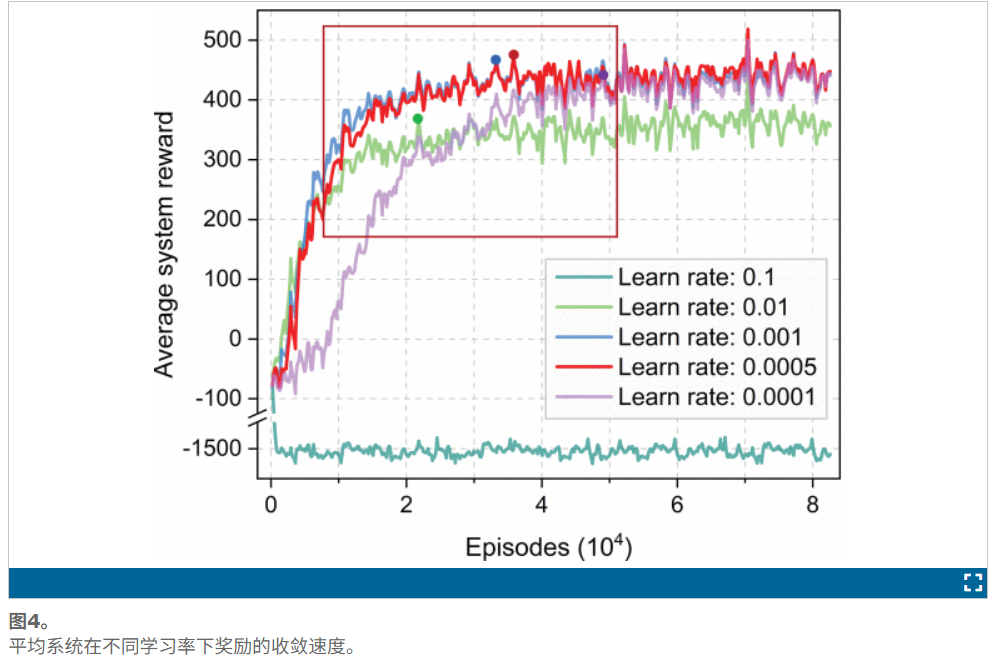
可以观察到,过高的学习率(例如0.1)会阻碍算法收敛。红色框表示随着学习率降低,收敛速度会减慢。此外,过低的学习率只能在收敛后提高系统的平均奖励。当学习率设置为5e4 收敛速度和平均系统奖励实现了良好的平衡
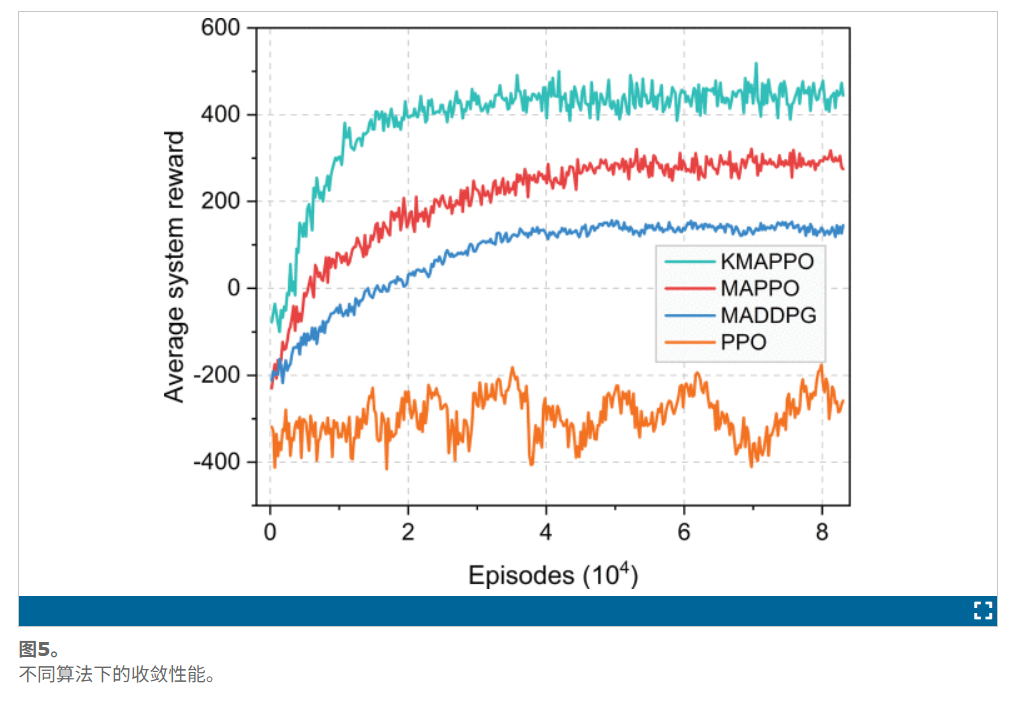
示了该系统在多集内的平均奖励。在3架无人机和3台GBS服务20个MUS的情景下,我们比较这四个算法的收敛速度。显然,KMAPPO实现了最快的收敛(比MAPPO快32%),并获得最高的平均系统奖励。一旦实现趋同,MAPPO的奖励低于KMAPPO。我们将在后续实验中详细分析MAPPO和KMAPPO的性能。此外,MADDPG的最终回报明显低于KMAPPO,这表明MADDPG在灾害环境中可能无效
四、总结
该论文提出的KMAPPO方法,通过融合增强K-means初始化与多智能体PPO强化学习,为解决动态灾难场景下多无人机协同轨迹优化问题提供了一个高效、稳定、实用的解决方案。仿真实验表明,KMAPPO在收敛速度、最终性能(服务用户比例、系统总容量)和算法稳定性上均显著优于PPO、MAPPO、MADDPG及传统PSO等基准算法。
这项工作不仅具有重要的学术价值,展示了传统机器学习与现代深度强化学习结合的有效性,也具备强烈的实际应用前景,为未来智能、自主、协同的无人机应急通信网络奠定了算法基础。
这项研究标志着我们向构建坚韧、自组织、响应迅速的"空中生命线"迈出了坚实的一步。当灾难使地面通信陷入瘫痪,天空中由AI驱动的无人机集群,将成为照亮生命希望、重建信息桥梁的关键力量。