前言
在金融合规领域,私募基金的运作指引条款繁杂、更新频繁。传统的"关键词匹配"或简单的 RAG(检索增强生成)往往难以处理需要多步推理的复杂问题。
今天,我们将带大家实战构建一个基于 ReAct (Reasoning and Acting) 模式的智能体(Agent)。它不仅能查库,还能像人类一样"思考-行动-观察",最终给出精准答案。
我们将使用 Python 、LangChain 和阿里 通义千问 (Qwen-Max) 大模型来实现,并重点讲解如何通过自定义 Prompt 模板 与增强型输出解析器来解决 Agent 常见的"幻觉"和"格式错误"问题。
1. 系统架构设计
本系统的核心在于 Agent(智能体)。它充当"大脑",接收用户问题,决定调用哪个工具(搜索、问答等),并根据工具返回的结果(Observation)决定下一步行动,直到得出最终答案(Final Answer)。
核心流程图
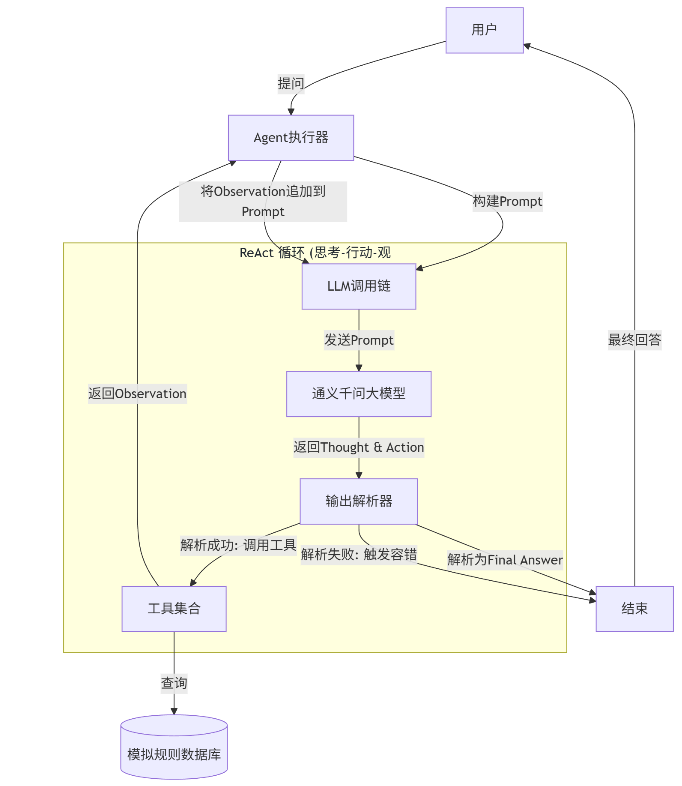
2. 核心代码实现步骤
步骤一:环境与数据源模拟
首先,我们需要模拟一个私募基金的规则库。在实际生产中,这通常是向量数据库(Vector DB)或 SQL 数据库。
python
# 模拟数据
FUND_RULES_DB = [
{
"id": "rule001",
"category": "设立与募集",
"question": "私募基金的合格投资者标准是什么?",
"answer": "合格投资者是指具备相应风险识别能力...净资产不低于1000万元的单位..."
},
# ... 更多规则
]
# 数据源类:提供检索方法
class FundRulesDataSource:
def __init__(self, llm):
self.llm = llm
self.rules_db = FUND_RULES_DB
def search_rules_by_keywords(self, keywords: str) -> str:
"""工具实现:关键词搜索"""
# (省略具体匹配逻辑,详见完整代码)
return "..."
def search_rules_by_category(self, category: str) -> str:
"""工具实现:按类别查询"""
return "..."步骤二:定义工具 (Tools)
Agent 需要知道有哪些"手"可以使用。我们将上述方法封装为 LangChain 的 Tool 对象。
python
from langchain_core.tools import Tool
def create_tools(data_source):
return [
Tool(
name="关键词搜索",
func=data_source.search_rules_by_keywords,
description="通过关键词搜索规则。输入例如:'合格投资者', '募集规模'",
),
Tool(
name="类别查询",
func=data_source.search_rules_by_category,
description="查询特定类别。输入必须是:'设立与募集' 或 '监管规定'",
),
# ... 可以添加更多工具
]步骤三:编写 Prompt 模板(核心优化点)
这是 ReAct 模式的灵魂。我们需要告诉大模型如何"思考"。
优化重点:
- 明确的 ReAct 格式 :强制要求模型按照
Thought->Action->Action Input->Observation的顺序输出。 - Scratchpad 处理 :在
CustomPromptTemplate中,我们显式地处理了中间步骤(intermediate_steps),并在 Observation 后追加\nThought:,强制引导模型进入下一轮思考,防止模型不知道接下来说什么。
python
AGENT_TMPL = """你是一个专业的私募基金问答助手。你的任务是利用给定工具回答用户问题。
你可以使用以下工具:
{tools}
请严格遵循以下思考流程(Thought/Action/Observation/Final Answer):
1. **Thought**: 思考用户的问题需要什么信息,我应该采取什么行动?
2. **Action**: 选择一个合适的工具,工具名称必须是 [{tool_names}] 之一。
3. **Action Input**: 输入工具所需的参数。
4. **Observation**: 工具返回的结果(这一步由系统自动完成)。
5. **Thought**: 观察结果。如果结果足以回答问题,请直接给出最终答案。
6. **Final Answer**: 给用户的最终回答。
**重要提示**:
- 当你得到 "Observation" 后,请立即思考并给出 "Final Answer"。
- 不要编造工具名称。
- 如果知识库没有相关信息,请在 Final Answer 中诚实说明。
--- 示例 ---
Question: 私募基金的合格投资者标准是什么?
Thought: 我需要查找关于合格投资者的定义。
Action: 关键词搜索
Action Input: 合格投资者标准
Observation: 合格投资者是指...(工具返回内容)
Thought: 我已经获得了关于合格投资者的信息,可以回答用户了。
Final Answer: 私募基金的合格投资者标准是...
--- 示例结束 ---
开始回答:
Question: {input}
{agent_scratchpad}"""
class CustomPromptTemplate(StringPromptTemplate):
def format(self, **kwargs) -> str:
intermediate_steps = kwargs.pop("intermediate_steps")
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
# 【关键技巧】手动拼接 Observation 和 下一步的 Thought 引导词
thoughts += f"\nObservation: {observation}\nThought: "
kwargs["agent_scratchpad"] = thoughts
kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
return self.template.format(**kwargs)步骤四:输出解析器与容错机制(关键修复)
大模型通过 API 返回的是纯文本,我们需要用正则解析出 Action 和 Action Input。
优化重点 :
模型有时会"不听话",比如跳过 Action 直接给答案,或者格式微调导致正则失败。我们在 parse 方法中增加了 Fallback(兜底)机制 ,如果正则匹配失败但看起来像是在回答问题,就将其视为 Final Answer,极大提高了系统的鲁棒性。
python
import re
from langchain_core.agents import AgentAction, AgentFinish
from langchain_classic.agents import AgentOutputParser
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str):
llm_output = llm_output.strip()
# 1. 如果包含 Final Answer,直接结束
if "Final Answer:" in llm_output:
return AgentFinish(
return_values={"output": llm_output.split("Final Answer:")[-1].strip()},
log=llm_output,
)
# 2. 尝试正则解析 Action
regex = r"Action\s*\d*\s*:(.*?)\nAction\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if match:
return AgentAction(tool=match.group(1).strip(), tool_input=match.group(2).strip(' "'), log=llm_output)
# 3. [容错] 如果没找到 Action,假设模型是在直接回答
# 避免因格式微小错误导致整个程序 Crash
if not match and "Action:" not in llm_output:
return AgentFinish(
return_values={"output": llm_output},
log=f"Fallback parsing: {llm_output}"
)
raise ValueError(f"无法解析 LLM 输出: `{llm_output}`")步骤五:组装 Agent 并运行
最后,我们将 LLM、Prompt、Parser 组装起来。
注意 :设置 stop=["\nObservation:"] 至关重要,这能防止 LLM 产生幻觉(自己编造工具的返回结果)。
python
from langchain_classic.agents import LLMSingleActionAgent, AgentExecutor
from langchain_community.llms import Tongyi
def create_fund_qa_agent():
# 建议 temperature 设低,保证工具调用的准确性
llm = Tongyi(model_name="qwen3-max", temperature=0.1)
# ... 初始化 tool, prompt, parser ...
llm_chain = LLMChain(llm=llm, prompt=agent_prompt)
agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\nObservation:"], # 遇到 Observation 立即停止生成
allowed_tools=[tool.name for tool in tools],
)
return AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True, # 开启日志,观察思考过程
handle_parsing_errors=True
)3. 运行效果展示
当我们询问:"合格投资者需要满足什么条件? "时,控制台输出如下(verbose模式):

可以看到,Agent 成功地:
- 理解意图:分析出需要查询定义。
- 调用工具:准确使用了"关键词搜索"。
- 整合答案:根据 Observation 生成了最终回复。
4. 总结与优化思路
通过本文的代码,我们构建了一个鲁棒性较强的垂直领域问答助手。相比于简单的 RAG,Agent 能够处理更复杂的逻辑,例如"先查A,再查B,最后对比"。
本次代码的 3 大优化点总结:
- Prompt 强化 :通过
intermediate_steps的手动拼接,强制模型进入思考状态,减少卡壳。 - Parser 兜底:解决了模型"不按格式输出"导致的程序崩溃问题,提升了用户体验。
- Stop Token:有效防止了模型自问自答的幻觉问题。
后续扩展方向:
- 接入真实的向量数据库(如 Milvus, Chroma)。
- 增加更多工具(如计算器、实时汇率查询)。
- 将 LangChain Classic 迁移至最新的
langchain.agents.create_react_agent接口。
5. 完整代码
python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
私募基金运作指引问答助手 - 反应式智能体实现 (优化版)
"""
import os
import re
from typing import List, Dict, Any, Union
# 注意:根据您的环境,请保留您原本能跑通的导入路径
# 如果是较新版本的 LangChain,建议逐渐迁移到 langchain.agents.create_react_agent
from langchain_classic.agents import AgentOutputParser, LLMSingleActionAgent, AgentExecutor
from langchain_classic.chains.llm import LLMChain
from langchain_community.llms import Tongyi
from langchain_core.agents import AgentFinish, AgentAction
from langchain_core.language_models import BaseLLM
from langchain_core.prompts import PromptTemplate, StringPromptTemplate
from langchain_core.tools import Tool
# 通义千问API密钥
DASHSCOPE_API_KEY = os.environ.get("DASHSCOPE_API_KEY")
# --- 数据定义保持不变 ---
FUND_RULES_DB = [
{
"id": "rule001",
"category": "设立与募集",
"question": "私募基金的合格投资者标准是什么?",
"answer": "合格投资者是指具备相应风险识别能力和风险承担能力,投资于单只私募基金的金额不低于100万元且符合下列条件之一的单位和个人:\n1. 净资产不低于1000万元的单位\n2. 金融资产不低于300万元或者最近三年个人年均收入不低于50万元的个人"
},
{
"id": "rule002",
"category": "设立与募集",
"question": "私募基金的最低募集规模要求是多少?",
"answer": "私募证券投资基金的最低募集规模不得低于人民币1000万元。对于私募股权基金、创业投资基金等其他类型的私募基金,监管规定更加灵活,通常需符合基金合同的约定。"
},
{
"id": "rule014",
"category": "监管规定",
"question": "私募基金管理人的风险准备金要求是什么?",
"answer": "私募证券基金管理人应当按照管理费收入的10%计提风险准备金,主要用于赔偿因管理人违法违规、违反基金合同、操作错误等给基金财产或者投资者造成的损失。"
}
]
# --- Prompt 模板定义 (这里不需要变动太大,主要逻辑在 Agent Prompt) ---
CONTEXT_QA_TMPL = """
你是私募基金问答助手。请根据以下信息回答问题:
信息:{context}
问题:{query}
"""
CONTEXT_QA_PROMPT = PromptTemplate(
input_variables=["query", "context"],
template=CONTEXT_QA_TMPL,
)
OUTSIDE_KNOWLEDGE_TMPL = """
你是私募基金问答助手。用户的问题是关于私募基金的,但我们的知识库中没有直接相关的信息。
请礼貌地告知用户知识库中暂无此详细信息,并根据通用知识简要回答。
用户问题:{query}
缺失的知识主题:{missing_topic}
"""
OUTSIDE_KNOWLEDGE_PROMPT = PromptTemplate(
input_variables=["query", "missing_topic"],
template=OUTSIDE_KNOWLEDGE_TMPL,
)
# --- 工具类保持不变 ---
class FundRulesDataSource:
def __init__(self, llm: BaseLLM):
self.llm = llm
self.rules_db = FUND_RULES_DB
def search_rules_by_keywords(self, keywords: str) -> str:
"""通过关键词搜索相关私募基金规则"""
keywords = keywords.strip().lower()
keyword_list = re.split(r'[,,\s]+', keywords)
matched_rules = []
for rule in self.rules_db:
rule_text = (rule["category"] + " " + rule["question"]).lower()
match_count = sum(1 for kw in keyword_list if kw in rule_text)
if match_count > 0:
matched_rules.append((rule, match_count))
matched_rules.sort(key=lambda x: x[1], reverse=True)
if not matched_rules:
return "未找到与关键词相关的规则。"
result = []
for rule, _ in matched_rules[:2]:
result.append(f"类别: {rule['category']}\n问题: {rule['question']}\n答案: {rule['answer']}")
return "\n\n".join(result)
def search_rules_by_category(self, category: str) -> str:
"""根据规则类别查询私募基金规则"""
category = category.strip()
matched_rules = []
for rule in self.rules_db:
if category.lower() in rule["category"].lower():
matched_rules.append(rule)
if not matched_rules:
return f"未找到类别为 '{category}' 的规则。"
result = []
for rule in matched_rules:
result.append(f"问题: {rule['question']}\n答案: {rule['answer']}")
return "\n\n".join(result)
def answer_question(self, query: str) -> str:
"""直接回答用户关于私募基金的问题"""
query = query.strip()
best_rule = None
best_score = 0
for rule in self.rules_db:
query_words = set(query.lower().split())
rule_words = set((rule["question"] + " " + rule["category"]).lower().split())
common_words = query_words.intersection(rule_words)
score = len(common_words) / max(1, len(query_words))
if score > best_score:
best_score = score
best_rule = rule
if best_score < 0.2 or best_rule is None:
missing_topic = self._identify_missing_topic(query)
prompt = OUTSIDE_KNOWLEDGE_PROMPT.format(query=query, missing_topic=missing_topic)
response = self.llm(prompt)
return f"知识库无直接记录。补充回答:{response}"
context = best_rule["answer"]
prompt = CONTEXT_QA_PROMPT.format(query=query, context=context)
return self.llm(prompt)
def _identify_missing_topic(self, query: str) -> str:
return "私募基金相关规则"
# --- 核心修改部分开始 ---
# 1. 优化 Agent Prompt:增加对 Final Answer 的明确指引
AGENT_TMPL = """你是一个专业的私募基金问答助手。你的任务是利用给定工具回答用户问题。
你可以使用以下工具:
{tools}
请严格遵循以下思考流程(Thought/Action/Observation/Final Answer):
1. **Thought**: 思考用户的问题需要什么信息,我应该采取什么行动?
2. **Action**: 选择一个合适的工具,工具名称必须是 [{tool_names}] 之一。
3. **Action Input**: 输入工具所需的参数。
4. **Observation**: 工具返回的结果(这一步由系统自动完成)。
5. **Thought**: 观察结果。如果结果足以回答问题,请直接给出最终答案。
6. **Final Answer**: 给用户的最终回答。
**重要提示**:
- 当你得到 "Observation" 后,请立即思考并给出 "Final Answer"。
- 不要编造工具名称。
- 如果知识库没有相关信息,请在 Final Answer 中诚实说明。
--- 示例 ---
Question: 私募基金的合格投资者标准是什么?
Thought: 我需要查找关于合格投资者的定义。
Action: 关键词搜索
Action Input: 合格投资者标准
Observation: 合格投资者是指...(工具返回内容)
Thought: 我已经获得了关于合格投资者的信息,可以回答用户了。
Final Answer: 私募基金的合格投资者标准是...
--- 示例结束 ---
开始回答:
Question: {input}
{agent_scratchpad}"""
# 2. 优化 Prompt Template:正确处理 scratchpad
class CustomPromptTemplate(StringPromptTemplate):
template: str
tools: List[Tool]
def format(self, **kwargs) -> str:
intermediate_steps = kwargs.pop("intermediate_steps")
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
# 关键修改:在 Observation 后加上 \nThought: 引导模型进入思考
thoughts += f"\nObservation: {observation}\nThought: "
kwargs["agent_scratchpad"] = thoughts
kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
return self.template.format(**kwargs)
# 3. 增强 Output Parser:增加容错逻辑
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
# 清理输出中的多余空行
llm_output = llm_output.strip()
# 情况1:模型已经给出了最终答案
if "Final Answer:" in llm_output:
return AgentFinish(
return_values={"output": llm_output.split("Final Answer:")[-1].strip()},
log=llm_output,
)
# 情况2:解析 Action 和 Action Input
regex = r"Action\s*\d*\s*:(.*?)\nAction\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if match:
action = match.group(1).strip()
action_input = match.group(2).strip(' "')
return AgentAction(tool=action, tool_input=action_input, log=llm_output)
# 情况3 [关键修复]:模型没有严格遵循格式,但已经输出了文本内容(通常发生在得到 observation 后)
# 如果模型没有输出 Action,我们假设它是在尝试直接回答
if not match and "Action:" not in llm_output:
# 视为最终答案
return AgentFinish(
return_values={"output": llm_output},
log=f"Fallback parsing: treated as final answer. Output: {llm_output}"
)
raise ValueError(f"无法解析 LLM 输出: `{llm_output}`")
def create_fund_qa_agent():
# 使用温度为0,增加输出的确定性
llm = Tongyi(model_name="qwen3-max", dashscope_api_key=DASHSCOPE_API_KEY, temperature=0.1)
fund_rules_source = FundRulesDataSource(llm)
tools = [
Tool(
name="关键词搜索",
func=fund_rules_source.search_rules_by_keywords,
description="通过关键词搜索规则。输入例如:'合格投资者', '募集规模'",
),
Tool(
name="类别查询",
func=fund_rules_source.search_rules_by_category,
description="查询特定类别。输入必须是:'设立与募集' 或 '监管规定'",
),
Tool(
name="回答问题",
func=fund_rules_source.answer_question,
description="当需要综合分析或直接回答时使用。输入完整问题。",
),
]
agent_prompt = CustomPromptTemplate(
template=AGENT_TMPL,
tools=tools,
input_variables=["input", "intermediate_steps"],
)
output_parser = CustomOutputParser()
# 绑定 stop 参数,防止模型替工具生成 Observation
llm_chain = LLMChain(llm=llm, prompt=agent_prompt)
tool_names = [tool.name for tool in tools]
agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\nObservation:"],
allowed_tools=tool_names,
)
# 增加 max_iterations 防止死循环
agent_executor = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True,
max_iterations=5,
handle_parsing_errors=True # 允许 LangChain 自动处理部分解析错误
)
return agent_executor
if __name__ == "__main__":
if not DASHSCOPE_API_KEY:
print("错误:请设置 DASHSCOPE_API_KEY 环境变量")
exit(1)
fund_qa_agent = create_fund_qa_agent()
print("=== 私募基金运作指引问答助手(优化版)===\n")
# 测试案例
test_questions = [
"合格投资者需要满足什么条件?",
# "风险准备金是多少?", # 可以取消注释测试更多
]
# 交互模式
while True:
try:
user_input = input("\n请输入您的问题 (输入 'q' 退出):")
if user_input.lower() in ['q', 'quit', 'exit']:
break
# 使用 invoke 替代 run (LangChain 新版推荐)
if hasattr(fund_qa_agent, "invoke"):
response = fund_qa_agent.invoke({"input": user_input})
print(f"\n>> 回答: {response['output']}\n")
else:
response = fund_qa_agent.run(user_input)
print(f"\n>> 回答: {response}\n")
except Exception as e:
print(f"执行出错: {e}")