磁盘
在了解mysql的索引机制前需要先了解一下磁盘的存储机制

这是我们使用的磁盘的结构图,虽然我们现在的家用计算机大都是使用的固态硬盘,但是磁盘还是广泛的使用于大量的数据存储,其造价和稳定性都更优于固态硬盘。
磁盘是使用的磁性来记录数据,在计算机中数据都是按照01格式进行存储,所以就分为正负磁性代表01数据,数据都存储在盘片中,一张盘片有正反两面,每一面都是存储数据,每个磁盘都拥有一组盘片相互叠起,但是互不挨着。
数据的读取依靠磁头,磁头会根据盘片对应区域的磁性读取其数据值。盘片的每一面都对应一个磁头,两组的磁头对应一组盘片(正反面所以磁头是盘片数量的两倍)。
盘片通过主轴下方的马达进行选择让磁头可以读取到盘片的每个区域。磁头通过传动轴进行移动来读取盘片不同半径中的区域。
盘片
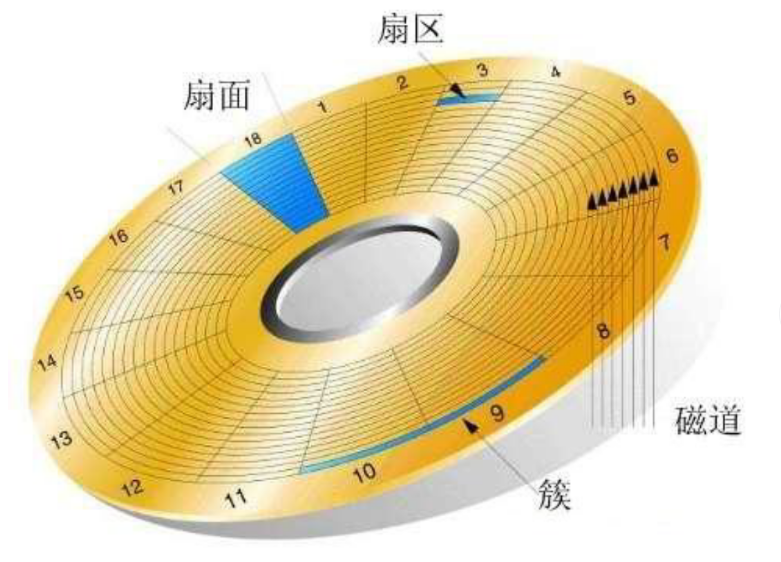
盘片存储数据的结构图,图片每一个格子就是一个扇区,操作系统与磁盘的交互就是以扇区作为单位,计算机就算是只需要读取扇区内的一个bit的数据都会将整个扇区的数据读入内存中,而每次交互都会读取4KB的数据(局部性原理),一般我们读取数据,那么下次需要的数据很有可能就会在当前数据的附近,一次性读取周围的数据可以减少IO的次数。
磁盘每个扇区一般为512字节(每次读取四个扇区的数据)或4KB,同半径的扇区组成的称为磁道,同一列中不同半径的扇区称为扇面。整个磁盘不止一片磁盘,而是由很多磁盘堆叠而成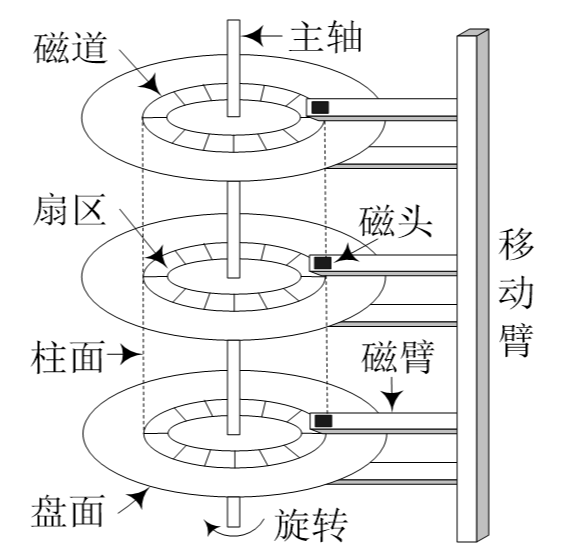
同一个扇区位置,由不同的盘片组合而成的一个柱状体就是柱面。
所以当我们访问一些数据,如打开一个目录,打开一个文件,计算机需要找到在磁盘中文件或目录内部存储的数据对应在磁盘的哪个盘片中,然后定位到其所在的柱面,将磁头移动到此柱面上,盘片通过马达连接主轴将其柱面旋转至磁头的位置,定位到是哪个磁头读取的数据,将数据传拷贝到内存中。
磁盘的随机访问与连续访问
两次的IO操作之间需要访问的磁盘位置是否连续,若是连续就是连续访问,若是两次IO操作的地址不是连续的磁头需要进行移动就是随机访问。连续访问的效率是比随机访问要高不少的。
mysql与磁盘交互的基本单位
mysql在计算机中也就是一个软件,其数据的交互落实到硬件上就是与磁盘的交互。只是其与一般的文件系统所进行的IO操作有些不同,以此提高与一般文件相比的数据交互效率。mysql进行IO的基本单位统一都是16KB每次。
MariaDB [(none)]> show global status like 'innodb_page_size';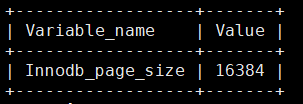
虽然这里查找的是innodb存储引擎的基本单位16*1024=16384。但是mysql的与磁盘交互的基本全部都统一的,这个基本的数据单元,在mysql中就是page(linux系统中的page是4KB)。
为了更好的进行与磁盘的交互操作,mysql在运行时会向操作系统申请一大片的内存空间在服务器内部(buffer pool) 一般默认是128M,这是可以设置的。
索引-innodb
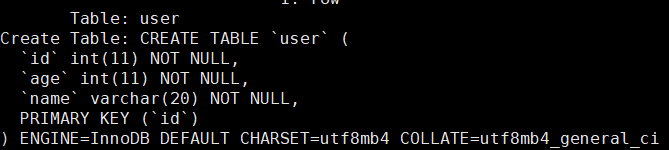
我们先创建一个带有主键的表然后不按顺序进行多条数据的插入
insert into user (id,age,name) values
-> (3, 18, '杨过'),
-> (4, 16, '小龙女'),
-> (2, 26, '黄蓉'),
-> (5, 36, '郭靖'),
-> (1, 56, '欧阳锋');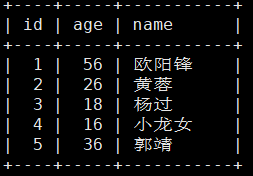
当我们查询表的数据时,会发现其是有序的,按照主键进行排序。
page
根据上文我们知道,mysql按照page为基本单位进行交互。而对数据的管理就可以理解为对page和其内部数据的管理。
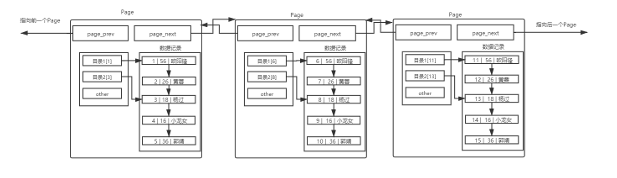
这是单个page的示意图,内部通过链表方式将每一条数据按照主键进行排序和连接,当我们查找数据时就是找到对应的page然后遍历查找数据就可以。
但是当数据量庞大的时候,若是再遍历每一个数据来查找数据其效率会变得十分低下,可能查找一个数据都需要非常久得时间。那么就需要一个方式进行更为高效得数据排查。所以在page内还有一部分空间用于存放目录信息,既然数据已经排好序了,那么我们就可以通过主键进行范围筛选。
page的管理
innodb中使用得是索引B+树进行对page的组织管理。
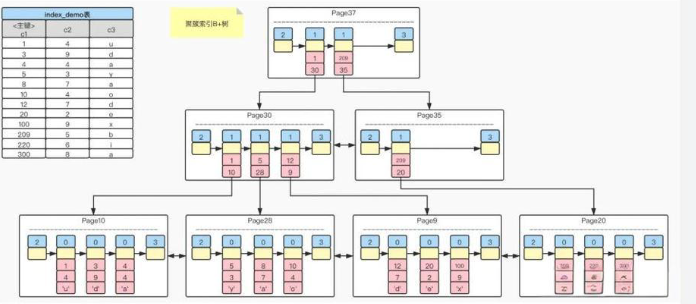
这个B+树我们可以将其理解为目录的目录,当page十分多的时候我们就可以对page也进行如同内部管理数据一样,对page也进行目录摘取。用一个page专门负责存储page中的数据存放的信息。如第一个page存放的数据的主键值为1~20,那么在目录page中我们只需要记录这个page对应的主键值的起始号和指向其的指针作为一条数据存放在目录page中,只要查找的数据的主键值不在此范围中我们一次就能过滤掉一个page,这可以大大提升效率。
目录page是不包含数据的,只有叶子节点才存放数据,这样每个目录page就能存放更多的数据page信息了。如此一来,这颗树必是一颗矮胖树,所以每次查找数据的IO次数就会很少,能大幅度提高其整体的查询效率。
而且叶子节点是相互通过链表方式进行连接。进行范围查找时,mysql只需要通过很少的IO次数,查找到起始位置和结束位置,或者根据起始位置和数据条数,进行读取链表的读取即可。这一切都是因为有按照主键进行了排序,其数据本身是有序的链表。这个主键就是作为这个表的索引从而使整体查找效率提高了多个数量级。
mysql各引擎使用的数据结构
BTREE是B+树不是B树
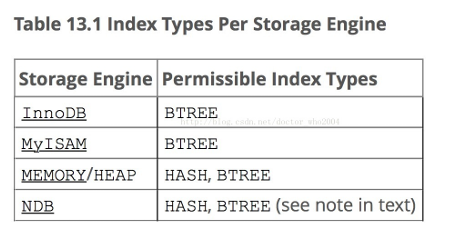
聚簇索引和非聚簇索引
上图我们看到innodb和myisam引擎用的都是b+树那么其差异就在innodb是聚簇索引,myisam是非聚簇索引。
聚簇索引:数据是直接存放在叶子节点中的,数据与树结构是一体的。
非聚簇索引:叶子节点中并不存放数据,而是存放数据的存储位置的相关信息(指针或其他索引信息),树结构与数据是分离的。

创建一个myisam引擎的表来对比一下两个的不同。
我们进入到存放mysql数据的目录
root@VM-20-3-ubuntu:/var/lib/mysql/test_db# 
.frm是表结构文件,这里两个表的结构是相同的。
.ibd是index block data的意思就是索引结构和数据这是innodb的索引文件
.MYD是my data的意思就是单独存放数据的文件
.MYI是my index的意思就是索引结构。
由此我们就能看到两个引擎的数据存放的差异也是聚簇索引和非聚簇索引的差异。
回表查询与普通索引
查询索引语句:
MariaDB [test_db]> show index from user\G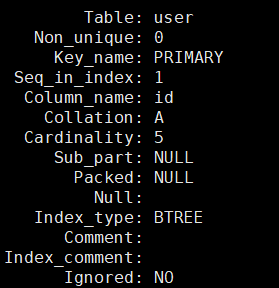
这里我们能查看一张表的全部全索引情况。虽然我们没有主动的添加索引,但是innodb会自动按照主键为我们建立索引结构如图索引名称为:PRIMARY即主键索引,索引结构是BTREE就是b+树。
一张表一定有索引的,若是没有主键mysql在建表时也会给一个值来构建索引,只是这个值我们是看不到的。但是表不一定只用一个索引
MariaDB [test_db]> alter table user add unique(age);这里我们将age更改成唯一键了。
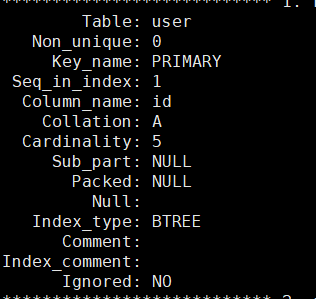
再来查看索引时我们能看到,表中是多了一个索引,索引名是:age 索引结构也是BTREE。
这是一个普通索引,若我们要为普通索引再从新做一个聚簇索引得B+树,那么再叶子节点中又会多一份数据,所以除了主键索引是聚簇索引外其余得索引都是非聚簇索引,但是跟myisam不同,叶子节点放的不是数据得地址,而是主键得值,获取到主键得值,再根据值在以主键为key得B+树中查找对应得数据。这就是回表查询。
建立索引
索引一共有四类:主键索引 ,唯一键索引, 普通索引, 全文索引四种
其中主键索引是聚簇索引在设置主键时就会自动建立索引结构
MariaDB [test_db]> alter table user drop primary key;
MariaDB [test_db]> alter table user add primary key(id);这个分别时删除主键和添加主键得语句,也可以在创建时添加主键,只要添加主键就会建立主键索引,删除主键就会删除主键索引。
唯一键索引其实就是普通索引,只是我们添加唯一键时会自动构成普通索引
MariaDB [test_db]> show keys from user\G
MariaDB [test_db]> alter table user drop index age;
MariaDB [test_db]> alter table user add unique(age);
MariaDB [test_db]> alter table user add index(name);这四条语句分别是,查询索引与show index from user\G等价,第二条是删除普通索引得索引名,第三条是添加唯一键,因为唯一键也会自动创建普通索引。第四条是给name列设置普通索引。一般不指定索引名字索引名为第一列得名字。索引是可以根据多列得值作为key值构建b+树的。
给索引重命名语句:
MariaDB [test_db]> alter table user add index myname(name);
MariaDB [test_db]> alter table user rename index myname to seconname;explain
MariaDB [test_db]> explain select * from user where id=3\Gexplain可以查看是否有使用和使用什么索引结构进行数据的查找
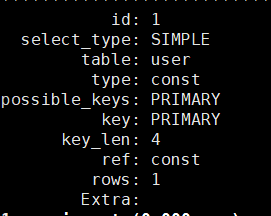
索引创建原则
比较频繁作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合作创建索引
不会出现在where子句中的字段不该创建索引