MySQL数据库
数据库--->服务器
核心功能是用来存储数据的
List、Dictionary集合----->对象是存储在内存当中,当程序停止或者服务停止时,存储在内存当中的数据就消失了,
对于一些重要的数据(用户)是需要永久保存的,数据可以存储到文件中,而文件是存储在硬盘上。
数据库本质上就是一个文件系统,首先需要先创建一个数据库(database),创建的数据库它是一个
文件夹,在数据库中创建的表它是一个文件。
MY 我的
SQL----> Struct Query Language 结构化 查询 语言
对于数据库来说,我们可以分类:
(根据数据库中存储的数据是否按照二维表行列存储),我们可以把数据库简单的分为:关系型数据
库和非关系型数据库。
MYSQL它属于关系型数据库
根据sql的功能不同,我们可以把sql大致上分为四类:
•DDL: Data Definition Language 数据定义语言,主要是用来操作数据库和表 关键字:create alter drop
•DML:Data Manipulation Language 数据操作语言,主要是用于进行对表增、删、改操作 关键字:insert delete update
•DCL:Data Control Language 数据控制语言,主要是用于对数据库的用户权限和安全级别进行设置控制。
•DQL:Data Query Language 数据查询语言,主要用于对数据库中的表进行查询操作。 select from where
Navicat中的具体操作
1.打开Navicat软件
2.选择你所对应的数据库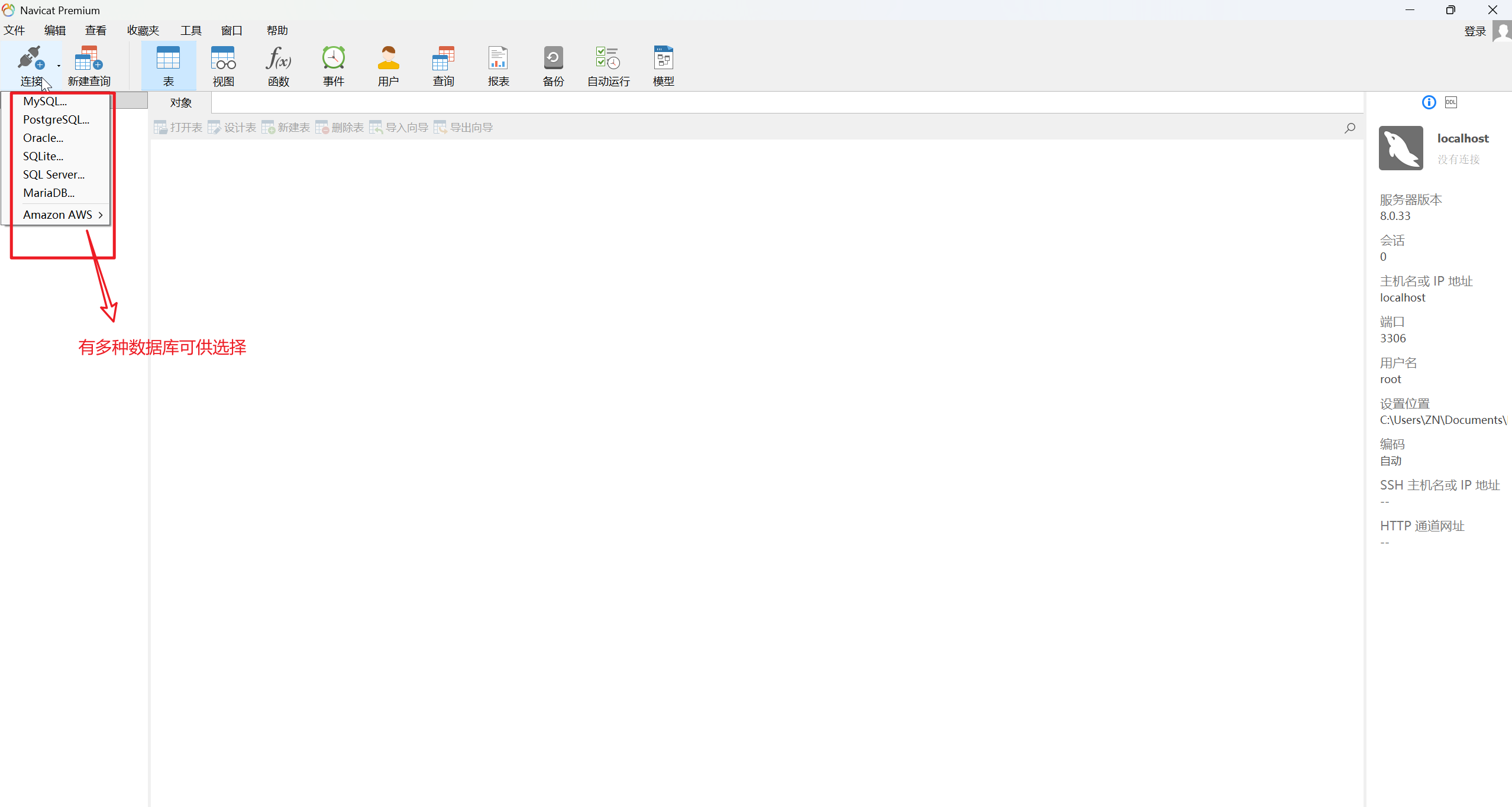
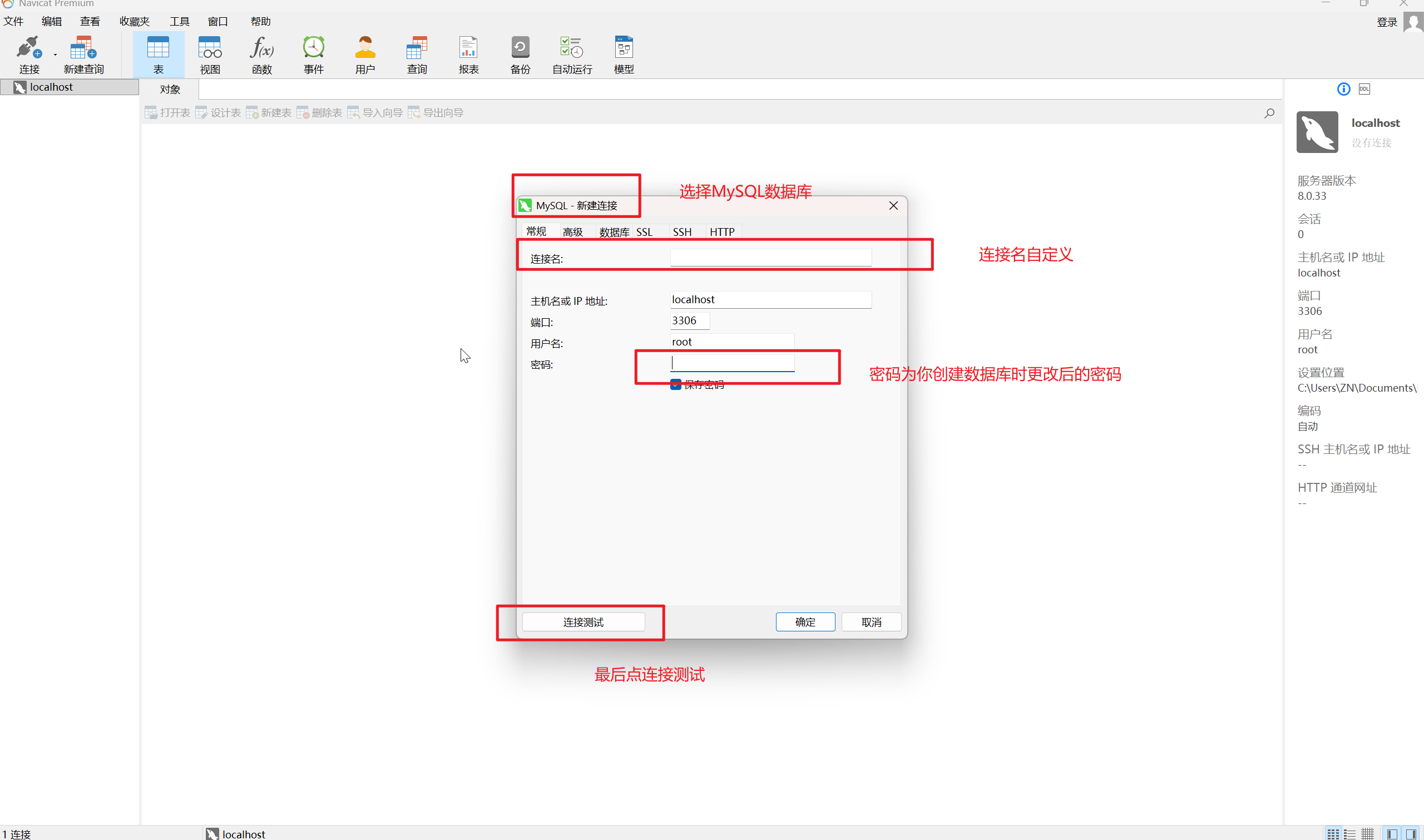
3.根据电脑和个人密码进行登录
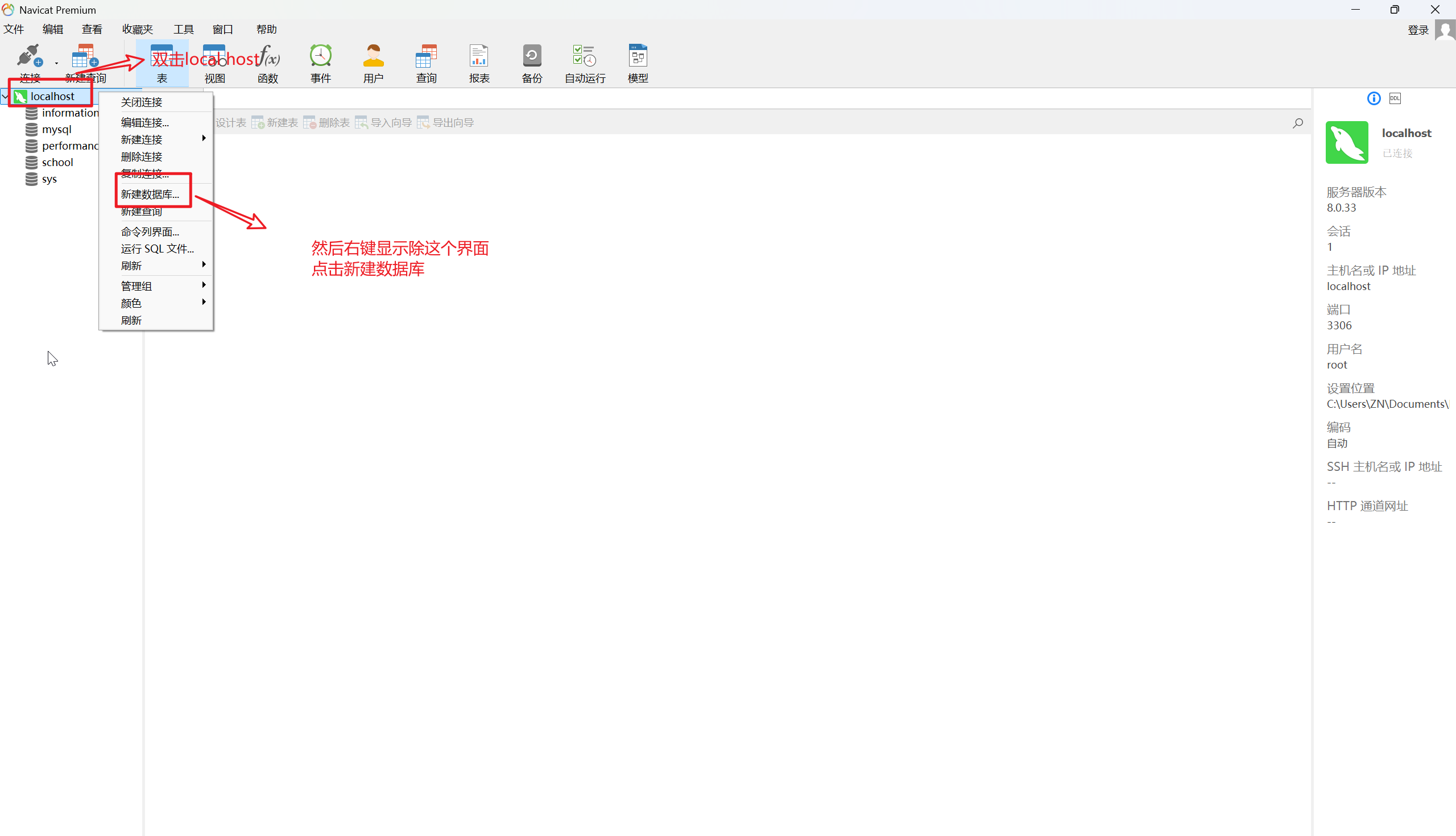
4.新建数据库
5.设定数据库名称和编码格式
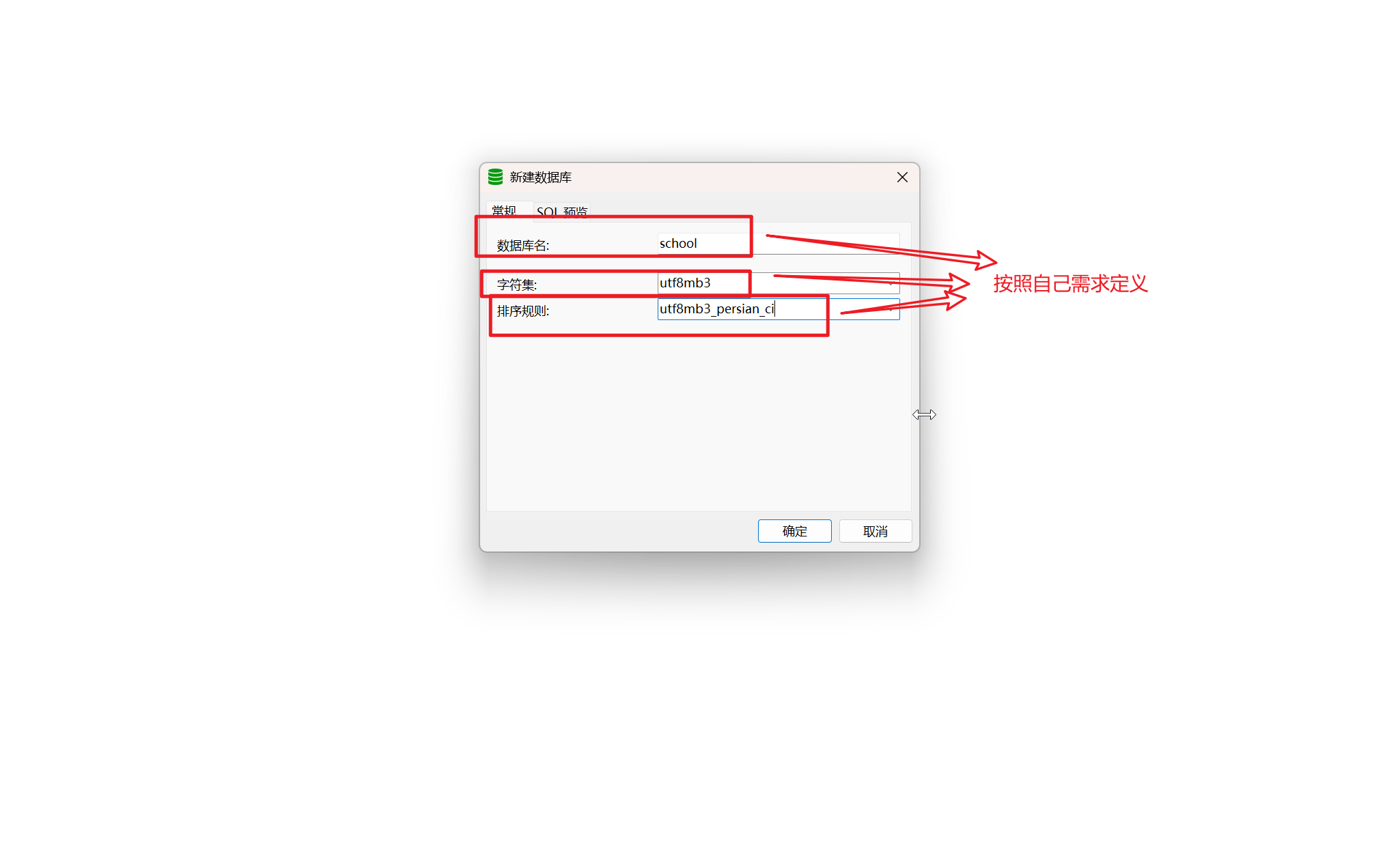
6.创建表
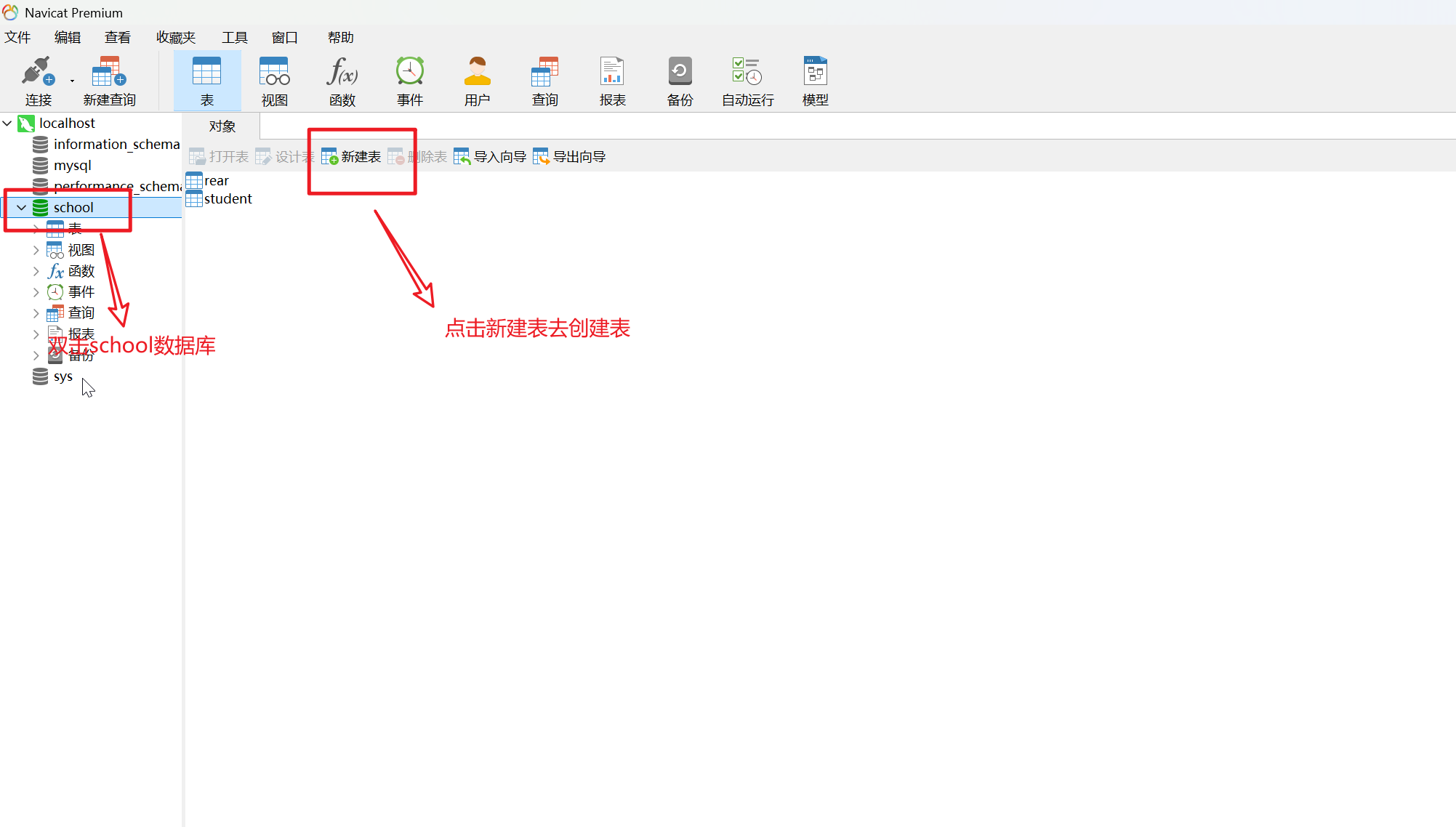
7.设置所需的字段信息
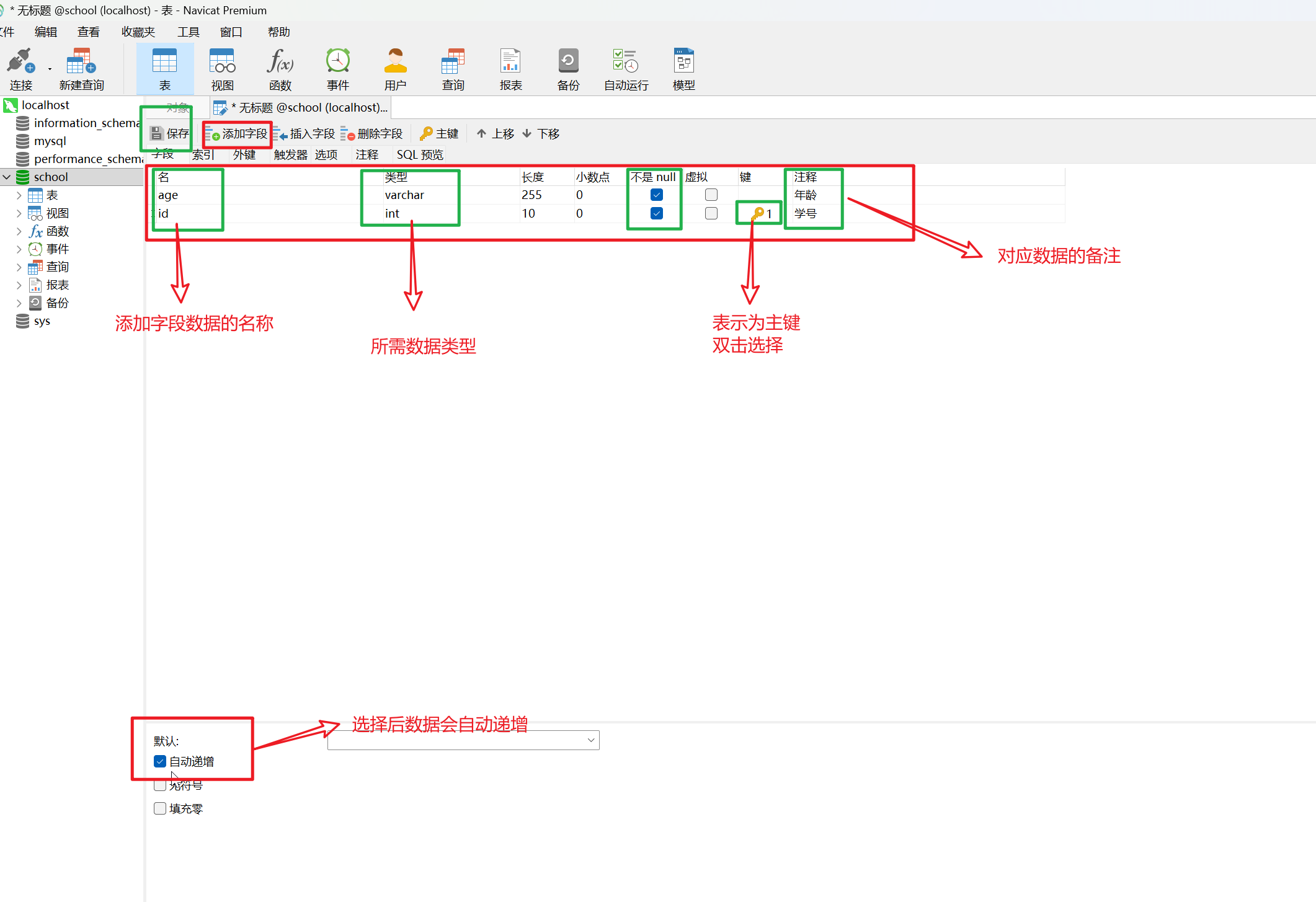
8.设置表的具体数据内容
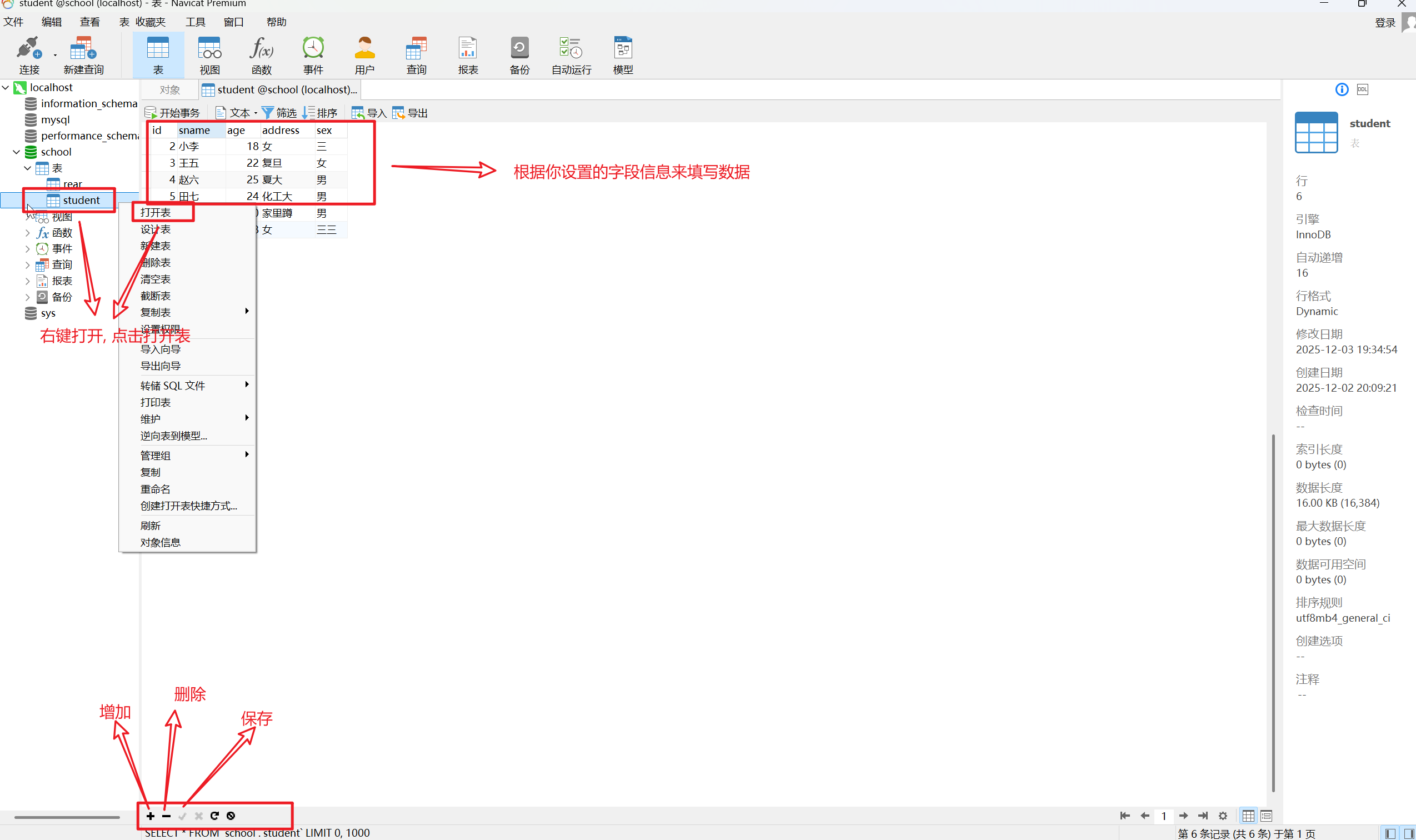
数据库操作
用户:root---超管 超级管理员
用户:admin---管理员 具有普通的权限
sql
-- ---------------数据库操作 ---------------
-- 两个短划线+空格 是Mysql的注释
-- 创建数据库 create database 数据库
-- CREATE DATABASE student;
-- 创建数据库指定编码字符集 create database 数据库名称 character set 编码字符集;
-- 查看数据库 show create database 数据库名称;
-- SHOW CREATE DATABASE student;
-- 删除数据库 drop database 数据库名称;
-- drop database student;
-- 查看当前服务器下创建的所有数据库 show databases;
-- SHOW DATABASES;
-- 使用数据库 use 数据库名称;
-- USE student;
-- 查看操作的数据库 select database();
-- SELECT DATABASE();表的操作
表中的数据类型
•整数类型:可以存储整数值,一般用int类型
•小数类型:可以存储小数值,一般用double类型
•日期类型:可以存储日期类型,一般用datetime类型
•文本二进制类型:可以存储字符串和字节数据,一般用varchar类型
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 整数类型 | tinyint | 很小的整数 |
| 整数类型 | smallint | 小的整数 |
| 整数类型 | mediumint | 中等大小的整数 |
| 整数类型 | int(integer) | 普通大小的整数 |
| 小数类型 | float | 单精度浮点数 |
| 小数类型 | double | 双精度浮点数 |
| 小数类型 | decimal (m,d) | 压缩严格的定点数,m 表示总位数,d 表示小数点几位 |
| 日期类型 | year | YYYY 1901~2155 |
| 日期类型 | time | HH:MM:SS -838:59:59~838:59:59 |
| 日期类型 | date | YYYY-MM-DD 1000-01-01~9999-12-31 |
| 日期类型 | datetime | YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~9999-12-31 23:59:59 |
| 日期类型 | timestamp | YYYY-MM-DD HH:MM:SS 1970-01-01 00:00:01 UTC~2038-01-19 03:14:07UTC |
| 文本、二进制类型 | CHAR(M) | M 为 0~255 之间的整数 |
| 文本、二进制类型 | VARCHAR(M) | M 为 0~65535 之间的整数 |
| 文本、二进制类型 | TINYBLOB | 允许长度 0~255 字节 |
| 文本、二进制类型 | BLOB | 允许长度 0~65535 字节 |
| 文本、二进制类型 | MEDIUMBLOB | 允许长度 0~167772150 字节 |
| 文本、二进制类型 | LONGBLOB | 允许长度 0~4294967295 字节 |
| 文本、二进制类型 | TINYTEXT | 允许长度 0~255 字节 |
| 文本、二进制类型 | TEXT | 允许长度 0~65535 字节 |
| 文本、二进制类型 | MEDIUMTEXT | 允许长度 0~167772150 字节 |
| 文本、二进制类型 | LONGTEXT | 允许长度 0~4294967295 字节 |
| 文本、二进制类型 | VARBINARY(M) | 允许长度 0~M 个字节的变长字节字符串 |
| 文本、二进制类型 | BINARY(M) | 允许长度 0~M 个字节的定长字节字符串 |
常用约束
约束就是对表中的数据进行操作的一种限制,一般是为了保证数据的一种安全。
-
主键约束:唯一性,非空性 添加关键字:primary key
-
唯一约束:唯一性,可以为空,但是只能有一个 添加关键字:unique
-
默认约束:给字段添加默认值,如果给表中的字段赋值时没有赋值,就会使用你自己设置的默认值赋值 添加关键字:default
-
自增长:类型一般都是整数类型,一般用于主键自动增长
-
非空约束:数据不能为空,添加关键字:not null
| 约束名称 | SQL 表示 | 说明 |
|---|---|---|
| 主键约束 | primary key | 具备唯一性、非空性 |
| 唯一约束 | unique | 具备唯一性,可空但空值只能存在一个 |
| 默认约束 | default | 字段未赋值时,自动使用预设的默认值 |
| 自增长 | auto_increment | 通常用于整数类型的主键,实现自动增长 |
| 非空约束 | not null | 字段数据不允许为空 |
sql
-- ---------------表的操作---------------
-- 主键约束:唯一性,非空性 添加关键字:primary key
-- 唯一约束:唯一性,可以为空,但是只能有一个 添加关键字:unique
-- 默认约束:给字段添加默认值,如果给表中的字段赋值时没有赋值,就会使用你自己设置的
-- 默认值赋值 添加关键字:default
-- 自增长: 类型一般都是整数类型,一般用于主键自动增长
-- 非空约束:数据不能为空,添加关键字:not null
-- 创建表
-- create table 表名(
-- 字段名 类型(长度) [约束],
-- 字段名 类型(长度) [约束],
-- 字段名 类型(长度) [约束]
-- ...
-- );
-- 使用数据库
-- USE school;
-- 创建学生表
-- CREATE TABLE student (
-- id int(15) primary key,
-- sname varchar(20),
-- age int(3),
-- address varchar(30)
-- );
-- 查看当前数据库中的表
-- show tables;
-- 查看表结构 desc 表名;
-- DESC student;
-- 删除表 drop table 表名;
-- 修改表
-- 1. 添加1列 alter table 表名 add 字段名 类型(长度)[约束];
-- ALTER TABLE student ADD sex VARCHAR(2);
-- 2. 修改列的类型(长度,类型)
-- alter table 表名 modify 要修改的字段名 类型(长度)[新约束];
-- 3. 修改列名
-- alter table 表名 change 旧列名 新列名 类型(长度)[约束];
-- 4. 删除表中的列 alter table 表名 drop 列名;
-- 5. 修改表名 rename table 旧表名 to 新表名;
-- 6. 修改表的字符集 alter table 表名 character set 编码字符集;
-- 7. 查看你当前创建的表结构 show create table 表名;
-- SHOW CREATE TABLE student;
-- 退出mysql服务 quit数据库中的记录(数据)操作
sql
-- ---------------数据库中的记录(数据)操作---------------
-- 增删改查
-- 1. 插入记录 insert
-- 第一种写法: 指定具体的插入字段值, 没有指定的不能赋值
-- INSERT INTO 表名 (字段1, 字段2, ...) VALUES (值1, 值2, ...);
-- 第二种写法: 批量插入(高效,减少IO)
-- INSERT INTO 表名 (字段1, 字段2, ...) VALUES (值1-1, 值1-2, ...), (值2-1, 值2-2, ...), ...;
-- 第三种写法: 省略字段(按表结构顺序插入,需包含所有非自增/非默认字段)
-- INSERT INTO 表名 VALUES (值1, 值2, ...);
-- 第四种写法: 插入并忽略重复(主键/唯一索引冲突时跳过)
-- INSERT IGNORE INTO 表名 (字段1, ...) VALUES (...);
-- 第五种写法: 插入或更新(主键/唯一索引冲突时更新指定字段)
-- INSERT INTO 表名 (字段1, ...) VALUES (...) ON DUPLICATE KEY UPDATE 字段1=新值1, 字段2=新值2;
-- 2. 修改表记录带有条件 update
-- update 表名 set 字段名1=值1,字段名2=值2,...where 条件;
-- 3. 删除表记录带条件 delete
-- delete from 表名 where 条件
-- 4. 删除表记录不带条件--->删除表中的所有数据
-- delete from 表名; 不会删除之前的自增序列
-- 或者
-- truncate table 表名; 会自动删除自增的序列
-- 5. 查询操作 select
-- 查询所有 select * form 表名;
-- 查询指定列信息 select 列名1,列名2,.. from 表名;
-- 查询所有信息使用表的别名 select * from 表名 as 别名;
-- 查询列信息使用列别名 select 字段名 as 别名 from 表名;
-- 查询去掉重复 select distinct(字段名) from 表名;
-- 将所有的学生的年龄+5进行显示
-- select id,snmae,age+5,address from student;条件查询
| 运算分类 | 运算符表示 | 说明 |
|---|---|---|
| 比较运算符 | >、<、>=、<=、=、!=、<>(等价于!=)、<=> | 基本数值 / 字符串比较,包含大于、小于、大于 (小于) 等于、不等于 |
| 范围运算符 | BETWEEN ... AND ...、IN(set)、NOT IN(set) | 显示在某一区间(含头含尾)或列表中的值;NOT IN 表示排除列表内的值,例:IN (100,200) |
| 模糊查询运算符 | LIKE、NOT LIKE | 模糊查询,含两个通配符:% 匹配多个字符(例:first_name like 'a%');*匹配一个字符(例:first_name like 'a_');NOT LIKE 为排除匹配结果 |
| 空值判断运算符 | IS NULL、IS NOT NULL | 判断字段是否为空;IS NULL 对应判断为空,IS NOT NULL 对应判断不为空 |
| 逻辑运算符 | and、or、not | 多条条件组合:and 为同时成立,or 为任一成立,not 为不成立(例:where not (salary>100));优先级:NOT > AND > OR |
sql
-- ---------------条件查询---------------
-- 查询学生表中地址为清华的学生信息
-- select * from stutable where address = '清华';
-- 查询年龄大于20岁的学生信息
-- select * from stutable where age > 20;
-- 查询姓名中包含"小"的学生信息 模糊查询
-- select * from stutable where sname like '%三%';
-- 或者下面写法
-- select * from stutable where username like "%" '三' "%";
-- 查询年龄在(22,24,26)范围的学生信息
-- select * from stutable where age in(22,24,26);
-- 查询年龄在(18,22)之间的所有的学生信息
-- select * from stutable where age between 18 and 22;
-- 查询学生名称带有三并且id为(6,10)之间的学生信息
-- select * from stutable where username like '%三%' and id between 6 and 10;
-- 查询id为5或者为6的学生信息
-- select * from stutable where id = 5 or id = 6;
-- 按照id进行降序排序展示
-- select * from stutable order by id desc;
-- 按照年龄进行降序排序展示 降序(DESC)
-- select * from stutable order by age desc;
-- 按照年龄进行升序排序展示 升序(ASC)
-- select * from stutable order by age asc;
-- 查询地址中带有河的并且按照年龄进行降序排序
-- select * from stutable where address like '%河%' order by age desc;聚合函数查询
sql
-- -------------聚合函数查询-----------------
-- count() 统计
-- max() 最大值
-- min() 最小值
-- sum() 求和
-- avg() 平均值
-- 查询学生表中年龄总和为多少?
-- select sum(age) as 年龄总和 from student;
-- 查询学生表中年龄的平均值为多少?
-- select avg(age) as 平均年龄 from student;
-- 查询学生表中学生的个数?
-- select count(id) as 总数量 from student;分组操作
sql
-- ---------------分组操作---------------
-- 分组操作 group by
-- 根据地址进行分组分别统计各个组人数有多少?
-- select address,count(id) as '总人数'from student GROUP BY address;
-- 根据地址字段分组,分组后统计学生的平均年龄,并且平均年龄大于20的信息
-- 分组操作不能和where连起来使用,如果分组后还需要过滤条件,需要使用having关键字添加过滤条件
-- select address,avg(age) as avgAge from student GROUP BY address having avgAge > 20分页操作
sql
-- ---------------分页操作limit---------------
-- select * from student limit a,b
-- 其中a代表的是从第几条记录开始查询,b代表的是查询多少条记录
-- 如果a是5,那么记录的条数就是从第6条开始
-- 当显示的内容小于b的时候,sql不会发生错误,会正常显示剩余所有的条数记录
-- 从第四条记录开始,查询15条记录
-- select * from student limit 3,15;多表查询
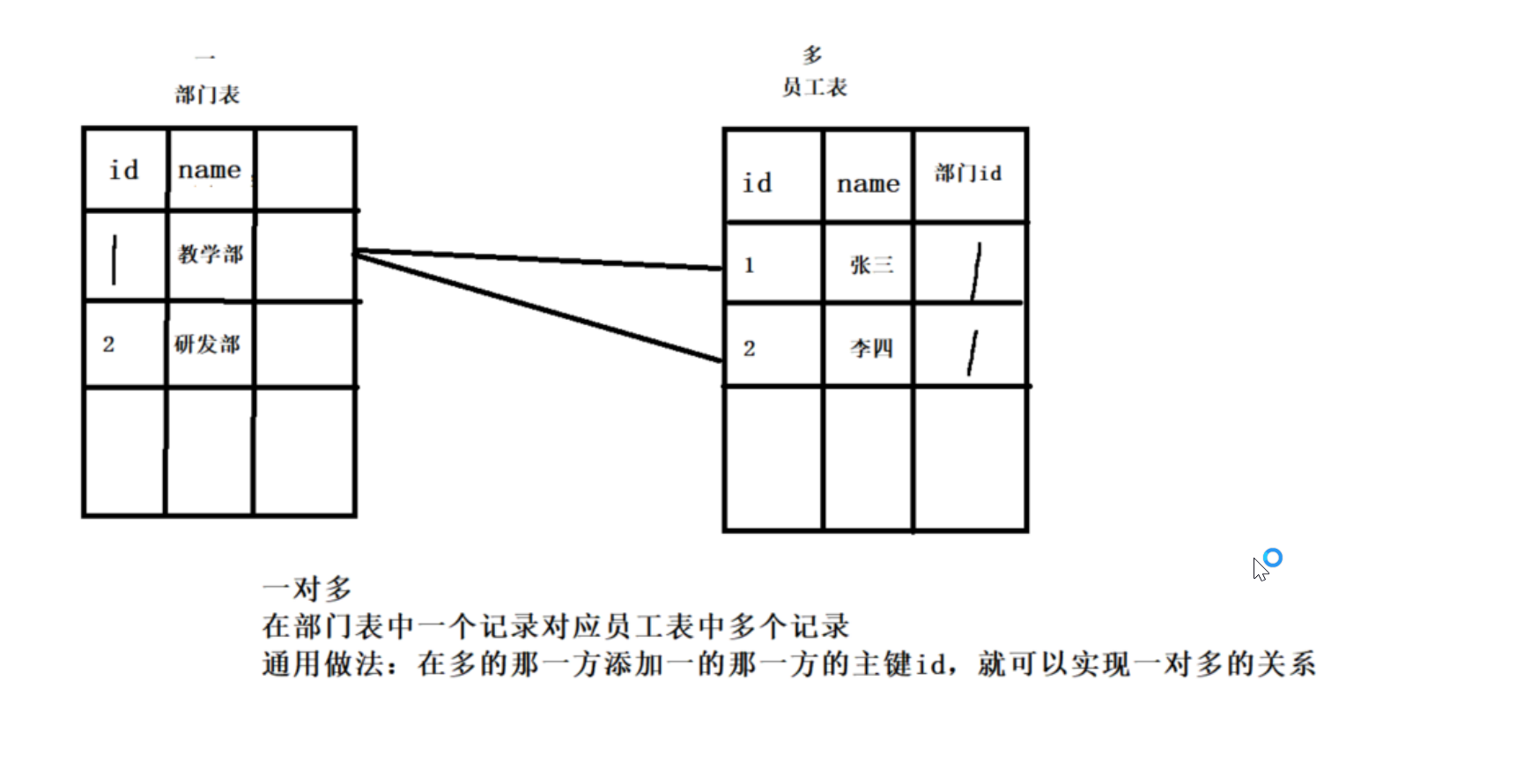
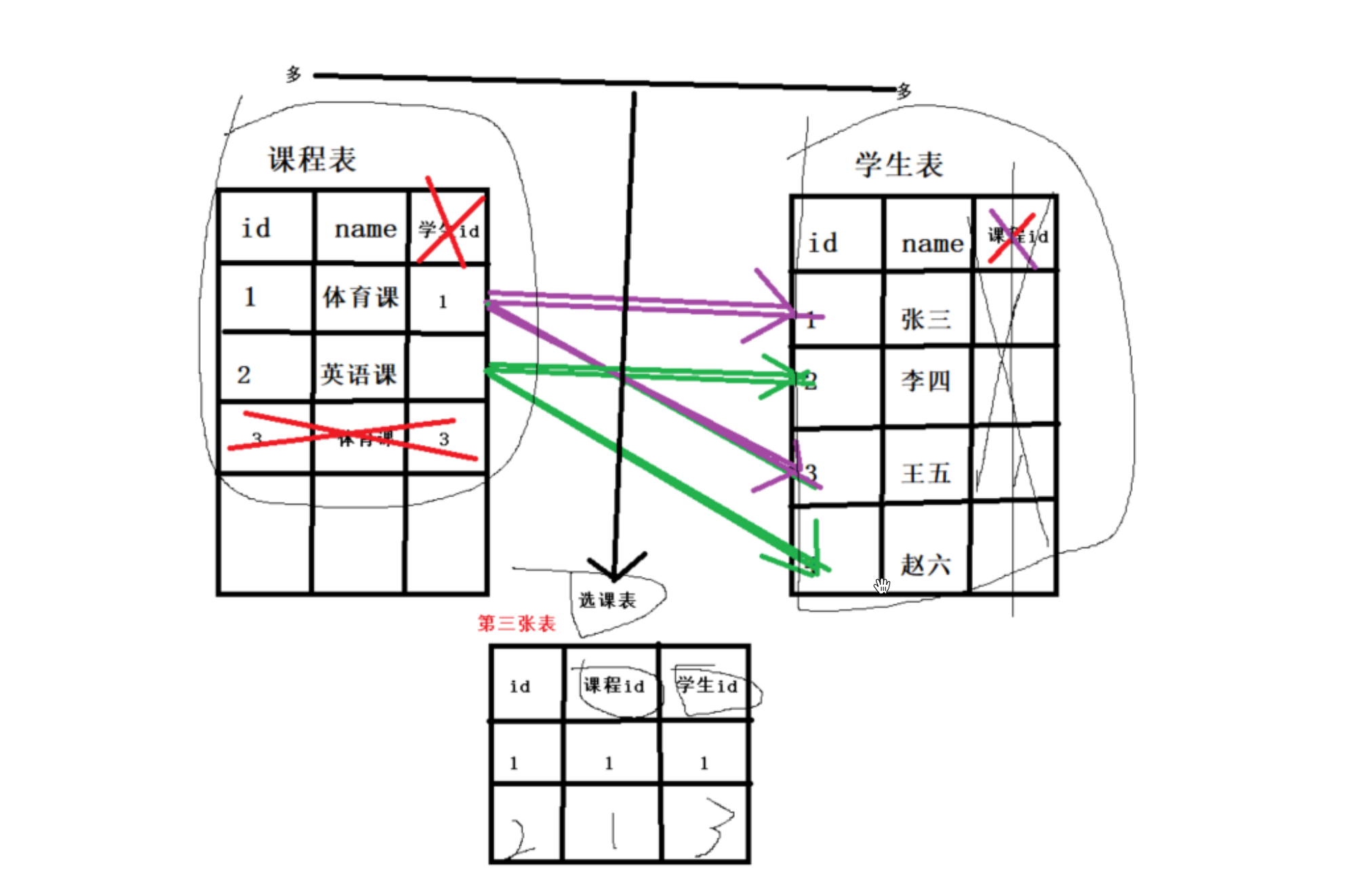
表与表关系:一对一、一对多、多对多
一对多:部门表与员工表
多对多:
sql
-- ---------------多表查询---------------
-- 多表联查操作
-- insert into department values (null,'开发部');
-- insert into department values (null,'教学部');
-- insert into department values (null,'网络部');
-- insert into department values (null,'运维部');
-- insert into department values (null,'市场部');
-- insert into staff values (null,'张三工程师',1);
-- insert into staff values (null,'李四老师',2);
-- insert into staff values (null,'王五装电脑',3);
-- insert into staff values (null,'可老师',2);
-- insert into staff values (null,'ss老师',2);
-- insert into staff values (null,'li老师',2);
-- insert into staff values (null,'lili网管',3);
-- insert into staff values (null,'lucy工程师',1);
-- insert into staff values (null,'pl',4);
-- select * from department;
-- select * from staff;
-- 1.交叉连接(基本不用) 笛卡尔积 查询出来的记录数:n*m
-- 使用关键字 cross join 可以省略为","
-- select * from staff cross join department;
-- select * from staff,department;
-- 2.内连接查询
-- 使用关键字 inner join inner可以省略不写
-- 隐式内连接
-- SELECT * FROM department d,staff s where d.id = s.did;
-- SELECT s.name 员工姓名,d.name 部门名称 FROM department d,staff s WHERE d.id =s.did;
-- 显式内连接
-- 如果使用显式内连接 后面关联条件需要用on关键字不能使用where关键字
-- SELECT * FROM department as d INNER JOIN staff as s on d.id = s.did where s.id > 3;
-- 3.外连接查询
-- 关键字是outer join outer可以省略不写,外连接要用on不能用where
-- 左外连接 以左表为主表,右表为副表 查询的时候以左表的记录为查询记录(记录总数不确定),右表的数据满足条件为数据,不满足条件显示为null
-- SELECT * FROM staff s LEFT JOIN department d on d.id = s.did;
-- 右外连接 以右表为主表,左表为副表 查询的时候以右表的记录为查询记录(记录总数不确定),左表的数据满足条件显示为数据,不满足条件显示为null
-- SELECT * FROM staff s RIGHT JOIN department d on d.id = s.did;
-- 4. 子查询方式 父子查询
-- 嵌套结构 一个查询的结果可以作为另外一个查询的条件值
-- 查询教学部中有哪些员工信息
-- 第一步:先查询部门表中教学部的id是多少
-- select id from department where name='教学部'; d_id =1 d_id = 4
-- select * from staff as s where s.d_id in (select d.d_id from department as d where d.d_name = '教学部');查询总结
● select 一般后面的内容都是要查询的字段 *----> 查询所有字段,如果查询指定字段,写上指定字段名,如果有多个字段中间用逗号隔开
● from 后面跟的是表名
● where 后面跟的是条件 id = 1 username like '% 小 %'
● group by 后面的是依据什么字段进行分组 分组统计总数
● having 分组后如果带有条件不能使用 where 只能用 having 带条件
● order by 后面跟的是依据什么字段排序 放的位置一般在 sql 语句中最后面
标量函数(单行函数)
MySQL 标量函数(Scalar Function)是对单个输入值进行操作,每行数据返回一个唯一输出值 的函数,与聚合函数(如 SUM、COUNT,多行返回一个值)完全不同。标量函数广泛用于数据转换、逻辑判断、字符串处理、日期计算等场景,是 SQL 查询中最常用的函数类型。
(一)字符串函数(最常用)
用于字符串的拼接、截取、替换、转换等操作,处理 CHAR、VARCHAR、TEXT 类型数据。
| 函数名 | 语法 | 功能描述 | 参数说明 | 示例 | 结果 |
|---|---|---|---|---|---|
CONCAT |
CONCAT(str1, str2, ..., strN) |
拼接多个字符串,遇到 NULL 则返回 NULL | str1~strN:要拼接的字符串(列名、字面量均可) |
CONCAT('Hello', ' ', 'MySQL') |
Hello MySQL |
CONCAT_WS |
CONCAT_WS(separator, str1, ..., strN) |
用分隔符拼接字符串,忽略 NULL 值 | separator:分隔符;str1~strN:要拼接的字符串 |
CONCAT_WS('-', '2025', '12', '03') |
2025-12-03 |
SUBSTRING(别名 SUBSTR) |
SUBSTRING(str, pos[, len]) |
截取字符串片段 | str:原字符串;pos:起始位置(1 开始,负数表示从末尾倒数);len:截取长度(可选,默认到末尾) |
SUBSTRING('MySQL', 2, 3)``SUBSTRING('MySQL', -3) |
ySQ``SQL |
TRIM |
TRIM([direction] remstr FROM str) |
去除字符串首尾指定字符(默认去除空格) | direction:可选(LEADING 前 /TRAILING 后 /BOTH 首尾,默认 BOTH);remstr:要去除的字符(默认空格);str:原字符串 |
TRIM(' MySQL ')``TRIM(LEADING 'x' FROM 'xxMySQLxx') |
MySQL``MySQLxx |
LENGTH |
LENGTH(str) |
返回字符串的字节数(UTF-8 下中文占 3 字节,英文占 1 字节) | str:目标字符串 |
LENGTH('MySQL')``LENGTH('中文') |
5``6 |
CHAR_LENGTH(别名 CHARLEN) |
CHAR_LENGTH(str) |
返回字符串的字符数(与编码无关,中文 / 英文均算 1 个字符) | str:目标字符串 |
CHAR_LENGTH('中文')``CHAR_LENGTH('MySQL') |
2``5 |
UPPER/LOWER |
UPPER(str) / LOWER(str) |
字符串转大写 / 小写 | str:目标字符串 |
UPPER('mysql')``LOWER('MySQL') |
MYSQL``mysql |
REPLACE |
REPLACE(str, old, new) |
将字符串中所有 old 子串替换为 new |
str:原字符串;old:要替换的子串;new:替换后的子串 |
REPLACE('MySQL', 'My', 'Your') |
YourSQL |
INSTR |
INSTR(str, substr) |
返回 substr 在 str 中首次出现的位置(1 开始,未找到返回 0) |
str:原字符串;substr:要查找的子串 |
INSTR('MySQL', 'SQL')``INSTR('MySQL', 'Oracle') |
3``0 |
LEFT/RIGHT |
LEFT(str, len) / RIGHT(str, len) |
从字符串左侧 / 右侧截取 len 个字符 |
str:原字符串;len:截取长度 |
LEFT('MySQL', 2)``RIGHT('MySQL', 3) |
My``SQL |
(二)数值函数
用于数值计算(取整、绝对值、随机数等),处理 INT、DECIMAL、FLOAT 等数值类型。
| 函数名 | 语法 | 功能描述 | 参数说明 | 示例 | 结果 |
|---|---|---|---|---|---|
ABS |
ABS(num) |
返回数值的绝对值 | num:数值(列值或字面量) |
ABS(-10.5)``ABS(20) |
10.5``20 |
ROUND |
ROUND(num[, decimals]) |
四舍五入到指定小数位(默认 0 位,即整数) | num:数值;decimals:保留小数位数(可选,负数表示整数位四舍五入) |
ROUND(3.1415, 2)``ROUND(123.45, -1) |
3.14``120 |
FLOOR |
FLOOR(num) |
向下取整(返回小于等于数值的最大整数) | num:数值 |
FLOOR(3.9)``FLOOR(-3.1) |
3``-4 |
CEIL/CEILING |
CEIL(num) |
向上取整(返回大于等于数值的最小整数) | num:数值 |
CEIL(3.1)``CEIL(-3.9) |
4``-3 |
MOD |
MOD(num1, num2) |
返回 num1 除以 num2 的余数(同 num1 % num2) |
num1:被除数;num2:除数(不能为 0) |
MOD(10, 3)``MOD(7, 2) |
1``1 |
POWER |
POWER(base, exp) |
返回 base 的 exp 次方 |
base:底数;exp:指数(可为小数) |
POWER(2, 3)``POWER(4, 0.5) |
8``2 |
SQRT |
SQRT(num) |
返回数值的平方根(num 必须非负) |
num:非负数值 |
SQRT(16)``SQRT(2) |
4``1.4142... |
RAND |
RAND([seed]) |
返回 0~1 之间的随机浮点数(带种子则生成固定序列) | seed:随机数种子(可选,整数,相同种子返回相同序列) |
RAND()``RAND(10) |
随机值固定值 |
TRUNCATE |
TRUNCATE(num, decimals) |
截断数值到指定小数位(不四舍五入) | num:数值;decimals:保留小数位数(负数表示截断整数位) |
TRUNCATE(3.1415, 2)``TRUNCATE(123.45, -1) |
3.14``120 |
(三)日期时间函数(高频使用)
用于日期 / 时间的提取、计算、格式化,处理 DATE、TIME、DATETIME、TIMESTAMP 类型。
| 函数名 | 语法 | 功能描述 | 参数说明 | 示例(当前时间:2025-12-03 10:30:00) | 结果 |
|---|---|---|---|---|---|
NOW() |
NOW() |
返回当前日期 + 时间(DATETIME 类型) |
无参数 | NOW() |
2025-12-03 10:30:00 |
CURDATE()/CURRENT_DATE() |
CURDATE() |
返回当前日期(DATE 类型) |
无参数 | CURDATE() |
2025-12-03 |
CURTIME()/CURRENT_TIME() |
CURTIME() |
返回当前时间(TIME 类型) |
无参数 | CURTIME() |
10:30:00 |
YEAR/MONTH/DAY |
YEAR(date) |
提取日期中的年 / 月 / 日(返回整数) | date:日期类型或字符串(需符合日期格式) |
YEAR(NOW())``MONTH(CURDATE()) |
2025``12 |
HOUR/MINUTE/SECOND |
HOUR(time) |
提取时间中的时 / 分 / 秒(返回整数) | time:时间类型或字符串(需符合时间格式) |
HOUR(CURTIME())``MINUTE(NOW()) |
10``30 |
DATE_ADD |
DATE_ADD(date, INTERVAL expr unit) |
给日期 / 时间添加指定时间间隔 | date:基准日期 / 时间;expr:数值;unit:单位(DAY/HOUR/MINUTE等) |
DATE_ADD(NOW(), INTERVAL 7 DAY) |
2025-12-10 10:30:00 |
DATE_SUB |
DATE_SUB(date, INTERVAL expr unit) |
给日期 / 时间减去指定时间间隔 | 同 DATE_ADD |
DATE_SUB(NOW(), INTERVAL 1 HOUR) |
2025-12-03 09:30:00 |
DATEDIFF |
DATEDIFF(date1, date2) |
返回 date1 - date2 的天数差(仅计算日期,忽略时间) |
date1/date2:日期类型或字符串 |
DATEDIFF('2025-12-10', '2025-12-03') |
7 |
TIMESTAMPDIFF |
TIMESTAMPDIFF(unit, start, end) |
返回 end - start 的时间差(支持多单位,如年、月、小时) |
unit:单位(YEAR/MONTH/HOUR等);start/end:起始 / 结束时间 |
TIMESTAMPDIFF(MONTH, '2024-01-01', NOW()) |
23 |
STR_TO_DATE |
STR_TO_DATE(str, format) |
将字符串按指定格式转为日期 / 时间(格式不匹配返回 NULL) | str:待转换字符串;format:格式符(如下表) |
STR_TO_DATE('2025-12-03', '%Y-%m-%d') |
2025-12-03 |
DATE_FORMAT |
DATE_FORMAT(date, format) |
将日期 / 时间按指定格式转为字符串 | 同 STR_TO_DATE 的 format |
DATE_FORMAT(NOW(), '%Y年%m月%d日 %H时%i分') |
2025年12月03日 10时30分 |
日期格式符(常用)
| 格式符 | 含义 | 示例 |
|---|---|---|
%Y |
4 位年份 | 2025 |
%y |
2 位年份 | 25 |
%m |
2 位月份(01-12) | 12 |
%d |
2 位日期(01-31) | 03 |
%H |
24 小时制(00-23) | 10 |
%h |
12 小时制(01-12) | 10 |
%i |
2 位分钟(00-59) | 30 |
%s |
2 位秒(00-59) | 00 |
(四)转换函数
用于不同数据类型之间的转换,核心是 CAST 和 CONVERT(功能基本一致,语法略有差异)。
| 函数名 | 语法 | 功能描述 | 支持的目标类型 | 示例 | 结果 |
|---|---|---|---|---|---|
CAST |
CAST(expr AS type) |
将表达式转为指定类型 | CHAR、DATE、DATETIME、DECIMAL(n,m)、INT、FLOAT 等 |
CAST(123 AS CHAR)``CAST('2025-12-03' AS DATE) |
'123'``2025-12-03 |
CONVERT |
CONVERT(expr, type) 或 CONVERT(expr USING charset) |
类型转换或字符集转换 | 同 CAST;USING charset 用于字符集转换(如 utf8mb4) |
CONVERT('123.45', DECIMAL(5,2))``CONVERT('中文' USING utf8mb4) |
123.45``'中文'(utf8mb4 编码) |
注意:
-
转换失败返回
NULL(如CAST('abc' AS INT)→NULL); -
DECIMAL(n,m)中n是总位数,m是小数位数(如DECIMAL(5,2)支持 123.45)。
(五)条件函数(逻辑判断)
用于基于条件返回不同结果,核心是 IF、IFNULL、NULLIF、CASE WHEN。
| 函数名 | 语法 | 功能描述 | 示例(表 users 含 age、status 列) |
结果 |
|---|---|---|---|---|
IF |
IF(condition, true_val, false_val) |
条件成立返回 true_val,否则返回 false_val(支持嵌套) |
IF(age > 18, '成年', '未成年')``IF(age > 60, '老年', IF(age > 18, '成年', '未成年')) |
按年龄返回对应标签 |
IFNULL |
IFNULL(expr1, expr2) |
若 expr1 是 NULL,返回 expr2;否则返回 expr1(处理 NULL 缺省值) |
IFNULL(phone, '未填写')(phone 为 NULL 时返回未填写) |
非 NULL 则返回原值,否则返回缺省值 |
NULLIF |
NULLIF(expr1, expr2) |
若 expr1 = expr2,返回 NULL;否则返回 expr1(用于过滤特定值) |
NULLIF(username, 'admin')(用户名是 admin 时返回 NULL) |
相等返回 NULL,否则返回 expr1 |
CASE WHEN |
简单形式:CASE expr WHEN val1 THEN res1 [WHEN val2 THEN res2] ELSE resN END搜索形式:CASE WHEN cond1 THEN res1 [WHEN cond2 THEN res2] ELSE resN END |
多条件判断(搜索形式更灵活,支持复杂条件) | 简单形式:CASE status WHEN 1 THEN '正常' WHEN 0 THEN '禁用' ELSE '未知' END搜索形式:CASE WHEN score >= 90 THEN 'A' WHEN score >= 80 THEN 'B' ELSE 'C' END |
按条件返回对应结果 |
重点:
-
CASE WHEN是标准 SQL 语法,兼容性更好,优先用于复杂条件; -
所有条件函数的返回值类型需一致(如避免同时返回字符串和数值)。
(六)系统函数(获取系统信息)
用于获取 MySQL 系统信息或会话状态。
| 函数名 | 语法 | 功能描述 | 示例 | 结果 |
|---|---|---|---|---|
USER() |
USER() |
返回当前登录用户(格式 用户@主机) |
USER() |
root@localhost |
DATABASE() |
DATABASE() |
返回当前使用的数据库 | DATABASE() |
test(当前库名) |
VERSION() |
VERSION() |
返回 MySQL 版本号 | VERSION() |
8.0.36(版本示例) |
LAST_INSERT_ID() |
LAST_INSERT_ID() |
返回当前会话最后插入的自增 ID(仅对 AUTO_INCREMENT 列有效) |
INSERT INTO users(username) VALUES('test'); SELECT LAST_INSERT_ID(); |
插入记录的自增 ID |
(七)其他常用标量函数
| 函数名 | 语法 | 功能描述 | 示例 | 结果 |
|---|---|---|---|---|
MD5 |
MD5(str) |
对字符串进行 MD5 加密(32 位小写) | MD5('123456') |
e10adc3949ba59abbe56e057f20f883e |
SHA1 |
SHA1(str) |
对字符串进行 SHA1 加密(40 位) | SHA1('123456') |
7c4a8d09ca3762af61e59520943dc26494f8941b |
UUID() |
UUID() |
生成全球唯一标识符(36 位字符串) | UUID() |
550e8400-e29b-41d4-a716-446655440000 |
ISNULL |
ISNULL(expr) |
判断表达式是否为 NULL(返回 1/0) | ISNULL(NULL)``ISNULL('test') |
1``0 |
标量函数使用注意事项
-
区分标量函数与聚合函数 :标量函数每行返回一个值(如
UPPER(username)),聚合函数多行返回一个值(如COUNT(*)),不可混用(如SUM(UPPER(username))报错)。 -
NULL 值处理:
-
CONCAT、+等遇到 NULL 返回 NULL; -
CONCAT_WS、IFNULL可忽略或替换 NULL,需根据需求选择。
-
-
字符串长度函数选择:
-
统计字符个数用
CHAR_LENGTH(如中文计数); -
统计存储字节数用
LENGTH(如判断字段存储是否超限)。
-
-
日期函数格式符 :
%Y(4 位年)和%y(2 位年)、%H(24 小时制)和%h(12 小时制)不可混用,否则导致转换失败。 -
性能优化:
-
避免在 WHERE 子句中对索引列使用标量函数(如
WHERE UPPER(username) = 'TEST'会导致索引失效); -
复杂嵌套函数(如多层
DATE_FORMAT+DATE_ADD)在大数据量下会影响性能,尽量简化或在应用层处理。
-
-
函数嵌套 :支持多层嵌套,如
DATE_FORMAT(DATE_ADD(NOW(), INTERVAL 1 DAY), '%Y-%m-%d')(获取明天日期并格式化)。
希望本文章对大家有所帮助, 感谢大家的关注和点赞。