(Gemini 3pro曾多次吐槽书上的代码有年代感)
本文的代码基本都是采用能简则简的形式。图的那几个算法的代码均使用 java.util 而非手搓队列(过于繁琐且没必要)。
目录
- 知识点详解(上)
- 知识点详解(下)
-
- [5. 图](#5. 图)
-
- [5.1 图的定义(包括完全图、连通图、简单路径、有向图、无向图、无环图等)及图与二叉树、树和森林的结构异同点](#5.1 图的定义(包括完全图、连通图、简单路径、有向图、无向图、无环图等)及图与二叉树、树和森林的结构异同点)
-
- [5.1.1 图的基本概念与分类](#5.1.1 图的基本概念与分类)
- [5.1.2 路径、回路与特殊结构](#5.1.2 路径、回路与特殊结构)
- [5.1.3 连通性相关定义](#5.1.3 连通性相关定义)
- [5.1.4 顶点的度 (Degree)](#5.1.4 顶点的度 (Degree))
- [5.1.5 图与二叉树、树、森林的异同点](#5.1.5 图与二叉树、树、森林的异同点)
- [5.2 图采用相邻矩阵和邻接表进行存储的差异性](#5.2 图采用相邻矩阵和邻接表进行存储的差异性)
-
- [5.2.1 邻接矩阵 (Adjacency Matrix)](#5.2.1 邻接矩阵 (Adjacency Matrix))
- [5.2.2 邻接表 (Adjacency List)](#5.2.2 邻接表 (Adjacency List))
- [5.3 图的广度优先遍历和深度优先遍历](#5.3 图的广度优先遍历和深度优先遍历)
-
- [5.3.1 深度优先遍历 (DFS - Depth First Search)](#5.3.1 深度优先遍历 (DFS - Depth First Search))
- [5.3.2 广度优先遍历 (BFS - Breadth First Search)](#5.3.2 广度优先遍历 (BFS - Breadth First Search))
- [5.3.3 代码实现](#5.3.3 代码实现)
- [5.4 最小支撑树(Prim算法、Kruskal算法)、最短路径(Dijkstra算法)及拓扑排序的实现过程](#5.4 最小支撑树(Prim算法、Kruskal算法)、最短路径(Dijkstra算法)及拓扑排序的实现过程)
-
- [5.4.1 最小支撑树(最小生成树)](#5.4.1 最小支撑树(最小生成树))
- [5.4.2 最短路 dijkstra](#5.4.2 最短路 dijkstra)
- [5.4.3 拓扑排序](#5.4.3 拓扑排序)
- [6. 查找](#6. 查找)
-
- [6.1 查找的定义](#6.1 查找的定义)
- [6.2 查找算法的衡量指标(平均查找长度、成功查找的查找长度、不成功查找的查找长度)](#6.2 查找算法的衡量指标(平均查找长度、成功查找的查找长度、不成功查找的查找长度))
- [6.3 顺序查找法和折半查找法的实现及二者之间的异同点](#6.3 顺序查找法和折半查找法的实现及二者之间的异同点)
-
- [6.3.1 顺序查找法](#6.3.1 顺序查找法)
- [6.3.2 折半查找法](#6.3.2 折半查找法)
- [6.3.3 二者异同点](#6.3.3 二者异同点)
- [6.4 散列技术(散列函数、散列表、散列冲突的发生及其解决方法、负载因子)](#6.4 散列技术(散列函数、散列表、散列冲突的发生及其解决方法、负载因子))
-
- [6.4.1 散列表 (Hash Table)](#6.4.1 散列表 (Hash Table))
- [6.4.2 散列函数 (Hash Function)](#6.4.2 散列函数 (Hash Function))
- [6.4.3 散列冲突 (Hash Collision)](#6.4.3 散列冲突 (Hash Collision))
- [6.4.4 散列冲突的解决方法](#6.4.4 散列冲突的解决方法)
- [6.4.5 负载因子 (Load Factor)](#6.4.5 负载因子 (Load Factor))
- [6.4.6 平均查找长度 ASL (Average Search Length)](#6.4.6 平均查找长度 ASL (Average Search Length))
- [6.4.7 散列代码实现](#6.4.7 散列代码实现)
- [7. 排序](#7. 排序)
-
- [7.1 排序的稳定性](#7.1 排序的稳定性)
- [7.2 各类排序算法的排序过程、排序特点及时间复杂度、空间复杂度、稳定性等特性](#7.2 各类排序算法的排序过程、排序特点及时间复杂度、空间复杂度、稳定性等特性)
-
- [7.2.1 直接插入排序 (Insertion Sort)](#7.2.1 直接插入排序 (Insertion Sort))
- [7.2.2 冒泡排序 (Bubble Sort)](#7.2.2 冒泡排序 (Bubble Sort))
- [7.2.3 简单选择排序 (Selection Sort)](#7.2.3 简单选择排序 (Selection Sort))
- [7.2.4 快速排序 (Quick Sort)](#7.2.4 快速排序 (Quick Sort))
- [7.2.5 堆排序 (Heap Sort)](#7.2.5 堆排序 (Heap Sort))
- [7.2.6 归并排序 (Merge Sort)](#7.2.6 归并排序 (Merge Sort))
- [7.2.7 基数排序 (Radix Sort)](#7.2.7 基数排序 (Radix Sort))
- [7.2.8 希尔排序 (Shell Sort)(考纲没有)](#7.2.8 希尔排序 (Shell Sort)(考纲没有))
- [7.3 根据不同应用需求选择合适排序算法](#7.3 根据不同应用需求选择合适排序算法)
- 题型(待更新)
- 22年真题回忆版(待答)
知识点详解(上)
知识点详解(下)
5. 图
5.1 图的定义(包括完全图、连通图、简单路径、有向图、无向图、无环图等)及图与二叉树、树和森林的结构异同点
5.1.1 图的基本概念与分类
图(Graph)是由顶点的非空有限集合 V V V 和顶点之间边的集合 E E E 组成的数据结构,通常表示为 G = ( V , E ) G = (V, E) G=(V,E)。
- 有向图 (Directed Graph)
- 边是有方向的,称为弧。
- 表示为尖括号 < v , w > <v, w> <v,w>,其中 v v v 为弧尾(起点), w w w 为弧头(终点)。
- < v , w > ≠ < w , v > <v, w> \neq <w, v> <v,w>=<w,v>。
- 无向图 (Undirected Graph)
- 边没有方向。
- 表示为圆括号 ( v , w ) (v, w) (v,w)。
- ( v , w ) = ( w , v ) (v, w) = (w, v) (v,w)=(w,v)。
- 完全图 (Complete Graph)
- 无向完全图 :任意两个顶点之间都存在一条边。若有 n n n 个顶点,则边数为 n ( n − 1 ) / 2 n(n-1)/2 n(n−1)/2。
- 有向完全图 :任意两个顶点之间都存在方向互为相反的两条弧。若有 n n n 个顶点,则弧数为 n ( n − 1 ) n(n-1) n(n−1)。
- 稀疏图与稠密图
- 边数很少(如 e < n log n e < n \log n e<nlogn)称为稀疏图,反之称为稠密图。
5.1.2 路径、回路与特殊结构
- 路径 (Path)
- 顶点序列 v 1 , v 2 , . . . , v k v_1, v_2, ..., v_k v1,v2,...,vk,其中相邻顶点之间存在边/弧。
- 简单路径 (Simple Path)
- 序列中顶点不重复出现的路径。
- 回路/环 (Cycle)
- 第一个顶点和最后一个顶点相同的路径。
- 简单回路:除起点和终点外,其余顶点不重复的回路。
- 无环图 (Acyclic Graph)
- 不存在环的图。
- DAG (Directed Acyclic Graph):有向无环图,常用于描述工程进度、依赖关系(拓扑排序)。
5.1.3 连通性相关定义
- 连通图 (Connected Graph)
- 无向图:若图中任意两个顶点都是连通的(有路径可达),则称该图为连通图。
- 连通分量:无向图中的极大连通子图。
- 强连通图 (Strongly Connected Graph)
- 有向图 :若任意两个顶点 v i v_i vi 和 v j v_j vj 之间都存在双向路径(从 v i v_i vi 到 v j v_j vj 以及从 v j v_j vj 到 v i v_i vi),则称该图为强连通图。
- 强连通分量:有向图中的极大强连通子图。
5.1.4 顶点的度 (Degree)
- 无向图的度 :TD(v) = 依附于顶点 v v v 的边数。总度数 = 边数的2倍。
- 有向图的度 :
- 入度 (ID) :以顶点 v v v 为终点的弧的数目。
- 出度 (OD) :以顶点 v v v 为起点的弧的数目。
- 度 (TD) : T D ( v ) = I D ( v ) + O D ( v ) TD(v) = ID(v) + OD(v) TD(v)=ID(v)+OD(v)。有向图的弧数 = 所有顶点的入度之和 = 所有顶点的出度之和。
5.1.5 图与二叉树、树、森林的异同点
| 比较维度 | 图 (Graph) | 树 (Tree) | 森林 (Forest) | 二叉树 (Binary Tree) |
|---|---|---|---|---|
| 定义核心 | 多对多关系 | 一对多关系 | m棵互不相交的树 | 特殊的一对多(有序) |
| 父子关系 | 无父子概念,只有邻接关系 | 有明确的父子层次关系 | 有明确的父子层次关系 | 有明确的父子层次关系 |
| 根结点 | 通常无根(除非人为指定) | 有且仅有一个根结点 | 有 m 个根结点 | 有且仅有一个根结点 |
| 回路/环 | 可以有环 | 绝对无环 | 绝对无环 | 绝对无环 |
| 连通性 | 可能连通,也可能不连通 | 必须连通 | 由多个连通分量组成 | 必须连通 |
| 边数限制 (n个顶点) | 0 ≤ e ≤ n ( n − 1 ) 0 \le e \le n(n-1) 0≤e≤n(n−1) | 恰好 n-1 条边 | n − m n - m n−m 条边 | 恰好 n-1 条边 |
| 孩子有序性 | 无序 | 无序(普通树) | 无序 | 有序(左右孩子严格区分) |
| 结构包含关系 | 最通用的结构,包含树和森林 | 是特殊的图(连通且无环) | 是特殊的图(无环,非连通) | 特殊的树形结构 |
5.2 图采用相邻矩阵和邻接表进行存储的差异性
5.2.1 邻接矩阵 (Adjacency Matrix)
- 定义 :用一个二维数组
A[n][n]存储图,其中n是顶点数。- 若 ( v i , v j ) ∈ E (v_i, v_j) \in E (vi,vj)∈E,则
A[i][j] = 1(或权值)。 - 否则
A[i][j] = 0(或 ∞ \infty ∞)。
- 若 ( v i , v j ) ∈ E (v_i, v_j) \in E (vi,vj)∈E,则
- 特点 :
- 无向图:矩阵关于主对角线对称,存储时可压缩为上/下三角矩阵。
- 有向图:不一定对称。行和 = 出度,列和 = 入度。
- 空间复杂度 : O ( n 2 ) O(n^2) O(n2)。
- 空间只与顶点数有关,与边数无关。
- 适用场景 :稠密图 (边数接近 n 2 n^2 n2),或需要快速判断两点间是否有边的场景。
java
public class AdjacencyMatrix {
private int n; // 顶点数
private int[][] graph; // 邻接矩阵
// 初始化:n个顶点,初始无边
public AdjacencyMatrix(int n) {
this.n = n;
graph = new int[n][n]; // 默认值0(无边)
}
// 添加边:无向图(i→j 和 j→i 都设为1),有向图只需保留一行
public void addEdge(int i, int j) {
if (i >= 0 && i < n && j >= 0 && j < n) { // 避免数组越界
graph[i][j] = 1;
graph[j][i] = 1; // 无向图关键:双向边
}
}
// 打印邻接矩阵(直观查看存图结果)
public void print() {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
System.out.print(graph[i][j] + " ");
}
System.out.println();
}
}
// 测试:3个顶点(0,1,2),边0-1、1-2、0-2
public static void main(String[] args) {
AdjacencyMatrix am = new AdjacencyMatrix(3);
am.addEdge(0, 1);
am.addEdge(1, 2);
am.addEdge(0, 2);
System.out.println("邻接矩阵(3顶点无向图):");
am.print();
}
}5.2.2 邻接表 (Adjacency List)
- 定义 :数组 + 链表的结合体。
- 一个数组
adj[n]存储所有顶点。 - 每个数组元素
adj[i]指向一个单链表,链表中存储所有与顶点 v i v_i vi 邻接的顶点。
- 一个数组
- 特点 :
- 无向图 :每条边 ( v i , v j ) (v_i, v_j) (vi,vj) 在链表中出现两次(分别在 i i i 的链表和 j j j 的链表中)。
- 有向图 :
- 邻接表(出边表):存储出度边。便于求出度,难求入度。
- 逆邻接表(入边表):存储入度边。便于求入度,难求出度。
- 空间复杂度 :
- 有向图: O ( n + e ) O(n + e) O(n+e)。
- 无向图: O ( n + 2 e ) O(n + 2e) O(n+2e)。
- 适用场景 :稀疏图 (边数远小于 n 2 n^2 n2),或需要频繁遍历邻接点的场景。
ArrayList[] 的实现
java
import java.util.ArrayList;
public class AdjacencyListArray {
private int n; // 顶点数
private ArrayList<Integer>[] adj; // 核心存储:数组元素是ArrayList(邻接顶点列表)
// 初始化:n个顶点,给每个顶点创建空的邻接列表
@SuppressWarnings("unchecked") // 抑制泛型数组的编译警告(Java语法兼容)
public AdjacencyListArray(int n) {
this.n = n;
// 1. 创建数组:长度为n,每个元素是ArrayList<Integer>类型
adj = new ArrayList[n];
// 2. 给每个顶点初始化邻接列表(必须手动创建,否则会空指针)
for (int i = 0; i < n; i++) {
adj[i] = new ArrayList<>();
}
}
// 添加边(无向图:i和j互相添加为邻接顶点)
public void addEdge(int i, int j) {
// 校验顶点合法性(避免数组越界)
if (i >= 0 && i < n && j >= 0 && j < n && i != j) {
adj[i].add(j); // 数组索引i直接访问,调用add()添加邻接顶点(终于能这么写了!)
adj[j].add(i); // 无向图双向添加
}
}
// 打印邻接表(直观查看结果)
public void print() {
for (int i = 0; i < n; i++) {
System.out.print("顶点" + i + "的邻接顶点:");
// 遍历顶点i的邻接列表(adj[i]直接获取,无需.get())
for (int neighbor : adj[i]) {
System.out.print(neighbor + " ");
}
System.out.println();
}
}
// 测试:和之前相同的图(3顶点,边0-1、1-2、0-2)
public static void main(String[] args) {
AdjacencyListArray al = new AdjacencyListArray(3);
al.addEdge(0, 1);
al.addEdge(1, 2);
al.addEdge(0, 2);
System.out.println("ArrayList[] 实现的邻接表:");
al.print();
}
}提供一个带权图邻接表的实现:
java
import java.util.ArrayList;
// 自定义Edge类:存储「邻接顶点编号」和「边的权重」
class Edge {
int to; // 邻接顶点编号(比如顶点i指向的顶点)
int weight; // 边的权重(i到to的边的权重)
// Edge构造器:初始化邻接顶点和权重
public Edge(int to, int weight) {
this.to = to;
this.weight = weight;
}
}
public class WeightedAdjacencyList {
private int n; // 顶点数
// 核心存储:数组元素是ArrayList<Edge>,每个元素存对应顶点的所有(邻接顶点+权重)
private ArrayList<Edge>[] adj;
// 初始化:n个顶点,给每个顶点创建空的邻接列表(存储Edge对象)
@SuppressWarnings("unchecked")
public WeightedAdjacencyList(int n) {
this.n = n;
adj = new ArrayList[n]; // 创建数组,长度=顶点数
// 给每个顶点初始化邻接列表(必须手动创建,避免空指针)
for (int i = 0; i < n; i++) {
adj[i] = new ArrayList<>();
}
}
// 添加加权边(无向图:i→j和j→i的边权重相同,双向添加)
public void addEdge(int from, int to, int weight) {
// 校验顶点合法性(避免越界)
if (from >= 0 && from < n && to >= 0 && to < n && from != to) {
adj[from].add(new Edge(to, weight)); // from的邻接列表添加(to+权重)
adj[to].add(new Edge(from, weight)); // to的邻接列表添加(from+权重)
}
}
// 打印加权邻接表(直观查看顶点→邻接顶点+权重)
public void print() {
for (int i = 0; i < n; i++) {
System.out.print("顶点" + i + "的邻接边(顶点-权重):");
// 遍历顶点i的所有邻接边(每个元素是Edge对象)
for (Edge edge : adj[i]) {
System.out.print("(" + edge.to + "-" + edge.weight + ") ");
}
System.out.println();
}
}
// 测试:3个顶点,加权边0-1(权重5)、1-2(权重3)、0-2(权重7)
public static void main(String[] args) {
WeightedAdjacencyList wal = new WeightedAdjacencyList(3);
wal.addEdge(0, 1, 5); // 顶点0和1之间的边,权重5
wal.addEdge(1, 2, 3); // 顶点1和2之间的边,权重3
wal.addEdge(0, 2, 7); // 顶点0和2之间的边,权重7
System.out.println("ArrayList[] 实现的加权无向图邻接表:");
wal.print();
}
}提供一个在算法竞赛常用的极简版链式前向星的存图实现(cpp):
cpp
int cnt, head[N]; // head[i]存的是以i为起点的边的个数; cnt为边总数
struct node{
int to,next,w; // to边的终点; next是该边在head[起点]的序号; w为权重
}e[M]; // 边的集合
void add(int u,int v,int w){
e[++cnt].to=v; e[cnt].next=head[u]; e[cnt].w =w; head[u]=cnt;
e[++cnt].to=u; e[cnt].next=head[v]; e[cnt].w =0; head[v]=cnt;
}
int main(){
/* 省略建图过程 */
// 遍历全图 但是一般不这么用 一般都是对于特定的u 遍历其所连的所有边
for(int u=1; u<=n; u++){
for(int i=head[u];i;i=e[i].next ){
int v=e[i].to ;
printf("%d ---%d---> %d\n", u, e[i].w, v);
}
}
}| 比较维度 | 邻接矩阵 (Matrix) | 邻接表 (List) |
|---|---|---|
| 空间效率 | 浪费空间,固定 O ( n 2 ) O(n^2) O(n2) | 节省空间,动态 O ( n + e ) O(n+e) O(n+e) |
| 适合图类型 | 稠密图 | 稀疏图 |
| 判断两点是否有边 | 极快 O ( 1 ) O(1) O(1),直接查数组 | 较慢,需遍历链表 O ( d ) O(d) O(d) ( d d d为度) |
| 计算度数 | 必须遍历整行/整列 O ( n ) O(n) O(n) | 遍历链表即可,出度为 O ( d ) O(d) O(d) |
| 找所有邻接点 | 慢,必须扫描整行 O ( n ) O(n) O(n) | 快,直接遍历链表 O ( d ) O(d) O(d) |
| 实现复杂度 | 简单,二维数组 | 稍复杂,涉及到指针/链表操作 |
| 唯一性 | 唯一(顶点编号确定后) | 不唯一(链表中结点的次序可变) |
5.3 图的广度优先遍历和深度优先遍历
5.3.1 深度优先遍历 (DFS - Depth First Search)
- 思想 :"一条路走到黑,撞了南墙再回头" 。
- 从起始点 v v v 出发,访问 v v v。
- 依次从 v v v 的未被访问的邻接点出发,进行深度优先遍历。
- 若当前顶点的所有邻接点都被访问过,则回退(Backtrack)到最近的一个仍有未访问邻接点的顶点。
- 实现核心 :
- 通常使用递归实现(隐式栈)。
- 非递归实现需使用显式栈 (Stack)。
- 时间复杂度 :
- 邻接矩阵: O ( n 2 ) O(n^2) O(n2)(每个点都要访问,且找邻接点需遍历行)
- 邻接表: O ( n + e ) O(n + e) O(n+e)(所有点访问一次,所有边扫描一次)
- 应用 :
- 检测环
- 寻找连通分量
- 拓扑排序
- 迷宫寻路(寻找任意路径)
5.3.2 广度优先遍历 (BFS - Breadth First Search)
- 思想 :"层层递进,地毯式搜索" 。
- 从起始点 v v v 出发,访问 v v v。
- 依次访问 v v v 的所有未被访问过的邻接点 w 1 , w 2 , . . . w_1, w_2, ... w1,w2,...。
- 再依次访问 w 1 , w 2 , . . . w_1, w_2, ... w1,w2,... 的所有未被访问过的邻接点。
- 保证"先被访问顶点的邻接点"先于"后被访问顶点的邻接点"被访问。
- 实现核心 :
- 必须使用队列 (Queue) 辅助。
- 时间复杂度 :
- 邻接矩阵: O ( n 2 ) O(n^2) O(n2)。
- 邻接表: O ( n + e ) O(n + e) O(n+e)。
- 应用 :
- 最短路径问题(无权图):BFS 生成的路径即为从起点到各点的最短路径(边数最少)。
- 寻找连通分量。
5.3.3 代码实现
java
import java.util.List;
import java.util.ArrayList;
import java.util.Queue;
import java.util.LinkedList;
public class Graph {
private List<Integer>[] adj;
private int n;
public Graph(int n) {
this.n = n;
adj = new ArrayList[n]; // 现在adj是一个长度为n的数组,每个元素都是null
for (int i = 0; i < n; i++)
adj[i] = new ArrayList<>(); // 为adj的每个元素放入一个具体的 ArrayList 对象
// 没有这句的话 会空指针报错
}
public void addEdge(int u, int v) {
adj[u].add(v);
adj[v].add(u); // 无向图加双向边 有向图加一条即可
}
public void DFS(int v) {
boolean[] vis = new boolean[n];
dfs(v, vis);
}
private void dfs(int v, boolean[] vis) {
vis[v] = true;
System.out.print(v + " ");
for (int n : adj[v])
if (!vis[n])
dfs(n, vis);
}
public void BFS(int start) {
boolean[] vis = new boolean[n];
Queue<Integer> q = new LinkedList<>();
q.add(start);
vis[start] = true;
while (!q.isEmpty()) {
int v = q.poll();
System.out.print(v + " ");
for (int n : adj[v]) {
if (!vis[n]) {
vis[n] = true;
q.add(n);
}
}
}
}
public static void main(String[] args) {
// 创建一个5个顶点的图
Graph graph = new Graph(5);
// 添加边
graph.addEdge(0, 1);
graph.addEdge(0, 2);
graph.addEdge(1, 3);
graph.addEdge(2, 4);
graph.addEdge(3, 4);
// 测试DFS
System.out.print("DFS: ");
graph.DFS(0);
// 测试BFS
System.out.print("\nBFS: ");
graph.BFS(0);
}
}输出:
DFS: 0 1 3 4 2
BFS: 0 1 2 3 4 一般使用双向列表 LinkedList 来实现 Queue。Queue是个接口,在实例化时必须实例化 LinkedList 的对象,因为 LinkedList 实现了Queue接口。
ArrayList 和 List 的关系也是如此。
| 特性 | 深度优先遍历 (DFS) | 广度优先遍历 (BFS) |
|---|---|---|
| 数据结构辅助 | 栈 (Stack) (递归栈或显式栈) | 队列 (Queue) |
| 搜索策略 | 纵向深入,回溯 | 横向扩展,分层 |
| 生成树形态 | 树高且瘦(倾向于长路径) | 树矮且胖(倾向于短路径) |
| 最优性 | 不一定能找到最短路径 | 必定能找到无权图的最短路径 |
| 对应树遍历 | 类似于树的先序遍历 | 类似于树的层次遍历 |
| 连通性判断 | 可用于判断连通性 | 可用于判断连通性 |
5.4 最小支撑树(Prim算法、Kruskal算法)、最短路径(Dijkstra算法)及拓扑排序的实现过程
5.4.1 最小支撑树(最小生成树)
最小支撑树(Minimum Spanning Tree, MST):在加权无向图中,找到一棵包含所有顶点的树,使得树的所有边权重之和最小。
顶点:A(0), B(1), C(2), D(3), E(4)
边和权重:
A-B: 4 A-C: 2 A-D: 5
B-C: 1 B-E: 3
C-D: 8 C-E: 6
D-E: 7初始图:
4 2 5 1 3 8 6 7 A B C D E
总权重 = 4+2+5+1+3+8+6+7 = 36
-
Prim算法:从单个顶点开始,每次添加一个与当前树连接的最小权重边,直到包含所有顶点。
- 选择图中的任意一个顶点N作为起点,将最小生成树(MST)初始化为仅包含顶点N
- 计算当前MST中的所有顶点,到所有未加入MST的顶点之间的边的权重(距离)
- 从这些边中选择权重最小的一条,将这条边对应的未加入MST的顶点添加到MST中
- 重复执行"计算距离""选择最小边并添加顶点"的步骤,直到所有顶点都被加入到MST中
步骤1:从顶点A开始
4 2 5 1 3 8 6 7 A B C D E A-B A-C A-D
候选边:A-C(2, 最小), A-B(4), A-D(5)
步骤2:选择最小边A-C(2),加入C
4 2 5 1 3 8 6 7 A C B D E A-C A-B A-D B-C C-D C-E
新增候选边:B-C(1, 最小), C-D(8), C-E(6),加上之前的A-B(4), A-D(5)
步骤3:选择最小边B-C(1),加入B
4 2 5 1 3 8 6 7 A C B D E A-C B-C A-B A-D B-E C-D C-E
新增候选边:B-E(3),加上之前的A-B(4), A-D(5), C-D(8), C-E(6)
步骤4:选择最小边B-E(3),加入E
4 2 5 1 3 8 6 7 A C B E D A-C B-C B-E A-B A-D C-D C-E D-E
新增候选边:D-E(7),加上之前的A-D(5, 最小), C-D(8), C-E(6)
步骤5:选择最小边A-D(5),加入D
4 2 5 1 3 8 6 7 A C B E D A-C B-C B-E A-D A-B C-D C-E D-E
最终 Prim 算法 MST:边A-C(2), B-C(1), B-E(3), A-D(5),总权重=2+1+3+5=11
- Kruskal 算法:按边权重从小到大排序,依次选择边,如果加入该边不会形成环,则加入,直到选择了V-1条边。
步骤1-3:排序边:B-C(1), A-C(2), B-E(3), A-B(4), A-D(5), C-E(6), D-E(7), C-D(8)
4 2 5 1 3 8 6 7 A B C D E B-C A-C B-E A-B A-D C-E D-E C-D
已选边:B-C(1), A-C(2), B-E(3)
当前连通分量:{A, B, C, E}, {D}
步骤4:考虑边A-B(4),但A和B已在同一连通分量(会形成环),跳过
步骤5:考虑边A-D(5),A和D在不同连通分量,加入
4 2 5 1 3 8 6 7 A B C D E B-C A-C B-E A-D A-B C-E D-E C-D
最终Kruskal算法MST:边B-C(1), A-C(2), B-E(3), A-D(5),总权重=1+2+3+5=11
java
import java.util.*;
// 边类
class Edge implements Comparable<Edge> {
int u, v, weight;
Edge(int u, int v, int weight) {
this.u = u;
this.v = v;
this.weight = weight;
}
@Override
public int compareTo(Edge other) {
return this.weight - other.weight;
}
}
// 并查集(用于Kruskal算法)
class UnionFind {
private int[] parent, rank;
UnionFind(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) parent[i] = i;
}
int find(int x) {
if (parent[x] != x) parent[x] = find(parent[x]);
return parent[x];
}
boolean union(int x, int y) {
int rootX = find(x), rootY = find(y);
if (rootX == rootY) return false;
if (rank[rootX] < rank[rootY]) parent[rootX] = rootY;
else if (rank[rootX] > rank[rootY]) parent[rootY] = rootX;
else { parent[rootY] = rootX; rank[rootX]++; }
return true;
}
}
public class MST {
// Prim算法
public static List<Edge> prim(int n, List<List<int[]>> adj) {
List<Edge> mst = new ArrayList<>();
boolean[] visited = new boolean[n];
PriorityQueue<int[]> pq = new PriorityQueue<>(Comparator.comparingInt(a -> a[1]));
visited[0] = true;
for (int[] neighbor : adj.get(0)) pq.offer(new int[]{0, neighbor[0], neighbor[1]});
while (!pq.isEmpty() && mst.size() < n - 1) {
int[] edge = pq.poll();
int u = edge[0], v = edge[1], w = edge[2];
if (visited[v]) continue;
mst.add(new Edge(u, v, w));
visited[v] = true;
for (int[] neighbor : adj.get(v)) {
if (!visited[neighbor[0]])
pq.offer(new int[]{v, neighbor[0], neighbor[1]});
}
}
return mst;
}
// Kruskal算法
public static List<Edge> kruskal(int n, List<Edge> edges) {
Collections.sort(edges);
UnionFind uf = new UnionFind(n);
List<Edge> mst = new ArrayList<>();
for (Edge edge : edges) {
if (uf.union(edge.u, edge.v)) {
mst.add(edge);
if (mst.size() == n - 1) break;
}
}
return mst;
}
public static void main(String[] args) {
int n = 5;
// 构建邻接表
List<List<int[]>> adj = new ArrayList<>();
for (int i = 0; i < n; i++) adj.add(new ArrayList<>());
// 添加边:A=0, B=1, C=2, D=3, E=4
addEdge(adj, 0, 1, 4); // A-B
addEdge(adj, 0, 2, 2); // A-C
addEdge(adj, 0, 3, 5); // A-D
addEdge(adj, 1, 2, 1); // B-C
addEdge(adj, 1, 4, 3); // B-E
addEdge(adj, 2, 3, 8); // C-D
addEdge(adj, 2, 4, 6); // C-E
addEdge(adj, 3, 4, 7); // D-E
// Prim算法
System.out.println("Prim算法结果:");
List<Edge> primResult = prim(n, adj);
printMST(primResult);
// Kruskal算法
List<Edge> edges = Arrays.asList(
new Edge(0, 1, 4), new Edge(0, 2, 2), new Edge(0, 3, 5),
new Edge(1, 2, 1), new Edge(1, 4, 3), new Edge(2, 3, 8),
new Edge(2, 4, 6), new Edge(3, 4, 7)
);
System.out.println("\nKruskal算法结果:");
List<Edge> kruskalResult = kruskal(n, edges);
printMST(kruskalResult);
}
static void addEdge(List<List<int[]>> adj, int u, int v, int w) {
adj.get(u).add(new int[]{v, w});
adj.get(v).add(new int[]{u, w});
}
static void printMST(List<Edge> mst) {
int total = 0;
for (Edge e : mst) {
System.out.printf(" %c-%c(%d)", 'A'+e.u, 'A'+e.v, e.weight);
total += e.weight;
}
System.out.println("\n总权重: " + total);
}
}| 特性 | Prim算法 | Kruskal算法 |
|---|---|---|
| 思想 | 从点出发,逐步扩展 | 从边出发,按权重排序 |
| 数据结构 | 优先队列(最小堆) | 并查集 + 排序 |
| 时间复杂度 | O(E log V) | O(E log E) |
| 适合场景 | 稠密图(边多) | 稀疏图(边少) |
| 是否需要图连通 | 需要 | 不需要(可生成最小生成森林) |
5.4.2 最短路 dijkstra
Dijkstra 的核心是贪心算法。它的逻辑是:如果不走回头路(即没有负权边),那么"目前离起点最近的那个点",它的最短路径就已经确定了。
-
Node类(辅助类)- 我们需要在优先队列中同时存储"是哪个点 (
id)"和"当前走到的距离 (dist)"。 implements Comparable<Node>:这是为了让PriorityQueue知道怎么排序。compareTo方法中this.dist - other.dist表示按距离从小到大排序。这是 Dijkstra 的核心------每次都先处理距离起点最近的点。
- 我们需要在优先队列中同时存储"是哪个点 (
-
graph(邻接表)- 类型
List<List<Edge>>。 graph.get(u)返回的是一个列表,里面包含了所有从u出发能直接到达的边。每条边记录了终点v和权重w。
- 类型
核心逻辑流程
-
初始化 (
dist数组)javaint[] dist = new int[n]; Arrays.fill(dist, Integer.MAX_VALUE); dist[start] = 0;- 我们假设起点到所有点的距离都是无穷大(不可达)。
- 唯独起点到自己的距离是 0。
-
优先队列 (
PriorityQueue)javaQueue<Node> pq = new PriorityQueue<>(); pq.offer(new Node(start, 0));- 我们将起点放入队列。队列会自动把距离最小的点放在队头。
-
主循环 (Processing)
javawhile (!pq.isEmpty()) { Node curr = pq.poll(); // 1. 弹出当前距离最近的点 int u = curr.id; if (curr.dist > dist[u]) continue; // 2. 过期数据过滤(重要!) // 3. 松弛操作 for (Edge edge : graph.get(u)) { ... } }- 重点解释
if (curr.dist > dist[u]) continue;:- 这是 Java
PriorityQueue实现 Dijkstra 的一个关键细节。 - Java 的优先队列不支持高效地"修改"已经在队列里的元素的优先级。
- 如果在处理过程中,我们要把节点 A 的距离从 10 更新为 5,我们不会 去队列里找那个 10 并改成 5,而是直接新加 一个
Node(A, 5)进队列。 - 这样队列里会有两个 A:一个距离 5,一个距离 10。距离 5 的会先被弹出来处理。
- 等到那个距离 10 的 A 被弹出来时,我们发现
10 > dist[A](此时dist[A]已经是 5 了),说明这个节点是旧的、被优化过的 废弃数据,直接跳过,不做处理。这叫"懒删除"。
- 这是 Java
- 重点解释
-
松弛操作 (Relaxation)
javaint newDist = dist[u] + edge.weight; if (newDist < dist[v]) { dist[v] = newDist; pq.offer(new Node(v, newDist)); }- 意思就是:"我发现了一条经过
u到达v的路,比以前知道的任何路都要近。" - 如果是这样,就更新
dist[v],并把v(带着新的更短距离)加入队列,让它去更新它的邻居。
- 意思就是:"我发现了一条经过
完整代码
java
import java.util.*;
public class Dijkstra {
// 简单的边对象
static class Edge {
int to, weight;
Edge(int to, int weight) { this.to = to; this.weight = weight; }
}
// 放入优先队列的节点,存储当前点id和到起点的距离
static class Node implements Comparable<Node> {
int id, dist;
Node(int id, int dist) { this.id = id; this.dist = dist; }
// 按距离从小到大排序
@Override
public int compareTo(Node other) { return this.dist - other.dist; }
}
/**
* @param n 节点数量 (节点编号 0 到 n-1)
* @param graph 邻接表
* @param start 起点
* @return 从起点到所有点的最短距离数组
*/
public static int[] dijkstra(int n, List<List<Edge>> graph, int start) {
int[] dist = new int[n];
Arrays.fill(dist, Integer.MAX_VALUE);
dist[start] = 0;
// 使用优先队列,每次取出当前距离最短的点
Queue<Node> pq = new PriorityQueue<>();
pq.offer(new Node(start, 0));
while (!pq.isEmpty()) {
Node curr = pq.poll();
int u = curr.id;
// 如果当前取出的距离大于已经记录的最短距离,说明该节点已被处理过,跳过
if (curr.dist > dist[u]) continue;
// 遍历邻居进行松弛操作
for (Edge edge : graph.get(u)) {
int v = edge.to;
int newDist = dist[u] + edge.weight;
if (newDist < dist[v]) {
dist[v] = newDist;
pq.offer(new Node(v, newDist));
}
}
}
return dist;
}
}5.4.3 拓扑排序
拓扑排序常用于解决任务调度 或课程先修 问题。核心概念是入度 (In-degree):有多少条边指向我?(即:我有多少个前置条件没完成?)
inDegree[]数组inDegree[i] = k表示节点i有k个前置任务。只有当k变成 0 时,节点i才能被执行。
Queue(普通队列)- 这里不需要优先队列,普通的
LinkedList即可。因为只要入度为 0,谁先谁后由于没有依赖关系,顺序通常不重要(除非题目有特殊要求)。
- 这里不需要优先队列,普通的
核心逻辑流程
-
计算所有点的入度
javafor (List<Integer> neighbors : graph) { for (int neighbor : neighbors) { inDegree[neighbor]++; } }- 遍历整个图,数一数每个点被多少个箭头指着。
-
寻找起始点 (入度为 0)
javafor (int i = 0; i < n; i++) { if (inDegree[i] == 0) { queue.offer(i); } }- 入度为 0 意味着没有任何先决条件,这些任务可以直接开始。
-
BFS 处理 (拆除边)
javawhile (!queue.isEmpty()) { int u = queue.poll(); result.add(u); // 1. 执行任务 u for (int v : graph.get(u)) { inDegree[v]--; // 2. u 完成了,v 的前置条件少了一个 if (inDegree[v] == 0) { queue.offer(v); // 3. v 的所有前置条件都解决了,v 可以入队了 } } }- 这就像剥洋葱。你把最外层(入度0)的点拿走,连带着把它们发出的边也"剪断"(
inDegree[v]--)。 - 剪断后,如果里面的节点露出来了(入度变成了0),它就成了新的最外层,加入队列等待处理。
- 这就像剥洋葱。你把最外层(入度0)的点拿走,连带着把它们发出的边也"剪断"(
-
环检测
javaif (result.size() != n) return new ArrayList<>();- 如果图中有环(例如 A -> B -> A),那么 A 和 B 的入度永远不会减到 0,它们永远不会进队列。
- 最后导致
result里的节点数量少于总节点数n。这是判断 DAG(有向无环图)的重要标准。
完整代码
java
import java.util.*;
public class TopologicalSort {
/**
* @param n 节点数量
* @param graph 邻接表 (无权图,List<Integer>即可)
* @return 拓扑排序结果,如果图中有环则返回空列表或部分列表
*/
public static List<Integer> kahnTopologicalSort(int n, List<List<Integer>> graph) {
int[] inDegree = new int[n];
// 1. 统计入度
for (List<Integer> neighbors : graph) {
for (int neighbor : neighbors) {
inDegree[neighbor]++;
}
}
// 2. 将入度为0的点加入队列
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < n; i++) {
if (inDegree[i] == 0) {
queue.offer(i);
}
}
List<Integer> result = new ArrayList<>();
// 3. BFS 处理
while (!queue.isEmpty()) {
int u = queue.poll();
result.add(u);
for (int v : graph.get(u)) {
inDegree[v]--;
// 若入度变为0,说明依赖已解决,加入队列
if (inDegree[v] == 0) {
queue.offer(v);
}
}
}
// 如果结果集大小不等于n,说明图中存在环
if (result.size() != n) return new ArrayList<>();
return result;
}
}6. 查找
6.1 查找的定义
查找 (Searching)是在一个数据元素集合(或称查找表 ,Search Table)中,定位某个特定数据元素的过程。该过程通过给定的某个关键字(Key,可以是数据元素中某个数据项的值)进行。
- 查找表 :由同一类型的数据元素(或记录)构成的集合。对查找表常进行的操作有:
- 检索某个"特定的"数据元素是否存在
- 插入一个数据元素
- 删除一个数据元素
- 关键字 :数据元素中某个可以唯一标识 该元素的数据项,称为主关键字 (Primary Key)。若一个关键字仅能识别若干条记录,则称为次关键字(Secondary Key)。查找是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素。
- 静态查找表:只进行上述第1类操作(检索)的查找表。它的结构在查找过程中不会改变。
- 动态查找表:同时进行上述第1、2、3类操作的查找表。在查找过程中,表结构可能会因插入或删除操作而改变。
6.2 查找算法的衡量指标(平均查找长度、成功查找的查找长度、不成功查找的查找长度)
评价一个查找算法效率的主要指标是平均查找长度 ASL(Average Search Length)。
- 查找长度 :在查找运算中,需要比较关键字的次数,称为查找长度。它反映了查找操作的时间复杂度。
- 平均查找长度(ASL) :所有查找过程中进行关键字比较次数的期望值(平均值) 。其数学定义为:
ASL = Σ(Pi * Ci),其中:Pi为查找表中第i个数据元素的概率 (通常取等概率,即Pi = 1/n,n为表长)。Ci为找到第i个数据元素时,已进行过的关键字比较次数。
在具体分析时,ASL通常被分为两种情形:
-
平均成功查找长度(ASL_success) :查找成功时的平均查找长度。即查找目标存在于查找表中时的平均比较次数。
ASL_success = Σ(Pi * Ci),其中i遍历查找表中所有存在的元素。 -
平均不成功查找长度(ASL_failure) :查找失败时的平均查找长度。即查找目标不存在于查找表中时的平均比较次数。这需要针对查找表的所有可能"失败位置"进行计算。
ASL_failure = Σ(Qj * Cj),其中Qj是查找失败落到第j种失败情形的概率,Cj是在该失败情形下所进行的比较次数。
ASL 是衡量查找算法整体性能的最重要指标。一个好的查找算法应具有尽可能低的 ASL。
6.3 顺序查找法和折半查找法的实现及二者之间的异同点
6.3.1 顺序查找法
基本思想:从表的一端(通常是起始端)开始,依次将记录的关键字与给定值进行比较。若某个记录的关键字等于给定值,则查找成功;若直至表的另一端仍未找到匹配记录,则查找失败。
java
// 顺序查找独立实现类
public class SequentialSearch {
public static int sequentialSearch(int[] L, int n, int key) {
for (int i = 0; i < n; i++) {
if (L[i] == key) {
return i; // 查找成功,返回下标
}
}
return -1; // 查找失败
}
public static void main(String[] args) {
int[] arr = {5, 2, 9, 1, 5, 6};
int key = 9;
int result = sequentialSearch(arr, arr.length, key);
System.out.println("顺序查找结果:关键字 " + key + " 的下标为:" + result);
}
}- 时间复杂度:O(n)
- 优点:算法简单,对表的存储结构(顺序或链式)和元素是否有序均无要求。
- 缺点:当 n 较大时,平均查找长度较大,效率低。
6.3.2 折半查找法
前提条件 :查找表必须采用顺序存储结构 ,且表中的元素按关键字有序排列 (通常为升序)。
基本思想:
- 用给定值
key与表中间位置元素的关键字比较。 - 若相等,则查找成功。
- 若
key小于中间关键字,则在中间元素的左半区继续以同样方法查找。 - 若
key大于中间关键字,则在中间元素的右半区继续以同样方法查找。 - 重复此过程,直到查找成功或区间缩小至空(查找失败)为止。
java
// 折半查找独立实现类
public class BinarySearch {
public static int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
// 注意这里是 <=,因为当 left == right 时,该位置仍需检查
while (left <= right) {
// 防止 (left + right) 溢出,等同于 (left + right) / 2
int mid = left + (right - left) / 2;
if (nums[mid] == target)
return mid; // 找到了
else if (nums[mid] < target)
left = mid + 1; // 在右半区,mid已经看过了,所以+1
else
right = mid - 1; // 在左半区,mid已经看过了,所以-1
return -1; // 没找到
}
}
public static void main(String[] args) {
int[] arr = {1, 2, 5, 6, 9, 10};
int key = 6;
int result = binarySearch(arr, arr.length, key);
System.out.println("折半查找结果:关键字 " + key + " 的下标为:" + result);
}
}- 时间复杂度:O(log₂n)
- 优点:查找效率远高于顺序查找。
- 缺点:要求表有序且必须顺序存储,对线性链表无效。插入和删除操作困难。
6.3.3 二者异同点
| 特性 | 顺序查找 | 折半查找 |
|---|---|---|
| 前提条件 | 无要求(可无序,可链式存储) | 必须有序 且顺序存储 |
| 查找思想 | 遍历、逐个比较 | 分治、每次将查找区间缩小一半 |
| 平均时间复杂度 | O(n) | O(log₂n) |
| ASL | 较大(成功时约为 (n+1)/2) | 较小(成功时约为 log₂(n+1)-1) |
| 适用场景 | 1. 表长 n 较小 2. 无序表或链式表 3. 动态查找表(频繁插入/删除) | 1. 表长 n 较大 2. 静态查找表(建立后改动少) |
| 相同点 | 1. 均属于基于比较的查找算法。 2. 目标都是确定关键字等于给定值的记录在集合中的位置。 |
6.4 散列技术(散列函数、散列表、散列冲突的发生及其解决方法、负载因子)
散列(Hashing)是一种通过映射函数将任意长度的数据转换为固定长度值(散列值)的技术,其核心目的是实现数据的快速查找。
6.4.1 散列表 (Hash Table)
散列表(也称哈希表)是一种根据键(Key)直接访问内存存储位置的数据结构。
- 核心原理 :通过计算
index = Hash(key),将数据存储在数组下标为index的位置。 - 时间复杂度 :在理想情况下,插入、删除、查找的时间复杂度均为 O(1)。
- 应用场景:缓存系统(Redis)、数据库索引、编程语言中的 Map/Set 集合、唯一性检测。
6.4.2 散列函数 (Hash Function)
散列函数是将输入(Key)映射到散列表索引的数学函数。
- 设计原则 :
- 确定性:同样的 Key 必须得到同样的 Hash 值。
- 高效性:计算过程要快。
- 均匀性:尽可能将 Key 均匀分布在整个散列表中,避免某些位置过度拥挤(减少冲突)。
- 常见构造方法 :
- 保留余数法 (Division Method) :最常用。公式为
H(key) = key % p。通常选取p为不大于表长的素数。 - 直接定址法 :
H(key) = a * key + b。适合 Key 分布连续且范围小的情况。 - 数字分析法 (提取关键字中均匀分布的若干位或他们的组合 比如说提取同学们的出生年月日或者学号)、平方取中法 、折叠法 、随机数法等。
- 保留余数法 (Division Method) :最常用。公式为
6.4.3 散列冲突 (Hash Collision)
- 定义 :当两个不同的 Key 通过散列函数计算出相同的索引时(即
Hash(key1) == Hash(key2)),称为冲突或碰撞。把散列地址相同的不同关键字成为同义词。 - 根本原因:输入空间(Key的范围)通常是无穷的,而输出空间(散列表大小)是有限的(抽屉原理)。冲突在理论上无法完全避免,只能减少或解决。
6.4.4 散列冲突的解决方法
当冲突发生时,需要寻找下一个可用的存储位置。
注意在中文教材中,以下这两个方法的命名常有混淆,以下是ys的ppt的命名:

(1) 开地址法 (Open Addressing) ------ 闭散列法 (Closed Hashing)
所有元素都存储在散列表数组本身中。当冲突发生时,按照某种探测序列寻找空槽。注意处理懒删除(Lazy Deletion),即标记该位置为"已删除"(deleted),而不是"空"(empty)。
- 线性探测法 (Linear Probing) :
index = (Hash(key) + i) % size,即冲突了就看下一个位置,再冲突再看下一个。- 缺点 :容易产生堆积(Clustering)现象,连续的已占位块会导致新插入的元素查找时间变长。
- 二次探测法 (Quadratic Probing) :
index = (Hash(key) + i^2) % size,探测序列为 1 2 , − 1 2 , 2 2 , − 2 2 . . . 1^2, -1^2, 2^2, -2^2... 12,−12,22,−22...。- 缓解了堆积问题,但需要表长满足特定条件(如 4 k + 3 4k+3 4k+3 的素数)才能保证探测所有位置。
- 双重散列法 (Double Hashing) :
- 使用两个哈希函数。
index = (Hash1(key) + i * Hash2(key)) % size。 - 分布最均匀,但计算代价大。
- 使用两个哈希函数。
(2) 开散列法(Open Hashing) ------拉链法 / 链地址法 (Chaining) / 闭地址法(Close Addressing) Java HashMap 采用此法
- 原理 :散列表的每个槽位(Slot)不再存储元素本身,而是存储一个链表的头指针。所有哈希值相同的元素都挂在这个链表上。
- 优点 :
- 处理冲突简单,无堆积现象。
- 对负载因子不敏感,表满了也能继续插(虽然效率会降)。
- 优化 :当链表过长时(如 Java 8 中超过 8),可转化为红黑树,将查找复杂度从 O(N) 降为 O(log N)。
6.4.5 负载因子 (Load Factor)
负载因子是衡量散列表"满"的程度的指标。
- 公式 : λ = 填入表中的元素个数 散列表的长度 \lambda = \frac{\text{填入表中的元素个数}}{\text{散列表的长度}} λ=散列表的长度填入表中的元素个数
- 意义 :
- λ \lambda λ 越大:表越满,冲突概率越高,查找性能越差(空间利用率高)。
- λ \lambda λ 越小:表越空,冲突概率越低,性能越好(空间浪费大)。
- 扩容机制 :
- 通常设定一个阈值(如 Java HashMap 默认为 0.75)。
- 当负载因子超过该阈值时,系统会自动触发扩容(Rehash) :申请一个更大的数组(通常是原大小的 2 倍),并将原表中的所有元素重新计算哈希值放入新表。这是一个耗时的 O ( N ) O(N) O(N) 操作。
- 对于不同机制的负载因子取值
- 线性探测法 一般 λ < 0.3 \lambda < 0.3 λ<0.3 效率比较好
- 平方探测法或双哈希 一般 λ < 0.5 \lambda < 0.5 λ<0.5 效率比较好
- 开散列法比较特殊, λ \lambda λ 可以大于一,性能也还可以,一般 λ < 1 \lambda < 1 λ<1 效率比较好
6.4.6 平均查找长度 ASL (Average Search Length)
-
A S L s u c c ASL_{succ} ASLsucc 搜索成功的平均搜索长度:查找表中已存在的关键字。也就是找到表中各个已有表项的探查次数的平均值。
在将数据填充入表的过程中可以直接数。没有冲突直接填入记为1,每多一个冲突就加一。分母是已有表项的个数。
-
A S L u n s u c c ASL_{unsucc} ASLunsucc 搜索不成功的平均搜索长度:查找表中不存在的关键字。也就是从表中每个位置开始探查,直到探查到空位时所需的探查次数的平均值。
(这个的计算在各个教材中有争议,ys的版本是,空指针的比较也算一次,也就是说找到空位置的那一次也算)
6.4.7 散列代码实现
通常在构造时使用除留余数法。
以下是使用线性探测法处理冲突的实现。
java
import java.util.Arrays;
public class LinearProbingHash {
private int[] table;
private int size;
// 定义状态常量
private static final int EMPTY = -1;
private static final int DELETED = -2; // 墓碑标记
public LinearProbingHash(int size) {
this.size = size;
this.table = new int[size];
Arrays.fill(table, EMPTY);
}
private int hash(int key) {
return key % size;
}
public void insert(int key) {
int idx = hash(key);
// 线性探测:遇到 EMPTY 或者 DELETED 都可以利用
while (table[idx] != EMPTY && table[idx] != DELETED) {
idx = (idx + 1) % size;
}
table[idx] = key;
}
public int search(int key) {
int idx = hash(key);
int startIdx = idx;
// 查找循环:遇到 EMPTY 才能确定找不到,遇到 DELETED 必须继续找
while (table[idx] != EMPTY) {
if (table[idx] == key) return idx;
idx = (idx + 1) % size;
if (idx == startIdx) break; // 找了一圈
}
return -1;
}
public boolean delete(int key) {
int idx = search(key); // 复用查找逻辑
if (idx != -1) {
table[idx] = DELETED; // 关键:标记为删除,而不是设为 EMPTY
return true;
}
return false;
}
}以下是拉链法处理冲突的实现
java
import java.util.LinkedList;
public class ChainingHash {
private LinkedList<Integer>[] table;
private int size;
@SuppressWarnings("unchecked")
public ChainingHash(int size) {
this.size = size;
this.table = new LinkedList[size];
for (int i = 0; i < size; i++) {
table[i] = new LinkedList<>();
}
}
// 哈希函数:除留余数法
private int hash(int key) {
return key % size;
}
public void insert(int key) {
int idx = hash(key);
table[idx].add(key); // 直接加到对应链表末尾
}
public boolean search(int key) {
int idx = hash(key);
// 使用 LinkedList 自带的 contains 方法查找
return table[idx].contains(key);
}
public boolean delete(int key) {
int idx = hash(key);
// LinkedList 的 remove(Object o) 方法会删除找到的第一个匹配元素并返回 true
// 注意:需要将 int 装箱为 Integer 对象,否则会调用 remove(int index)
return table[idx].remove(Integer.valueOf(key));
}
}7. 排序
八大排序算法之间的关系
排序 内部排序 外部排序 交换排序 插入排序 选择排序 归并排序 基数排序 冒泡排序 快速排序 直接插入排序 希尔排序 简单选择排序 堆排序
7.1 排序的稳定性
- 定义 :如果待排序序列中存在两个或两个以上关键字相等的元素,在排序前和排序后,这些元素之间的相对次序保持不变,则称该排序算法是稳定 的;否则称为不稳定 的。
- 例如:
[(StudentA, 80), (StudentB, 80)]。如果按分数排序后,A 依然在 B 前面,则稳定;若 B 跑到了 A 前面,则不稳定。
- 例如:
- 意义:当进行多关键字排序时(例如先按数学成绩排,再按总分排),稳定性非常重要。
| 排序算法 | 稳定性 | 解释 |
|---|---|---|
| 直接插入排序 | 稳定 | 从后向前扫描,遇到相等元素时停止移动,插入到相等元素后面 |
| 冒泡排序 | 稳定 | 相邻元素比较,相等时不交换,保持原顺序 |
| 简单选择排序 | 不稳定 | 选择最小元素时,可能将前面的相等元素交换到后面 |
| 快速排序 | 不稳定 | 分区操作中,可能交换不相邻的相等元素 |
| 堆排序 | 不稳定 | 堆调整过程中可能改变相等元素的相对顺序 |
| 归并排序 | 稳定 | 合并操作中,遇到相等元素优先选择左侧元素 |
| 基数排序 | 稳定 | 基于稳定的子排序(通常是计数排序) |
在实际开发中,稳定性选择需要考虑:
- 需要稳定性的场景 :
- 多级排序(先按次要条件排,再按主要条件排)
- 保持用户数据的原始顺序
- 需要可重现的结果
- Java内置排序 :
Arrays.sort():对于基本类型使用快速排序(不稳定),对于对象类型使用TimSort(稳定归并排序变体)Collections.sort():使用TimSort(稳定)
- 性能与稳定性权衡 :
- 稳定排序通常稍慢于不稳定排序
- 归并排序是常见的稳定且高效的算法
- 快速排序在大多数情况下最快,但不稳定
7.2 各类排序算法的排序过程、排序特点及时间复杂度、空间复杂度、稳定性等特性
7.2.1 直接插入排序 (Insertion Sort)
- 过程:将数组分为"已排序"和"未排序"两部分。每次从未排序部分取出一个元素,插入到已排序部分的正确位置。类似打扑克牌理牌。
- 特点 :数据越接近有序,效率越高。 N N N 较小时效率很高。
java
void insertionSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int key = arr[i];
int j = i - 1;
// 将大于key的元素后移
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}最外层循环为轮到第i个数插入,插入到左边的序列中,使得 0~i 为有序数列。内层循环是第i个数与其左边的数进行比较以确定它应该插入的位置(从右往左把大于它的数全部后移 直到遇到第一个小于它的数停止)。
- 复杂度 :时间 O ( N 2 ) O(N^2) O(N2),空间 O ( 1 ) O(1) O(1)。
- 稳定性 :稳定。
7.2.2 冒泡排序 (Bubble Sort)
- 过程:重复走访数组,比较相邻元素,如果顺序错误就交换。每轮走访会将当前最大的元素"冒泡"到顶端。
- 特点:实现最简单,但由于交换次数多,通常是最慢的。
java
void bubbleSort(int[] arr) {
boolean swapped = true;
for (int i = 0; i < arr.length - 1 && swapped; i++) {
swapped = false; // 优化:如果一轮没发生交换,说明已有序
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swapped = true;
}
}
}
}外层循环是遍历次数,每次遍历从头开始,两两比较 ,每次遍历都会把(未有序的数中)最大的数放到最右边,使得右端成为有序数列。第 i 次遍历则右端的有序数列长度为 i,只需要检查下标为 0~n-i 这些数(两两比较)就好。
- 复杂度 :时间 O ( N 2 ) O(N^2) O(N2),空间 O ( 1 ) O(1) O(1)。
- 稳定性 :稳定。
7.2.3 简单选择排序 (Selection Sort)
- 过程:每次从未排序区间找到最小(或最大)的元素,将其放到已排序区间的末尾。
- 特点 :交换次数最少(最多 N − 1 N-1 N−1 次),但比较次数多。
java
void selectionSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int minIdx = i;
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[minIdx]) minIdx = j;
}
// 交换
int temp = arr[i];
arr[i] = arr[minIdx];
arr[minIdx] = temp;
}
}最外层为遍历次数。第i趟选择右端无序数列中最小的值 ,与第i个数交换,使得左端成为有序数列。内层循环就是找出并记录每趟的最小值及其位置。
- 复杂度 :时间 O ( N 2 ) O(N^2) O(N2),空间 O ( 1 ) O(1) O(1)。
- 稳定性 :不稳定 (例如
[2, 2, 1],第一个 2 会被交换到 1 的后面)。
7.2.4 快速排序 (Quick Sort)
- 过程:分治法。选一个"基准值"(pivot),将小于它的放左边,大于它的放右边,然后递归处理左右两边。
- 特点:平均性能最快的通用排序算法。
java
void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pivot = partition(arr, low, high);
quickSort(arr, low, pivot - 1);
quickSort(arr, pivot + 1, high);
}
}
int partition(int[] arr, int low, int high) {
int pivot = arr[high]; // 选最后一个元素作为基准
int i = low - 1;
for (int j = low; j < high; j++) {
if (arr[j] < pivot) {
i++;
int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp;
}
}
// 将基准放到正确位置
int temp = arr[i + 1]; arr[i + 1] = arr[high]; arr[high] = temp;
return i + 1;
}- 复杂度 :平均时间 O ( N log N ) O(N \log N) O(NlogN),最坏 O ( N 2 ) O(N^2) O(N2)。空间 O ( log N ) O(\log N) O(logN)(递归栈)。
- 稳定性 :不稳定。
7.2.5 堆排序 (Heap Sort)
- 过程:将数组构建成大顶堆,堆顶是最大值。将堆顶与末尾交换,缩小堆范围,重新调整堆。重复直至堆空。
- 特点:不需要递归,辅助空间少,适合大数据量且对最坏情况有要求的场景。
java
void heapSort(int[] arr) {
int n = arr.length;
// 建堆
for (int i = n / 2 - 1; i >= 0; i--) heapify(arr, n, i);
// 排序
for (int i = n - 1; i > 0; i--) {
int temp = arr[0]; arr[0] = arr[i]; arr[i] = temp;
heapify(arr, i, 0);
}
}
void heapify(int[] arr, int n, int i) {
int largest = i, l = 2 * i + 1, r = 2 * i + 2;
if (l < n && arr[l] > arr[largest]) largest = l;
if (r < n && arr[r] > arr[largest]) largest = r;
if (largest != i) {
int swap = arr[i]; arr[i] = arr[largest]; arr[largest] = swap;
heapify(arr, n, largest);
}
}- 复杂度 :时间 O ( N log N ) O(N \log N) O(NlogN),空间 O ( 1 ) O(1) O(1)。
- 稳定性 :不稳定。
7.2.6 归并排序 (Merge Sort)
- 过程:分治法。将数组递归对半切分,直到只剩一个元素,然后两两合并有序序列。
- 特点 :性能不受输入数据影响,严格的 O ( N log N ) O(N \log N) O(NlogN),但需要额外内存。
java
void mergeSort(int[] arr, int l, int r) {
if (l < r) {
int m = l + (r - l) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
merge(arr, l, m, r);
}
}
void merge(int[] arr, int l, int m, int r) {
int[] temp = new int[r - l + 1]; // 辅助数组
int i = l, j = m + 1, k = 0;
while (i <= m && j <= r)
temp[k++] = (arr[i] <= arr[j]) ? arr[i++] : arr[j++];
while (i <= m) temp[k++] = arr[i++];
while (j <= r) temp[k++] = arr[j++];
System.arraycopy(temp, 0, arr, l, temp.length);
}- 复杂度 :时间 O ( N log N ) O(N \log N) O(NlogN),空间 O ( N ) O(N) O(N)。
- 稳定性 :稳定。
7.2.7 基数排序 (Radix Sort)
- 过程:非比较排序。按照低位先排序,收集;再按高位排序,收集;以此类推。
- 特点:基于桶排序思想,适用于整数或定长字符串。
java
void radixSort(int[] arr) {
int max = Arrays.stream(arr).max().getAsInt();
// exp: 1, 10, 100... 按位数循环
for (int exp = 1; max / exp > 0; exp *= 10) {
int[] output = new int[arr.length];
int[] count = new int[10];
for (int i : arr) count[(i / exp) % 10]++;
for (int i = 1; i < 10; i++) count[i] += count[i - 1];
// 倒序遍历以保证稳定性
for (int i = arr.length - 1; i >= 0; i--) {
output[count[(arr[i] / exp) % 10] - 1] = arr[i];
count[(arr[i] / exp) % 10]--;
}
System.arraycopy(output, 0, arr, 0, arr.length);
}
}- 复杂度 :时间 O ( d ( N + K ) ) O(d(N+K)) O(d(N+K)) ( d d d为位数),空间 O ( N + K ) O(N+K) O(N+K)。
- 稳定性 :稳定。
7.2.8 希尔排序 (Shell Sort)(考纲没有)
- 过程:插入排序的改进版。将数组按增量分组,对每组进行插入排序;逐步缩小增量,重复分组排序;增量减至1时,对整个数组进行插入排序。
- 特点:通过增量跳跃式移动,减少比较和交换次数,提升插入排序效率。
java
void shellSort(int[] arr) {
int n = arr.length;
// 逐步缩小增量gap
for (int gap = n / 2; gap > 0; gap /= 2) {
// 从第gap个元素开始,对每个分组进行插入排序
for (int i = gap; i < n; i++) {
int temp = arr[i];
int j = i;
// 在分组内进行插入排序
while (j >= gap && arr[j - gap] > temp) {
arr[j] = arr[j - gap];
j -= gap;
}
arr[j] = temp;
}
}
}- 复杂度 :时间 O ( n 1.3 ) O(n^{1.3}) O(n1.3) 到 O ( n 2 ) O(n^2) O(n2)(取决于增量序列),空间 O ( 1 ) O(1) O(1)。
- 稳定性 :不稳定(相同元素可能分在不同组中移动)。
7.3 根据不同应用需求选择合适排序算法
| 排序算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 稳定性 | 适用场景 | 不适用场景 |
|---|---|---|---|---|---|---|---|
| 直接插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 | 1. 小规模数据 2. 基本有序的数据 3. 链式存储结构 | 1. 大规模数据 2. 完全逆序数据 |
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 | 1. 教学示例 2. 小规模且接近有序的数据 3. 需要稳定性且数据量小 | 1. 实际生产环境 2. 大规模数据 |
| 简单选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 | 1. 数据量小 2. 交换代价高的场景(如大对象) 3. 不关心稳定性 | 1. 需要稳定性的场景 2. 大规模数据 |
| 快速排序 | O(n log n) | O(n log n) | O(n²) | O(log n)~O(n) | 不稳定 | 1. 大规模随机数据 2. 平均性能要求高 3. 内存空间有限 | 1. 已排序或基本有序数据 2. 需要稳定性的场景 3. 递归深度有限制的环境 |
| 堆排序 | O(n log n) | O(n log n) | O(n log n) | O(1) | 不稳定 | 1. 需要保证最坏情况性能 2. 数据量极大(内存有限) 3. 实时系统(可预测时间) | 1. 需要稳定性的场景 2. 数据量很小 3. 内存访问模式要求高(缓存不友好) |
| 归并排序 | O(n log n) | O(n log n) | O(n log n) | O(n) | 稳定 | 1. 需要稳定性 2. 链表排序 3. 外部排序(大数据) 4. 并行排序 | 1. 内存空间有限的场景 2. 小规模数据(开销大) |
| 基数排序 | O(d·(n+k)) | O(d·(n+k)) | O(d·(n+k)) | O(n+k) | 稳定 | 1. 非负整数排序 2. 字符串排序(字典序) 3. 固定长度关键字 4. 数据范围有限 | 1. 浮点数排序(需转换) 2. 关键字范围过大 3. 负数需要特殊处理 |
说明:
- d:数字的位数或字符串长度
- k:基数范围(如十进制数字,k=10)
- n:数据元素个数
总结口诀:
只有插、冒、归、基是稳定 的。
快、归、堆、基的时间复杂度优于 O ( N 2 ) O(N^2) O(N2)。
快速排序通常是综合性能之王,但最坏情况用堆排序保底,由于内存够用且要稳定用归并。
题型(待更新)
选填作业题
点击跳转 ↑
八股文概念题
1)基本概念部分
-
数据:是描述客观事物的符号的集合,是信息的载体。
-
数据元素 :是组成数据的的基本单位。在程序中作为整体处理。
-
数据项 :是数据元素的组成部分 ,是数据中不可分割的最小单位。一个数据元素可以由若干个数据项组成。
-
数据结构 :由某一数据元素的集合以及该集合所有元素的关系组成,记为
Data_Structure = {D, R},D 是元素集合,R 是元素间关系的有限集合。一个完整的数据结构包含以下三个要素:逻辑结构、存储结构、运算。
- 逻辑结构:从逻辑上描述数据元素之间的相互关系,与数据的存储无关,可以看作是抽象意义上的数据结构。
- 存储结构:指数据结构在计算机中的实际表示(映像),包括数据元素的表示和关系的表示。
- 运算::指施加在数据上的一组操作或算法。它定义了在特定逻辑和存储结构上,允许执行哪些功能
-
数据类型:是一组性质相同的值的集合以及定义在这个集合上的一组操作的总称。(一个类型和定义在该类型上的操作)
-
抽象数据类型 ADT:是指基于一个逻辑类型的数据类型以及这个类型上的一组操作。包含数据对象、数据关系和基本操作。
-
数据结构、数据类型、抽象数据类型的关系:数据类型是抽象数据类型的物理基础,抽象数据类型是数据结构的抽象描述,数据结构是抽象数据类型的物理实现
2)算法分析
- 时间复杂度 :评估 (获知) 算法执行时间的复杂程度
- 空间复杂度 :评估 (获知) 算法执行过程中所需占用的存储空间大小
- 渐进性分析 :指在算法输入规模逐渐增大时,忽略算法执行效率中的(常数项、低阶项 以及具体硬件环境、数据分布等)非本质因素 ,仅关注算法执行时间或空间占用 随输入规模 增长的 "趋势特征",从而客观衡量算法效率优劣的分析方法。
-
Ο标记法(渐进上界,描述最坏情况) :如果存在正常数
c和n₀,使得对所有n ≥ n₀,都有T(n) ≤ c * f(n),则称T(n)是O(f(n))的。 -
Ω标记法(渐进下界,描述最好情况) :如果存在正常数
c和n₀,使得对所有n ≥ n₀,都有T(n) ≥ c * f(n),则称T(n)是Ω(f(n))的。 -
Θ标记法(大Θ记法,渐进紧确界) :如果存在正常数
c₁,c₂和n₀,使得对所有n ≥ n₀,都有c₁ * f(n) ≤ T(n) ≤ c₂ * f(n),则称T(n)是Θ(f(n))的。
- 时空权衡原则:用时间换空间或用空间换时间
3)数据结构
-
线性表 :具有相同数据类型的 n ( n ≥ 0 ) n(n≥0) n(n≥0) 个数据元素的有限序列
-
二叉树(Binary Tree) :n(n≥0)个节点的有限集合,每个节点最多有两个子树(左子树、右子树),子树有左右顺序之分
-
树(Tree) :n(n≥0)个节点的有限集合,存在唯一 "根节点",其余节点划分为互不相交的子树(n=0 时为空树),子树之间没有次序关系。
-
森林(Forest):m(m≥0)棵互不相交的树的集合(m=0 时为空森林,单棵树可视为 m=1 的森林)
-
满二叉树 full binary tree:满二叉树的每一个结点,要么是一个恰有两个非空结点的分支结点要么是一个叶子结点。
-
完全二叉树 complete binary tree:完全二叉树有严格的要求,从根结点起,每一层从左往右填充。一棵高度为d的完全二叉树除了d-1层(最后一层)以外,每一层都是满的
-
Huffman编码:一种不等长编码。高频字符用短码,低频用长码,保证无歧义,且总编码长度最短。
-
二叉搜索树 BST:任意节点左子树所有节点值 < 该节点值 < 右子树所有节点值。
-
堆 :是一种基于数组 实现的完全二叉树 。大顶堆 ,任意节点的值 ≥ \ge ≥ 其子节点的值。
- 并查集:是一种用于管理元素分组的树形数据结构。专门用来处理一些不交集(Disjoint Sets) 的合并与查询问题。它能动态地维护多个互不相交的集合,并支持合并与查找这两个核心操作。
渐进性分析
- 数组求和
java
public class ArraySum {
public static int arraySum(int[] arr) {
int sumVal = 0;
for (int num : arr) {
sumVal += num;
}
return sumVal;
}
}答案:
时间复杂度:O(n)
空间复杂度:O(1)
分析:单循环遍历n个元素,循环内为O(1)操作,时间复杂度O(n);仅用固定额外变量,空间复杂度O(1)。
- 上三角矩阵求和
java
public class UpperTriangleSum {
public static int upperTriangleSum(int[][] matrix) {
int n = matrix.length;
int total = 0;
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
total += matrix[i][j];
}
}
return total;
}
}答案:
时间复杂度:O(n²)
空间复杂度:O(1)
分析:总循环次数为n+(n-1)+...+1 = n(n+1)/2,忽略低阶项和常数,时间复杂度O(n²);无额外动态空间,空间复杂度O(1)。
- 递归二分查找
java
public class BinarySearch {
public static int binarySearchRecursive(int[] arr, int target, int left, int right) {
if (left > right) {
return -1;
}
int mid = (left + right) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] > target) {
return binarySearchRecursive(arr, target, left, mid - 1);
} else {
return binarySearchRecursive(arr, target, mid + 1, right);
}
}
}答案:
时间复杂度:O(log n)
空间复杂度:O(log n)
分析:每次递归缩小一半区间,递归深度log₂n,时间复杂度O(log n);递归栈空间等于深度,空间复杂度O(log n)。
- 数组处理与构建二维列表
java
import java.util.ArrayList;
import java.util.List;
public class ProcessArray {
public static List<List<Integer>> processArray(int[] arr) {
int count = 0;
for (int num : arr) {
count++;
}
List<List<Integer>> result = new ArrayList<>();
for (int i = 0; i < count; i++) {
List<Integer> row = new ArrayList<>();
for (int j = 0; j < count; j++) {
row.add(arr[i] * j);
}
result.add(row);
}
return result;
}
}答案:
时间复杂度:O(n²)
空间复杂度:O(n²)
分析:单循环O(n),嵌套循环O(n²),总复杂度取最高阶O(n²);构建n×n二维集合,空间复杂度O(n²)。
- 归并排序
java
public class MergeSort {
public static int[] mergeSort(int[] arr) {
if (arr.length <= 1) {
return arr;
}
int mid = arr.length / 2;
int[] left = new int[mid];
int[] right = new int[arr.length - mid];
System.arraycopy(arr, 0, left, 0, mid);
System.arraycopy(arr, mid, right, 0, arr.length - mid);
left = mergeSort(left);
right = mergeSort(right);
return merge(left, right);
}
private static int[] merge(int[] left, int[] right) {
int[] res = new int[left.length + right.length];
int i = 0, j = 0, k = 0;
while (i < left.length && j < right.length) {
if (left[i] <= right[j]) {
res[k++] = left[i++];
} else {
res[k++] = right[j++];
}
}
while (i < left.length) res[k++] = left[i++];
while (j < right.length) res[k++] = right[j++];
return res;
}
}答案:
时间复杂度:O(n log n)
空间复杂度:O(n)
分析:递归深度log₂n,每一层合并总时间O(n),总时间O(n log n);合并需临时数组,最大空间O(n),取最高阶为O(n)。
- 计算阶乘
java
public class Factorial {
public static int factorial(int n) {
if (n <= 1) {
return 1;
}
return n * factorial(n - 1);
}
}答案:
时间复杂度:O(n)
空间复杂度:O(n)
分析:函数执行了n次递归调用,每次调用执行常数时间操作,时间复杂度O(n)。递归调用深度为n,每次调用需要在栈中保存返回地址和参数,占用常数空间,空间复杂度O(n)。
- 数组元素查找
java
public class FindMax {
public static int findMax(int[] arr) {
int maxVal = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > maxVal) {
maxVal = arr[i];
}
}
return maxVal;
}
}答案:
时间复杂度:O(n)
空间复杂度:O(1)
分析:遍历数组一次,执行n-1次比较操作,时间复杂度O(n)。只使用了固定数量的变量,与输入规模n无关,空间复杂度O(1)。
- 二分查找(迭代版)
java
public class BinarySearchIterative {
public static int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
}答案:
时间复杂度:O(log n)
空间复杂度:O(1)
分析:最坏情况下每次将搜索范围减半,循环次数为⌊log₂n⌋+1,时间复杂度O(log n)。只使用了固定数量的变量,空间复杂度O(1)。
- 嵌套循环
java
public class TripleNestedLoop {
public static int processMatrix(int n) {
int count = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++) {
count++;
}
}
}
return count;
}
}答案:
时间复杂度:O(n³)
空间复杂度:O(1)
分析:三重嵌套循环,每层循环n次,基本操作执行次数n³,时间复杂度O(n³)。只使用了常数个变量,空间复杂度O(1)。
- 斐波那契数列(递归)
java
public class Fibonacci {
public static int fibonacci(int n) {
if (n <= 1) {
return n;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}
}答案:
时间复杂度:O(2ⁿ)
空间复杂度:O(n)
分析:递归调用形成二叉树,高度约为n,节点总数约为2ⁿ,时间复杂度O(2ⁿ)。递归深度为n,每层调用占用常数栈空间,空间复杂度O(n)。
- 深度优先搜索(DFS)
java
import java.util.HashSet;
import java.util.Set;
public class DFS {
public static void dfs(int[][] graph, int node, Set<Integer> visited) {
if (visited.contains(node)) {
return;
}
visited.add(node);
for (int neighbor : graph[node]) {
dfs(graph, neighbor, visited);
}
}
}答案:
时间复杂度:O(V + E)(V为顶点数,E为边数)
空间复杂度:O(V)
分析:每个顶点被访问一次,每条边被遍历一次(无向图每条边访问两次),时间复杂度O(V + E)。visited集合存储所有顶点占用O(V)空间,递归栈深度在最坏情况下为O(V),空间复杂度O(V)。
- 硬币找零(动态规划)
java
public class CoinChange {
public static int coinChange(int[] coins, int amount) {
int[] dp = new int[amount + 1];
for (int i = 1; i <= amount; i++) {
dp[i] = amount + 1;
}
dp[0] = 0;
for (int coin : coins) {
for (int i = coin; i <= amount; i++) {
dp[i] = Math.min(dp[i], dp[i - coin] + 1);
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
}答案:
时间复杂度:O(k × amount)(k为硬币种类数)
空间复杂度:O(amount)
分析:外层循环遍历硬币列表,设硬币种类数为k;内层循环遍历金额从coin到amount,总操作次数约k × amount,时间复杂度O(k × amount)。使用长度为amount+1的数组dp,空间复杂度O(amount)。
- 查找重复元素
java
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class FindDuplicates {
public static List<Integer> findDuplicates(int[] arr) {
Set<Integer> seen = new HashSet<>();
List<Integer> duplicates = new ArrayList<>();
for (int item : arr) {
if (seen.contains(item)) {
duplicates.add(item);
} else {
seen.add(item);
}
}
return duplicates;
}
}答案:
时间复杂度:O(n)
空间复杂度:O(n)
分析:遍历数组一次,每次操作(查找和插入集合、追加列表)平均为O(1),时间复杂度O(n)。最坏情况下所有元素都不重复,seen集合存储n个元素;duplicates列表在最坏情况下可能存储n/2个元素,空间复杂度O(n)。
- 矩阵旋转
java
public class RotateMatrix {
public static void rotateMatrix(int[][] matrix) {
int n = matrix.length;
// 转置矩阵
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
// 反转每一行
for (int i = 0; i < n; i++) {
for (int j = 0; j < n / 2; j++) {
int temp = matrix[i][j];
matrix[i][j] = matrix[i][n - 1 - j];
matrix[i][n - 1 - j] = temp;
}
}
}
}答案:
时间复杂度:O(n²)
空间复杂度:O(1)
分析:转置操作访问矩阵上三角元素,操作次数为n(n-1)/2,即O(n²);反转每一行需要O(n)时间,共n行,总时间O(n²)。原地操作,仅使用常数个临时变量,空间复杂度O(1)。
树的证明题
-
二叉树基本定理:对任何一棵二叉树T,如果其叶结点数为 n 0 n_0 n0,则双孩子结点数为 n 2 n_2 n2,则有 n 0 = n 2 + 1 n_0 = n_2 + 1 n0=n2+1
证明 :二叉树中,只有三种结点: 叶结点 n 0 n_0 n0,单孩子结点 n 1 n_1 n1,双孩子结点 n 2 n_2 n2,设该树的结点总数为 n n n,则有 n = n 0 + n 1 + n 2 n = n_0 + n_1 + n_2 n=n0+n1+n2,也有 n = 0 × n 0 + 1 × n 1 + 2 × n 2 ⏟ 分支数 + 1 n = \underbrace{0 \times n_0 + 1 \times n_1 + 2 \times n_2}_{分支数} + 1 n=分支数 0×n0+1×n1+2×n2+1,结合这两个式子消去 n n n 即可证明. -
满二叉树定理:非空满二叉树的叶结点数等于其分支结点数+1
证明 :满二叉树无单孩子结点 n 1 = 0 n_1=0 n1=0,其分支结点即为双孩子节点 n 2 n_2 n2,由二叉树基本定理,叶结点数 n 0 n_0 n0 = 分支节点数 n 2 n_2 n2 + 1. -
一棵非空二叉树空子树的数目等于其结点数目+1
证明 :二叉树有 n n n 个结点,每个节点有两个指针,共有 2 n 2n 2n 个,其中非空指针数即为树的边数 n − 1 n-1 n−1,那么空指针数也就是空子树数目为 2 n − ( n − 1 ) = n + 1 2n-(n-1) = n+1 2n−(n−1)=n+1. -
高度为k的二叉树最多有 2 k − 1 ( k ≥ 1 ) 2^k - 1 (k \geq1) 2k−1(k≥1) 个结点
证明 :当二叉树为满二叉树时结点数最多。第 i i i 层最多有 2 i − 1 2^{i-1} 2i−1 个结点,共 k k k 层,故最多结点数为:
∑ i = 1 k 2 i − 1 = 2 k − 1. \sum_{i=1}^k 2^{i-1} = 2^k - 1. i=1∑k2i−1=2k−1. -
具有 n n n 个结点的完全二叉树的高度为 ⌊ l o g 2 n ⌋ + 1 \lfloor log_2 n \rfloor +1 ⌊log2n⌋+1 或 ⌈ l o g 2 ( n + 1 ) ⌉ \lceil log_2(n+1) \rceil ⌈log2(n+1)⌉
证明 :设高度为 h h h。由完全二叉树定义,前 h − 1 h-1 h−1 层满(共 2 h − 1 − 1 2^{h-1}-1 2h−1−1 个结点),第 h h h 层至少 1 1 1 个、至多 2 h − 1 2^{h-1} 2h−1 个结点,故:
2 h − 1 ≤ n ≤ 2 h − 1 < 2 h 2^{h-1} \le n \le 2^h - 1 < 2^h 2h−1≤n≤2h−1<2h取对数得
h − 1 ≤ log 2 n < h h-1 \le \log_2 n< h h−1≤log2n<h
log 2 n < h ≤ log 2 n + 1 \log_2 n < h \le \log_2 n + 1 log2n<h≤log2n+1
h = ⌊ log 2 n ⌋ + 1. h = \lfloor \log_2 n \rfloor + 1. h=⌊log2n⌋+1.同时由 2 h − 1 < n + 1 ≤ 2 h 2^{h-1} < n+1 \le 2^h 2h−1<n+1≤2h 取对数可得:
h − 1 < log 2 ( n + 1 ) ≤ h h-1 < \log_2(n+1) \leq h h−1<log2(n+1)≤h
h = ⌈ log 2 ( n + 1 ) ⌉ . h = \lceil \log_2 (n+1) \rceil. h=⌈log2(n+1)⌉.
二叉树与树和森林的转换
- 树与二叉树:左孩子右兄弟法
右连所有兄弟、删非长子(留左长子)。反之同理,操作可逆。
【树】 【中间步骤】 【二叉树】
A A A
/ | \ / /
B C D B-->C-->D B
/ \ / / \
E F E-->F E C
\ \
F D- 森林与二叉树
树转二叉树、右连下一颗树。反之同理,操作可逆。
【原始森林】 【树转为二叉树】 【合并后的二叉树】
树1: 树2: 树1: 树2: A
A X A X / \
/ \ / / / B X <-- A右接X
B C Y B Y / /
/ C Y
C画递归调用栈
以阶乘为例
java
public class Factorial {
public static int factorial(int n) {
// 基线条件 (Base Case)
if (n == 0 || n == 1) {
return 1;
}
// 递归条件 (Recursive Step)
else {
return n * factorial(n - 1);
}
}
public static void main(String[] args) {
int n = 3; // 我们用 n=3 来演示,方便画图
int result = factorial(n);
System.out.println(n + "! = " + result);
}
}递归调用栈(这种画法没有问题)
| |
| |
|---------------------------|
| factorial(1) | <--- 栈顶
| 参数 n=1 |
| 命中基准条件: return 1 |
|---------------------------|
| factorial(2) |
| 参数 n=2 |
| 等待: 2 * factorial(1) |
|---------------------------|
| factorial(3) |
| 参数 n=3 |
| 等待: 3 * factorial(2) |
|---------------------------|
| main 方法 | <--- 栈底
| 调用 factorial(3) |
-----------------------------时序图
Main factorial(3) factorial(2) factorial(1) ⬇️ 递过程 (压栈) 调用 factorial(3) 需计算 3 * factorial(2) 调用 factorial(2) 需计算 2 * factorial(1) 调用 factorial(1) n=1, 命中基准条件 直接返回 1 ⬆️ 归过程 (出栈) return 1 计算 2 * 1 = 2 return 2 计算 3 * 2 = 6 return 6 Main factorial(3) factorial(2) factorial(1)
再以 fibonacci 函数为例
java
public class Fibonacci {
// 递归计算斐波那契数列
public static int fib(int n) {
// 基准情况 (Base Case)
if (n <= 1) {
return n;
}
// 递归步骤
return fib(n - 1) + fib(n - 2);
}
public static void main(String[] args) {
int n = 4;
System.out.println("fib(" + n + ") = " + fib(n));
}
}- 调用 6. 调用 2. 调用 5. 调用 3. 调用 4. 调用 7. 调用 8. 调用 fib(4) fib(3) fib(2) fib(2) fib(1) = 1 fib(1) = 1 fib(1) = 1 fib(0) = 0 fib(0) = 0
(呃啊上课没听 不知道这样画可以不 因为Fibonacci一次调用两个 所以没法画成线性结构)
画邻接表
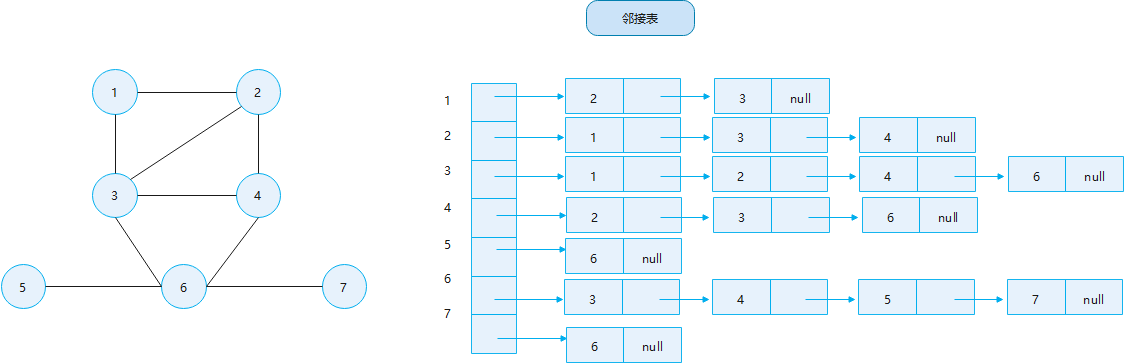
(借yjq学长笔记的一张图)
邻接表画成这样应该就可以了吧
补充:怎么写伪代码
1. 核心原则 (The Golden Rules)
- 忽略语法细节 :不需要写分号
;,不需要声明变量类型(int, String),不需要写public static void main。 - 利用缩进 :用缩进(Indentation)来表示层级关系,替代大括号
{}。 - 关键字大写 :为了区分逻辑指令和变量名,通常将关键字(如
IF,ELSE,FOR)全大写。 - 自然语言 :对于复杂的数学操作或库函数,可以直接用一句话描述(例如:
Sort list或Swap a and b)。
2. 常用词汇表 (Cheat Sheet)
- 赋值 (Assignment)
x ← 5(最标准,箭头表示赋值,避免和等于号混淆)Set x to 5x = 5(也可以,但有时会和判断相等混淆)
- 算术运算
+,-,*,/,MOD(取余)
- 比较
=,≠,<,>,≤,≥
- 输入/输出
READ,INPUT,GETPRINT,OUTPUT,DISPLAY,RETURN
- 分支 (决策)
IF ... THEN ...ELSE IF ... THEN ...ELSE ...ENDIF(明确结束块)
- 循环
WHILE ... DO ... ENDWHILEFOR ... DO ... ENDFORREPEAT ... UNTIL ...
- 函数
FUNCTION name(arguments)CALL nameENDFUNCTION
3. 例子
例子 A:简单的 IF-ELSE (阶乘)
思路:如果是 0 或 1,返回 1,否则返回 n * 递归。
text
FUNCTION Factorial(n)
IF n = 0 OR n = 1 THEN
RETURN 1
ELSE
RETURN n * Factorial(n - 1)
ENDIF
ENDFUNCTION例子 B:循环结构 (数组求和)
思路:拿到一个数组,遍历它,累加到一个 total 变量里。
text
FUNCTION SumArray(arr)
SET total ← 0
SET length ← length of arr
FOR i FROM 0 TO length - 1 DO
total ← total + arr[i]
ENDFOR
RETURN total
ENDFUNCTION例子 C:稍微复杂一点的逻辑 (查找最大值)
思路:假设第一个是最大的,然后去和剩下的比。
text
FUNCTION FindMax(numbers)
IF numbers is empty THEN
RETURN error
ENDIF
SET maxVal ← numbers[0]
FOR EACH num IN numbers DO
IF num > maxVal THEN
maxVal ← num
ENDIF
ENDFOR
RETURN maxVal
ENDFUNCTION4. 写伪代码的步骤
如果你在面试或做题,碰到一个新问题,按这个步骤来:
- 用人话描述:先别管格式,在脑子里或者纸上想一遍流程。"先拿到A,如果A大于10,就做这个,否则做那个。"
- 翻译成关键字 :把"如果"改成
IF,把"重复做"改成WHILE或FOR。 - 处理缩进 :把属于
IF内部的逻辑往右推一格。 - 检查逻辑:人肉跑一遍代码(Trace),看看有没有死循环或漏掉的情况。
5. 常见的坑
- ❌ 太像代码 :不要写
System.out.println("Hello")。- ✅ 修正 :
PRINT "Hello"
- ✅ 修正 :
- ❌ 太抽象 :不要写
Process the data(除非那个处理过程极其复杂且不重要)。- ✅ 修正:写出具体的循环或判断逻辑。
- ❌ 滥用语法 :不要纠结是
i++还是i = i + 1,伪代码里两个都行,甚至写Increment i也行。
22年真题回忆版(待答)
一、
1、渐进分析定义。
- 指在算法输入规模逐渐增大时,忽略算法执行效率中的(常数项、低阶项 以及具体硬件环境、数据分布等)非本质因素 ,仅关注算法执行时间或空间占用 随输入规模 增长的 "趋势特征",从而客观衡量算法效率优劣的分析方法。
2、给复杂度排序。
| 复杂度 | 名称 | 随着 n 增大,耗时增长趋势 | 评价 |
|---|---|---|---|
| O ( 1 ) O(1) O(1) | 常数阶 | 基本不变 | 极好 |
| O ( log n ) O(\log n) O(logn) | 对数阶 | 增长极慢 | 优秀 |
| O ( n ) O(n) O(n) | 线性阶 | 匀速增长 | 良好 |
| O ( n log n ) O(n \log n) O(nlogn) | 线性对数 | 稍快于线性 | 还可以 (排序的极限) |
| O ( n 2 ) O(n^2) O(n2) | 平方阶 | 抛物线增长 | 差 (小数据可用) |
| O ( 2 n ) O(2^n) O(2n) | 指数阶 | 爆炸式增长 | 极差 (通常需要优化) |
| O ( n ! ) O(n!) O(n!) | 阶乘阶 | 垂直式增长 | 灾难 |
3、给代码分析复杂度。
- 见题型-渐进性分析
二、
1、关于线性表概念的三个判断题(原老师的选择题作业中涉及过)。
2、用循环数组实现一个特殊的队列,伪代码写实现方式。
- 给出用循环数组实现一个普通队列
java
CLASS CircularQueue
// 属性定义
capacity: 整数 // 数组总大小
array: 数组 // 存储数据的容器
front: 整数 // 队头指针
rear: 整数 // 队尾指针
count: 整数 // 当前元素数量
// 初始化函数
FUNCTION Init(size)
capacity ← size
array ← create new Array of size [capacity]
front ← 0
rear ← 0
count ← 0
ENDFUNCTION
// 入队
FUNCTION Enqueue(item)
// 1. 检查溢出
IF count == capacity THEN
PRINT "Error: Queue is Full"
RETURN False
ENDIF
// 2. 存入数据
array[rear] ← item
// 3. 移动尾指针 (核心:环形回绕)
rear ← (rear + 1) MOD capacity
// 4. 更新计数
count ← count + 1
RETURN True
ENDFUNCTION
// 出队
FUNCTION Dequeue()
// 1. 检查下溢
IF count == 0 THEN
PRINT "Error: Queue is Empty"
RETURN Null
ENDIF
// 2.以此取出数据
item ← array[front]
// 3. 移动头指针 (核心:环形回绕)
front ← (front + 1) MOD capacity
// 4. 更新计数
count ← count - 1
RETURN item
ENDFUNCTION
// 查空
FUNCTION IsEmpty()
RETURN (count == 0)
ENDFUNCTION
// 查满
FUNCTION IsFull()
RETURN (count == capacity)
ENDFUNCTION
// 查看队头元素但不取出
FUNCTION Peek()
IF count == 0 THEN
RETURN Null
ENDIF
RETURN array[front]
ENDFUNCTION
ENDCLASS三、
1、能用递归解决问题的条件。
- 一个大问题可以拆解为"更小"的同类问题
- 必须有一个明确的"停止点"
- 递归的过程必须向"停止点"逼近
2、分析一个递归函数结果。
3、画递归函数调用栈。
- 见题型-画递归调用栈
四、
1、堆是什么,证明完全二叉树的高度是 ⌈ l o g 2 ( n + 1 ) ⌉ \lceil log_2{(n+1)} \rceil ⌈log2(n+1)⌉。
- 堆是一种基于数组 实现的完全二叉树 。大顶堆 ,任意节点的值 ≥ \ge ≥ 其子节点的值。
- 具有 n n n 个结点的完全二叉树的高度为 ( ⌊ l o g 2 n ⌋ + 1 \lfloor log_2 n \rfloor +1 ⌊log2n⌋+1 或 ) ⌈ l o g 2 ( n + 1 ) ⌉ \lceil log_2(n+1) \rceil ⌈log2(n+1)⌉
证明 :设高度为 h h h。由完全二叉树定义,前 h − 1 h-1 h−1 层满(共 2 h − 1 − 1 2^{h-1}-1 2h−1−1 个结点),第 h h h 层至少 1 1 1 个、至多 2 h − 1 2^{h-1} 2h−1 个结点,故:
2 h − 1 ≤ n ≤ 2 h − 1 2^{h-1} \le n \le 2^h - 1 2h−1≤n≤2h−1
由 2 h − 1 < n + 1 ≤ 2 h 2^{h-1} < n+1 \le 2^h 2h−1<n+1≤2h 取对数可得:
h − 1 < log 2 ( n + 1 ) ≤ h h-1 < \log_2(n+1) \leq h h−1<log2(n+1)≤h
h = ⌈ log 2 ( n + 1 ) ⌉ . h = \lceil \log_2 (n+1) \rceil. h=⌈log2(n+1)⌉.
2、给一个数组依次插入 BST,并画出。
arr = [41, 20, 65, 11, 29, 50, 91]
- 比当前节点小 ,往左走。
- 比当前节点大 ,往右走。
- 如果有空位,就坐下。
11 20 29 41 50 65 91
3、二叉树化森林。
[原始森林] [每棵树各自转换为二叉树] [最终合并后的二叉树]
树1 树2 树3 二叉树1 二叉树2 二叉树3 (合并结果)
A X M A X M A --->1 root
/ \ / \ /| / / / / \
B C Y Z P Q B Y P B X --->2 root
/ / | / \ \ \ / \ / \
E F R E C Z Q E C Y M --->3 root
/ / / \ /
F R F Z P
\
Q
/
R4、把这个森林当做并查集,画两次 union 后结果。
对于两次union,我理解的是,原题的森林应该是三个树,然后两次union将这三个树合成一个树。
按照重量权衡平衡原则,小树挂在大树下,所以树2挂在树1下变成新树,树3再挂在新树下。
[原始森林]
树1 树2 树3
A X M
/ \ / \ /|
B C Y Z P Q
/ / |
E F R
[A] <--- 最终的集合代表 (根)
/ / \ \
/ / \ \
[B] [C] [X] [M] <--- 原来的根 X, M 变成了 A 的直接子节点
/ / / \ | \
[E] [F] [Y] [Z][P][Q]
\
[R]五、
1、给一个包含十余个顶点的图,画邻接表。
(这个例子实际上就是在"题型-画邻接表"学长笔记那个图)
1 2 3 4 5 6 7
这里用更简洁的形式表示邻接表:
- 1: 2, 3
- 2: 1, 3, 4
- 3: 1, 2, 4, 6
- 4: 2, 3, 6
- 5: 6
- 6: 3, 4, 5, 7
- 7: 6
2、用邻接表画深搜生成树。
我们首先要根据邻接表 严格按照这个顺序执行 DFS ,记录下搜索过程中真正走过的那些边,这些边构成的树就是"深搜生成树"。
邻接表中节点的顺序不同 ,生成的树形状也会不同。
最终的深搜生成树 (DFS Spanning Tree)。虚线表示图中存在但 DFS 没走的边(称为回边)。
1 2 3 4 5 6 7
生成的树形结构是长这样的(一条很深的长链):
text
1
|
2
|
3
|
4
|
6
/ \
5 73、Prim 算法画出最小支撑树。
4、画出最短路径树。
六、(guide上的原版真题回忆版在本题有一堆概念矛盾模糊之处 所以博主自行对题目做了更改)
1、给一个数组,用(闭散列)线性探测法,画出将所有数放入散列表的结果,算平均成功搜索长度。
假设数组为 [12, 25, 45, 15, 38, 28]
散列函数: H ( k e y ) = k e y ( m o d 13 ) H(key) = key \pmod{13} H(key)=key(mod13)
表长 (Table Size): m = 13 m = 13 m=13 (下标 0-12)
- 算出 H a s h = k e y % 13 Hash = key \% 13 Hash=key%13。
- 如果位置是空的,放入。
- 如果位置有人(冲突),往后找下一个位置 ( i n d e x + 1 index + 1 index+1),直到找到空位。
插入过程:
- 12 : 12 % 13 = 12 12 \% 13 = 12 12%13=12。位置12空,放入。
- 比较次数: 1
- 25 : 25 % 13 = 12 25 \% 13 = 12 25%13=12。位置12被(12)占了 -> 探测下个位置(0)。位置0空,放入。
- 比较次数: 2 (查12, 查0)
- 45 : 45 % 13 = 6 45 \% 13 = 6 45%13=6。位置6空,放入。
- 比较次数: 1
- 15 : 15 % 13 = 2 15 \% 13 = 2 15%13=2。位置2空,放入。
- 比较次数: 1
- 38 : 38 % 13 = 12 38 \% 13 = 12 38%13=12。位置12占了 -> 位置0占了 -> 位置1空,放入。
- 比较次数: 3 (查12, 查0, 查1)
- 28 : 28 % 13 = 2 28 \% 13 = 2 28%13=2。位置2占了 -> 位置3空,放入。
- 比较次数: 2 (查2, 查3)
散列表结果:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ... | 12 |
|---|---|---|---|---|---|---|---|---|---|
| 值 | 25 | 38 | 15 | 28 | 45 | ... | 12 |
平均查找长度 (ASL Success):
总比较次数 = 1 + 2 + 1 + 1 + 3 + 2 = 10 1 + 2 + 1 + 1 + 3 + 2 = 10 1+2+1+1+3+2=10
A S L = 10 6 ≈ 1.67 ASL = \frac{10}{6} \approx 1.67 ASL=610≈1.67
ASL Unsuccess 计算: 总次数 = 5 + 4 + 3 + 2 + 1 + 1 + 2 + 1 + 1 + 1 + 1 + 1 + 6 = 29 总次数 = 5+4+3+2+1+1+2+1+1+1+1+1+6 = 29 总次数=5+4+3+2+1+1+2+1+1+1+1+1+6=29 A S L u n s u c c e s s = 29 13 ≈ 2.23 ASL_{unsuccess} = \frac{29}{13} \approx 2.23 ASLunsuccess=1329≈2.23 (分母是表长 13,不是元素个数 6)
2、用开散列法(闭地址/链式),画出散列表,算平均成功搜索长度 。
规则:
- 算出 H a s h = k e y % 13 Hash = key \% 13 Hash=key%13。
- 直接挂在对应下标的链表后面(通常采用头插法 或尾插法 ,考试中画图顺序通常不影响查找长度,这里用尾插法展示)。
插入过程:
- 12 : 12 % 13 = 12 12 \% 13 = 12 12%13=12。放入下标12的链表。 (查找长度: 1)
- 25 : 25 % 13 = 12 25 \% 13 = 12 25%13=12。放入下标12的链表。 (查找长度: 2,因为排在12后面)
- 45 : 45 % 13 = 6 45 \% 13 = 6 45%13=6。放入下标6的链表。 (查找长度: 1)
- 15 : 15 % 13 = 2 15 \% 13 = 2 15%13=2。放入下标2的链表。 (查找长度: 1)
- 38 : 38 % 13 = 12 38 \% 13 = 12 38%13=12。放入下标12的链表。 (查找长度: 3,排在12, 25后面)
- 28 : 28 % 13 = 2 28 \% 13 = 2 28%13=2。放入下标2的链表。 (查找长度: 2,排在15后面)
散列表结果图:
text
0 ^
1 ^
2 --> [15] --> [28] ^
3 ^
4 ^
5 ^
6 --> [45] ^
...
12 --> [12] --> [25] --> [38] ^平均查找长度 (ASL Success):
总比较次数 = 1 + 2 + 1 + 1 + 3 + 2 = 10 1 + 2 + 1 + 1 + 3 + 2 = 10 1+2+1+1+3+2=10
A S L = 10 6 ≈ 1.67 ASL = \frac{10}{6} \approx 1.67 ASL=610≈1.67
ASL Unsuccess 计算: 直接把所有链表的长度加起来即可 。
A S L u n s u c c e s s = 6 13 ≈ 0.46 ASL_{unsuccess} = \frac{6}{13} \approx 0.46 ASLunsuccess=136≈0.46
(注:如果使用头插法,链表顺序是倒过来的,ASL计算逻辑也是看它在第几个节点)
3、问开/闭散列法删除元素时能不能直接删去。
闭散列法(开地址法)不能。
原因:
在使用线性探测时,元素可能会因为冲突而被"挤"到后面的位置。查找过程依赖于连续性 ------ 只要没遇到"空位",就会一直往后找。
必须使用 惰性删除 (Lazy Deletion) 。
不直接把位置清空,而是放一个特殊的标记(比如 DELETED 或 TOMBSTONE 墓碑标记)。
- 查找时:遇到标记继续往后找。
- 插入时:遇到标记可以视为"空位"填入新值。
开散列法(闭地址法/链式)可以直接删。
七、
1、给一个数组,写出选择排序第三趟后的数组。
2、写出快排第一趟后的数组(选轴是三选一,分组用上课讲的)。
3、用基数为 5 的基数排序,写出第二趟收集分发后的结果。
4、用堆排,先画出数组转换成的大项堆,再写出第三趟后的结果。
算法题:
1、手写代码写一个桶排。
2、手写代码,用递归写计算二叉树奇偶层节点元素差的和。