单链表的应用
练习1---用快慢指针找倒数第 k 个节点

(1)算法的基本设计思想
双指针:快慢指针
定义两个指针变量 fast 和 slow ,初始时均指向头结点的下一个结点(链表的第一个结点)。 fast指针沿链表移动:当 fast 指针移动到第 k 个结点时, fast 指针开始与 slow 指针同步移动:当 fast 指针移动到最后一个结点时, slow 指针所指示结点为倒数第 k 个结点。以上过程对链表仅进行一遍扫描。
(2)算法的详细实现步骤
①fast 和 slow 指向链表表头结点的下一个结点; ②快指针提前走 k 步; ③快慢指针同步移动至快指针到末尾; ④ 输出该结点的 data 域的值,返回; ⑤算法结束
(3)关键算法:
c
int findNodeFS(Node*L,int k) {
Node* fast = L->link;
Node* slow = L->link;
for (int i = 0; i < k; i++)
{
fast = fast->link;
}
while (fast != NULL)
{
fast = fast->link;
slow = slow->link;
}
printf("倒数第%d个节点值为%d\n", k, slow->data);
return 1;
}完整代码:
c
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct node {
ElemType data;
struct node* link;
}Node;
//初始化
Node* initList()
{
Node* head = (Node*)malloc(sizeof(Node));
head->data = 0;
head->link = NULL;
return head;
}
int findNodeFS(Node*L,int k) {
Node* fast = L->link;
Node* slow = L->link;
for (int i = 0; i < k; i++)
{
fast = fast->link;
}
while (fast != NULL)
{
fast = fast->link;
slow = slow->link;
}
printf("倒数第%d个节点值为%d\n", k, slow->data);
return 1;
}
//尾插法
Node* get_tail(Node* L) {
Node* p = L;
while (p->link != NULL) {
p = p->link;
}
return p;
}
int insertTail(Node* L, ElemType e) {
Node* tail=get_tail(L);
Node* p = (Node*)malloc(sizeof(Node));
//赋值并连接节点
p->data = e;
tail->link = p;
p->link = NULL;
return 1;
}
//遍历
void PrintNode(Node*L)
{
Node* p = L->link;
while (p != NULL) {
printf("%d ", p->data);
p = p->link;
}
printf("\n");
}
//释放链表
void freeList(Node* L) {
Node* p = L->link;
Node* q;
while (p != NULL) {
q = p->link;
free(p);
p = q;
}
L->link = NULL;
}
int main() {
Node* list = initList();
insertTail(list, 10);
insertTail(list, 20);
insertTail(list, 30);
insertTail(list, 40);
insertTail(list, 50);
insertTail(list, 60);
insertTail(list, 70);
PrintNode(list);
findNodeFS(list, 3);
freeList(list);
return 0;
}运行结果:
10 20 30 40 50 60 70
倒数第3个节点值为50
练习2---两链表公共后缀
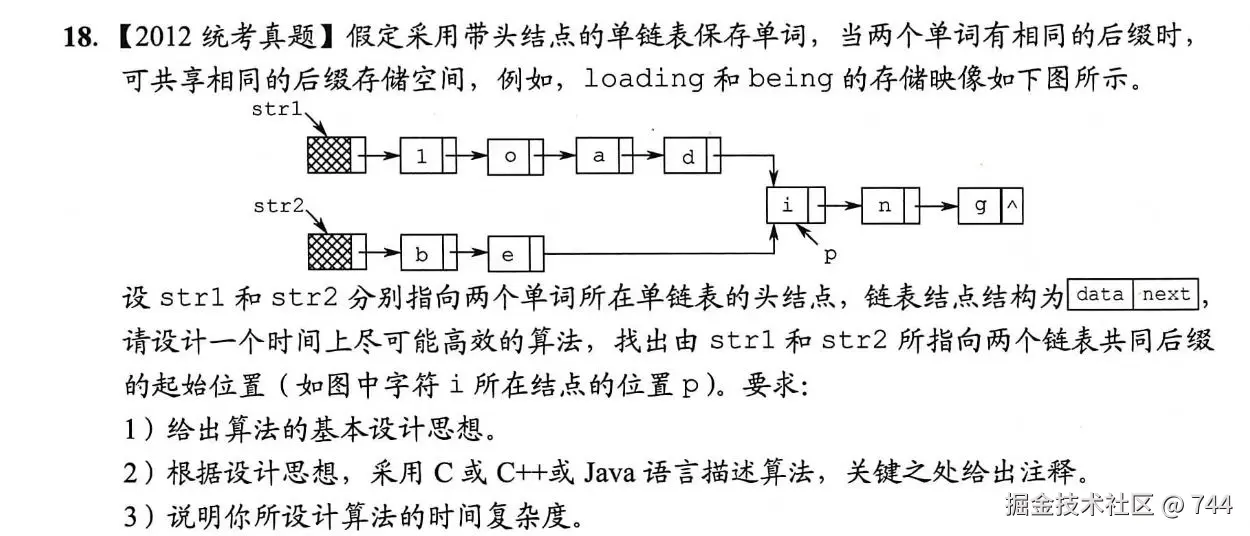
(1)算法基本设计思路
第一步:分别求出两个链表的长度m和n
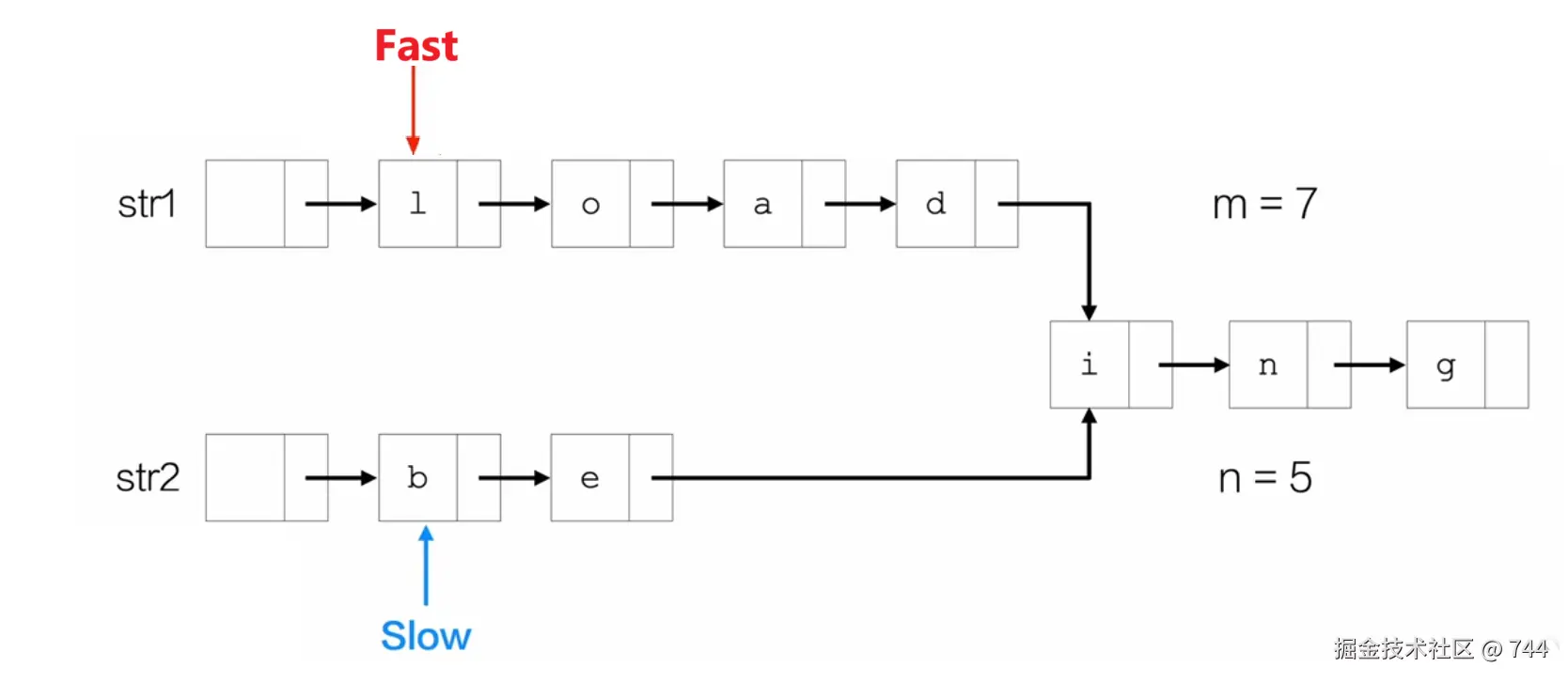
第二步:Fast指针指向较长的链表,先走m-n或n-m步。
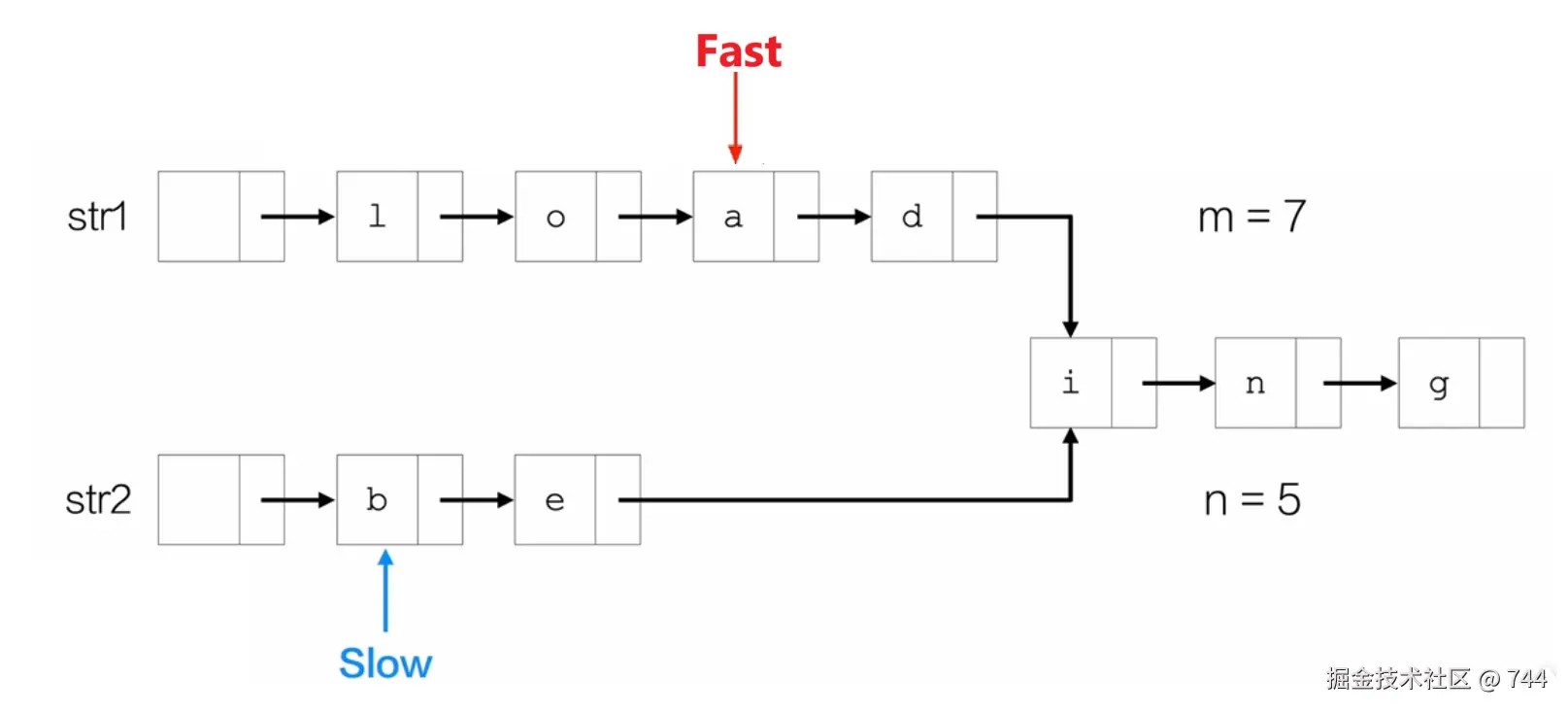 第三步:同步移动指针,判断是否指向同一个节点。
第三步:同步移动指针,判断是否指向同一个节点。
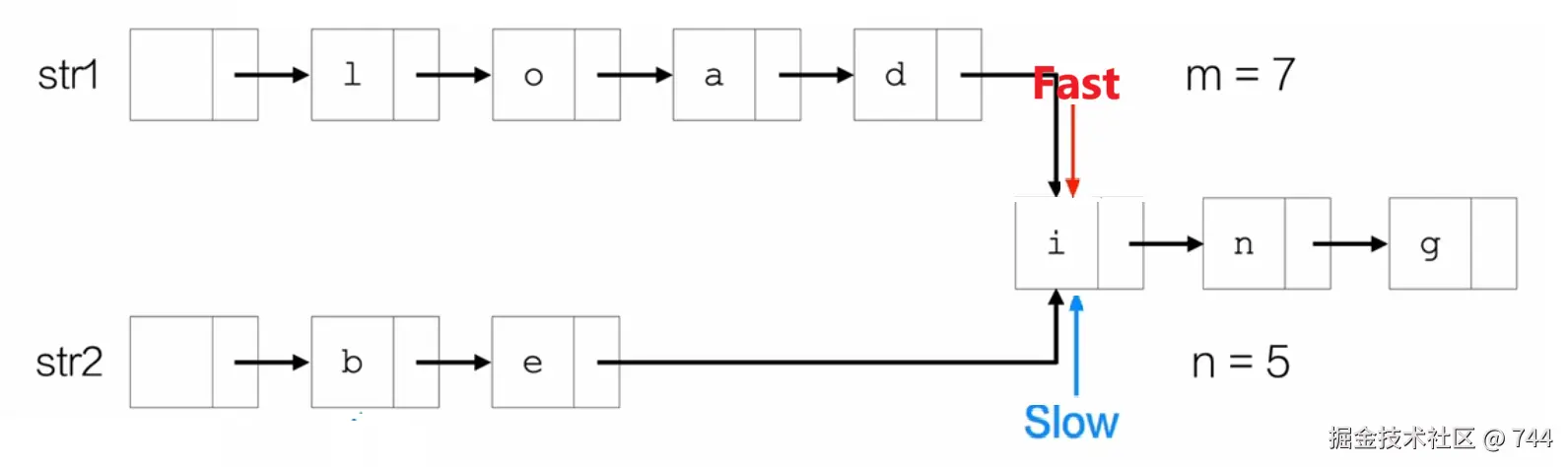
完整代码:
c
#include<stdio.h>
#include<stdlib.h>
typedef char ElemType;
typedef struct node {
ElemType data;
struct node* next;
}Node;
//初始化
Node* initList()
{
Node* head = (Node*)malloc(sizeof(Node));
head->data = 0;
head->next = NULL;
return head;
}
//初始化节点(带节点数据参数)
Node* initListWithElem(ElemType e) {
Node* node = (Node*)malloc(sizeof(Node));
node->data = e;
node->next = NULL;
return node;
}
//获取链表长度
int getLength(Node* L) {
Node* p = L->next;
int len = 0;
while (p != NULL) {
p = p->next;
len++;
}
return len;
}
//
Node* findCommonSuff(Node* str1, Node* str2)
{
if (str1 == NULL || str2 == NULL)
{
return NULL;
}
int m = getLength(str1);
int n = getLength(str2);
Node* longList = str1->next;
Node* shortList = str2->next;
if (n > m) {
longList = str2->next;
shortList = str1->next;
}
int diff = abs(m - n);//m n的差值
for (int i = 0; i < diff; i++)
{
if (longList == NULL) break;
longList = longList->next;
}
while (longList!=NULL&&shortList!=NULL)
{
if (longList == shortList)
{
return longList;
}
longList = longList->next;
shortList = shortList->next;
}
return NULL;
}
//尾插法
Node* get_tail(Node* L)
{
Node* p = L;
while (p->next != NULL)
{
p = p->next;
}
return p;
}
Node* TailList(Node* L, ElemType e)
{
Node* tail = get_tail(L);
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
tail->next = p;
p->next = NULL;
return p;
}
//尾插法(节点)
Node* insertTailWithNode(Node* L, Node* node) {
Node* tail = get_tail(L);
tail->next = node;
node->next = NULL;
return node;
}
//遍历
void PrintList(Node* L)
{
Node* p = L->next;
while (p != NULL) {
printf("%c ", p->data);
p = p->next;
}
printf("\n");
}
int main() {
Node* str1 = initList();
Node* str2 = initList();
TailList(str1, 'l');
TailList(str1, 'o');
TailList(str1, 'a');
TailList(str1, 'd');
TailList(str2, 'b');
TailList(str2, 'e');
//创建带数据域的新节点
Node* node1 = initListWithElem('i');
Node* node2 = initListWithElem('n');
Node* node3 = initListWithElem('g');
//让str1和str2都指向 i n g
insertTailWithNode(str1, node1);
insertTailWithNode(str1, node2);
insertTailWithNode(str1, node3);
insertTailWithNode(str2, node1);
insertTailWithNode(str2, node2);
insertTailWithNode(str2, node3);
//遍历
PrintList(str1);
PrintList(str2);
Node*com=findCommonSuff(str1, str2);
printf("%c ", com->data);
}运行结果:
l o a d i n g
b e i n g
i
(3)时间复杂度:O(m+n)
练习3---用辅助数组删除绝对值重复节点
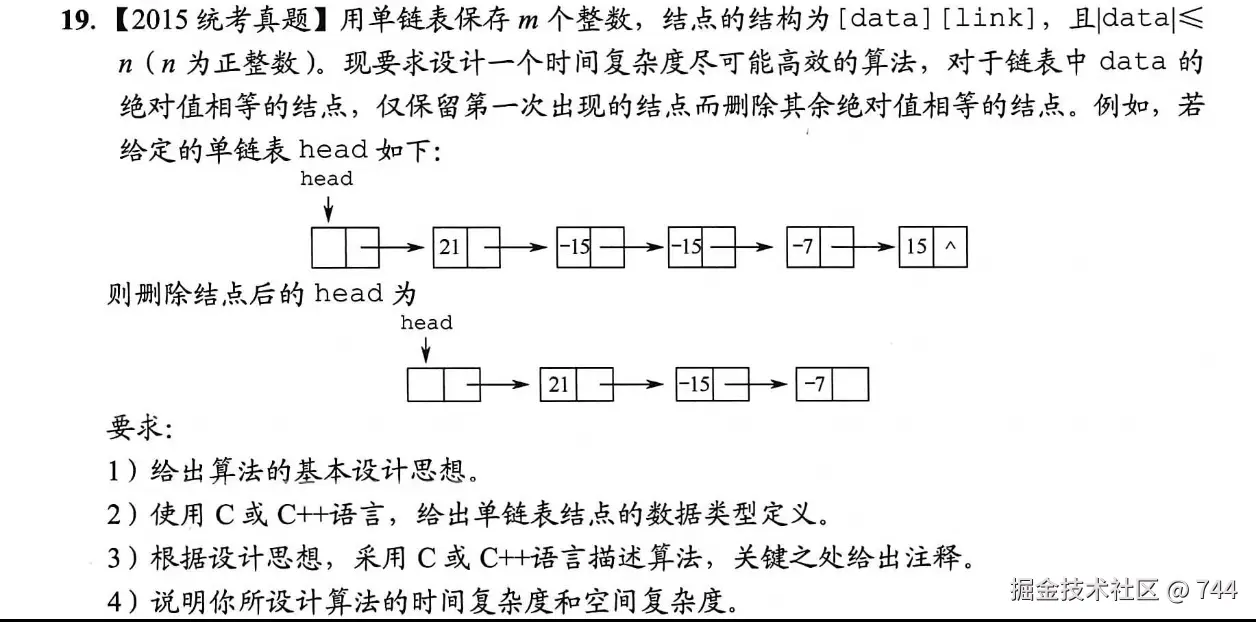
(1)算法基本设计思想
利用空间换时间的策略,借助辅助数组记录链表中已出现的节点绝对值:
-
由于
|data| ≤ n,创建大小为n+1的辅助数组(下标对应节点绝对值),初始值为 0; -
遍历链表,对每个节点取其
data的绝对值,检查辅助数组对应下标的值:- 若为 0,说明该绝对值首次出现,保留节点并将数组对应值设为 1;
- 若为 1,说明该绝对值已出现过,删除当前节点。
 (2) 单链表结点的数据类型定义
(2) 单链表结点的数据类型定义
c
typedef struct node {
int data; // 数据域
struct node* link; // 指针域,指向下一个结点
} Node;(3)关键算法:
c
void removeNode(Node* L, int n)
{
Node* p = L; // p指向当前节点的前驱(从头结点开始,方便删除操作)
int index; //作为数组下标
int* q = (int*)malloc(sizeof(int) * (n + 1));//给数组分配空间
//遍历数组,初始化值为0
for (int i = 0; i < n + 1; i++)
{
*(q + i) = 0;
}
while (p->next != NULL)
{
index = abs(p->next->data);//获取绝对值
if (*(q + index) == 0)
{
*(q + index) = 1;
p = p->next;
}
else // 重复出现,删除p的后继节点
{
Node* temp = p->next; // 保存待删除节点
p->next = temp->next; // 跳过待删除节点
free(temp);
//此处p不后移,因为新的p->next需要重新检查
}
}
free(q);//释放数组
}完整代码:
c
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct node {
ElemType data;
struct node* next;
}Node;
//初始化
Node* initList()
{
Node* head = (Node*)malloc(sizeof(Node));
head->data = 0;
head->next = NULL;
return head;
}
void removeNode(Node* L, int n)
{
Node* p = L; // p指向当前节点的前驱(从头结点开始,方便删除操作)
int index; //作为数组下标
int* q = (int*)malloc(sizeof(int) * (n + 1));//给数组分配空间
//遍历数组,初始化值为0
for (int i = 0; i < n + 1; i++)
{
*(q + i) = 0;
}
while (p->next != NULL)
{
index = abs(p->next->data);//获取绝对值
if (*(q + index) == 0)
{
*(q + index) = 1;
p = p->next;
}
else // 重复出现,删除p的后继节点
{
Node* temp = p->next; // 保存待删除节点
p->next = temp->next; // 跳过待删除节点
free(temp);
//此处p不后移,因为新的p->next需要重新检查
}
}
free(q);//释放数组
}
//尾插法
Node* get_tail(Node* L)
{
Node* p = L;
while (p->next != NULL)
{
p = p->next;
}
return p;
}
Node* TailList(Node* L, ElemType e)
{
Node* tail = get_tail(L);
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
tail->next = p;
p->next = NULL;
return p;
}
//遍历
void PrintList(Node* L)
{
Node* p = L->next;
while (p != NULL)
{
printf("%d ",p->data);
p = p->next;
}
printf("\n");
}
int main() {
Node* list = initList();
TailList(list, 21);
TailList(list, -15);
TailList(list, -15);
TailList(list, 7);
TailList(list, 15);
PrintList(list);
removeNode(list, 21);
PrintList(list);
}运行结果:
21 -15 -15 7 15
21 -15 7
反转链表
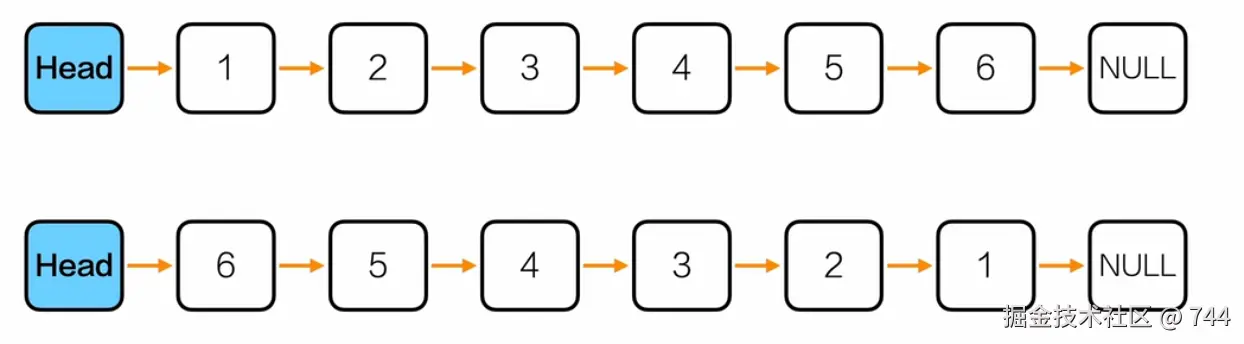
核心思路(迭代法,最优
通过 3 个指针(
first/second/third)逐步反转节点指向:
- 初始化
first=NULL(反转后的尾节点)、second=head->next(当前待反转节点,跳过头结点);- 遍历链表,每次先保存
second的后继节点(third=second->next);- 将
second的next指向first(反转指向);first和second分别后移(first=second,second=third);- 遍历结束后,将头结点
hd->next指向first(新的链表头)。
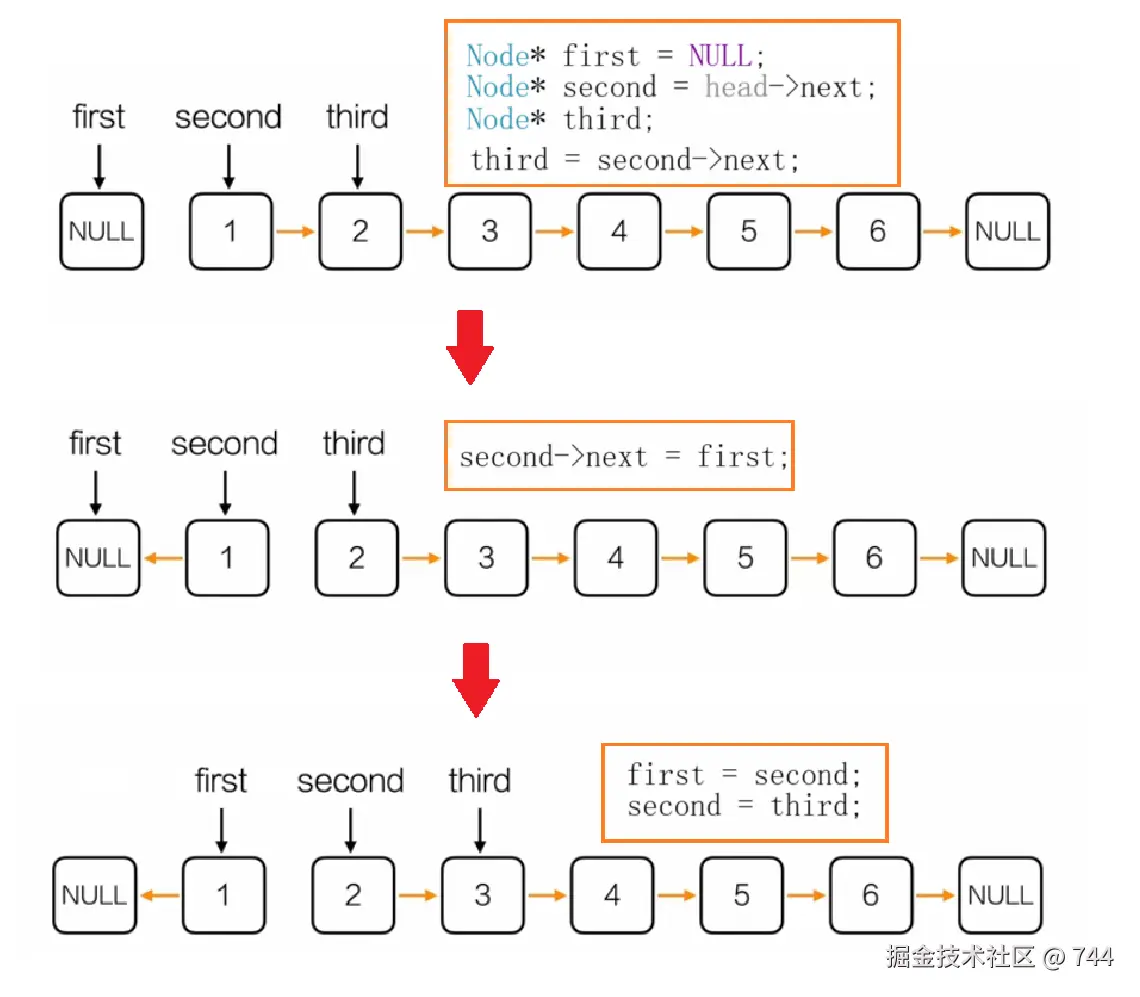
最后一次情况如下图:
头节点指向fiest head->next = first;
c
Node* reverseList(Node* head)
{
Node* first = NULL;
Node* second = head->next;
Node* third;
while (second != NULL) {
third = second->next;
second->next = first;
first = second;
second = third;
}
head->next = first;
}完整代码:
c
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct node {
ElemType data;
struct node* next;
}Node;
//初始化
Node* initList()
{
Node* head = (Node*)malloc(sizeof(Node));
head->data = 0;
head->next = NULL;
return head;
}
//尾插法
Node* get_tail(Node* L)
{
Node* p = L;
while (p->next != NULL)
{
p = p->next;
}
return p;
}
Node* TailList(Node* L, ElemType e)
{
Node* tail = get_tail(L);
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
tail->next = p;
p->next = NULL;
return p;
}
//反转链表
Node* reverseList(Node* head)
{
Node* first = NULL;
Node* second = head->next;
Node* third;
while (second != NULL) {
third = second->next;
second->next = first;
first = second;
second = third;
}
head->next = first;
return head;
}
//遍历
void PrintList(Node* L)
{
Node* p = L->next;
while (p != NULL)
{
printf("%d ",p->data);
p = p->next;
}
printf("\n");
}
int main() {
Node* list = initList();
TailList(list, 1);
TailList(list, 2);
TailList(list, 3);
TailList(list, 4);
TailList(list, 5);
TailList(list, 6);
PrintList(list);
Node* reserve=reverseList(list);
PrintList(reserve);
}运行结果:
1 2 3 4 5 6
6 5 4 3 2 1
删除链表的中间节点

用快慢指针:
- 慢指针(slow) :每次走 1 步,最终指向中间节点的前驱(方便删除)。
- 快指针(fast):每次走 2 步,用于控制慢指针的停止位置。
假设链表有效节点数为 n:
- 若
n为奇数(如 n=5):中间节点是第(n+1)/2个(第 3 个),快指针走到尾节点时,慢指针到中间节点前驱; - 若
n为偶数(如 n=4):中间节点通常取第n/2个(第 2 个),快指针走到 NULL 时,慢指针到中间节点前驱。
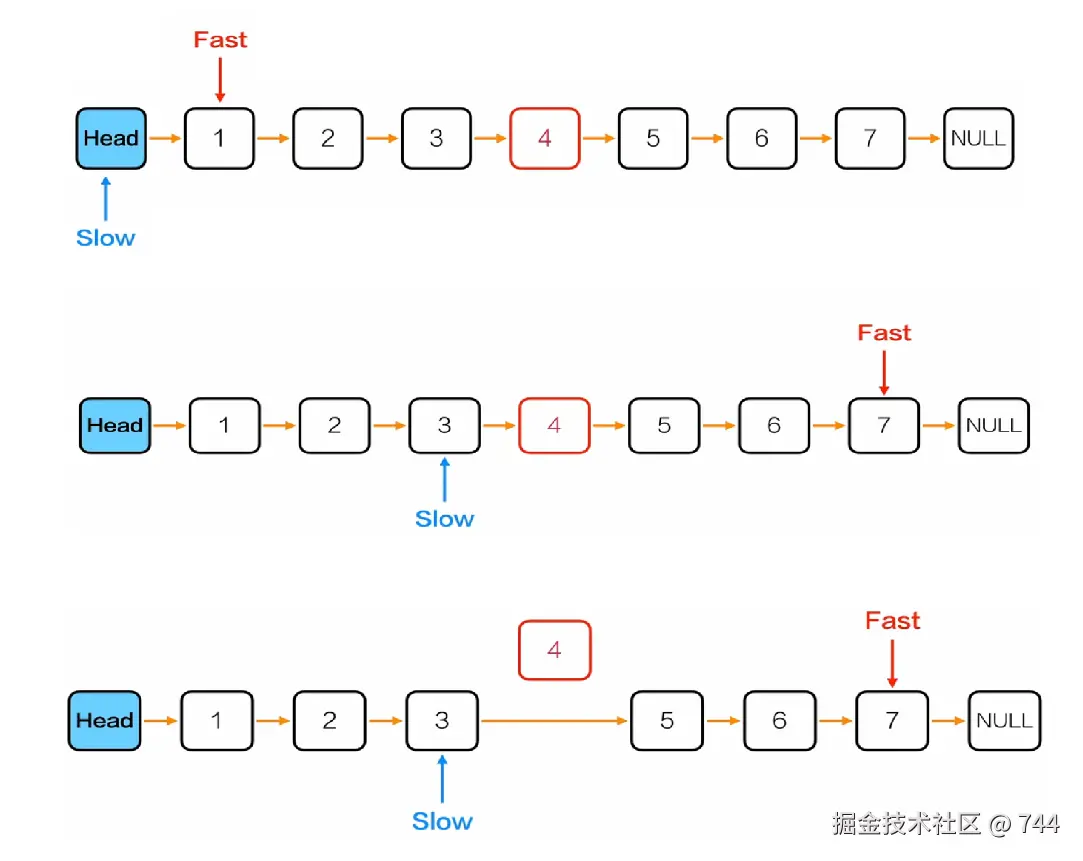
c
//删除中间节点
int delMiddleNode(Node* head)
{
Node* fast = head->next;
Node* slow = head;
while (fast != NULL && fast->next!=NULL)
{
fast = fast->next->next;//fast移动两步
slow = slow->next;//slow移动一步
}
Node* q = slow->next;//q记录被删除的节点
slow->next = q->next;//slow指向被删除的下一个节点
free(q);
return 1;
}完整代码:
c
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct node {
ElemType data;
struct node* next;
}Node;
//初始化
Node* initList()
{
Node* head = (Node*)malloc(sizeof(Node));
head->data = 0;
head->next = NULL;
return head;
}
//尾插法
Node* get_tail(Node* L)
{
Node* p = L;
while (p->next != NULL)
{
p = p->next;
}
return p;
}
Node* TailList(Node* L, ElemType e)
{
Node* tail = get_tail(L);
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
tail->next = p;
p->next = NULL;
return p;
}
//删除中间节点
int delMiddleNode(Node* head)
{
Node* fast = head->next;
Node* slow = head;
while (fast != NULL && fast->next!=NULL)
{
fast = fast->next->next;//fast移动两步
slow = slow->next;//slow移动一步
}
Node* q = slow->next;//q记录被删除的节点
slow->next = q->next;//slow指向被删除的下一个节点
free(q);
return 1;
}
//遍历
void PrintList(Node* L)
{
Node* p = L->next;
while (p != NULL)
{
printf("%d ",p->data);
p = p->next;
}
printf("\n");
}
int main() {
Node* list = initList();
TailList(list, 1);
TailList(list, 2);
TailList(list, 3);
TailList(list, 4);
TailList(list, 5);
TailList(list, 6);
TailList(list, 7);
PrintList(list);
delMiddleNode(list);
PrintList(list);
}运行结果:
1 2 3 4 5 6 7
1 2 3 5 6 7
练习---拆分、反转后半段再交替合并的重排序方法

核心逻辑分为三步:
- 快慢指针找链表中点,将链表拆分为前半段和后半段;
- 反转后半段链表;
- 将前半段和反转后的后半段交替合并。
- 追加剩余节点(将中间节点接入链表末尾)
 关键算法:
关键算法:
c
//链表重新排序
void reOrderList(Node* head)
{
Node* fast = head->next;
Node* slow = head;
while (fast != NULL && fast->next != NULL)
{
fast = fast->next->next;
slow = slow->next;
}
Node* first = NULL;
Node* second = slow->next; //记录中间节点
slow->next = NULL; //从中间将链表打断
Node* third = NULL;
while (second != NULL)
{
third = second->next;
second->next = first;
first = second;
second = third;
}
Node* p1 = head->next; // p1:前半段指针
Node* q1 = first; // q1:反转后后半段指针
Node* p2, *q2; // 临时变量,保存p1/q1的后继(避免合并时丢失)
while (p1 != NULL && q1 != NULL) // 只要两段都有节点,就交替合并
{
p2 = p1->next; //保存p1的下一个节点
q2 = q1->next; //保存q1的下一个节点
p1->next = q1; //交替合并
q1->next = p2;
p1 = p2;
q1 = q2;
}
//追加剩余节点,若后半段还有未处理的剩余节点(如链表个数为奇数时)
if (q1 != NULL)
{
// 找到当前链表的末尾节点
Node* tail = head;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = q1; // 将剩余节点(4)接入末尾
}
}完整代码:
c
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct node {
ElemType data;
struct node* next;
}Node;
//初始化
Node* initList()
{
Node* head = (Node*)malloc(sizeof(Node));
head->data = 0;
head->next = NULL;
return head;
}
//尾插法
Node* get_tail(Node* L)
{
Node* p = L;
while (p->next != NULL)
{
p = p->next;
}
return p;
}
Node* TailList(Node* L, ElemType e)
{
Node* tail = get_tail(L);
Node* p = (Node*)malloc(sizeof(Node));
p->data = e;
tail->next = p;
p->next = NULL;
return p;
}
//链表重新排序
void reOrderList(Node* head)
{
Node* fast = head->next;
Node* slow = head;
while (fast != NULL && fast->next != NULL)
{
fast = fast->next->next;
slow = slow->next;
}
Node* first = NULL;
Node* second = slow->next; //记录中间节点
slow->next = NULL; //从中间将链表打断
Node* third = NULL;
while (second != NULL)
{
third = second->next;
second->next = first;
first = second;
second = third;
}
Node* p1 = head->next; // p1:前半段指针
Node* q1 = first; // q1:反转后后半段指针
Node* p2, *q2; // 临时变量,保存p1/q1的后继(避免合并时丢失)
while (p1 != NULL && q1 != NULL) // 只要两段都有节点,就交替合并
{
p2 = p1->next; //保存p1的下一个节点
q2 = q1->next; //保存q1的下一个节点
p1->next = q1; //交替合并
q1->next = p2;
p1 = p2;
q1 = q2;
}
//追加剩余节点,若后半段还有未处理的剩余节点(如链表个数为奇数时)
if (q1 != NULL)
{
// 找到当前链表的末尾节点
Node* tail = head;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = q1; // 将剩余节点(4)接入末尾
}
}
//遍历
void PrintList(Node* L)
{
Node* p = L->next;
while (p != NULL)
{
printf("%d ",p->data);
p = p->next;
}
printf("\n");
}
int main() {
Node* list = initList();
TailList(list, 1);
TailList(list, 2);
TailList(list, 3);
TailList(list, 4);
TailList(list, 5);
TailList(list, 6);
TailList(list, 7);
PrintList(list);
reOrderList(list);
PrintList(list);
}运行结果:
1 2 3 4 5 6 7
1 7 2 6 3 5 4
单链表有哪些局限?------不能回头