论文题目:DreamOmni: Unified Image Generation and Editing(统一的图像生成和编辑)
会议:CVPR2025
摘要:目前,大型语言模型(大型语言模型)的成功表明,统一的多任务处理方法可以显著增强模型可用性,简化部署,并促进跨不同任务的协同效益。然而,在计算机视觉中,虽然文本到图像(T2I)模型通过放大显著提高了生成质量,但其框架设计最初并未考虑如何与下游任务(如各种类型的编辑)统一。为了解决这个问题,我们引入了DreamOmni,一个用于图像生成和编辑的统一模型。我们首先分析了现有的框架和下游任务的需求,提出了一个整合T2I模型和各种编辑任务的统一框架。此外,另一个关键挑战是高效地创建高质量的编辑数据,特别是基于指令和基于拖动的编辑。为此,我们开发了一个合成数据管道,使用类似贴纸的元素来有效地合成准确、高质量的数据集,从而可以编辑数据扩展以进行统一的模型训练。在培训方面,DreamOmni联合培训T2I代和下游任务。T2I训练增强了模型对具体概念的理解,提高了生成质量,而编辑训练帮助模型掌握编辑任务的细微差别。这种协作极大地提高了编辑性能。大量的实验证实了DreamOmni的有效性。
项目地址:https://zj-binxia.github.io/DreamOmni-ProjectPage/

DreamOmni: 统一图像生成与编辑的里程碑式工作
引言:为什么需要统一的图像生成与编辑模型?
在大语言模型(LLM)领域,统一的多任务方法已经证明了其巨大价值------它不仅显著提升了模型的可用性,简化了部署流程,还在不同任务之间产生了协同效应。然而,在计算机视觉领域,尽管文本到图像(T2I)模型通过扩大规模显著提升了生成质量,但其框架设计从一开始就没有考虑如何与下游任务(如各种类型的编辑)进行统一。
DreamOmni的出现,正是为了解决这一根本性问题。
一、问题分析:当前T2I模型面临的两大挑战
1.1 框架设计的碎片化
当前将T2I基础模型适配到下游应用时,通常需要以不同方式集成各种插件或扩展输入通道:
| 方法 | 适配方式 | 局限性 |
|---|---|---|
| ControlNet | 额外的条件控制插件 | 需要为每种条件训练单独的模块 |
| IP-adapter | 通过交叉注意力注入图像信息 | 架构复杂,部署困难 |
| InstructP2P | 扩展模型输入通道 | 与原始T2I架构不兼容 |
| SD-inpainting | 专门的修复模型 | 无法泛化到其他任务 |
这种依赖专门框架的方式阻碍了多任务泛化,使部署变得复杂,并妨碍了T2I与编辑任务的联合训练。
1.2 高质量编辑数据的获取困境
创建和过滤准确的编辑数据是另一个核心挑战:
指令编辑数据:
- InstructP2P使用微调的GPT-3和Prompt-to-Prompt策略生成数据集
- 成功率不到15%,且经常出现伪影和细节丢失
- MagicBrush通过人工创建和过滤数据,但人工方法限制了数据量
拖拽编辑数据:
- 大多数方法(如FreeDrag、DragDiffusion)是无训练的,限制了性能和效率
- InstaDrag利用视频数据构建拖拽编辑数据,但从视频中过滤有效数据仍然低效
主体驱动生成数据:
- DreamBooth需要在每次推理前对多张主体相关图像进行训练,不方便且低效
- 从网络收集同一人物的多张照片并进行过滤仍然是挑战
二、DreamOmni的核心创新
2.1 统一的模型框架

DreamOmni提出了一个能够支持多种任务的统一框架,其核心设计包括:
2.1.1 VLM特征与噪声Latent的联合处理
输入 → VLM编码 → [VLM特征 ⊕ 噪声Latent] → DIT Block → 输出
↑
联合多头自注意力关键设计决策:
- 将VLM特征与噪声latent连接 后输入DIT Block进行联合多头自注意力操作
- FeedForward模块中,VLM特征和噪声latent通过两个独立但结构相同的网络处理
- 这种设计允许模型自主学习从整体一致性到主体一致性的任意级别特征
2.1.2 视觉语言模型(VLM)编码器
与传统使用CLIP或T5作为文本编码器不同,DreamOmni采用Qwen2-VL 7B作为编码器,原因是:
- 支持任意分辨率的图像输入
- 强大的多模态理解能力
- 开源许可证友好
VLM特征来自Qwen2-VL的倒数第二层。
2.1.3 框架对比实验
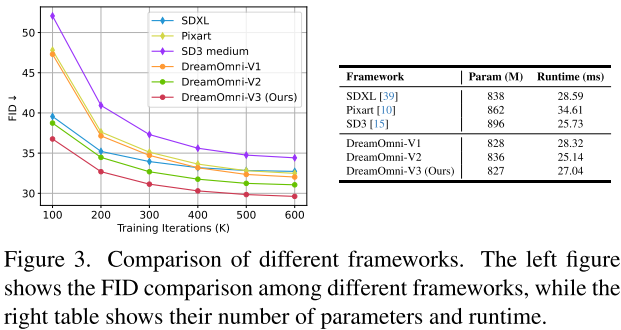
论文在公平设置下对比了多种框架(参数量约0.85B):
| 框架 | 参数量(M) | 运行时间(ms) | 特点 |
|---|---|---|---|
| SDXL | 838 | 28.59 | UNet结构,有残差连接 |
| Pixart | 862 | 34.61 | DIT结构,无残差连接 |
| SD3-Medium | 896 | 25.73 | DIT结构,无残差连接 |
| DreamOmni-V3 | 827 | 27.04 | DIT+残差连接+2×计算集中 |
核心发现:
- 残差连接显著加速收敛:有UNet连接的模型(SDXL, DreamOmni-V2/V3)比没有的(SD3-Medium, DreamOmni-V1)收敛快得多
- 计算集中于高分辨率latent更高效:将DIT block计算集中在2×下采样的latent上(而非4×)更具成本效益
- DreamOmni-V3的收敛速度是SD3-Medium的4倍
2.2 合成拼贴数据流水线
这是论文的另一个核心贡献------提出了一个高效、准确的合成数据生成方法。
2.2.1 为什么合成数据可行?
"我们发现,有效编辑的关键在于帮助模型理解编辑操作的含义,而不是学习特定概念(这是模型在T2I训练中已经具备的能力)。"
这一洞察是合成数据流水线成功的理论基础。
2.2.2 六大任务的数据合成策略
1. T2I生成增强
在传统T2I数据基础上,增加合成数据来提升:
- 文本生成:在空白画布上随机生成不同字体、颜色、粗细、大小的文字
- 形状和数量:随机创建不同数量、颜色、大小的几何图形
- 空间关系:使用贴纸和分割数据合成,计算精确的空间关系
2. 修复与外扩(Inpainting & Outpainting)
随机生成三种类型的遮罩:
- 涂抹式遮罩
- 块状遮罩
- 边缘遮罩
训练时有50%概率包含图像描述。
3. 指令编辑(Instruction-based Editing)
分为三种操作:
| 操作类型 | 源图像构建 | 目标图像构建 |
|---|---|---|
| 删除 | 背景图像 + 物体图像 | 背景图像 |
| 替换 | 背景图像 + 物体A | 背景图像 + 物体B(同位置) |
| 添加 | 空白背景 | 空白背景 + 物体 |
4. 拖拽编辑(Drag Editing)
分为三种类型:平移、缩放、旋转
创新的拖拽点表示方法:
每个拖拽点 = (x, y, dx, dy)
- (x, y): 源图像中拖拽点的坐标(归一化)
- (dx, dy): 位移向量(归一化)这种表示方法比InstaDrag将每对拖拽点作为单独图像更加灵活且实用。
5. 参考图像生成(Reference Image Generation)
分为两类:
- 图像条件生成(ControlNet式):创建canny图、深度图、分割图作为条件
- 主体驱动生成:合成包含多个贴纸的画布,训练模型从给定图像中提取特定物体或细节
6. 分割与检测(Segmentation & Detection)
- 随机选择背景图像和物体图像合成源图像
- 基于物体的alpha通道进行颜色标注或绘制边界框得到目标图像
2.3 三阶段训练策略
| 阶段 | 分辨率 | 批次大小 | 学习率 | 迭代次数 |
|---|---|---|---|---|
| 第一阶段 | 256×256 | 2048 | 1×10⁻⁴ | 377K |
| 第二阶段 | 512×512 | 1024 | 5×10⁻⁵ | 189K |
| 第三阶段 | 1024×1024 | 256 | 2×10⁻⁵ | 140K |
数据配置:
- T2I数据:125M图像(LAION 103M + 自收集22M)
- 合成数据:每类任务12M图像,共约60M图像
- 分割&检测数据:8M图像
第三阶段微调:选择12M高质量T2I数据 + 每类合成数据随机采样1M高质量图像
三、实验结果
3.1 T2I生成
在GenEval基准测试上的结果:

| 模型 | Overall | Single | Two | Counting | Colors | Position | Color Attribution |
|---|---|---|---|---|---|---|---|
| SD 1.5 | 0.43 | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 |
| SDXL | 0.55 | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 |
| SD3-Medium | 0.70 | 0.99 | 0.84 | 0.63 | 0.88 | 0.28 | 0.55 |
| DreamOmni | 0.70 | 0.99 | 0.81 | 0.65 | 0.88 | 0.34 | 0.54 |
亮点:
- 与2B参数的开源SOTA模型SD3-Medium持平
- 在Counting 和Position指标上超越SD3-Medium
- 合成数据显著提升了数量、颜色、位置等属性的生成准确性
3.2 修复与外扩

| 模型 | Inpainting FID↓ | Inpainting LPIPS↓ | Outpainting FID↓ | Outpainting LPIPS↓ |
|---|---|---|---|---|
| SD-inpainting | 1.3522 | 0.1560 | 2.9179 | 0.2475 |
| ControlNet-inpainting | 1.8393 | 0.1594 | 4.2337 | 0.2521 |
| DreamOmni | 0.8371 | 0.1203 | 1.6926 | 0.1995 |
DreamOmni在所有指标上都显著优于现有方法。
3.3 图像条件生成

在canny、depth、segmentation三种条件下,DreamOmni相比ControlNet:
- 更准确地遵循图像条件和文本提示
- 生成更高质量的图像,具有更好的构图和更丰富的细节
3.4 主体驱动生成

与BLIP-Diffusion和IP-Adapter对比:
- 在保持指定主体的同时更好地遵循文本提示
- 在照片和动漫风格上都展现了强大的泛化能力
3.5 指令编辑

与MGIE和InstructP2P对比:
- 更精确的添加、删除、替换操作
- 非编辑区域变化最小
- 编辑内容生成质量更高
3.6 拖拽编辑

- 准确执行平移、旋转和缩放操作
- 平移和缩放时能保持物体完整性
- 大角度旋转仍存在挑战(涉及物体自身的复杂变换)
四、技术细节
4.1 模型配置
- DIT模型:2.5B参数
- VLM编码器:Qwen2-VL 7B
- VAE:FLUX-schnell的VAE(保留更多latent通道,捕获更精细的图像细节)
- 优化方法:Rectified Flow
4.2 损失函数
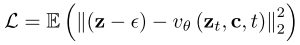
其中:
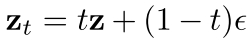 :时间步t的噪声特征图
:时间步t的噪声特征图- z:通过VAE编码的ground truth图像latent
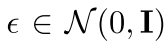 :高斯噪声
:高斯噪声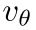 :DIT模型
:DIT模型- c:条件信息
4.3 分辨率适配
类似SDXL的bucket策略:
- 根据宽高比将图像分为31个bucket
- 宽高比范围:4:1 到 1:4
五、核心洞察与启示
5.1 统一的价值
"T2I训练增强模型对特定概念的理解并提高生成质量,而编辑训练帮助模型掌握编辑任务的细微差别。这种协作显著提升了编辑性能。"
统一训练带来的协同效应是DreamOmni成功的关键------T2I与编辑任务相互促进,而非相互干扰。
5.2 合成数据的有效性
论文证明了合成数据是一种有效、高质量、低成本的方法来扩展编辑数据:
- 不需要复杂的数据收集和过滤流程
- 可以精确控制数据的属性和标注
- 易于扩展到数十亿级别的数据量
5.3 框架设计的重要性
通过公平的对比实验,论文揭示了几个重要发现:
- 残差连接对训练收敛速度有显著影响
- 计算资源应该集中在高分辨率latent上
- DIT的优势来自于其计算分配策略,而非架构本身
六、局限性与未来方向
根据论文内容,可以看出以下潜在改进方向:
- 大角度旋转:当前模型在大角度旋转编辑时可能出现物体变形
- 更多任务统一:可以进一步扩展到视频生成、3D生成等任务
- 更轻量的VLM:当前使用7B的Qwen2-VL,可能探索更轻量的替代方案
七、结论
DreamOmni代表了图像生成与编辑领域的重要进展:
✅ 提出了首个原生统一的图像生成与编辑模型
✅ 设计了高效的合成数据流水线,解决了编辑数据获取难题
✅ 通过公平实验揭示了框架设计的关键因素
✅ 在多个任务上取得了SOTA或竞争性结果
这项工作为构建更加通用、强大的视觉生成基础模型指明了方向。