纯手打,代码整理中,持续更新中^-^
需要延用总结四
本节学习特征降维的相关知识点
特征降维是机器学习中常用的技术,用于减少特征的数量,同时尽可能保留原始数据的信息。在Scikit learn中,特征降维主要有两种方法:特征选择和特征提取。
1.特征选择:从原始特征中选择一部分特征。方法包括:移除低方差特征(VarianceThreshold),单变量统计(SelectKBest, SelectPercentile)、基于模型的特征选择(如SelectFromModel)、递归特征 消除(RFE)等。,
2.特征提取:将原始特征转换到新的特征空间,从而减少特征数量。常用的方法有主成分分析 (PCA)、线性判别分析(LDA)、非负矩阵分解(NMF)等。
10、特征选择-移除低 方差 特征(VarianceThreshold)
适用于移除 方差 低于阈值的特征,这些特征通常包含很少的信息。
VarianceThreshold 是机器学习中一个简单但实用的特征选择方法,它通过移除低方差特征来简化数据集。
VarianceThreshold 的主要参数是threshold ,它决定了特征被保留与否的方差门槛。
我们来看一个示例:
python
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import load_iris
# 加载示例数据
X, y = load_iris(return_X_y=True)
# 设置阈值,移除方差低于0.8的特征
#主要是threshold这个浮点数,指定保留特征的最低的方差阈值。
#训练集中方差低于此阈值的特征将被移出
selector = VarianceThreshold(threshold=0.8)
X_new = selector.fit_transform(X)
print(f"原始特征数: {X.shape[1]}")
print(f"筛选后特征数: {X_new.shape[1]}")输出
python
原始特征数: 4
筛选后特征数: 1数学知识:方差
方差公式是一个数学公式,是数学统计学中的重要公式,应用于生活中各种事情,方差越小,代表这组数据越稳定,方差越大,代表这组数据越不稳定。
若 x 1,x 2,x 3...xn 的平均数为 M,则方差公式可表示为:
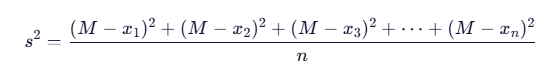
11、单变量特征选择 SelectKBest - 选择Top K个特征
基于统计检验选择最佳特征。
SelectKBest 的原理非常直观,其名称就完美概括了其工作方式:
Select(选择) + K + Best(最好的)
顾名思义,它的目标是从原始特征集中选择出 K 个"最好的"特征。那么,核心问题就变成了:如何定义"最好"?
SelectKBest 的工作流程可以概括为以下三个步骤:
- 打分(Scoring):
○ 对于数据集中的每一个特征,都使用一个特定的评分函数 f 进行计算。
○ 这个评分函数会计算该特征与目标变量 y 之间的某种统计关系或依赖性。关系越强,得分越高。
○ 例如,它可以使用卡方检验、相关系数、互信息等作为评分标准。
- 排序(Ranking):
○ 得到所有待选特征及其对应的分数后,SelectKBest 会根据分数从高到低对所有特征进行排序。
- 选择(Selecting):
○ 最后,它简单地保留Top-K个得分最高的特征,并剔除其余的所有特征。
○ 用户指定的参数 k 就是这里需要保留的特征数量。
我们先来看一个示例:
python
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.datasets import load_iris
# 加载数据
X, y = load_iris(return_X_y=True)
# 选择最佳的2个特征
selector = SelectKBest(score_func=f_classif, k=3)
X_new = selector.fit_transform(X, y)
print(f"原始特征数: {X.shape[1]}")
print(f"筛选后特征数: {X_new.shape[1]}")
print(f"特征得分: {selector.scores_}")输出
python
原始特征数: 4
筛选后特征数: 3
特征得分: [ 119.26450218 49.16004009 1180.16118225 960.0071468 ]主要函数
1.score_func 用于计算特征得分的函数。2、k 选择要保留的topK个特征。可以设置为'all'来保留所有特征。
常见的 score_func 评分函数:
选择哪个评分函数取决于你的问题类型(分类还是回归)以及特征的数据类型。
|------------------------|------|----------------------------------------------|
| 评分函数 | 适用问题 | 说明 |
| f_classif | 分类 | 计算每个特征与目标变量之间的 ANOVA F值。适用于连续特征和分类目标。默认选项。 |
| chi2 | 分类 | 卡方检验。计算每个特征与目标变量之间的卡方统计量。适用于非负的特征(如词频、布尔特征)。 |
| mutual_info_classif | 分类 | 互信息。衡量特征和目标变量之间的非线性关系。非常强大,但计算成本更高。 |
| f_regression | 回归 | 计算每个特征与目标变量之间的 F值(线性回归模型的简单线性回归)。 |
| mutual_info_regression | 回归 | 互信息的回归版本,同样用于捕捉非线性关系。 |