本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
文章目录
- 前言
- [一、REDO LOG(重做日志)](#一、REDO LOG(重做日志))
-
- [1.1、redo log 的存储](#1.1、redo log 的存储)
- [1.2、redo log file的写入机制](#1.2、redo log file的写入机制)
- 1.3、崩溃与恢复
- [二、UNDO LOG(回滚日志)](#二、UNDO LOG(回滚日志))
- [三、redo log 与 undo log 核心对比](#三、redo log 与 undo log 核心对比)
- 四、生产环境关键配置与常见问题
-
- [4.1 核心参数推荐配置(生产环境)](#4.1 核心参数推荐配置(生产环境))
- [4.2 常见问题与排查思路](#4.2 常见问题与排查思路)
前言
本篇主要介绍InnoDB 存储引擎层的重做日志和回滚日志,上述两个日志,是InnoDB 存储引擎特有的核心组件,是实现 ACID 特性的核心依赖
一、REDO LOG(重做日志)
redo log 是实现事务ACID特性中的D(持久化)的核心组件,redo log是物理日志,记录的是磁盘上数据页的物理操作,主要用于保证事务的持久性,即保证已经提交的事务,其对应的数据,即使是数据库崩溃,也不会丢失。其实现原理是重启后 InnoDB 可通过 redo 日志重放未刷写到磁盘的数据页修改,确保已提交的事务不会丢失。
同时redo log对于优化磁盘IO性能也有帮助,InnoDB 使用预写日志机制,修改数据时,先将数据存入redo log,再异步将数据页写入磁盘中:
- redo log是
顺序写,而数据页修改是随机写,顺序写的效率要高于随机写,避免了寻址的问题。 - 避免了事务提交时同步写数据页,否则每次提交事务都要等到磁盘随机IO结束,效率很低。
redo log还起到了保护undo log的作用,undo log也保存在 InnoDB 的数据页中,修改 undo 日志时同样会写入 redo 日志。
1.1、redo log 的存储
redo log同时存在于内存和磁盘,二者是不同的形态和作用:
- 内存中的 redo log -
redo log buffer:InnoDB 在内存中开辟了redo log buffer(重做日志缓冲区,默认 16MB,由innodb_log_buffer_size配置),这是 redo log 的内存暂存区域。事务执行过程中产生的 redo log 记录,会首先写入redo log buffer,目的是减少直接写磁盘的 I/O 次数(内存写远快于磁盘写)。redo log buffer中的日志是临时的,可能被多个事务共享,且会在特定时机刷写到磁盘。 - 磁盘中的 redo log -
redo log file:磁盘上的 redo log 以日志文件组(如ib_logfile0、ib_logfile1)的形式存在,是 redo log 的持久化存储。redo log buffer中的日志刷写到磁盘后,就成为持久化的 redo log 记录,即使数据库崩溃也不会丢失
其中日志文件组,是一个环形的结构,其存储由两个关键指针控制:
- write pos(写入位置):当前 redo 日志的写入指针,指向日志文件组中待写入的位置。
- checkpoint(检查点):当前需要擦除的日志位置,擦除前需确保该位置之前的日志对应的数据页已刷写到磁盘(即 "日志落地→数据落地→日志可覆盖")。
日志文件组的空间分为三个区域:
- 已刷盘区:checkpoint 之前的区域,数据页已刷盘,日志可被覆盖。
- 可写区:write pos 与 checkpoint 之间的区域,可写入新的 redo 日志。
- 已满区:write pos 追上 checkpoint 时,日志文件组满,此时 InnoDB 会暂停新的写入,触发 checkpoint 推进(强制刷写数据页,释放日志空间)。
1.2、redo log file的写入机制
当事务执行的过程中,生成的日志会存放到redo log buffer中,redo log buffer中的日志会在特定时机刷写到redo log file中。时机通常有:
-
事务提交时:这里涉及到一个参数:
innodb_flush_log_at_trx_commit,它有三个值:-
0:事务提交时不写入
redo log file,而是由后台线程每隔1s写入一次(每秒同步),这样做极端情况下会丢失1s的数据。
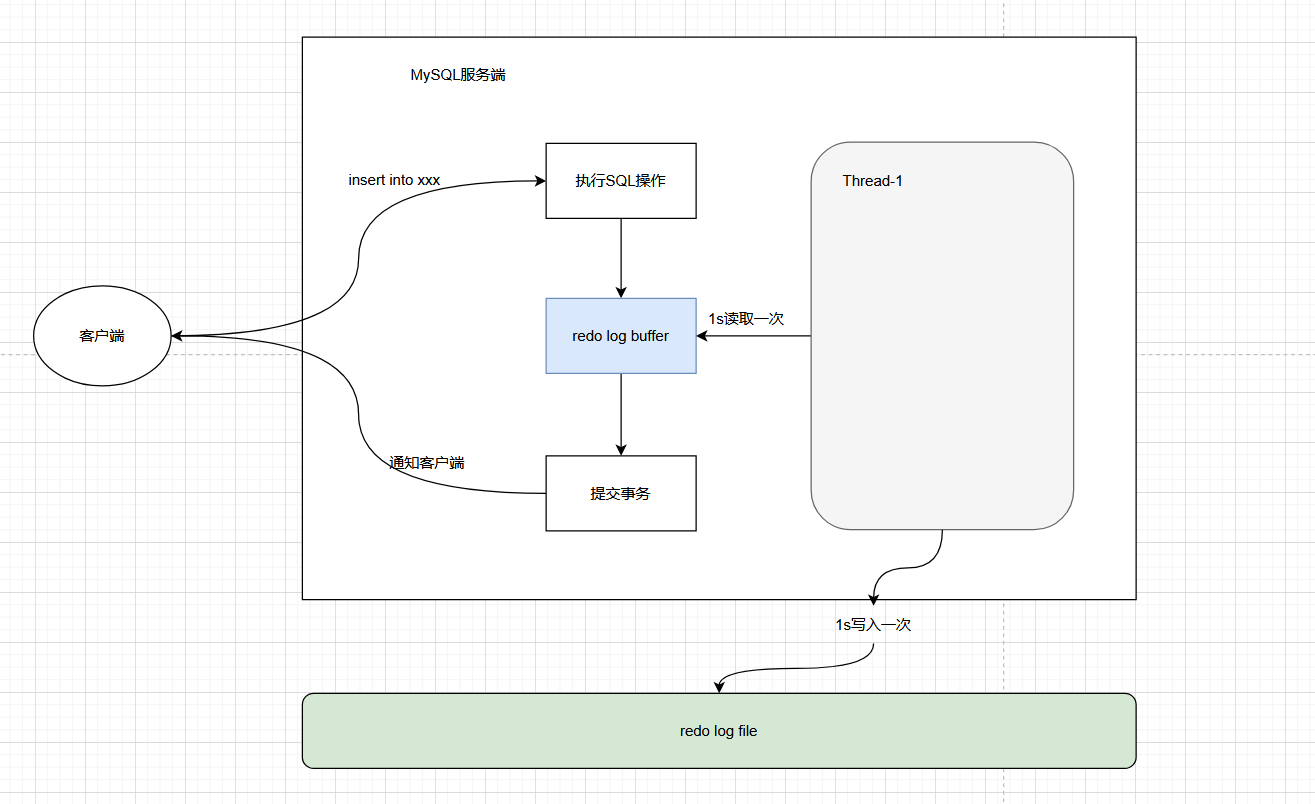
-
1:事务提交时,同步写到磁盘,这样最安全,但是效率较低。
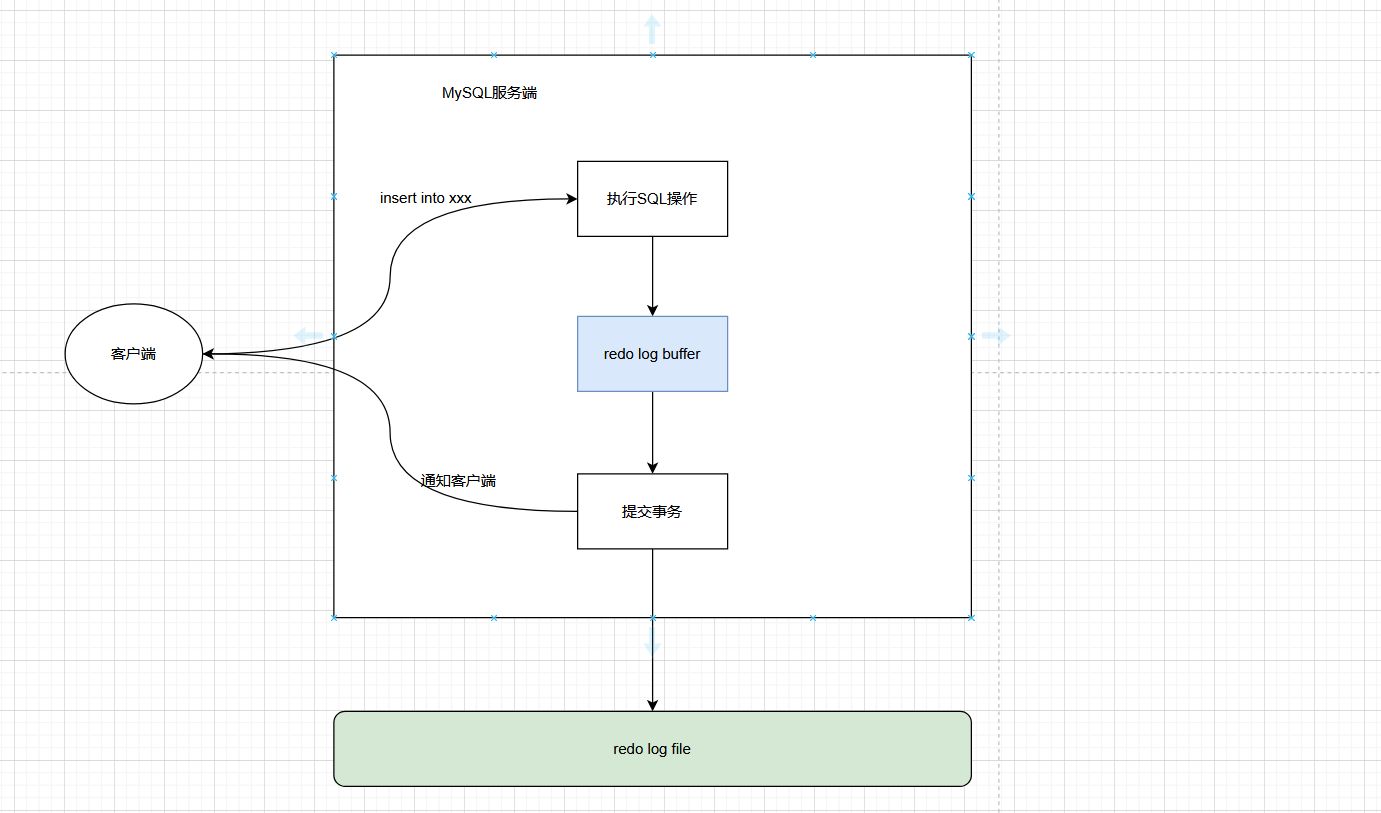
-
2:事务提交时不写入
redo log file,而是写入操作系统缓存,由操作系统每隔1s写入。
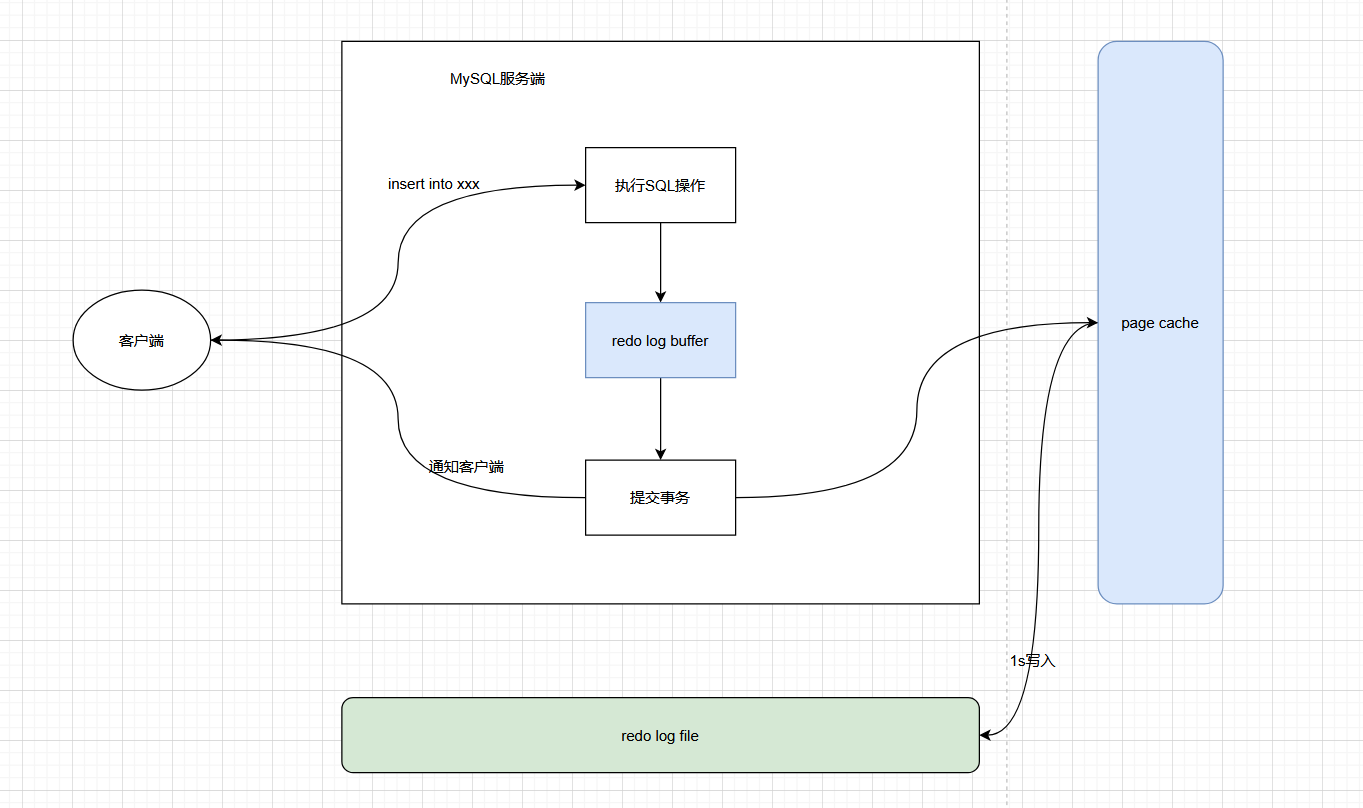
-
-
后台线程定期刷写:InnoDB 的主线程每 1 秒执行一次
redo log buffer刷写(无论事务是否提交)。 -
redo log buffer的使用量达到阈值。
-
数据库关闭/重启时。
-
触发 checkpoint 时:当 redo 日志文件组的可写空间不足时,InnoDB 推进 checkpoint,过程中会刷写
redo log buffer到磁盘。
那么innodb_flush_log_at_trx_commit的0和2有什么区别?同样是每隔1s写入一次,2还加入了写入到操作系统的缓存,既然极端情况下都会丢失1s的数据,那2的做法是否是多此一举?其实不然,0是纯纯的内存操作,但是2加入了一次从用户态到内核态的内存 -> 内存的拷贝,MySQL 进程崩溃不影响内核态内存同样是丢失1s的数据,后者丢失的少一些,是一种兼顾安全性和效率的折中方案。
1.3、崩溃与恢复
这里仅仅讨论MySQL服务进程崩溃后的恢复情况,MySQL服务进程崩溃,但是操作系统没有终止,页缓存的数据不会丢失,仅仅是redo log buffer中的没有持久化到redo log file的数据丢失。
恢复指的是,先加载磁盘旧数据到内存,再用 redo log 修复内存数据,最后通过 undo log 清理无效数据
数据丢失的情况,要基于innodb_flush_log_at_trx_commit的策略具体分析:
- 0:事务提交时,redo log 仅在
redo log buffer,进程崩溃后这部分数据会丢失(无法恢复) - 1:事务提交时,redo log 已通过fsync写入物理磁盘,故不会丢失
- 2:事务提交时,redo log 已通过write写入操作系统页缓存,尚未刷到物理磁盘,但 OS 未崩溃,该数据仍保留。
redo log的恢复流程,分为日志预处理,redo 和 undo 三个步骤:
1.3.1、日志预处理
日志预处理主要是确定redo log的恢复范围,InnoDB 首先读取磁盘上的checkpoint 信息,获取checkpoint_lsn,然后InnoDB 扫描 redo log 文件,找到最新的 LSN作为current_lsn,两者之间的数据是没有持久化到磁盘中的,也就是需要进行恢复的
1.3.2、redo
重放 checkpoint_lsn 到 current_lsn 之间的所有 redo log,恢复所有已记录的物理修改(包括未提交事务的修改),使 Buffer Pool 中的数据达到崩溃前的最新状态;
1.3.3、undo
扫描事务链表,识别所有未提交的事务,通过 undo log 执行反向操作(如插入→删除、更新→恢复旧值),撤销这些事务的修改,最终确保仅已提交事务的修改保留。
二、UNDO LOG(回滚日志)
undo log同样是InnoDB 特有的日志,核心用于保证事务的原子性,以及MVCC机制,也是配合redo log进行故障恢复的重要组成部分。在redo log进行故障恢复的过程中,undo log通常用于反向撤销事务的修改操作。和redo log不同的是,undo log是逻辑日志。
2.1、事务回滚
undo log,记录的是用户执行的sql增删改操作的反向操作(也是逻辑日志的体现),例如:
- 执行INSERT时,undo 日志记录插入行的主键,回滚时执行DELETE。
- 执行UPDATE时,undo 日志记录修改前的字段值,回滚时执行UPDATE恢复。
- 执行DELETE时,undo 日志记录删除前的完整行数据,回滚时执行INSERT恢复。
MySQL 崩溃重启时,InnoDB 先通过 redo 日志前滚所有事务(包括未提交的),再通过 undo 日志回滚未提交的事务,保障数据一致性。
2.2、存储结构
undo log存储在 InnoDB 的undo 表空间中,其中包括:
- 回滚段:undo 表空间由回滚段构成,每个回滚段有1024个槽位,每个槽位对应一个事务。MySQL 5.7 及以上默认配置innodb_rollback_segments = 128(回滚段数量),因此理论上最大并发事务数为128 * 1024 = 131072。
- undo页与undo log记录:回滚段由多个undo 页组成,每个 undo 页存储多条undo log 记录。undo log 记录包含:
- 事务 ID(TRX_ID):生成该 undo 日志的事务 ID;
- 旧版本数据:数据修改前的字段值、主键信息;
- 回滚指针(ROLL_PTR):指向前一个 undo log 记录的指针(形成版本链);
- 日志类型标记:区分 Insert/Update undo log。
2.3、写入时机
undo log同样分为undo buffer(内存级别)和undo 表空间(磁盘级别)两种写入方式。并且所有 undo log 的生成和修改操作,都会被 InnoDB 记录到 redo log 中
2.3.1、undo buffer的写入时机
当执行具体的增删改sql语句时,即会同步记录到undo buffer中:
- INSERT 操作:事务执行INSERT时,立即生成Insert Undo Log记录(仅包含插入行的主键信息),并写入 undo buffer 中当前事务的专属缓存区块。
- UPDATE/DELETE 操作:事务执行UPDATE/DELETE时,立即生成Update Undo Log记录(包含数据修改前的旧版本信息),并写入 undo buffer 中当前事务的专属缓存区块。
- 事务内的批量操作:若事务执行批量 DML(如INSERT INTO ... SELECT),undo log 记录会随每一条数据修改逐行生成并写入 undo buffer,而非事务结束时批量写入。
2.3.2、undo 表空间的写入时机
当buffer中缓存的 undo log 记录达到容量阈值时,InnoDB 会触发被动刷盘。以及Checkpoint 机制触发时,也会间接的将undo log 进行刷盘。InnoDB 的后台线程,也会定时检查 undo buffer 的使用情况,当超出阈值后,也会进行刷盘的操作。
2.4 undo log 的类型与清理
undo log 分为两类,生命周期差异显著:
-
Insert Undo Log:仅用于事务回滚(插入的行仅当前事务可见,提交后无其他事务依赖),事务提交后可立即被删除;
-
Update/Delete Undo Log:不仅用于回滚,还支撑 MVCC 版本链,事务提交后不能立即删除,需等待「purge 线程」确认「无任何事务引用该版本链」后,再清理无效的 undo 记录。
关键配置:
-
innodb_purge_threads:purge 线程数量(默认 4,高并发场景可适当增大); -
innodb_undo_tablespaces:独立 undo 表空间数量(默认 0,建议设置为 2-4,避免系统表空间 ibdata1 膨胀); -
innodb_undo_log_truncate:开启 undo 日志截断(默认开启,当 undo 表空间达到阈值时自动收缩)。
三、redo log 与 undo log 核心对比
| 对比维度 | redo log(重做日志) | undo log(回滚日志) |
|---|---|---|
| 日志类型 | 物理日志(记录数据页的物理修改) | 逻辑日志(记录操作的反向逻辑) |
| 核心作用 | 保障事务持久性(D)+ 崩溃恢复前滚 | 保障事务原子性(A)+ 隔离性(MVCC)+ 崩溃恢复回滚 |
| 存储位置 | redo log buffer(内存)+ ib_logfile0/1(磁盘日志组) | undo buffer(内存)+ undo 表空间(磁盘,默认 ibdata1,可独立配置) |
| 写入时机 | 事务提交、后台线程 1 秒刷盘、缓冲区阈值、checkpoint | DML 执行时实时生成(写入 undo buffer),缓冲区阈值 /checkpoint/ 后台线程刷盘 |
| 生命周期 | 环形覆盖(checkpoint 后可覆盖) | Insert Undo(事务提交后删除);Update Undo(MVCC 无引用后 purge 线程清理) |
| 与 redo log 关系 | 无依赖(自身是独立日志) | 所有 undo 操作均会记录到 redo log(保障 undo 日志不丢失) |
四、生产环境关键配置与常见问题
4.1 核心参数推荐配置(生产环境)
| 参数名称 | 推荐值 | 说明 |
|---|---|---|
| innodb_flush_log_at_trx_commit | 1 | 强一致性场景(如金融),牺牲性能保安全;追求性能可设 2 |
| innodb_log_buffer_size | 64M | 高并发写入场景增大(默认 16M),减少刷盘频率 |
| innodb_log_file_size | 2G-4G | redo log 文件大小(默认 48M),太大影响恢复速度,太小触发 checkpoint 频繁 |
| innodb_log_files_in_group | 2 | redo log 文件组数量(默认 2),环形写入 |
| innodb_undo_tablespaces | 2-4 | 独立 undo 表空间,避免 ibdata1 膨胀 |
| innodb_undo_log_truncate | ON | 开启 undo 日志截断,自动收缩表空间 |
| innodb_purge_threads | 4-8 | 高并发场景增大 purge 线程数,加速 undo 清理 |
4.2 常见问题与排查思路
- redo log 频繁刷盘导致性能下降?
-
排查:通过
SHOW ENGINE INNODB STATUS查看「LOG SECURITY STATUS」,确认刷盘频率; -
解决:增大
innodb_log_buffer_size,避免小事务频繁触发刷盘;非核心业务可将innodb_flush_log_at_trx_commit设为 2。
- undo 表空间持续膨胀?
-
排查:通过
SELECT * FROM INFORMATION_SCHEMA.INNODB_UNDO_LOGS查看活跃 undo 日志数量; -
解决:确认
innodb_undo_log_truncate开启,增大innodb_purge_threads,排查长事务(长事务会持有旧版本链,导致 undo 无法清理)。
- 崩溃恢复时间过长?
-
排查:
innodb_log_file_size过大,导致 redo log 重放时间长; -
解决:将
innodb_log_file_size控制在 2G-4G,避免过大。