文章目录
多模态模型发展演变
仅供学习参考
自监督学习
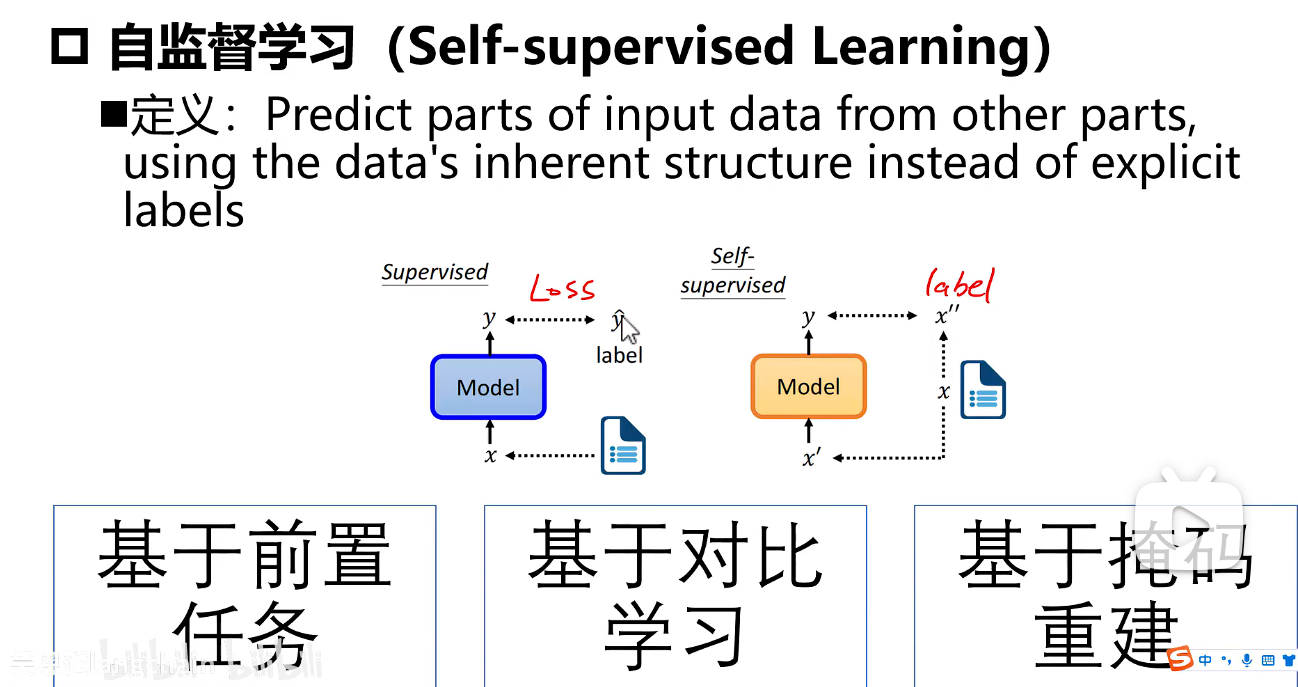
监督学习:输入+模型+求损失(预测值,标签)
自监督学习:输入+模型+求损失(预测值,输入中找标签)
分三类:
- 基于前置任务
- 基于对比学习
- 基于掩码重建
基于前置任务
1.位置预测
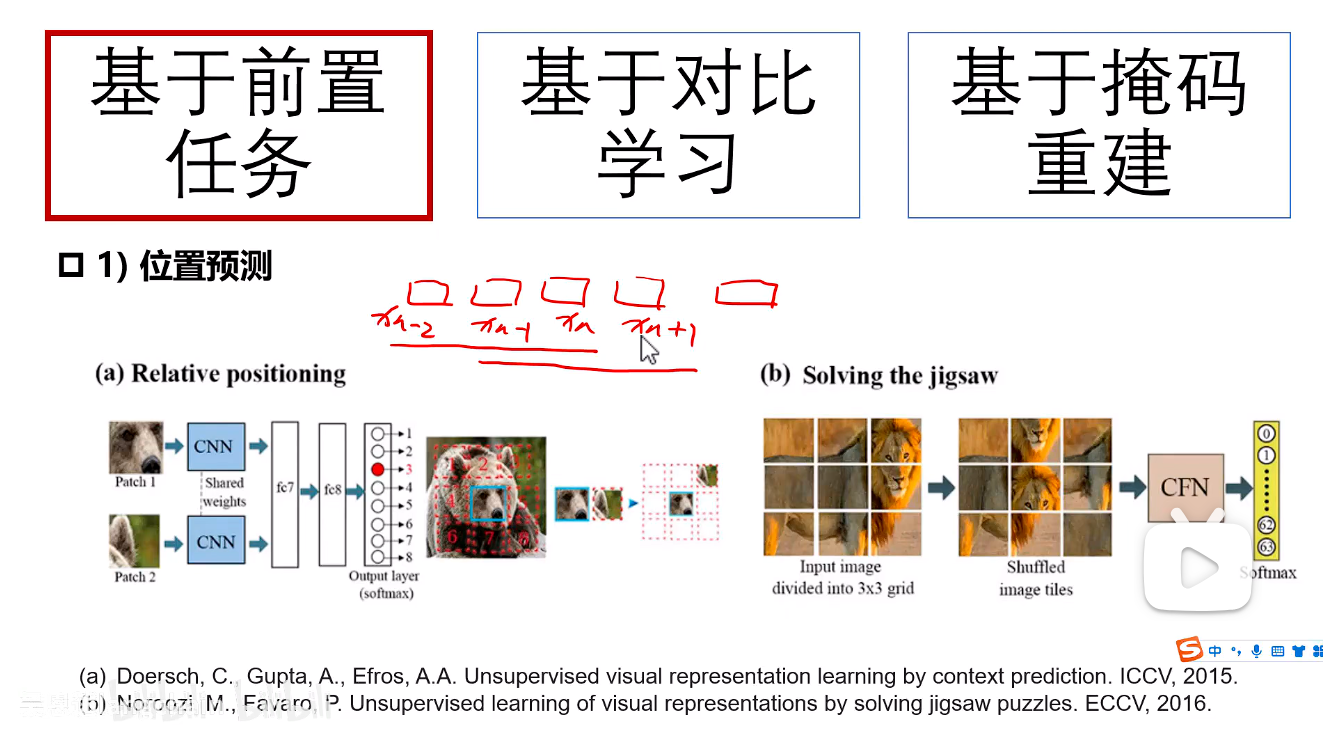
从一张图中取出一个补丁(Patch A),然后在其"八邻域"中取出另一个补丁(Patch B),让模型判断B相对于A的位置(例如:右上、正左、右下等)。
2.旋转预测
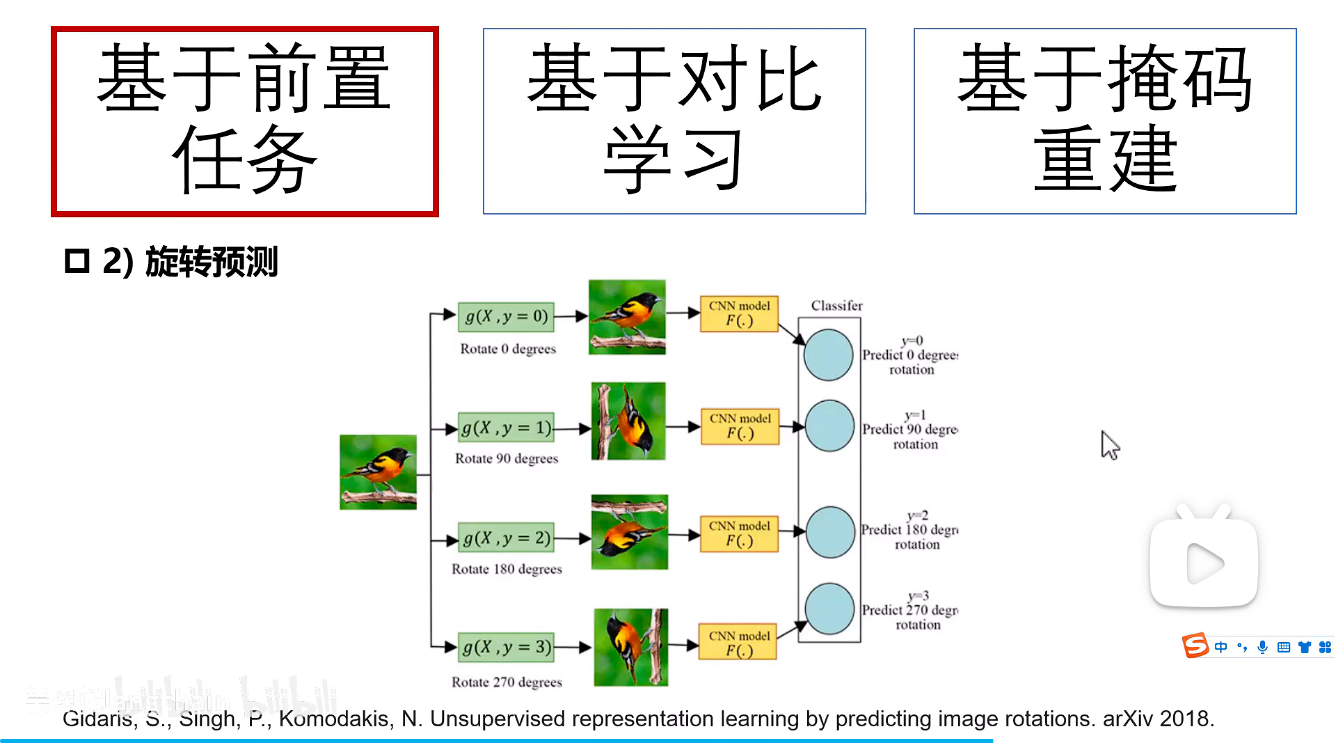
自设定旋转角度,模型自己去旋转自己去预测。
3.上色
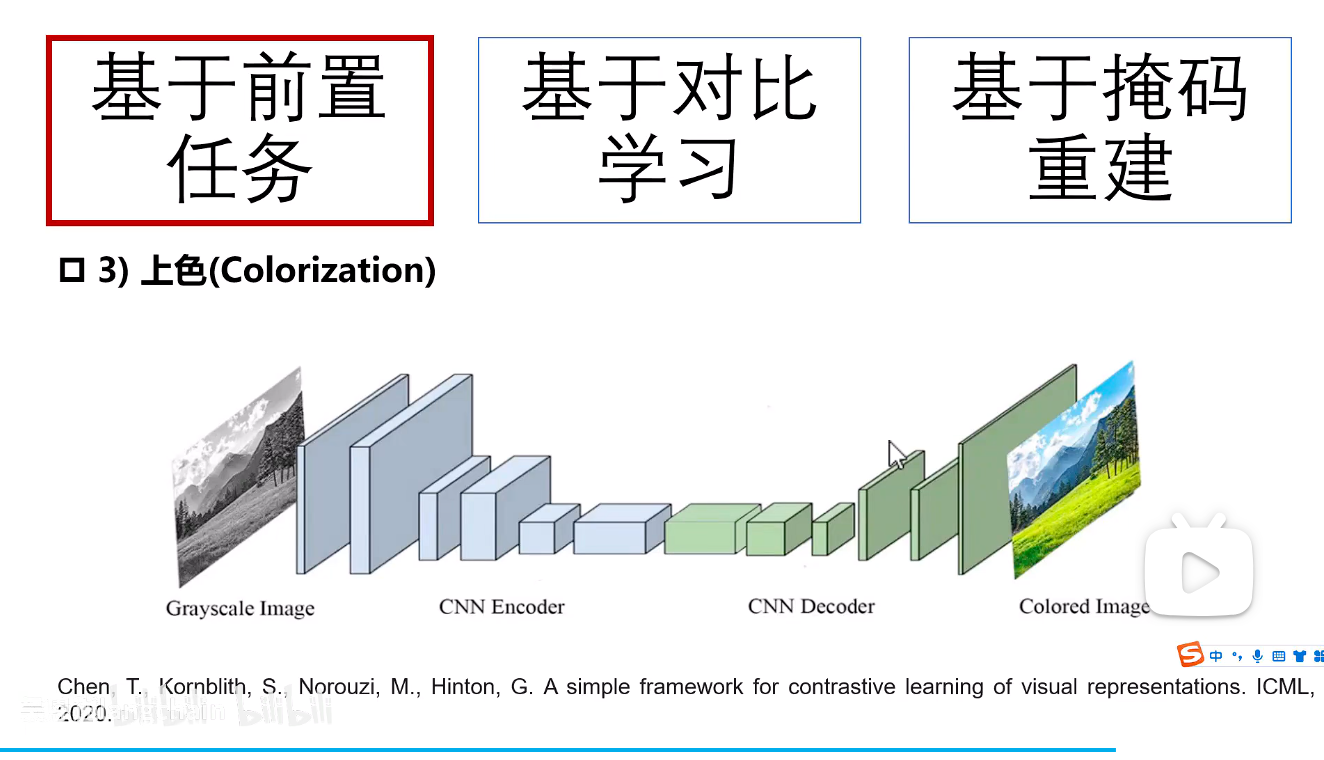
一般操作是操作的图片的灰度图,我们上色则是输入灰度图,然后进行卷积提取特征,然后和原始图片进行对比求损失来进行图片上色。
这里的"和原始图片进行对比求损失"通常是在 Lab颜色空间 下进行的。输入是L通道(亮度,即灰度图),模型需要预测ab通道(颜色通道)。损失函数是计算预测的ab通道与真实的ab通道之间的差异(如L2损失)
4.聚类预测
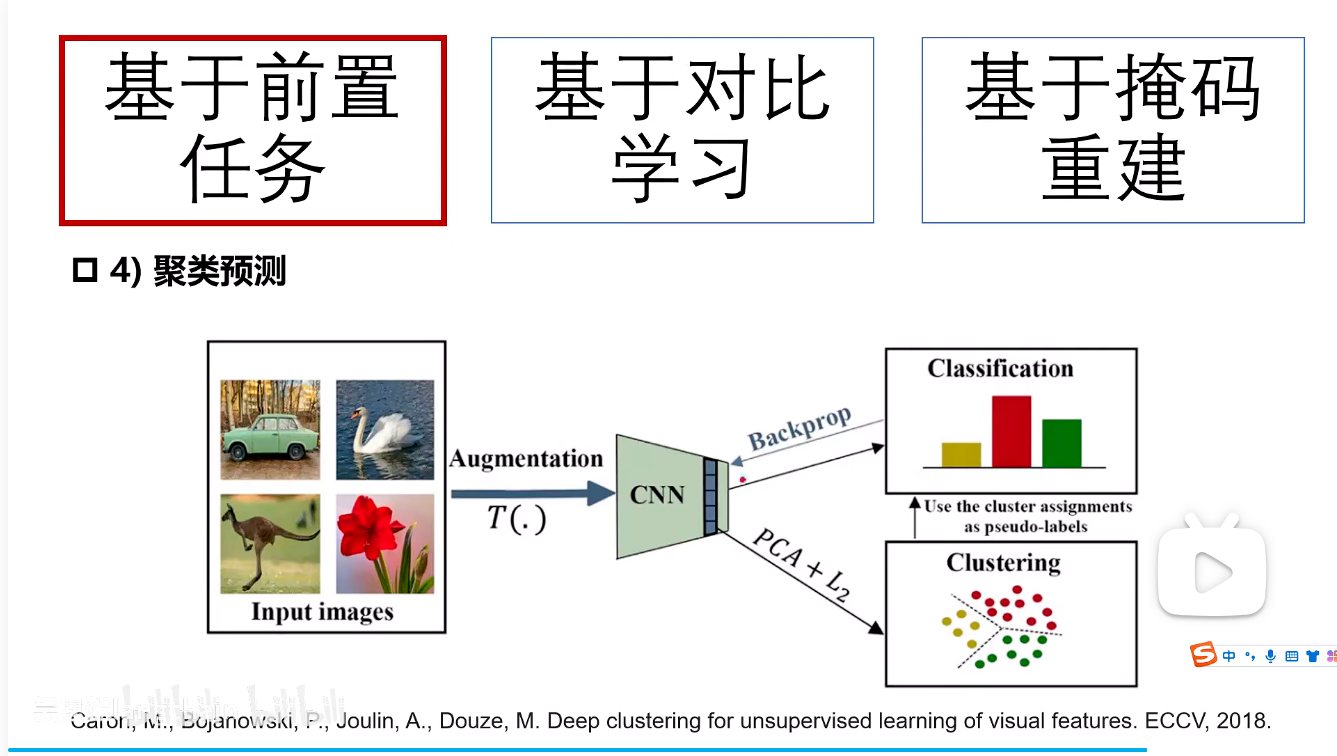
多个图片通过CNN获取特征可以进行聚类算法,给他们预测分类标签,则认为他的标签就是预测的标签,则之后就用这个标签进行反向传播去优化。(类似于半监督学习)
基于对比学习
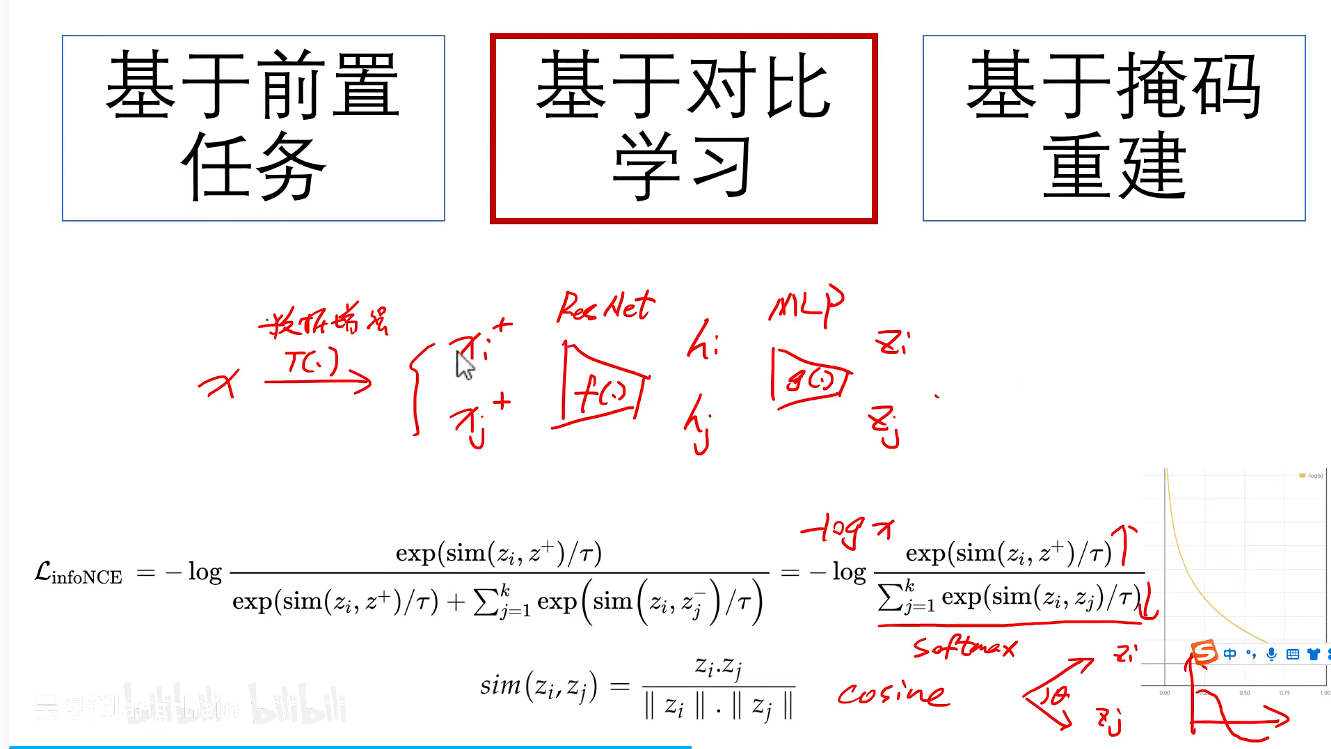
对比学习
我创建一对pair(正样本,负样本),让正样本之间的距离尽可能的近,让负样本的距离尽可能的远。
正样本:原始图像进行数据增强后的图像
负样本:当前Batch中,除锚点图像本身外,所有其他图像的增强视图。
将正样本拉近,负样本推远的这种学习方式,最小化这个loss
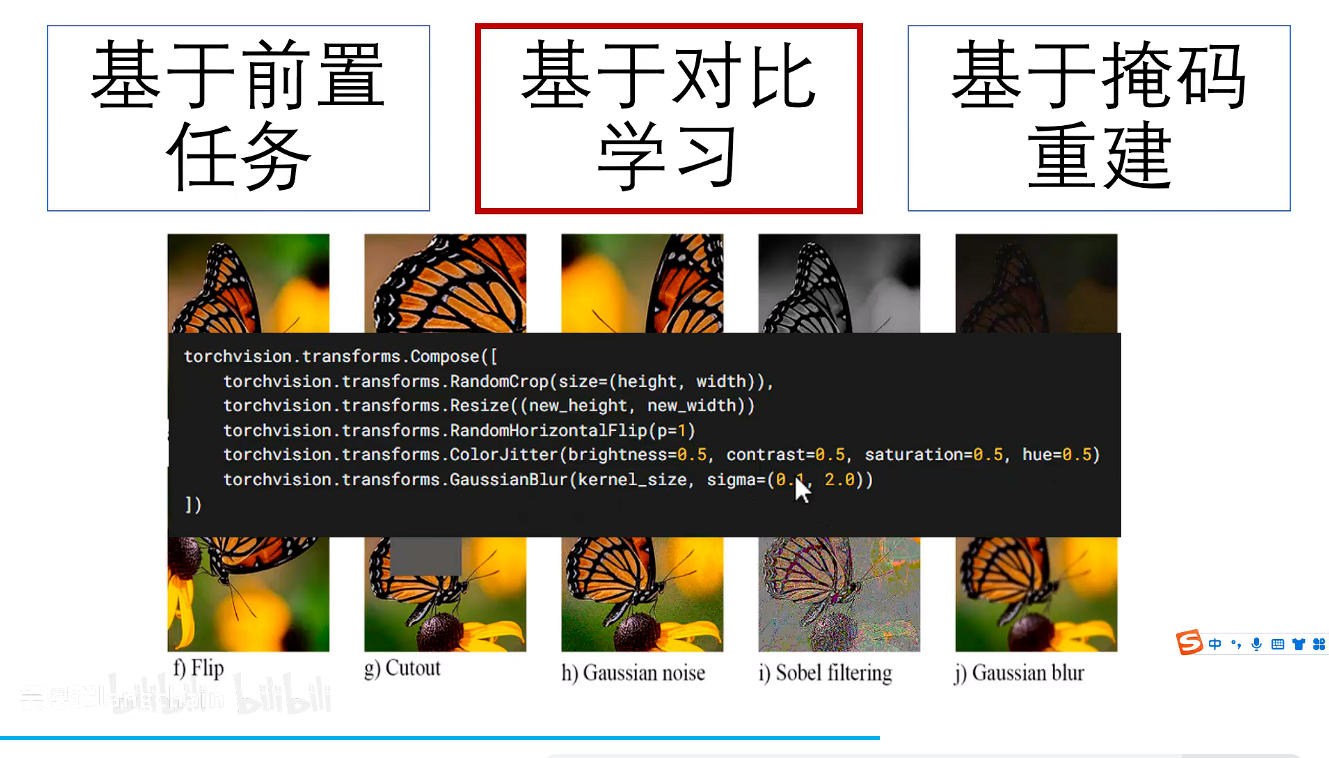
数据增强

对比学习中也会有前置任务比如说:图片的改变也就是数据增强
pytorch中实现方式:
SimCLR
A Simple Framework for Contrastive Learning of Visual Representations
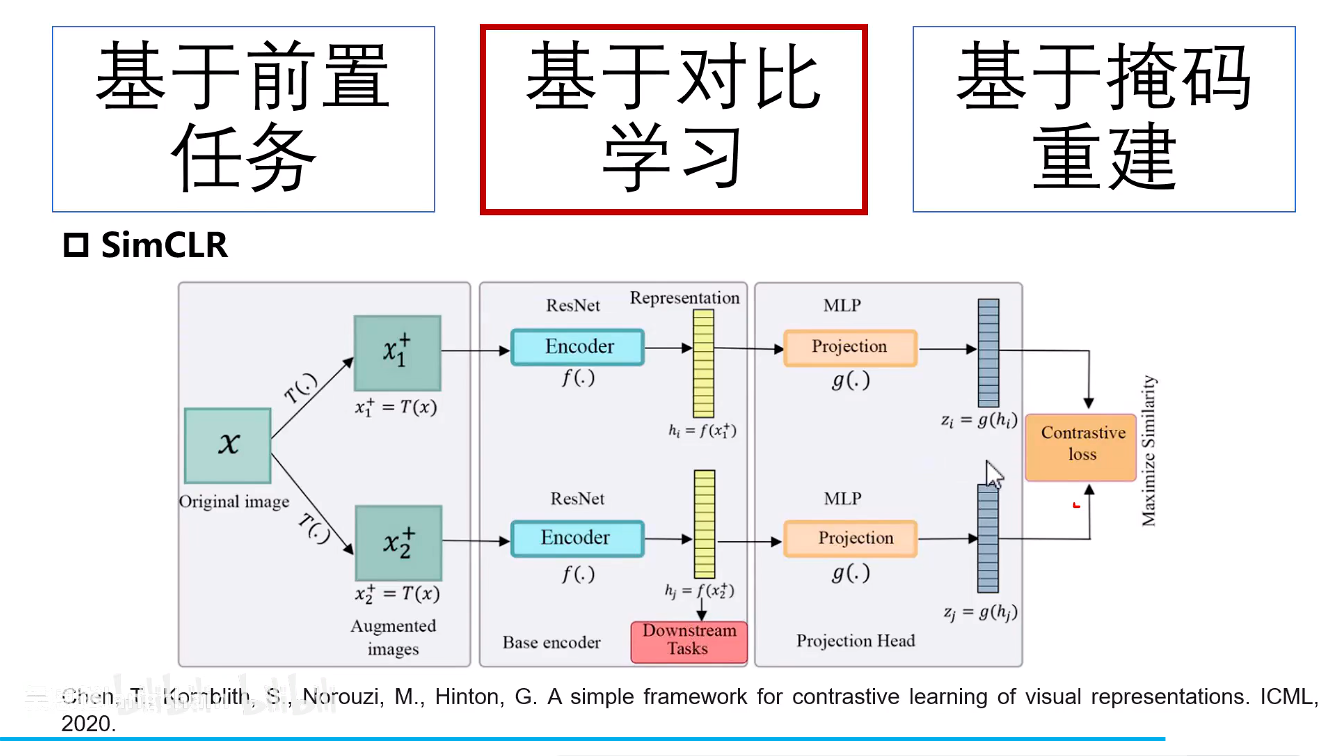
hi和hj进行下游任务特征输入,通过MLP之后zi和zj计算损失反向传播优化。
实验结论:
- 随机裁剪和颜色抖动可以获得更好的一个效果
- batch_size比较大也可以获得一个更好的一个效果,一个大的batch_size中可以包含更多的一个负样本,也就是在一个batch中见到的负样本越多效果相对越好。
- 更大的网络和训练时间可以提升模型效果,比有监督带来的提升更大。
MoCo:Momentum Contrast
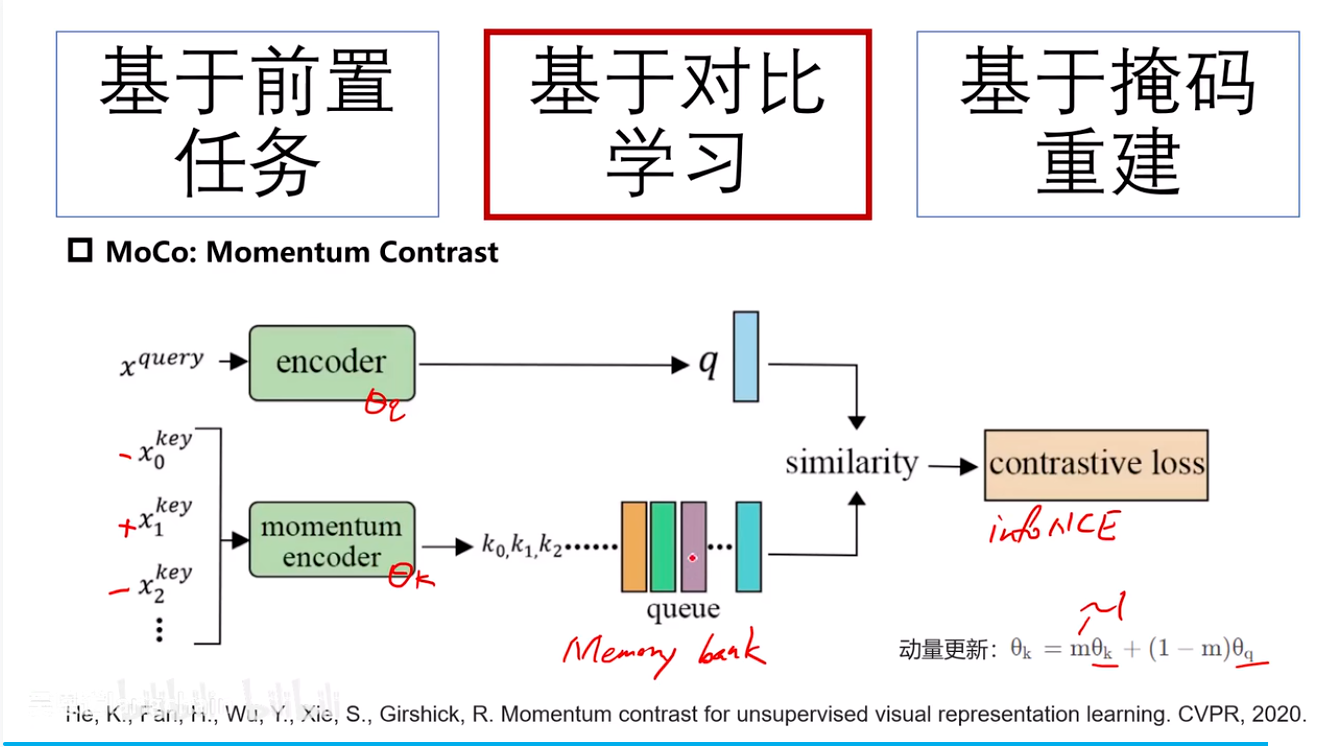
x_query:原始图像
x_key*:数据增强后的图像
encoder是直接x_q求损失反向传播更新
momentum_encoder参与计算对比损失,但其参数通过动量更新从查询编码器继承,而非通过梯度反向传播直接更新。
m≈1
特点:
- 所有的负样本全部放进队列中,方便检索和添加更多负样本。
- 使用动量更新是为了保持键编码器参数的平稳变化,从而确保队列中负样本特征的一致性,避免快速变化的编码器导致对比学习目标的不稳定。
基于掩码重建
BEiT
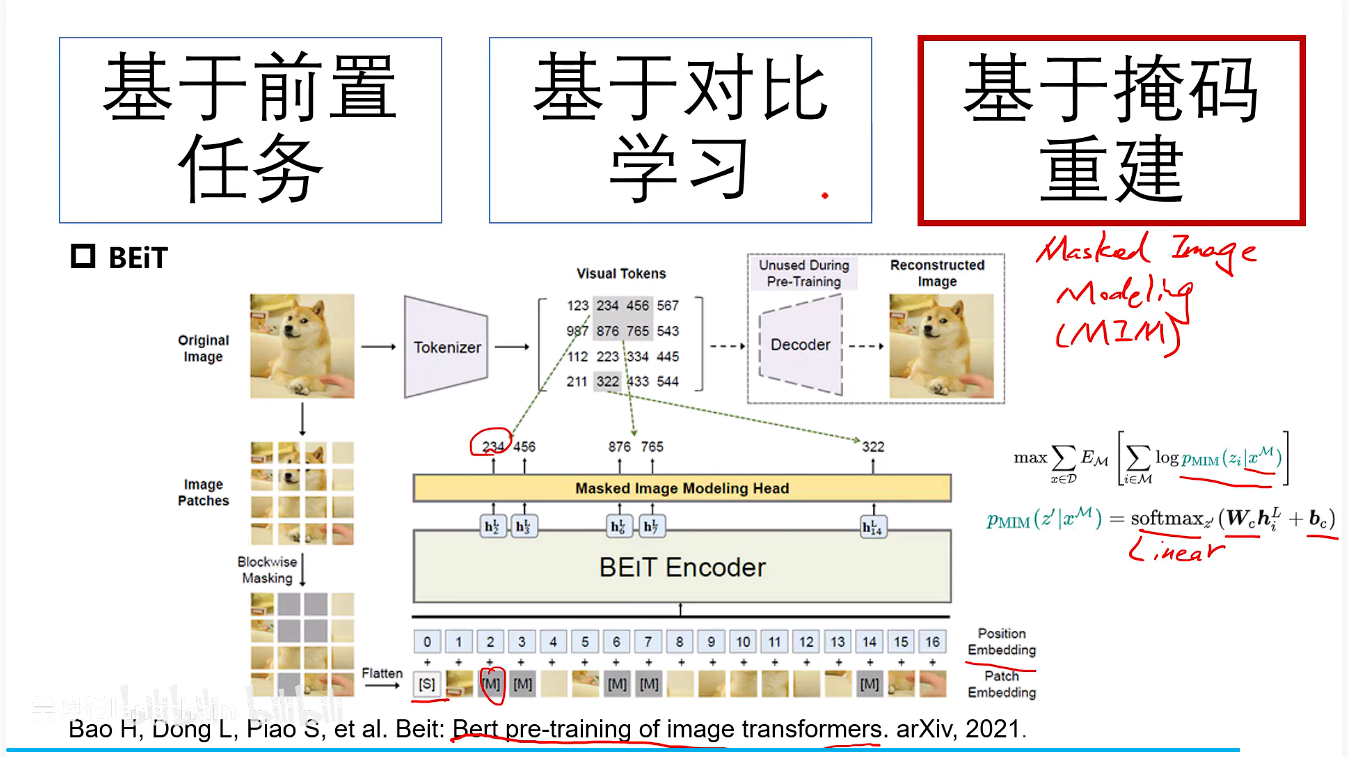
基于Birt的一个思想也就是通过随机挖取空(随机掩码)来预测其位置的图像。
BEiT使用一个预训练好的图像Tokenizer,将每个图像块编码成一个离散的视觉令牌。模型的目标是预测被掩码图像块所对应的视觉令牌ID。
将图像进行tokenizer图像分词,也就是图像中的每一个位置都有有一个token,在预测的时候就是去预测这个token,之后求损失反向传播优化。
Vision Transformer(ViT)
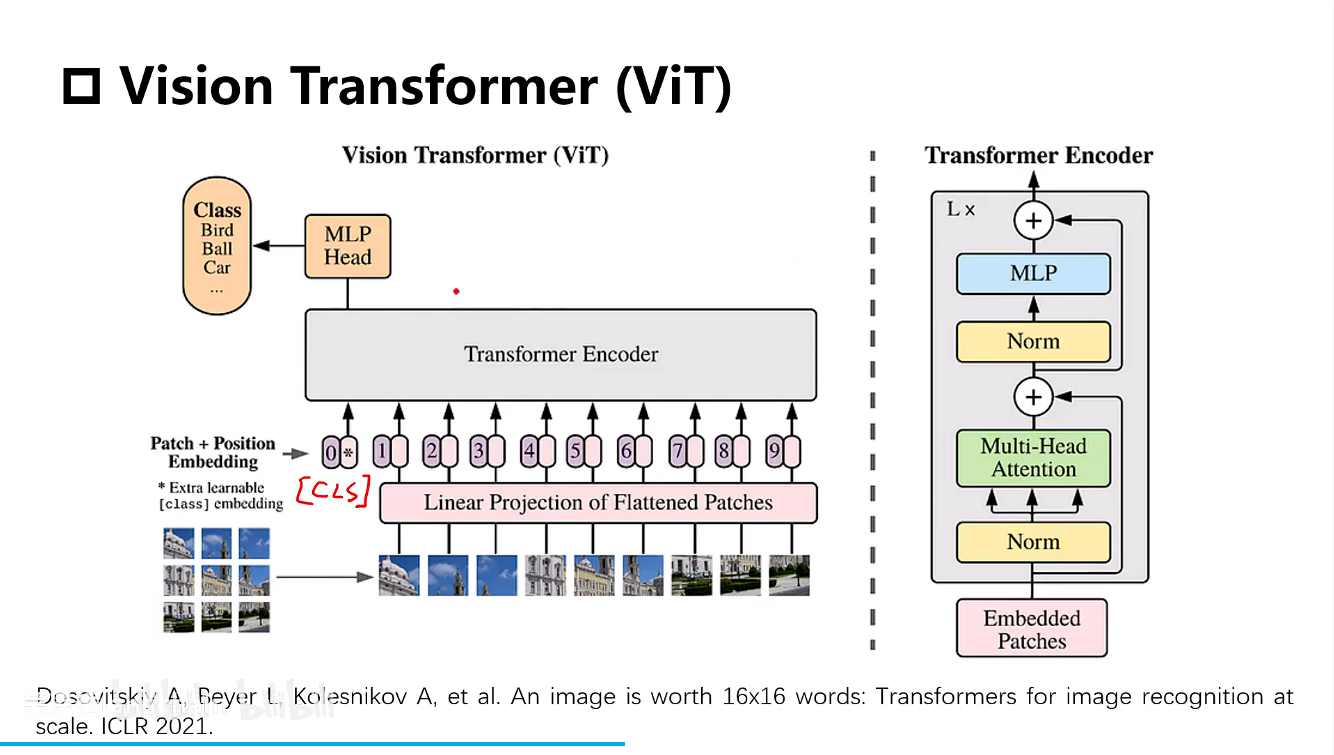
- 一张图像切成多个patch,每个patch对应模型的一个输入位置。
- 通过一个线性的映射层把patch转换成维度的embedding,比如768维度的一个向量,以及一个额外的可学习
[class]令牌以及位置编码。
说白了就是将图片转换成向量 + class令牌 + 位置编码 进行训练。[class]令牌的输出用作最终的表征。
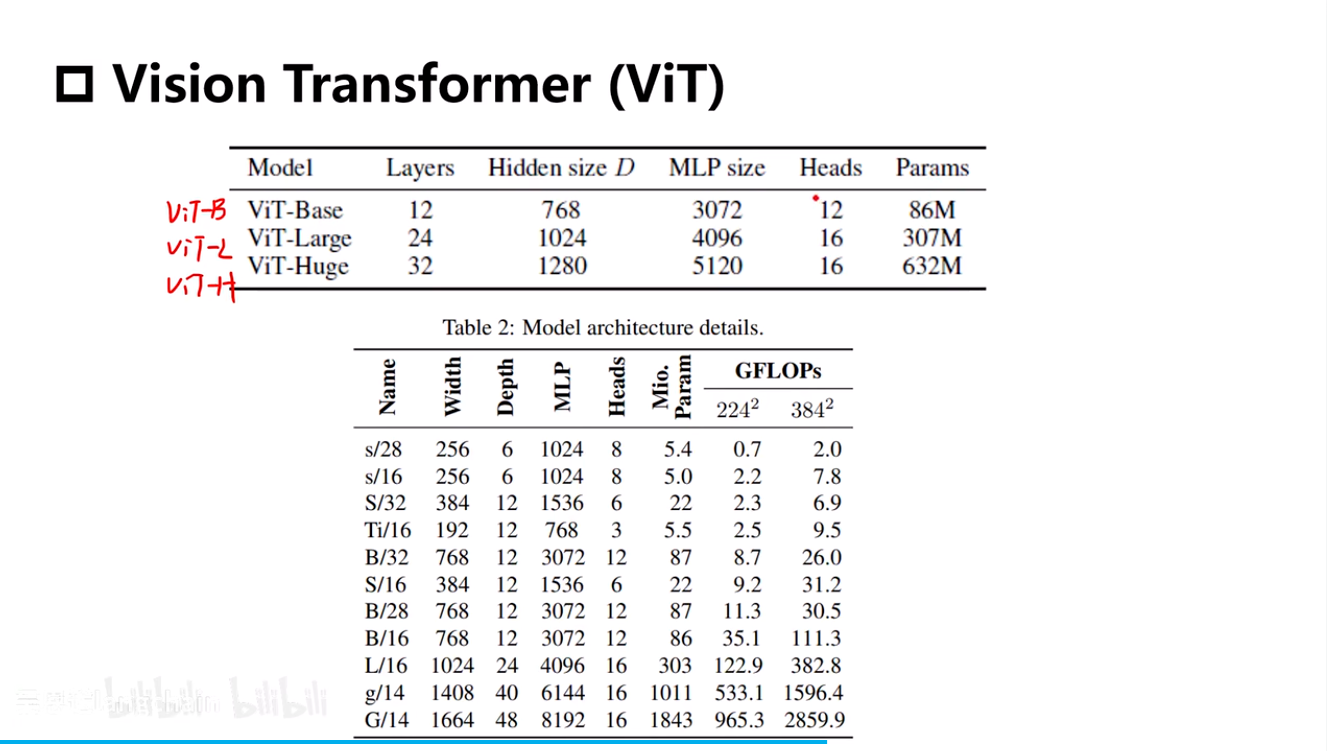
模型规模版本
MoCo v3
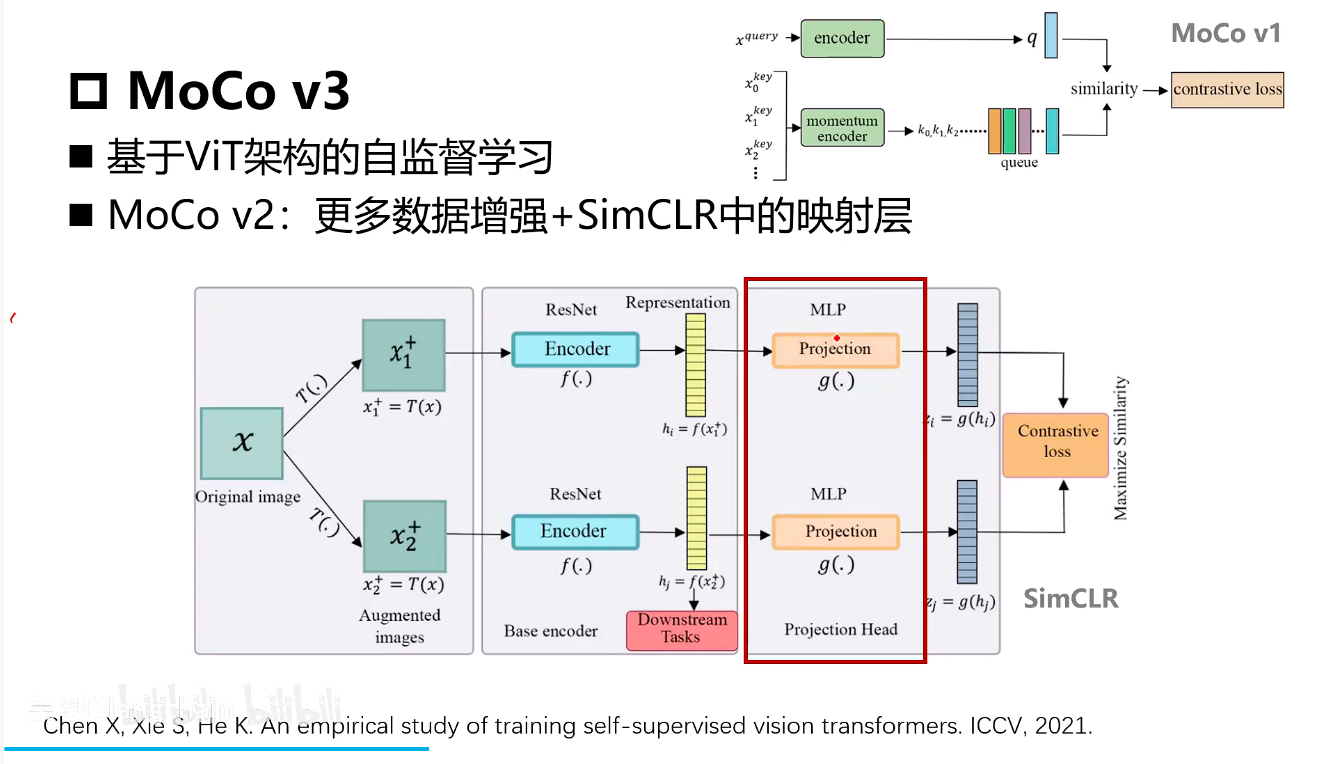
moco v2就是Encoder特征层后加了一层MLP。
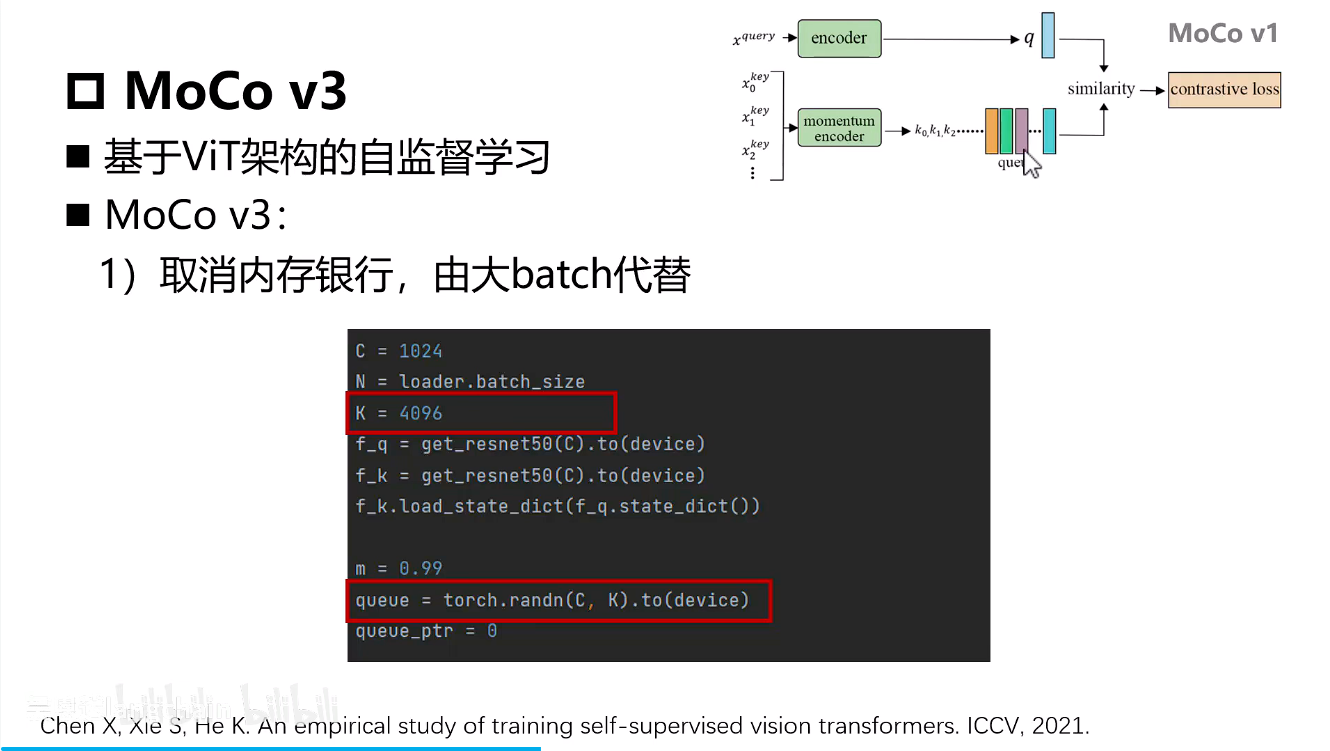
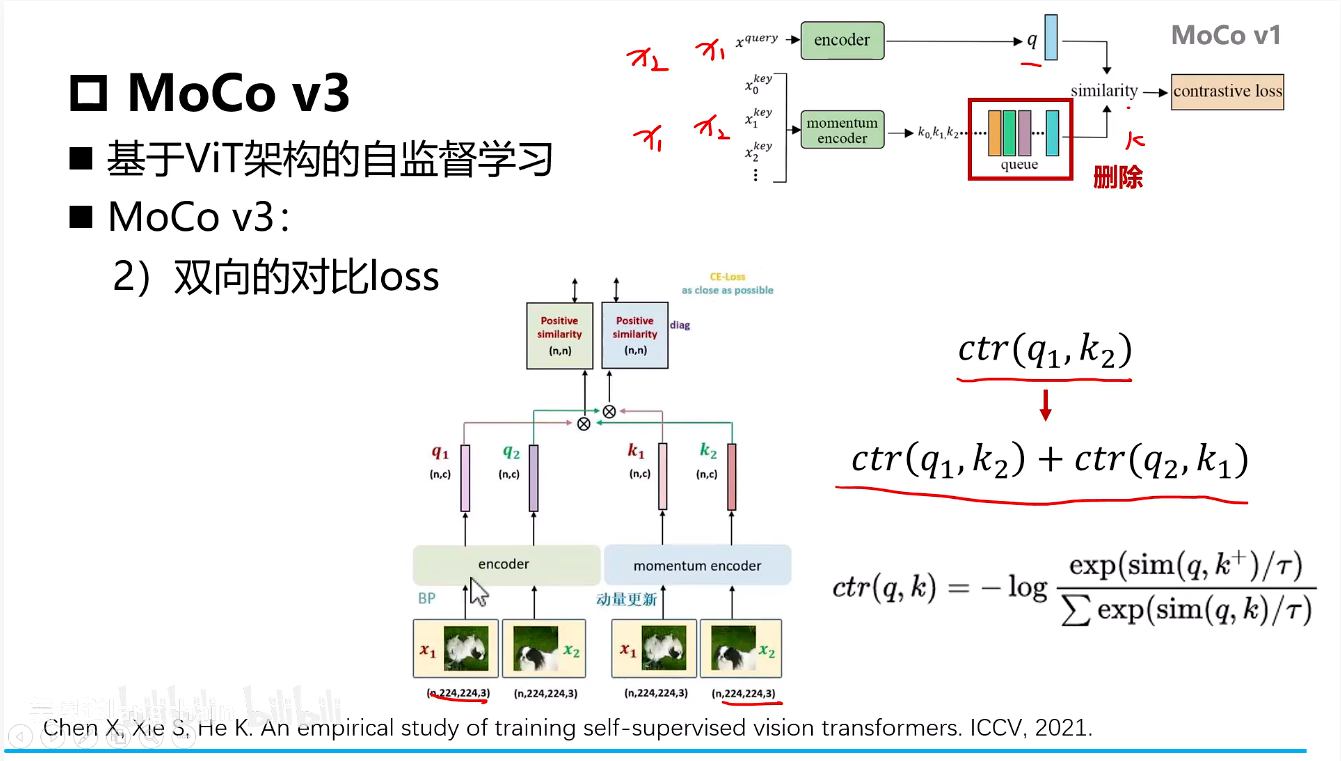
- encoding部分替换成了ViT的架构方式
- 移除了外部字典队列,转而使用当前大Batch内的所有其他样本作为负样本来源
- 采用了对称的对比损失,即计算了
query1 vs key2和query2 vs key1两个InfoNCE损失,并求和。
DINO
Knowledge distillation with no labels
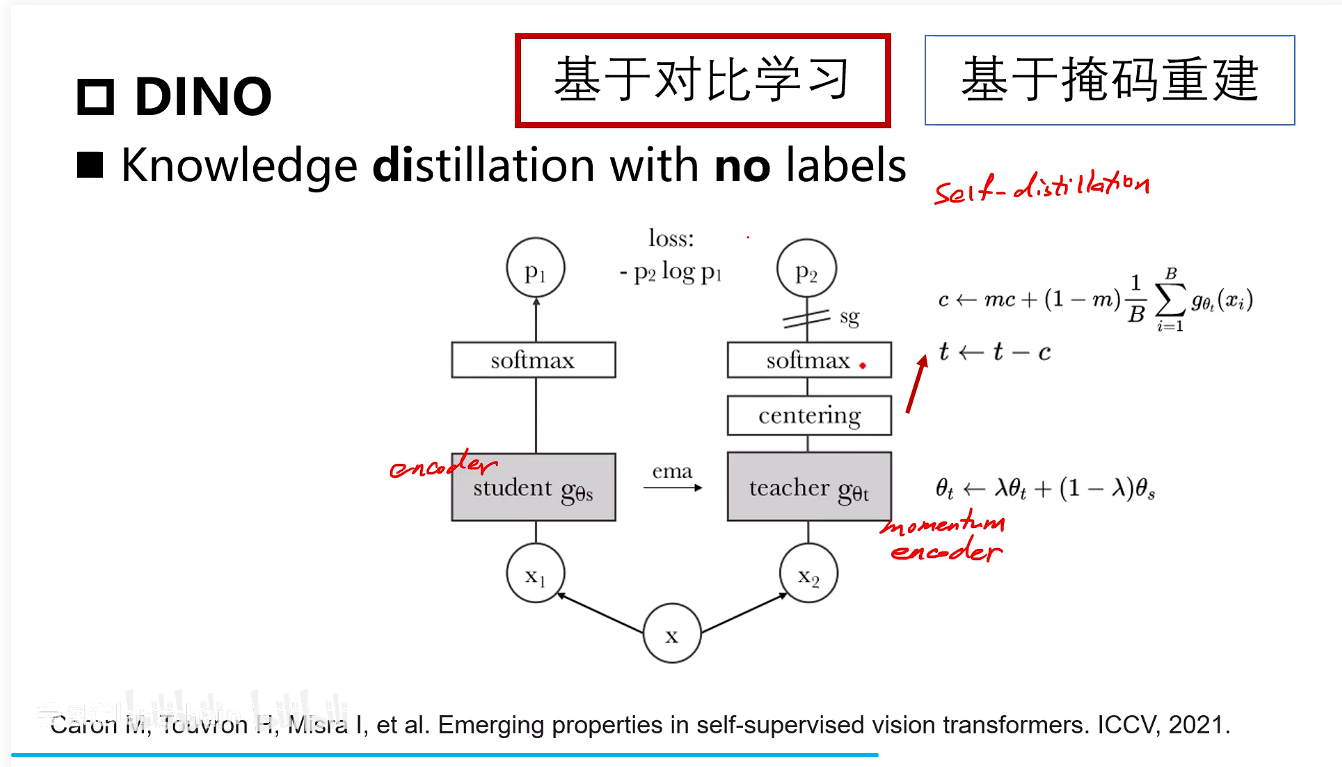
这里的center是一个可学习的参数,它通过一个动量项在整个训练过程中更新,代表所有Teacher网络输出特征的全局中心 ,用指数平滑一下,c可以看作是全局特征的中心,每次输入一张图像进入teacher网络的这个特征减掉这个c
MAE
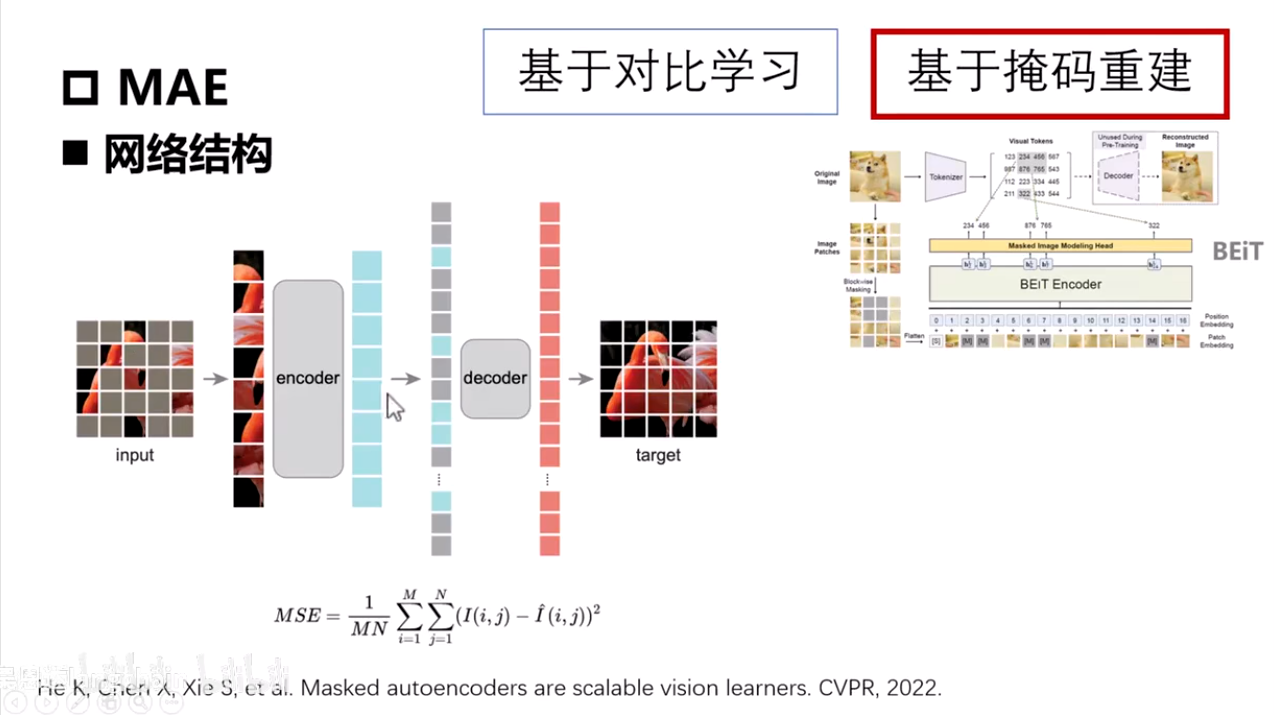
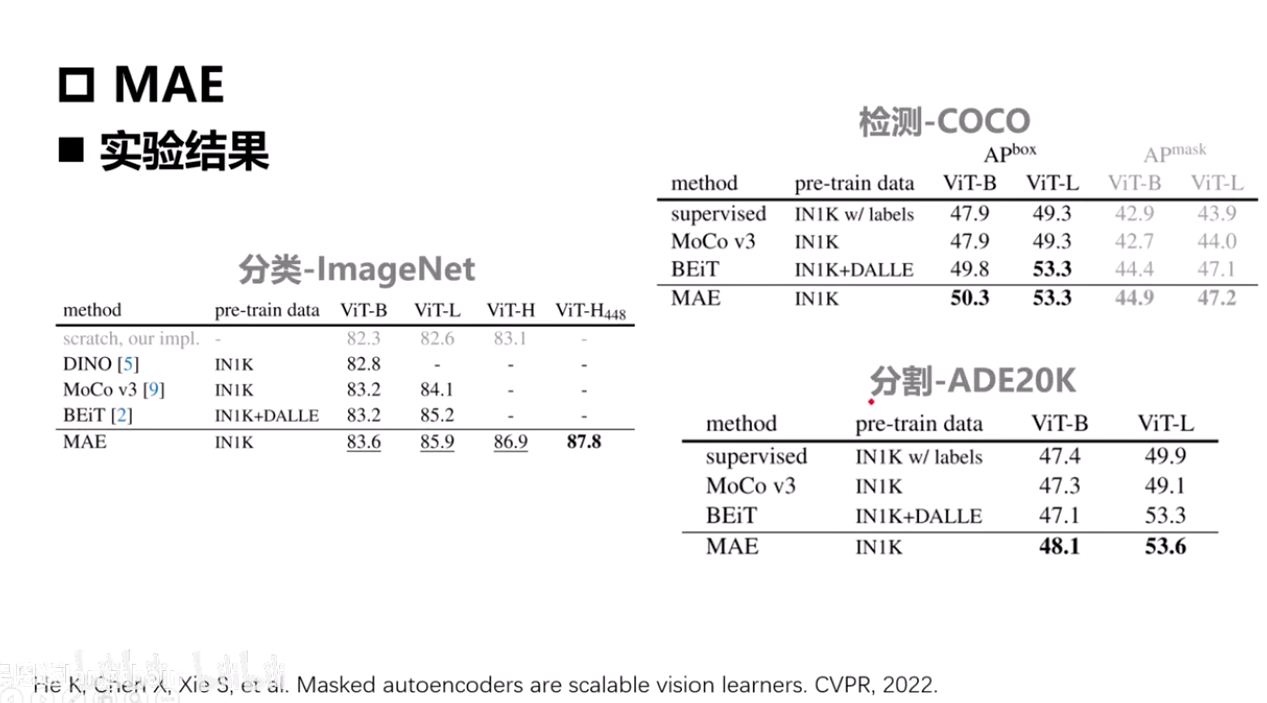
- 例:输入图像mask75%的图像
- 图像向量嵌入通过ViT
- 通过位置编码信息,加上被掩盖的位置进行预测
- 和目标图片进行损失求取反向传播优化
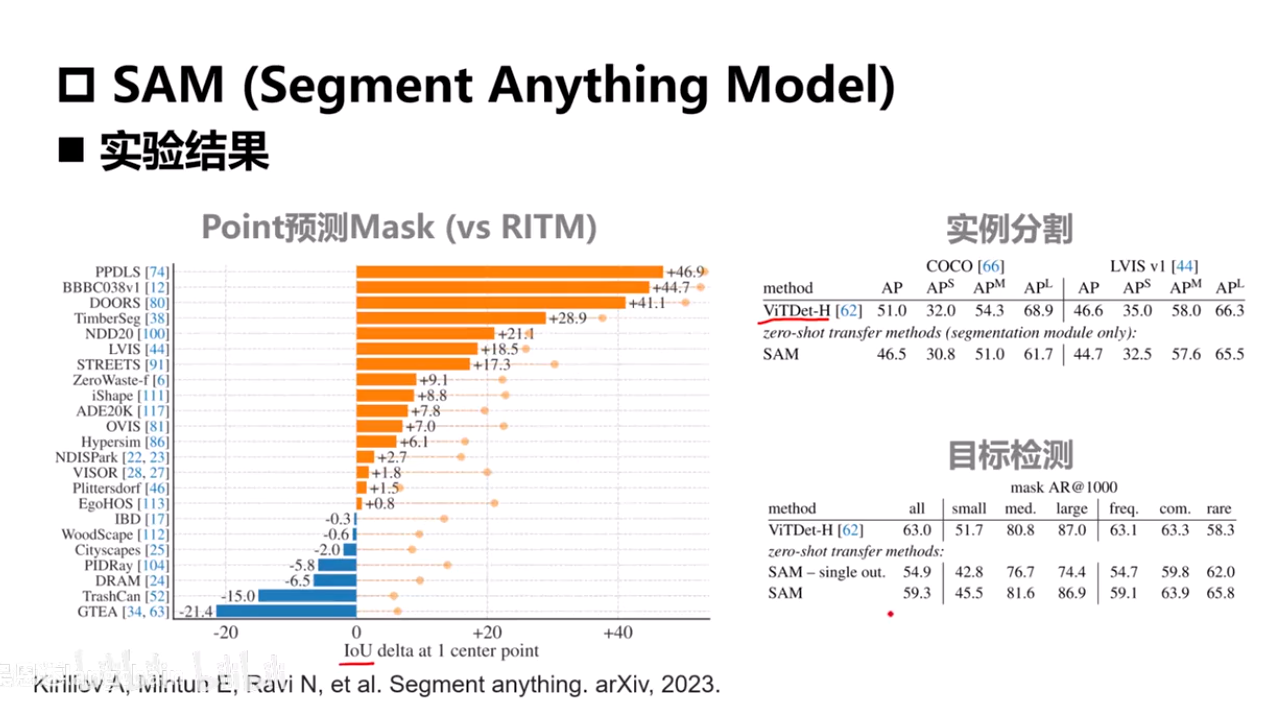
SAM
Segment Anything Model
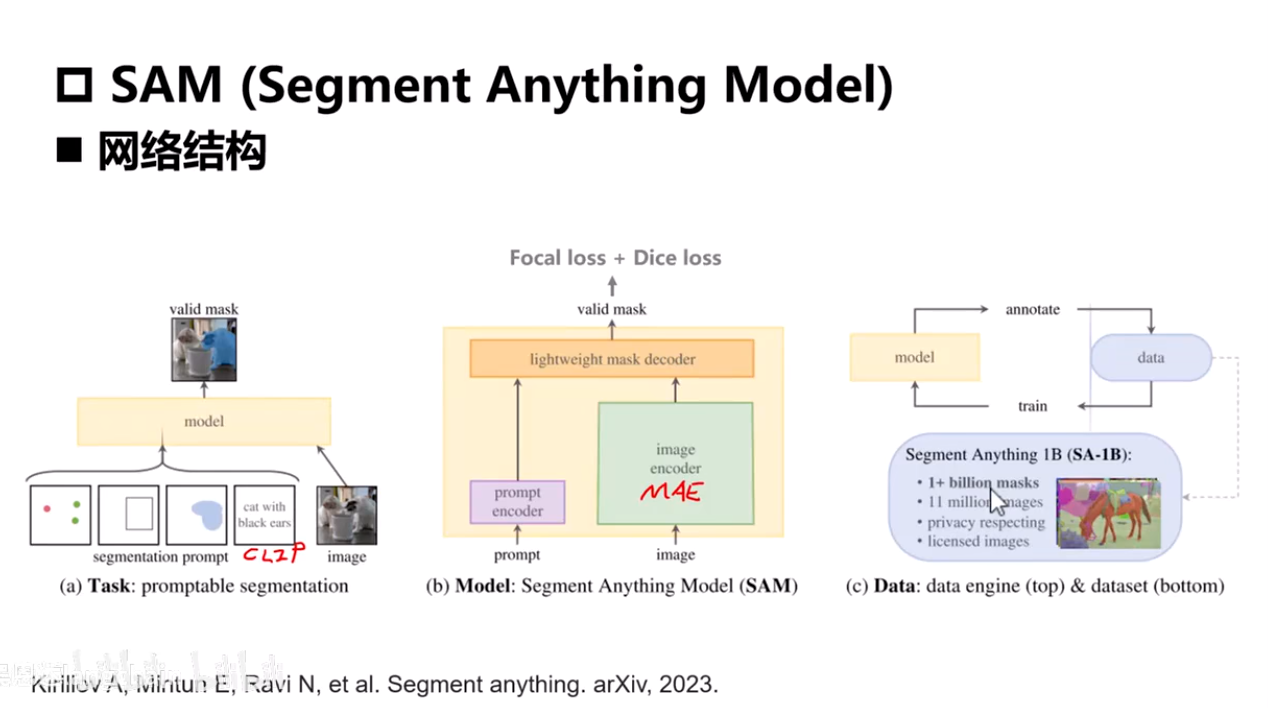
- 文本输入-->prompt_encoder
- 图像输入-->image_encoder
- 将两个特征融合然后经过ViT逐一token的计算
- encoder足够重(预训练模型),decoder足够轻(大模型范式)
- Focal_loss:线性加权,给容易预测的像素值给一个更低的权重,给预测困难的值更高的一个权重值,把注意力放在更加难分割的区域上,比如说前景和背景的边缘。
- Dice_loss:衡量预测的这个mask和真实的mask的重叠度求取的一个损失,类似于IOU(交并比)
模型训练策略:
- 先用有真实标签的数据集去训练第一版的分割模型
- 然后拿这个模型去给没有标注的数据预测一个假的标签
- 设置了一个检测机制,检测结果是否可信(半自动标注),剩余数据进行人工标注
- 再用这个数据去训练这个模型
- 训练好后再用新数据集去训练模型
- 不断迭代
研究方向提出:从海量的数据集中找出最具代表性的一些数据来训练模型,用最少的数据集训练出最有效果的模型
多模态的概念
多模态类型
- 输入与输出模态不同
- 多模态输入
- 多模态输出
多模态网络的要素
针对于如何融合多模态的信息提出几种方式:
- Encoder:针对每个模态定义单独的Encoder来转成向量
- 图片:CNN/ViT让它变成固定尺寸的向量
- 文本:分词+词嵌入转向量+位置编码
- Align Strategy:不同模态的对齐/融合方式
- LLM(Optional):以大语言模型为核心的网络
模型架构方式
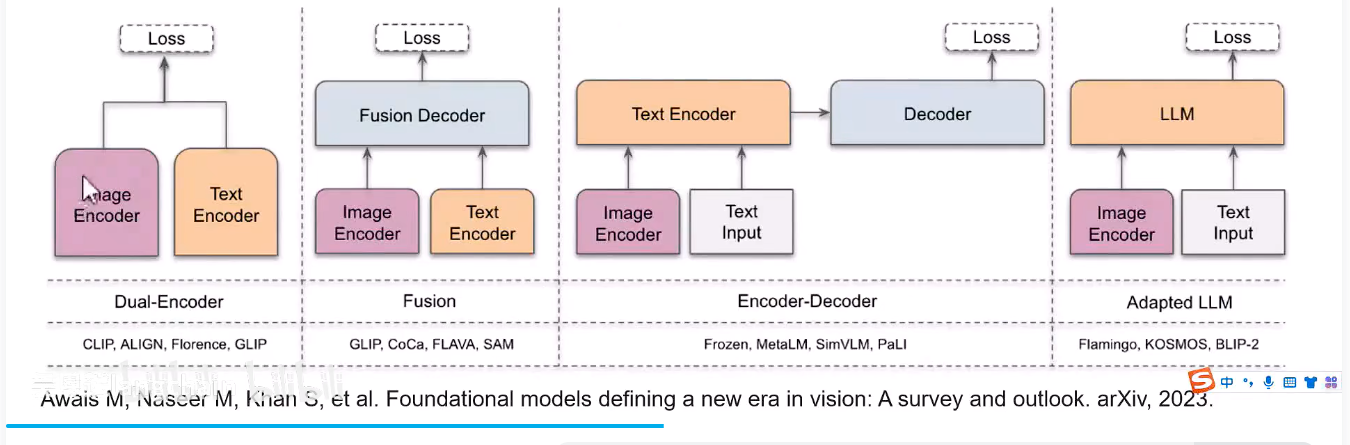
Dual-Encoder:通过对比学习约束image和text这对pair的loss
Fusion:在Dual-Encoder的基础上加入一个融合的decoder,之后再去求loss
Encoder-Decoder+Adapted-LLM:两种架构方式差不多,可以看作是通过大语言模型来架构这个多模态。
CLIP
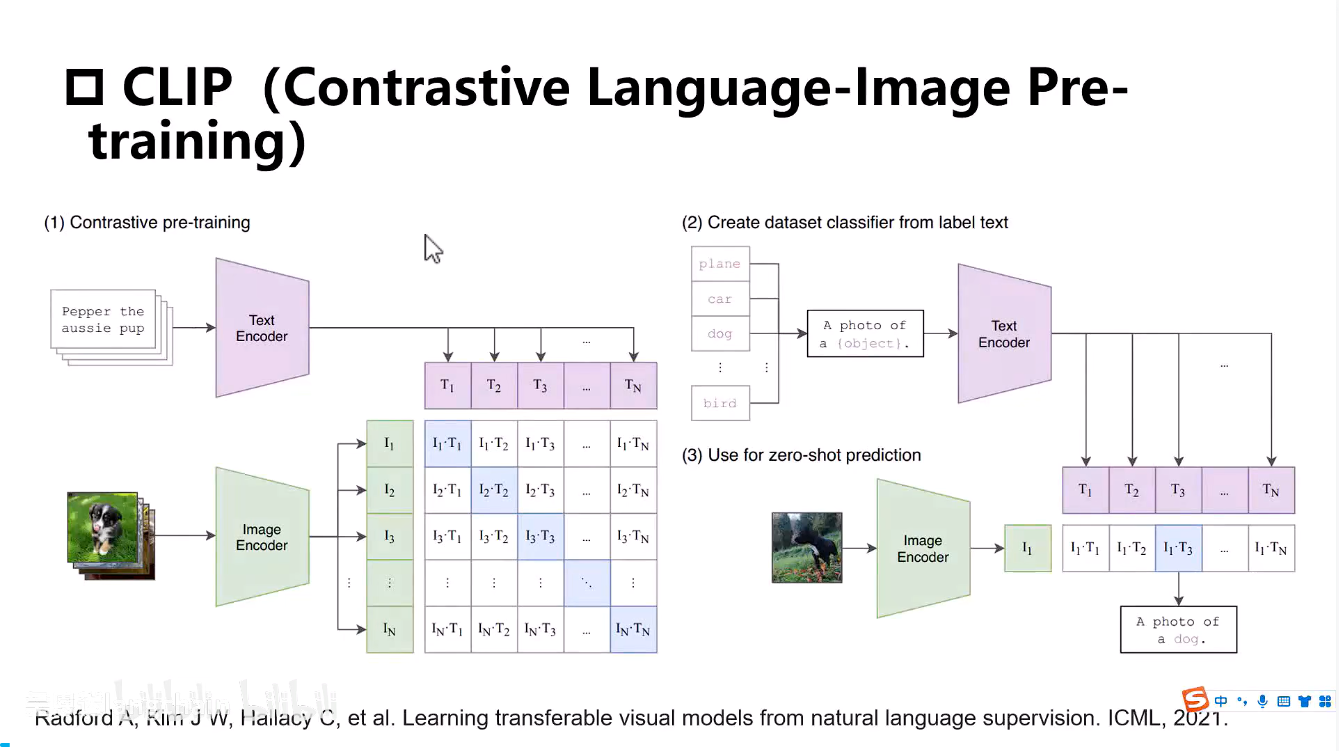
三要素:
-
文本嵌入+图像嵌入
-
同一样本的相似度尽可能的大,不同样本的相似度尽可能小来约束图像与文本之间的距离
-
loss是最大化对角线上的(图像,文本)对的相似度,最小化其他元素上的相似度
使用对称的交叉熵损失,同时从两个方向约束:(1)每张图像与匹配文本的相似度高于其他文本;(2)每个文本与匹配图像的相似度高于其他图像
- 不存在LLM
训练:大量的图像和文本对,进行对比学习
主要用于分类图像
-
通过一个prompt来与图像进行计算一个相似度,然后找到相似度最大的这一个,就认为这个图像属于这个类别
-
输入和标签之间同时经过网络让后来约束他们之间的距离,而不是只有输入到预测目标这样一个单向的路径
Flamingo
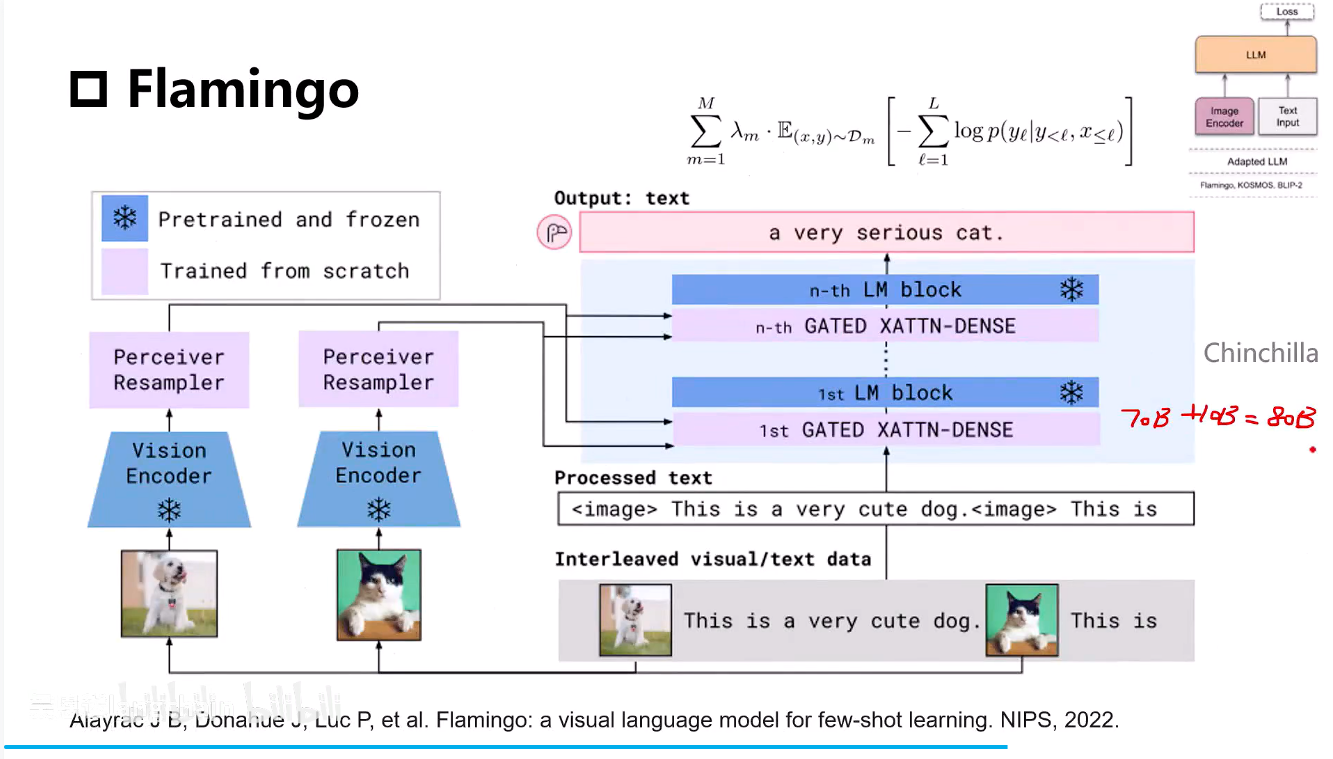
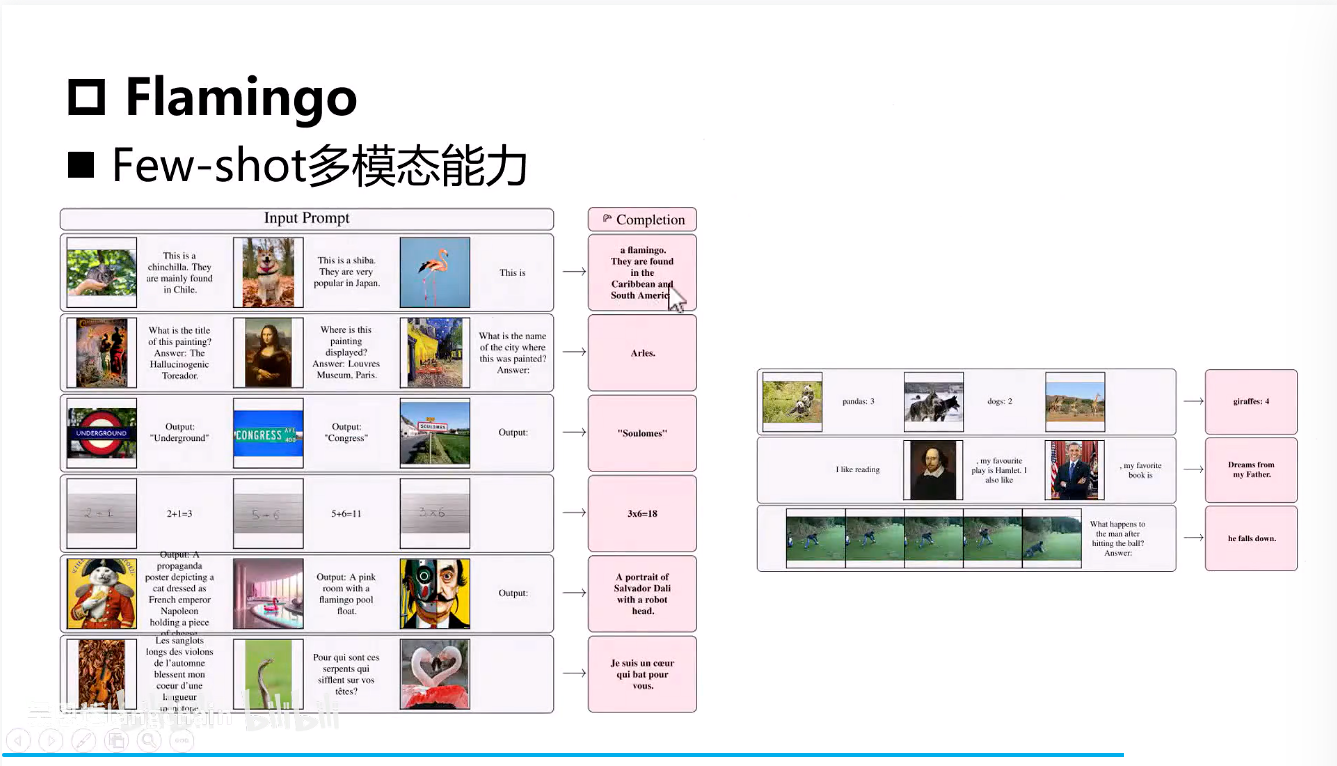
- Vision_Encoder:使用的是CNN+MLP
可以直接使用VIT来优化
- Perceiver Resampler:使用可学习查询向量作为Q,以图像特征作为K和V,通过交叉注意力将图像特征聚合成固定数量的视觉Token
- GATED XATTN-DENSE层:在LLM层中插入,以文本特征作为Q,以视觉Token作为K和V,进行跨模态融合
- 输入图像是有顺序的,用特殊字符进行替换。
LLaVA
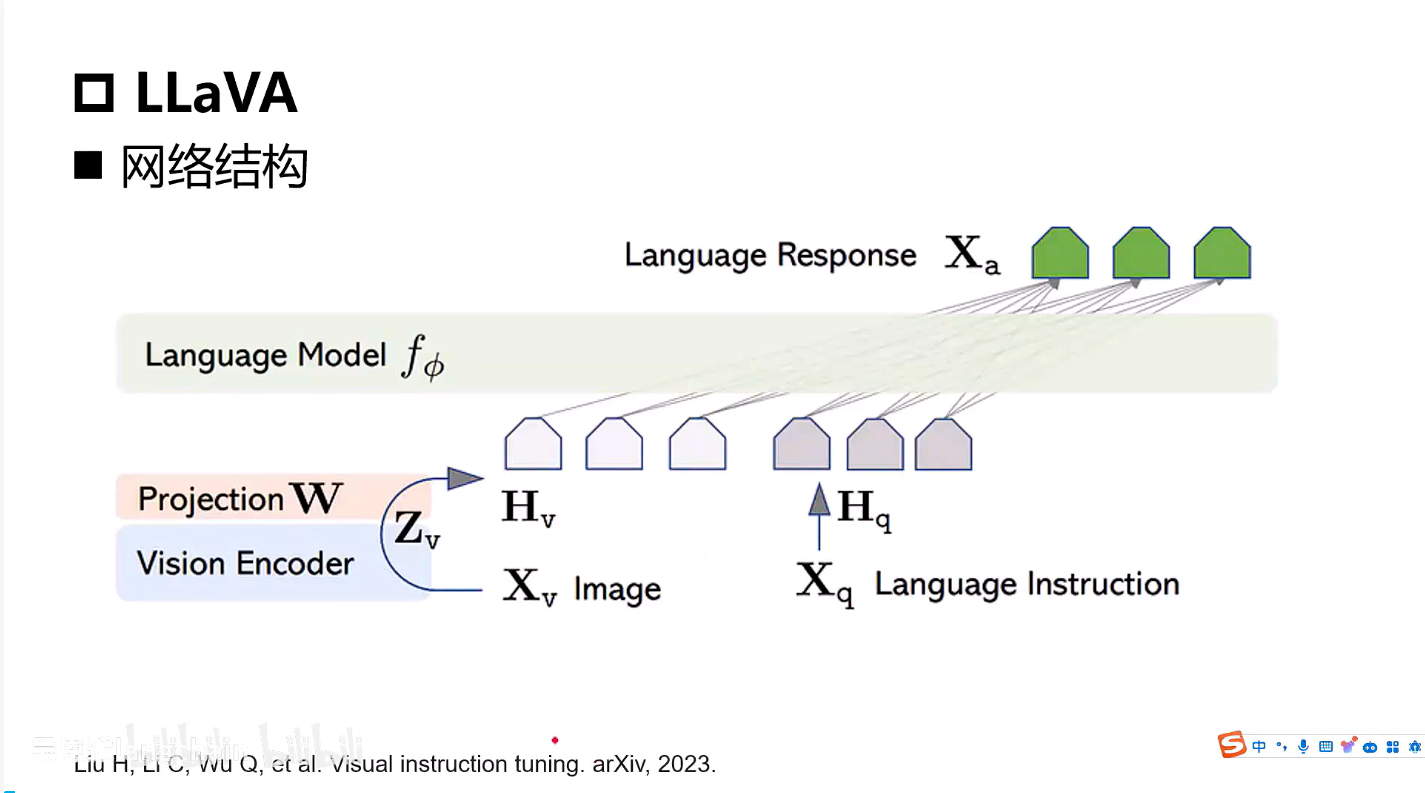
可以近似的看成是一个Flamingo的一个简化版
Vision_Encoder使用的是CLIP训练得到的
LLM使用的是LLaMA
第一个阶段(预训练)
-
训练映射层(ProjectionW)
-
冻结视觉编码器
-
冻结LLM的权重
-
目的是让图像与文本对齐
第二个阶段(精调)
- 冻结视觉编码器
- 训练映射层
- 训练LLM的权重(让模型同时理解图像和文本)
数据集的需求:包含文本和图像的对话形式的数据集
视觉多轮对话能力
最主要的一个方式是采用GPT来生成多模态训练数据的方法,并且用这样的一个形式造出来了一个很大的数据集来训练LLaVA。
o的一个简化版
Vision_Encoder使用的是CLIP训练得到的
LLM使用的是LLaMA
第一个阶段(预训练)
-
训练映射层(ProjectionW)
-
冻结视觉编码器
-
冻结LLM的权重
-
目的是让图像与文本对齐
第二个阶段(精调)
- 冻结视觉编码器
- 训练映射层
- 训练LLM的权重(让模型同时理解图像和文本)
数据集的需求:包含文本和图像的对话形式的数据集
视觉多轮对话能力
最主要的一个方式是采用GPT来生成多模态训练数据的方法,并且用这样的一个形式造出来了一个很大的数据集来训练LLaVA。