深度神经网络训练参数优化概论
深度神经网络训练参数优化概论
- 深度神经网络训练参数优化概论
- 前言
-
- 一、深度学习之向量化与矩阵化
- 二、深度神经网络之L2正则化
- 三、深度神经网络之Dropout
-
- [1、 Dropout如何工作](#1、 Dropout如何工作)
- [2、经典 Dropout 示例:训练 vs 推理](#2、经典 Dropout 示例:训练 vs 推理)
- 四、深度神经网络之数据归一化处理
- 五、深度神经网络之初始化权重参数
-
- [1、 0 初始化](#1、 0 初始化)
- 2、随机初始化
- 3、Xavier初始化
- 4、He初始化
- [六、深度神经网络之全批量梯度下降、随机梯度下降和小批量梯度下降(mini-batch size)](#六、深度神经网络之全批量梯度下降、随机梯度下降和小批量梯度下降(mini-batch size))
-
- 随机梯度下降与小批量梯度下降
-
- 1、随机梯度下降
- [2、 小批量梯度下降](#2、 小批量梯度下降)
- 七、深度神经网络之梯度参数调优
- 八、深度神经网络之参数优化(BatchNormaliztion)
-
- [1、Batch Normaliztion的作用](#1、Batch Normaliztion的作用)
- 总结
前言
一、深度学习之向量化与矩阵化
线性回归向量化的实现
公式:
z = W T X + b {z = W^T X + b} z=WTX+b
z = w 1 ∗ x 1 + w 2 ∗ x 2 + . . . + b ( 神经元 ) {z = w_1*x_1 +w_2*x_2 + ... + b(神经元)} z=w1∗x1+w2∗x2+...+b(神经元)
1、非向量化代码实现
javascript
for i in rang(n):
z += w[i] * x[j];
z += b;2、向量化的代码实现
javascript
w_t = w.T;
z = np.dot(w_t, x) + b;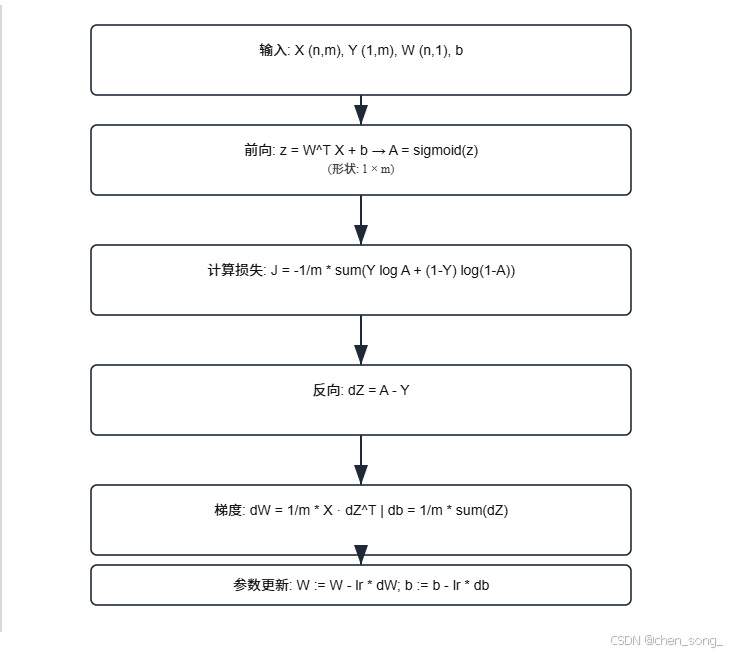
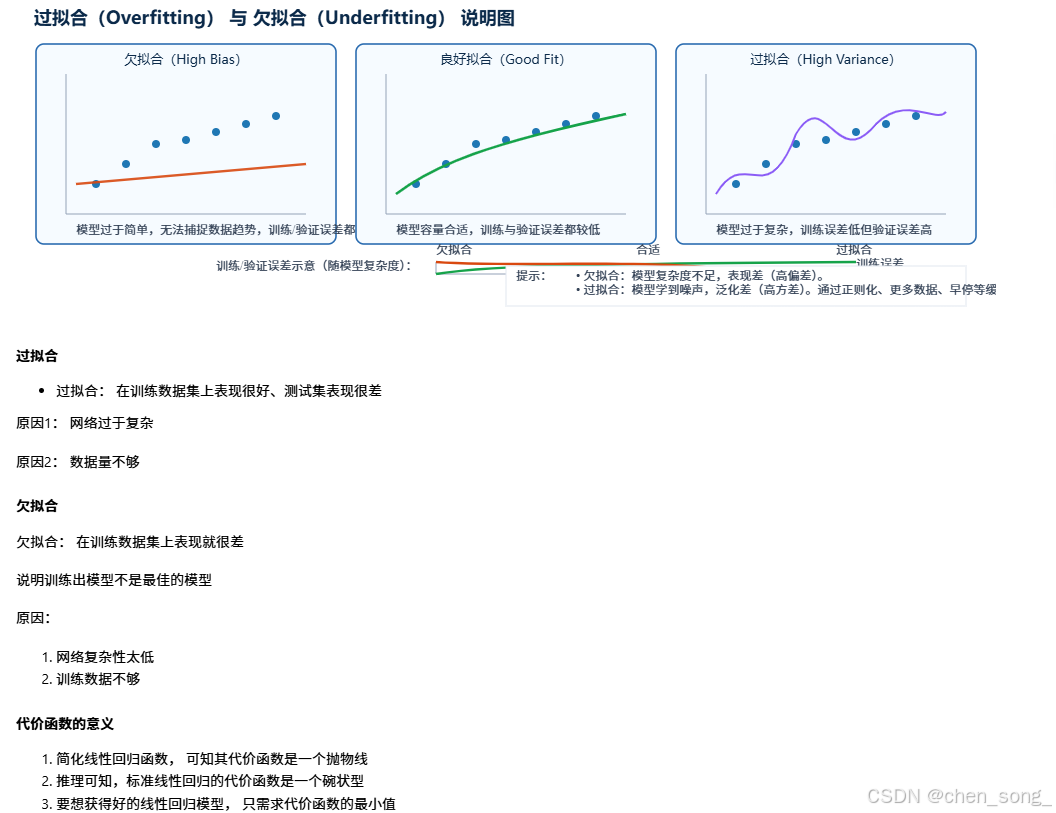
二、深度神经网络之L2正则化
为了让模型更"规则" 或 "平滑"从而得到更稳定,泛化能力更强的模型
作用是降低更过拟合问题
拟合与代价函数
- 拟合: 模拟,合成为一条线
- 损失函数: L(i)(w, b) = 1/2(y^(i) - y(i))2
- 代价函数:J(w, b) = 1/m(w, b)
- 结果越小, 拟合效果越好
一条直线上的误差
三、深度神经网络之Dropout
- L2正则化虽然可以有效降低过拟合,但也有局限性
- 当神经网络特别复杂时,仍然会出现过拟合
- 一种新的正则化提了出来, 就是Dropout
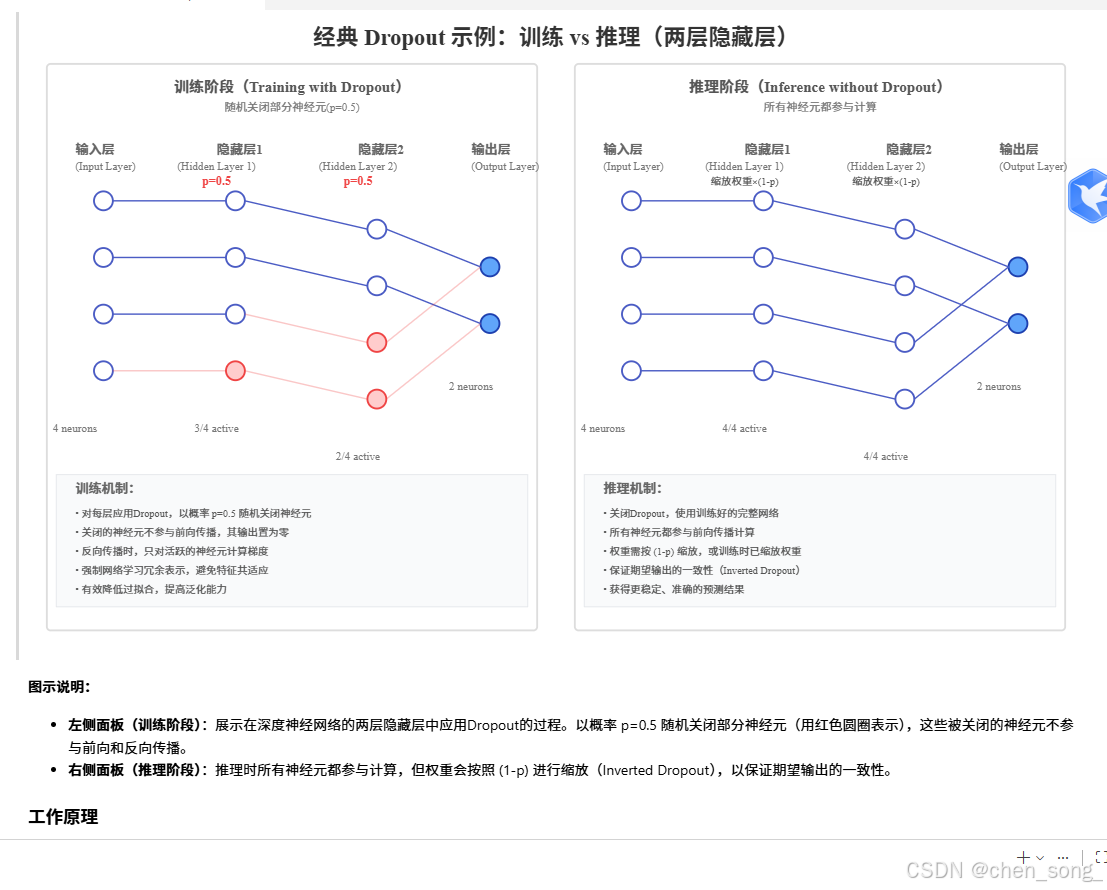
1、 Dropout如何工作
- 在神经网络的每一层随机让一下神经元失效
2、经典 Dropout 示例:训练 vs 推理
四、深度神经网络之数据归一化处理
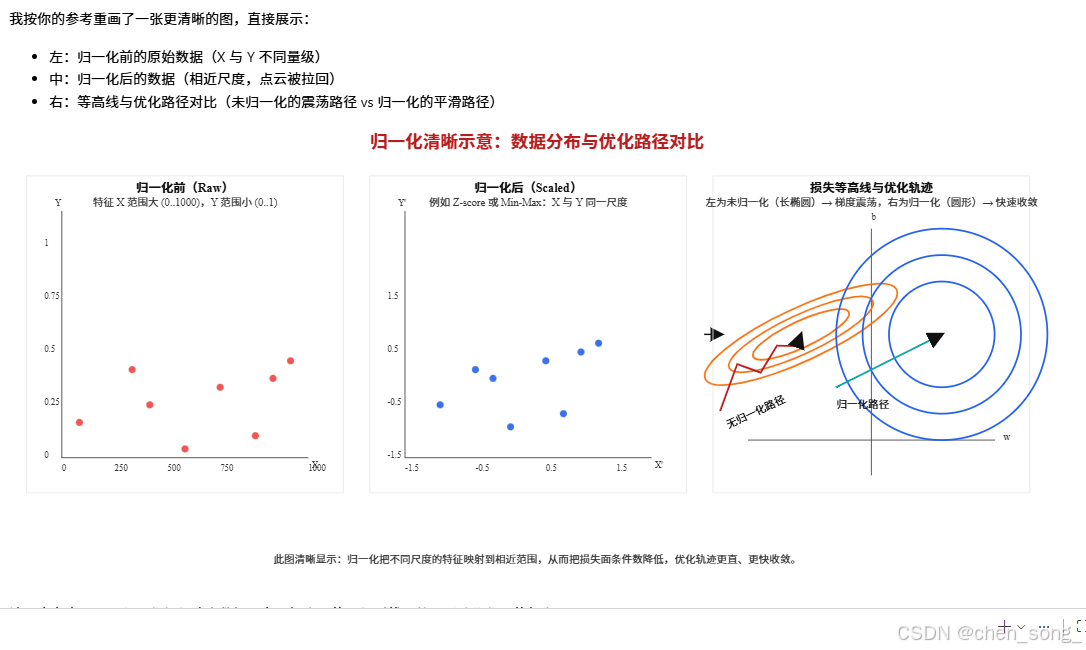
输入数据归一化的好处
- 加快收敛速度: 归一化使不同特征大小相似
- 避免梯度消失: 归一化可以防止输入范围过大或过小
- 提高模型的稳定性和泛化性
- 简化特征空间的映射关系
五、深度神经网络之初始化权重参数
1、 0 初始化
- 将所有的权重初始化为0
- 这种方式会带来严重问题,看个具体的例子
- 当w=0时,wx+b=b,反向传播时梯度消失
- 因此, 也无法有效训练模型
2、随机初始化
- 使用均匀分布或正态分布的随机数初始化
- 当随机数没有选好,也会出现梯度消失
3、Xavier初始化
- 专门针对sigmoid/tanh激活函数的初始化方法
- 可以使每一层输入与输出方差尽量保持一致
- 有效防止梯度消失或爆炸
- sigmoid/tanh很少使用,所以这种方法用的不多
4、He初始化
- He是由何凯明团队发明的
- 它是专门针对ReLU激活函数的初始化方法
- 公式: 2 n {\sqrt{\frac{2}{n}}} n2
六、深度神经网络之全批量梯度下降、随机梯度下降和小批量梯度下降(mini-batch size)
使用整个数据集计算梯度, 之后在更新模型参数
随机梯度下降与小批量梯度下降
1、随机梯度下降
随机梯度下降也称SGD,每次使用一个样本进行梯度更新
随机梯度降的优缺点
- 每次使用一个样本更新一次参数,计算量小
- 它可以更快地进行参数调整,有可能加速训练过程
- 无法充分利用GPU硬件
- 收敛不稳定,容易出现较大的抖动
2、 小批量梯度下降
将数据集分成多个小批次, 每个批次都更新一个模型参数
小批量的优点
- 学习的更快:梯度下降的速度比全批量梯度下降的速度快
- 收敛稳定:它比随机梯度下降收敛的更稳定
- 利用GPU硬件更充分
小批量的缺点
- 引入了新的超参数: mini-batch size
- 如果超参数设置不好, 会引起梯度下降的剧烈震荡
七、深度神经网络之梯度参数调优
- 动量梯度下降: 提出了参考历史梯度来平滑梯度震荡
- RMSProp: 提粗了通过历史梯度的倒数控制学习率控制震荡
- Adam: 动量梯度下降 + RMSProp 的结合
八、深度神经网络之参数优化(BatchNormaliztion)
- 输入数据归一化, 可以加速收敛
- Batch normatch是对隐藏层的数据归一化
1、Batch Normaliztion的作用
- 与输入数据归一化类似, 可以加速训练的收敛
- 同事提升模型的稳定性
- 在使用小批量梯度下降时使用
- 用在神经网络的隐藏层
总结
AI、ML、LLM和AIGC算法应用及其探索项目地址:https://chensongpoixs.github.io/LLMSAPP/