文章目录

概述
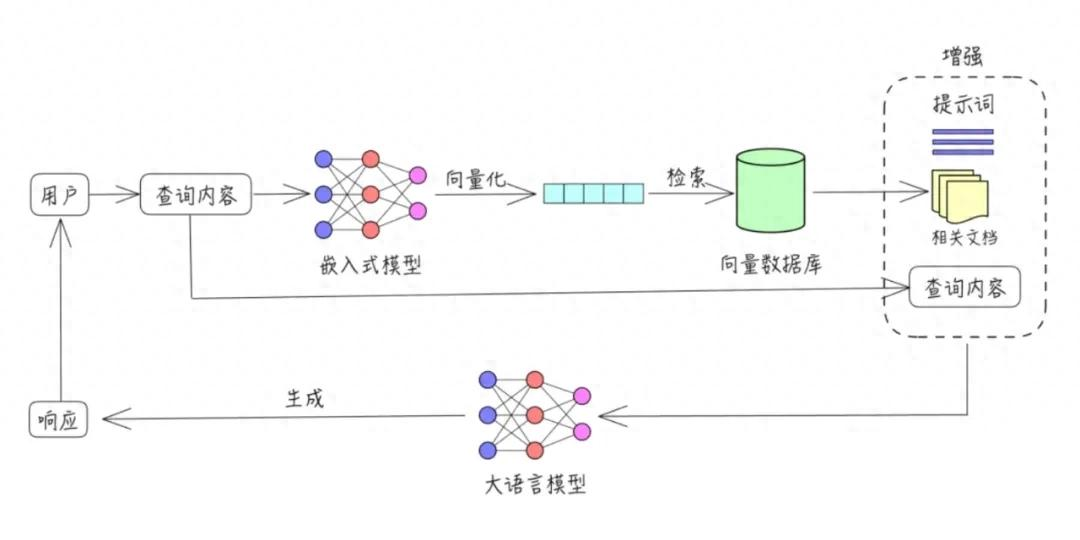
大模型 RAG 的优化可以分层、循序渐进地做:从数据与检索质量入手,再到生成策略和整体架构设计,最后用完善的评估与反馈体系持续迭代。
优化前先评估
在任何优化开始前,需要先建立一套可重复的评估体系,否则根本无法判断"有没有变好"。评估通常至少覆盖四类指标:
- 检索精度(例如 HR@K、MRR)、
- 生成质量(准确性、相关性、流畅度)、
- 真实性/faithfulness(是否严格依据检索文档,避免幻觉)
- 以及延迟与成本(整体响应时间与计算开销)。
一个完整的优化循环一般是"定位问题 → 应用针对性策略 → 评估 → 再迭代"。
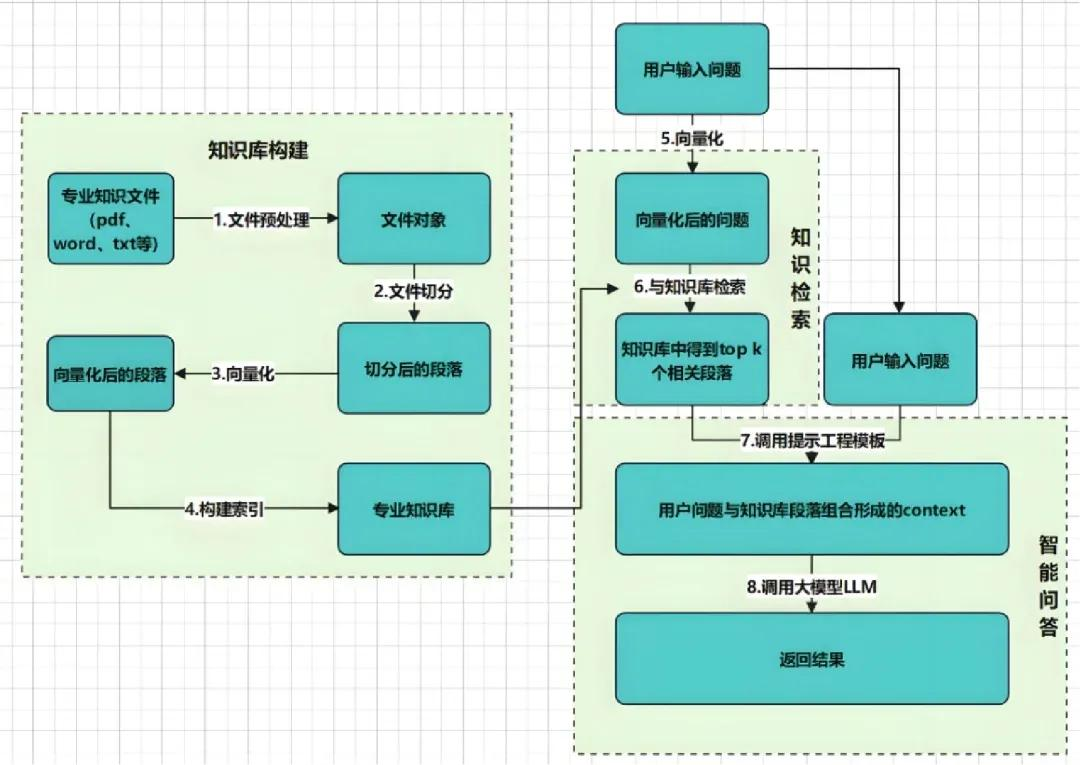
层次一:数据与切分
数据质量是 RAG 的地基,输入是垃圾,输出必然也是垃圾,因此首要工作是"喂好料"。
在文本切分上,应避免简单按固定长度硬切,而采用
- 递归分割(先按段落、标题再对过长部分二次划分)、
- 语义分割(按语义单元划块)
- 带重叠的滑动窗口,降低关键信息被切断的概率。
此外,应为每个 chunk 增强元数据(来源文件、章节、作者、创建时间、类型等),并搭配数据清洗流水线去掉噪声与乱码,让后续检索与过滤更精确。
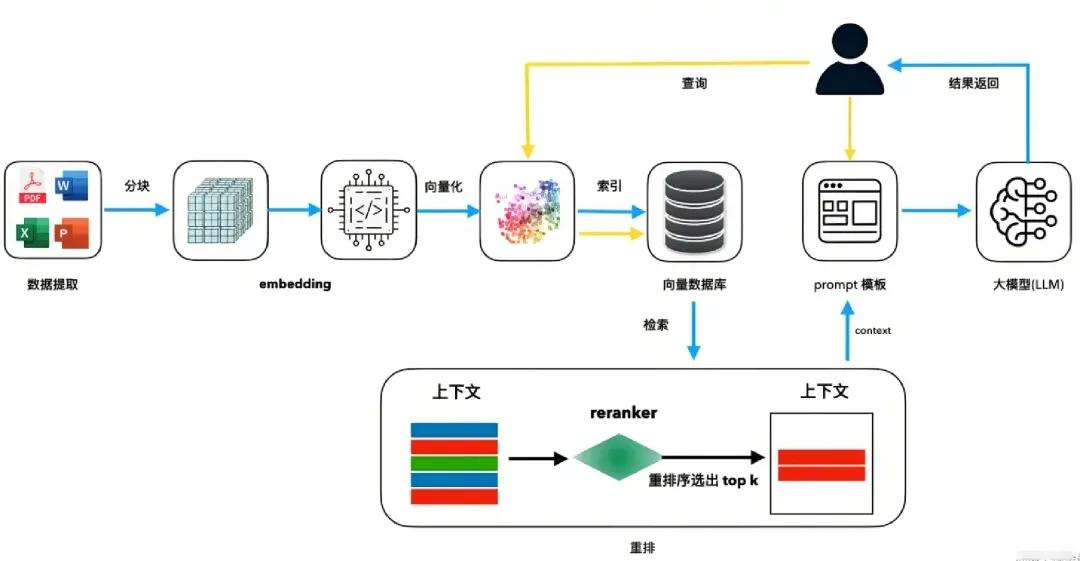
层次二:检索层升级
检索层的目标是"找得又准又全",是 RAG 成败的核心环节之一。
- 可以通过微调用于向量检索的嵌入模型(如对通用 BGE、M3E 等在领域数据上微调),让模型更懂行业术语和领域语义,并在多种嵌入模型之间做评测选型,例如结合不同厂商的大型 embedding 服务。
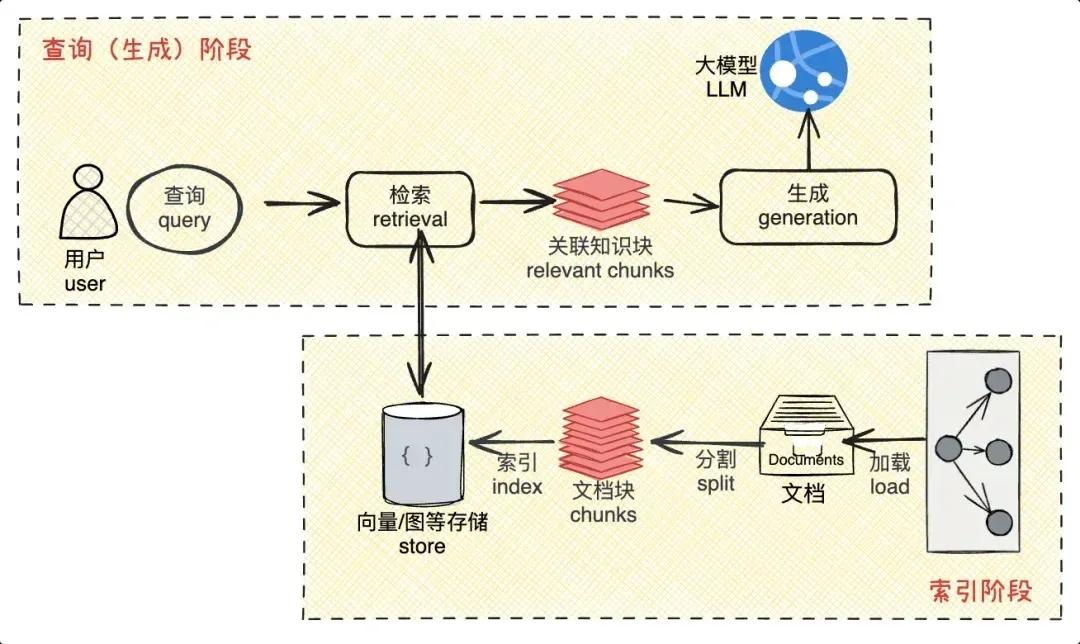
- 同时,引入"语义向量 + 关键词"的混合检索,将 BM25 等稀疏检索与稠密检索融合
- 再对初步 Top K 结果使用专门的重排序模型按 Query-Doc 相关性重新排序,能显著提升送入 LLM 的文档质量。
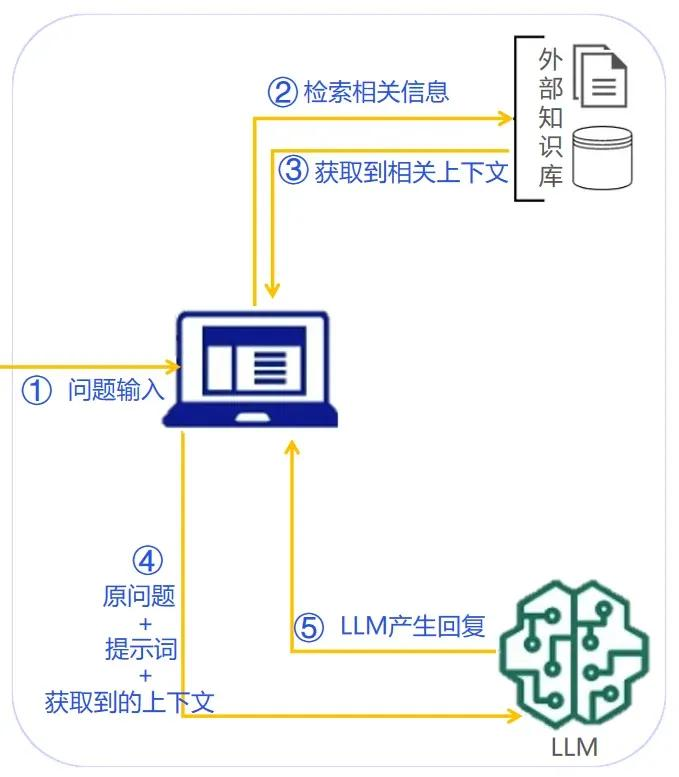
层次三:理解查询与改写
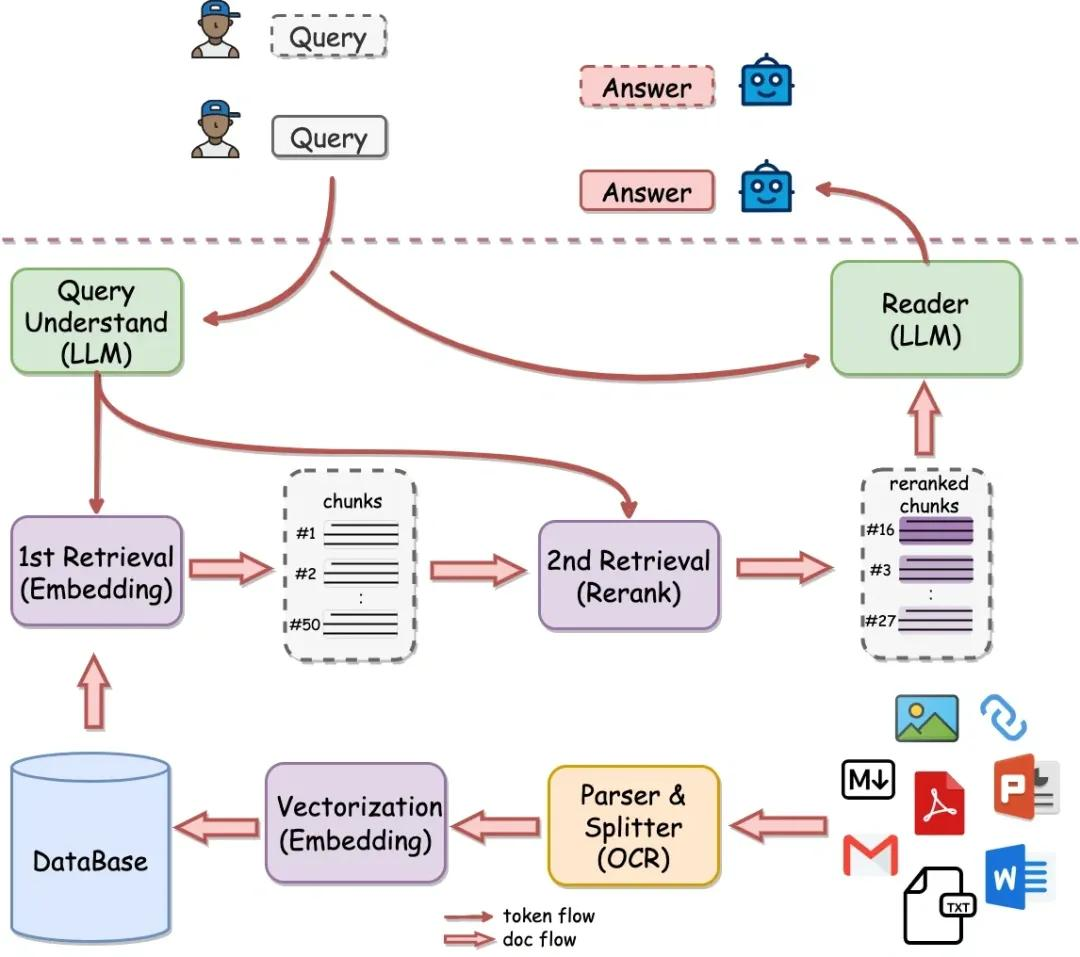
用户问题往往模糊或过短,需要先做"查询理解与改写"。可以
- 利用 LLM 做查询扩展(同义词扩展、生成假设答案、拆成多个子问题)
- 或采用 HyDE 思路:先让模型生成一段"假设答案/文档",再用它去检索更贴近真实需求的文档。
- 在生成侧,提示工程非常关键,可以通过结构化提示(明确"必须严格基于上下文,信息不足要如实说不知道"等指令)
- 以及 Few-Shot 示例(问题--上下文--答案范例)来引导模型优先使用检索内容、减少幻觉。
上下文管理与架构进阶
在长文档、多文档场景中,需要通过上下文管理避免超出上下文窗口并防止关键信息被淹没。
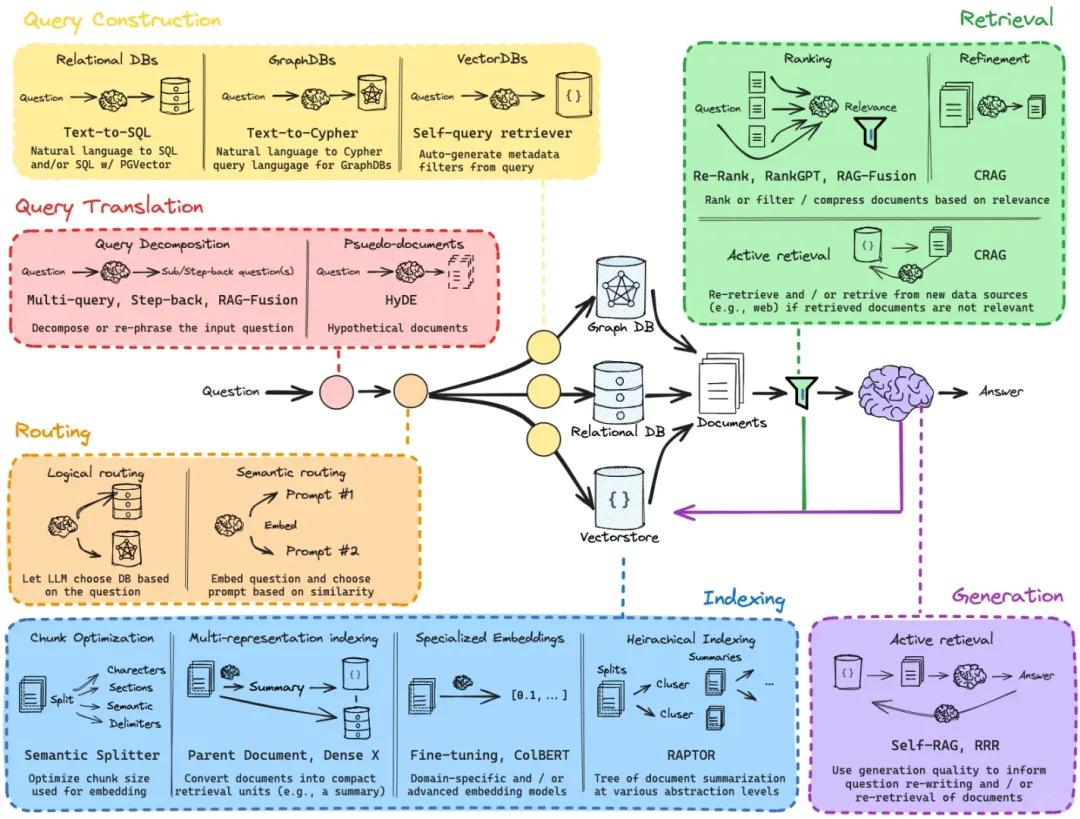
常见方案包括
- Map-Reduce(对每个文档分别生成子答案,再汇总生成最终答案)
- Refine(在逐步阅读新文档的过程中不断改写和完善当前答案),两者都能更好地利用大量检索结果。
进一步的架构优化包括:
-
让系统支持"迭代检索--生成"(LLM检测信息不足时主动发起新一轮检索)
思路: 不让检索和生成一步到位。先让(LLM根据第一轮检索结果进行思考,判断信息是否足够,若不够,则自主提出新的检索查询,进行多轮检索,直到信息充足再生成最终答案。这模仿了人类的研究过程。
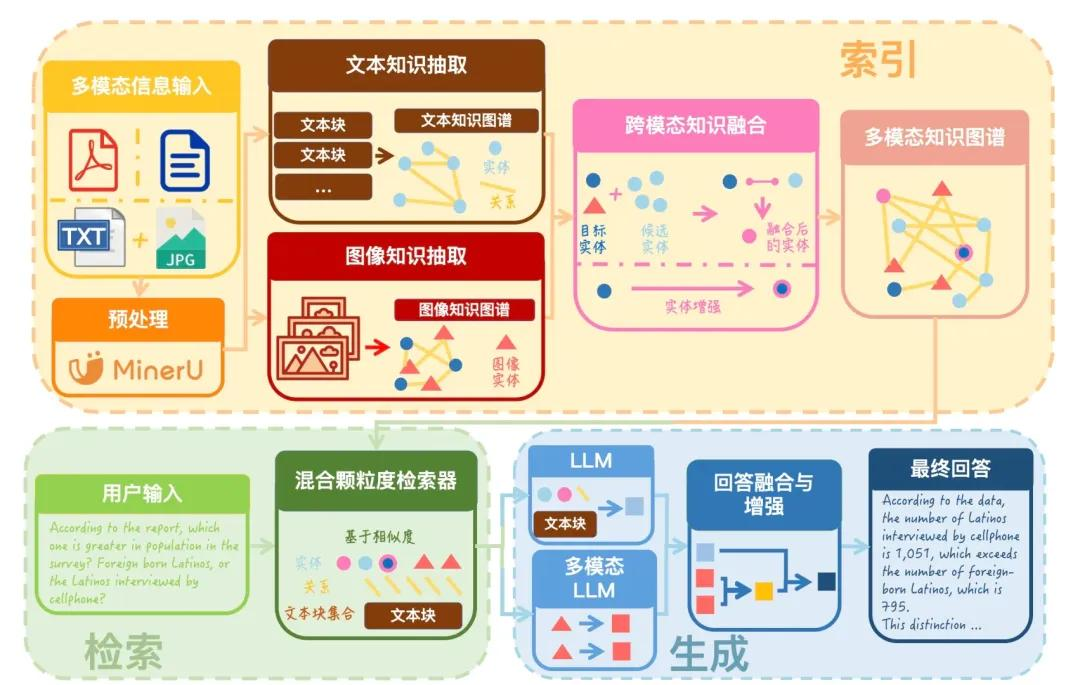
- 在索引阶段构建知识图谱并用 GraphRAG 在图上检索与推理
思路: 在索引阶段,不是简单分割文本,而是构建一个知识图谱。检索时在图谱上进行推理和搜索,能更好地捕捉实体间的关系,实现更深层次的推理 。
-
使用 Self-RAG/Corrective RAG 让模型在生成过程中自检证据、选择性引用来源,从而提升真实性和透明度。
思路: 让LLM在生成过程中具备自我反思能力。例如,在生成每个段落或句子前,判断检索到的信息是否相关、是否足以支持当前论断,并选择性引用来源。这类框架能大幅提升真实性和透明度
持续评估与落地建议
想要长期稳定提升,必须构建自动化评估流水线,对每项新策略做 A/B 测试,并将真实用户的正负反馈回流,用于持续微调检索器和生成策略。
在实际落地时,不必一次上满所有"高级玩法",更推荐从基础的数据优化与检索层优化入手,尤其是嵌入模型微调和重排序模块,这两项往往能以较低成本带来最明显的收益,再根据剩余痛点逐步引入更复杂的架构与自我反思机制。
