学习来源
【PPO × Family】第一课:开启决策 AI 探索之旅
1. 人工智能
- 算力
- 算法:感知型AI(语言、语音、图像)、决策型AI(规划、推理)
- 数据
2. 选择 DRL 的动机
- 搜索最优解的不同方式
- 用 RL 来优化
- 用 DL 来表征
- 决策问题的形式化定义
3. 搜索最优解的不同方式
- 从模仿中学习:归纳与演绎、判别与生成、精确性与多样性
- 从试错中学习:探索与利用、随机与确定、拟合与泛化
4. RL 的特点
- 可以建模环境的未知性和不确定性
- 需要从奖励中学习
- 训练过程是一个在线学习过程,需要平衡探索和利用
5. RL 结合 DL 的原因
- DNN 拥有强大的非线性建模能力和表征能力,可以处理各种模态的输入和输出,可以作为复杂决策场景的输入和输出的建模,可以建模多模态观察空间和混合动作空间
- 可以用 DL 建模 RL 中独有的一些算法概念
6. 形式化定义 RL 的方法
-
问题环境

-
优化目标



-
马尔科夫决策过程
7. 策略梯度
- 在线搜集数据:数据收集器、学习器
- 设计目标:

- 优化策略------策略梯度定理:增大策略选择高回报值动作的概率,减小策略选择低回报值动作的概率(类似极大似然估计)
8. 策略梯度的发展史
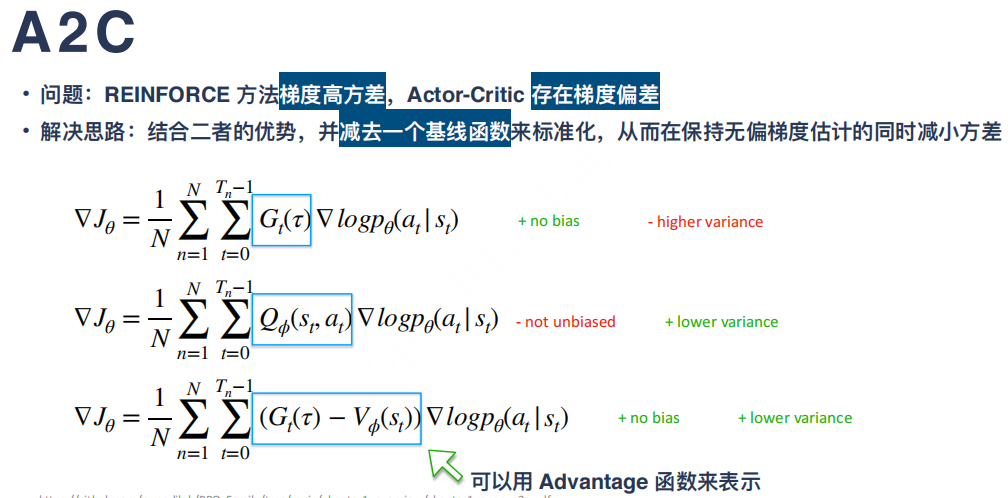
8.1 Reinforce:Actor-Critic、A2C、A3C

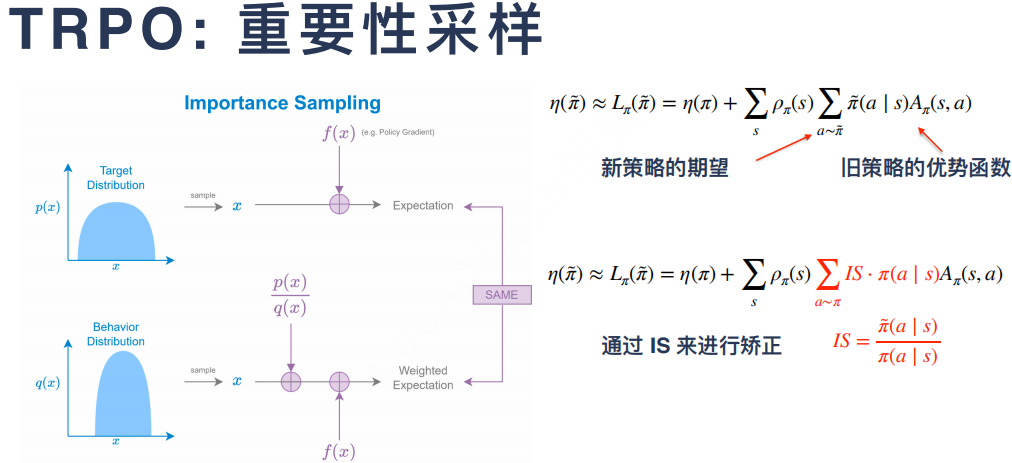
8.2 TRPO:ACKTR、PPO



- DPG:DDPG、TD3