(以下内容全部出自上述课程)
目录
- 基本分页存储管理
-
- [1. 什么是分页存储](#1. 什么是分页存储)
- [2. 页表](#2. 页表)
-
- [2.1 每个页表项占多少字节?](#2.1 每个页表项占多少字节?)
- [2.2 如何实现地址的转换](#2.2 如何实现地址的转换)
- [2.3 如何确定对应的页号和偏移量](#2.3 如何确定对应的页号和偏移量)
- [3. 逻辑地址结构](#3. 逻辑地址结构)
- [4. 小结](#4. 小结)
- 基本地址变换机构
-
- [1. 转换过程--图](#1. 转换过程--图)
- [2. 转换过程-文字](#2. 转换过程-文字)
- [3. 页表项大小](#3. 页表项大小)
- [4. 小结](#4. 小结)
- 具有快表的地址变换机构
-
- [1. 什么是快表](#1. 什么是快表)
- [2. 转换过程-图](#2. 转换过程-图)
- [3. 转换过程-文字](#3. 转换过程-文字)
- [4. 局部性原理](#4. 局部性原理)
- [5. 小结](#5. 小结)
- 两级页表
-
- [1. 单级表存在的问题](#1. 单级表存在的问题)
- [2. 如何解决连续存放](#2. 如何解决连续存放)
- [3. 两级页表的原理、地址结构](#3. 两级页表的原理、地址结构)
- [4. 如何实现地址变换](#4. 如何实现地址变换)
- [5. 如何解决整个页表常驻内存](#5. 如何解决整个页表常驻内存)
- [6. 细节](#6. 细节)
- [7. 小结](#7. 小结)
- 基本分段存储管理
-
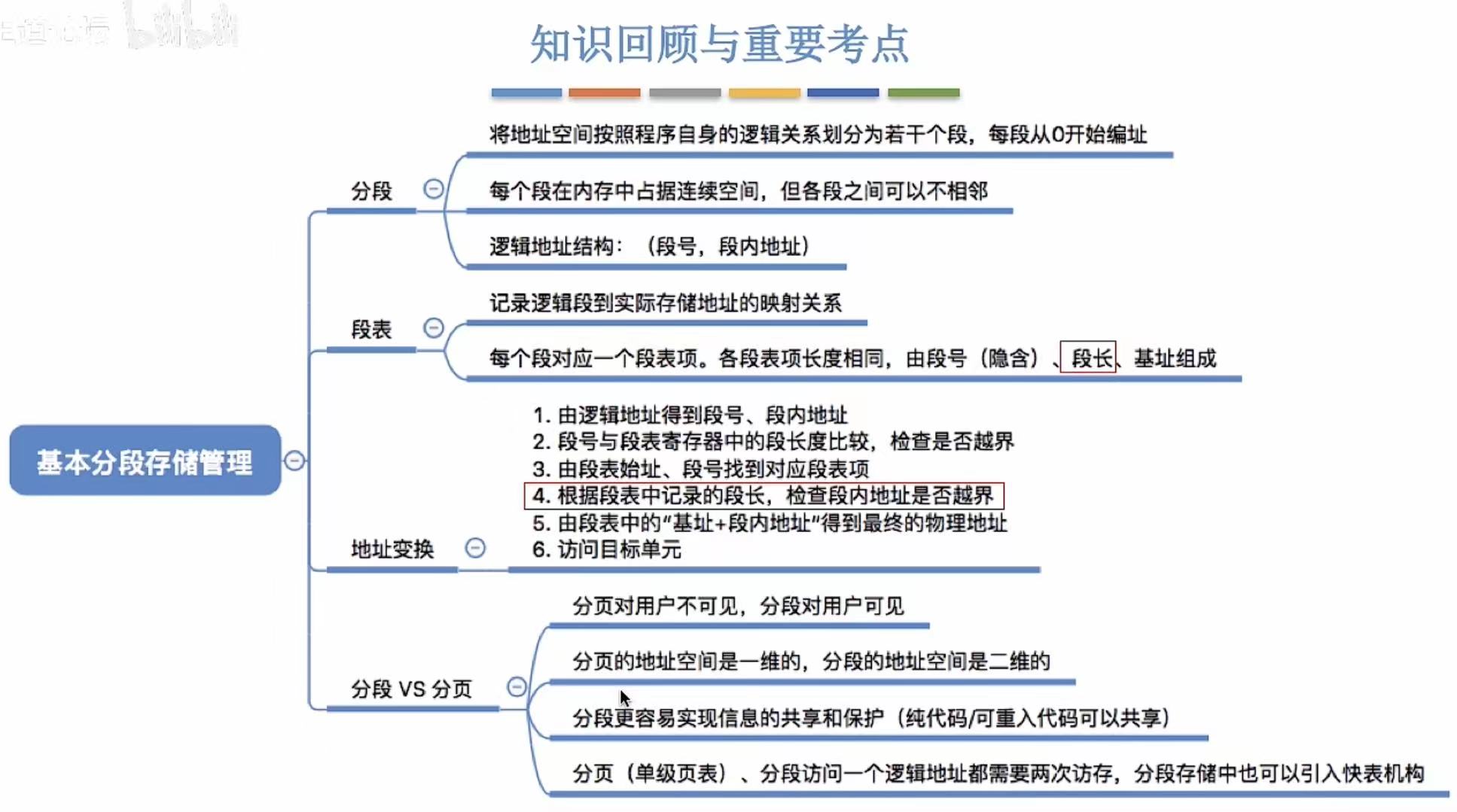
- [1. 分段](#1. 分段)
- 2.段表
- [3. 地址转换](#3. 地址转换)
- [4. 分段、分页管理的对比](#4. 分段、分页管理的对比)
- [5. 小结](#5. 小结)
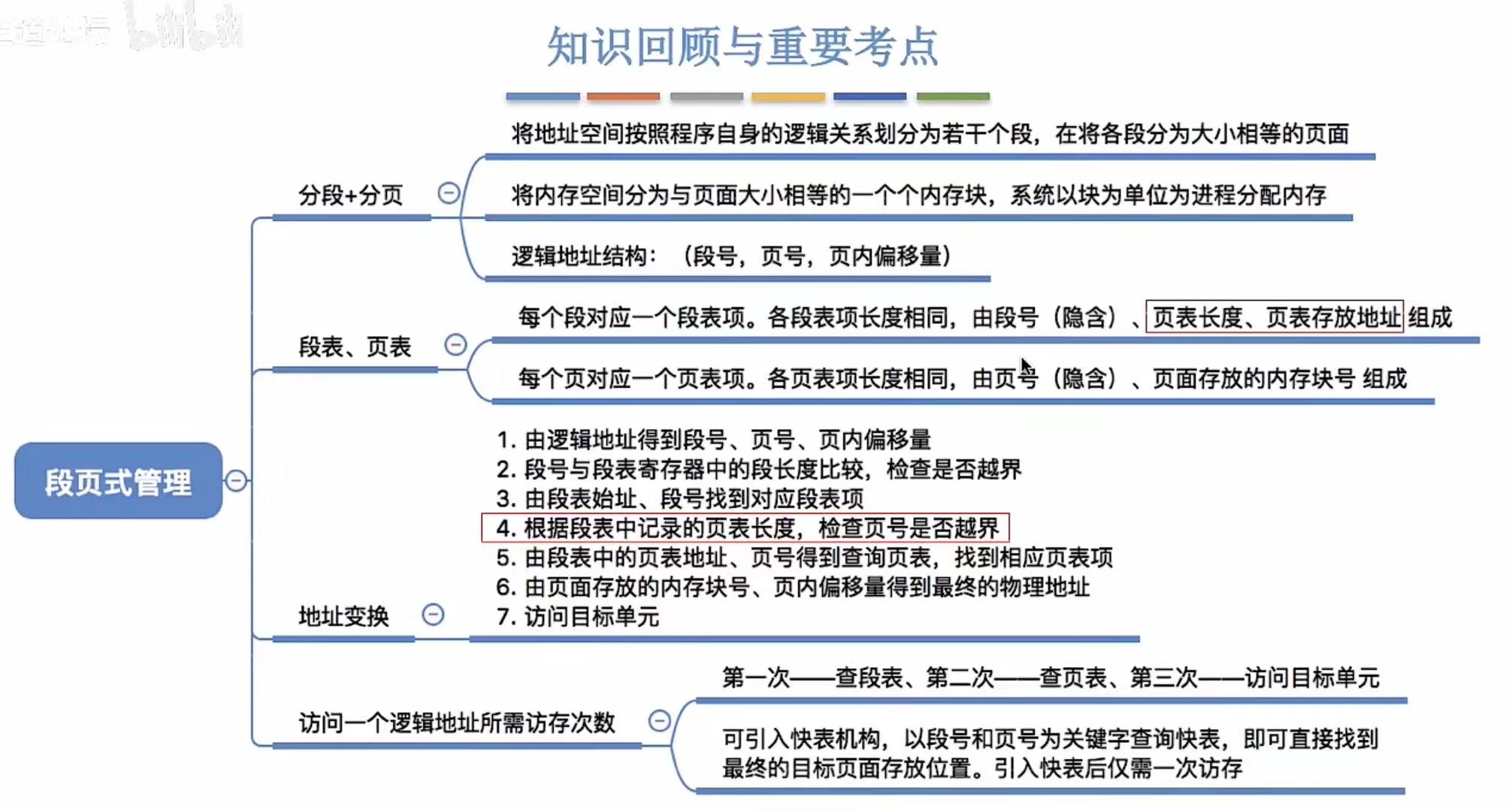
- 段页式管理方式
-
- [1. 优缺点分析](#1. 优缺点分析)
- [2. 段表、页表](#2. 段表、页表)
- [3. 地址转换](#3. 地址转换)
- [4. 小结](#4. 小结)
基本分页存储管理
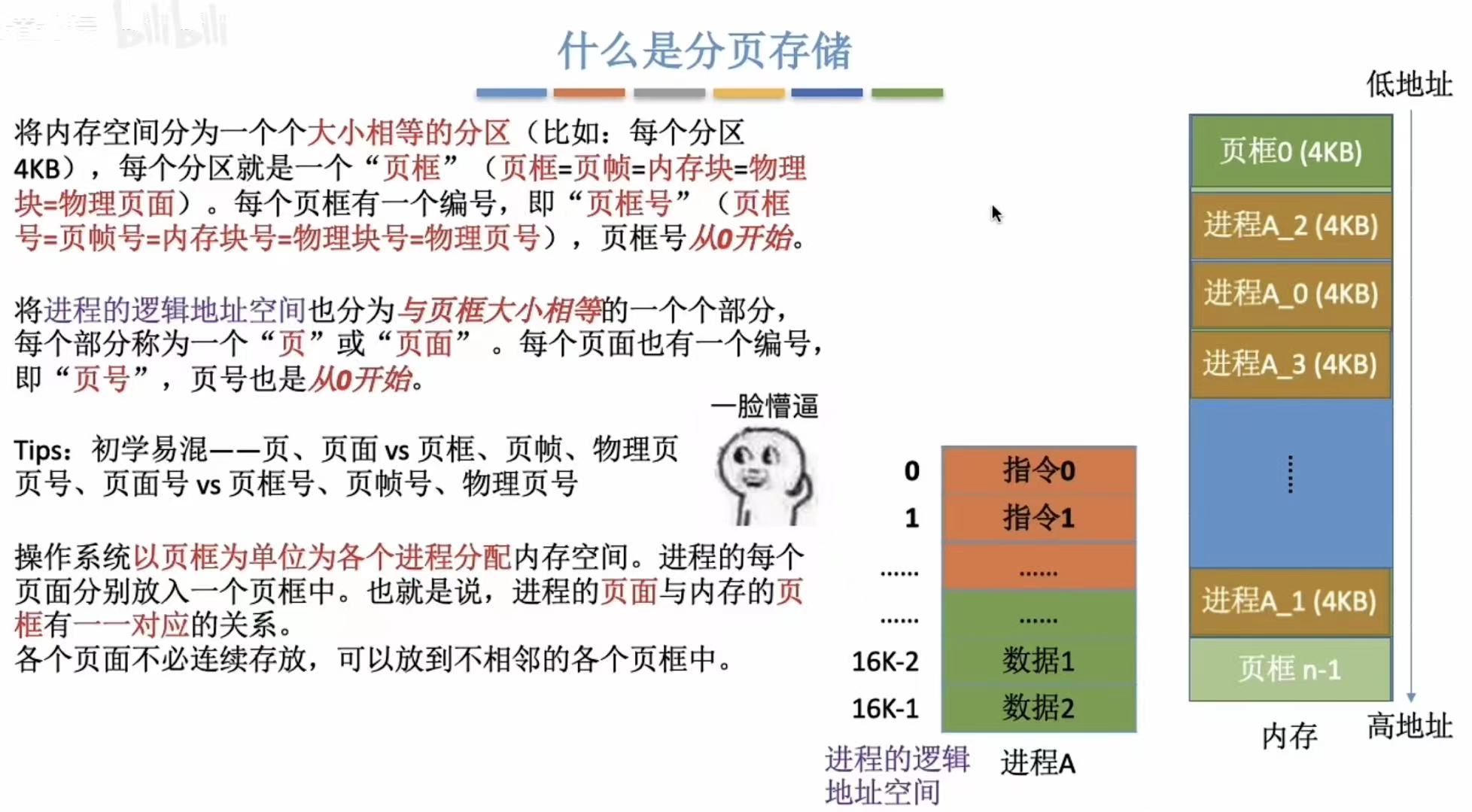
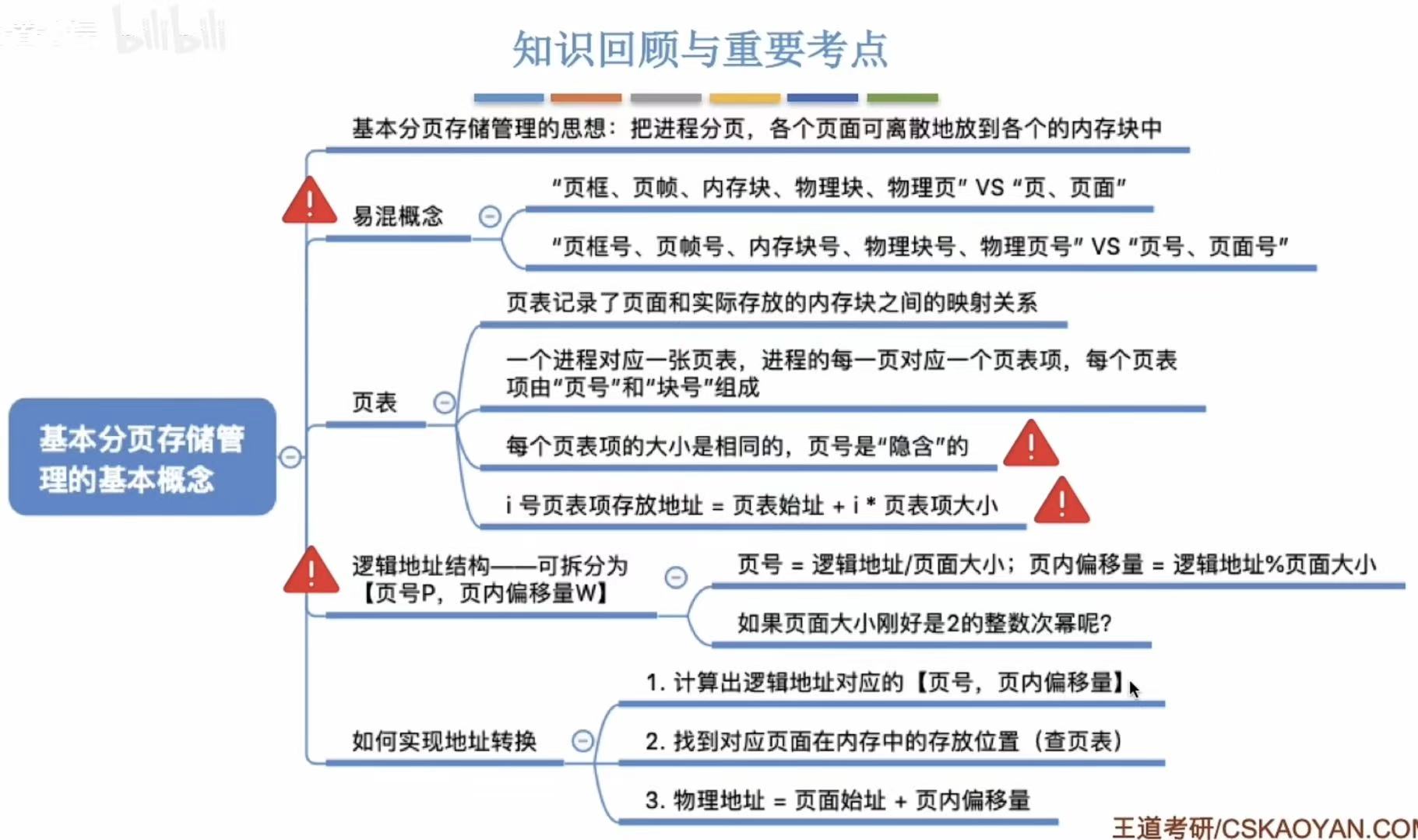
1. 什么是分页存储
- 内存 --分区--> 页框=页帧=内存块=物理块=物理页面
- 进程 --分区--> 页&页面
- 对应关系:一个页面对应一个页框(把分好的进程块放入分好的内存块内)
- 类似于,把一整块完整的牛肉(进程)平均切成不同的小块(页面),分别放到很多个相同的保鲜盒(页框)里,所有的保鲜盒都放在冰箱(内存)内。
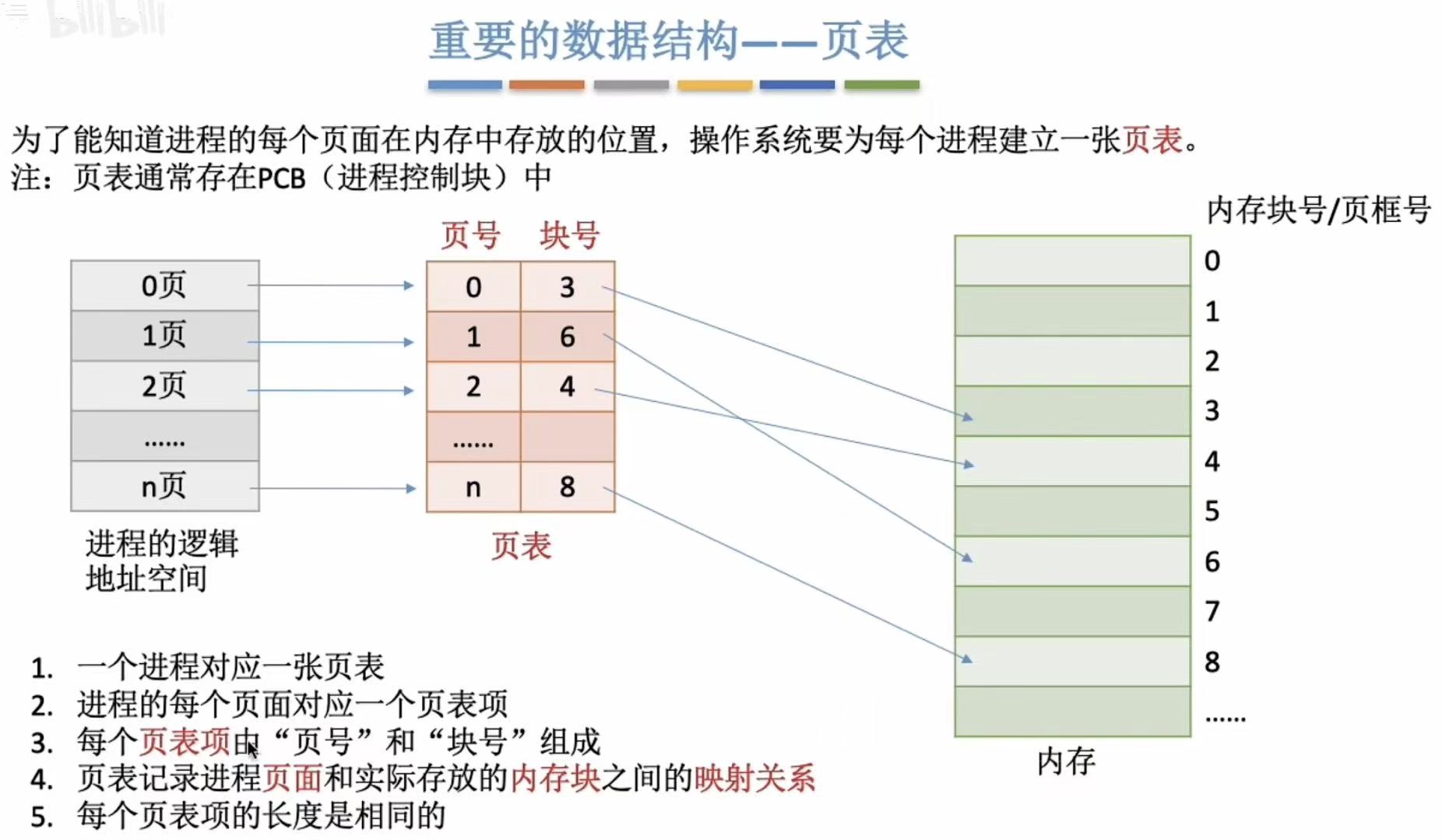
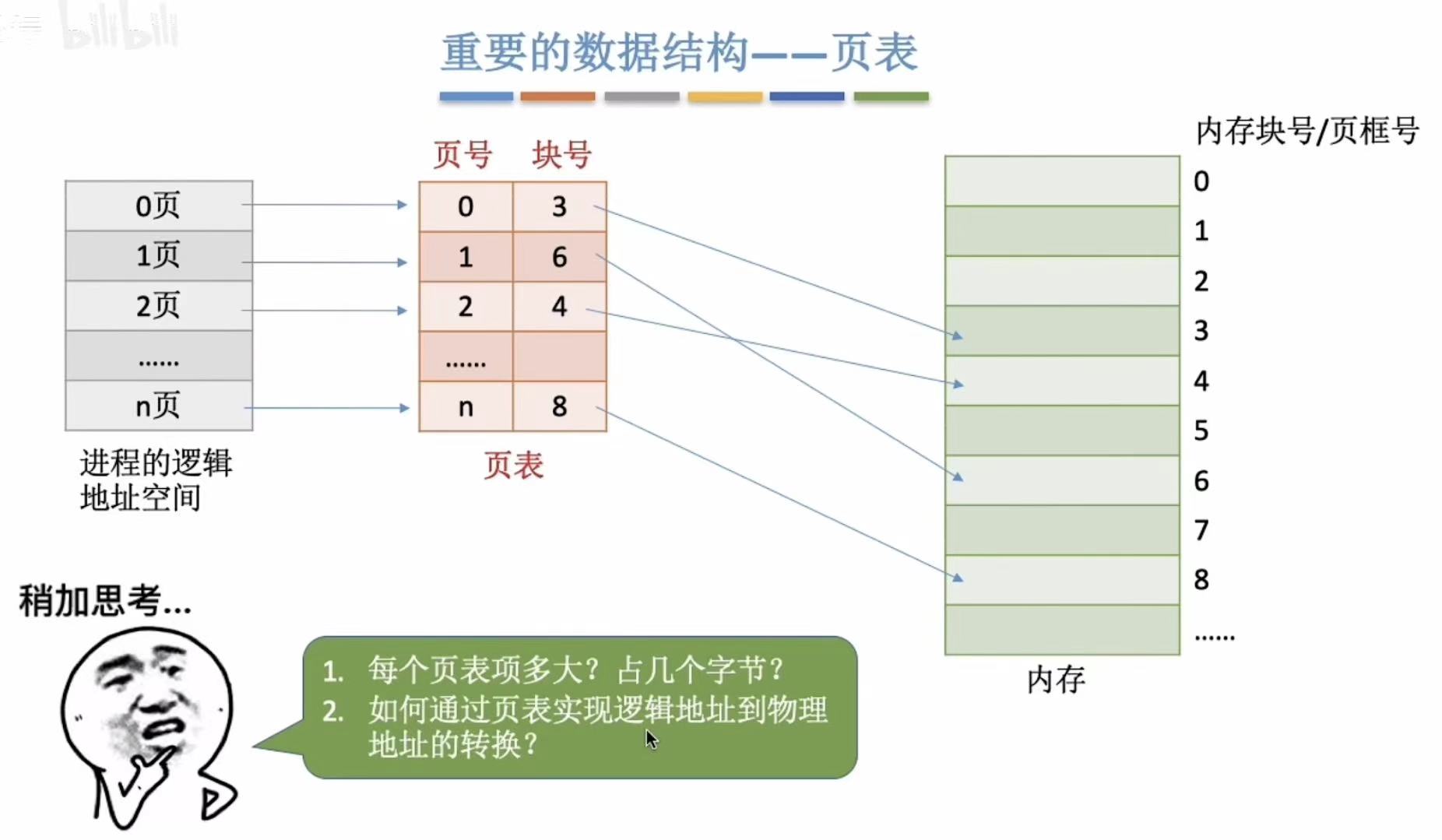
2. 页表
- 进程:页表=1:1
- 页面:页表项=1:1
- 页表项=页号+块号
- 映射关系:就是找出谁在哪儿
既然有了页表,自然而然我们就需要想到这个页表的属性 ,比如每个页表项有多大,占几个字节。
既然出现了映射关系,我们还需要考虑到逻辑地址和物理地址之间是如何转换的(主要研究的问题)
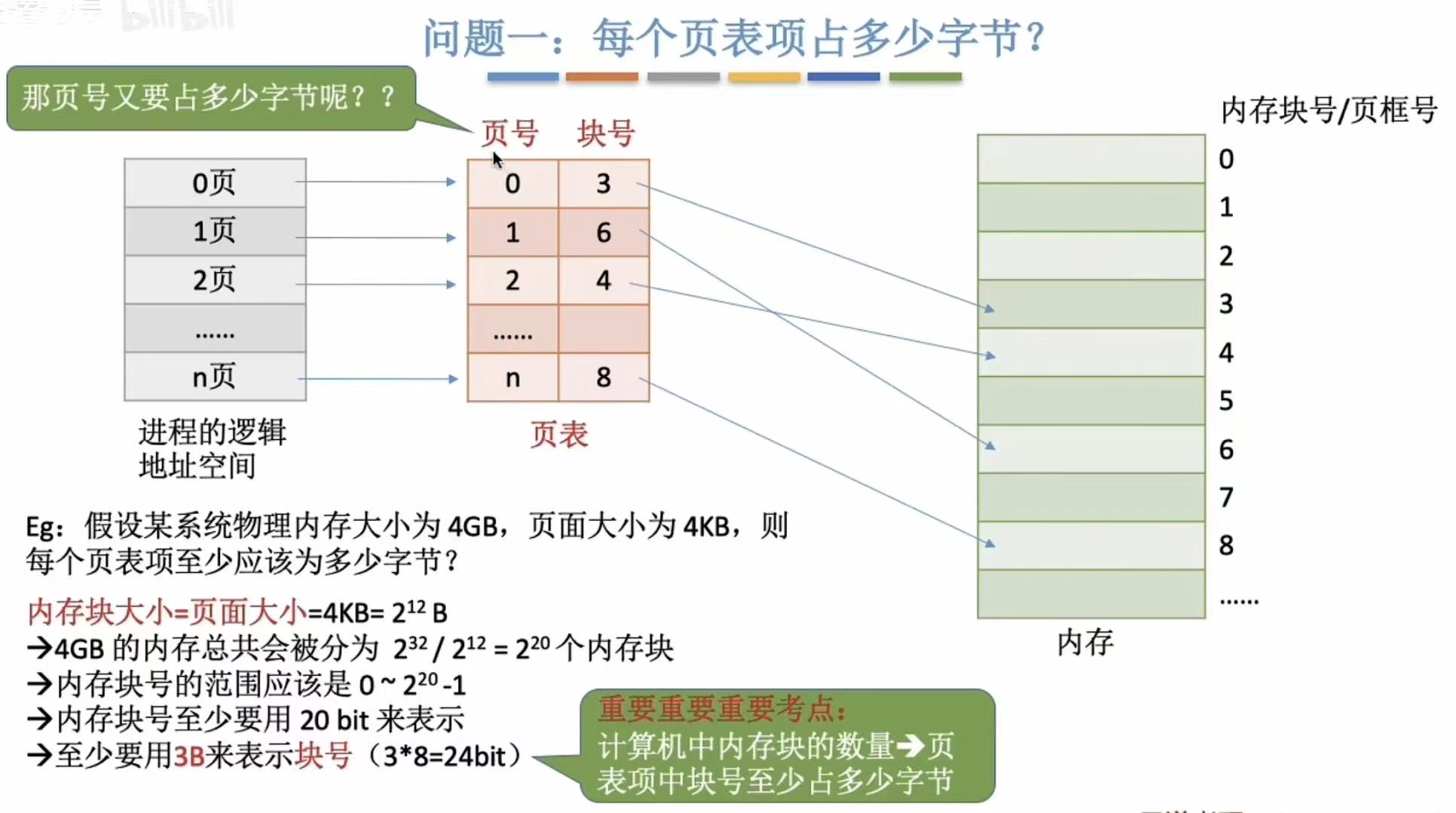
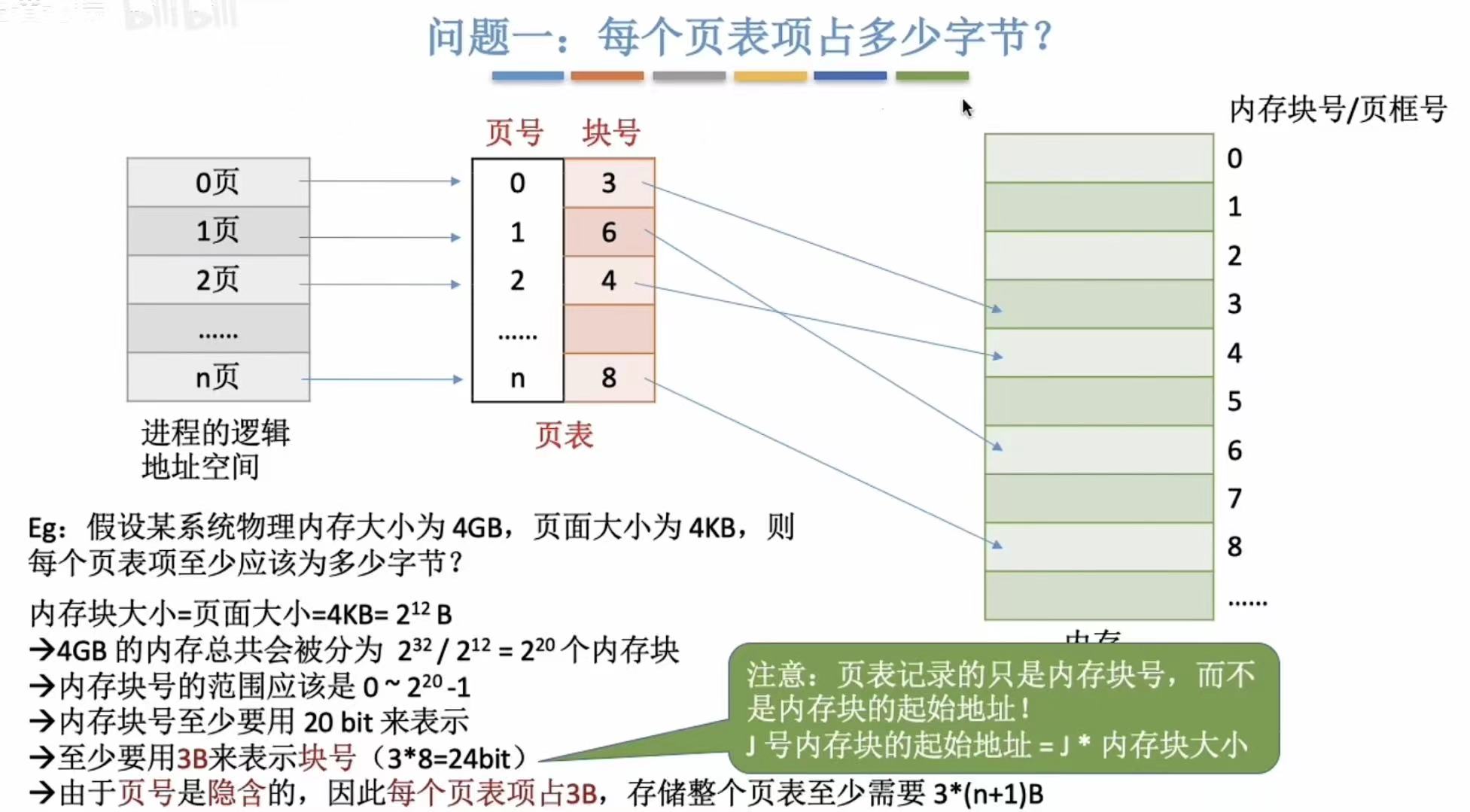
2.1 每个页表项占多少字节?
- 内存块大小:4KB=212B
- 内存大小:4GB=232B
- 块数=内存大小/内存块大小=232-12=220
- 内存块号至少用20bit表示
- 20/8取整=3B
- 所以至少用3B表示块号
这里补一个细节(其实是我总转不过脑子):
为什么因为内存块总数量是 220 个,所以需要 20bit 的二进制数才能唯一标识每个块号?
这其实是二进制数的 "位数" 与 "可表示不同数值数量" 的对应规律
用简单例子就能理解:二进制中,n 位二进制数能表示的不同数值数量是 2n 个,对应的数值范围是 0 ~2n-1。
举几个简单例子:
1 位二进制数(n=1):能表示 0、1,共 21=2个值;
2 位二进制数(n=2):能表示 00、01、10、11,共 22=4个值;
3 位二进制数(n=3):能表示 000~111,共 23=8个值;
回到问题:内存块总数量是 220 个,对应的块号需要覆盖0 ~2n-1个不同的编号。此时,我们需要找一个 "位数 n",让 n 位二进制数刚好能表示 220个不同值 ------ 显然当 n=20时,220个值正好能覆盖所有块号。
注意:页号不占存储空间。类似于角标,默认是按正常顺序,所以不需要额外注意。
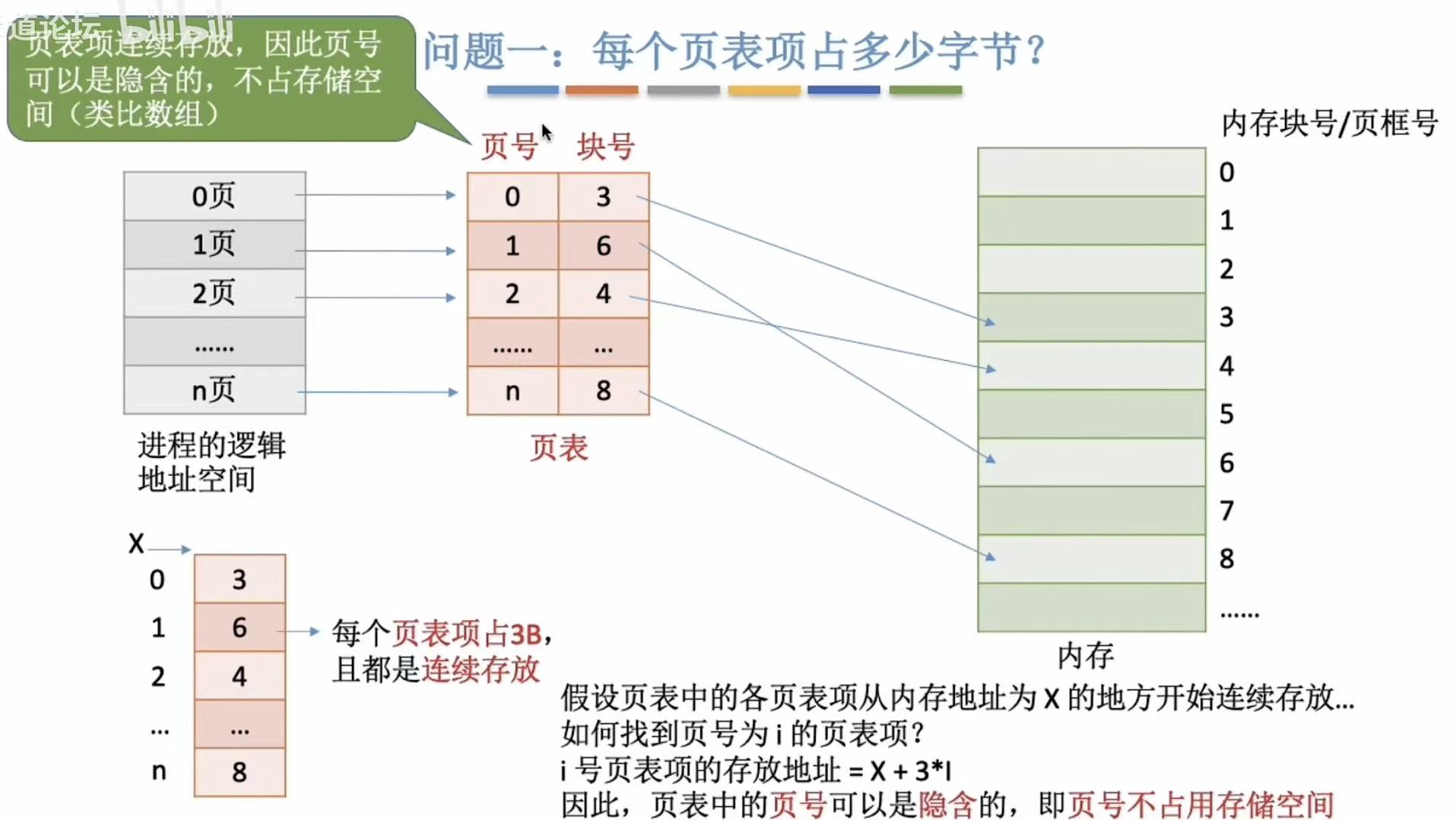
一个页表项需要3B,n+1个页表项(序号n,+1是因为有个序号0的)就需要3(n+1)B
2.2 如何实现地址的转换
重定位寄存器 :指明了进程在内存中的起始位置(重定位-->重新定位)
偏移量 :就是凡事都有误差,这个偏移量就是误差,比如测身高比自己实际身高少一两厘米。
页内偏移量 :逻辑地址在其所在页内的偏移量,用于在分页管理中定位具体的内存地址。
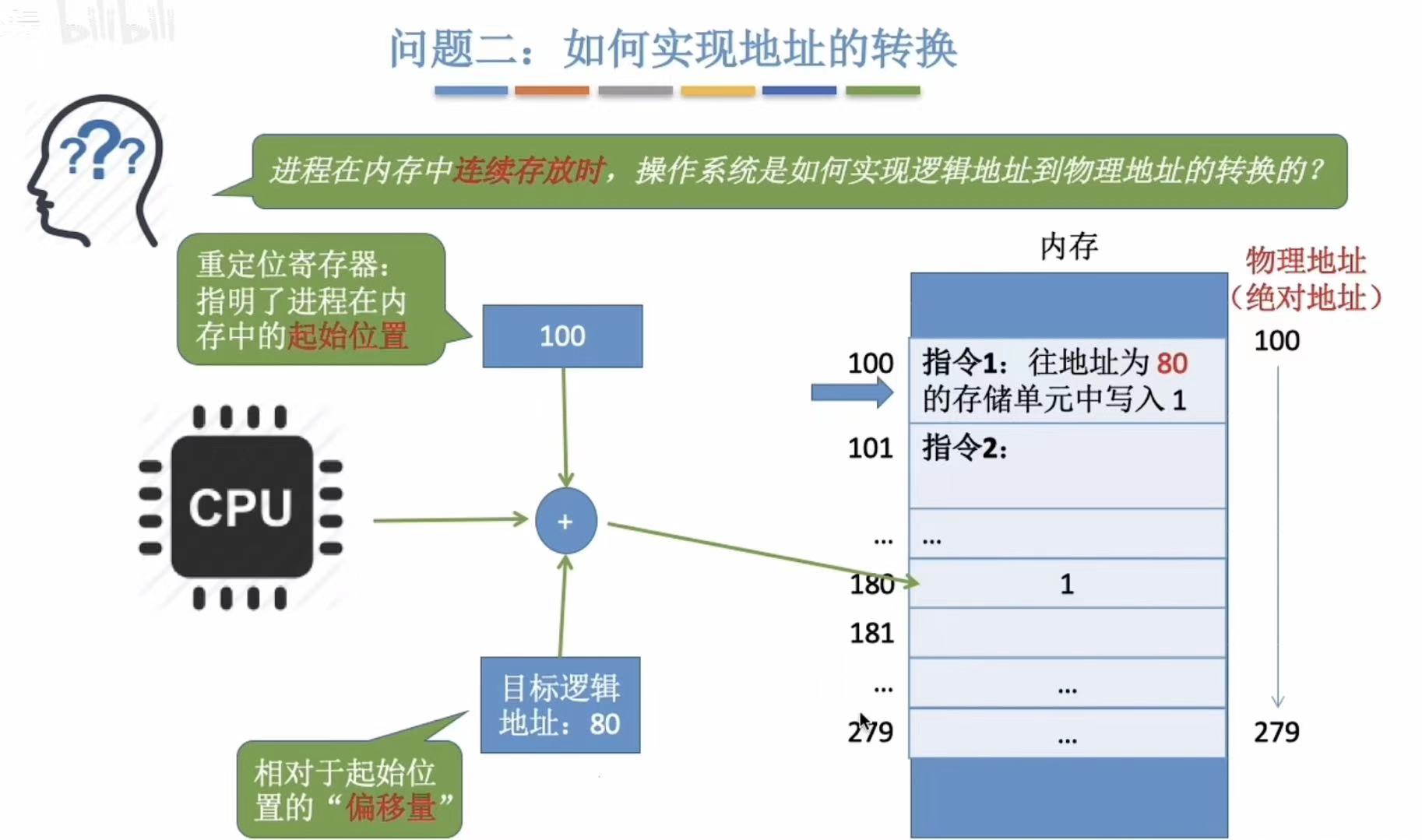
就是,进程分成一块一块的,可以不看位置放在内存中(谁家放牛肉还要指定哪块儿是头哪块儿是尾啊,随便儿放就行),但实际上在进程中它们还都是连续的。(因为刚切开的时候就是这个顺序位置)
- 访问逻辑地址A-->在冰箱里找到这块肉
- 确定A对应的页号P,看看你是想要哪块儿肉(毕竟不同位置的肉口感不一样)
- 找到P在内存中的起始地址-->放冰箱前规定(规定=页表)好哪层放肉,就去哪层找
- 确定A的页面偏移量W-->就是这个肉在在冰箱的前左位置还是后左位置
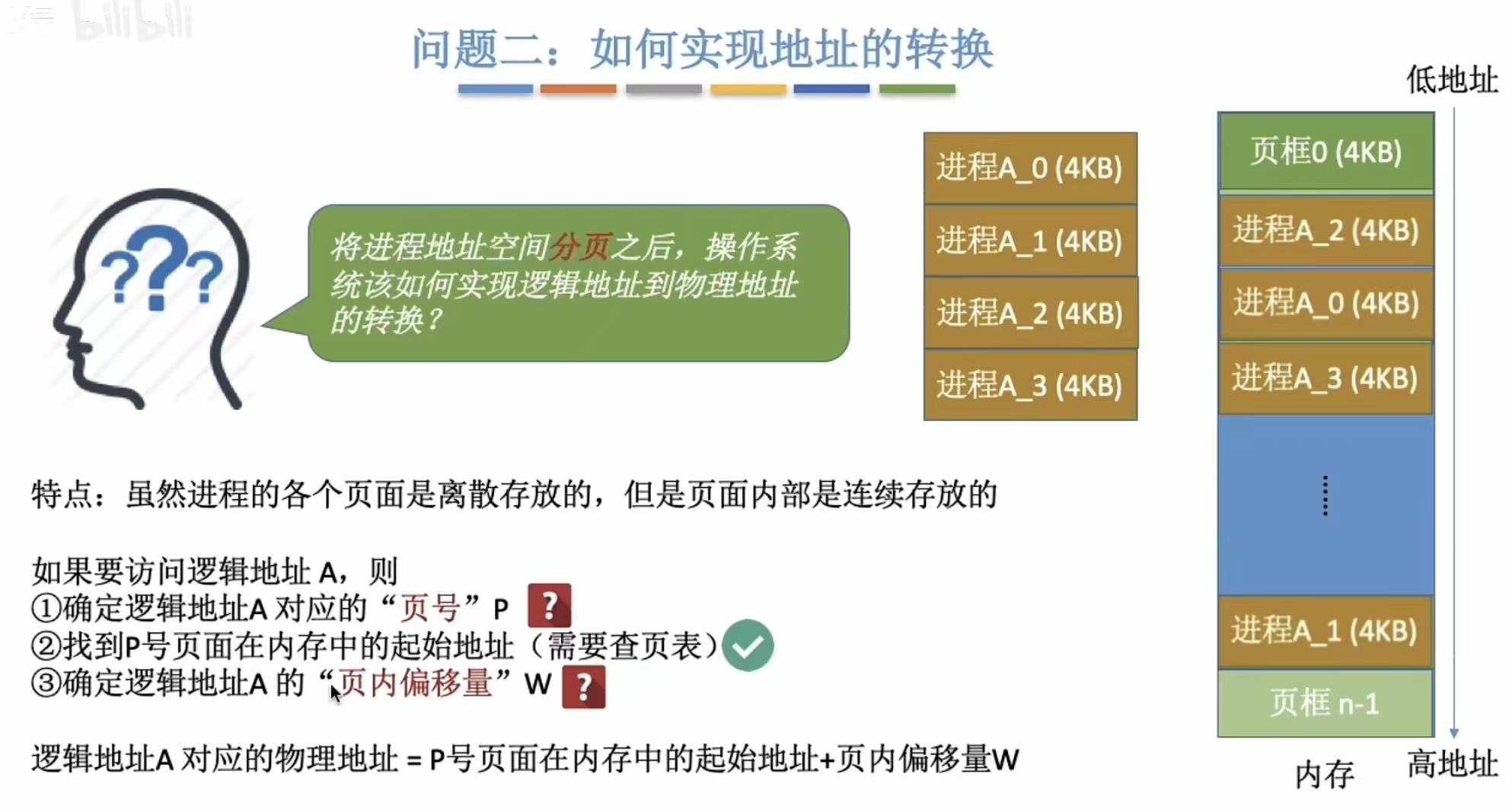
2.3 如何确定对应的页号和偏移量
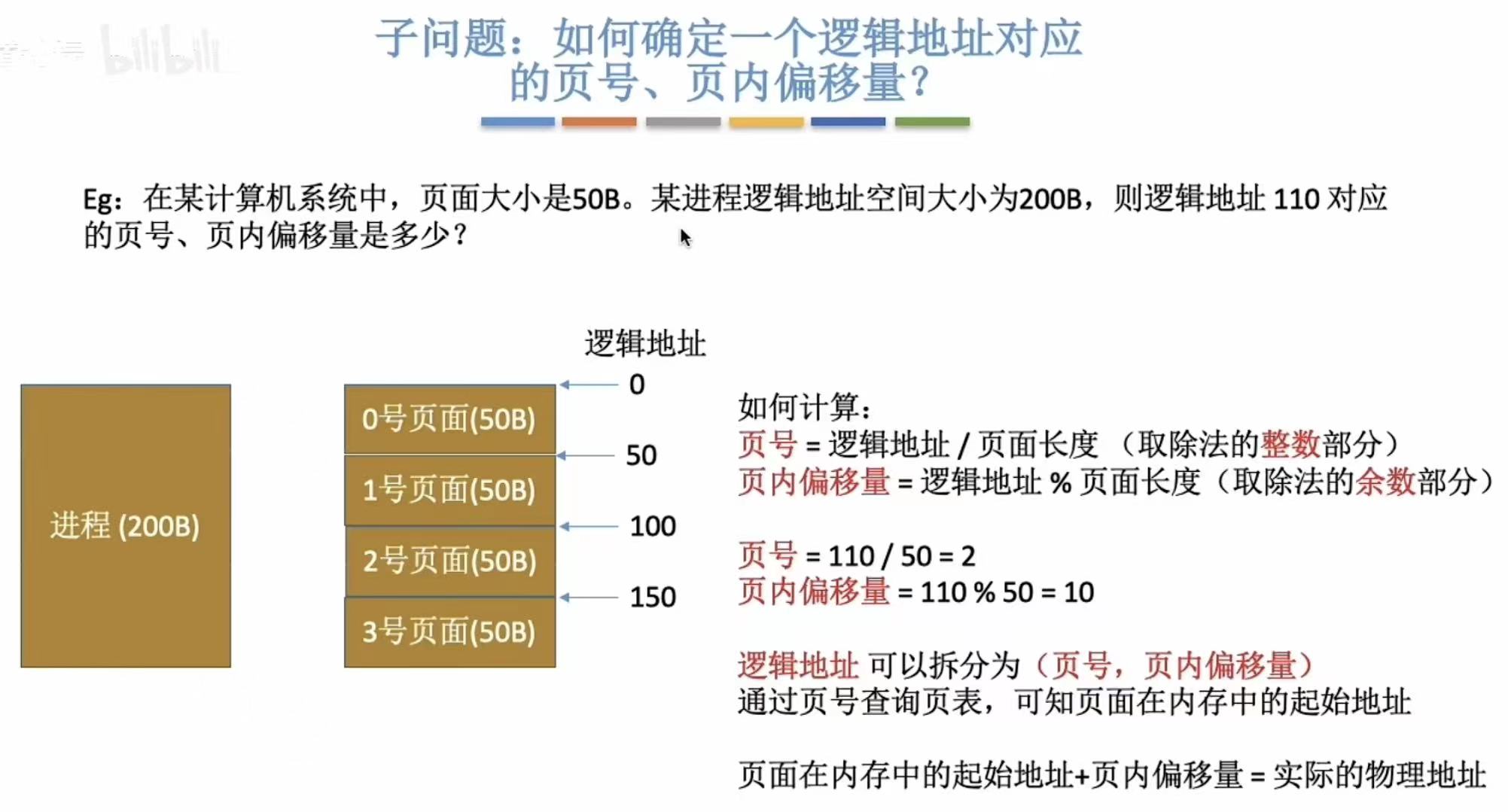
- 页号=逻辑地址/页面长度-->冰箱正好横着放四个保鲜盒,我就放了两个保鲜盒,先比量出我想找的在这四个位置的哪一个上
- 页内偏移量=逻辑地址%页面长度-->因为没正好放着四个,就两个,冰箱也没有分格,所以左右位置窜个一两厘米都正常
- ps:其实这个比喻也不太对应逻辑,不过倒是很好理解
- 页面大小4KB=212B --> 后12位是页面偏移量
- 32个二进制位-->32个0或1-->前20位页号+后12位页面偏移量
- 符合2的多少次幂的可以快速代入,不符合的就按公式算就可以

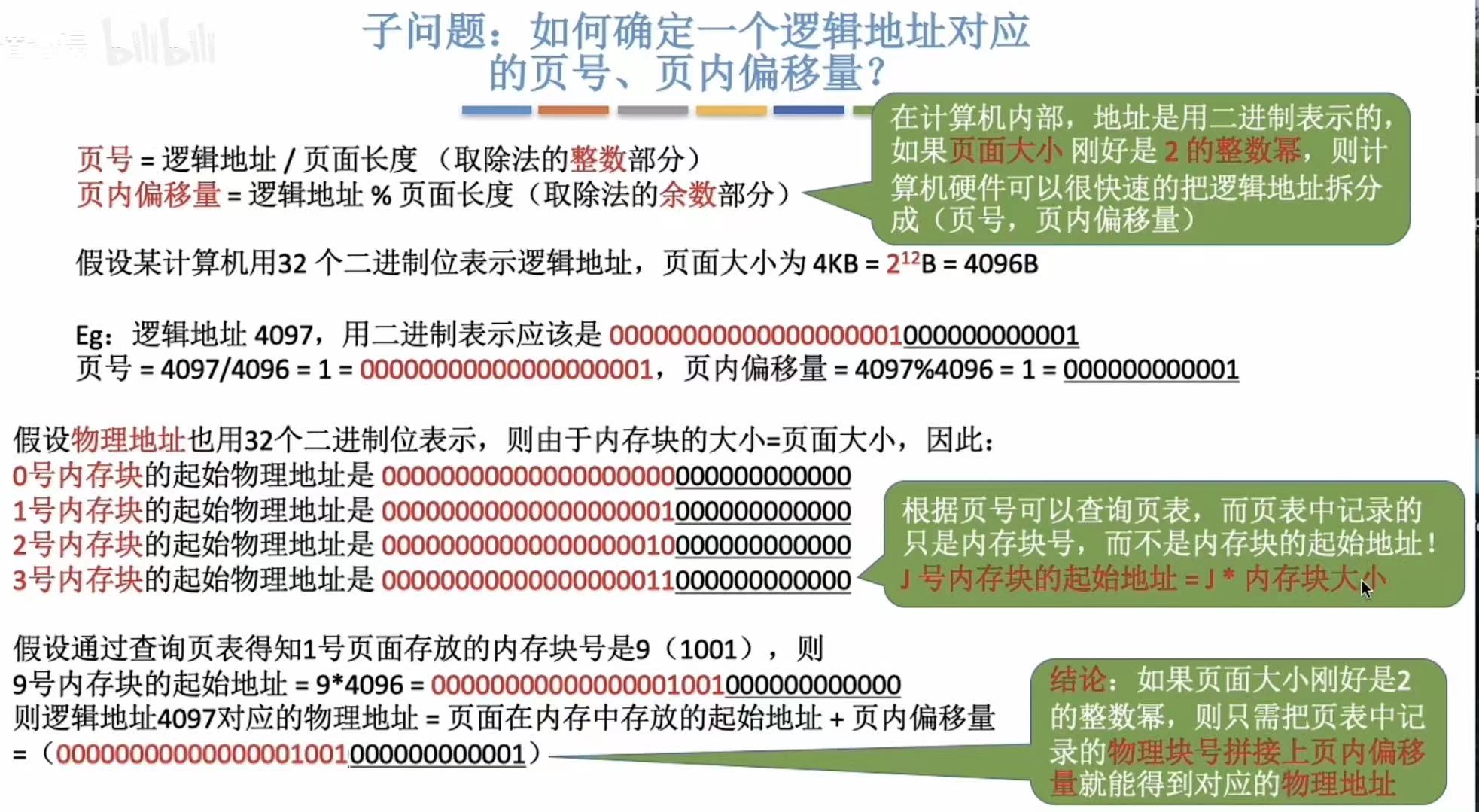
总之,碰到与2有关的数或者计算,都需要额外留一个心眼,毕竟计算机和二进制根本分不开。

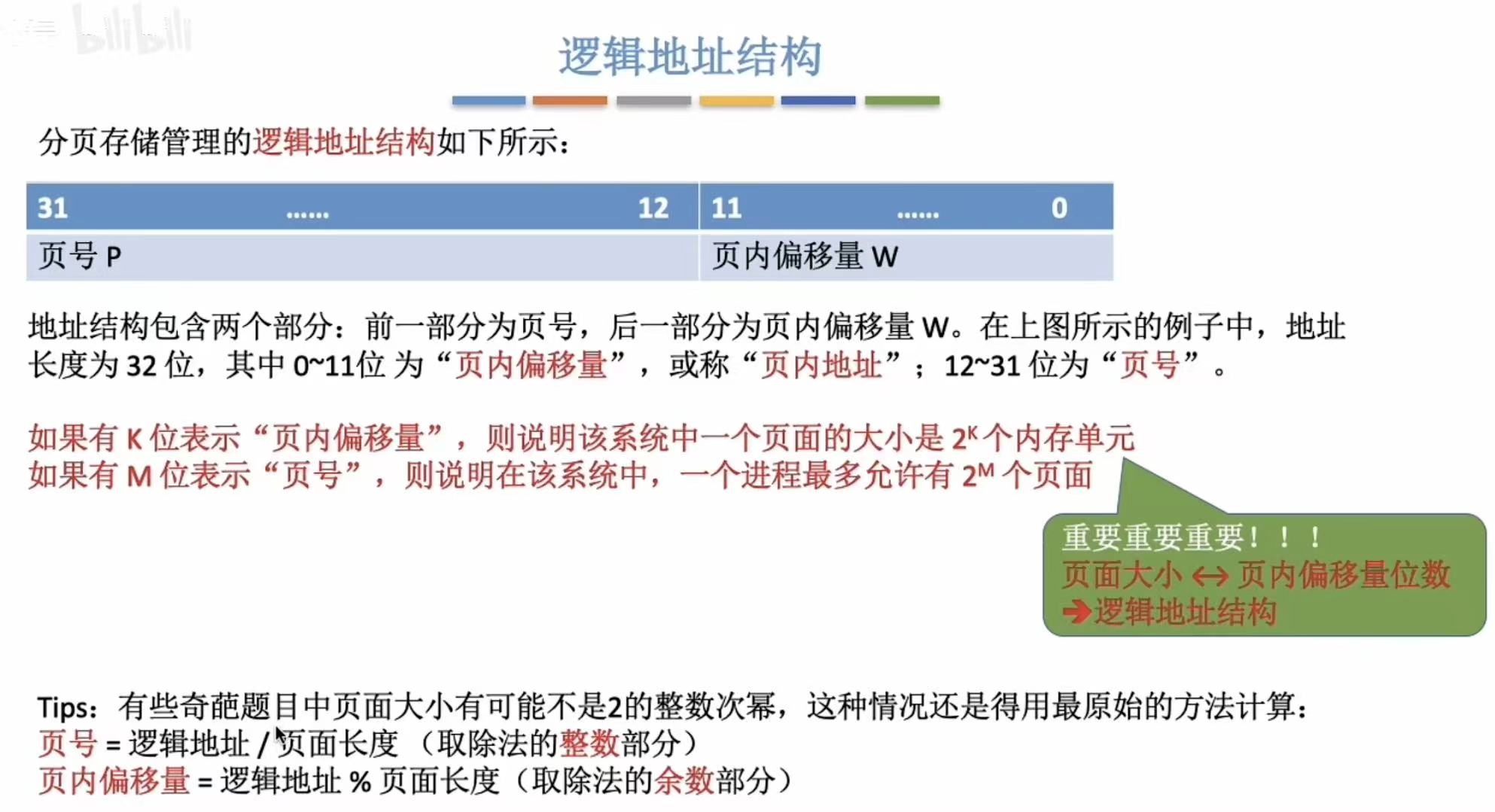
3. 逻辑地址结构
对比:
- 物理地址:页面在内存中的初始地址+页内偏移量
- 逻辑地址:页号+页内偏移量
为什么不一样,是因为物理 地址是在内存 中的,逻辑 地址是在进程 中的。
4. 小结
基本地址变换机构
说是机构,可以当成一个流程图看,就是怎么使用页表寄存器将逻辑地址转换为物理地址的。
混淆点:
- 基本分页存储管理:规则
- 基本地址变换机构:使用规则的工具

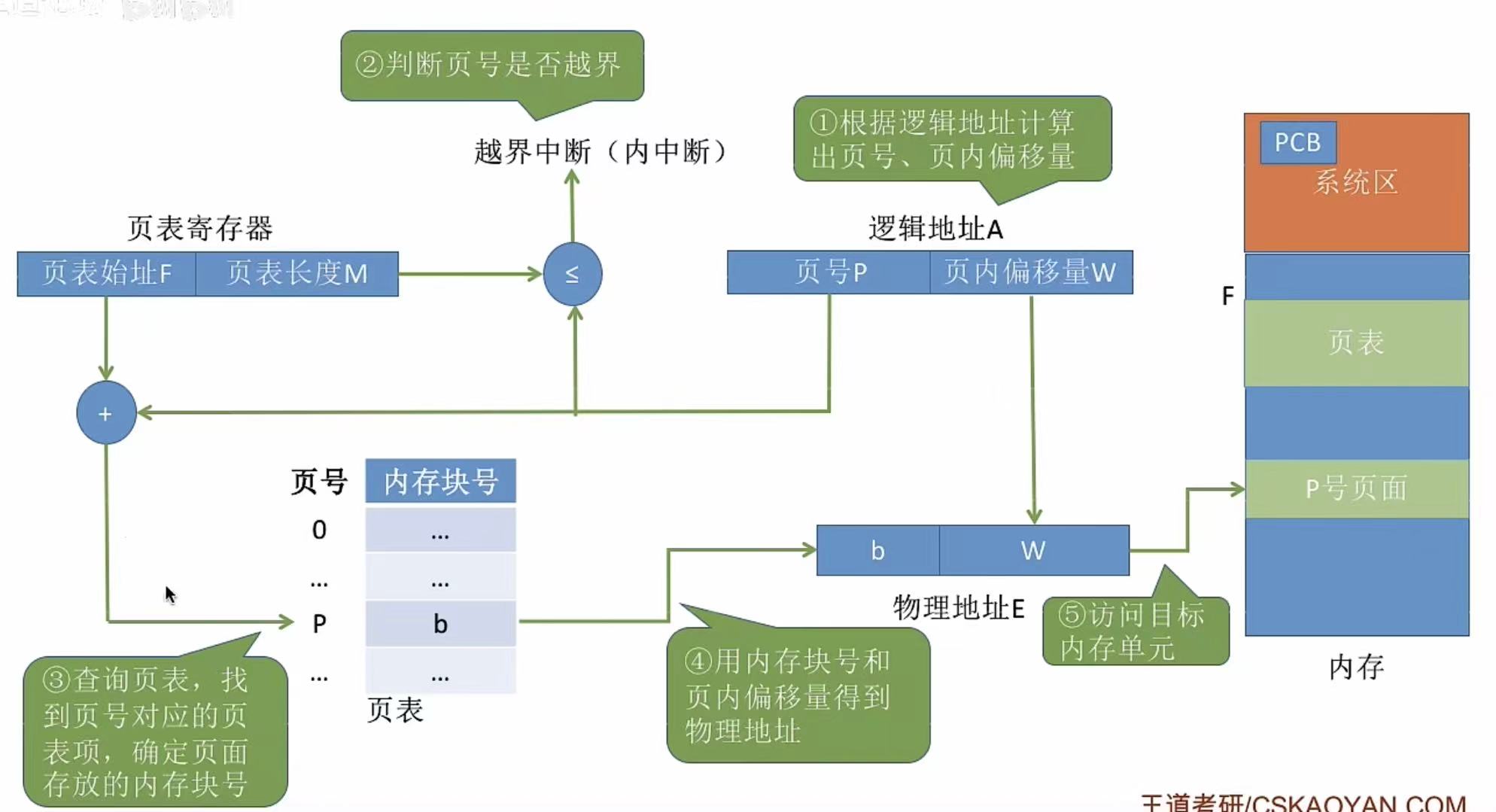
1. 转换过程--图
进程未执行-->需要的都在PCB-->进程启用-->将需要的东西都放进页表寄存器中

逻辑地址 get-->得到页号 P、页内偏移量 W-->页号P 和 页表长度M 比大小-->页号P 和 页表起始地址F 进行计算 ,查页表 -->得到这个页号对应页表中的哪个页表项 --> 得到页表项内容 b,也就是内存块号 --> 物理地址 E = 页面在内存中的初始地址b + 页内偏移量W
**唯一依次计算:**页表项号=页表起始地址F+页号P*页表项长度
ps:粗体字为当时步骤需要求出的信息
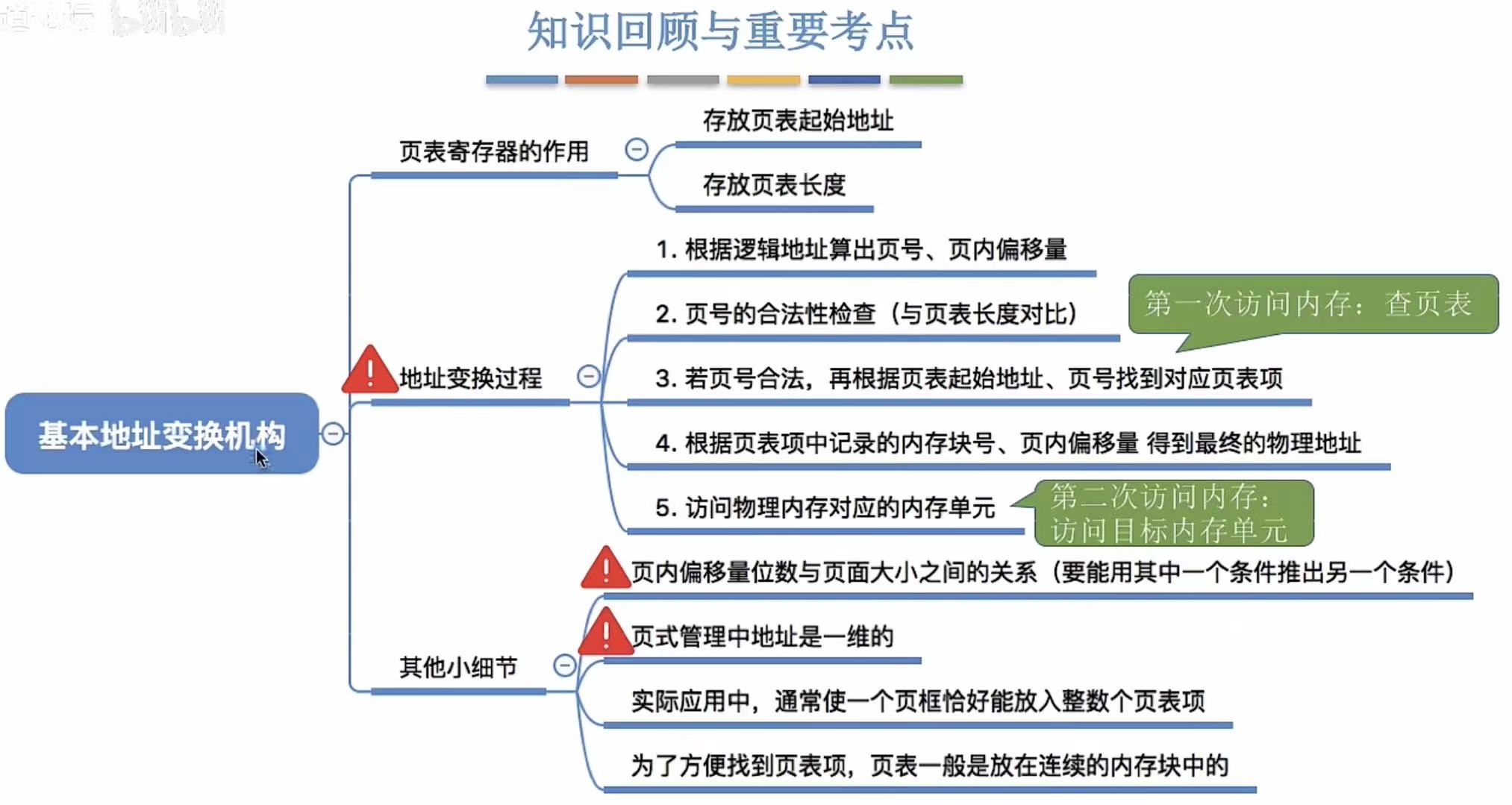
2. 转换过程-文字
建议和图片过程来回对照看,步骤3、4理解起来比较难。
对比:
-
物理地址:页面在内存中的初始地址+页内偏移量
-
逻辑地址:页号+页内偏移量
-
共用的数据是页内偏移量。
-
物理地址:内存中的初始地址=内存块号=查表=需要页表项号 -->页表项号=页表起始地址 F+页号 P×页表项长度
页表项长度=块号大小(页号不占空间)-->可由内存块大小和内存大小计算(见2.1或下面第三点)
-
逻辑地址:页号


3. 页表项大小
为了方便查询,原本3B(如何算出来的请看2.1)的就需要扩1B,变为4B,让每个页面刚好装得下整数个页表项。

4. 小结
具有快表的地址变换机构
1. 什么是快表
Cache相关内容具体可见:Cache

TLB,就是专门用来存放最近访问的页表项副本 的Cache。
因为Cache比内存访问速度更快,所以叫做快表,内存里的就只能叫做慢表了。

2. 转换过程-图
大体流程和基本地址变换机构相同。
不同点:
- 因为是Cache,所以第一次访问的页号会存入Cache中
- 再次访问时,Cache中有的就可以快速访问,没有的就需要从内存中找
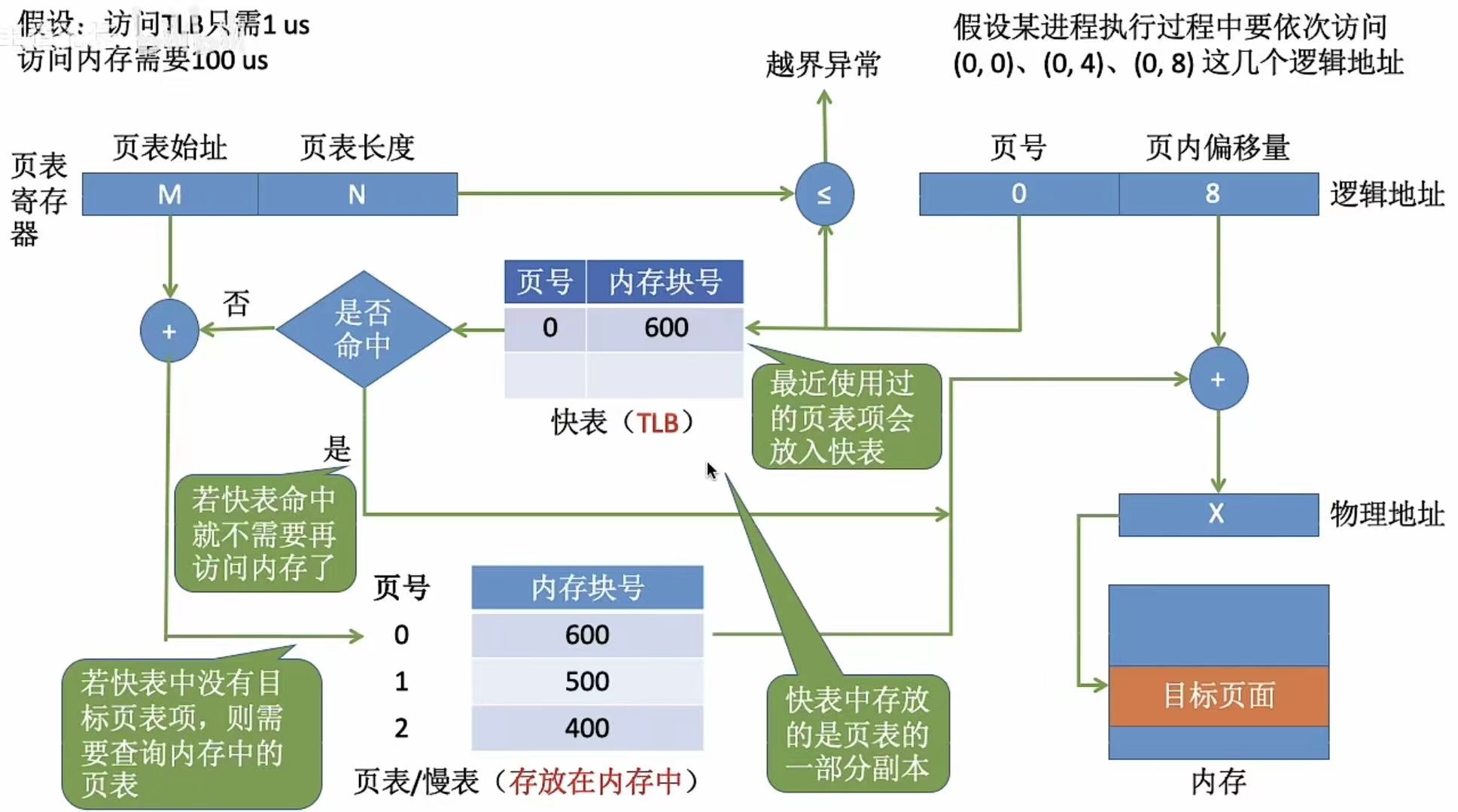
3. 转换过程-文字
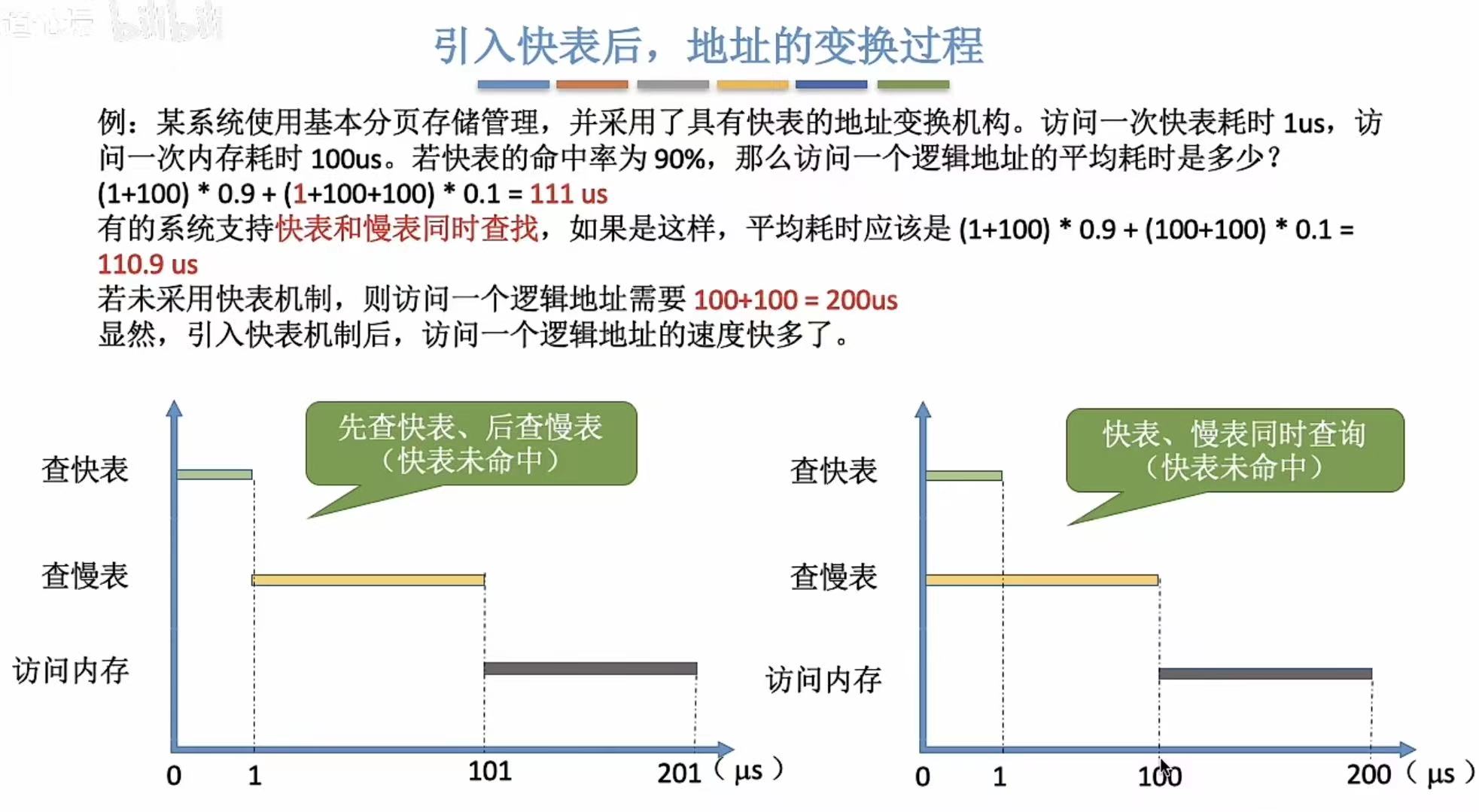
平均耗时和普通Cache一样(算是Cache的基本特性吧):
- 一种是先查Cache,没有再查主存
- 一种是Cache和主存同时查
- 显而易见第二种效率更高

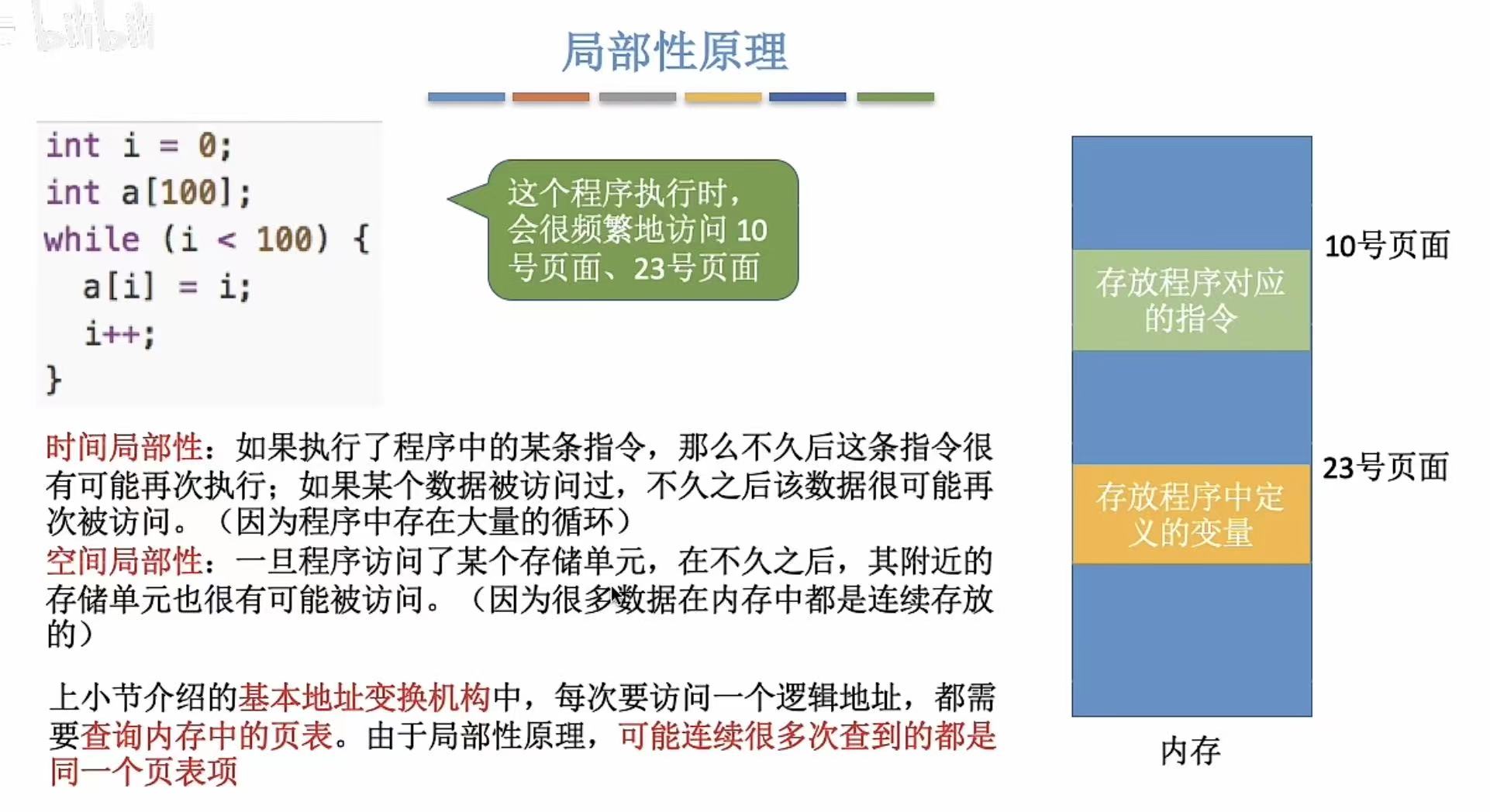
4. 局部性原理
就是啥都不一定。
5. 小结

两级页表
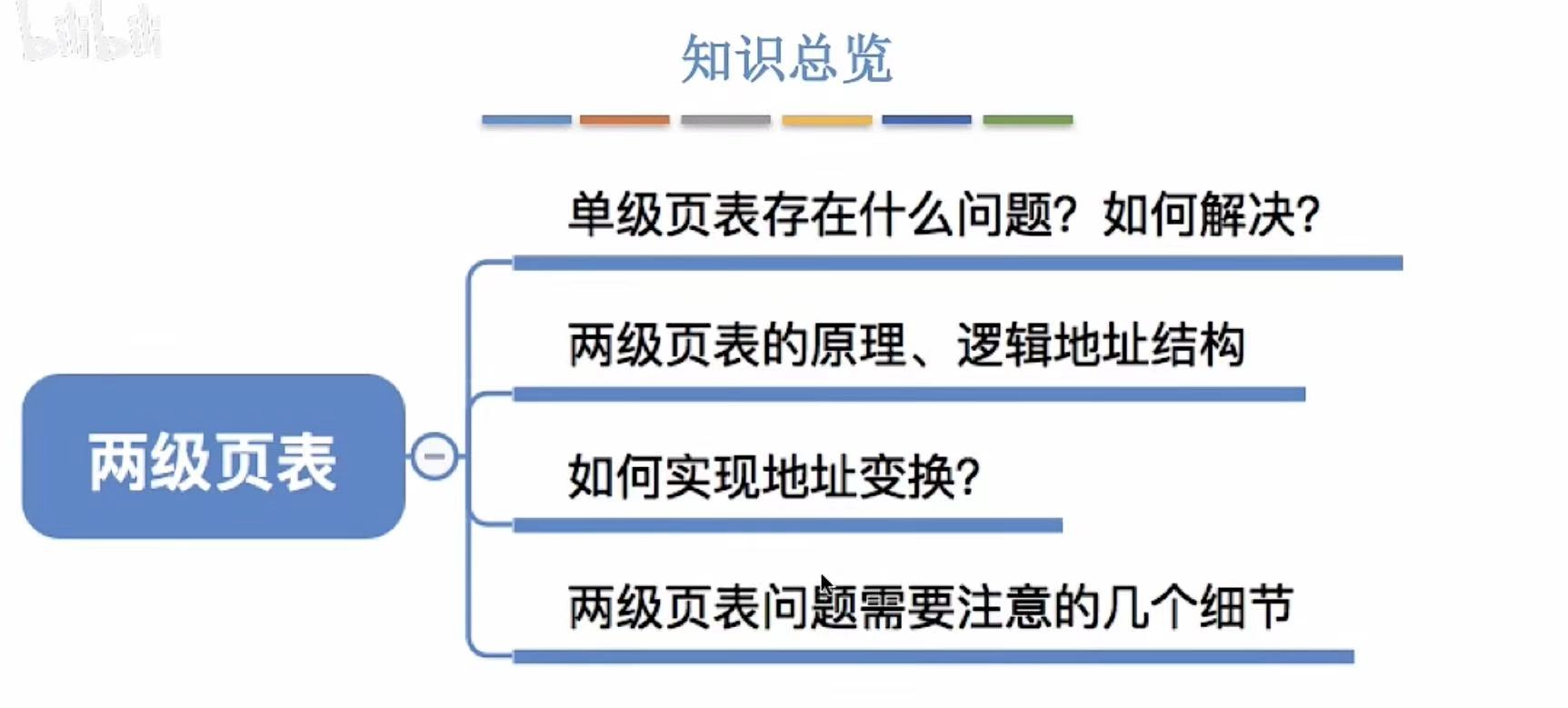
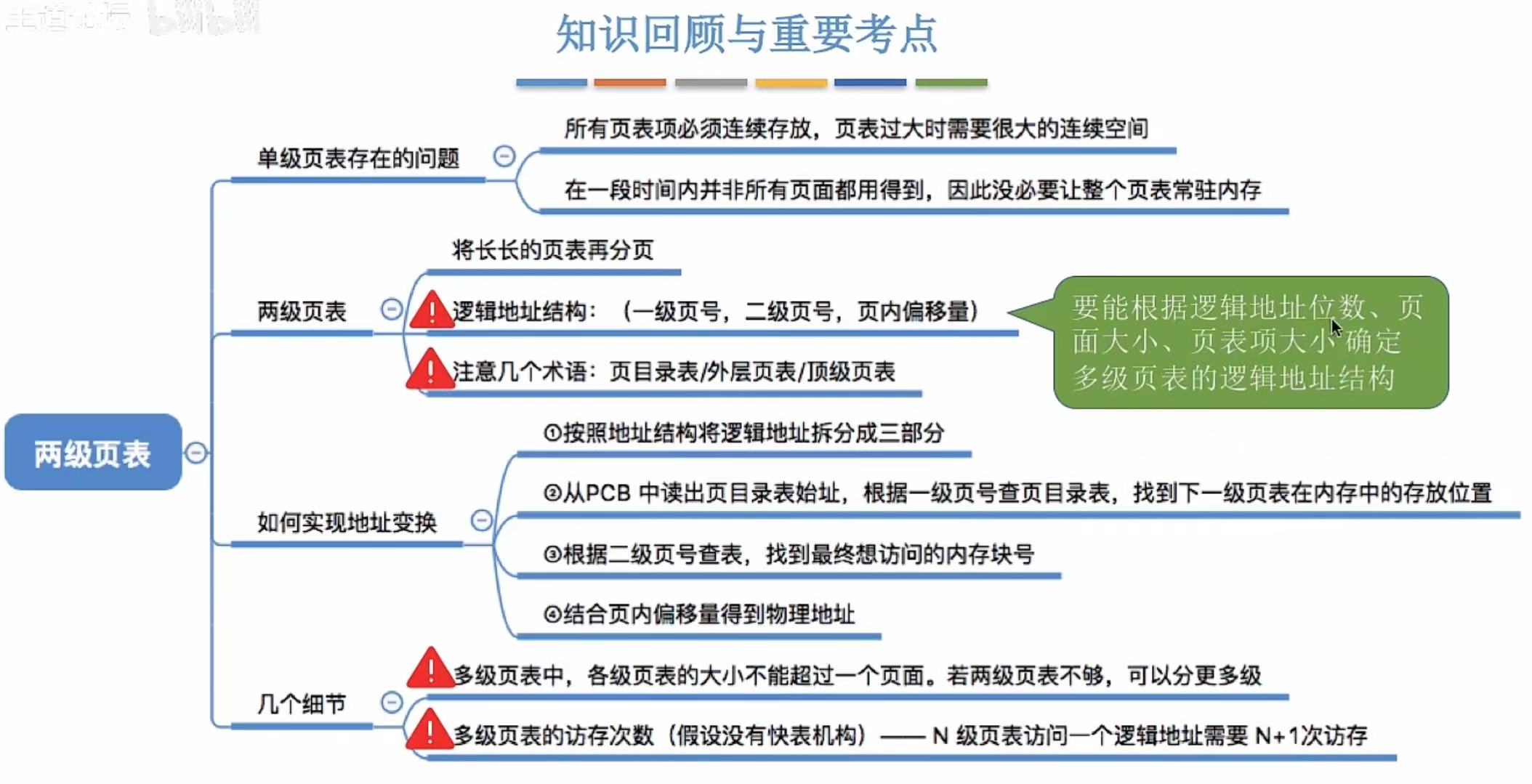
1. 单级表存在的问题
简单说,就是一维的内存占得太多,就像人类古时候写字,一个横代表一,两个横代表二,一百总不能画一百个横吧,所以就有了竖的概念,多引入了一个维度,可以更好地解决空间的问题。
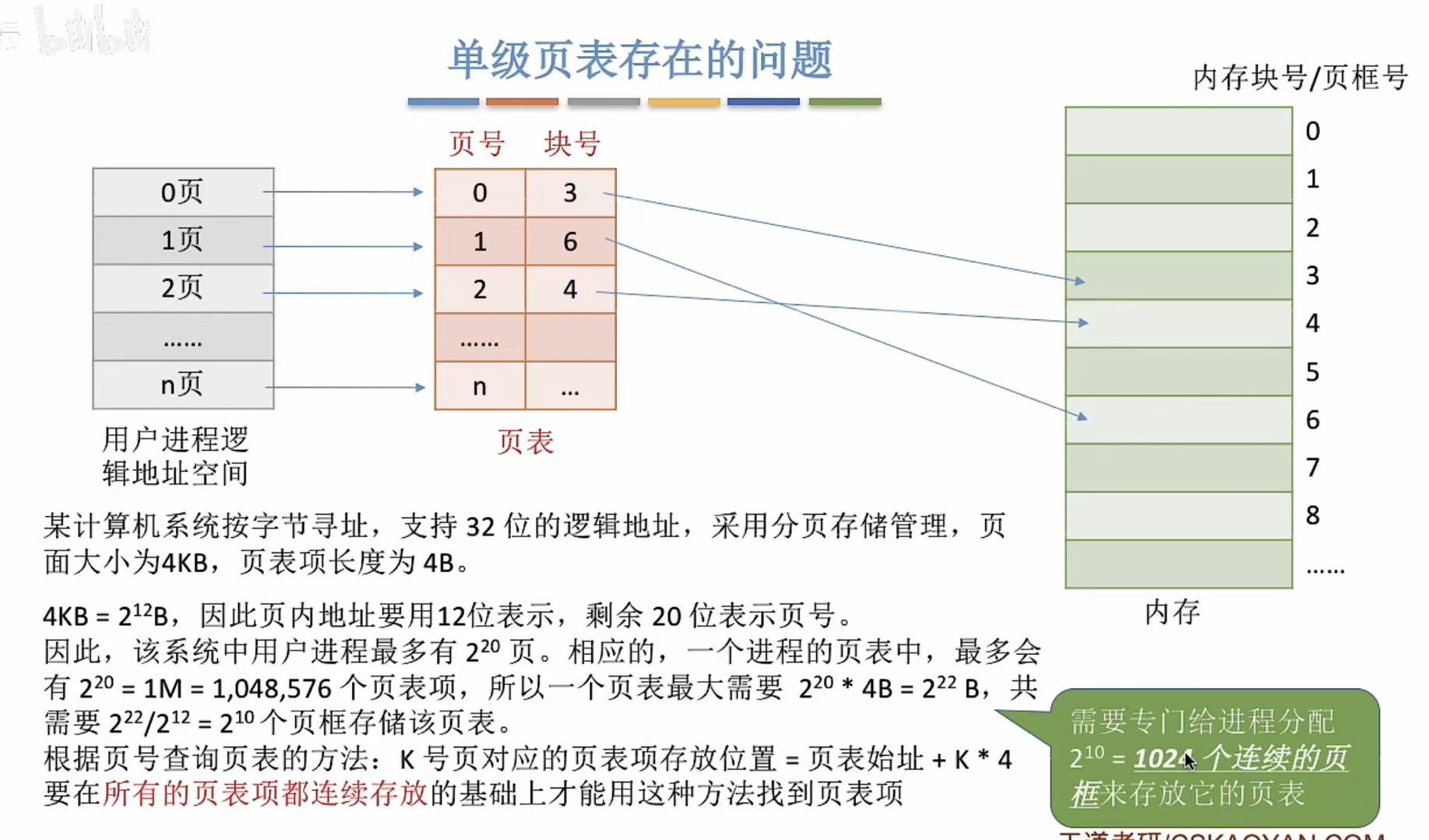
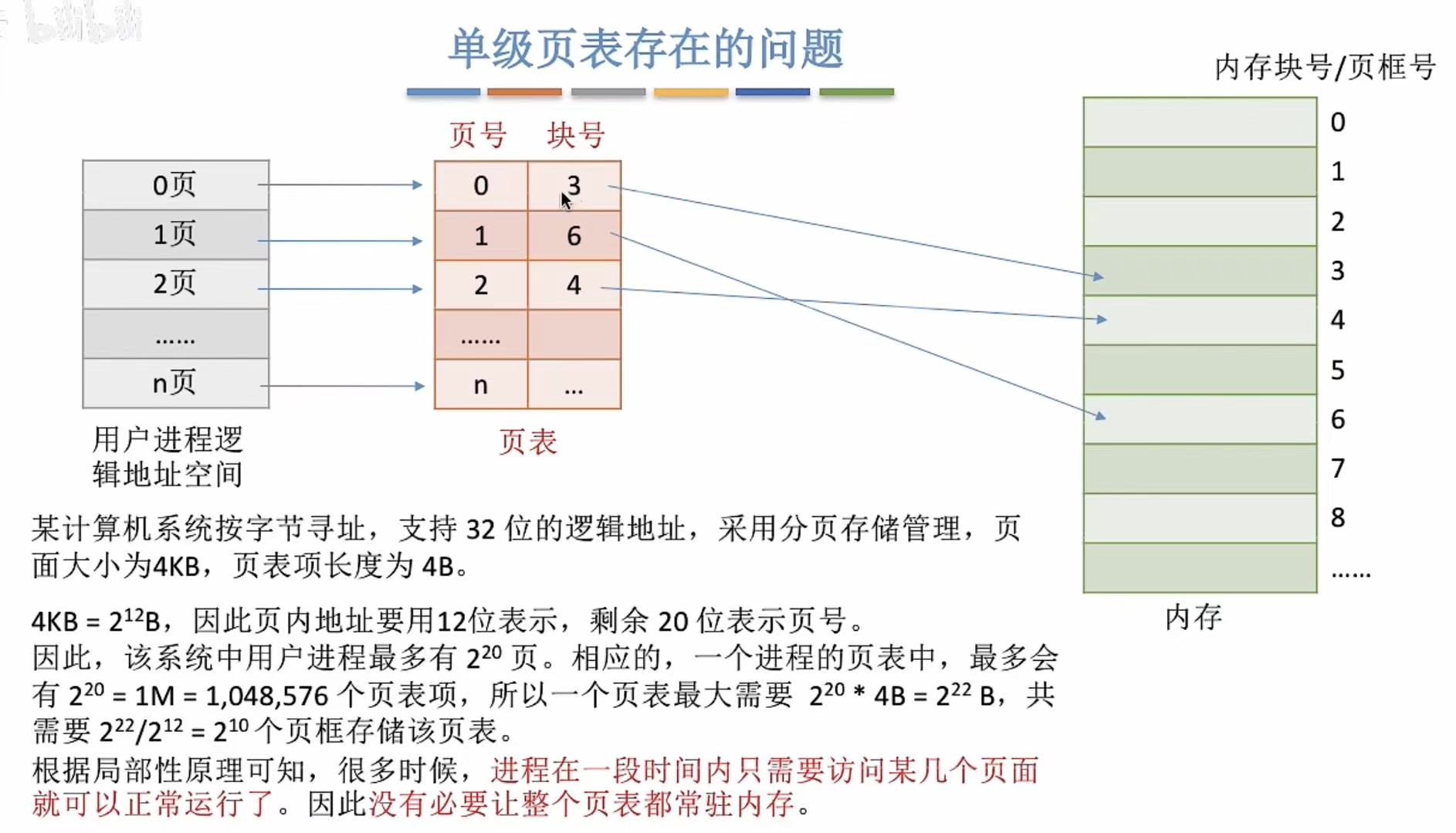
2. 如何解决连续存放
像我上面说的,多引入一个维度的概念,比如单级不够用,那就引入二级,二级不够用就引入三级,叠罗汉和套娃,总有一种方法适合。
这里就是给页表也创造了一个页表,多层查询。
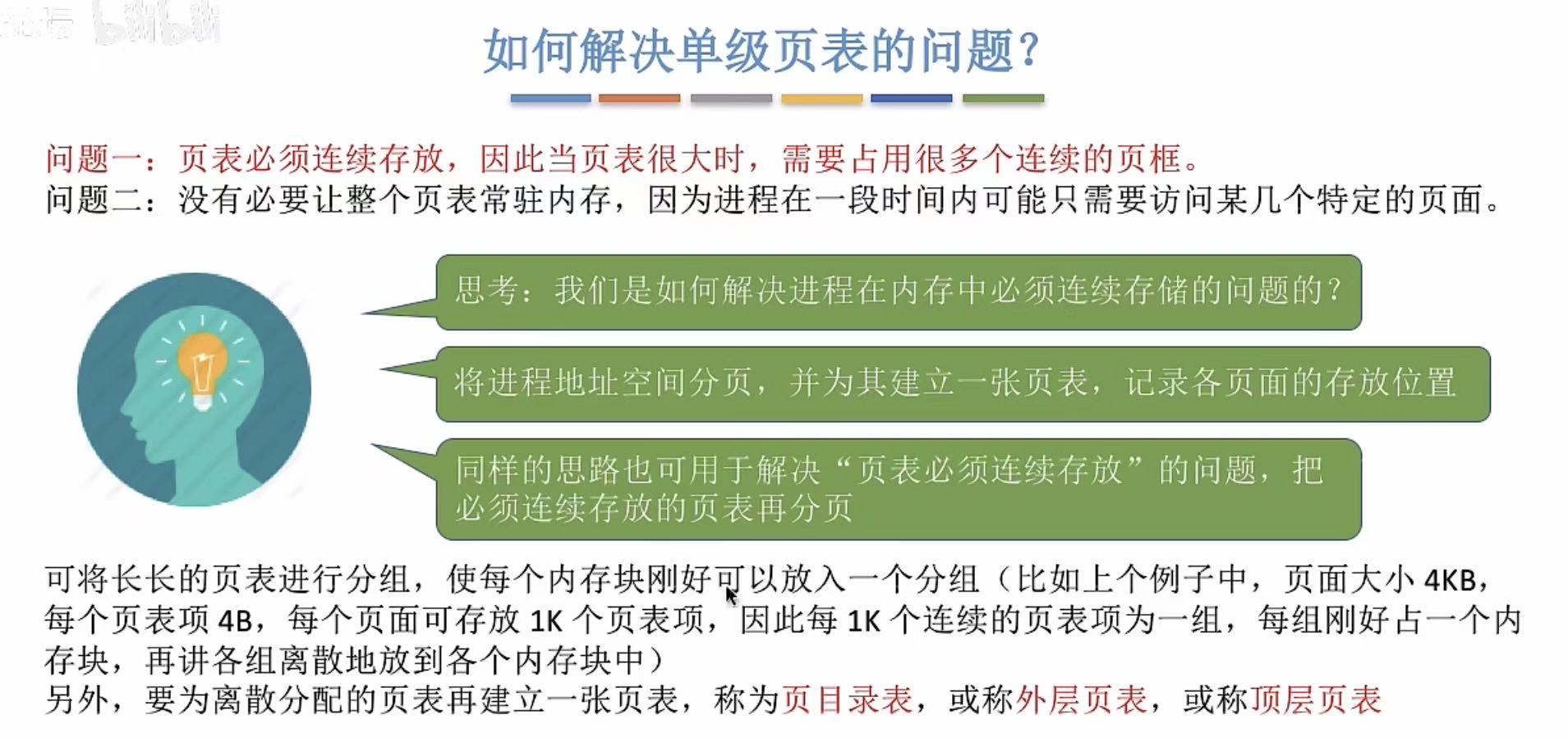
3. 两级页表的原理、地址结构
- 第一列:是第二列分割后的索引。
- 第二列:是第三列的直接索引。
- 第一列绿色部分:是第一列索引的索引。
简单说就是丢掉第二列改用第一列,想用第一列的第一步,就是用绿色的索引查出你要用哪个序号的页表,再查这个页表中的页表项获得块号什么的,因为是由第二列顺序切割开的,所以每个页表的块号和第二列的块号是对应的。
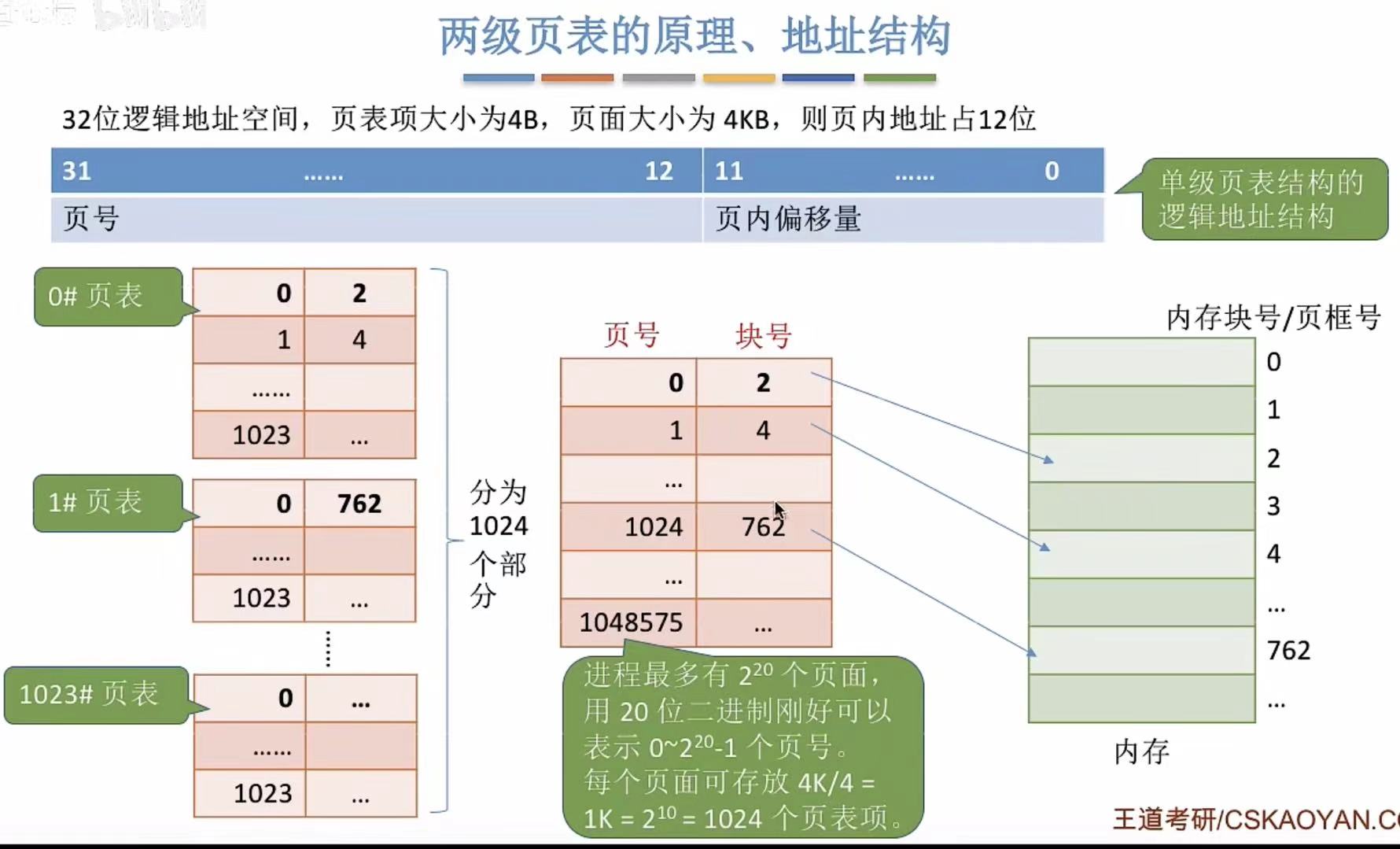
此图就是把绿色的索引收集起来也变成了一个页表。一级查一级。
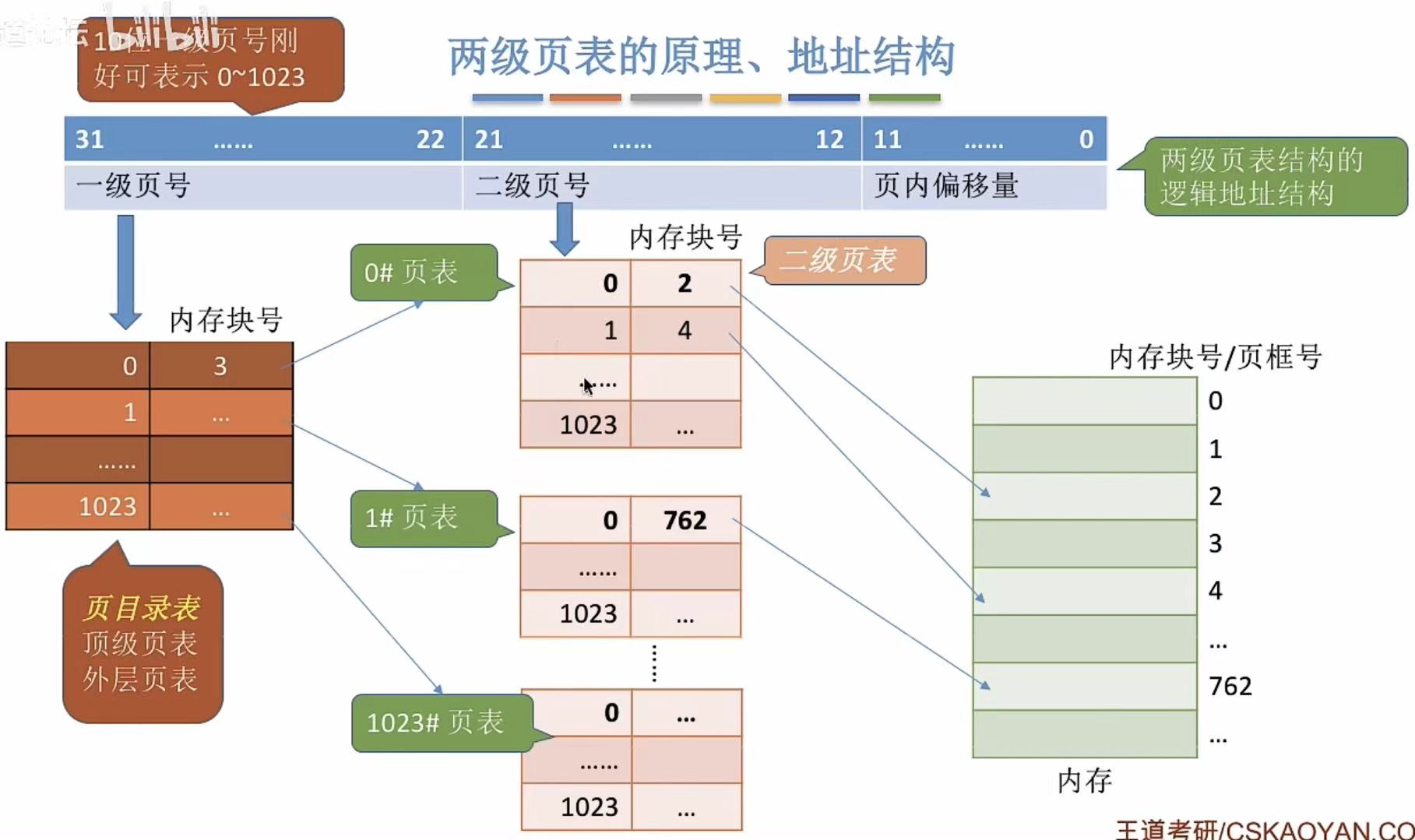
4. 如何实现地址变换
这里访问的顺序是:
- 通过一级页号0获得内存块号3
- 到达内存块号3获得二级页表
- 通过二级页号1获得内存块号4
- 成功到达
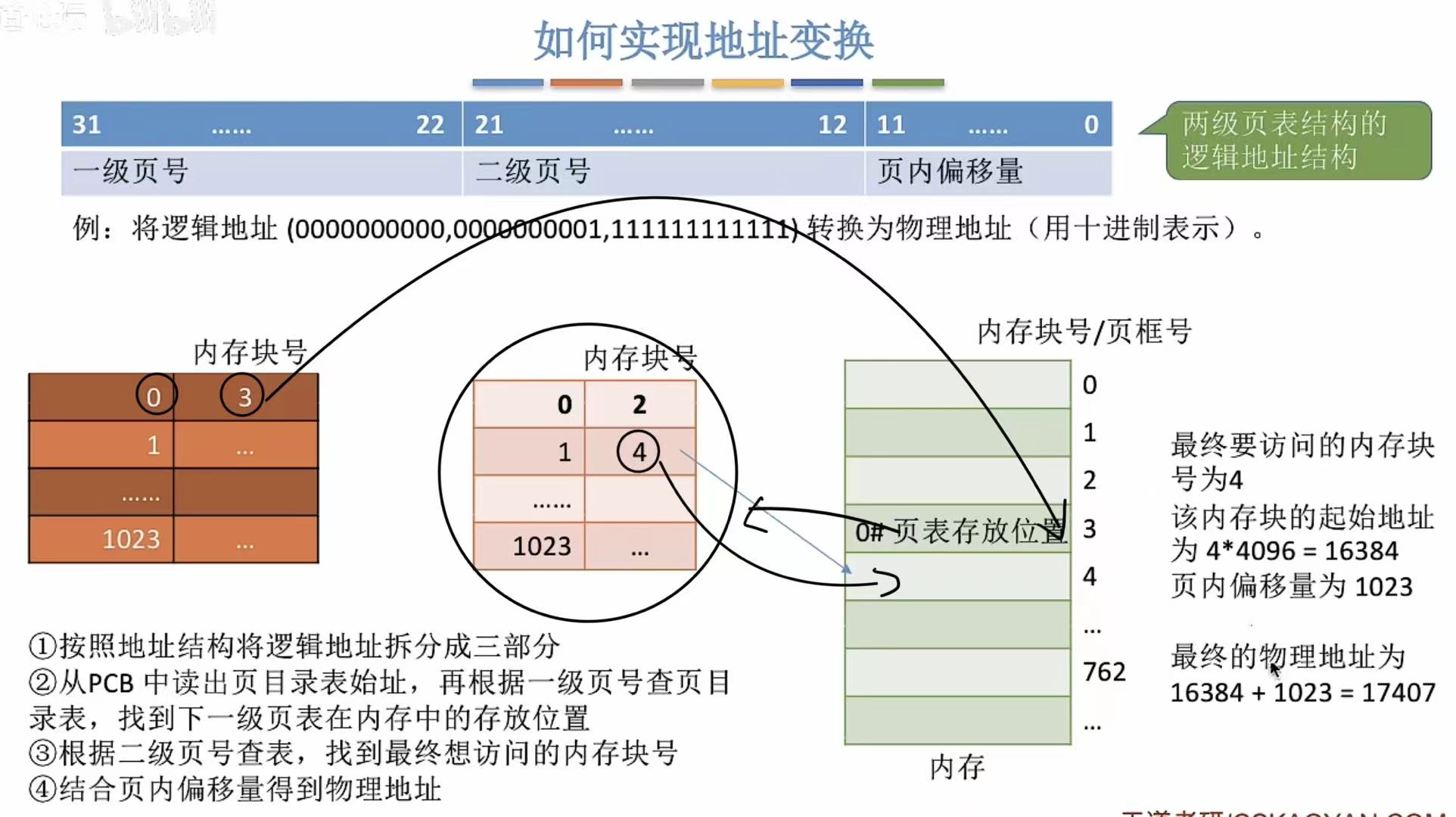
5. 如何解决整个页表常驻内存
人性化处理,用到你时才用你来,用不到也不强迫你来
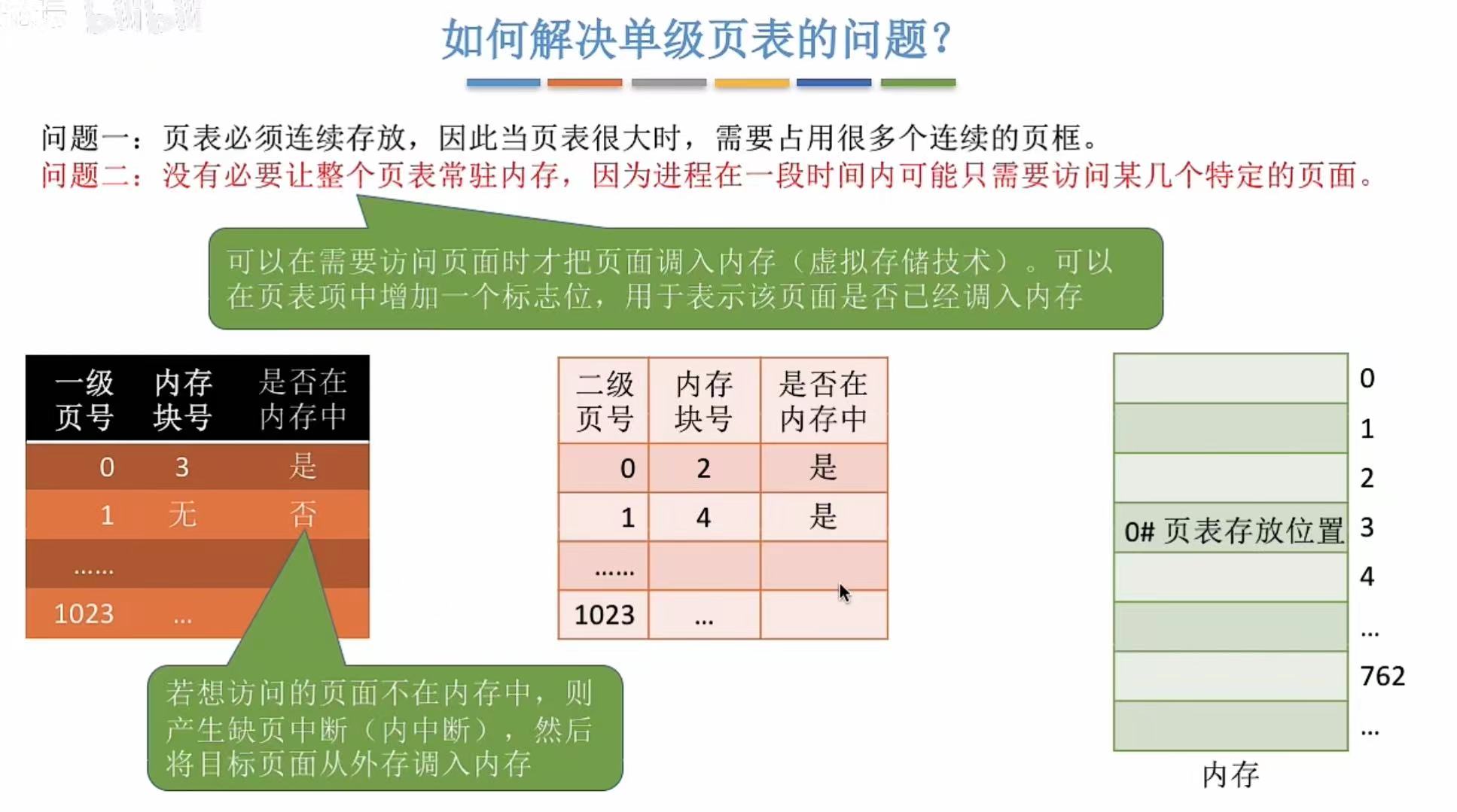
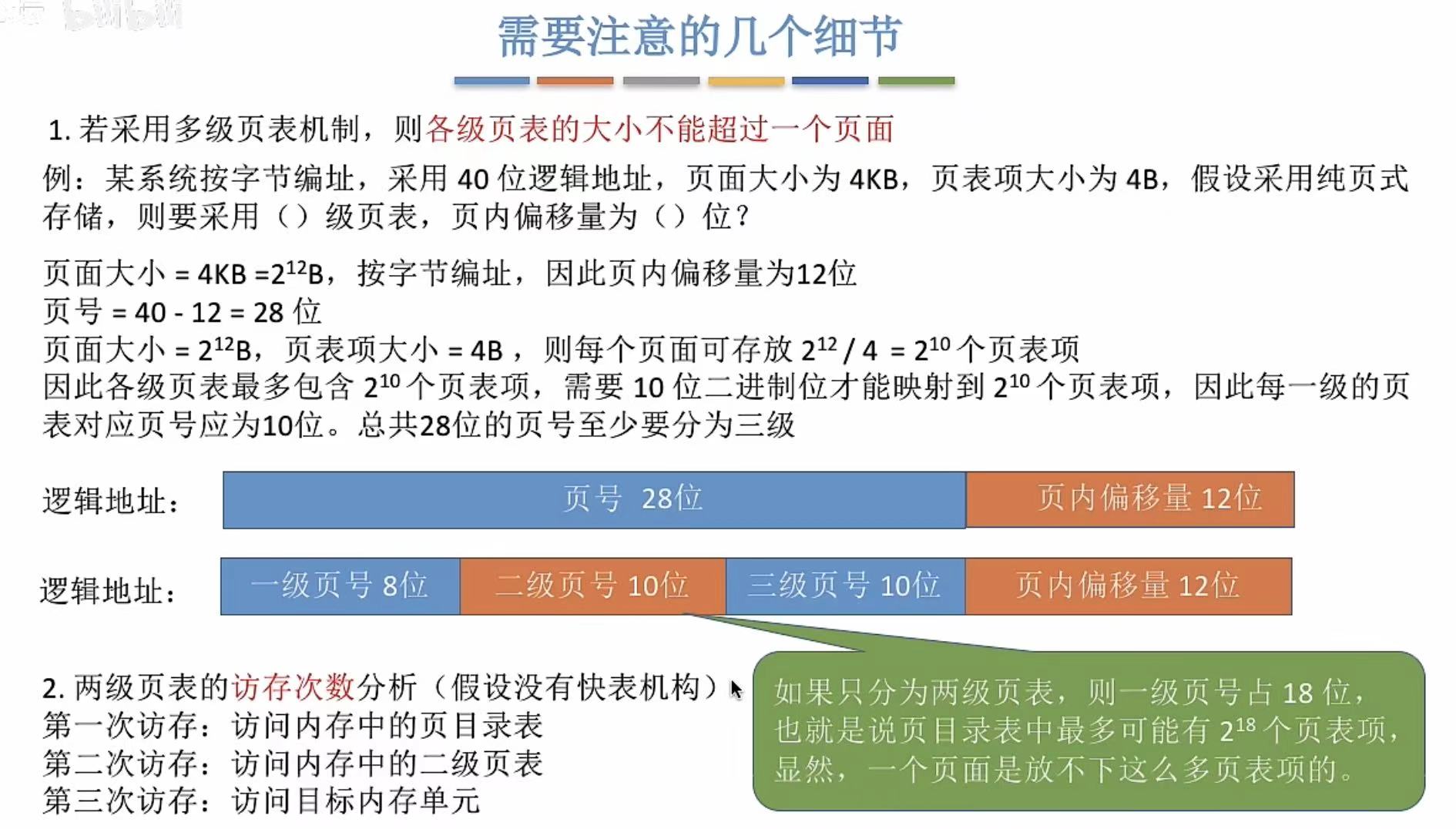
6. 细节
各级页表大小不能超过一个页面
总之就是计算计算计算
7. 小结
基本分段存储管理
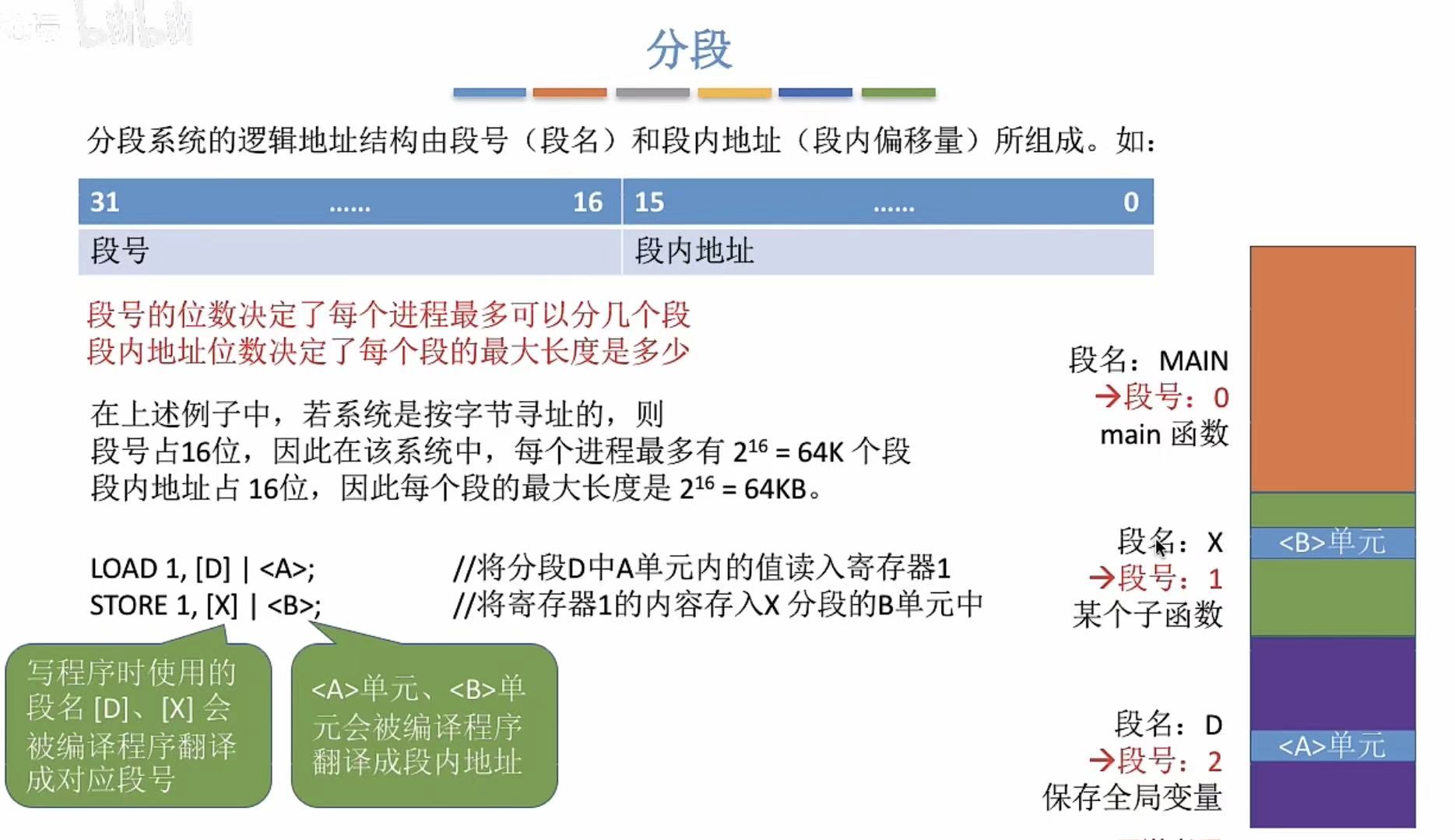
1. 分段
就是按照功能,把进程分成不同的程序段。
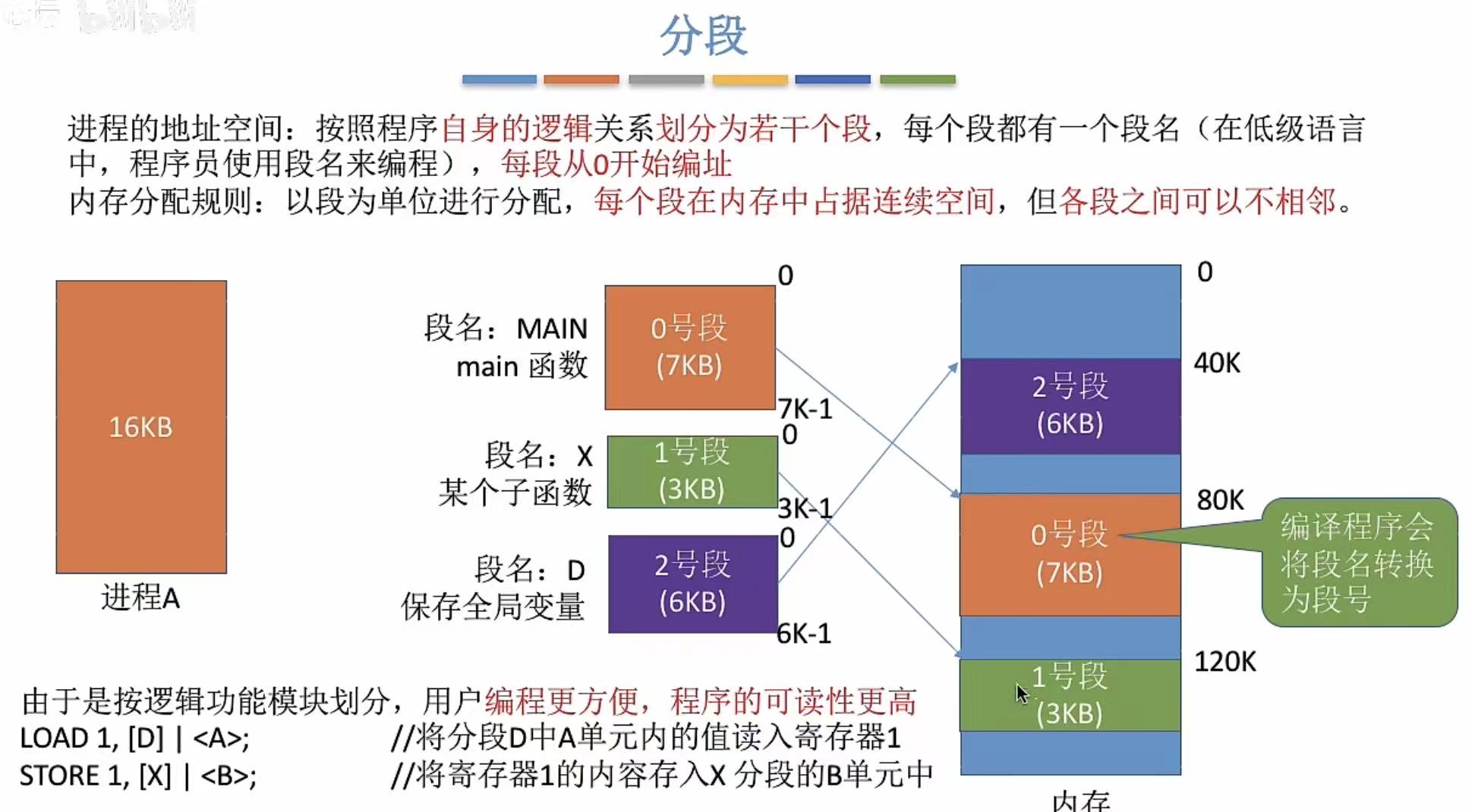
- \[\]放的是段号
- <>放的是段内地址
- 段号位数-->多少个段
- 段内地址位数-->段的最大长度
2.段表
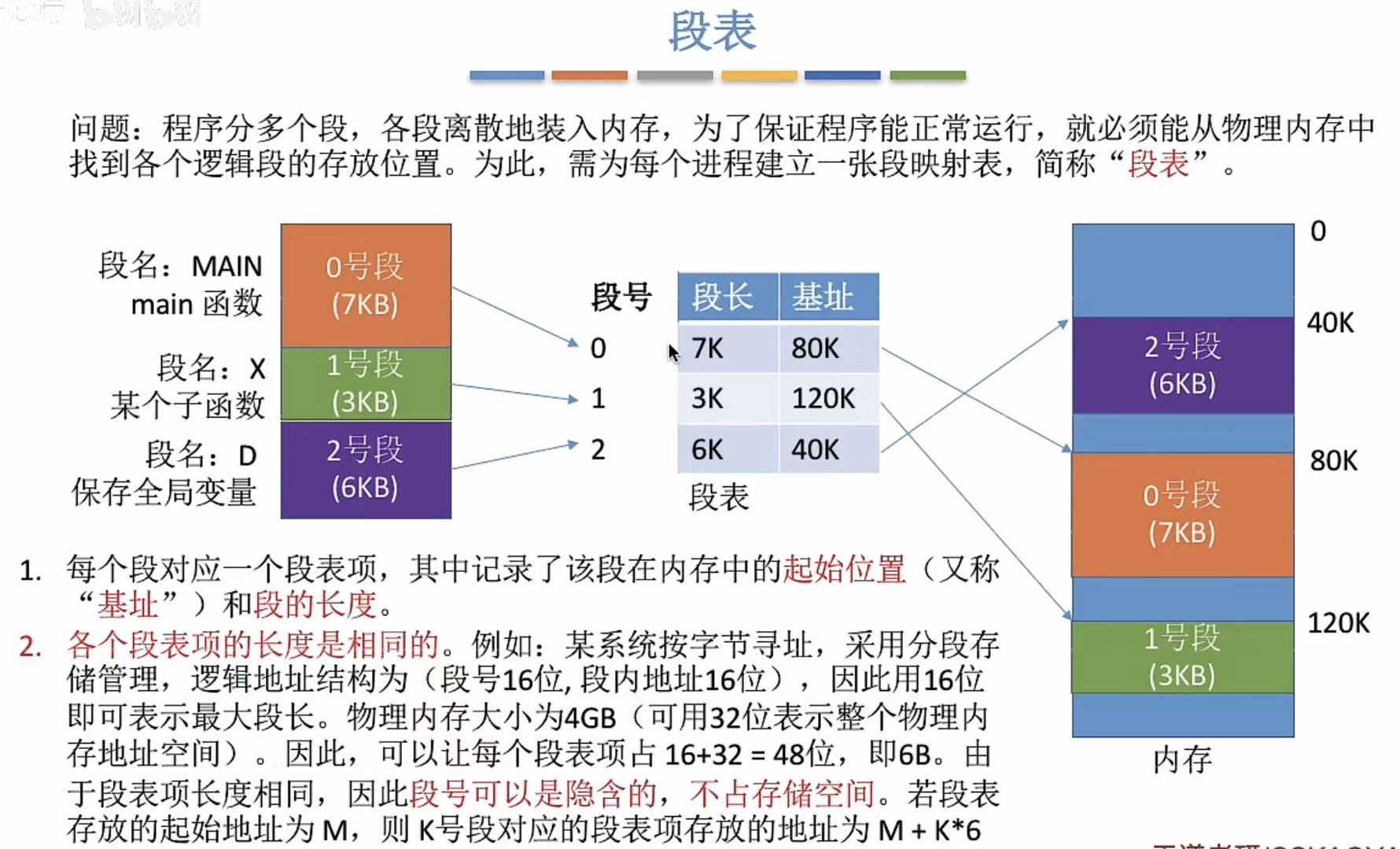
和页表一样的概念,就是加了个目录,这样好找程序段。
同样,因为是默认升序,所以段号不占内存。
3. 地址转换
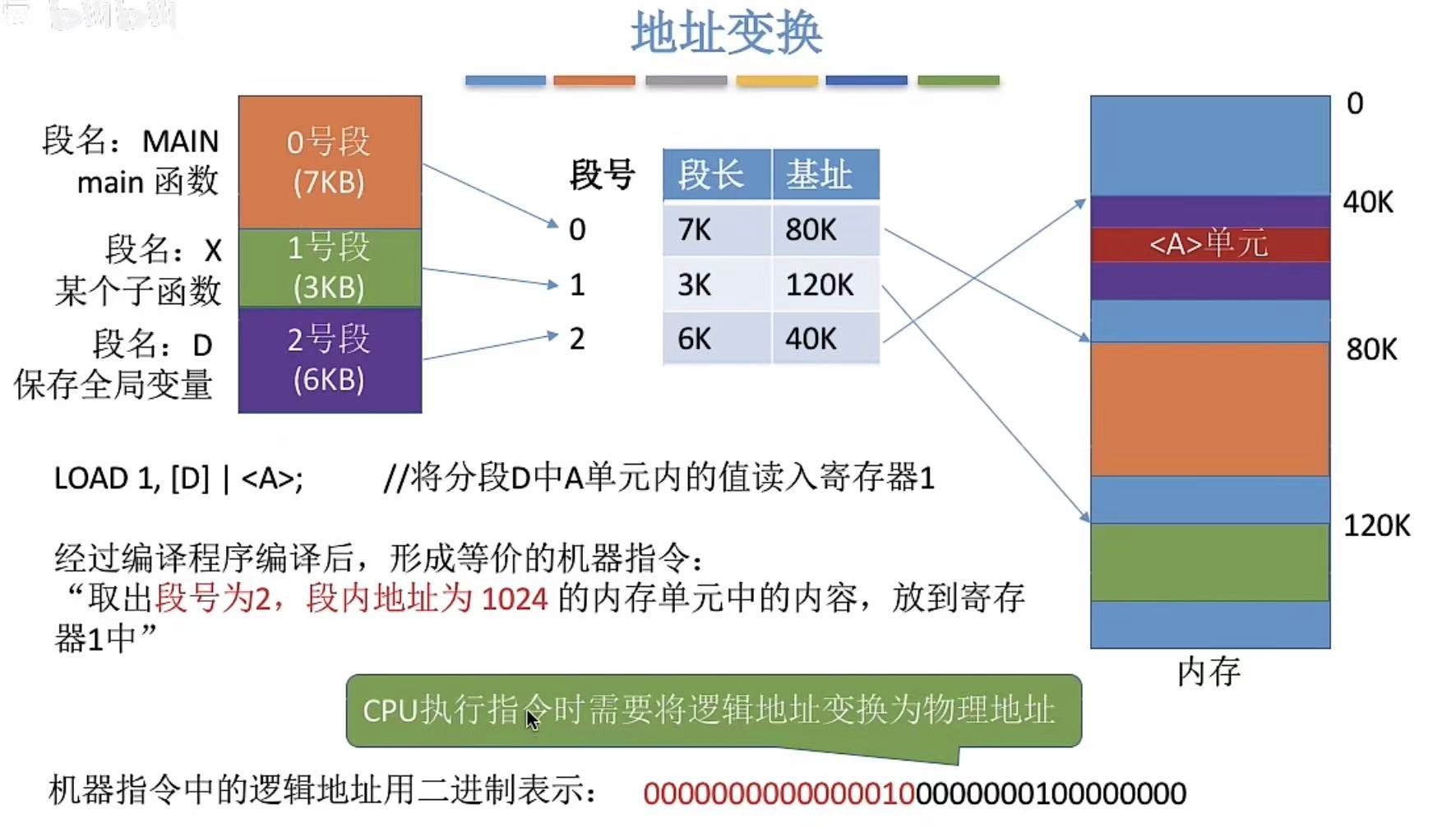
和基本地址变换机构相同,都是在进程启用的时候把需要用的东西从PCB中送到寄存器中。
ps:怪不得都姓"基础"呢...

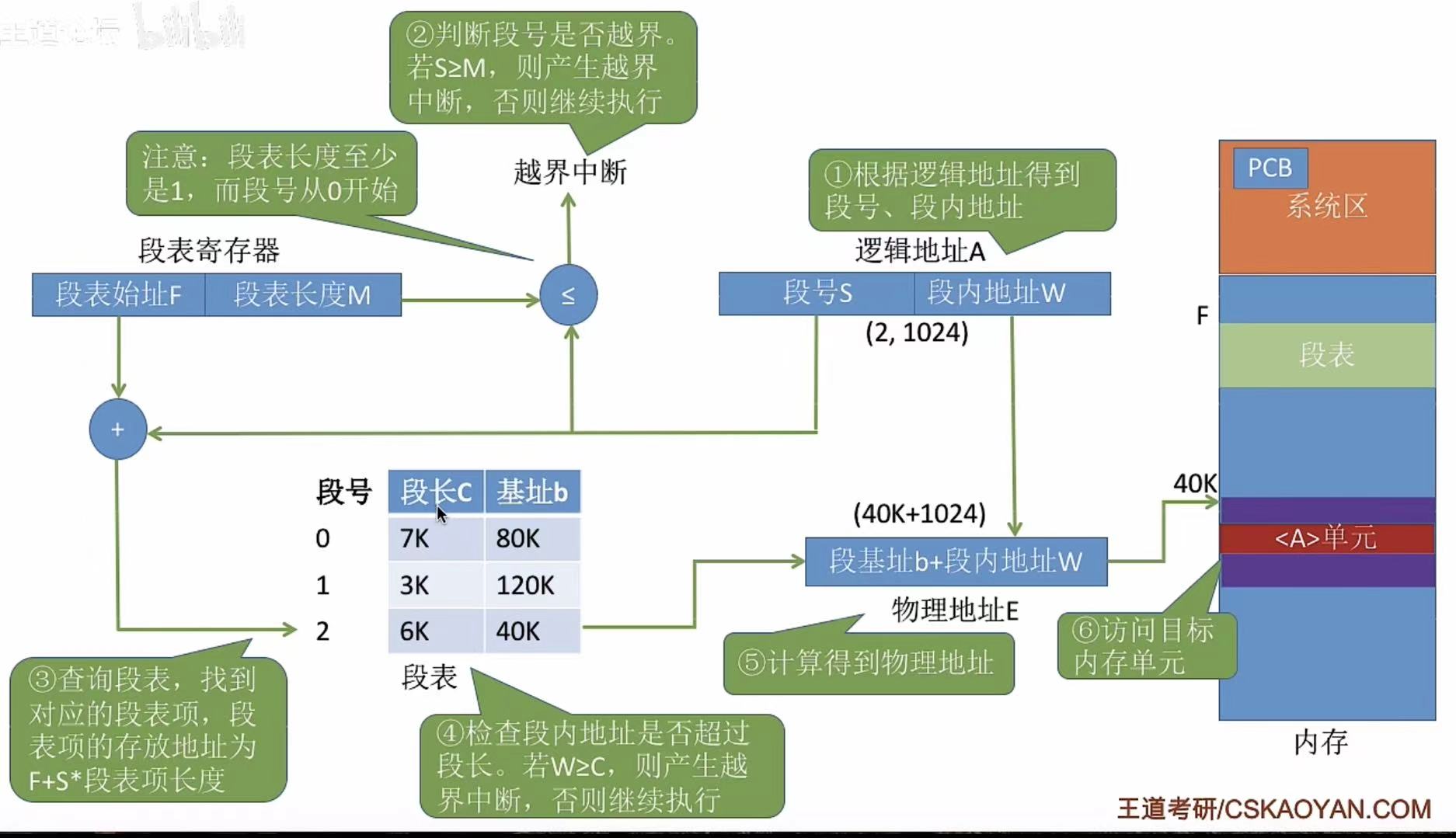
大体流程和基本地址变换机构相同,不过多了第四步,需要检查段内地址是否超过段长。
4. 分段、分页管理的对比
- 分页-->系统-->长度固定-->一维
- 分段-->用户-->长度不固定-->二维
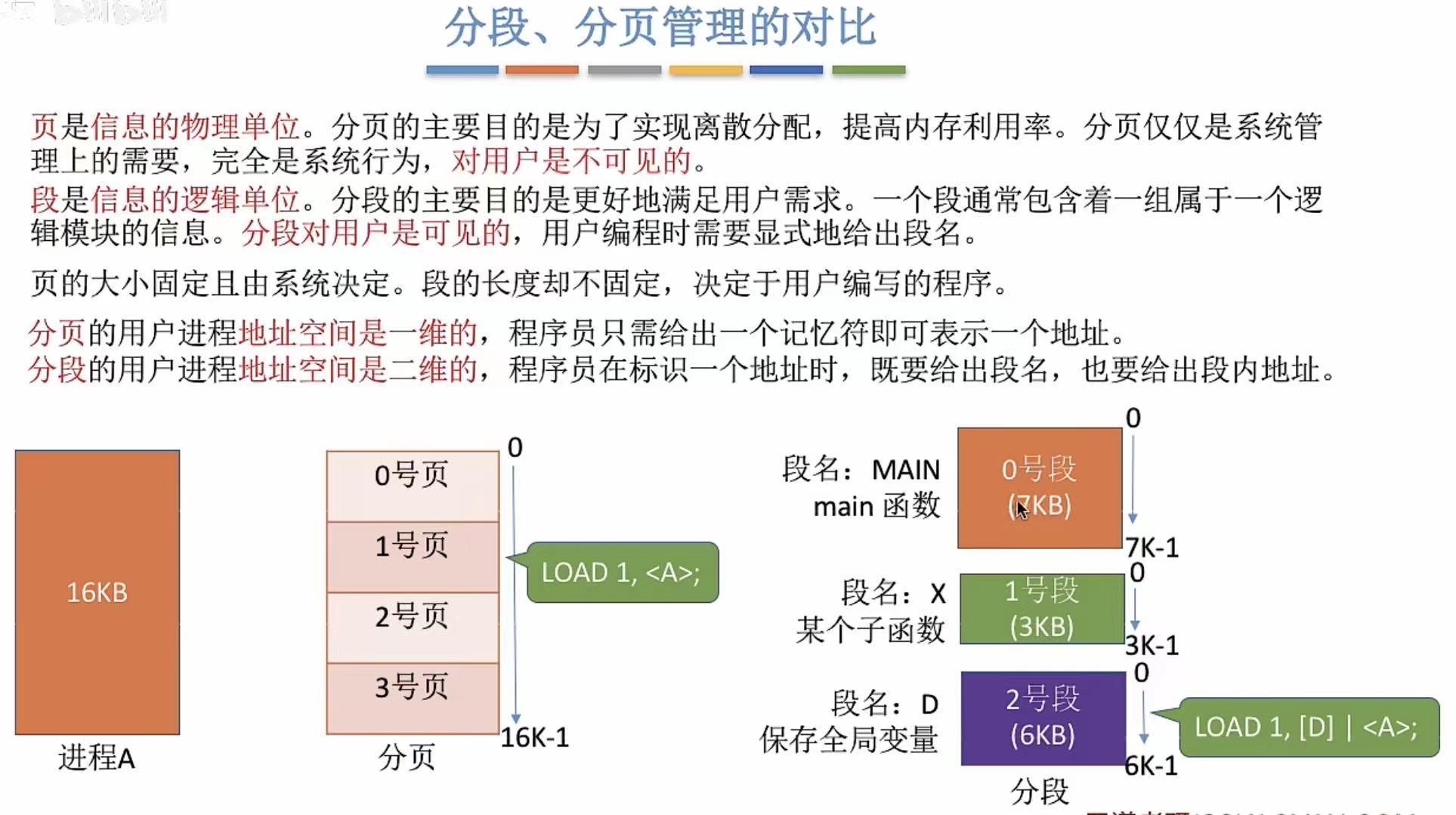
分段因为每个程序段的作用不同,就可以更好地设置权限,比如不能改的就干脆给个只读的权限什么的。
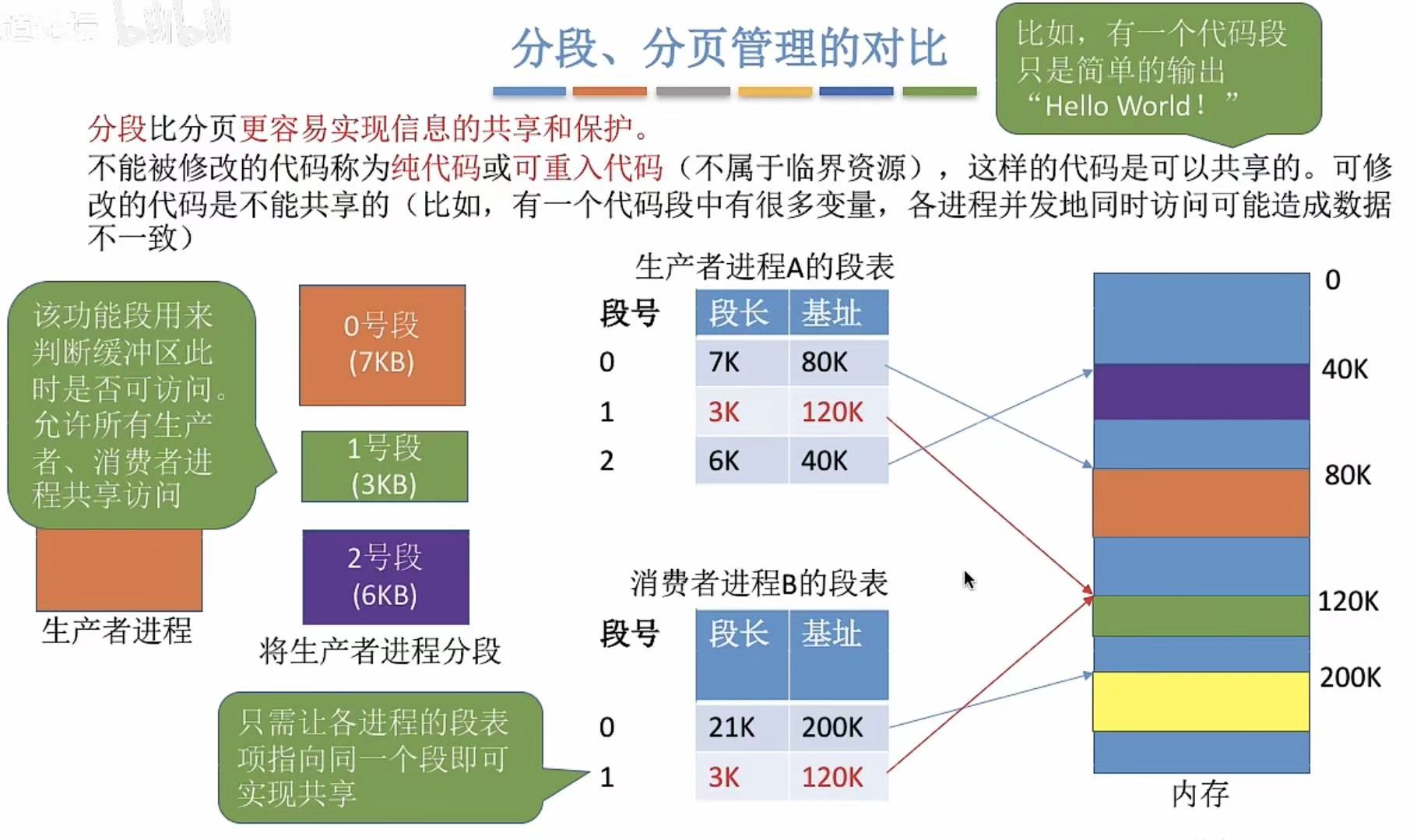
分页的话,可能需要区分两种权限的刚好分在一个页面上,一个只能读,一个可读可修改,根本中和不到一起,所以就可能出现安全问题。


5. 小结
段页式管理方式
两相结合,具体不再赘述。
1. 优缺点分析
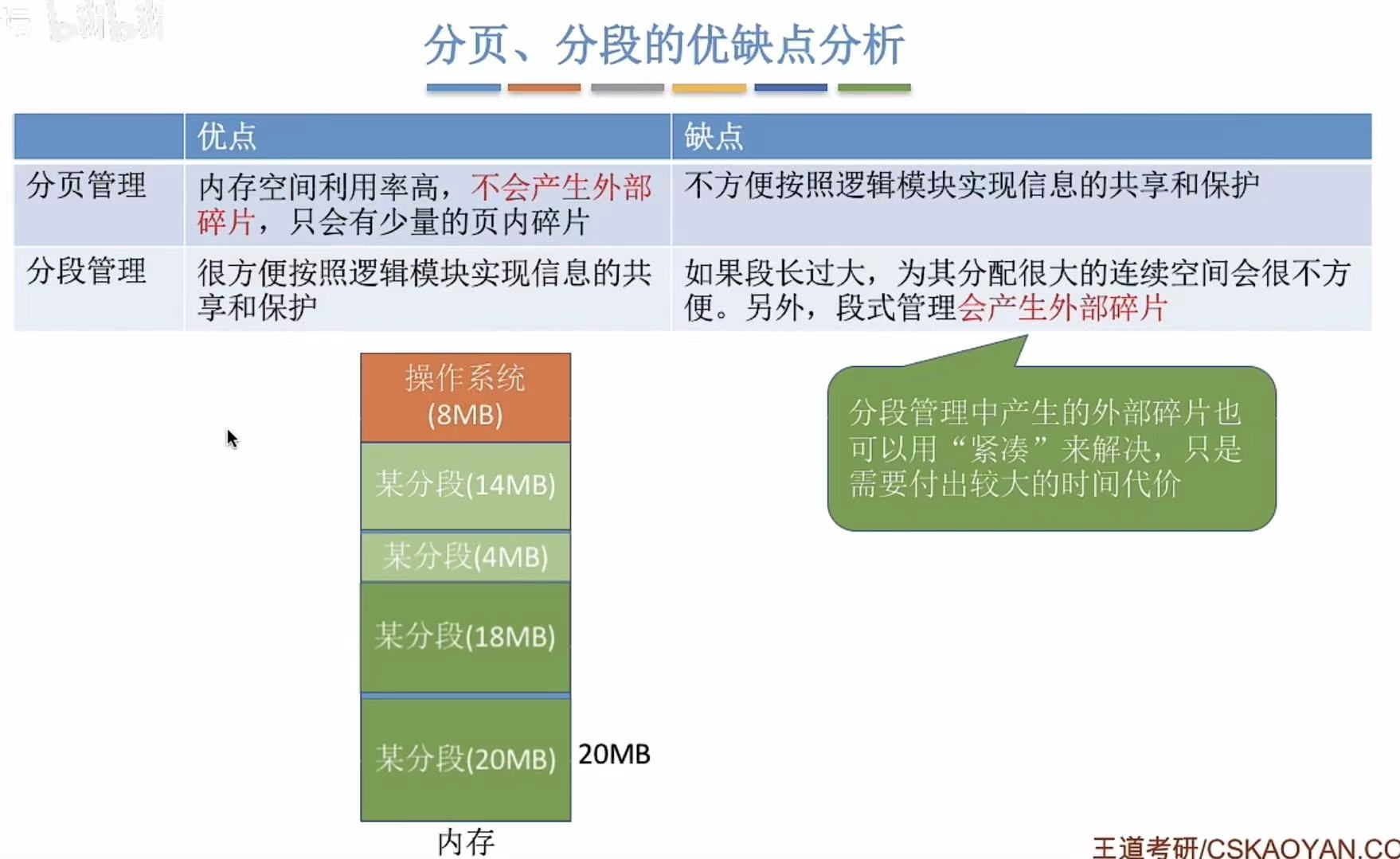
先分段再分页,保证每个程序段中都只有自己这一类的代码,保住了安全性还更节约内存了。
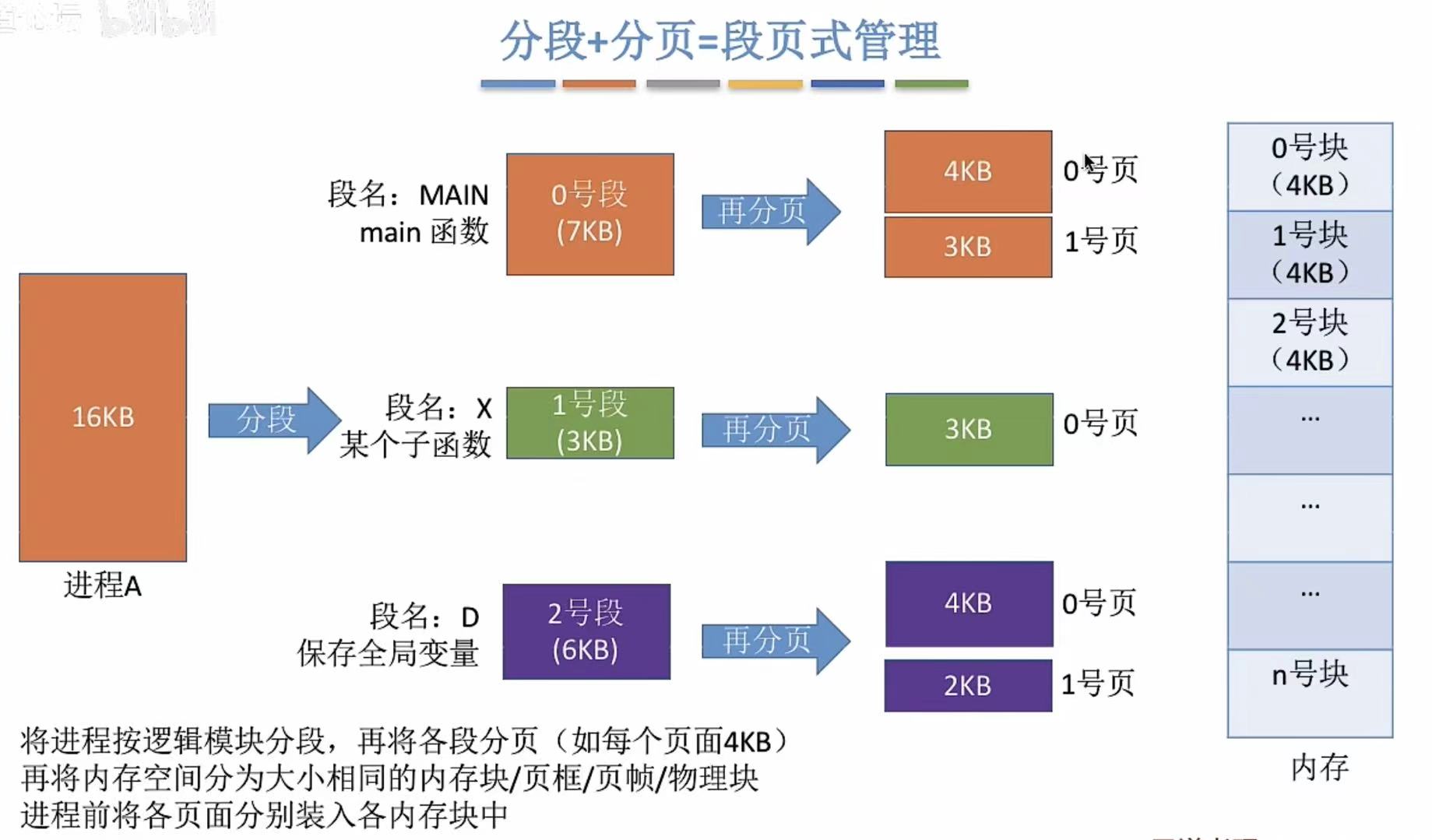
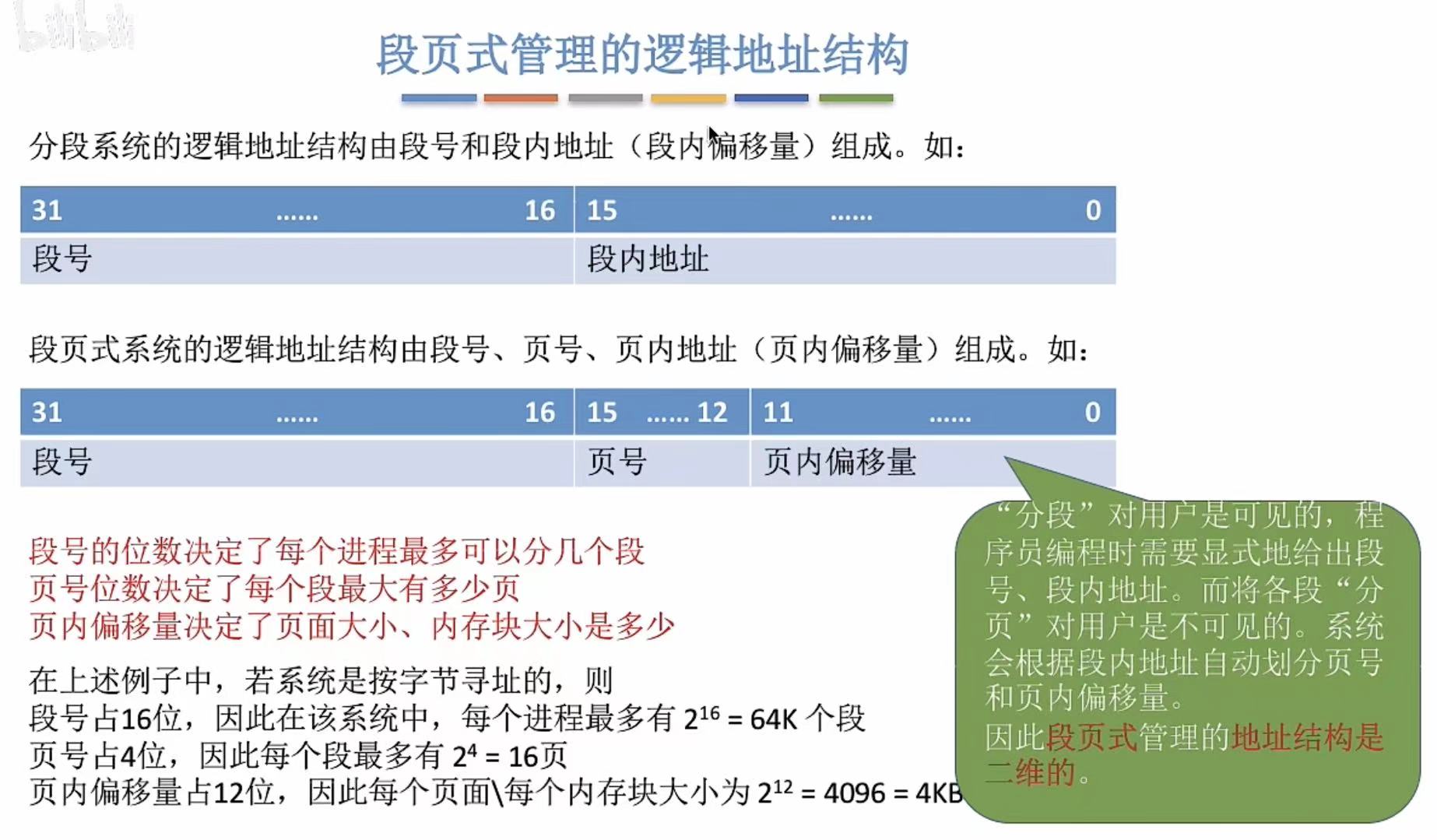
2. 段表、页表
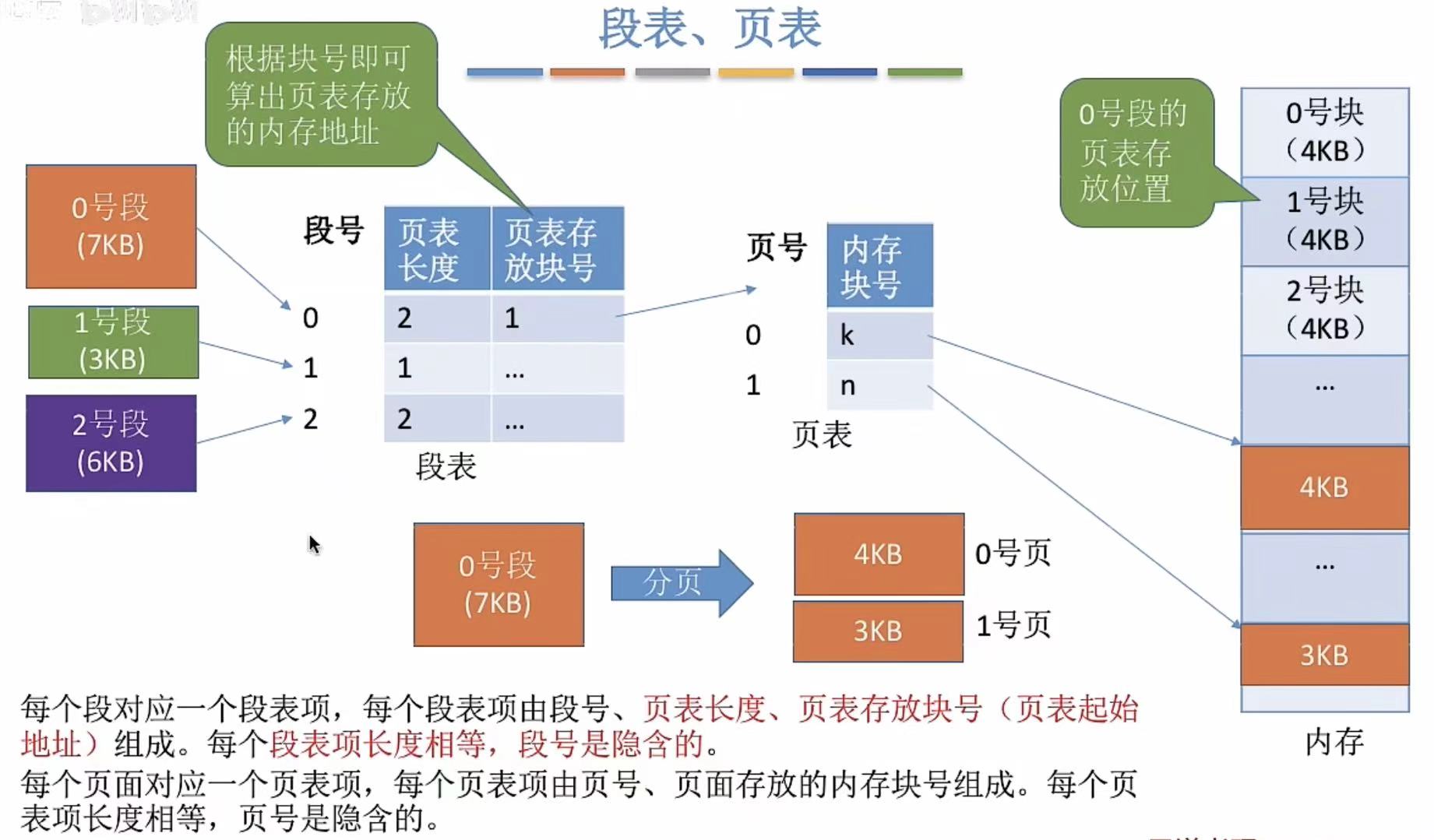
3. 地址转换
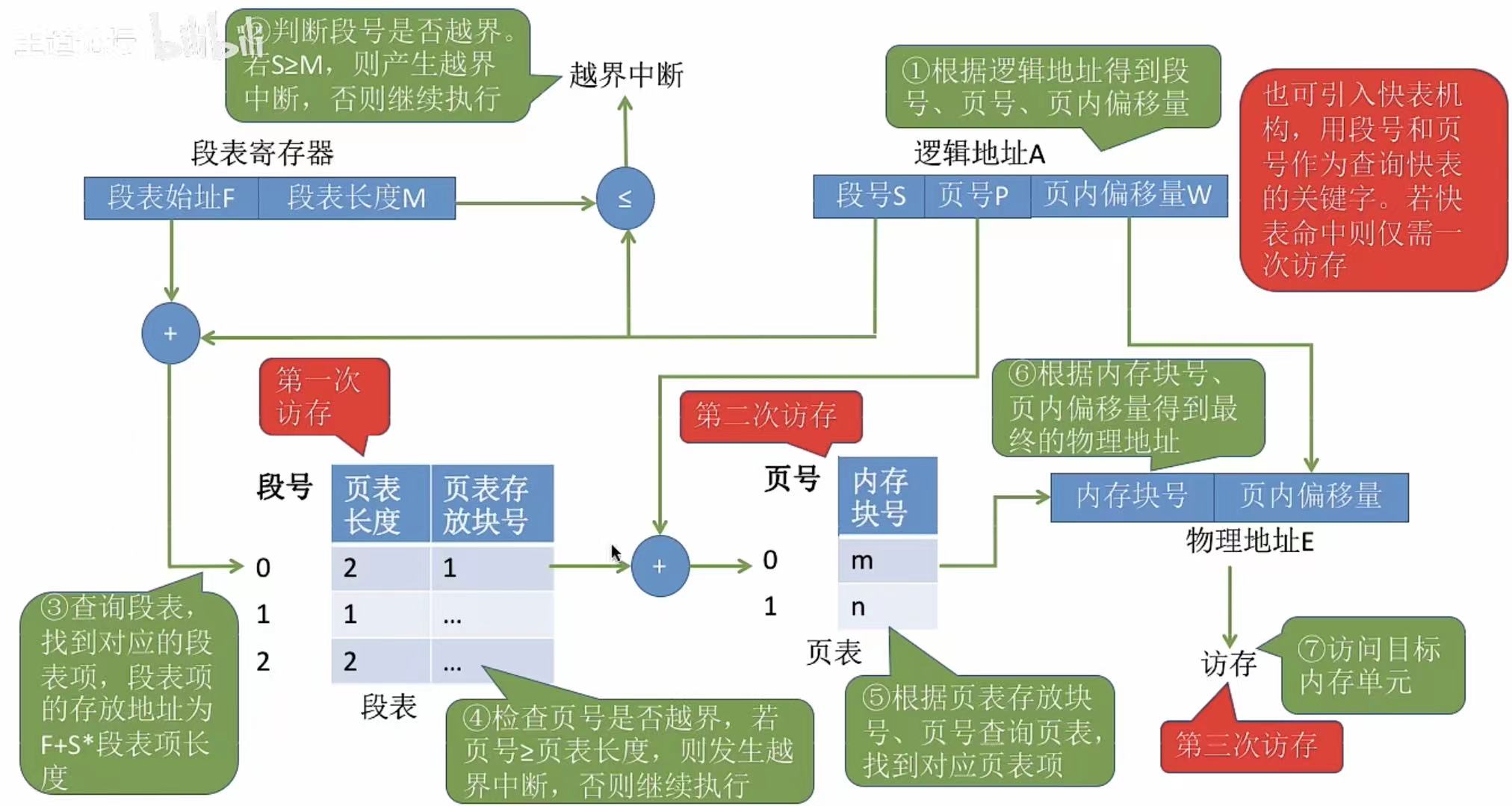
4. 小结