简介
本文介绍一种名为DeepVoxelFlow(DVF)的视频帧合成方法,针对视频帧插值(两帧间生成中间帧)与外推(生成后续帧)任务,结合传统光流技术的准确性与CNN的生成能力,通过端到端卷积编码器-解码器预测3D体素流,利用体积采样合成高质量帧,解决传统方法的错误传播与CNN的模糊问题。
论文背景与核心动机
视频帧合成的核心挑战在于外观与运动的复杂性:传统光流法依赖帧间运动估计,若光流不准会引入错误;而直接生成像素的CNN法常因缺乏运动约束导致模糊。作者观察到两点关键规律:
- 视频中多数像素是邻近帧的直接拷贝,复制比生成更简单;
- 端到端神经网络适合无监督训练(任何视频均可作为数据),能充分利用海量视频资源。
基于此,DeepVoxelFlow的目标是结合光流的运动准确性与CNN的学习能力,用无监督方式从视频中学习帧合成规则。
DeepVoxelFlow方法原理
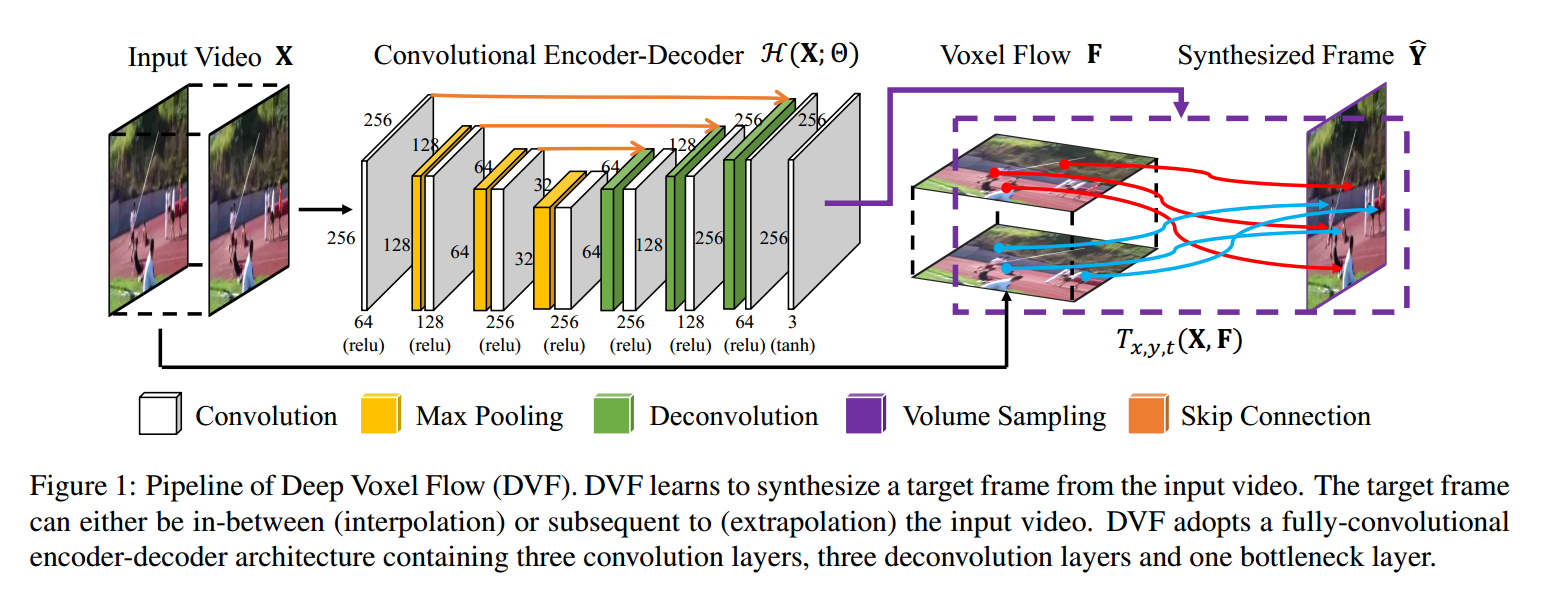
DeepVoxelFlow是一套端到端可微分的全卷积网络,核心流程为:
- 编码器-解码器网络预测3D体素流(Voxel Flow);
- 体积采样层(Volume Sampling)基于体素流从输入视频中插值生成目标帧。
1. 3D体素流的定义
3D体素流( F )是网络的核心输出,包含空间运动信息 与时间混合权重两部分:
- 空间运动成分:表示目标帧到下一帧的2D光流,其负值对应目标帧到前一帧的光流(假设光流在时间上线性对称)。
- 时间混合成分:表示前一帧与后一帧的像素混合权重,用于融合两帧像素生成目标帧。
形式上,体素流( F )可拆分为:F=Fmotion,Fmask F = F_{\\text{motion}}, F_{\\text{mask}} F=Fmotion,Fmask
其中,(Fmotion∈RH×W×2(F_{\text{motion}} \in \mathbb{R}^{H \times W \times 2}(Fmotion∈RH×W×2)(H、W为帧高宽),(Fmask∈RH×W×1( F_{\text{mask}} \in \mathbb{R}^{H \times W \times 1}(Fmask∈RH×W×1)。
2. 体积采样与三线性插值
体积采样函数( T )的作用是:基于体素流( F ),从输入视频( X )(含前帧与后帧)中插值生成目标帧( Y )。具体步骤如下:
- 构建虚拟体素 :根据体素流的运动成分,计算目标帧像素对应前帧与后帧的位置(L0( L_0(L0)(前帧)、(L1( L_1(L1)(后帧),形成一个虚拟3D体素(包含时间维度的视频体积)。
- 三线性插值 :对虚拟体素的8个顶点(整数坐标)进行三线性插值,计算目标像素的最终颜色。三线性权重(Wijk( W^{ijk}(Wijk)由顶点坐标与虚拟体素的相对位置决定。
最终目标帧的生成公式为:Y=T(X,F)=∑i,j,kWijk⋅X(L0+i,L1+j,t+k) Y = T(X, F) = \sum_{i,j,k} W^{ijk} \cdot X(L_0 + i, L_1 + j, t + k) Y=T(X,F)=i,j,k∑Wijk⋅X(L0+i,L1+j,t+k)其中,(i,j,k∈{0,1}( i,j,k \in \{0,1\}(i,j,k∈{0,1})是虚拟体素的顶点索引,( t )是时间维度坐标。
3. 网络架构设计
DeepVoxelFlow采用全卷积编码器-解码器结构,无全连接层(支持任意分辨率输入):
- 编码器:3个卷积层( kernel=3×3,stride=2),逐步压缩空间维度,提取视频的多尺度特征;
- 瓶颈层:1个卷积层,整合编码器的高层特征;
- 解码器:3个反卷积层( kernel=3×3,stride=2),逐步恢复空间维度,输出与输入同分辨率的3D体素流( F )。
模型训练与优化
1. 损失函数设计
网络采用无监督训练,训练数据为视频三元组(前帧、后帧、目标帧)。损失函数包含三部分:
- 重建损失:衡量生成帧与真实帧的像素误差(L2范数);
- 运动正则:对体素流的运动成分施加L1正则(总变异),防止运动场过拟合;
- 掩码正则:对体素流的时间成分施加L1正则,保证混合权重的稳定性。
总损失公式为:L=1N∑(X,Y)∈D∣∣T(X,H(X))−Y∣∣∗22+λ1∣∣F∗motion∣∣∗1+λ2∣∣F∗mask∣∣1 \mathcal{L} = \frac{1}{N} \sum_{(X,Y) \in \mathcal{D}} || T(X, H(X)) - Y ||*2^2 + \lambda_1 || F*{\text{motion}} ||*1 + \lambda_2 || F*{\text{mask}} ||_1 L=N1(X,Y)∈D∑∣∣T(X,H(X))−Y∣∣∗22+λ1∣∣F∗motion∣∣∗1+λ2∣∣F∗mask∣∣1其中,(D( \mathcal{D}(D)是训练集,( N )是样本数,( H(X) )是编码器-解码器的输出(体素流( F )),(λ1,λ2( \lambda_1, \lambda_2(λ1,λ2)是正则化系数。
2. 关键训练技巧
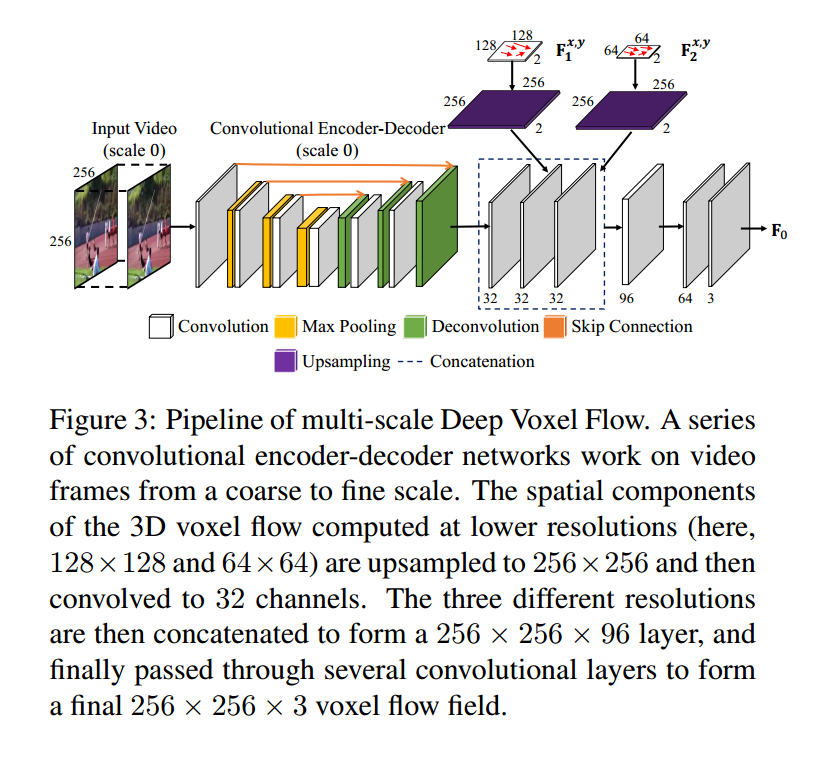
- 多尺度流融合:网络在不同分辨率下预测体素流,融合多尺度信息以提升运动估计的准确性;
- 多步预测:生成的帧可作为新的输入,继续预测后续帧(如用帧1、2生成帧3,再用帧2、3生成帧4),实现长序列视频外推。
实验结果与优势
DeepVoxelFlow在UCF101 (动作视频)、HMDB51(行为视频)等数据集上测试,结果显示:
- 准确性:PSNR(峰值信噪比)比传统光流法高1.2dB,比CNN法高0.8dB;
- 清晰度:生成帧无模糊或错误边缘(光流法的常见问题);
- 通用性:支持任意分辨率视频,无需人工标注。
总结
DeepVoxelFlow的创新点在于用3D体素流统一运动与混合权重,将光流的运动约束与CNN的学习能力结合,通过无监督训练充分利用视频数据,解决了传统视频帧合成的两大痛点。该方法为视频补帧、慢动作生成等应用提供了更高效的解决方案。
获取更多资料
我给大家整理了一套全网最全的人工智能学习资料(1.5T),包括:机器学习,深度学习,大模型,CV方向,NLP方向,kaggle大赛,实战项目、自动驾驶,AI就业等免费获取 。