本文为Milvus Week系列第5篇,该系列旨在把Zilliz团队过去半年多积累的先进的技术实践和创新整理成多篇干货深度文章发布。
本系列已发表内容:
88.9 倍性能飙升!JSON Shredding 让 JSON 查询告别全表扫描| Milvus Week
Struct Array 如何让多向量检索返回完整实体?知识库、电商、视频通用|Milvus Week
语义+R-Tree空间索引:Milvus如何帮外卖APP做3公里内美食推荐| Milvus Week
内存涨疯了?AiSAQ让十亿级向量内存成本降低3200 倍| Milvus Week
以下是DAY 5内容 划重点:
-
CAGRA是英伟达推出的专为GPU打造的十亿级向量数据的图索引技术
-
GPU建图+CPU检索,在实际落地中往往更为高效且具备性价比
-
Milvus adapt_for_cpu参数是控制CAGRA索引的序列化与反序列化行为的关键。
文|陈建霖
面对十亿级乃至百亿、千亿级高维向量数据,要如何选择索引,才能同时兼顾检索精度与效率?
答案无疑是图索引(Graph-based Index)。
以 NSW、HNSW、CAGRA、Vamana 为代表的图索引,通过将高维向量映射为可导航的图结构,检索阶段通过图上路径导航快速定位近邻,可以实现精度与效率之间的平衡。
但在实际落地过程中,我们往往会发现,图索引虽然在检索阶段足够高效,但在建图阶段,却需要执行大量计算密集型操作,对硬件资源要求较高,而传统 CPU 并不擅长处理此类并行计算任务。
也正是因此,近两年来专为 GPU 并行计算加速设计的 CAGRA 索引逐渐引发关注。
基于这一行业需求,Milvus 2.6.1 版本为 GPU 索引 CAGRA 推出灵活部署选项,创新实现**"GPU 构建 + CPU 查询" 混合模式** ------ 既借助 CAGRA 强大的 GPU 图构建能力保障索引质量,又复用 HNSW 成熟的 CPU 检索能力降低部署成本,完美实现两者优势互补。
该模式尤其适用于数据更新频率低、查询规模大、成本敏感的场景,是兼顾性能与性价比的实用解决方案。
下文我们将详细拆解 Milvus 中 CAGRA 索引的构建原理与应用细节。
01
如何理解CAGRA
目前主流的图索引技术主要分为两类:以CAGRA(Milvus中已实现)为代表的迭代式图构建技术,和以Vamana(能力构建中)为代表的插入式图构建技术,两者针对的场景与技术路径存在显著差异,分别适配不同的数据规模与业务需求。
其中,CAGRA是迭代式构建的代表,核心优势在于高精度与高效能。
具体来说,CAGRA是NVIDIA提出的面向GPU优化的图索引技术,其核心特点是采用NN-Descent(Nearest Neighbor Descent)算法进行迭代式图构建,然后通过多轮 剪枝 优化(2-hop detours)逐步提升图结构质量,最终实现高精度的检索效果。
第一步:NN-Descent(Nearest Neighbor Descent)作图构建
其中,NN-Descent(Nearest Neighbor Descent)的核心是:如果节点u是节点v的近邻,且节点w是节点u的近邻,那么w有极高概率也是v的近邻,通过这种传递性可高效挖掘节点间的近邻关系。
其图构建流程如下:
-
随机初始化:每个节点随机选择若干邻居,形成初始图结构。
-
邻居扩展:在每轮迭代中,为每个节点收集其当前邻居及邻居的邻居,形成候选邻居池,计算候选节点与目标节点的相似度。不同候选池可分配至不同GPU核心并行批量执行,最终筛选潜在的更近邻节点。
-
连接更新:若发现更优的邻居,则替换当前较远的连接,逐步优化图的整体结构。
-
收敛判断:当更新的连接数量低于阈值时,迭代停止,图结构趋于稳定。
可以看到,在以上过程中,不同节点的邻居扩展、相似度计算完全独立,我们可通过GPU的线程块(Thread Block)机制为每个节点分配独立计算资源,实现大规模并行。
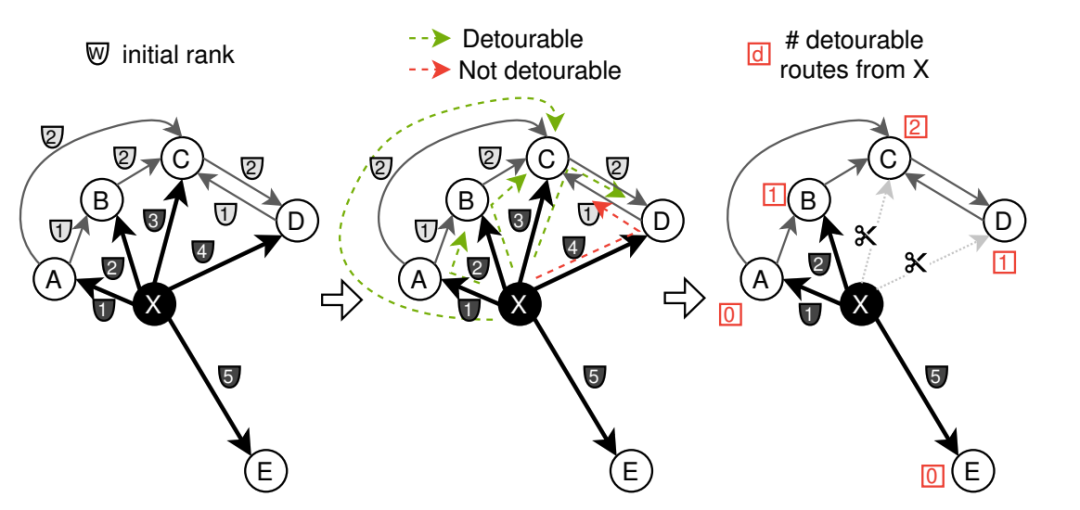
第二步: 2-hop detours 对图结构进行 剪枝 优化
经过前面NN-Descent算法构建中间图的流程之后,我们通常会发现,其节点度数通常是最终目标度数的2倍甚至更高,也就是说,图结构中存在大量冗余边,我们需要对其进行剪枝优化(2-hop detours)处理。
CAGRA 通过 2-hop detours 机制去除冗余边,核心思想就是:若节点A可通过另一个邻居节点C间接到达节点B(即存在路径A→C→B),且A到B的直接距离与A→C→B的间接距离差异较小,则认为A与B的直接连接是冗余边,可予以删除。
这种剪枝机制的优势在于,每条边的冗余判断仅依赖于其两端节点与共同邻居的距离计算,无跨边的数据依赖关系,可通过GPU批量并行执行,在不损失检索精度的前提下,将图的存储开销降低40%-50%,同时提升查询导航速度。
02
Milvus上的CAGRA有什么不同?
尽管GPU在图索引构建阶段优势显著,但在实际生产环境中,GPU资源通常比CPU更昂贵且稀缺。若索引构建与查询均依赖GPU,会导致一系列问题:
-
资源利用率低(查询请求零散,GPU大量时间空闲)
-
部署成本高(需为每个查询服务配置GPU,增加不必要的硬件成本)
-
扩展性受限(GPU数量限制服务实例数)
-
灵活性不足(无法按需切换 GPU 和 CPU )
针对这些痛点,开源向量数据库Milvus在2.6.1版本中,通过adapt_for_cpu参数,为GPU索引CAGRA推出灵活部署选项,实现GPU构建高质量图索引+CPU查询(一般用 HNSW )的混合模式,在保证索引质量的同时大幅降低部署成本。对于数据更新频率低(无需频繁重新构建索引)、查询规模大(需大量查询服务实例)、成本敏感(希望降低GPU资源投入)的场景,这是一种非常实用的解决方案。
(1)adapt_for_cpu解读
Milvus通过adapt_for_cpu参数控制CAGRA索引的序列化与反序列化行为,实现构建与查询设备的灵活切换。
该参数在构建阶段与加载阶段的不同组合,对应四种核心执行逻辑,可以覆盖不同业务需求:
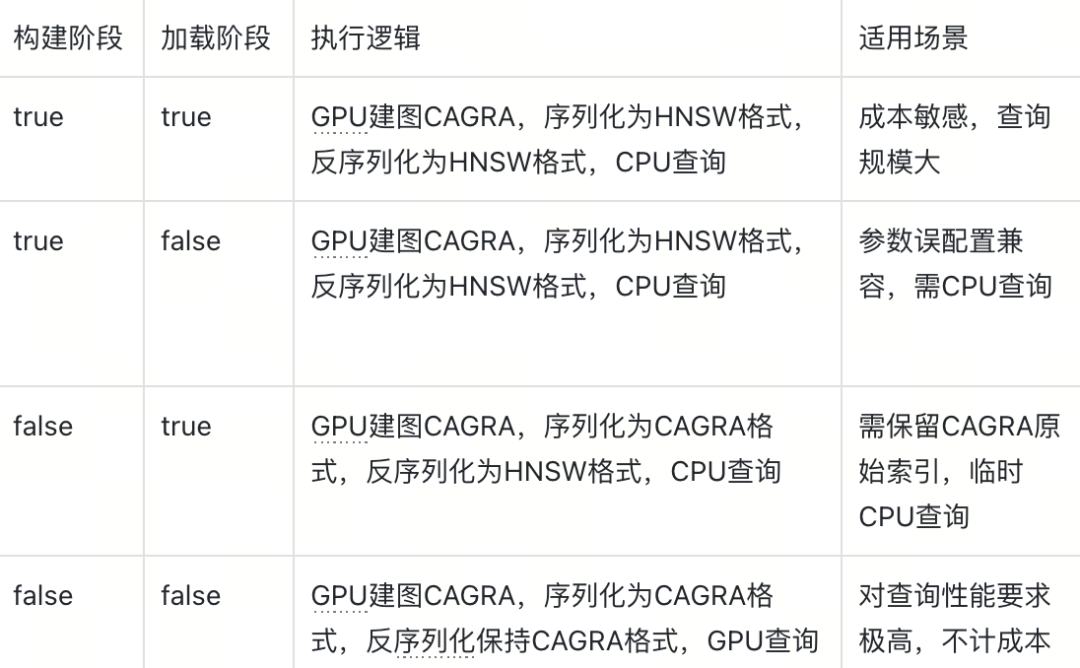
需要注意的是,该机制支持CAGRA格式向HNSW格式的单向转换(因CAGRA的图结构包含HNSW所需的全部近邻信息),但HNSW格式无法反向转换为CAGRA格式,因此构建阶段的参数设置需结合长期业务需求规划。
03
实验
为验证GPU构建+CPU查询混合模式的有效性,Milvus团队在标准测试环境下开展了系统性实验,从建图性能、查询性能、召回率三个维度进行对比分析。
实验环境
实验采用行业主流硬件配置,确保结果的参考价值:
CPU: MD EPYC 7R13 Processor(16 cpus)
GPU: NVIDIA L4
对比一:建图性能对比
CAGRA图在GPU上构建,HNSW在CPU上构建,图度数是64
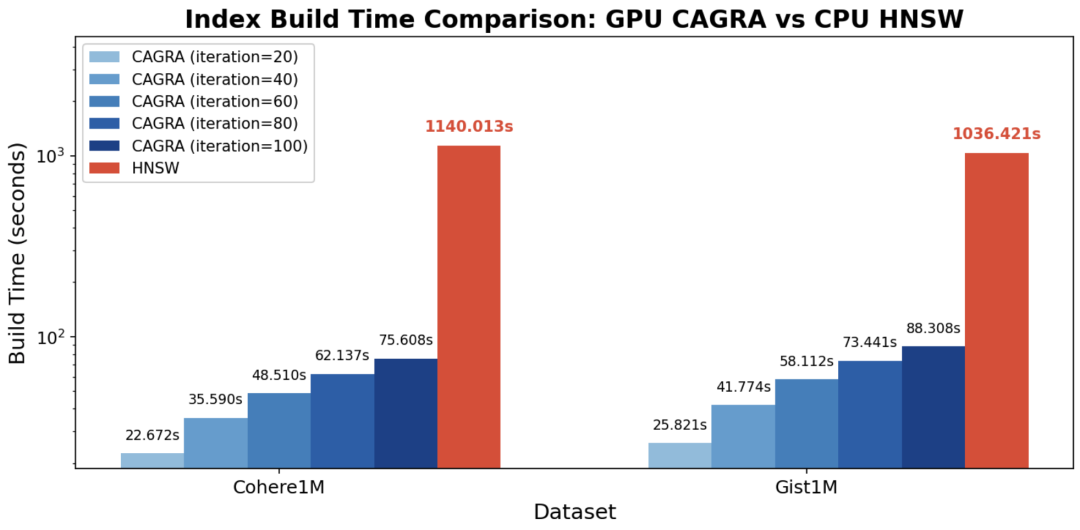
结论:
-
GPU CAGRA 的索引构建速度比 CPU HNSW 快 12-15 倍,充分体现了 GPU 在图索引构建阶段的显著优势。
-
随着iteration增加,构建时间也线性增长
对比二:查询性能
CAGRA图在GPU上构建,分别在CPU和GPU做查询,CPU查询需要先反序列化为HNSW格式
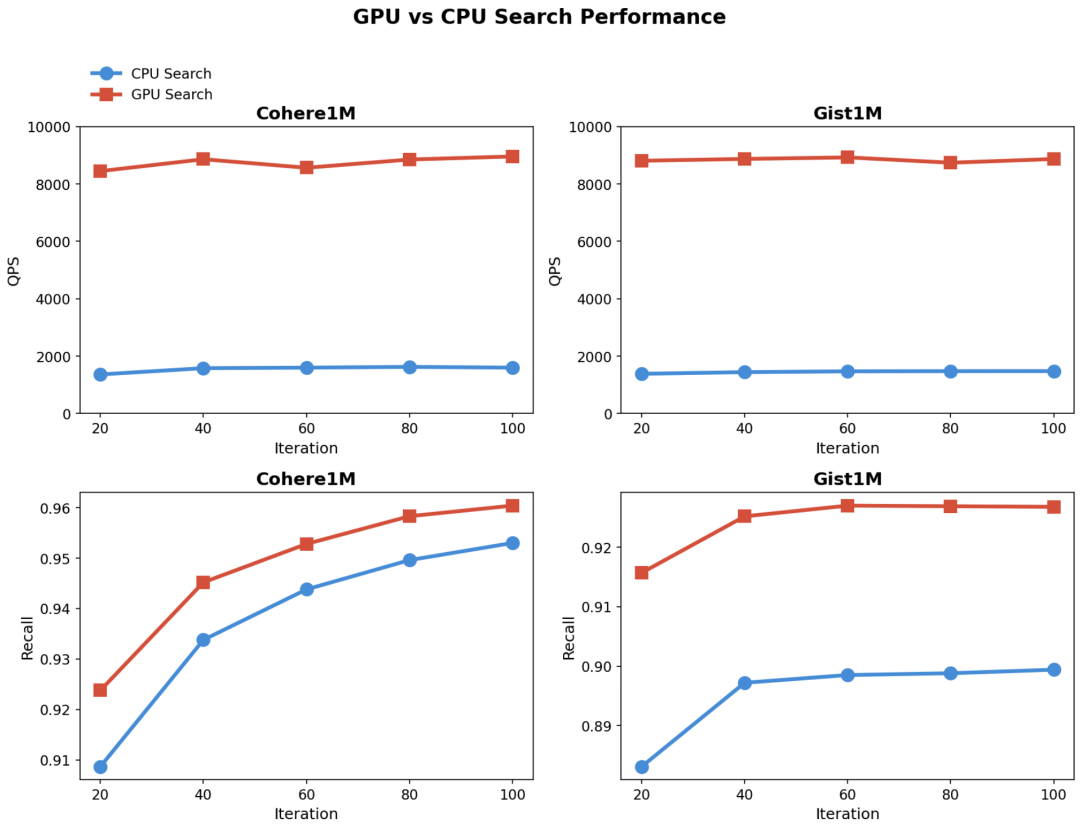
结论
-
GPU 搜索的 QPS 约为 CPU 搜索的 5-6 倍。
-
随着 iteration 增加,Recall 逐渐提升并趋于稳定,到一定阈值后,继续调大iteration的收益就不大。
对比三:CAGRA和HNSW召回对比
CAGRA和HNSW在CPU上查询,比较召回率
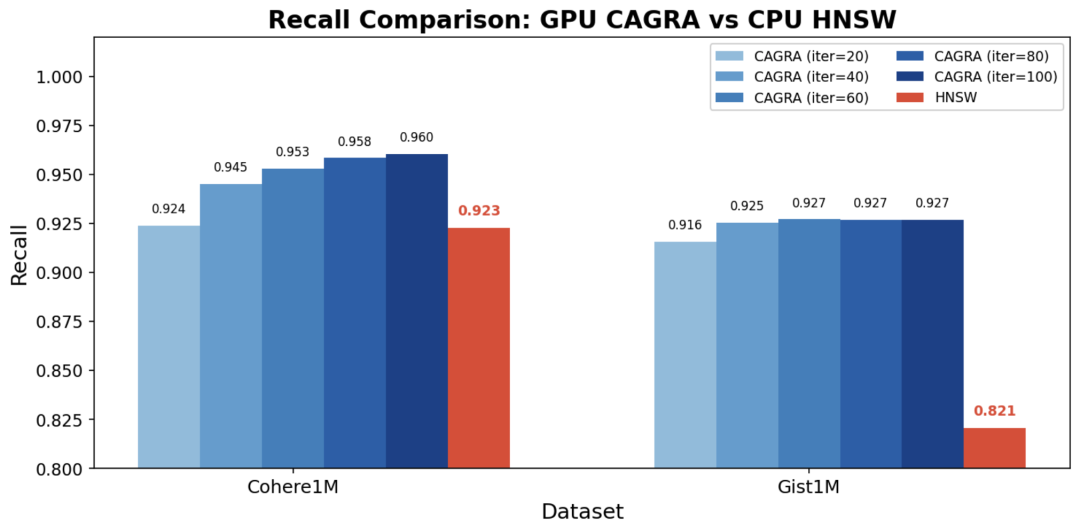
结论:CAGRA 的 Recall 在两个数据集上均超过 HNSW,表示虽然CAGRA是在GPU上构建的,反序列化到CPU上仍然能够保证图的质量
04
One more thing
Milvus推出的GPU建图+CPU查询混合模式,创新性地实现了GPU技术优势与CPU成本控制的平衡,为数据更新频率低、查询规模大、成本敏感的业务场景提供了最优解。
不过,应对超大规模数据集,业内通常会采用Vamana构建插入式图构建。该方案能够在一次性显存不足的情况下高效构建图索引。核心思想是 "化整为零":将所有节点分成若干批次,每批次只占用有限工作内存,同时保证构建出的图结构高质量。
其构建流程包括三步骤:一是几何增长批次划分(早期小批次建骨架、中期批次提并行、后期大批次补细节);二是贪婪搜索插入节点(从中心点导航筛选近邻并扩展范围);三是反向边更新(保证图对称性与可导航性)。剪枝融合在建图中,通过α-RNG准则实时筛选:若候选邻居v被已选邻居p'覆盖(d(p',v)<α×d(p,v))则剪除,α值调控图稀疏度与精度。GPU加速通过批内并行(同批次节点并行搜索剪枝)和几何增长批次(平衡质量与并行度)实现。
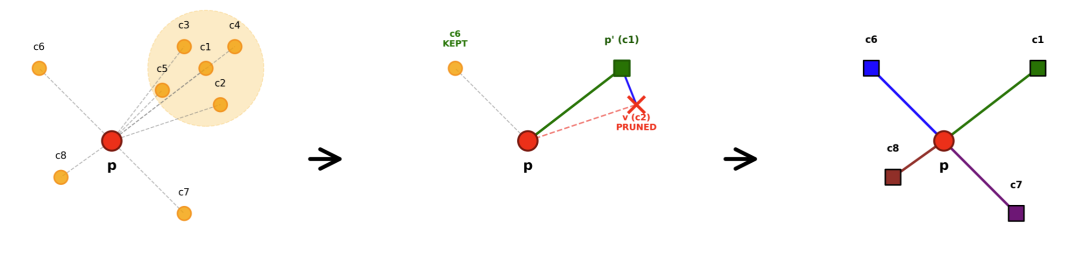
借助这一机制,我们可以很好应对业务数据高速增长的团队海量数据更新、查询困境。目前,该索引Milvus团队已经在快马加鞭的建设中,预计能在2026年上半年与大家见面,对这一功能大家有什么期待与建议,欢迎评论区与我们交流。
作者介绍

陈建霖
Zilliz Senior Software Engineer
阅读推荐
内存涨疯了?AiSAQ让十亿级向量内存成本降低3200 倍| Milvus Week
语义+R-Tree空间索引:Milvus如何帮外卖APP做3公里内美食推荐| Milvus Week
Struct Array 如何让多向量检索返回完整实体?知识库、电商、视频通用|Milvus Week
88.9 倍性能飙升!JSON Shredding 让 JSON 查询告别全表扫描| Milvus Week
写在 Milvus4 万 Star 之际:Zilliz这七年如何走来,又要去往何处?