在 Linux 系统中,进程控制是操作系统核心能力之一,涵盖进程的创建、终止、等待及程序替换等关键操作。在之前的文章我们已经探讨了进程创建的核心函数 fork 及其底层原理,本文将聚焦进程生命周期的另外三个核心环节 ------进程终止、进程等待和进程程序替换,结合底层实现、实用函数及典型场景,带你全面掌握进程控制的精髓。
1. 进程终止
1.1 进程退出的三种场景
进程退出并非只有 "执行完毕" 一种情况,具体可分为三类:
正常终止且结果正确: 程序按预期执行完成,如 main 函数返回 0、调用 exit(0)。
正常终止但结果错误: 程序执行完毕,但逻辑或数据处理有误,如参数错误导致计算结果异常,通常返回非 0 退出码。
**异常终止:**程序执行过程中遭遇不可恢复的错误,被迫中断,如除零错误、非法内存访问、收到 Ctrl+C 信号等。
这里要重点区分第二类和第三类的区别:
第二类其实就类似于我们在程序中写了检查异常的代码,如try和catch,如果try到了特定错误就会跳到对应的catch里好让我们知道对应错误然后进行处理,这种其实就是正常终止但结果错误了,属于"可控的错误",因为它是按照我们的设置跳到了异常里,但没有得到我们想要的正确结果。
第三类就是程序直接发生了我们意料之外的错误,如除零错误导致程序直接崩溃,发生这种异常其实就是我们的第三类异常终止。
1.2 进程退出的核心方法
(1)return 退出(main 函数专属)
return 是最常见的退出方式,但仅在 main 函数中有效 ------ 子函数中的 return 仅退出当前函数,不会终止进程。main 函数的返回值本质是进程的退出码(退出码我们会在下面进行讲解),等同于调用 exit(返回值)。
示例:
cpp
#include <stdio.h>
int main()
{
printf("程序正常执行完毕\n");
return 0; // 等同于 exit(0),退出码为 0
}运行结果:

(2)exit 函数(标准库函数)
exit 是标准 C 库提供的函数,可在程序任意位置调用,用于终止当前进程。其核心特点是退出前会执行一系列清理操作,确保资源有序释放:
执行通过 atexit 或 on_exit 注册的自定义清理函数;
冲刷所有打开的文件流(将缓冲区数据写入文件);
关闭所有打开的文件描述符;
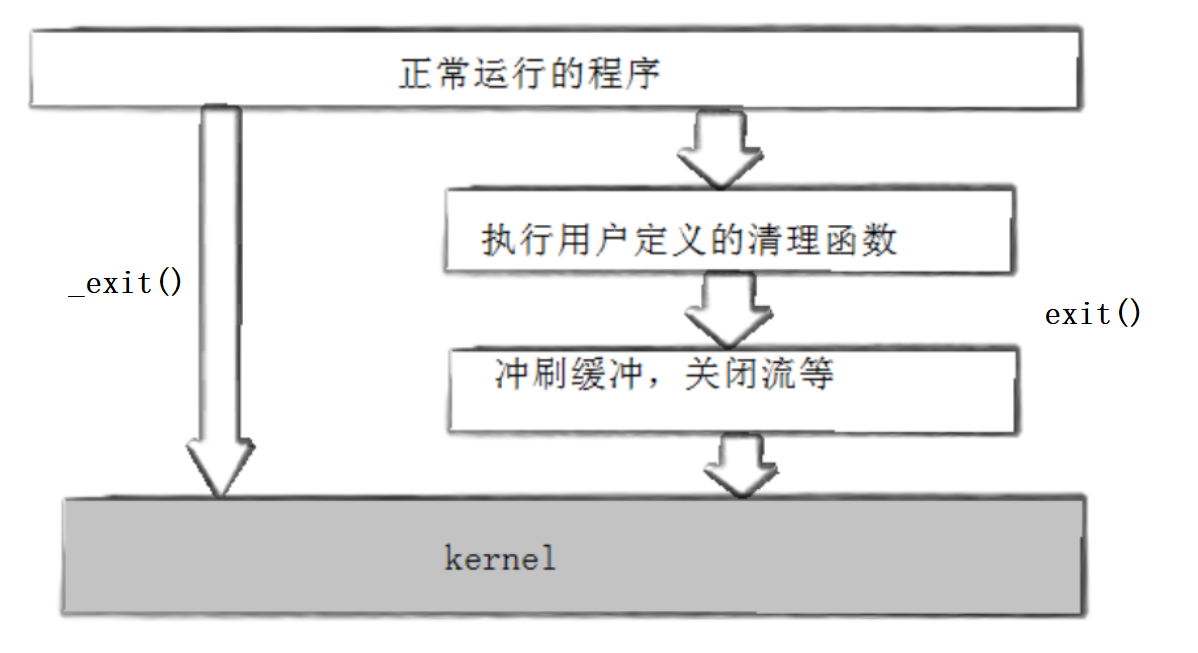
最终调用 _exit 系统调用完成进程终止。
上面的步骤我们可以简单的理解为,exit函数会冲刷缓冲区,然后调用_exit退出进程。这里注意exit是用C语言编写的库函数,它的底层还是通过调用系统调用_exit实现进程终止的,只不过封装多了冲刷缓冲区等功能,而_exit就只有终止进程的功能。
函数原型:
cpp
#include <stdlib.h>
void exit(int status); // status 为退出码,仅低 8 位有效示例:
cpp
#include <stdio.h>
#include <stdlib.h>
int main()
{
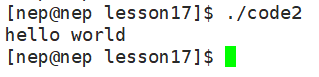
printf("hello world\n");
exit(1);
}
何为冲刷缓冲区呢?我们平常在main函数中想用用printf函数或cout在终端上打印信息,但实际上它们会先将数据存入缓冲区中,如果不冲刷缓冲区它们就不会在终端上打印,那为什么我们平常都能正常打印呢,那是因为我们在使用**return 0;**来结束进程时会默认冲刷缓冲区,从视觉上来看和直接打印无异。
我们可以运行如下代码查看结果:
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello world!");
sleep(3);
return 0;
}运行结果:


我们会发现运行代码后,视觉上会看到先sleep(3)再进行print,实际上这是因为print的数据存入了缓存区,只有进程结束后刷新缓存区才会把它们打印出来。
注:换行符**\n** 和fflush函数均可刷新缓冲区。
(3)_exit 函数(系统调用)
_exit 是 Linux 系统提供的底层系统调用,直接终止进程,不执行任何清理操作(不冲刷缓冲区、不调用自定义清理函数),适用于需要快速退出的场景。
函数原型:
cpp
#include <unistd.h>
void _exit(int status); // status 为退出码,仅低 8 位有效示例:
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello world"); // 无换行符,缓冲区数据未冲刷
_exit(1); // 直接终止进程,缓冲区数据丢失
}运行结果:

exit函数的底层是调用_exit的,它们的区别就是_exit()只负责进程终止,而exit()除了负责进程终止,还会进行缓冲区刷新等操作。
1.3 退出码和退出信号
进程终止时,会通过 "退出码" 或 "退出信号" 告知父进程终止原因,这是进程间通信的重要方式。
(1)退出码(正常终止)
退出码是进程正常终止时返回的状态值,范围为 0~255(超过则取模 256)。其中:
退出码 0 表示程序执行成功;
非 0 退出码表示执行失败,不同值对应不同错误类型(具体含义可自定义或遵循系统约定)。
我们平常在main函数最后会写一个**return 0;**表示进程终结,其实这个0就是我们的退出码,上面讲解的示例exit(1)、_exit(1),它们的1也是我们的退出码,想返回什么返回码我们可以自己定义。
既然是返回退出码,那么是返回到哪儿呢?其实我们的退出码是返回到父进程的,父进程创建子进程一般是想要子进程完成一些任务的,我们的父进程在子进程结束后肯定是想要知道子进程的任务完成状态的,是执行成功还是执行失败了?执行失败又是哪种类型的失败?这时返回码的作用就体现出来了,而我们平常的进程的其实都是由bash创建的子进程,退出码也是返回给了bash。
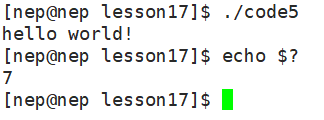
在 Shell 中,可通过 echo $? 查看最近一次进程的退出码:
cpp
#include<stdio.h>
int main()
{
printf("hello world!\n");
return 7;
// exit(6)
// _exit(5)
// 返回啥值,成功执行后echo $?就会打印什么
}
Linux 系统常见退出码约定如下:

可通过strerror 函数获取退出码对应的字符串描述:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
for (int i = 0; i < 200; i++)
{
printf("退出码 %d -> %s\n", i, strerror(i));
}
return 0;
}我们可以发现总共有134个错误码:
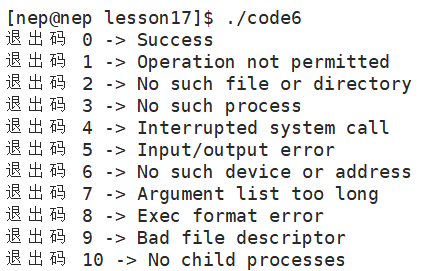

(2)退出信号(异常终止)
当进程异常终止时,会收到系统发送的 "退出信号",而非退出码。常见信号如下:
SIGINT(信号 2):Ctrl+C 触发,强制终止进程;
SIGKILL(信号 9):kill -9 PID 触发,无法被进程捕获,强制终止;
SIGSEGV(信号 11):非法内存访问(如数组越界)触发;
SIGFPE(信号 8):算术错误(如除零)触发。
可通过 kill -l命令查看系统支持的所有信号:

退出码和退出信号有什么区别呢?答案是它们使用的场景不同,退出码应用在进程退出的前两种场景(即正常终止场景),程序正常终止。而退出信号应用于进程退出的第三种场景(即异常终止场景)。
打个比方,我们在考试时一般来说无非分为及格和不及格两个场景,而无论是59分还是60分都是我们自己正常考出来的(退出码),对应前两个场景。而一旦我们在考试中作弊被抓到了,此时不仅成绩会直接作废,我们还会受到惩罚,这时候我们的考试成绩就根本就是个废值了(退出码),只有退出信号才能正确反映我们此时的场景(如除零错误导致程序的崩溃)。
所以综上所述,如果我们发生了异常终止,再看**echo $?**的值就毫无意义了,因为此时进程的退出码就是个废值了,打印什么值都是无意义的。
2. 进程等待
进程等待是父进程的核心操作,指父进程等待子进程终止,回收其资源并获取退出状态。若父进程不等待子进程,子进程终止后会变成 "僵尸进程",占用内核资源导致内存泄漏。
2.1 进程等待的必要性
回收僵尸进程: 子进程终止后,PCB 不会立即释放(需父进程确认),若父进程不处理,子进程会一直处于僵尸状态(Z 状态),占用 PID 和内核资源;
获取子进程退出状态: 父进程需要知道子进程任务完成情况(成功 / 失败、异常原因),以便后续决策;
**保证进程资源有序释放:**父进程通过等待确认子进程完成后,再释放其占用的所有资源,避免资源泄露。
2.2 核心等待函数:wait 与 waitpid
Linux 提供 wait 和 waitpid 两个函数实现进程等待,后者功能更灵活,是实际开发的首选。
(1)wait 函数(简单等待)
wait 函数用于等待任意一个子进程终止,若没有子进程或子进程未终止,父进程会阻塞。
函数原型:
cpp
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);参数 status: 输出型参数,用于存储子进程的退出状态(退出码或退出信号),若不关心可传入 NULL;
**返回值:**成功返回被等待子进程的 PID;失败返回 -1(如无子进程)。
示例:
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == 0)
{
// 子进程:执行 5 秒后退出
printf("我是子进程,PID:%d\n", getpid());
sleep(5);
exit(3); // 退出码为 3
}
else if (pid > 0)
{
// 父进程:等待子进程终止
int status;
pid_t ret = wait(&status);
if (ret > 0)
{
printf("等待子进程 %d 成功\n", ret);
// 判断子进程是否正常退出
if (WIFEXITED(status))
{
printf("子进程正常退出,退出码:%d\n", WEXITSTATUS(status));
}
}
}
return 0;
}
对于WIFEXITED和WEXITSTATUS,我们会在下面进行讲解。
(2)waitpid 函数(灵活等待)
waitpid 支持指定等待的子进程、非阻塞等待等高级功能,是 wait 函数的增强版。
函数原型:
cpp
pid_t waitpid(pid_t pid, int *status, int options);参数详解:
1. pid:指定等待的子进程 PID:
pid = -1:等待任意子进程(与 wait 等效);
pid > 0:等待 PID 等于该值的子进程;
pid = 0:等待同一进程组内的所有子进程;
pid < -1:等待进程组 ID 等于 |pid| 的所有子进程。
**2. status:**输出型参数,存储子进程退出状态(与 wait 一致);
3. options:等待方式选项:
0: 默认值,阻塞等待(子进程未终止时,父进程暂停执行);
**WNOHANG:**非阻塞等待(子进程未终止时,函数立即返回 0,父进程可继续执行其他任务)。
返回值:
成功: 返回被等待子进程的 PID;
非阻塞模式下无已终止子进程: 返回 0;
**失败:**返回 -1(如无子进程、被信号中断)。
(3)解析 status 参数
status 是一个 32 位整型变量,但并非直接存储退出码或信号,而是通过位图(比特位) 分段存储不同信息,仅低 16 位有效,结构如下:
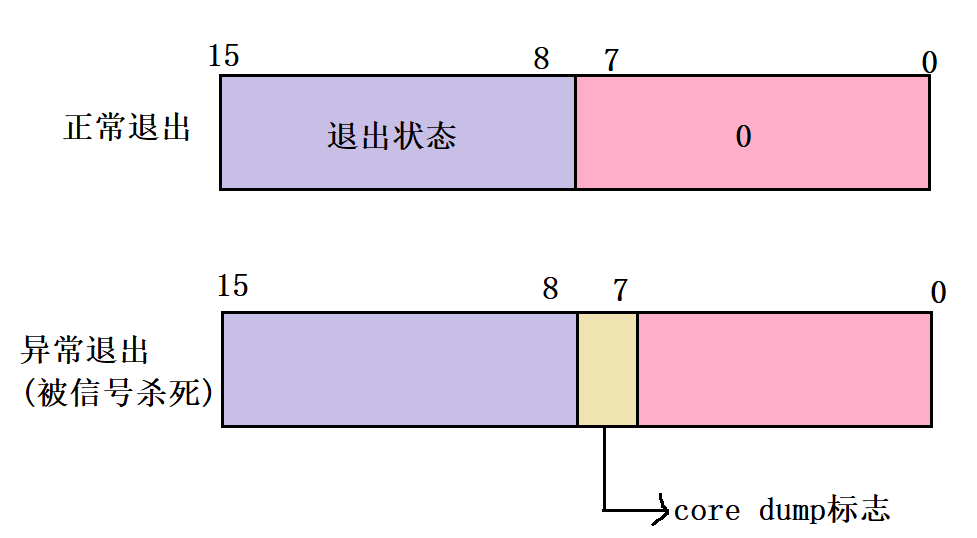
高 8 位(bit 8~15): 子进程的退出码(仅当子进程正常退出时有效);
低 7 位(bit 0~6): 子进程的退出信号(仅当子进程异常终止时有效);
**第 8 位(bit 7):**Core Dump 标志(1 表示进程异常终止时生成核心转储文件)。
在图上我们可以看到,返回到的status值是不可以直接用的,打个比方:
我们正常退出,return 1,这个1在status的低16位中存储如下:00000001 00000000,转化为十进制就是256(2的八次方),如果我们不处理直接用显然是不对的。
两种解析方式:
1. 位运算直接解析:
cpp
int exit_code = (status >> 8) & 0xFF; // 提取退出码(右移 8 位,与 0xFF 保留低 8 位)
int exit_signal = status & 0x7F; // 提取退出信号(与 0x7F 保留低 7 位)
int core_dump = (status >> 7) & 1; // 提取 Core Dump 标志2. 系统提供的宏(推荐):
WIFEXITED(status): 判断子进程是否正常退出(返回非 0 表示正常退出);
WEXITSTATUS(status): 提取子进程的退出码(仅 WIFEXITED 为真时有效);
WIFSIGNALED(status): 判断子进程是否被信号终止(返回非 0 表示异常终止);
**WTERMSIG(status):**提取终止子进程的信号(仅 WIFSIGNALED 为真时有效)。
示例:解析子进程退出状态
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == 0)
{
// 子进程:模拟除零错误(触发 SIGFPE 信号,信号码 8)
int a = 1 / 0;
exit(0);
}
else if (pid > 0)
{
int status;
waitpid(pid, &status, 0);
if (WIFEXITED(status))
{
printf("子进程正常退出,退出码:%d\n", WEXITSTATUS(status));
}
else if (WIFSIGNALED(status))
{
printf("子进程被信号终止,信号码:%d\n", WTERMSIG(status));
}
}
return 0;
}运行结果:

2.3 阻塞等待与非阻塞轮询
根据 waitpid 的 options 参数,进程等待分为两种模式:
(1)阻塞等待(默认模式,options=0)
父进程调用 waitpid 后,若子进程未终止,父进程会进入阻塞状态(暂停执行),直到子进程终止或被信号中断。这种模式简单直接,但父进程在等待期间无法处理其他任务,适用于不需要并发处理的场景。
示例:阻塞等待
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == 0)
{
printf("子进程 %d 执行中...\n", getpid());
sleep(5); // 子进程执行 5 秒
exit(0);
}
else if (pid > 0)
{
printf("父进程等待子进程...\n");
int status;
waitpid(pid, &status, 0); // 阻塞等待
printf("父进程等待结束,子进程退出码:%d\n", WEXITSTATUS(status));
}
return 0;
}运行结果:


(2)非阻塞轮询(options=WNOHANG)
父进程调用 waitpid 后,无论子进程是否终止,函数都会立即返回:
若子进程未终止: 返回 0,父进程可继续执行其他任务;
若子进程已终止: 返回子进程 PID,父进程处理退出状态;
**若出错:**返回 -1。
这种模式下,父进程需要通过循环反复调用 waitpid(即 "轮询"),直到子进程终止,适用于需要并发处理多个任务的场景(如服务器处理多个客户端请求)。
示例:非阻塞轮询
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == 0)
{
printf("子进程 %d 执行中...\n", getpid());
sleep(5); // 子进程执行 5 秒
exit(2);
}
else if (pid > 0)
{
int status;
pid_t ret;
// 非阻塞轮询
while (1)
{
ret = waitpid(pid, &status, WNOHANG);
if (ret == 0)
{
// 子进程未终止,父进程处理其他任务
printf("父进程执行其他任务...\n");
sleep(1);
}
else if (ret == pid)
{
// 子进程已终止,处理退出状态
printf("子进程 %d 终止,退出码:%d\n", ret, WEXITSTATUS(status));
break;
}
else
{
// 等待出错
perror("waitpid error");
break;
}
}
}
return 0;
}运行结果:


3. 进程替换
fork 创建的子进程默认执行与父进程相同的代码(仅代码分支不同),但实际开发中,子进程常需要执行全新的程序(如 Shell 执行 ls、pwd 命令),这就需要通过进程程序替换实现。
3.1 程序替换的核心原理
进程程序替换是通过 exec 系列函数,将磁盘上的可执行文件(如 ls、自定义程序)加载到当前进程的地址空间,覆盖原进程的代码段和数据段,从新程序的入口(main 函数或启动例程)开始执行。
关键特性:
• 替换后,进程的 PID、PCB、虚拟地址空间不变,仅用户空间的代码和数据被替换;
• 替换成功后,原进程的代码不再执行(被新程序覆盖),因此 exec 函数成功时无返回值;
• 替换失败时返回 -1(如文件不存在、权限不足),原进程代码继续执行。
底层实现:
销毁原进程用户空间的代码段、数据段、堆、栈;
读取新程序的 ELF 文件头部,加载代码段、数据段到虚拟地址空间;
更新页表,将虚拟地址映射到新程序的物理内存;
设置程序计数器(PC)为新程序的入口地址,开始执行。
示例:
cpp
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("进程开始...\n");
execl("/usr/bin/ls", "/usr/bin/ls", "-l", NULL);//程序替换
printf("进程结束...\n");
return 0;
}运行结果:
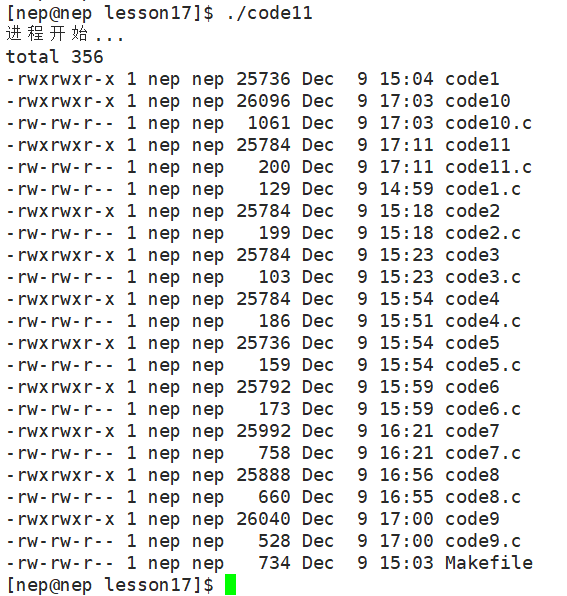
我们可以看到,在输出了**"运行开始...后"** ,我们的进程直接被替换为了execl函数中的进程,然后就运行了ls -l 命令(进程),直到最后我们也没有输出**"进程结束...",**说明在进程替换后,我们整个代码段和数据都被新进程完全覆盖了,替换成功后原进程后续的代码也就不会再执行了。
3.2 exec 函数族
Linux 提供 6 个以 exec 开头的函数(统称 exec 函数族),核心功能一致,仅参数格式和特性不同。函数原型如下:
cpp
#include <unistd.h>
// 1. 列表传参,需指定程序路径,使用当前环境变量
int execl(const char* path, const char* arg, ...);
// 2. 列表传参,自动搜索 PATH,使用当前环境变量
int execlp(const char* file, const char* arg, ...);
// 3. 列表传参,需指定程序路径,自定义环境变量
int execle(const char* path, const char* arg, ..., char* const envp[]);
// 4. 数组传参,需指定程序路径,使用当前环境变量
int execv(const char* path, char* const argv[]);
// 5. 数组传参,自动搜索 PATH,使用当前环境变量
int execvp(const char* file, char* const argv[]);
// 6. 数组传参,需指定程序路径,自定义环境变量
int execve(const char* path, char* const argv[], char* const envp[]);注:这个 ... 其实就是我们C++学习的可变参数,表示这个位置可以传入任意数量、同类型的参数,直到遇到一个 NULL 作为参数结束的标志 ------ 这是 execl 这类函数识别参数边界的关键。
函数命名规则(快速记忆)
l(list): 参数以列表形式传入,最后必须以 NULL 结尾;
v(vector): 参数以字符串数组形式传入,数组最后必须以 NULL 结尾;
p(path): 自动从 PATH 环境变量中搜索程序,无需指定完整路径;
**e(env):**自定义环境变量,需传入环境变量数组(最后以 NULL 结尾)。
常用函数对比表:
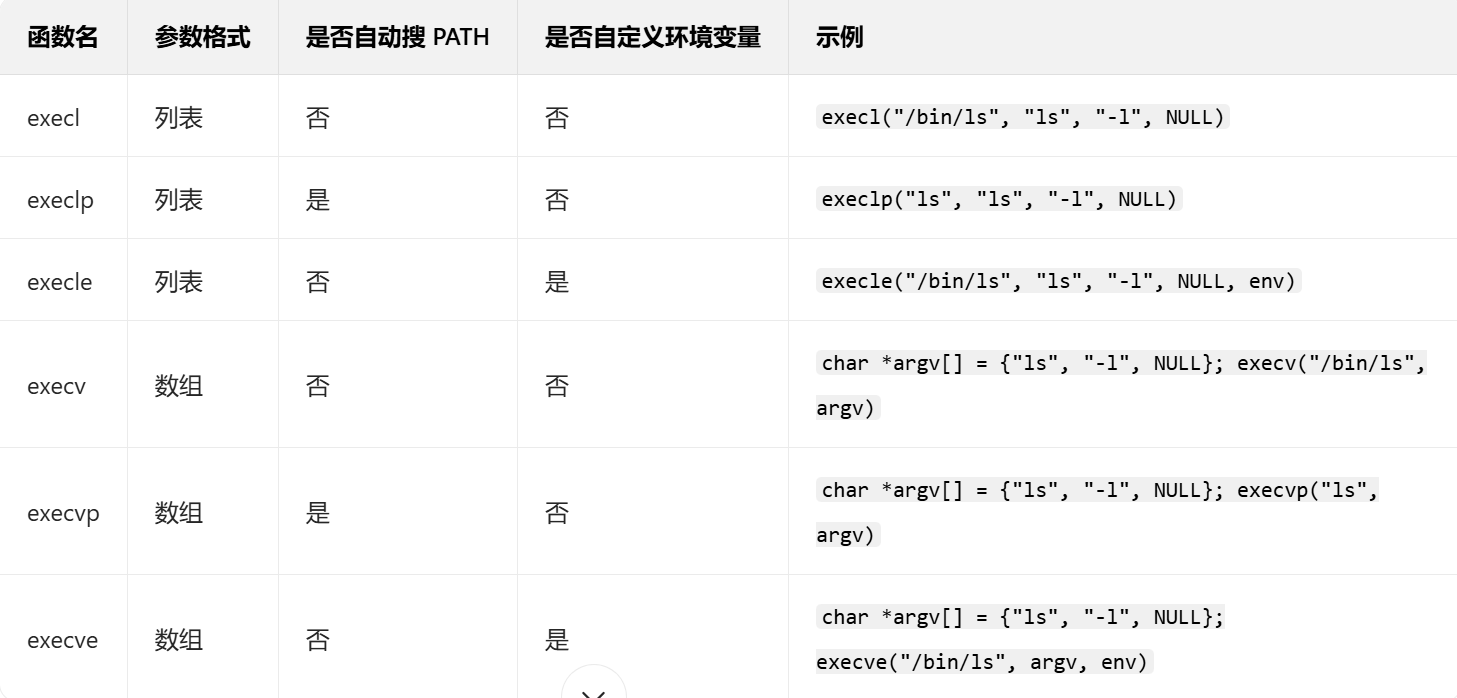
关键注意事项
无论列表传参还是数组传参,第一个参数(arg 或 argv0)必须是程序名(与实际执行的程序一致,可自定义但建议保持一致);
列表传参必须以 NULL 结尾,数组传参必须以 NULL 终止(告知函数参数结束);
仅 execve 是系统调用,其他 5 个函数均为库函数,最终调用 execve 实现。
场景 1:Shell 执行命令(最常用)
Shell 的核心工作流程就是 "创建子进程 + 程序替换":
Shell 读取用户输入的命令(如 ls -l);
fork 创建子进程;
子进程调用 execvp 替换为 ls 程序;
父进程 wait 等待子进程终止,打印结果。
示例:模拟 Shell 执行 ls -l
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == 0)
{
// 子进程:替换为 ls -l
char* argv[] = { "ls", "-l", NULL };
execvp("ls", argv); // 自动搜索 PATH,无需完整路径
perror("execvp error"); // 替换失败时执行
exit(1);
}
else if (pid > 0)
{
// 父进程:等待子进程
wait(NULL);
}
return 0;
}
场景 2:子进程执行自定义程序
父进程创建子进程后,子进程替换为自定义的可执行文件(如 test 程序)。
示例:子进程替换为自定义程序
cpp
// 自定义程序 test.c
#include <stdio.h>
int main(int argc, char* argv[])
{
printf("自定义程序执行,参数个数:%d\n", argc);
for (int i = 0; i < argc; i++)
{
printf("argv[%d] = %s\n", i, argv[i]);
}
return 0;
}
// 父进程程序 main.c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == 0)
{
// 子进程:替换为 ./test 程序,传入参数 "hello" "world"
execl("./test", "test", "hello", "world", NULL);
perror("execl error");
exit(1);
}
else if (pid > 0)
{
wait(NULL);
}
return 0;
}运行结果:

注意:如果这里是execv,带v的必须直接传数组:
cpp
char* argv[] = { "test", "hello", "world", NULL };
execv("./test", argv); // 直接传数组,不用再写一个个参数场景 3:自定义环境变量
通过 execle 或 execve 函数,子进程可使用自定义的环境变量,而非继承父进程的环境变量。
示例:自定义环境变量
cpp
// code14.c - 父进程:传递自定义环境变量并执行打印程序
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
pid_t pid = fork();
if (pid == 0)
{
// 1. 定义自定义环境变量数组(结尾必须是NULL)
char* envp[] = {
"MY_ENV1=hello",
"MY_ENV2=world",
"PATH=/bin",
"USER=test_user",
NULL
};
// 2. 用execle传递envp,并执行print_env_array程序
// 注意:第一个参数是print_env_array的编译后路径(当前目录下)
execle("./print_env_array", "print_env_array", NULL, envp);
// 如果execle执行失败,才会执行下面的代码
perror("execle 执行失败");
exit(1);
}
else if (pid > 0)
{
// 父进程等待子进程执行完成
wait(NULL);
printf("\n父进程:子进程打印环境变量完成\n");
}
return 0;
}
// print_env_array.c
#include <stdio.h>
int main(int argc, char* argv[], char* envp[])
{
printf("===== 整个自定义环境变量数组内容 =====\n");
// 遍历通过参数传入的 envp 数组(结尾是NULL)
for (int i = 0; envp[i] != NULL; i++)
{
printf("环境变量[%d]:%s\n", i, envp[i]);
}
printf("======================================\n");
return 0;
}运行结果:
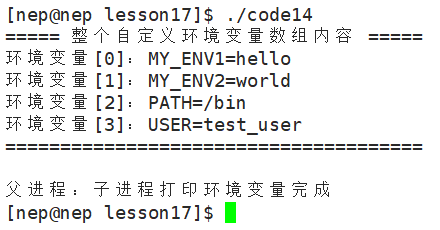
这里我们注意,如果不传自己的环境变量,会默认传从父进程bash传下来的环境变量,也即environ,而如果传自己的环境变量就会把它直接覆盖。
如果我们想在保有原本环境变量的基础上追加我们自己的自定义环境变量,可以在父进程中通过全局的 environ 拿到父进程的所有环境变量,然后将我们的自定义环境变量与它合并,传给子进程时直接传修改过的就好了,这样我们就能追加式的打印所有环境变量了。
其实这些进程替换不止能替换同语言的,也可以替换异语言的,进程替换的核心是加载 "可执行文件" 到进程地址空间,而和编程语言无关 ------ 只要目标程序是系统能识别的可执行格式(比如 Python 的.py文件通过解释器执行、Java 的.class通过 JVM 执行),不管原进程用什么语言写,都能替换。
比如 C++ 父进程替换 Python 子进程的实际逻辑是:
C++ 父进程fork创建子进程;
子进程调用execl("/usr/bin/python3", "python3", "test.py", NULL);
系统会加载 Python 解释器,再由解释器执行test.py------ 本质是 "替换成解释器进程,再由解释器运行 Python 代码",但对外表现就是 "C++ 进程替换成了 Python 进程"。
4. 总结
进程控制是 Linux 系统编程的核心,本文聚焦的进程终止、进程等待和程序替换,与上一篇的进程创建共同构成了进程生命周期的完整闭环:
进程终止: 通过 return、exit、_exit 实现,核心是释放资源并返回退出状态;
进程等待: 通过 wait/waitpid 实现,核心是回收僵尸进程、获取退出状态,支持阻塞和非阻塞两种模式;
**程序替换:**通过 exec 函数族实现,核心是让进程执行全新程序,是 Shell、服务器等程序的基础。
掌握这些知识点后,你可以轻松实现诸如简易 Shell、多进程服务器等复杂程序,深入理解 Linux 系统的进程管理机制。
结语
好好学习,天天向上!有任何问题请指正,谢谢观看!