**🔍**本文提出新型YOLO框架,显著提升航拍图像小目标检测精度与效率。
核心贡献为:
-
创新架构:新增高分辨率检测头,专门强化小目标细微特征捕捉。
-
模块集成:引入CBAM注意力机制以聚焦关键信息,采用Involution模块增强上下文建模。
-
性能突破:在VisDrone2019数据集上将mAP从基准的35.5提升至61.2,优于主流对比方法,实现了精度与速度的更好平衡。

博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
-
YOLO算法结构性创新 :于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块 ,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
-
技术生态建设与知识传播 :独立运营 "计算机视觉大作战" 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
-
荣获腾讯云年度影响力作者 与创作之星奖项,内容质量与专业性获行业权威平台认证。
-
全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
-
具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 "让每一行代码都有温度" 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原创自研系列, 25年计算机视觉顶会创新点
应用系列篇:
23、24年最火系列,加入24年改进点内涵100+优化改进篇,涨点小能手,助力科研,好评率极高
原理介绍

论文: https://arxiv.org/pdf/2512.07379
摘要: 本文研究并开发了大规模航空图像中小目标物体的检测方法。当前航空图像小目标检测常采用图像裁剪及检测网络架构调整策略,主要包括滑动窗口裁剪技术和架构增强方法,如采用更高分辨率特征图与注意力机制等。随着航空影像在各关键领域及工业应用中日益重要,构建稳健的小目标检测框架显得尤为迫切。为应对这一需求,本文以基础SW-YOLO方法为起点,通过优化滑动窗口的裁剪尺寸与重叠区域提升小目标检测的速度与精度,并进一步进行架构改进。我们提出一种新型模型,对基础架构进行多维度改造:在颈部网络引入先进特征提取模块以增强特征图表达能力,在骨干网络集成CBAM注意力机制以保留空间与通道信息,并设计新型检测头以提升小目标识别精度。最后,我们将所提方法与当前处理大规模图像的主流框架SAHI及同样基于图像裁剪的CZDet进行对比,实现了显著的精度提升。在VisDrone2019数据集上,本文模型较基线YOLOv5L检测器取得突破性进展:最终模型将mAP_0.5:0.95精度从YOLOv5L的基准值35.5提升至61.2。值得关注的是,在该数据集上另一经典方法CZDet的精度为58.36。本研究成果实现了检测精度从35.5至61.2的跨越式提升,具有显著进步意义。
1 引言
目标检测在人工智能研究中扮演着关键角色,尤其是在机器视觉领域。其核心任务是在给定场景中识别所有物体,并为每个物体绘制一个边界框------即一个能包围物体所有部分,同时最大限度减少无关背景包含在内的最优矩形框。多年来,得益于数据可用性的快速增长、计算能力的提升以及更先进AI算法的发展,该领域已取得显著进步。
目标检测在工业自动化、医学影像、军事监控和安全系统等多个领域有着广泛应用。其突出用途包括身份识别、辅助视障人士进行物体识别以及实现自动驾驶。尽管最新算法(如最新版本的YOLO和基于Transformer的检测器)取得了令人瞩目的成果,但它们在航空影像上的表现,无论是效率还是准确性,都仍不理想。
航空影像带来了一些独特的挑战,这主要源于大尺度图像中物体分布不均且尺寸较小。这些挑战影响了目标检测算法在训练和推理阶段的性能。具体而言,在大尺度航空图像中检测小目标,由于需要将图像调整尺寸以输入目标检测网络而变得复杂。这种尺寸调整通常导致图像显著缩小,进而使得小目标在视觉上变得更小。其结果是特征图的有效性降低,对检测精度产生负面影响。
此外,航空影像还存在其他复杂性,例如密集排列且高度重叠的小物体、图像内物体尺度的多样性以及物体样本的不平衡性。这些复杂性进一步加剧了在航空影像中有效检测物体所面临的挑战。根据1提供的更为传统的定义,尺寸小于32×32像素的物体被归类为小物体,与输入图像的大小无关。
基于上述考虑,本研究工作的总结归纳如下:
-
评估SAHI2的参数并针对所研究数据集进行性能优化。在分析各参数结果后,确定了适用于本研究数据集的SAHI最优设置。
-
将CZDet3方法作为基线方法进行评估,并检验了在训练和推理阶段应用超分辨率技术的影响。
-
最后,对SW-YOLO4基础模型进行了分析,并对其检测头、颈部网络和骨干网络组件进行了改进。这些改进使本研究提出的基础模型和最终模型的准确性均得到了提升。
本文首先全面回顾了前人工作,总结了针对本研究所识别挑战(小目标检测和大尺度图像分析)的现有方法。随后,转向对SAHI参数优化的深入探讨。文中亦分析了改进CZDet框架的努力。此外,还详细、逐步地阐述了对SW_YOLO所做的增强。最后,报告并比较了所研究方法的准确性与速度,展示了应用于VisDrone数据集的创新成果。
2 相关研究
根据所进行的调查,针对本研究的两大主要挑战------小目标尺寸和大尺度图像------的解决方案可归纳如下。尽管本研究最初分别审视了应对各挑战的解决方案,但最终提出的框架和方法受到整合解决这两个挑战的方案的启发。
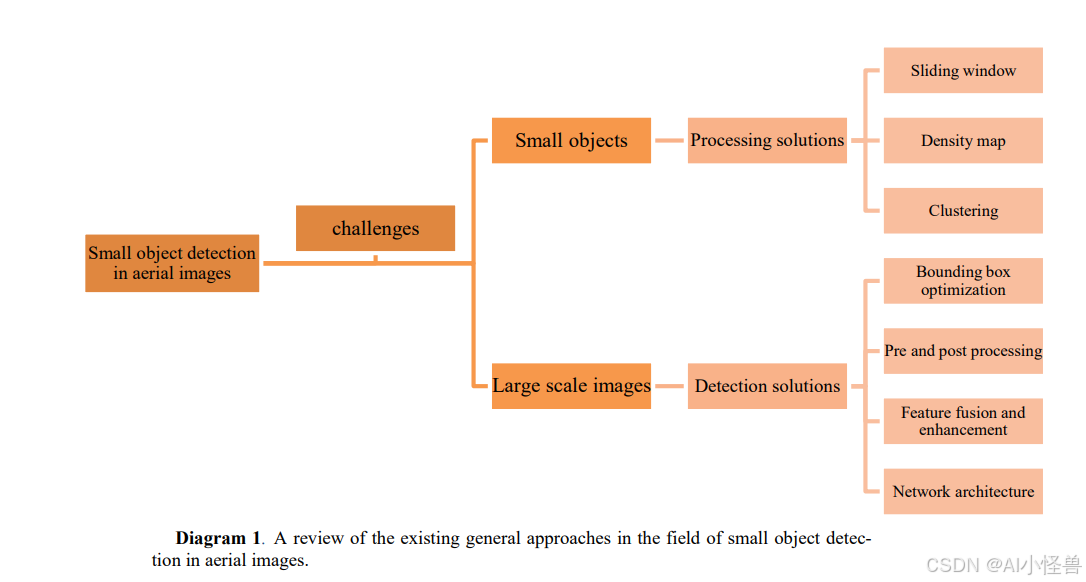
2.1 小目标检测
小目标检测的解决方案可分为三大类:网络架构、预处理与后处理方法以及边界框优化技术。本节将回顾在这些领域进行的研究,以评估其在应对小目标检测挑战方面的有效性。
网络架构。 多尺度目标检测方法主要分为四类:图像金字塔、预测金字塔、集成特征和特征金字塔5。
-
图像金字塔:使用不同尺度的图像作为网络的输入进行目标检测和识别。
-
预测金字塔:利用不同尺度的特征图进行预测。
-
集成特征:基于通过融合多尺度特征图获得的一个特征图进行预测。
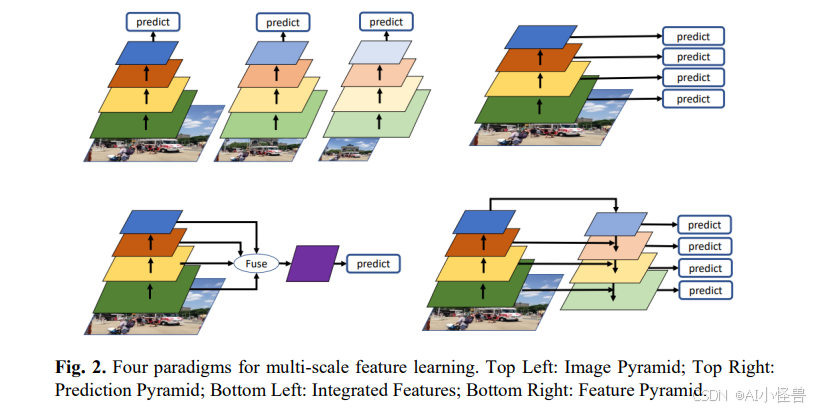
多尺度检测的早期改进之一是YOLOv36引入的预测金字塔,以增强不同尺度的检测能力。TridentNet7进一步发展了这一概念,采用多分支检测方法,结合了图像和特征金字塔。TridentNet不依赖多张输入图像,而是利用并行分支来生成不同尺度的特征图,从而提升了检测性能。
一些研究探索了修改网络架构以增强小目标检测。在8中,引入了一种新颖的检测头来生成更高分辨率的特征图,同时在骨干网络末端集成了一个注意力机制。这种方法在保留关键空间信息的同时减少了计算开销。此外,还提出了一种新的损失函数以提高检测精度。类似地,在9中,探索了修改YOLO架构的方法,用基于Transformer的检测头(Transformer Prediction Head,TPH)替代了传统的四个检测头。这种自注意力机制提升了预测精度,同时采用了卷积块注意力模块(CBAM)来强调密集场景中的关键区域。该研究还利用数据增强、多尺度评估和模型集成来进一步提高检测性能。下图展示的TPH-YOLOv5架构增强了对VisDrone2021数据集的微小目标检测能力。
尽管增加检测头有优势,但其计算和内存开销仍是一个挑战。为解决这一问题,TPH-YOLOv5++ 11引入了CATrans模块,作为多检测头的替代方案,该模块在保持计算效率的同时保留了高层特征信息。同样,在HIC-YOLO框架8中,提出了重新设计的检测头,结合骨干网络中的CBAM模块,以增强对小目标的检测精度。另一项研究12对YOLOv5s进行了结构调整,将颈部网络中的PANet13替换为BiFPN13,并提出了一种专为小目标检测设计的损失函数。此外,在14中,通过将瓶颈块集成到骨干网络中来提升检测精度,从而实现了从浅层更好地提取特征。该研究还引入了重新设计的检测头以及其他架构优化,以进一步增强小目标检测。
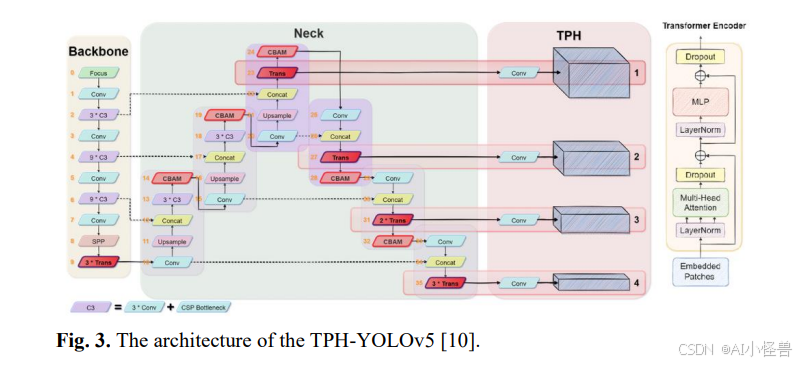
这些方法共同突显了目标检测领域的持续进展,特别是通过架构修改、注意力机制和优化策略来提升小目标识别能力。
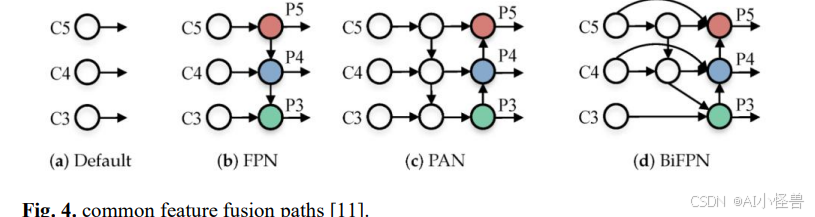
特征融合与增强。 在改善小目标检测特征提取方面的一项关键进展是特征融合网络的使用,例如FPN15。FPN提高了特征图的质量,通常用作许多检测架构中的颈部网络组件。FPN的增强版本,如PAFPN13、NasFPN16和ImFPN17,则专注于进一步改进特征融合。
在18中,引入了一种新颖的高分辨率(HR)块以实现有效的特征融合。在该块中,每一层应用不同核大小的卷积操作,生成结合了强语义信息和不同尺度精细细节的特征图。这些特征图随后被融合以增强小目标检测。此外,19提出了一种专门用于航空影像中小目标检测的方法,旨在增加特征图浅层的语义信息。
Gold-YOLO20利用聚集-分发机制,通过融合多尺度特征图来提高精度。该机制从所有主层级聚集全局信息,将其组合后分发回各个层级,以改进检测。其他研究,如PPYOLO21和PPYOLOE22,则侧重于通过修改颈部网络组件和优化特征图融合策略来提高精度。
下图说明了用于小目标检测的各种特征提取方法之间的差异。该图清晰地展示了所提出的技术,包括FPN、PAFPN等特征融合网络,突出显示了它们在提高检测精度方面的独特方法和有效性。
2.2 大规模图像处理
已经提出了多种处理大规模图像并改进小目标检测的方法,包括滑动窗口法、密度图法和聚类法。
滑动窗口。 滑动窗口法将图像分割成重叠的切片,然后由目标检测网络处理。将所有切片的结果合并以产生最终的检测输出。虽然这种方法提高了精度,但显著增加了计算时间,使其不太适合实时应用。SAHI框架23是该领域一项稳健且有效的工作,主要关注滑动窗口技术,该技术可在训练和推理阶段使用。此外,研究47提出了一个框架,与现有方法相比,优化了计算成本并减少了推理时间。在该研究中,切片尺寸与输入图像大小相关联,使切片数据的模型参数能与主数据集保持一致的比率。已经开发了几种基于分块的方法来增强目标检测,特别是在具有挑战性的场景中的小目标检测。例如,EdgeDuet框架24利用一系列关键步骤,包括瓦片级并行处理,通过解压缩不含小目标的块并通过重叠分块优化检测,从而更高效地处理视频帧。此外,另一项研究25专注于使用高分辨率图像从微型飞行器检测行人和车辆,采用一种在训练和推理阶段都能提高精度的分块方法。该方法有效减少了细节损失,同时确保模型接收固定尺寸的输入,在Nvidia Jetson TX1和TX2等平台上,配合VisDrone2018数据集,展现了显著的性能提升。这些技术反映了目标检测领域旨在克服传统处理方法局限性的持续创新。
密度图。 该方法生成密度图以识别图像中物体高度集中的区域。切片基于这些密度区域确定,并对每个切片执行目标检测。与滑动窗口法相比,密度图方法降低了计算成本,同时仍能实现有效的目标检测。26中引入的对象激活网络使用图像切片输出对象激活图,仅处理那些对象密度高于特定阈值的切片,以优化计算效率。
聚类。 另一种检测大规模图像中小目标的方法是聚类。3的一项研究提出了一种基于聚类的方法来识别图像中的密集区域,称为"密集区域切片"。这些区域被单独处理以提高小目标检测精度。此外,像ScaleNet和PP这样的模块确保了跨物体尺度的一致性。GLSAN框架27被开发用于增强密集区域中的小目标检测。它包括三个主要模块:用于通用和局部目标检测的GLDN、使用K-means聚类密集区域的SARSA,以及在将区域传递给检测网络之前提升SARSA识别区域质量的LSRN。
一个值得注意的基于聚类的方法是28中引入的聚类检测(ClusDet)网络,它解决了在航空图像中检测小、稀疏且非均匀分布物体的挑战。ClusDet将物体聚类和检测统一到一个端到端的框架中。它包含一个识别物体聚类区域的聚类提议子网络(CPNet)、一个估计这些区域物体尺度的尺度估计子网络(ScaleNet)以及一个专用的检测网络(DetecNet)。该方法通过仅关注预测的聚类区域,显著减少了最终目标检测所需的图像片段数量,从而优化了计算效率。此外,与基于单物体的方法相比,ClusDet中基于聚类的尺度估计提高了小目标检测的精度,并且DetecNet利用这些聚类区域内的上下文信息来提升整体检测精度。
为进一步完善聚类目标检测,29中的一项研究提出了一种改进的聚类芯片选择方案。该方法通过更有效地识别"聚类芯片"(密集物体区域)并对它们应用细粒度检测器,从而提高了航空图像中的检测性能。
在下一章中,将介绍本研究的基本概念,并对用于比较的经典实现方法进行全面解释。此外,还将讨论SAHI参数的优化,以评估其相对于最终结果的性能。
3 方法论
3.1 SAHI参数优化
切片辅助超推理(SAHI)框架旨在通过两个主要流程来改进大规模图像中的小目标检测:模型训练和推理。
-
模型训练:在训练过程中,图像被分割成具有特定尺寸和重叠区域的切片,以更好地利用预训练模型。这种方法有效增加了训练图像的数量,从而提高了模型的准确性。
-
推理:在推理阶段,原始图像同样被分割成切片,并与完整的原始图像一同输入到训练好的网络中进行处理。为了消除冗余的预测框,应用了多种合并方法,包括非极大值抑制(NMS)、局部软非极大值抑制(LS-NMS)、非极大值合并(NMM)和贪婪非极大值合并(Greedy NMM)。这些方法基于置信度分数和重叠度来比较边界框,有助于确保目标检测的准确性。
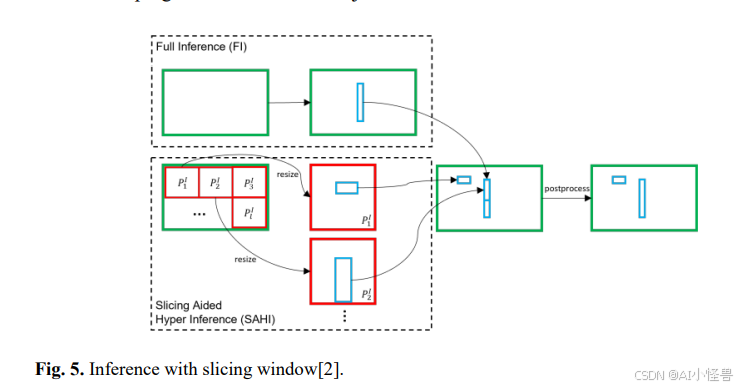
此外,在后处理阶段还利用了交并比(IoU)和自交集比(IoS)度量标准,以提高测试阶段的适应性。
3.2 CZDet改进
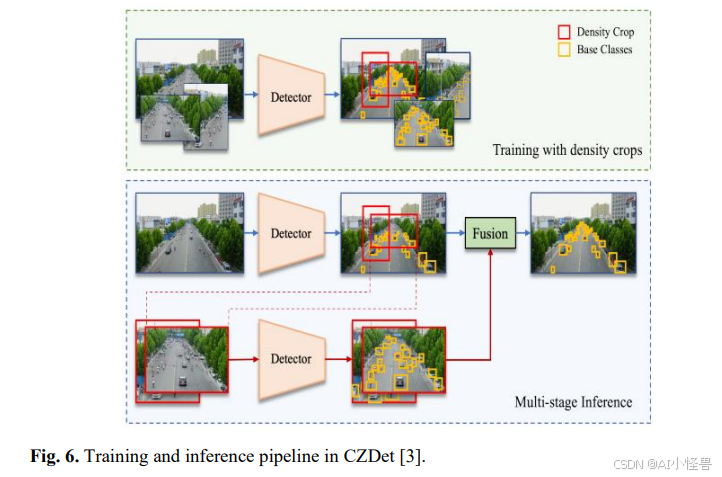
现有的针对杂乱区域目标检测的方法通常依赖于分割密集区域或聚类技术,由于需要额外的可训练模块或处理单元,这些方法可能非常耗时。为了解决这个问题,CZDet3提出了一种解决方案,即由检测网络本身识别杂乱区域,从而避免了额外的模块。随后,这些被识别出的区域会以更高的精度进行重新评估,从而提升了较小目标的检测精度。训练和推理流程在图6中完整展示。
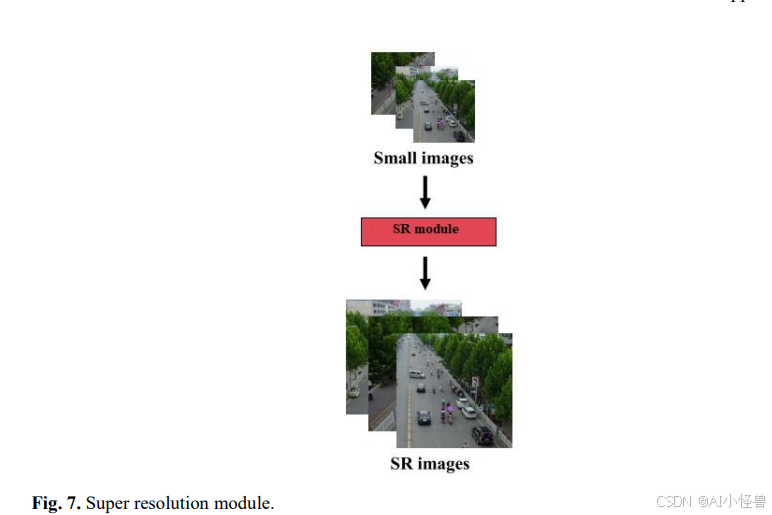
分析发现,被标记为"cut"类别的输出图像(无论是在数据集中包含的还是在推理过程中重新处理的)其尺寸通常比原始图像显著缩小。检测网络通常在平均尺寸为800×800像素的图像上进行训练,而"cut"图像可能只有约200×250像素。因此,这些图像需要进行尺寸调整以满足网络的输入要求。传统的尺寸调整(通常通过插值完成)可能会降低图像质量,导致图像模糊和关键细节丢失。为了应对这一问题,最初的解决方案涉及引入超分辨率网络架构来提升图像质量。
超分辨率网络旨在从低分辨率图像生成高分辨率图像。将一个SR模块集成到网络架构中,以支持训练和测试两个阶段:
-
训练阶段:"cut"图像通过SR模块处理以生成更高质量的版本,然后用于训练网络。然而,这种增强会显著延长训练时间。
-
测试阶段:在测试期间,被检测网络预测为"cut"类别的图像在重新进入检测网络之前会经过SR处理。为了优化这一过程,使用了在目标数据集上专门训练的SR模型,将低分辨率图像转换为高分辨率版本。这种方法通过在训练和测试阶段提高图像分辨率,从而提升了较小目标的检测精度。
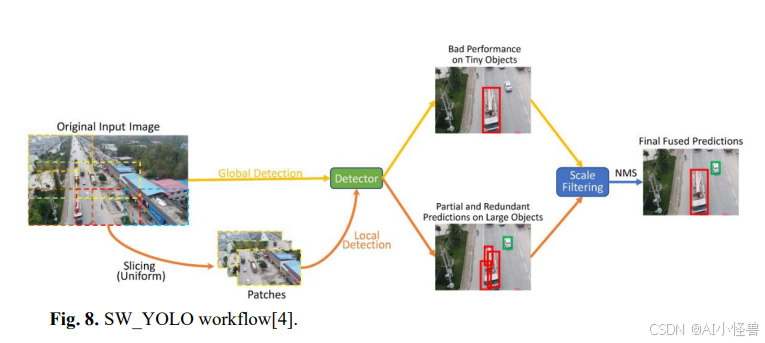
3.3 SW-YOLO增强
SW_YOLO4提出了一种高效的无人机目标检测框架,旨在应对密集集群、目标重叠和尺度多样性等挑战。其方法采用统一的切片窗口法,将输入图像分割成较小的图块以检测小目标,同时保持效率。该框架包括对完整图像的全局检测和对子图块的局部检测,以处理不同尺度的目标。一个尺度过滤机制将目标分配给适当的检测任务以保持尺度不变性。此外,该方法使用随机锚点裁剪进行数据增强,用多样化的场景丰富训练数据。通过两种定制的增强方法模拟具有密集目标集群的真实世界场景,尤其有助于检测稀有类别。综合实验表明,与其他方法相比,这种方法以更低的计算成本显著提高了检测性能。SW_YOLO的工作流程如图所示。该框架作为评估我们提出方法的基线。
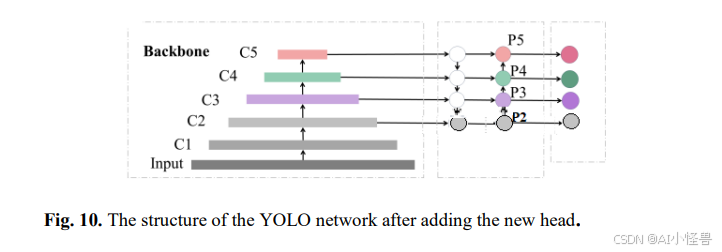
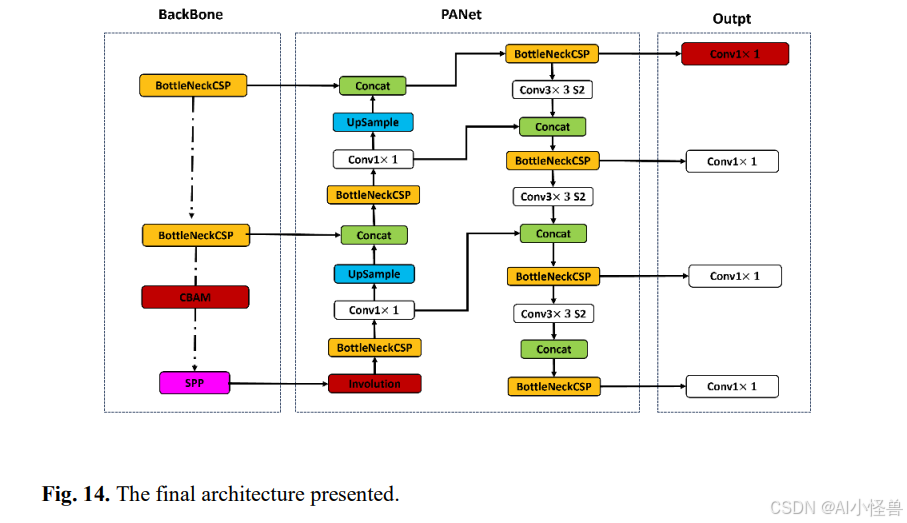
本研究对YOLO架构进行了多项增强,专门针对小目标检测进行了优化。受8的启发,这些旨在提升精度和计算效率的改进在三个主要层面实施:为小目标增加新的检测头、集成卷积块注意力模块(CBAM)以及利用involution块进行高级特征提取。YOLOv5的基础架构如图9所示。这些架构修改被整合到YOLOv5基础模型中,最终的增强型YOLOv5架构如图14所示。
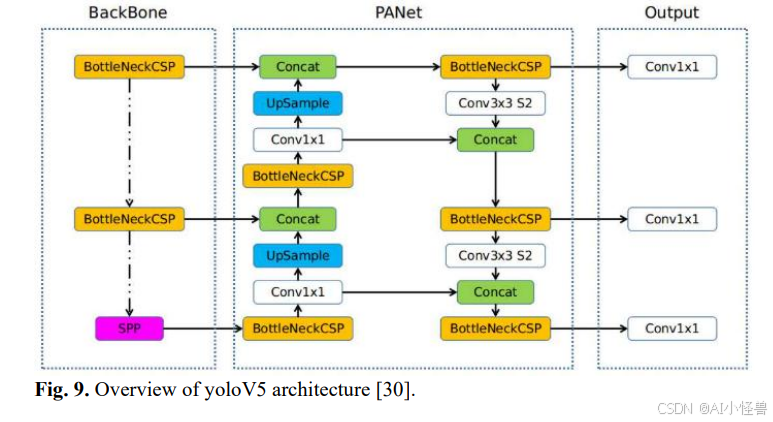
1. 为小目标增加新的检测头
研究表明,提高特征图的分辨率可以增强小目标检测的准确性。为了利用这一点,除了YOLO中通常用于检测小、中、大目标的典型特征图(P3、P4和P5)之外,本框架还包含了一个额外的高分辨率...
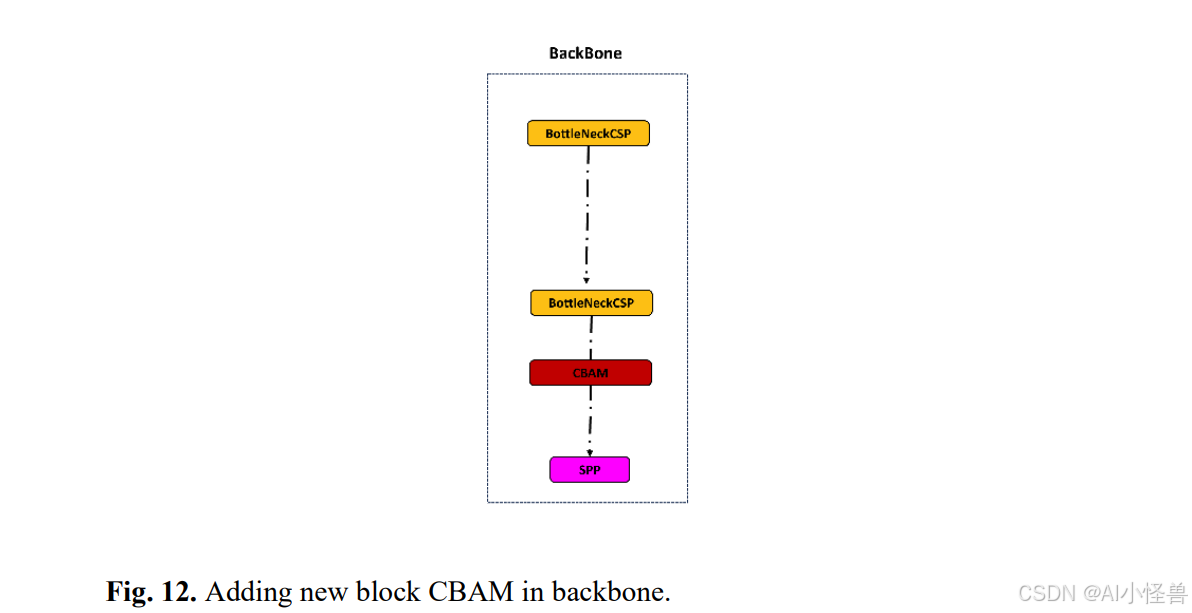
2. CBAM注意力机制
为了优先处理关键的空间和通道信息,CBAM模块被集成在骨干网络的末端。虽然传统方法通常将CBAM放在网络的颈部,但将其置于骨干网络中,由于该阶段的特征图尺寸较小(20×20),可以最大限度地减少计算开销。CBAM由两个注意力块组成:通道注意力模块(CAM)和空间注意力模块(SAM),各自针对特征优化的不同方面。
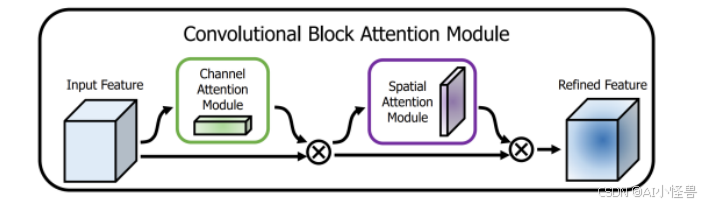
-
CAM:该模块通过同时使用平均池化和最大池化聚合空间信息,然后通过一个轻量级神经网络生成通道注意力图。该注意力图对每个通道应用独特的权重,从而优化通道特定特征的相关性。
-
SAM :在CAM之后,SAM强调关键的空间位置。它利用池化操作来降维,并使用一个7×7的卷积层来创建空间注意力图,为图像中的关键区域分配更大的权重。
新添加的块已整合到图中并以红色高亮显示。
3. Involution块
Involution块取代了传统的卷积层,以优化空间相关的特征提取。与固定的卷积滤波器(空间无关)不同,involution使用动态的、空间特定的滤波器,为图像中的每个位置应用定制的滤波器。这使得网络能够更好地保留位置特定的信息。
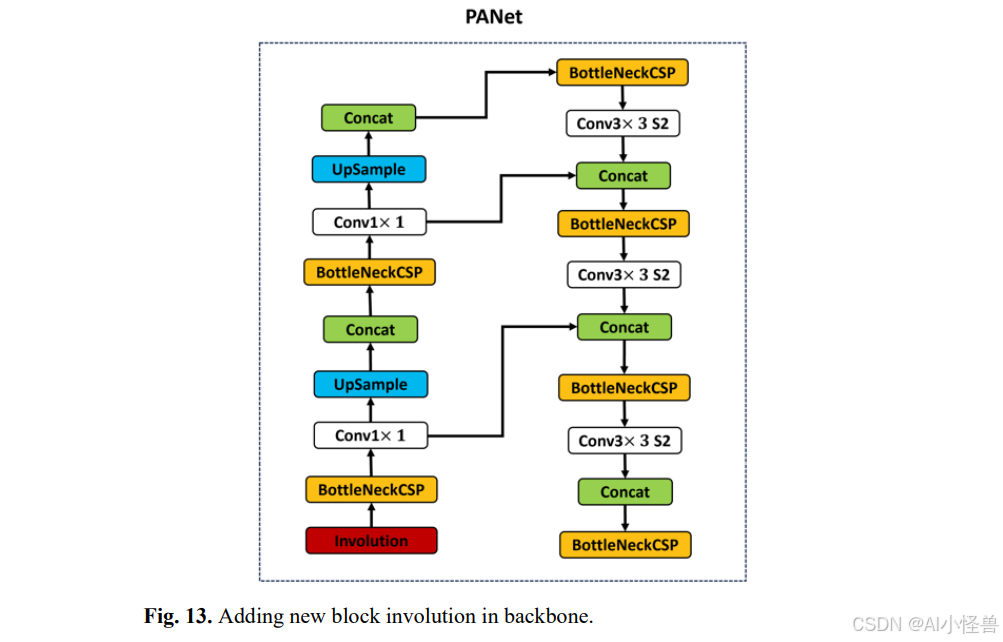
在involution块内部,每个像素生成一个唯一的核,该核统一应用于所有通道。然后,该核通过卷积与输入特征图结合。最后,一个求和聚合步骤整合了相邻像素上提取的特征,保留了空间上下文并提高了检测精度。
总体而言,这些策略显著提升了YOLOv5的小目标检测能力。通过减少计算负载和提高检测精度,这些增强使YOLOv5更适合对速度和可靠性都有高要求的工业应用。
新添加的块已整合到图中并以红色高亮显示。
在下一章中,将介绍所使用的数据集,然后展示每个提出想法的结果,并与先前的方法进行比较。
4 实验结果
4.1 数据集
在本研究中,选择VisDrone-Det2019数据集用于目标检测任务的训练与评估。作为更广泛的VisDrone挑战的一个子集,该数据集专门针对静态图像中的目标检测,包含6,471张训练图像,分辨率从1920×1080到3840×2160不等,代表了10个不同的目标类别。值得注意的是,该数据集中约有31.25%的目标被归类为"小"目标(> 32²像素),这突显了在高分辨率图像中检测较小目标的挑战性。

4.2 结果
本节阐述了基于基准目标检测模型训练所得的发现,这些训练旨在为后续实验建立坚实的基础。模型首先在MS-COCO数据集上进行了300轮的预训练,批次大小为32。模型性能评估采用COCO指标,特别关注不同交并比阈值下的平均精度,从而确保了精度度量的一致性。基于YOLO的模型以其单阶段架构为特点,与两阶段模型(如Faster R-CNN,需要一个额外的区域建议生成阶段)相比,展现出明显更优的推理速度。在各种YOLO架构中,YOLOv5L因其稳健的性能被确定为主要基准模型,在IoU阈值为0.5时取得了47.3%的AP,从而在精度和处理速度之间展现了值得称赞的平衡。
为进一步提升小目标检测的精度,采用了SAHI方法。该方法侧重于对图像进行分割以提高检测性能,特别是针对在整帧评估中常常漏检的小目标。评估了SAHI框架下的多种后处理技术,包括调整重叠率和裁剪尺寸。最优策略将整图预测与图像切片预测相结合,显著增强了模型检测小目标的能力,同时在所有尺寸目标上保持了65.1%的整体精度。然而,这种方法引入了一个权衡取舍,因为同时处理完整图像和裁剪图像的复杂性导致了推理速度的显著降低,从30 FPS降至18 FPS。
通过两种主要策略探索了进一步的改进,目标在于优化基准模型。第一种策略涉及使用ImageNet权重预训练CZDet模型,这带来了精度的显著提升,在验证集上达到了50.5%的AP。然而,在训练期间引入超分辨率模块却意外导致了精度下降,AP降至45.2%,同时训练时间增加。推测这种下降源于图像(特别是具有挑战性的夜景)中模糊或低分辨率部分的噪声被放大。第二种策略侧重于通过集成额外模块来改进SW-YOLO模型,具体是卷积块注意力模块和Involution模块。选择这些模块是因为它们能在不过度增加计算负担的情况下增强特征表示能力。CBAM的注意力机制有助于更好地聚焦于关键区域,提升了模型检测不同尺度下小型及被遮挡目标的能力。
将CBAM和Involution集成到SW-YOLO架构中,显著提升了模型的精度和鲁棒性。优化后的SW-YOLO模型在IoU=0.5时取得了52.7%的AP,超越了标准单阶段检测器的性能,同时保持了约25 FPS的相对稳定的推理速度。这种精度与速度之间的权衡对于广泛的应用场景仍然是有利的,因为SW-YOLO模型有效地平衡了计算效率与增强的检测精度。CBAM和Involution的战略性集成使SW-YOLO能够利用详细的上下文信息,最终使其成为需要快速处理和高精度目标检测场景的高效选择。
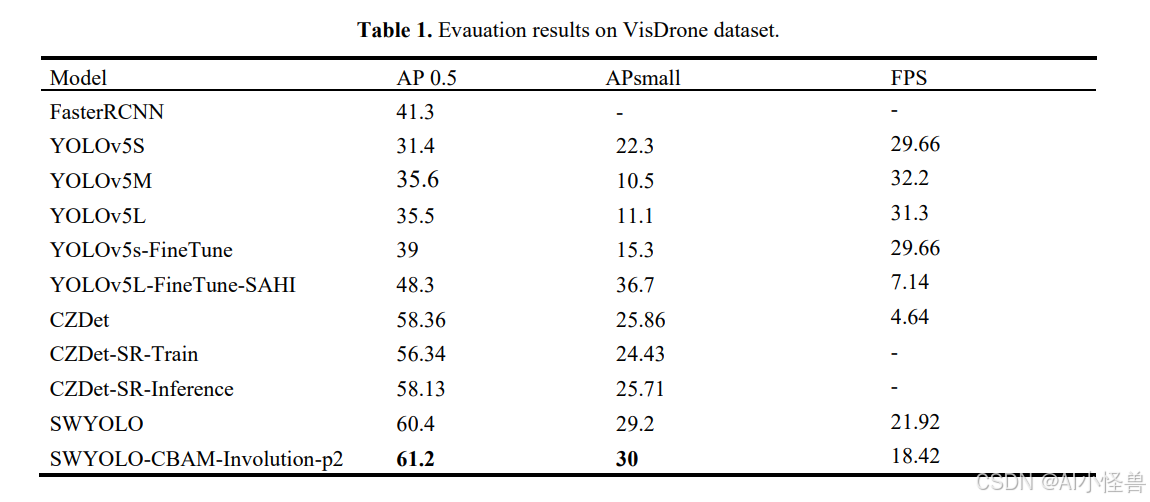
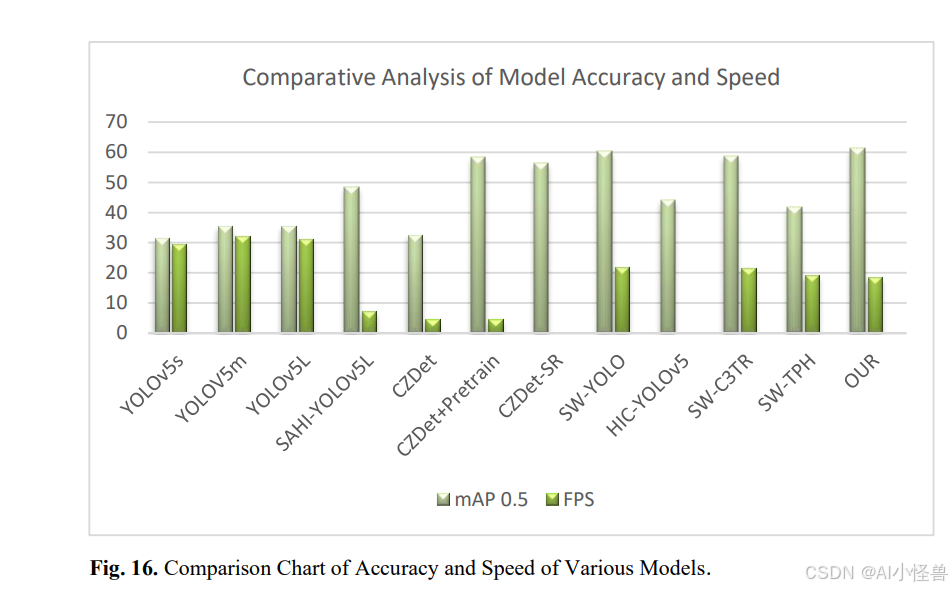
基准SW-YOLO模型最初达到了60.4%的mAP0.5。随后,对此基础架构进行了各种修改以优化性能。引入Transformer模块------将C3TR模块分别添加到骨干网络和各个检测头中------导致了精度和处理速度的下降。此外,将原始的VIOU损失函数替换为此实现中使用的SIOU损失函数;然而,此替换并未带来精度提升。
进一步的分析探讨了单独集成新检测头、Involution块和CBAM块的效果。虽然CBAM和Involution块没有提升精度,但有助于提高处理速度,分别使基准模型的FPS提升了3.78和2.68。最终,将这些模块与新检测头相结合,在保持有竞争力的处理速度(仅比原始SW-YOLO模型降低了3.5个单位)的同时获得了精度提升。这种增强配置优于最快的基准检测器,在速度上提升了0.57个单位,精度提高了1.7倍。
结论
本论文提出了一种针对大规模图像中小目标检测的框架,旨在有效平衡推理速度与精度。该方法采用图像切片技术,通过生成高分辨率图像片段来改进小目标检测。该技术在训练阶段(用于扩充数据集)和推理阶段(用于提高检测精度)均进行了评估。测试了多种后处理策略来整合这些图像切片,其中IOS和NMS方法取得了最有利的结果。此外,将完整图像与分割切片结合使用显著提高了精度,特别是对于较大目标。
在模型选择方面,基于在VisDrone2019数据集上评估的最新进展,选择了一个高性能基准模型。为了增强小目标检测,在推理和训练阶段都集成了超分辨率网络,以提高包含密集小目标的图像的清晰度。其他改进包括将CBAM集成到骨干网络中,以最小的计算开销聚焦于关键的空间和通道特征。在颈部模块中使用Involution块进一步增强了特征图质量,同时增加了一个额外的检测头以利用更高分辨率的特征图,最终提升了小目标检测性能。