一、前言
在现在很多自媒体平台的剧情类短视频创作中,多角色配音是核心环节但痛点显著:真人配音成本高、周期长,通用 TTS 工具缺乏角色区分度,多语言 /多情绪适配性差,且难以批量处理剧本、生成标准化字幕。
今天我们基于SpeechT5 模型构建一套自媒体多角色剧情配音系统,正是针对上述痛点的可落地解决方案。该系统以 SpeechT5 为核心引擎,支持中英文多角色配音,覆盖 "剧本解析→语音合成→音频拼接→字幕生成→项目报告" 全流程,还提供 Web 可视化界面与批量处理能力,完全适配自媒体小团队的配音需求。
系统的核心示例围绕 "校园魔法冒险" 剧情展开:以小明、小红、老师、魔法书等角色构建短剧情,通过不同音色(青年男 / 女、中年女)、语速、音调的定制化合成,搭配音效 / 停顿指令,生成完整的剧情音频,并自动输出 SRT/ASS 字幕与项目报告,直接适配短视频制作流程。
二、运行界面
1. 单句语音生成界面
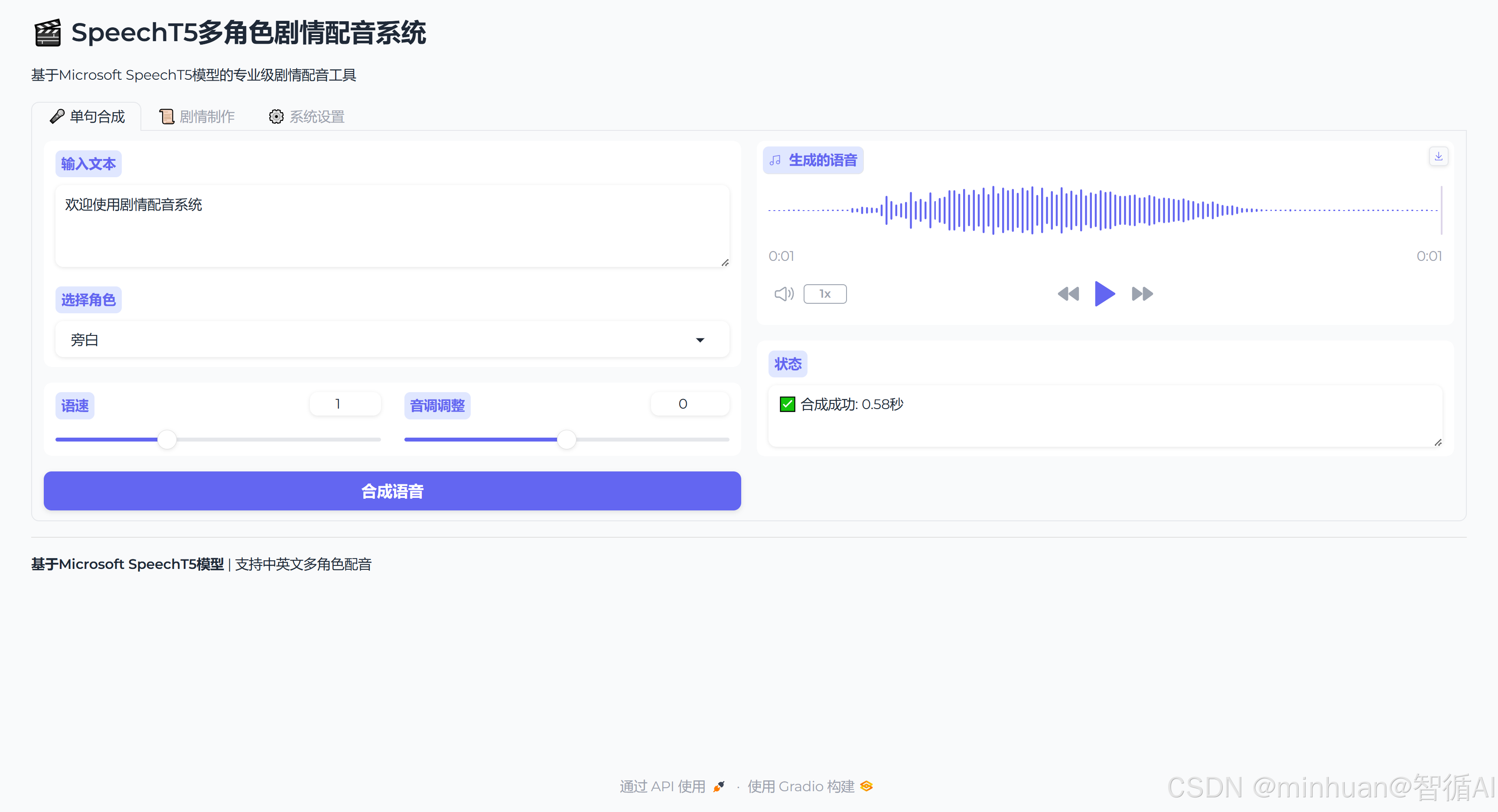
2. 剧情制作合成
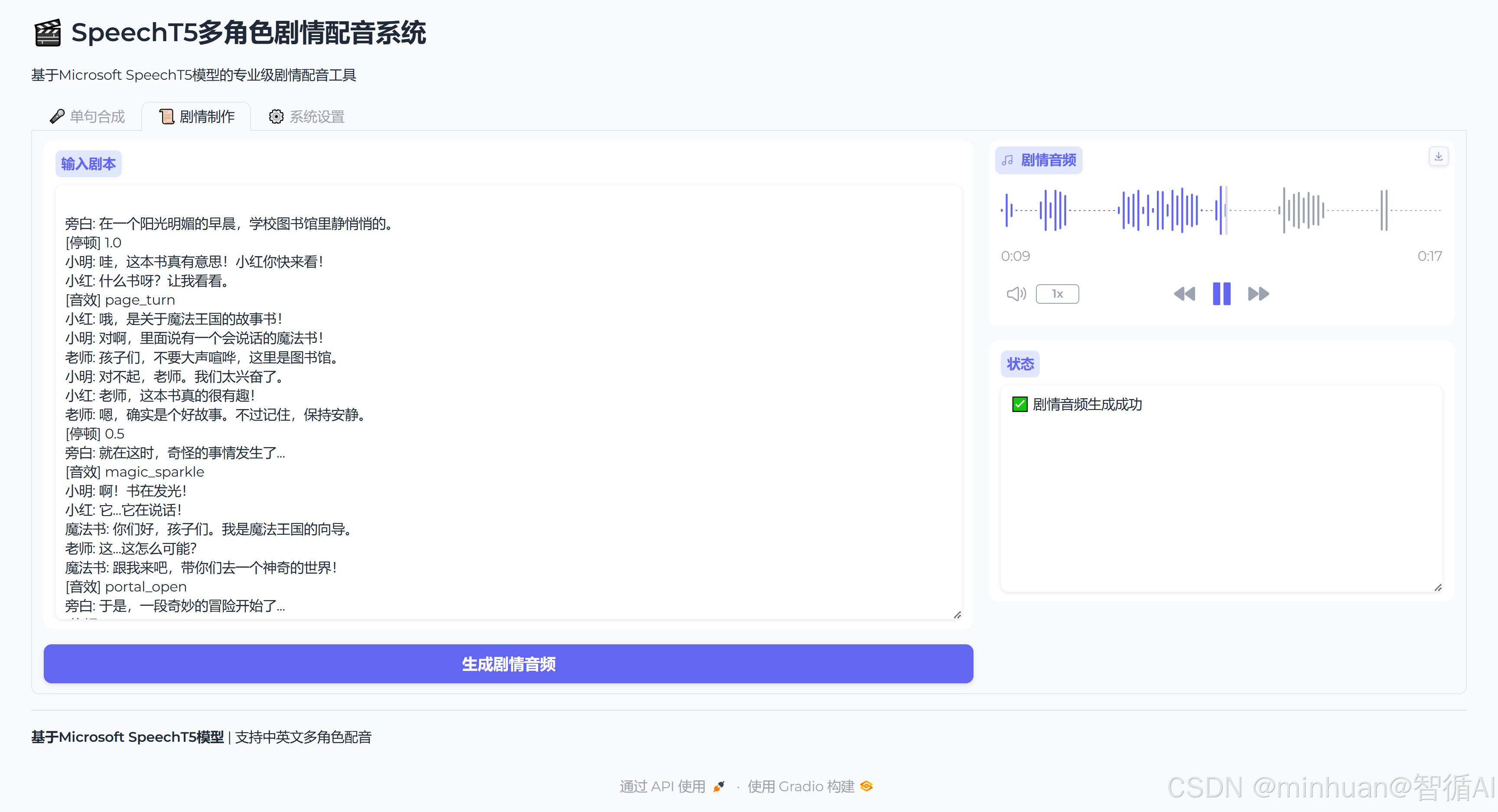
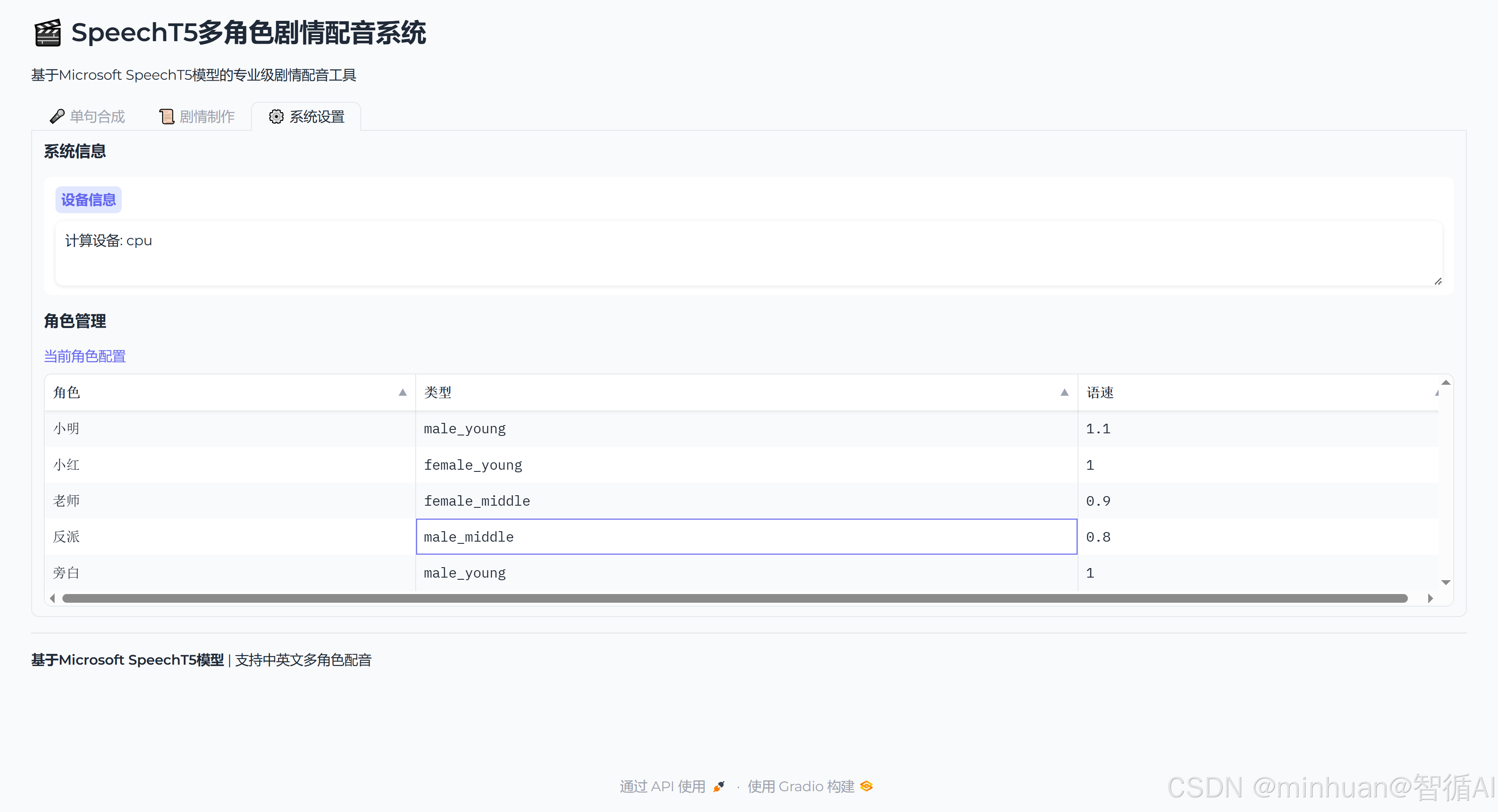
3. 系统角色配置
三、系统架构
Microsoft SpeechT5(轻量、开源、支持多说话人嵌入)+ FFmpeg(音频处理)+ Gradio(可视化交互)。
1. 说话人嵌入管理
SpeechT5 实现多角色配音的关键是说话人嵌入向量(512 维) ------ 不同向量对应不同音色,该类解决了 "本地嵌入加载与角色映射" 的核心问题,细节如下:
1.1 核心逻辑
- 初始化:指定本地嵌入文件目录(D:/AIWorld/dataset/spkrec-xvect),加载所有.npy 格式的嵌入文件;
- 文件名解析:通过正则匹配(cmu_us_{speaker}_arctic)提取说话人标识,并映射为易理解的角色标签:
- awb → male_young(青年男性)、slt → female_young(青年女性);
- bdl → male_middle(中年男性)、clb → female_middle(中年女性);
- rms/jmk → male_old(老年男性);
- 平均嵌入计算:对同一角色的多个嵌入文件取均值,保证音色稳定性;
- 容错机制:若未找到.npy 文件,给出明确提示,不中断系统运行。
1.2 关键作用
将技术化的说话人标识(如 awb)转化为创作者易理解的角色标签(如青年男性),降低使用门槛;通过平均嵌入提升音色一致性,避免单文件嵌入的随机性。
1.3 加载方式
今天我们采用本地数据集的加载方式,将spkrec-xvect.zip的集合加载到项目中,优化了模拟数据的使用过程。
数据集文件预览:

本地加载示例:
python
import numpy as np
import os
from pathlib import Path
import torch
import re
class LocalSpeakerEmbeddings:
"""
从本地目录加载说话人嵌入
支持 .npy 格式的文件
"""
def __init__(self, embeddings_dir="D:/AIWorld/dataset/spkrec-xvect"):
"""
初始化本地说话人嵌入加载器
Args:
embeddings_dir: 嵌入文件目录
"""
self.embeddings_dir = Path(embeddings_dir)
self.embeddings = {}
self.speaker_mapping = {}
# 加载所有嵌入文件
self.load_all_embeddings()
def load_all_embeddings(self):
"""加载所有嵌入文件"""
print(f"正在从 {self.embeddings_dir} 加载说话人嵌入...")
# 获取所有.npy文件
npy_files = list(self.embeddings_dir.glob("*.npy"))
if not npy_files:
print("❌ 未找到 .npy 文件")
return
print(f"找到 {len(npy_files)} 个嵌入文件")
# 按说话人分组
speaker_embeddings = {}
for file_path in npy_files:
try:
# 从文件名提取说话人信息
speaker_id = self.extract_speaker_from_filename(file_path.name)
if speaker_id not in speaker_embeddings:
speaker_embeddings[speaker_id] = []
# 加载嵌入向量
embedding = np.load(file_path)
# 确保形状正确 (512维)
if embedding.shape == (512,):
speaker_embeddings[speaker_id].append(embedding)
else:
print(f"⚠️ 文件 {file_path.name} 形状异常: {embedding.shape}")
except Exception as e:
print(f"❌ 加载文件失败 {file_path.name}: {str(e)}")
# 计算每个说话人的平均嵌入
self._compute_average_embeddings(speaker_embeddings)
def extract_speaker_from_filename(self, filename):
"""
从文件名提取说话人标识
文件名示例: cmu_us_awb_arctic-wav-arctic_a0324.npy
提取规则: cmu_us_{speaker}_arctic...
"""
try:
# 模式匹配: cmu_us_{speaker}_arctic
pattern = r'cmu_us_([a-z]+)_arctic'
match = re.search(pattern, filename)
if match:
return match.group(1)
else:
# 如果正则匹配失败,使用文件名的前部分
parts = filename.split('_')
if len(parts) >= 3:
return parts[2] # 通常是第三个部分
else:
return filename.split('.')[0]
except Exception:
return "unknown_speaker"
def _compute_average_embeddings(self, speaker_embeddings):
"""计算每个说话人的平均嵌入"""
print("\n计算说话人平均嵌入...")
for speaker_id, embeddings_list in speaker_embeddings.items():
if embeddings_list:
# 计算平均嵌入
avg_embedding = np.mean(embeddings_list, axis=0)
# 存储为torch tensor
self.embeddings[speaker_id] = torch.tensor(avg_embedding).unsqueeze(0)
print(f" {speaker_id}: {len(embeddings_list)} 个样本")
print(f"✅ 加载了 {len(self.embeddings)} 个说话人嵌入")
# 显示加载的说话人
self.list_speakers()
def list_speakers(self):
"""列出所有可用的说话人"""
print("\n📋 可用的说话人:")
for i, (speaker_id, embedding) in enumerate(self.embeddings.items(), 1):
print(f" {i:2d}. {speaker_id} - 维度: {embedding.shape[1]}")
def get_embedding(self, speaker_id, default_speaker="awb"):
"""
获取说话人嵌入
Args:
speaker_id: 说话人标识
default_speaker: 如果找不到时的默认说话人
Returns:
嵌入向量 (torch.Tensor)
"""
if speaker_id in self.embeddings:
return self.embeddings[speaker_id]
elif default_speaker in self.embeddings:
print(f"⚠️ 说话人 '{speaker_id}' 不存在,使用默认 '{default_speaker}'")
return self.embeddings[default_speaker]
else:
# 如果都没有,返回第一个可用的
if self.embeddings:
first_key = list(self.embeddings.keys())[0]
print(f"⚠️ 使用可用的第一个说话人 '{first_key}'")
return self.embeddings[first_key]
else:
# 如果没有嵌入,创建一个随机嵌入
print("⚠️ 没有可用的嵌入,创建随机嵌入")
return torch.randn(1, 512) * 0.1
def get_available_speakers(self):
"""获取所有可用说话人列表"""
return list(self.embeddings.keys())
if __name__ == "__main__":
# 实例化类并加载嵌入
embeddings_loader = LocalSpeakerEmbeddings()
# 列出所有可用的说话人
speakers = embeddings_loader.get_available_speakers()
print("可用的说话人:", speakers)示例运行输出:
正在从 D:\AIWorld\dataset\spkrec-xvect 加载说话人嵌入...
找到 7931 个嵌入文件
计算说话人平均嵌入...
awb: 1138 个样本
bdl: 1133 个样本
clb: 1132 个样本
jmk: 1132 个样本
ksp: 1132 个样本
rms: 1132 个样本
slt: 1132 个样本
✅ 加载了 7 个说话人嵌入
📋 可用的说话人:
awb - 维度: 512
bdl - 维度: 512
clb - 维度: 512
jmk - 维度: 512
ksp - 维度: 512
rms - 维度: 512
slt - 维度: 512
可用的说话人: 'awb', 'bdl', 'clb', 'jmk', 'ksp', 'rms', 'slt'
2. FFmpeg配置
FFmpeg是一个开源的跨平台多媒体处理框架,可以处理音频、视频等多种媒体格式。在本项目中,FFmpeg主要用于音频文件的合并与处理,其核心优势在于无损合并能力,在示例可以看到以下一些参数配置。
参数解析:
- -f concat:指定使用concat协议
- -safe 0:禁用安全检查,允许相对路径
- -i concat_list.txt:输入连接列表文件
- -c copy:流复制模式,不重新编码,保证音频质量
- -y:自动覆盖输出文件
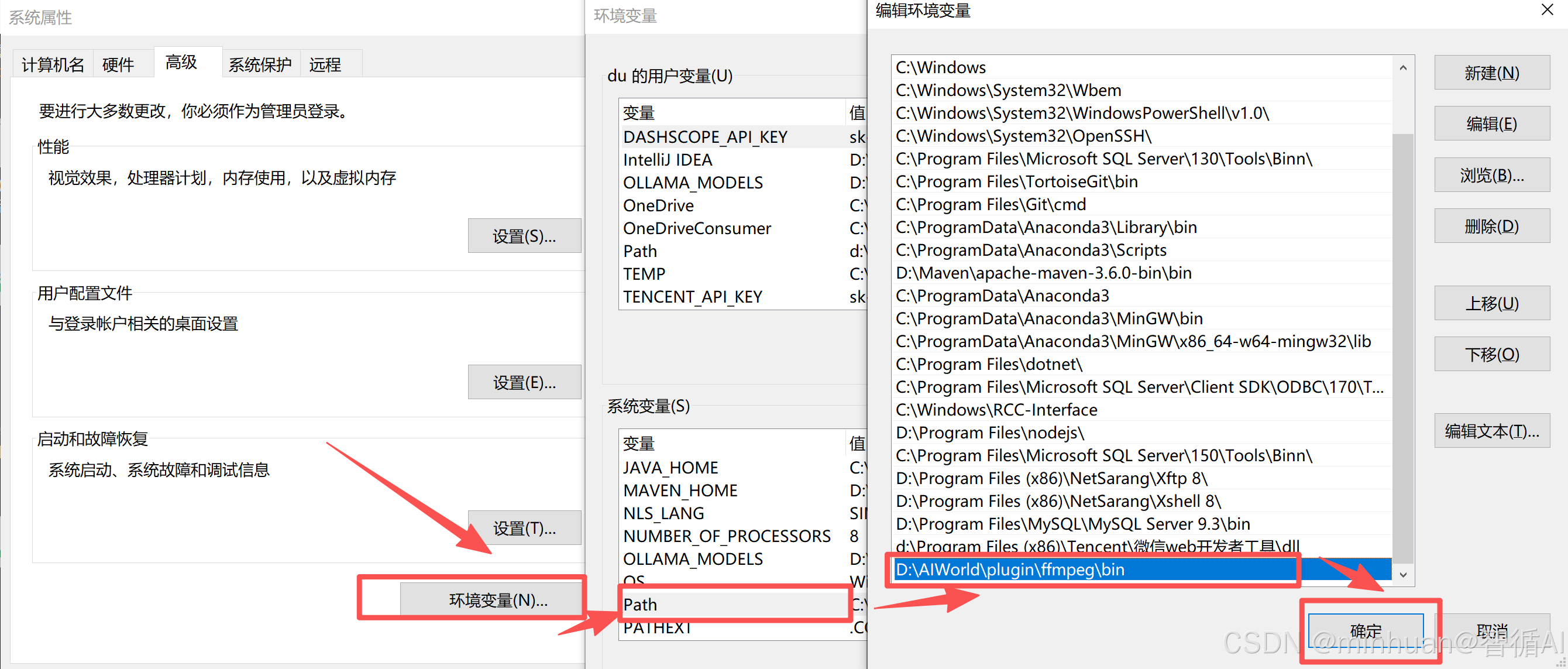
FFmpeg的安装配置步骤:
-
- 解压到目录(如D:\AIWorld\plugin\ffmpeg)
-
- 将D:\AIWorld\plugin\ffmpeg\bin添加到系统环境变量PATH
-
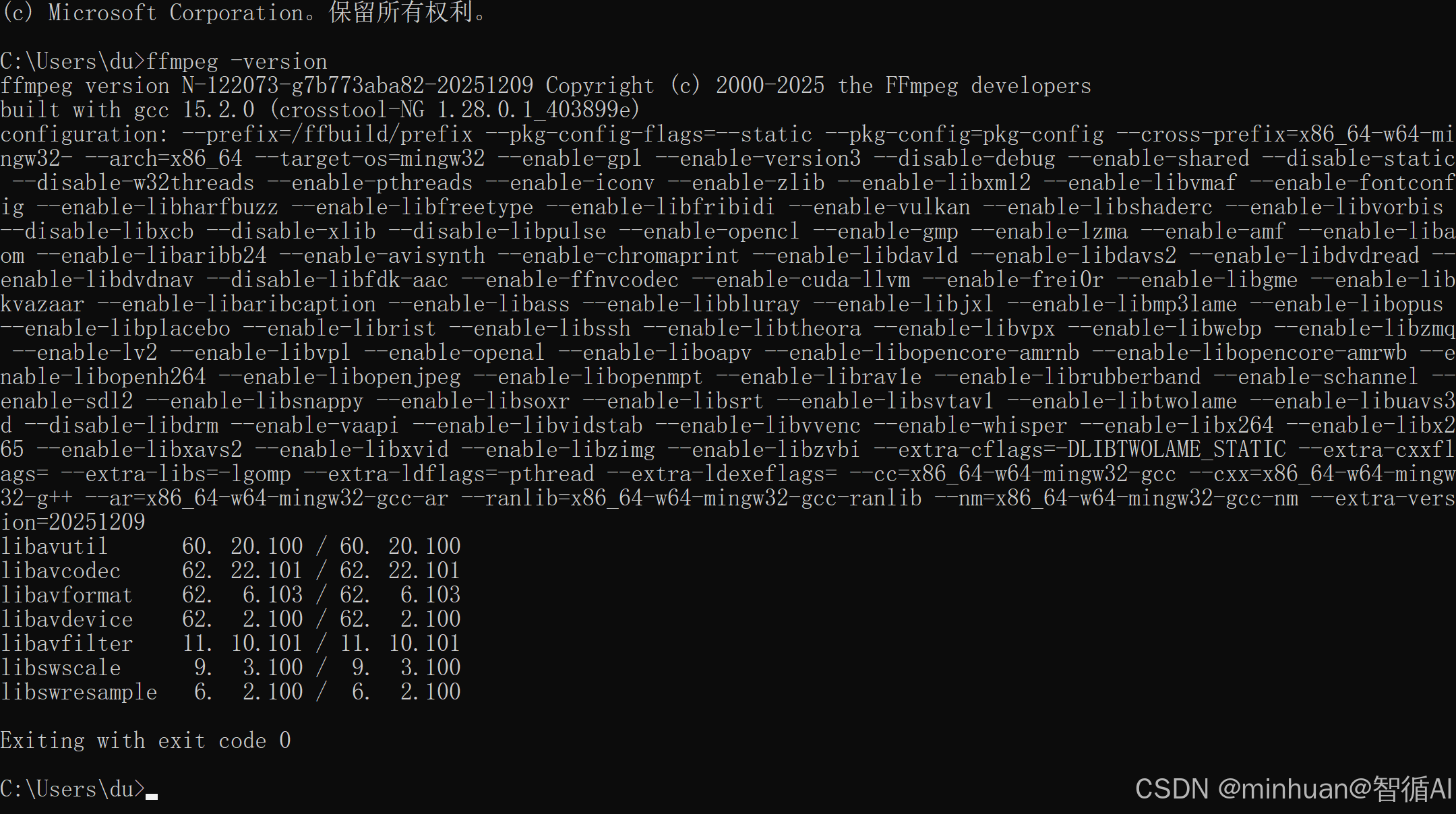
- 验证:终端输入 ffmpeg -version
3. 核心组件
3.1 LocalSpeakerEmbeddings类
**作用:**说话人嵌入管理,从本地文件系统加载和管理说话人嵌入向量,支持说话人识别和声音控制。
python
# 嵌入向量标准化处理
def _compute_average_embeddings(self, speaker_embeddings):
"""计算每个说话人的平均嵌入,确保声音一致性"""
for speaker_id, embeddings_list in speaker_embeddings.items():
if embeddings_list:
# 计算平均嵌入,减少单个样本的噪声影响
avg_embedding = np.mean(embeddings_list, axis=0)
# 转换为PyTorch张量并添加批次维度
self.embeddings[speaker_id] = torch.tensor(avg_embedding).unsqueeze(0)- 智能文件命名解析:支持cmu_us_awb_arctic-wav-arctic_a0324.npy格式自动识别
- 容错机制:当指定说话人不存在时自动回退到默认说话人
- 内存优化:使用平均嵌入减少内存占用,同时保持声音特征
角色音色的差异化控制:
通过 "说话人嵌入 + 语速 + 音调" 三维参数定制角色音色:
- 小明(male_young):语速 1.1 倍、音调 + 0.5 半音,体现活泼;
- 老师(female_middle):语速 0.9 倍、音调 - 0.2 半音,体现稳重;
- 反派(male_middle):语速 0.8 倍、音调 - 0.5 半音,体现阴沉。
3.2 SpeechT5VoiceSystem类
**作用:**语音合成引擎,封装SpeechT5模型,提供完整的TTS功能,包括多说话人、多语言支持。
python
def synthesize(self, text: str, speaker_type: str = "female_young",
speed: float = 1.0, pitch_shift: float = 0.0,
output_file: Optional[str] = None) -> np.ndarray:
"""核心合成函数,包含完整的处理流水线"""
# 1. 缓存检查(提高性能)
cache_key = f"{text}_{speaker_type}_{speed}_{pitch_shift}"
if cache_key in self.audio_cache:
return self.audio_cache[cache_key]
# 2. 说话人嵌入获取(支持回退机制)
if speaker_type not in self.speaker_embeddings:
speaker_type = "female_young"
speaker_embedding = self.speaker_embeddings[speaker_type].to(self.device)
# 3. 文本预处理和模型推理
inputs = self.processor(text=text, return_tensors="pt")
with torch.no_grad():
speech = self.model.generate_speech(
inputs["input_ids"].to(self.device),
speaker_embedding,
vocoder=self.vocoder
)
# 4. 音频后处理(语速、音调调整)
audio = speech.cpu().numpy().squeeze()
audio = self._postprocess_audio(audio, speed, pitch_shift)
# 5. 缓存管理
self._add_to_cache(cache_key, audio)语音合成与后处理:
- 核心方法:synthesize(文本、角色类型、语速、音调、输出路径);
- 缓存机制:以 "文本 + 角色 + 语速 + 音调" 为缓存键,缓存上限 50 条,避免重复合成,提升批量处理效率;
- 后处理细节:
- 语速调整:通过 librosa.effects.time_stretch 实现(0.5-2.0 倍速);
- 音调调整:通过 librosa.effects.pitch_shift 实现(-5~+5 半音);
- 音量归一化:将音频振幅压缩到 0.9 倍,避免失真。
3.3 DramaVoiceSystem类
**作用:**剧情编排系统,管理完整的剧情制作流程,包括角色配置、剧本解析、音频合成和后期处理。
python
def parse_script(self, script_text: str):
"""智能剧本解析器,支持多种格式"""
# 支持格式:
# 1. 角色对话: "小明: 你好啊!"
# 2. 音效: "[音效] door_open"
# 3. 停顿: "[停顿] 2.5"
# 4. 旁白: 直接文本视为旁白
# 时长估算算法:基于字符数和内容复杂度
duration = len(text) * 0.12 # 每个字符约0.12秒
if any(char in text for char in "。!?"): # 标点增加停顿
duration *= 1.2
def combine_audio(self, output_filename: str = "final_drama.wav") -> str:
"""使用FFmpeg进行专业级音频合并"""
# 1. 创建音频连接列表
# 2. 生成静音片段用于停顿
# 3. 使用FFmpeg的concat协议无损合并
# 4. 添加专业音频效果(淡入淡出、动态压缩)
# FFmpeg命令构建:
cmd = [
'ffmpeg',
'-f', 'concat', # 使用连接协议
'-safe', '0', # 允许非常规路径
'-i', concat_file, # 输入连接列表
'-c', 'copy', # 流复制(无损)
output_path,
'-y' # 覆盖输出
]该类是衔接 "TTS 引擎" 与 "自媒体需求" 的核心,覆盖剧本处理到音频输出的全业务流程,细节如下:
3.3.1 数据结构定义
- CharacterConfig:角色配置数据类,包含名称、说话人类型、语速、音调、音量、描述,支持字典转实例(from_dict);
- ScriptLine:剧本行数据类,包含角色、台词、时长、音频文件路径,清晰封装剧本元素。
3.3.2 剧本解析规则
- 支持 3 类剧本指令,完全贴合短视频剧本的写作逻辑:
- 角色台词:角色名: 台词(如 "小明:这本书真有意思!");
- 音效指令:音效 音效名称(如 "音效 magic_sparkle");
- 停顿指令:停顿 时间(秒)(如 "停顿 1.0");
- 容错处理:未知角色默认映射为 "旁白",未指定时长的停顿默认 1 秒,台词时长按 "字符数 ×0.12 秒" 估算(最短 2 秒)。
3.3.3 音频合并与后处理
- FFmpeg 批量拼接:生成 concat_list.txt 文件,按剧本顺序拼接语音、静音(音效 / 停顿)文件;
- 音频效果优化:
- 淡入淡出:默认淡入 0.5 秒、淡出 1 秒,避免音频开头 / 结尾突兀;
- 动态范围压缩:使不同角色的音量更均匀;
- 音量归一化:统一整体音量,适配短视频平台播放标准。
3.3.4 多格式字幕生成
- SRT 字幕:基础格式,兼容所有剪辑软件(剪映、PR、AE);
- ASS 字幕:富格式,支持角色样式区分(如小明用橙色、小红用绿色),提升字幕美观度;
- 时间轴计算:按音频实际时长生成,角色台词间添加 0.2 秒间隔,避免字幕重叠。
3.3.5 项目报告与临时文件清理
- 报告生成:输出 JSON(结构化数据)+ Markdown(可视化报告),包含角色配置、剧本摘要、音频文件列表,方便团队协作;
- 临时文件清理:自动删除 temp_audio、temp_combine 目录,避免冗余文件占用存储空间。
4. 交互与示例模块
主程序提供 4 种运行模式,适配不同使用场景:
- 完整示例:生成 "校园魔法冒险" 完整剧情音频 + 字幕 + 报告;
- 快速测试:测试单句语音合成,验证系统是否正常;
- Web 界面:Gradio 可视化操作,支持单句合成、剧情制作,无需编写代码;
- 批量处理:加载外部剧本文件,批量生成配音,适配多剧本创作需求。
示例剧本设计
- 示例剧本围绕 "校园魔法冒险" 展开,包含旁白、角色对话、音效、停顿,总时长约 30 秒(适配短视频时长),覆盖自媒体剧情类视频的典型元素。
5. 主要执行流程
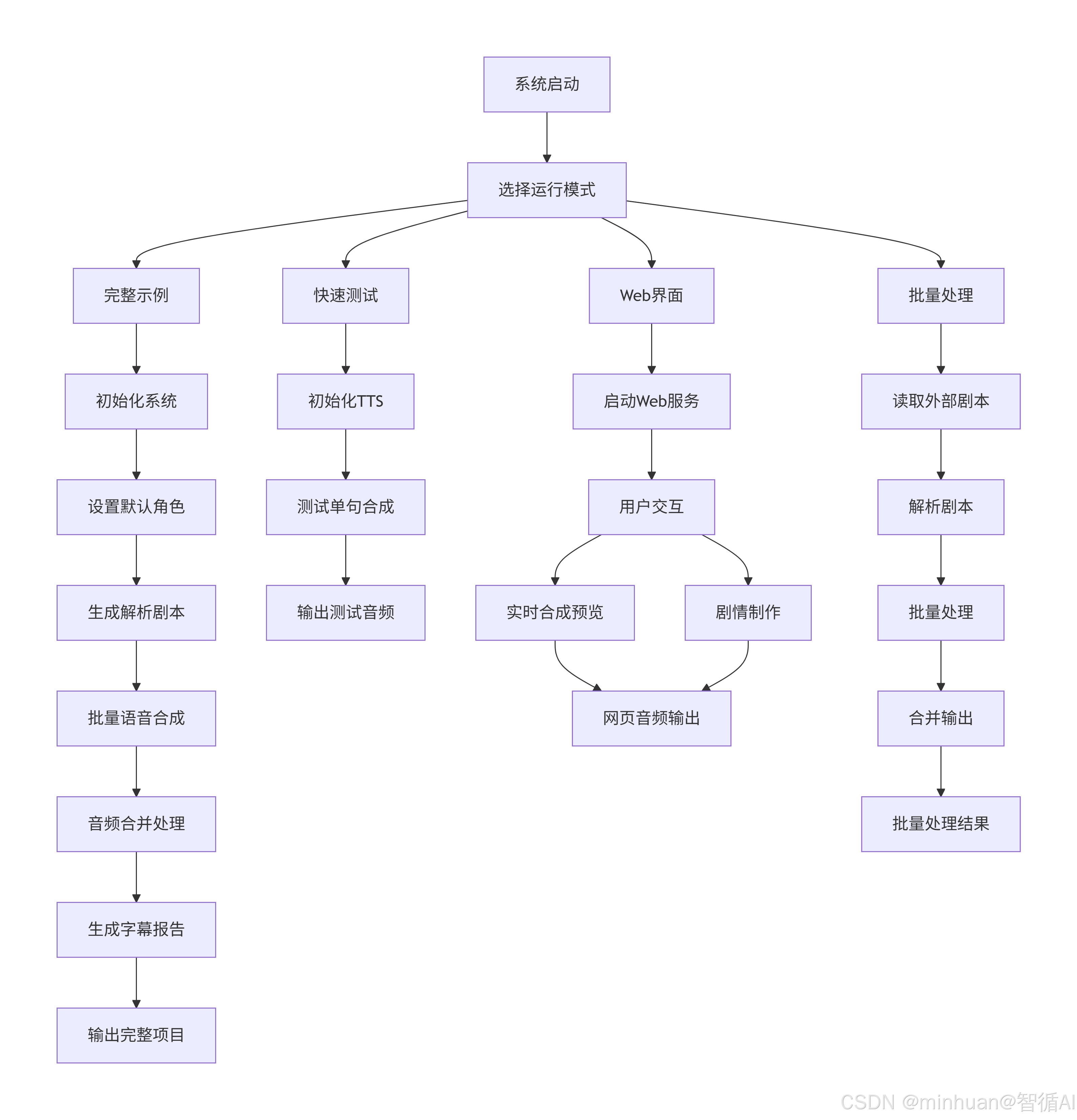
完整实例流程主要步骤:
- 系统初始化:创建配音系统实例,设置输出目录
- 角色配置:加载默认角色(小明、小红、老师、旁白等)
- 剧本处理:解析示例剧本,识别角色对话和音效标记
- 语音生成:为每个角色台词生成语音文件
- 音频拼接:使用FFmpeg将所有音频按顺序合并
- 后处理:添加淡入淡出效果,音量标准化
- 字幕生成:创建SRT和ASS格式字幕文件
- 项目报告:生成JSON和Markdown格式的项目文档
- 清理输出:删除临时文件,保留最终成果
四、运行过程
1. 选择运行模式
选择运行模式:
完整示例(生成完整剧情)
快速测试(测试语音合成)
Web界面(交互式操作)
批量处理(处理剧本文件)
请输入选择 (1-4): 1
2. 系统初始化
⚙️ 初始化SpeechT5系统...
设备: cpu
模型: microsoft/speecht5_tts
✅ SpeechT5系统初始化完成
🎭 剧情配音系统初始化完成
输出目录: my_drama_project
✅ 设置了 5 个默认角色
📢 测试SpeechT5系统...
📥 正在加载SpeechT5模型...
正在从 D:\AIWorld\dataset\spkrec-xvect 加载说话人嵌入...
找到 7931 个嵌入文件
计算说话人平均嵌入...
male_young: 2270 个样本
male_middle: 1133 个样本
female_middle: 1132 个样本
male_old: 2264 个样本
female_young: 1132 个样本
✅ 加载了 5 个说话人嵌入
📋 可用的说话人:
male_young - 维度: 512
male_middle - 维度: 512
female_middle - 维度: 512
male_old - 维度: 512
female_young - 维度: 512
✅ 从本地目录加载了 5 个说话人嵌入
✅ 模型加载成功!
3. 创建示例脚本
📜 创建示例剧本...
旁白: 在一个阳光明媚的早晨,学校图书馆里静悄悄的。
停顿 1.0
小明: 哇,这本书真有意思!小红你快来看!
小红: 什么书呀?让我看看。
音效 page_turn
小红: 哦,是关于魔法王国的故事书!
小明: 对啊,里面说有一个会说话的魔法书!
老师: 孩子们,不要大声喧哗,这里是图书馆。
小明: 对不起,老师。我们太兴奋了。
小红: 老师,这本书真的很有趣!
老师: 嗯,确实是个好故事。不过记住,保持安静。
停顿 0.5
旁白: 就在这时,奇怪的事情发生了...
音效 magic_sparkle
小明: 啊!书在发光!
小红: 它...它在说话!
魔法书: 你们好,孩子们。我是魔法王国的向导。
老师: 这...这怎么可能?
魔法书: 跟我来吧,带你们去一个神奇的世界!
音效 portal_open
旁白: 于是,一段奇妙的冒险开始了...
停顿 2.0
⚠️ 第17行: 未知角色 '魔法书'
⚠️ 第19行: 未知角色 '魔法书'
📜 解析了 20 行剧本
4. 按角色生成语音
🎤 开始生成语音...
1/20 旁白: 在一个阳光明媚的早晨,学校图书馆里静悄悄的。...
🔊 合成语音: 在一个阳光明媚的早晨,学校图书馆里静悄悄的。...
说话人: male_young, 语速: 1.0x, 音调: +0.0 半音
✅ 语音已保存: my_drama_project\temp_audio\line_001_旁白_215326.wav
3/20 小明: 哇,这本书真有意思!小红你快来看!...
🔊 合成语音: 哇,这本书真有意思!小红你快来看!...
说话人: male_young, 语速: 1.1x, 音调: +0.5 半音
语音已保存: my_drama_project\temp_audio\line_003_小明_215327.wav
4/20 小红: 什么书呀?让我看看。...
🔊 合成语音: 什么书呀?让我看看。...
说话人: female_young, 语速: 1.0x, 音调: +0.3 半音
✅ 语音已保存: my_drama_project\temp_audio\line_004_小红_215329.wav
6/20 小红: 哦,是关于魔法王国的故事书!...
🔊 合成语音: 哦,是关于魔法王国的故事书!...
说话人: female_young, 语速: 1.0x, 音调: +0.3 半音
✅ 语音已保存: my_drama_project\temp_audio\line_006_小红_215330.wav
7/20 小明: 对啊,里面说有一个会说话的魔法书!...
🔊 合成语音: 对啊,里面说有一个会说话的魔法书!...
说话人: male_young, 语速: 1.1x, 音调: +0.5 半音
✅ 语音已保存: my_drama_project\temp_audio\line_007_小明_215330.wav
8/20 老师: 孩子们,不要大声喧哗,这里是图书馆。...
🔊 合成语音: 孩子们,不要大声喧哗,这里是图书馆。...
说话人: female_middle, 语速: 0.9x, 音调: -0.2 半音
✅ 语音已保存: my_drama_project\temp_audio\line_008_老师_215330.wav
9/20 小明: 对不起,老师。我们太兴奋了。...
🔊 合成语音: 对不起,老师。我们太兴奋了。...
说话人: male_young, 语速: 1.1x, 音调: +0.5 半音
✅ 语音已保存: my_drama_project\temp_audio\line_009_小明_215331.wav
10/20 小红: 老师,这本书真的很有趣!...
🔊 合成语音: 老师,这本书真的很有趣!...
说话人: female_young, 语速: 1.0x, 音调: +0.3 半音
✅ 语音已保存: my_drama_project\temp_audio\line_010_小红_215331.wav
11/20 老师: 嗯,确实是个好故事。不过记住,保持安静。...
🔊 合成语音: 嗯,确实是个好故事。不过记住,保持安静。...
说话人: female_middle, 语速: 0.9x, 音调: -0.2 半音
✅ 语音已保存: my_drama_project\temp_audio\line_011_老师_215332.wav
13/20 旁白: 就在这时,奇怪的事情发生了......
🔊 合成语音: 就在这时,奇怪的事情发生了......
说话人: male_young, 语速: 1.0x, 音调: +0.0 半音
✅ 语音已保存: my_drama_project\temp_audio\line_013_旁白_215332.wav
15/20 小明: 啊!书在发光!...
🔊 合成语音: 啊!书在发光!...
说话人: male_young, 语速: 1.1x, 音调: +0.5 半音
✅ 语音已保存: my_drama_project\temp_audio\line_015_小明_215333.wav
16/20 小红: 它...它在说话!...
🔊 合成语音: 它...它在说话!...
说话人: female_young, 语速: 1.0x, 音调: +0.3 半音
✅ 语音已保存: my_drama_project\temp_audio\line_016_小红_215333.wav
17/20 老师: 这...这怎么可能?...
🔊 合成语音: 这...这怎么可能?...
说话人: female_middle, 语速: 0.9x, 音调: -0.2 半音
✅ 语音已保存: my_drama_project\temp_audio\line_017_老师_215334.wav
19/20 旁白: 于是,一段奇妙的冒险开始了......
🔊 合成语音: 于是,一段奇妙的冒险开始了......
说话人: male_young, 语速: 1.0x, 音调: +0.0 半音
✅ 语音已保存: my_drama_project\temp_audio\line_019_旁白_215334.wav
✅ 所有语音生成完成
🔗 合并音频...
执行命令: ffmpeg -f concat -safe 0 -i my_drama_project\temp_combine\concat_list.txt -c copy my_drama_project\my_drama_final.wav -y
✅ 音频合并完成: my_drama_project\my_drama_final.wav
🎵 添加了音频效果: 淡入0.5秒, 淡出1.0秒
5. 生成字幕
📝 生成字幕...
✅ SRT字幕已生成: my_drama_project\subtitles.srt
📝 生成字幕...
✅ ASS字幕已生成: my_drama_project\subtitles.ass
📊 生成项目报告...
✅ 项目报告已生成:
my_drama_project\project_report.json
my_drama_project\README.md
🧹 已清理临时音频文件
🧹 已清理临时合并文件
==================================================================
🎉 剧情配音制作完成!
==================================================================
🎵 最终音频: my_drama_project\my_drama_final.wav
📝 字幕文件:
SRT格式: my_drama_project\subtitles.srt
ASS格式: my_drama_project\subtitles.ass
📄 项目报告: my_drama_project/README.md
📊 详细数据: my_drama_project/project_report.json
🚀 下一步:
使用视频编辑软件导入音频和字幕
添加背景图片或视频
导出为完整的视频作品
字幕文件内容参考:
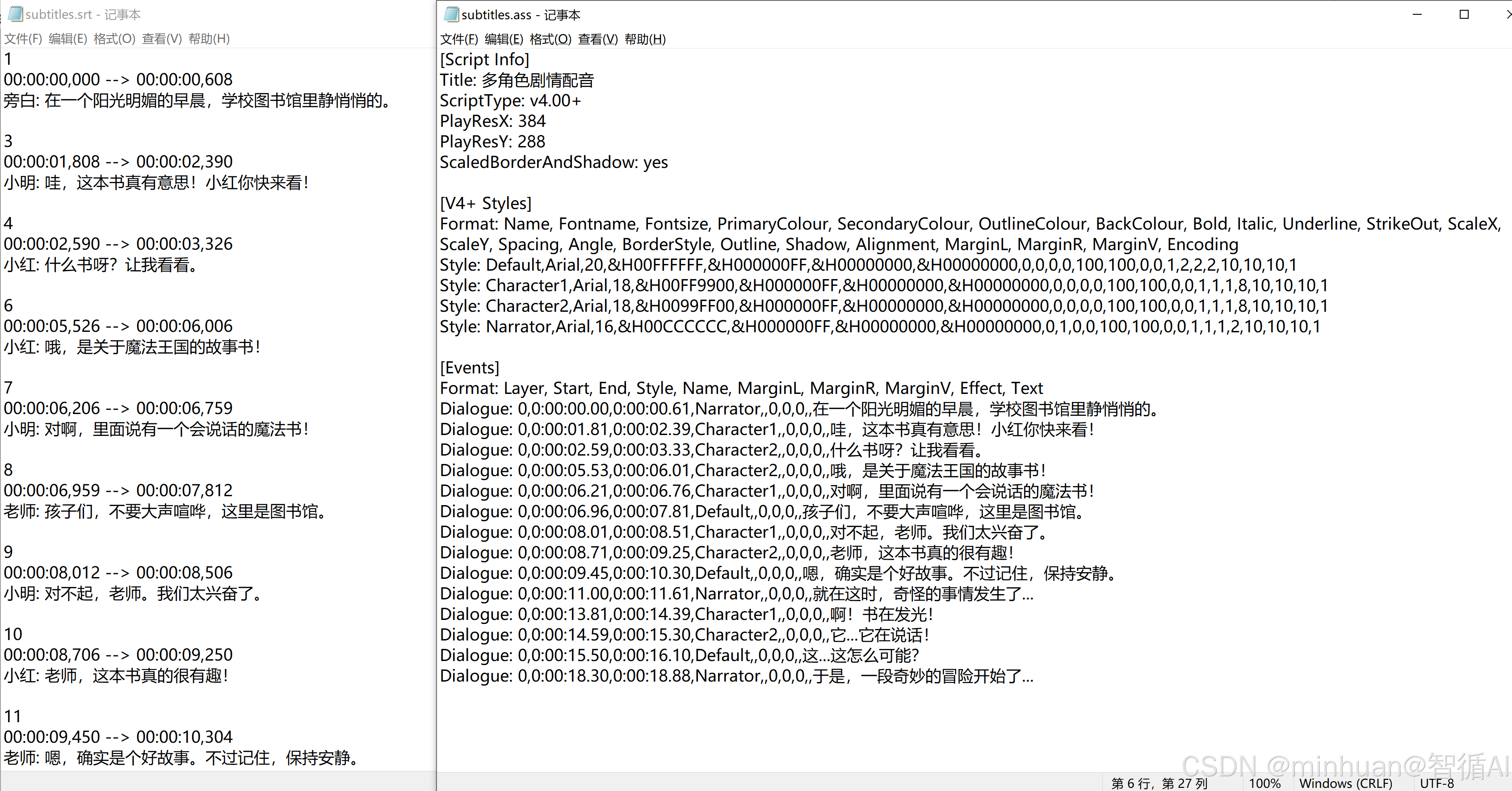
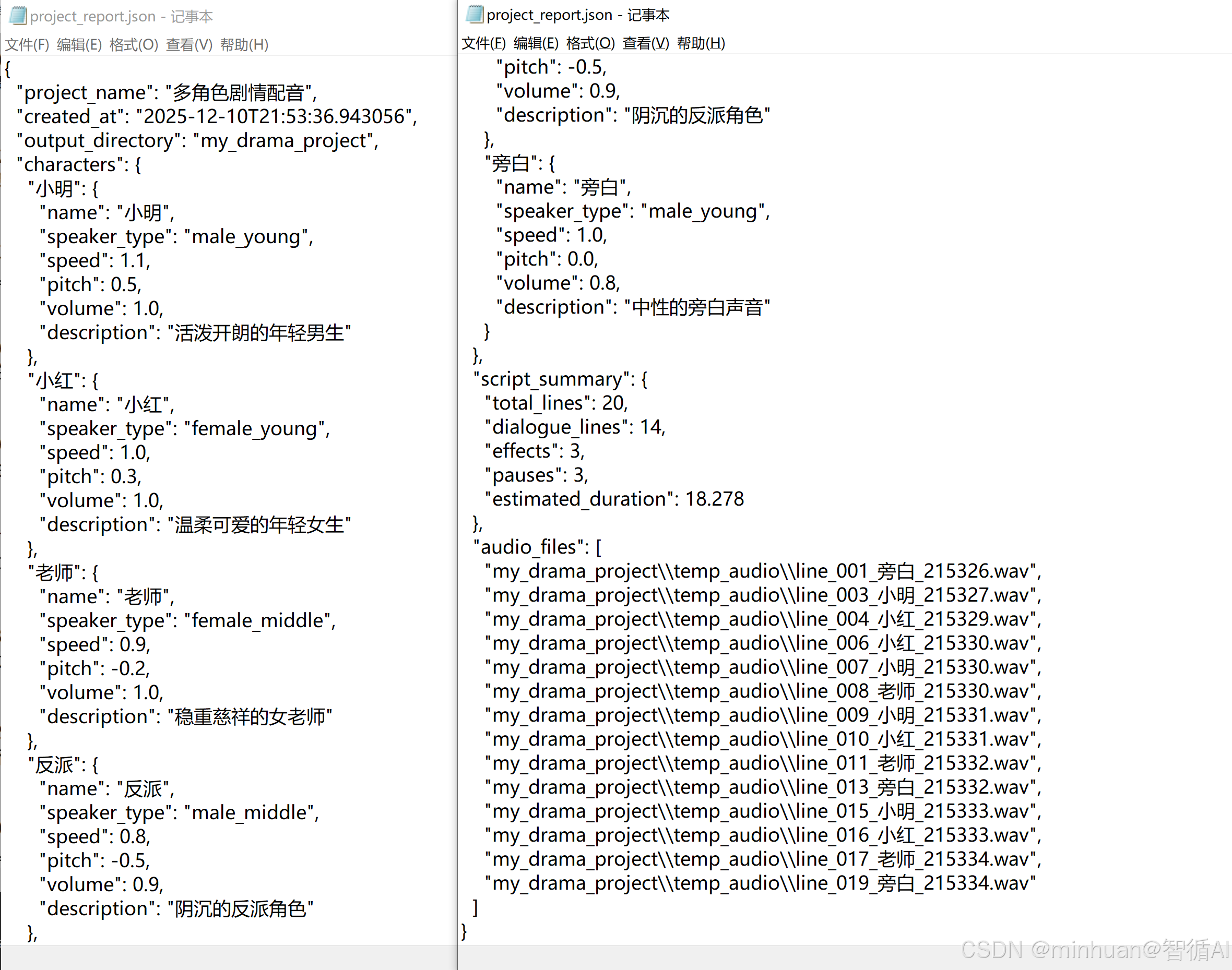
项目数据报告文档:
五、总结
这套基于 SpeechT5 的多角色剧情配音系统,是针对自媒体创作者的 "轻量化、全流程、可落地" 解决方案。其核心价值在于:以开源技术为底座,将专业级的 TTS 能力转化为创作者易使用的工具,解决了真人配音成本高、效率低的痛点。
系统的设计细节(如容错机制、缓存策略、多格式输出)充分考虑了自媒体创作的实际需求,从 "技术实现" 到 "业务落地" 形成了完整闭环。即使是无编程基础的创作者,也能通过 Web 界面快速生成多角色剧情配音;可通过代码定制角色、优化参数,适配更复杂的创作场景。
附录:完整示例代码
python
"""
自媒体多角色剧情配音系统 - 基于SpeechT5模型
完整可运行,支持中英文多角色配音
"""
import os
import re
import json
import torch
import torchaudio
import numpy as np
import pandas as pd
import soundfile as sf
from pathlib import Path
from typing import Dict, List, Tuple, Optional
from dataclasses import dataclass, asdict
from datetime import datetime
import subprocess
import tempfile
from pydub import AudioSegment
from pydub.effects import normalize, compress_dynamic_range
# ==================== 安装依赖说明 ====================
"""
安装依赖(请按顺序执行):
1. 核心依赖:
pip install torch torchaudio transformers datasets numpy soundfile
2. 音频处理依赖:
pip install pydub librosa scipy
3. Web界面依赖(可选):
pip install gradio streamlit flask
4. FFmpeg(必需!):
- Windows:
1. 下载ffmpeg:https://www.ffmpeg.org/download.html#build-windows
2. 解压到目录(如D:\ffmpeg)
3. 将D:\ffmpeg\bin添加到系统环境变量PATH
4. 验证:终端输入 ffmpeg -version
- macOS:
brew install ffmpeg
- Linux:
sudo apt-get install ffmpeg
sudo apt-get install libsndfile1
"""
# ==================== 核心模型类 ====================
class LocalSpeakerEmbeddings:
"""
从本地目录加载说话人嵌入
支持 .npy 格式的文件
"""
def __init__(self, embeddings_dir="D:/AIWorld/dataset/spkrec-xvect"):
"""
初始化本地说话人嵌入加载器
Args:
embeddings_dir: 嵌入文件目录
"""
self.embeddings_dir = Path(embeddings_dir)
self.embeddings = {}
self.speaker_mapping = {}
# 加载所有嵌入文件
self.load_all_embeddings()
def load_all_embeddings(self):
"""加载所有嵌入文件"""
print(f"正在从 {self.embeddings_dir} 加载说话人嵌入...")
# 获取所有.npy文件
npy_files = list(self.embeddings_dir.glob("*.npy"))
if not npy_files:
print("❌ 未找到 .npy 文件")
return
print(f"找到 {len(npy_files)} 个嵌入文件")
# 按说话人分组
speaker_embeddings = {}
for file_path in npy_files:
try:
# 从文件名提取说话人信息
speaker_id = self.extract_speaker_from_filename(file_path.name)
if speaker_id == 'awb':
speaker_id = 'male_young'
elif speaker_id == 'slt':
speaker_id = 'female_young'
elif speaker_id == 'bdl':
speaker_id = 'male_middle'
elif speaker_id == 'clb':
speaker_id = 'female_middle'
elif speaker_id == 'rms':
speaker_id = 'male_old'
elif speaker_id == 'jmk':
speaker_id = 'male_old'
else:
speaker_id = 'male_young'
if speaker_id not in speaker_embeddings:
speaker_embeddings[speaker_id] = []
# 加载嵌入向量
embedding = np.load(file_path)
# 确保形状正确 (512维)
if embedding.shape == (512,):
speaker_embeddings[speaker_id].append(embedding)
else:
print(f"⚠️ 文件 {file_path.name} 形状异常: {embedding.shape}")
except Exception as e:
print(f"❌ 加载文件失败 {file_path.name}: {str(e)}")
# 计算每个说话人的平均嵌入
self._compute_average_embeddings(speaker_embeddings)
def extract_speaker_from_filename(self, filename):
"""
从文件名提取说话人标识
文件名示例: cmu_us_awb_arctic-wav-arctic_a0324.npy
提取规则: cmu_us_{speaker}_arctic...
"""
try:
# 模式匹配: cmu_us_{speaker}_arctic
pattern = r'cmu_us_([a-z]+)_arctic'
match = re.search(pattern, filename)
if match:
return match.group(1)
else:
# 如果正则匹配失败,使用文件名的前部分
parts = filename.split('_')
if len(parts) >= 3:
return parts[2] # 通常是第三个部分
else:
return filename.split('.')[0]
except Exception:
return "unknown_speaker"
def _compute_average_embeddings(self, speaker_embeddings):
"""计算每个说话人的平均嵌入"""
print("\n计算说话人平均嵌入...")
for speaker_id, embeddings_list in speaker_embeddings.items():
if embeddings_list:
# 计算平均嵌入
avg_embedding = np.mean(embeddings_list, axis=0)
# 存储为torch tensor
self.embeddings[speaker_id] = torch.tensor(avg_embedding).unsqueeze(0)
print(f" {speaker_id}: {len(embeddings_list)} 个样本")
print(f"✅ 加载了 {len(self.embeddings)} 个说话人嵌入")
# 显示加载的说话人
self.list_speakers()
def list_speakers(self):
"""列出所有可用的说话人"""
print("\n📋 可用的说话人:")
for i, (speaker_id, embedding) in enumerate(self.embeddings.items(), 1):
print(f" {i:2d}. {speaker_id} - 维度: {embedding.shape[1]}")
def get_embedding(self, speaker_id, default_speaker="awb"):
"""
获取说话人嵌入
Args:
speaker_id: 说话人标识
default_speaker: 如果找不到时的默认说话人
Returns:
嵌入向量 (torch.Tensor)
"""
if not isinstance(speaker_id, str):
print(f"⚠️ 说话人标识 '{speaker_id}' 不是字符串类型,尝试转换为字符串")
speaker_id = str(speaker_id)
if speaker_id in self.embeddings:
return self.embeddings[speaker_id]
elif default_speaker in self.embeddings:
print(f"⚠️ 说话人 '{speaker_id}' 不存在,使用默认 '{default_speaker}'")
return self.embeddings[default_speaker]
else:
# 如果都没有,返回第一个可用的
if self.embeddings:
first_key = list(self.embeddings.keys())[0]
print(f"⚠️ 使用可用的第一个说话人 '{first_key}'")
return self.embeddings[first_key]
else:
# 如果没有嵌入,创建一个随机嵌入
print("⚠️ 没有可用的嵌入,创建随机嵌入")
return torch.randn(1, 512) * 0.1
def get_available_speakers(self):
"""获取所有可用说话人列表"""
return list(self.embeddings.keys())
class SpeechT5VoiceSystem:
"""
SpeechT5语音合成系统
支持多说话人、多语言、音调/语速调整
"""
def __init__(self, model_name="microsoft/speecht5_tts", device=None):
"""
初始化SpeechT5系统
Args:
model_name: 模型名称,默认为"microsoft/speecht5_tts"
device: 计算设备,默认自动选择(cuda/cpu)
"""
self.model_name = model_name
self.device = device or ("cuda" if torch.cuda.is_available() else "cpu")
print(f"⚙️ 初始化SpeechT5系统...")
print(f" 设备: {self.device}")
print(f" 模型: {model_name}")
# 延迟加载模型(减少启动时间)
self.processor = None
self.model = None
self.vocoder = None
self.speaker_embeddings = None
# 缓存系统
self.audio_cache = {}
self.max_cache_size = 50
print("✅ SpeechT5系统初始化完成")
def load_models(self):
"""加载SpeechT5模型和处理器"""
if self.processor is None:
try:
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
print("📥 正在加载SpeechT5模型...")
# 加载处理器
self.processor = SpeechT5Processor.from_pretrained(self.model_name)
# 加载TTS模型
self.model = SpeechT5ForTextToSpeech.from_pretrained(self.model_name)
self.model = self.model.to(self.device)
# 加载声码器
self.vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
self.vocoder = self.vocoder.to(self.device)
# 加载说话人嵌入
self._load_speaker_embeddings()
print("✅ 模型加载成功!")
except Exception as e:
print(f"❌ 模型加载失败: {str(e)}")
raise
def _load_speaker_embeddings(self):
"""加载或创建说话人嵌入"""
# 优先尝试从本地目录加载
if not self._load_speaker_embeddings_from_local():
try:
# 尝试从Hugging Face数据集加载
from datasets import load_dataset
print("📊 正在加载说话人嵌入数据集...")
dataset_path = "D:\\AIWorld\\dataset\\spkrec-xvect"
# embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
embeddings_dataset = load_dataset(dataset_path)
print("✅ 数据集加载成功!")
print(f"数据集结构: {embeddings_dataset}")
print(f"数据集样本数: {len(embeddings_dataset)}")
print(f"首条数据示例: {embeddings_dataset[0]}")
# 选择一些代表性的说话人
self.speaker_embeddings = {
"female_young": torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0),
"male_young": torch.tensor(embeddings_dataset[3000]["xvector"]).unsqueeze(0),
"female_middle": torch.tensor(embeddings_dataset[5000]["xvector"]).unsqueeze(0),
"male_middle": torch.tensor(embeddings_dataset[1000]["xvector"]).unsqueeze(0),
"female_old": torch.tensor(embeddings_dataset[6000]["xvector"]).unsqueeze(0),
"male_old": torch.tensor(embeddings_dataset[2000]["xvector"]).unsqueeze(0),
}
print(f"✅ 加载了 {len(self.speaker_embeddings)} 个说话人嵌入")
except Exception as e:
print(f"⚠️ 无法加载说话人数据集,使用随机嵌入: {str(e)}")
self._create_random_embeddings()
def _load_speaker_embeddings_from_local(self):
"""从本地目录加载说话人嵌入"""
try:
embeddings_loader = LocalSpeakerEmbeddings("D:/AIWorld/dataset/spkrec-xvect")
self.speaker_embeddings = embeddings_loader.embeddings
print(f"✅ 从本地目录加载了 {len(self.speaker_embeddings)} 个说话人嵌入")
return True
except Exception as e:
print(f"⚠️ 无法从本地目录加载说话人嵌入: {str(e)}")
return False
def _create_random_embeddings(self):
"""创建随机说话人嵌入"""
torch.manual_seed(42) # 固定随机种子确保一致性
embedding_dim = 512 # SpeechT5说话人嵌入维度
self.speaker_embeddings = {
"female_young": torch.randn(1, embedding_dim) * 0.1,
"male_young": torch.randn(1, embedding_dim) * 0.1,
"female_middle": torch.randn(1, embedding_dim) * 0.1,
"male_middle": torch.randn(1, embedding_dim) * 0.1,
"female_old": torch.randn(1, embedding_dim) * 0.1,
"male_old": torch.randn(1, embedding_dim) * 0.1,
}
# 添加一些偏差使声音不同
self.speaker_embeddings["female_young"][0, :100] += 0.3
self.speaker_embeddings["male_young"][0, 100:200] += 0.3
self.speaker_embeddings["female_middle"][0, 200:300] += 0.2
self.speaker_embeddings["male_middle"][0, 300:400] += 0.2
print(f"✅ 创建了 {len(self.speaker_embeddings)} 个随机说话人嵌入")
def list_available_speakers(self):
"""列出可用说话人"""
if self.speaker_embeddings is None:
self.load_models()
# print(self.speaker_embeddings)
print("\n📋 可用说话人类型:")
for i, (key, embedding) in enumerate(self.speaker_embeddings.items(), 1):
gender, age = key.split("_")
print(f" {i:2d}. {gender} ({age}) - 嵌入维度: {embedding.shape}")
# print(f" {i:2d}. {key} - 嵌入维度: {embedding.shape}")
return list(self.speaker_embeddings.keys())
def synthesize(self, text: str, speaker_type: str = "female_young",
speed: float = 1.0, pitch_shift: float = 0.0,
output_file: Optional[str] = None) -> np.ndarray:
"""
语音合成核心函数
Args:
text: 输入文本1
speaker_type: 说话人类型
speed: 语速 (0.5-2.0)
pitch_shift: 音调偏移 (半音,-5到+5)
output_file: 输出文件路径
Returns:
音频数据 (numpy数组)
"""
# 确保模型已加载
self.load_models()
# 检查缓存
cache_key = f"{text}_{speaker_type}_{speed}_{pitch_shift}"
if cache_key in self.audio_cache:
print(f"📦 使用缓存音频: {text[:30]}...")
audio = self.audio_cache[cache_key]
if output_file:
sf.write(output_file, audio, 16000)
return audio
try:
print(f"🔊 合成语音: {text[:50]}...")
print(f" 说话人: {speaker_type}, 语速: {speed}x, 音调: {pitch_shift:+} 半音")
# 获取说话人嵌入
if speaker_type not in self.speaker_embeddings:
print(f"⚠️ 未知说话人类型 '{speaker_type}',使用默认")
speaker_type = "female_young"
speaker_embedding = self.speaker_embeddings[speaker_type].to(self.device)
# 预处理文本
inputs = self.processor(text=text, return_tensors="pt")
# 生成语音
with torch.no_grad():
speech = self.model.generate_speech(
inputs["input_ids"].to(self.device),
speaker_embedding,
vocoder=self.vocoder
)
# 转换为numpy数组
audio = speech.cpu().numpy().squeeze()
# 应用后处理
audio = self._postprocess_audio(audio, speed, pitch_shift)
# 保存到文件
if output_file:
sf.write(output_file, audio, 16000)
print(f"✅ 语音已保存: {output_file}")
# 添加到缓存
self._add_to_cache(cache_key, audio)
return audio
except Exception as e:
print(f"❌ 语音合成失败: {str(e)}")
raise
def _postprocess_audio(self, audio: np.ndarray, speed: float, pitch_shift: float) -> np.ndarray:
"""音频后处理"""
import librosa
# 调整语速
if speed != 1.0:
audio = librosa.effects.time_stretch(audio, rate=speed)
# 调整音调
if pitch_shift != 0.0:
audio = librosa.effects.pitch_shift(audio, sr=16000, n_steps=pitch_shift)
# 音量归一化
audio = audio / (np.max(np.abs(audio)) + 1e-8) * 0.9
return audio
def _add_to_cache(self, key: str, audio: np.ndarray):
"""添加到缓存"""
if len(self.audio_cache) >= self.max_cache_size:
# 移除最早的一个缓存
oldest_key = next(iter(self.audio_cache))
del self.audio_cache[oldest_key]
self.audio_cache[key] = audio
# ==================== 剧情配音系统 ====================
@dataclass
class CharacterConfig:
"""角色配置"""
name: str
speaker_type: str
speed: float = 1.0
pitch: float = 0.0
volume: float = 1.0
description: str = ""
@classmethod
def from_dict(cls, data: dict):
return cls(**data)
@dataclass
class ScriptLine:
"""剧本行"""
character: str
text: str
duration: float = 0.0 # 估算时长
audio_file: str = "" # 生成的音频文件
class DramaVoiceSystem:
"""
多角色剧情配音系统
"""
def __init__(self, output_dir: str = "drama_production"):
self.output_dir = Path(output_dir)
self.output_dir.mkdir(parents=True, exist_ok=True)
# 初始化语音合成系统
self.tts = SpeechT5VoiceSystem()
# 角色配置
self.characters: Dict[str, CharacterConfig] = {}
# 剧本
self.script: List[ScriptLine] = []
# 音效库
self.sound_effects: Dict[str, str] = {}
# 背景音乐
self.background_music: Optional[str] = None
print(f"🎭 剧情配音系统初始化完成")
print(f" 输出目录: {self.output_dir}")
def setup_default_characters(self):
"""设置默认角色配置"""
self.characters = {
"小明": CharacterConfig(
name="小明",
speaker_type="male_young",
speed=1.1,
pitch=0.5,
volume=1.0,
description="活泼开朗的年轻男生"
),
"小红": CharacterConfig(
name="小红",
speaker_type="female_young",
speed=1.0,
pitch=0.3,
volume=1.0,
description="温柔可爱的年轻女生"
),
"老师": CharacterConfig(
name="老师",
speaker_type="female_middle",
speed=0.9,
pitch=-0.2,
volume=1.0,
description="稳重慈祥的女老师"
),
"反派": CharacterConfig(
name="反派",
speaker_type="male_middle",
speed=0.8,
pitch=-0.5,
volume=0.9,
description="阴沉的反派角色"
),
"旁白": CharacterConfig(
name="旁白",
speaker_type="male_young",
speed=1.0,
pitch=0.0,
volume=0.8,
description="中性的旁白声音"
),
}
print(f"✅ 设置了 {len(self.characters)} 个默认角色")
def add_character(self, character: CharacterConfig):
"""添加角色"""
self.characters[character.name] = character
print(f"➕ 添加角色: {character.name} ({character.description})")
def load_script_from_file(self, filepath: str):
"""从文件加载剧本"""
try:
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read()
self.parse_script(content)
print(f"✅ 从文件加载剧本: {filepath}")
except Exception as e:
print(f"❌ 加载剧本失败: {str(e)}")
def parse_script(self, script_text: str):
"""
解析剧本文本
格式:
角色: 台词
[音效] 音效名称
[停顿] 时间(秒)
"""
self.script = []
lines = script_text.strip().split('\n')
for line_num, line in enumerate(lines, 1):
line = line.strip()
if not line:
continue
# 检查是否是音效
if line.startswith('[音效]'):
effect_name = line[4:].strip()
self.script.append(ScriptLine(
character="[音效]",
text=effect_name,
duration=2.0 # 默认音效时长2秒
))
# 检查是否是停顿
elif line.startswith('[停顿]'):
try:
pause_time = float(line[4:].strip())
self.script.append(ScriptLine(
character="[停顿]",
text=f"停顿 {pause_time} 秒",
duration=pause_time
))
except:
self.script.append(ScriptLine(
character="[停顿]",
text="停顿 1 秒",
duration=1.0
))
# 检查是否是角色台词
elif ':' in line:
parts = line.split(':', 1)
if len(parts) == 2:
character = parts[0].strip()
text = parts[1].strip()
if character in self.characters:
# 估算时长(按字符数)
duration = len(text) * 0.12 # 每个字符约0.12秒
if duration < 1.0:
duration = 2.0 # 最短2秒
self.script.append(ScriptLine(
character=character,
text=text,
duration=duration
))
else:
print(f"⚠️ 第{line_num}行: 未知角色 '{character}'")
else:
# 默认作为旁白
self.script.append(ScriptLine(
character="旁白",
text=line,
duration=len(line) * 0.12
))
print(f"📜 解析了 {len(self.script)} 行剧本")
def generate_all_voices(self) -> List[ScriptLine]:
"""生成所有语音"""
print("\n🎤 开始生成语音...")
for i, line in enumerate(self.script):
try:
if line.character in ["[音效]", "[停顿]"]:
# 音效和停顿跳过语音生成
continue
# 获取角色配置
if line.character not in self.characters:
print(f"⚠️ 第{i+1}行: 角色 '{line.character}' 不存在,使用旁白配置")
char_config = self.characters.get("旁白", CharacterConfig(
name="旁白",
speaker_type="male_young",
speed=1.0,
pitch=0.0
))
else:
char_config = self.characters[line.character]
# 生成文件名
timestamp = datetime.now().strftime("%H%M%S")
filename = f"line_{i+1:03d}_{line.character}_{timestamp}.wav"
output_path = self.output_dir / "temp_audio" / filename
output_path.parent.mkdir(exist_ok=True)
print(f" [{i+1}/{len(self.script)}] {line.character}: {line.text[:40]}...")
# 生成语音
audio = self.tts.synthesize(
text=line.text,
speaker_type=char_config.speaker_type,
speed=char_config.speed,
pitch_shift=char_config.pitch,
output_file=str(output_path)
)
# 更新剧本行
line.audio_file = str(output_path)
line.duration = len(audio) / 16000 # 实际时长
except Exception as e:
print(f"❌ 第{i+1}行生成失败: {str(e)}")
print("✅ 所有语音生成完成")
return self.script
def combine_audio(self, output_filename: str = "final_drama.wav") -> str:
"""合并所有音频"""
print("\n🔗 合并音频...")
# 确保所有语音已生成
if any(line.audio_file == "" and line.character not in ["[音效]", "[停顿]"] for line in self.script):
print("⚠️ 检测到未生成的语音,正在生成...")
self.generate_all_voices()
# 创建临时目录
temp_dir = self.output_dir / "temp_combine"
temp_dir.mkdir(exist_ok=True)
# 生成音频列表文件(用于FFmpeg)
concat_file = temp_dir / "concat_list.txt"
with open(concat_file, 'w', encoding='utf-8') as f:
for i, line in enumerate(self.script):
if line.character == "[音效]":
# 音效处理(这里简化,实际需要加载音效文件)
silence_duration = line.duration
f.write(f"file 'silence_{i}.wav'\n")
# 创建静音文件
silence_audio = np.zeros(int(16000 * silence_duration), dtype=np.float32)
silence_path = temp_dir / f"silence_{i}.wav"
sf.write(silence_path, silence_audio, 16000)
elif line.character == "[停顿]":
# 停顿
silence_duration = line.duration
f.write(f"file 'silence_{i}.wav'\n")
silence_audio = np.zeros(int(16000 * silence_duration), dtype=np.float32)
silence_path = temp_dir / f"silence_{i}.wav"
sf.write(silence_path, silence_audio, 16000)
elif line.audio_file:
# 角色语音
f.write(f"file '{Path(line.audio_file).name}'\n")
# 复制到临时目录
import shutil
shutil.copy2(line.audio_file, temp_dir / Path(line.audio_file).name)
# 使用FFmpeg合并音频
output_path = self.output_dir / output_filename
try:
# 构建FFmpeg命令
cmd = [
'ffmpeg',
'-f', 'concat',
'-safe', '0',
'-i', str(concat_file),
'-c', 'copy',
str(output_path),
'-y' # 覆盖输出文件
]
print(f" 执行命令: {' '.join(cmd)}")
# 运行FFmpeg
result = subprocess.run(cmd, capture_output=True, text=True, check=True)
if result.returncode == 0:
print(f"✅ 音频合并完成: {output_path}")
# 添加淡入淡出效果
self._add_fade_effect(str(output_path))
return str(output_path)
else:
print(f"❌ FFmpeg错误: {result.stderr}")
return ""
except subprocess.CalledProcessError as e:
print(f"❌ FFmpeg执行失败: {str(e)}")
print(f" 错误输出: {e.stderr}")
return ""
except FileNotFoundError:
print("❌ 未找到ffmpeg,请确保已安装并添加到PATH")
return ""
def _add_fade_effect(self, audio_path: str, fade_in: float = 0.5, fade_out: float = 1.0):
"""添加淡入淡出效果"""
try:
audio = AudioSegment.from_file(audio_path)
# 添加淡入淡出
audio = audio.fade_in(int(fade_in * 1000)).fade_out(int(fade_out * 1000))
# 压缩动态范围(使音量更均匀)
audio = compress_dynamic_range(audio)
# 标准化音量
audio = normalize(audio)
# 保存
audio.export(audio_path, format="wav")
print(f"🎵 添加了音频效果: 淡入{fade_in}秒, 淡出{fade_out}秒")
except Exception as e:
print(f"⚠️ 音频效果处理失败: {str(e)}")
def generate_subtitles(self, format_type: str = "srt") -> str:
"""生成字幕文件"""
print("\n📝 生成字幕...")
if format_type == "srt":
return self._generate_srt_subtitles()
elif format_type == "ass":
return self._generate_ass_subtitles()
else:
return self._generate_srt_subtitles()
def _generate_srt_subtitles(self) -> str:
"""生成SRT字幕"""
subtitles = []
current_time = 0.0 # 秒
for i, line in enumerate(self.script, 1):
if line.character in ["[音效]", "[停顿]"]:
# 音效和停顿通常不在字幕中显示
current_time += line.duration
continue
start_time = current_time
end_time = current_time + line.duration
# 格式化时间
def format_time(seconds):
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
secs = seconds % 60
return f"{hours:02d}:{minutes:02d}:{secs:06.3f}".replace('.', ',')
subtitle = f"{i}\n"
subtitle += f"{format_time(start_time)} --> {format_time(end_time)}\n"
subtitle += f"{line.character}: {line.text}\n\n"
subtitles.append(subtitle)
current_time = end_time + 0.2 # 添加小间隔
# 保存文件
output_path = self.output_dir / "subtitles.srt"
with open(output_path, 'w', encoding='utf-8') as f:
f.writelines(subtitles)
print(f"✅ SRT字幕已生成: {output_path}")
return str(output_path)
def _generate_ass_subtitles(self) -> str:
"""生成ASS字幕(更丰富的格式)"""
ass_header = """[Script Info]
Title: 多角色剧情配音
ScriptType: v4.00+
PlayResX: 384
PlayResY: 288
ScaledBorderAndShadow: yes
[V4+ Styles]
Format: Name, Fontname, Fontsize, PrimaryColour, SecondaryColour, OutlineColour, BackColour, Bold, Italic, Underline, StrikeOut, ScaleX, ScaleY, Spacing, Angle, BorderStyle, Outline, Shadow, Alignment, MarginL, MarginR, MarginV, Encoding
Style: Default,Arial,20,&H00FFFFFF,&H000000FF,&H00000000,&H00000000,0,0,0,0,100,100,0,0,1,2,2,2,10,10,10,1
Style: Character1,Arial,18,&H00FF9900,&H000000FF,&H00000000,&H00000000,0,0,0,0,100,100,0,0,1,1,1,8,10,10,10,1
Style: Character2,Arial,18,&H0099FF00,&H000000FF,&H00000000,&H00000000,0,0,0,0,100,100,0,0,1,1,1,8,10,10,10,1
Style: Narrator,Arial,16,&H00CCCCCC,&H000000FF,&H00000000,&H00000000,0,1,0,0,100,100,0,0,1,1,1,2,10,10,10,1
[Events]
Format: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text
"""
current_time = 0.0
events = []
# 角色样式映射
style_map = {
"小明": "Character1",
"小红": "Character2",
"旁白": "Narrator",
}
for line in self.script:
if line.character in ["[音效]", "[停顿]"]:
current_time += line.duration
continue
start_time = current_time
end_time = current_time + line.duration
def format_ass_time(seconds):
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
secs = seconds % 60
return f"{hours:1d}:{minutes:02d}:{secs:05.2f}"
style = style_map.get(line.character, "Default")
event = f"Dialogue: 0,{format_ass_time(start_time)},{format_ass_time(end_time)},{style},,0,0,0,,{line.text}\n"
events.append(event)
current_time = end_time + 0.2
# 保存文件
output_path = self.output_dir / "subtitles.ass"
with open(output_path, 'w', encoding='utf-8') as f:
f.write(ass_header)
f.writelines(events)
print(f"✅ ASS字幕已生成: {output_path}")
return str(output_path)
def create_project_report(self) -> str:
"""创建项目报告"""
print("\n📊 生成项目报告...")
report = {
"project_name": "多角色剧情配音",
"created_at": datetime.now().isoformat(),
"output_directory": str(self.output_dir),
"characters": {name: asdict(char) for name, char in self.characters.items()},
"script_summary": {
"total_lines": len(self.script),
"dialogue_lines": len([l for l in self.script if l.character not in ["[音效]", "[停顿]"]]),
"effects": len([l for l in self.script if l.character == "[音效]"]),
"pauses": len([l for l in self.script if l.character == "[停顿]"]),
"estimated_duration": sum(l.duration for l in self.script),
},
"audio_files": [l.audio_file for l in self.script if l.audio_file],
}
# 保存JSON报告
json_path = self.output_dir / "project_report.json"
with open(json_path, 'w', encoding='utf-8') as f:
json.dump(report, f, ensure_ascii=False, indent=2)
# 创建Markdown报告
md_path = self.output_dir / "README.md"
with open(md_path, 'w', encoding='utf-8') as f:
f.write(f"# 剧情配音项目报告\n\n")
f.write(f"**生成时间**: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")
f.write(f"## 项目信息\n")
f.write(f"- 输出目录: `{self.output_dir}`\n")
f.write(f"- 总行数: {len(self.script)}\n")
f.write(f"- 预计时长: {sum(l.duration for l in self.script):.1f} 秒\n\n")
f.write(f"## 角色配置\n")
for name, char in self.characters.items():
f.write(f"### {name}\n")
f.write(f"- 类型: {char.speaker_type}\n")
f.write(f"- 语速: {char.speed}x\n")
f.write(f"- 音调: {char.pitch:+} 半音\n")
f.write(f"- 描述: {char.description}\n\n")
f.write(f"## 剧本摘要\n")
f.write(f"```\n")
for i, line in enumerate(self.script, 1):
prefix = f"{i:3d}. "
if line.character == "[音效]":
f.write(f"{prefix}[音效] {line.text}\n")
elif line.character == "[停顿]":
f.write(f"{prefix}[停顿] {line.duration:.1f}秒\n")
else:
f.write(f"{prefix}{line.character}: {line.text}\n")
f.write(f"```\n")
print(f"✅ 项目报告已生成:")
print(f" - {json_path}")
print(f" - {md_path}")
return str(json_path)
def cleanup_temp_files(self):
"""清理临时文件"""
temp_dir = self.output_dir / "temp_audio"
if temp_dir.exists():
import shutil
shutil.rmtree(temp_dir)
print("🧹 已清理临时音频文件")
temp_combine_dir = self.output_dir / "temp_combine"
if temp_combine_dir.exists():
import shutil
shutil.rmtree(temp_combine_dir)
print("🧹 已清理临时合并文件")
# ==================== 示例使用 ====================
def create_sample_script() -> str:
"""创建示例剧本"""
script = """
旁白: 在一个阳光明媚的早晨,学校图书馆里静悄悄的。
[停顿] 1.0
小明: 哇,这本书真有意思!小红你快来看!
小红: 什么书呀?让我看看。
[音效] page_turn
小红: 哦,是关于魔法王国的故事书!
小明: 对啊,里面说有一个会说话的魔法书!
老师: 孩子们,不要大声喧哗,这里是图书馆。
小明: 对不起,老师。我们太兴奋了。
小红: 老师,这本书真的很有趣!
老师: 嗯,确实是个好故事。不过记住,保持安静。
[停顿] 0.5
旁白: 就在这时,奇怪的事情发生了...
[音效] magic_sparkle
小明: 啊!书在发光!
小红: 它...它在说话!
魔法书: 你们好,孩子们。我是魔法王国的向导。
老师: 这...这怎么可能?
魔法书: 跟我来吧,带你们去一个神奇的世界!
[音效] portal_open
旁白: 于是,一段奇妙的冒险开始了...
[停顿] 2.0
"""
return script
def main():
"""主程序:运行完整示例"""
print("=" * 70)
print("🎬 自媒体多角色剧情配音系统 - SpeechT5版本")
print("=" * 70)
# 创建输出目录
output_dir = "my_drama_project"
# 初始化系统
drama_system = DramaVoiceSystem(output_dir)
# 设置默认角色
drama_system.setup_default_characters()
# 显示可用说话人
print("\n📢 测试SpeechT5系统...")
drama_system.tts.list_available_speakers()
# 创建示例剧本
print("\n📜 创建示例剧本...")
script = create_sample_script()
print(script)
# 解析剧本
drama_system.parse_script(script)
# 生成所有语音
drama_system.generate_all_voices()
# 合并音频
audio_output = drama_system.combine_audio("my_drama_final.wav")
# 生成字幕
srt_subtitles = drama_system.generate_subtitles("srt")
ass_subtitles = drama_system.generate_subtitles("ass")
# 生成项目报告
drama_system.create_project_report()
# 清理临时文件
drama_system.cleanup_temp_files()
print("\n" + "=" * 70)
print("🎉 剧情配音制作完成!")
print("=" * 70)
if audio_output:
print(f"\n🎵 最终音频: {audio_output}")
print(f"📝 字幕文件:")
print(f" - SRT格式: {srt_subtitles}")
print(f" - ASS格式: {ass_subtitles}")
print(f"📄 项目报告: {output_dir}/README.md")
print(f"📊 详细数据: {output_dir}/project_report.json")
print("\n🚀 下一步:")
print("1. 使用视频编辑软件导入音频和字幕")
print("2. 添加背景图片或视频")
print("3. 导出为完整的视频作品")
return drama_system
def quick_test():
"""快速测试SpeechT5功能"""
print("\n⚡ 快速测试模式")
# 初始化TTS
tts = SpeechT5VoiceSystem()
# 测试语音合成
test_texts = [
"你好,这是一个语音合成测试。",
"Hello, this is a text-to-speech test.",
"欢迎使用多角色剧情配音系统。",
]
for i, text in enumerate(test_texts, 1):
print(f"\n测试 {i}: {text}")
audio = tts.synthesize(
text=text,
speaker_type="female_young",
speed=1.0,
pitch_shift=0.0,
output_file=f"test_{i}.wav"
)
if audio is not None:
print(f"✅ 成功生成 {len(audio)/16000:.2f} 秒音频")
print("\n✅ 快速测试完成")
# ==================== Gradio Web界面 ====================
def create_web_interface():
"""创建Gradio Web界面"""
try:
import gradio as gr
# 初始化系统
drama_system = DramaVoiceSystem("web_drama_output")
drama_system.setup_default_characters()
def synthesize_voice(text, character, speed, pitch):
"""语音合成函数"""
if character not in drama_system.characters:
return None, "角色不存在"
char_config = drama_system.characters[character]
# 生成临时文件
import tempfile
temp_file = tempfile.NamedTemporaryFile(suffix=".wav", delete=False)
temp_path = temp_file.name
try:
audio = drama_system.tts.synthesize(
text=text,
speaker_type=char_config.speaker_type,
speed=float(speed),
pitch_shift=float(pitch),
output_file=temp_path
)
return temp_path, f"✅ 合成成功: {len(audio)/16000:.2f}秒"
except Exception as e:
return None, f"❌ 合成失败: {str(e)}"
def create_drama_script(script_text):
"""创建剧情音频"""
try:
drama_system.parse_script(script_text)
audio_path = drama_system.combine_audio("web_drama.wav")
if audio_path:
return audio_path, "✅ 剧情音频生成成功"
else:
return None, "❌ 生成失败"
except Exception as e:
return None, f"❌ 错误: {str(e)}"
# 创建界面
with gr.Blocks(title="多角色剧情配音系统", theme=gr.themes.Soft()) as demo:
gr.Markdown("# 🎬 SpeechT5多角色剧情配音系统")
gr.Markdown("基于Microsoft SpeechT5模型的专业级剧情配音工具")
with gr.Tab("🎤 单句合成"):
with gr.Row():
with gr.Column():
text_input = gr.Textbox(
label="输入文本",
placeholder="请输入要合成的文本...",
lines=3,
value="欢迎使用剧情配音系统"
)
character_select = gr.Dropdown(
choices=list(drama_system.characters.keys()),
value="旁白",
label="选择角色"
)
with gr.Row():
speed_slider = gr.Slider(
minimum=0.5, maximum=2.0, value=1.0,
step=0.1, label="语速"
)
pitch_slider = gr.Slider(
minimum=-5, maximum=5, value=0.0,
step=0.5, label="音调调整"
)
synth_btn = gr.Button("合成语音", variant="primary")
with gr.Column():
audio_output = gr.Audio(label="生成的语音", type="filepath")
status_output = gr.Textbox(label="状态", lines=2)
synth_btn.click(
synthesize_voice,
inputs=[text_input, character_select, speed_slider, pitch_slider],
outputs=[audio_output, status_output]
)
with gr.Tab("📜 剧情制作"):
with gr.Row():
with gr.Column(scale=2):
script_input = gr.Textbox(
label="输入剧本",
placeholder="格式:角色: 台词\n[停顿] 时间\n[音效] 音效名",
lines=10,
value=create_sample_script()
)
create_btn = gr.Button("生成剧情音频", variant="primary", size="lg")
with gr.Column(scale=1):
drama_audio_output = gr.Audio(label="剧情音频", type="filepath")
drama_status = gr.Textbox(label="状态", lines=3)
create_btn.click(
create_drama_script,
inputs=[script_input],
outputs=[drama_audio_output, drama_status]
)
with gr.Tab("⚙️ 系统设置"):
gr.Markdown("### 系统信息")
device_info = gr.Textbox(
label="设备信息",
value=f"计算设备: {drama_system.tts.device}"
)
gr.Markdown("### 角色管理")
characters_info = gr.Dataframe(
value=pd.DataFrame([
{"角色": name, "类型": char.speaker_type, "语速": char.speed}
for name, char in drama_system.characters.items()
]),
label="当前角色配置"
)
gr.Markdown("---")
gr.Markdown("**基于Microsoft SpeechT5模型** | 支持中英文多角色配音")
return demo
except ImportError:
print("⚠️ 未安装gradio,请运行: pip install gradio")
return None
except Exception as e:
print(f"❌ 创建Web界面失败: {str(e)}")
return None
# ==================== 主程序入口 ====================
if __name__ == "__main__":
print("选择运行模式:")
print("1. 完整示例(生成完整剧情)")
print("2. 快速测试(测试语音合成)")
print("3. Web界面(交互式操作)")
print("4. 批量处理(处理剧本文件)")
try:
choice = input("\n请输入选择 (1-4): ").strip()
if choice == "1":
# 运行完整示例
drama_system = main()
# 询问是否打开Web界面
open_web = input("\n是否打开Web界面进行进一步编辑? (y/n): ").lower()
if open_web == 'y':
demo = create_web_interface()
if demo:
demo.launch(server_name="127.0.0.1", server_port=7860)
elif choice == "2":
# 快速测试
quick_test()
elif choice == "3":
# Web界面
demo = create_web_interface()
if demo:
print("\n🌐 启动Web界面中...")
print("访问地址: http://127.0.0.1:7860")
demo.launch(server_name="127.0.0.1", server_port=7860)
elif choice == "4":
# 批量处理模式
script_file = input("请输入剧本文件路径: ").strip()
if os.path.exists(script_file):
drama_system = DramaVoiceSystem("batch_drama_output")
drama_system.setup_default_characters()
drama_system.load_script_from_file(script_file)
drama_system.generate_all_voices()
drama_system.combine_audio()
drama_system.generate_subtitles()
drama_system.create_project_report()
print("✅ 批量处理完成")
else:
print("❌ 文件不存在")
else:
print("❌ 无效选择")
except KeyboardInterrupt:
print("\n\n👋 用户中断,程序退出")
except Exception as e:
print(f"\n❌ 程序运行出错: {str(e)}")