在 Kubernetes 集群中,节点(Node)是运行 Pod 的基础单元。节点维护是保证集群稳定性和高可用性的关键操作。
本文直接给你一套 可落地、实战验证过 的节点维护方案。
1 节点维护前检查
确认节点健康
kubectl get nodes节点状态应为 Ready,否则维护可能会带来风险。
清楚节点上的 Pod
kubectl get pods -A -o wide | grep <NODE_NAME>
kubectl get pods -A -o wide | grep k8s-node2重点了解哪些是关键业务 Pod,哪些可以安全迁移,如果有Pod使用了Local PV,要慎重。
挑选维护时间 尽量选择业务低峰期进行维护,避免影响用户体验。
2 先"冻结"节点
维护前,先让腾空节点,不再接收新 Pod:
kubectl cordon <NODE_NAME>
kubectl cordon k8s-node2这样,新的 Pod 不会调度到这台节点上,已有的Pod不受影响,保证你维护时不会意外影响业务。
3 安全驱逐Pod
接下来,把节点上的 Pod 安全迁移到其他节点:
kubectl drain <NODE_NAME> --ignore-daemonsets --delete-emptydir-data-
--ignore-daemonsets:DaemonSet 管理的 Pod 不驱逐 -
--delete-emptydir-data:删除临时数据目录(确保无重要数据)
提示:关键业务 Pod 必须有副本,否则迁移可能导致服务中断。
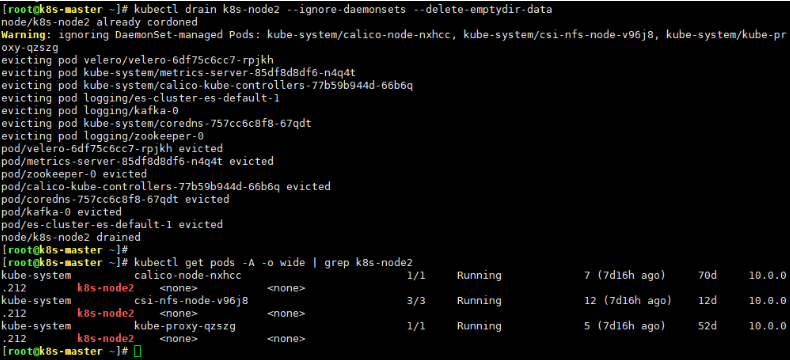
可以看到daemonset类型的Pod没有被驱逐掉,如果使用了Local PV的Pod,要慎重!
驱逐完要查看一下业务是否正常再进行节点维护工作,这一点很重要。
drain 有可能卡住的常见原因:
| 原因 | 表现 | 解决方法 |
|---|---|---|
| Pod 副本数=1 | drain 不动 | 先扩容 |
| 配置了 PDB | PDB 阻塞 | 调整 PDB 或加副本 |
| Local PV | 无法迁移 | 特殊规划 |
| StatefulSet | 默认不驱逐 | 需确认业务可停机 |
| DaemonSet | 不迁移 | 使用 --ignore-daemonsets |
这也是为什么很多团队 drain 一次,要等半小时。
4 节点维护
节点"空"了,你就可以放心操作了:
-
升级操作系统或内核
-
更新 Docker 或 containerd
-
硬件巡检:磁盘、内存、网络
5 恢复节点
维护完成后,让节点回到集群中:
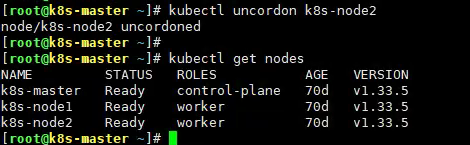
kubectl uncordon k8s-node2
kubectl get nodes
kubectl get pods -o wide-
uncordon:取消封锁,节点重新接收 Pod -
检查节点和 Pod 状态,确认一切正常
6 节点维护注意事项
-
数据持久化
所有重要数据必须存储在 PVC 或外部存储,避免
emptyDir数据丢失。 -
高可用部署
关键业务 Pod 必须有副本或分布在多节点上,单点维护不会中断服务。
-
滚动维护
生产环境不要一次停掉所有节点,分批维护,降低风险。
-
DaemonSet 和静态 Pod
维护前了解节点上的 DaemonSet 和静态 Pod,它们不会被
drain自动迁移,需要特殊处理。 -
资源紧张节点谨慎操作
节点资源接近满负荷时,迁移 Pod 可能失败,最好先释放部分负载。
K8S 节点维护核心就 4 步:
cordon → drain → 维护 → uncordon