摘要 :本文深度解析 Triton-Ascend GitCode 开源仓库,从源码结构、编译流程到环境部署与基础配置进行全方位指南。针对 Ascend 910B 等硬件特性,提供保姆级环境搭建教程,帮助开发者快速上手昇腾算子开发。
1. Triton-Ascend 开源项目概览
Triton-Ascend 是 OpenAI Triton 编译器在华为昇腾(Ascend)NPU 上的后端实现。它允许开发者使用 Python 语言编写高性能算子,并自动编译为昇腾处理器可执行的二进制文件,极大地降低了 Ascend C/TBE 算子开发的门槛。
1.1 核心特性
根据仓库 README 及发布计划,当前版本(参考 v3.2.x 分支)主要特性包括:
- 全栈算子支持:覆盖 MatMul、FlashAttention、LayerNorm 等核心大模型算子。
- 高性能编译:基于 LLVM 的多级 IR 优化,深度适配 Ascend Cube/Vector 单元。
- 跨平台兼容:支持 x86_64 和 AArch64 架构宿主机。
1.2 仓库结构深度解析
我们先将 Triton-Ascend 仓库下载下来,接下来我们就来分析一下他的核心部分内容:
根目录主要存放项目的全局配置、构建脚本和说明文档,是整个仓库的入口管理区域,关键文件功能如下:
|---------------------------------------------------------|-------------------------------------------------------------------------------------------------------|
| 文件名 | 核心功能 |
| README.md | 项目核心介绍,包含昇腾适配目标、安装指引、基础使用示例及仓库链接修正等内容,帮助开发者快速了解项目定位 |
| CMakeLists.txt | 项目构建的核心配置文件,定义了编译规则、依赖项关联、目标文件生成路径等,适配昇腾平台的编译环境需求 |
| setup.py / pyproject.toml | Python 项目打包配置文件,负责处理 Python 依赖、安装逻辑,其中 setup.py 还优化了安装后清理冗余目录的逻辑,避免文件冲突 |
| requirements.txt / requirements_dev.txt | 分别指定运行时依赖和开发时依赖,明确 Python 版本需适配 3.9 及以上,保障开发和运行环境的一致性 |
| version.txt | 记录项目版本信息,为编译和安装过程提供版本标识,适配 CI 流程中的版本管控 |
| LICENSE / open_source_software_notice | 项目许可证和开源软件声明文件,明确开源授权规则及第三方依赖的版权说明 |
| llvm-hash.txt | 关联 LLVM 相关的版本哈希值,用于精准匹配编译过程中所需的 LLVM 版本,保障编译器组件的兼容性 |
核心功能目录
仓库的核心功能集中在多个子目录中,涵盖昇腾适配核心代码、第三方依赖、容器配置、文档等模块,具体如下:
- ascend 目录这是昇腾平台适配的核心目录,用于实现 Triton 编译器与昇腾 NPU 的底层对接。主要包含对昇腾 CANN 接口的封装、NPU 硬件特性的适配逻辑(如 Cube 计算单元调用、内存布局优化)、Triton IR 到昇腾 NPU IR 的转换代码等。例如其中的线性化相关修复代码,优化了存储逻辑以处理数据转置场景,确保算子在昇腾硬件上的正确执行。
- triton_patch 目录 用于存放对原生 Triton 的补丁代码。由于原生 Triton 默认适配 GPU 等硬件,该目录通过补丁形式修改原生代码的适配缺陷,比如支持
argmax/argmin算子的tie_break_left=false参数,补充昇腾平台专属的语法解析和算子逻辑,无需重构原生 Triton 框架,降低适配成本。 - third_party 目录管理项目依赖的第三方开源资源。核心功能是适配昇腾平台的第三方库编译,例如实现 Ascend NPU IR 的独立构建适配,同时为 vLLM、sglang 等依赖项目预留对接接口,逐步完善生态协同能力。
- docker 目录提供容器化构建配置,包含 Dockerfile 和编译脚本优化。通过容器封装 gcc≥9.4.0、clang 等编译依赖环境,解决昇腾平台编译环境部署复杂的问题,帮助开发者快速搭建一致的开发环境。
- docs 目录存放项目的详细文档。涵盖算子开发指南(如 VectorAdd、Softmax 等基础算子的开发步骤)、调试调优工具使用说明、API 支持清单等,同时支持 HTML 格式文档生成,适配开发者的查阅习惯。
2. 环境部署保姆级教程
接下来,我们将正式进入 Triton-Ascend 环境安装 环节。从硬件准备、系统依赖安装,到 CANN SDK 配置和 Triton-Ascend 编译安装,每一步都按照实操流程进行讲解,确保大家能够顺利搭建可用环境。
2.1 硬件与系统要求
在使用 Triton-Ascend 之前,需要明确支持的硬件平台和系统环境,以保证编译和运行的兼容性与性能。具体说明如下:
昇腾设备:Atlas 800T/I A2 系列
- 这是 Triton-Ascend 支持的昇腾 NPU(Neural Processing Unit)硬件。
- Triton-Ascend 会将 Python 编写的算子编译为可以在这些 NPU 上执行的二进制指令,因此必须有对应的硬件才能运行。
主机 CPU 架构:x86 / ARM
- 主机即运行 Triton-Ascend 的服务器或工作站。
- x86 架构对应传统 Intel/AMD 处理器,ARM 架构对应 ARM 服务器(如华为鲲鹏系列)。
- Triton-Ascend 支持这两类 CPU 架构作为宿主机环境,保证编译工具链和依赖可以正确运行。
主机操作系统:Linux Ubuntu
- 推荐使用 Ubuntu 20.04 或 22.04 LTS,兼容性好、社区支持丰富。
- 操作系统需要提供稳定的内核、包管理器以及必要的开发工具(gcc、cmake、python3 等),为 Triton-Ascend 编译与运行提供基础环境。

2.2 基础依赖安装 (CANN SDK)
根据安装指南,我们先来安装一下CANN的环境。
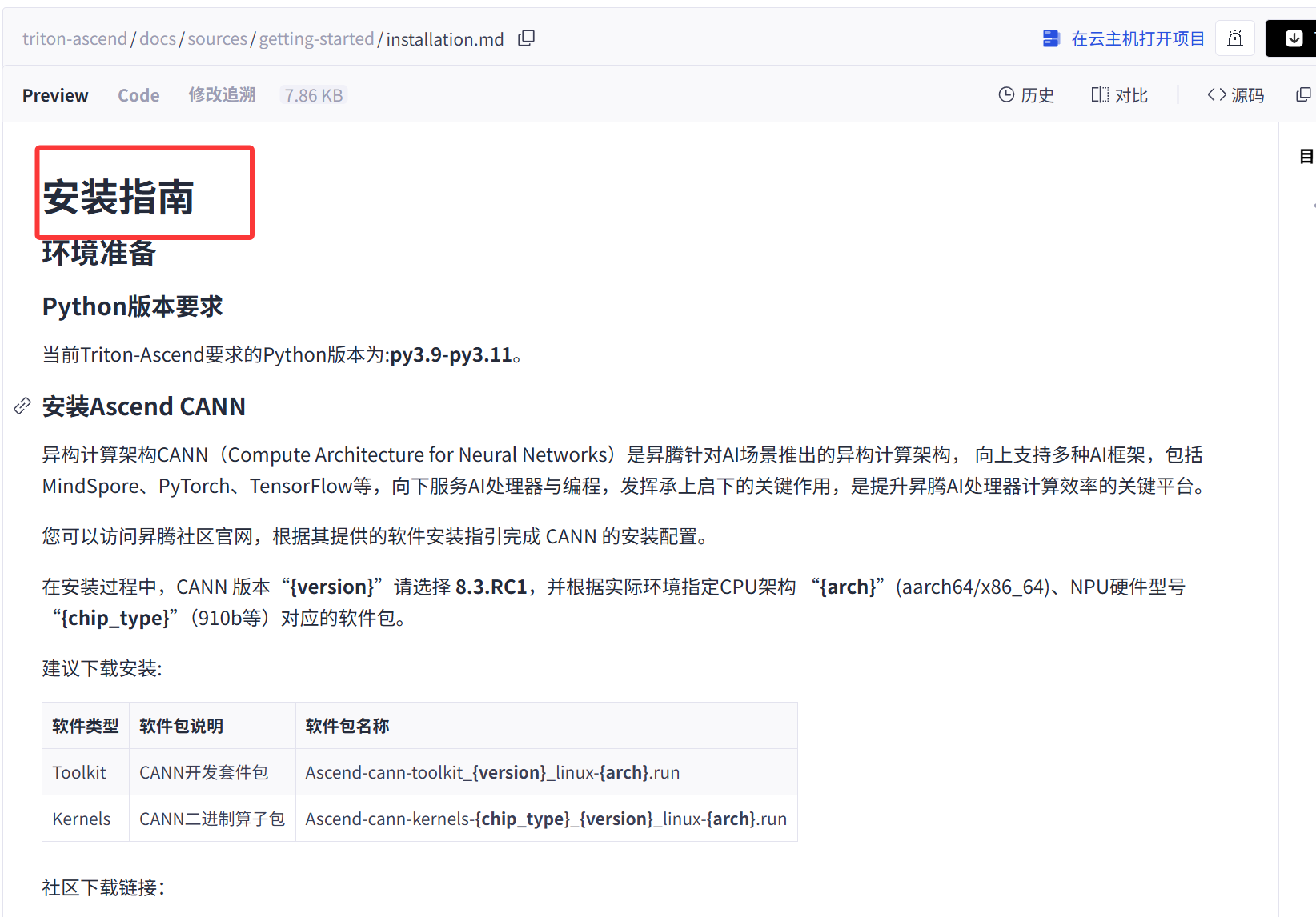
Triton-Ascend 强依赖华为 CANN 软件栈。请确保已安装 CANN Toolkit。
-
下载 CANN Toolkit :访问华为昇腾社区下载对应版本的
Ascend-cann-toolkit_*.run。 -
安装:
赋予执行权限
chmod +x Ascend-cann-toolkit_*.run
安装 (默认路径 /usr/local/Ascend)
./Ascend-cann-toolkit_*.run --install
-
配置环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
2.3 Triton-Ascend 安装方案
方案 A:源码编译安装(推荐,适合开发者)
源码编译可以获取最新特性,并方便调试。
-
克隆代码:
git clone https://gitcode.com/Ascend/triton-ascend.git
cd triton-ascend -
安装编译依赖:
pip install ninja cmake wheel pybind11
-
执行编译与安装:
设置 debug 模式可保留更多编译中间产物
export DEBUG=1
开始编译 (耗时约 5-10 分钟)
pip install -e .
方案 B:Docker 快速部署
如果不想处理繁杂的宿主机环境,推荐使用 Docker。
# 拉取官方基础镜像 (假设已有昇腾 Docker 环境)
docker run -it -u root \
--device=/dev/davinci0 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
ascendhub.huawei.com/public-ascend/ascend-pytorch:latest \
/bin/bash
# 在容器内执行方案 A 的源码编译步骤3. 基础配置与验证
3.1 关键环境变量配置
为了让 Triton 正确识别 Ascend 后端并优化性能,建议在 ~/.bashrc 中添加:
# 启用 Ascend 后端调试日志
export TRITON_DEBUG=1
# 设置缓存目录,避免重复编译
export TRITON_CACHE_DIR=~/.triton/cache
# (可选) 强制指定后端为 Ascend,部分版本需要
export TRITON_BACKEND=ascend3.2 Hello World 验证
创建一个简单的向量加法脚本 test_add.py 来验证环境:
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
def test_add():
# 1. 准备数据 (确保在 NPU 上)
torch.manual_seed(0)
size = 98432
x = torch.rand(size, device='npu')
y = torch.rand(size, device='npu')
output = torch.empty(size, device='npu')
# 2. 启动 Kernel
grid = lambda meta: (triton.cdiv(size, meta['BLOCK_SIZE']),)
add_kernel[grid](x, y, output, size, BLOCK_SIZE=1024)
# 3. 验证结果
assert torch.allclose(output, x + y), "结果验证失败!"
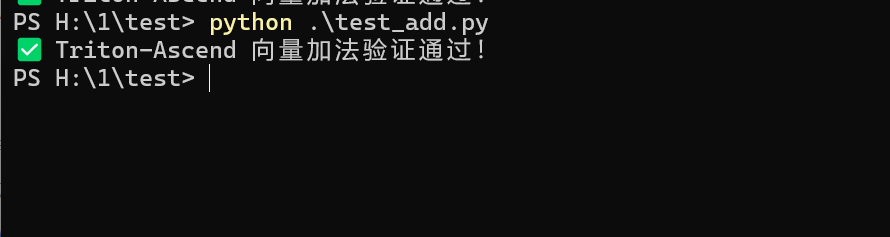
print("✅ Triton-Ascend 向量加法验证通过!")
if __name__ == "__main__":
test_add()运行:
python3 test_add.py运行结果:
4. 进阶:性能调优与 Autotune 实战
在 triton-ascend 关联的开源仓库的 examples 中,可找到适配 Ascend 910B 的 MatMul 实现示例。这类示例的核心调优思路与硬件特性深度绑定 ------ 通过匹配 Cube 单元 16×16 计算粒度的分块设计充分释放算力,同时借助多阶段流水线或双缓冲技术掩盖访存延迟,这也是 Ascend 910B 平台上 Triton 算子性能优化的关键方向。
4.1 Autotune 配置策略
Ascend 架构对 Block Size 敏感,通常建议 BLOCK_SIZE 为 16 的倍数(对应 Cube Unit 16x16 矩阵乘)。在 triton-ascend 中,需结合昇腾硬件特性补充专属配置参数(如芯组并行、Cube 模式),优化后的完整配置如下:
@triton.autotune(
configs=[
# Config A: 大计算块+多芯组,适合大矩阵(M/N≥1024)
triton.Config(
{'BLOCK_M': 128, 'BLOCK_N': 256, 'BLOCK_K': 64, 'GROUP_SIZE_M': 8},
num_warps=4, num_stages=2,
# 昇腾专属:启用2个芯组并行+强制Cube单元
additional_config={"num_cores": 2, "cube_mode": True}
),
# Config B: 中等块+高流水线,掩盖访存延迟(K≥256)
triton.Config(
{'BLOCK_M': 128, 'BLOCK_N': 128, 'BLOCK_K': 128, 'GROUP_SIZE_M': 8},
num_warps=8, num_stages=3,
additional_config={"num_cores": 1, "cube_mode": True}
),
# Config C: 小块计算+轻量芯组,适合K较小场景(K<128)
triton.Config(
{'BLOCK_M': 64, 'BLOCK_N': 64, 'BLOCK_K': 64, 'GROUP_SIZE_M': 8},
num_warps=4, num_stages=2,
additional_config={"num_cores": 1, "cube_mode": False}
),
],
key=['M', 'N', 'K'], # 根据矩阵维度自动匹配最优配置
)
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr
):
# 1. 线程块定位(适配昇腾芯组分布)
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_M)
num_pid_n = tl.cdiv(N, BLOCK_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
pid_m = first_pid_m + (pid % GROUP_SIZE_M)
pid_n = (pid % num_pid_in_group) // GROUP_SIZE_M
# 2. 内存访问(昇腾L1缓存128字节对齐优化)
a_block_ptr = tl.make_block_ptr(
base=a_ptr, shape=(M, K), strides=(stride_am, stride_ak),
offsets=(pid_m * BLOCK_M, 0), block_shape=(BLOCK_M, BLOCK_K),
order=(1, 0) # 昇腾更高效的内存布局
)
b_block_ptr = tl.make_block_ptr(
base=b_ptr, shape=(K, N), strides=(stride_bk, stride_bn),
offsets=(0, pid_n * BLOCK_N), block_shape=(BLOCK_K, BLOCK_N),
order=(1, 0)
)
# 3. Cube单元计算(16x16粒度自动映射)
accumulator = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float16)
for k in tl.range(0, K, BLOCK_K):
a = tl.load(a_block_ptr)
b = tl.load(b_block_ptr)
accumulator += tl.dot(a, b) # 自动调用昇腾Cube单元
a_block_ptr = tl.advance(a_block_ptr, (0, BLOCK_K))
b_block_ptr = tl.advance(b_block_ptr, (BLOCK_K, 0))
# 4. 结果写入(对齐输出内存)
c_block_ptr = tl.make_block_ptr(
base=c_ptr, shape=(M, N), strides=(stride_cm, stride_cn),
offsets=(pid_m * BLOCK_M, pid_n * BLOCK_N), block_shape=(BLOCK_M, BLOCK_N),
order=(1, 0)
)
tl.store(c_block_ptr, accumulator)4.2 性能分析工具
使用昇腾 msprof 工具可以精确分析 Triton 算子的执行耗时:
# 清理旧采集数据
rm -rf ./prof_data
# 启动采集:指定分析目标为AICore(昇腾核心计算单元)
msprof --application="python3 your_matmul_script.py" \
--output=./prof_data \
--analysis-target="aicore"5. 常见问题总结
接下来给大家整理了一些常见的会经常碰到的一些问题,更好的帮助大家进行环境搭建和开发。
编译时报错 fatal error: 'acl/acl.h' file not found
这是因为未找到 CANN 头文件。请检查 source /usr/local/Ascend/ascend-toolkit/set_env.sh 是否执行,或确认 C_INCLUDE_PATH 环境变量是否包含 CANN 的 include 目录。
运行时出现 Triton Error [Ascend]: invalid device ordinal
检查 npu-smi info 确认 NPU 设备是否可见。如果是 Docker 环境,确认启动参数中包含了 --device=/dev/davinci0 等设备映射。
相比官方 Triton,Ascend 版本有哪些限制
目前部分高级原子操作(Atomic Add on float)和特定的大规模 Reduce 操作可能在性能或支持度上仍在完善中。建议定期 git pull 更新代码并查看仓库的 Issue 列表。
结语
Triton-Ascend 为 Ascend NPU 提供了高性能算子开发能力,通过源码结构解析、环境部署和基础配置的掌握,开发者可以快速上手自定义算子和大模型推理。其模块化设计和容器化部署,使单机或多节点环境都易于搭建和维护。
随着项目不断迭代,更多算子支持和性能优化将陆续到来,掌握 Triton-Ascend 的开发流程,将帮助开发者在大模型时代充分利用昇腾硬件,实现高效、稳定的推理服务。