研究方向:Image Captioning
1.论文介绍
本文提出了LLaViT,一种扩展的视觉Transformer,它通过三个关键修改使LLM能够同时充当视觉编码器:
(1) 学习针对视觉模态的独立QKV投影;
(2) 实现视觉标记的双向注意力;
(3) 结合视觉编码器全局和局部视觉表示。
让LLM不仅作为语言模型,还作为一个强大的视觉编码器。
2.方法介绍
2.1 背景
LLM的第 层的多模态输入表示为三个不同的序列的组合:
(1)系统提示的m个文本令牌,;
(2)视觉信息的n个视觉令牌,;
(3)用户提示的o个文本令牌,。
在任何给定的层级 ,
、
和
被处理为一个单一的 N=m+n+o 长度序列。
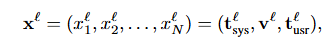
使用视觉编码器g提取视觉块特征,然后通过一个MLP投影将它们映射到LLM的嵌入空间
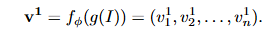
在输入层: 计算输入视觉标记 与词嵌入
的余弦相似度:
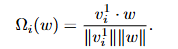
为每个视觉标记 提取前 k 个相似词汇
在输出层: 取 LLM 对每个视觉 token 产生的输出 logit 向量 提取出前 k 个词表征(从 LLM 的最终输出读出模型认为该视觉 token 最可能对应哪些词)
把两层的结果可视化:

在输入层,视觉 token 与词向量的相似度通常很低且最接近的词常常是无关的奇怪符号,说明视觉 token 在原始输入空间并没有很好地对齐到文本词表。
但在输出层,LLM 给出的一些 top-k 词实际上是和对应图像 patch 内容语义相关的。
表明LLM在一定程度上可以将视觉标记翻译成文本,认为LLM内部视觉标记转换的质量将对MLLM的整体能力产生影响。
2.2 将视觉Transformer扩展到LLM
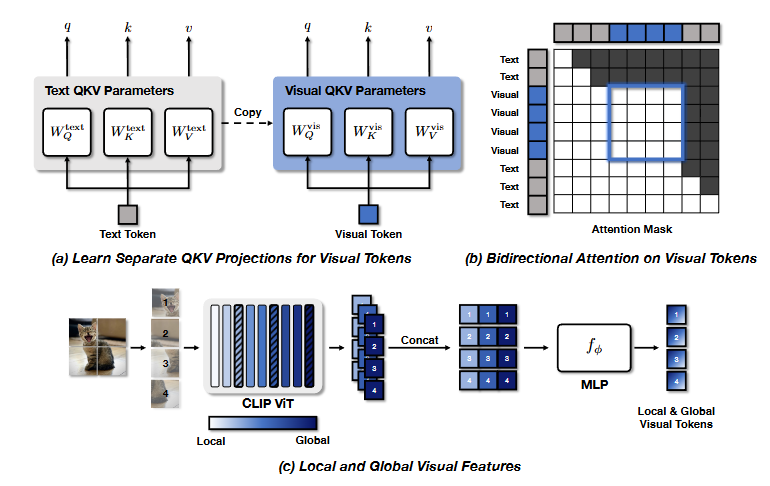
学习独立的 QKV 投影:
为视觉 token 单独设计查询、键和值(QKV)投影参数,避免将文本任务中的 QKV 参数直接应用于视觉 token,从而更有效地捕获视觉信息。
启用双向注意力机制:
传统的 LLM 使用因果注意力,允许后面的视觉 token 关注前面的视觉 token。在图像中,视觉 token 并没有时间顺序。通过启用视觉 token 间的双向注意力,消除了这种限制。
结合局部和全局视觉特征:
过提取 CLIP 模型多个层次的视觉特征,将低级别的细节和高级别的语义信息结合起来。然后将这些特征在特征维度上拼接并投影到 LLM 的输入空间中。