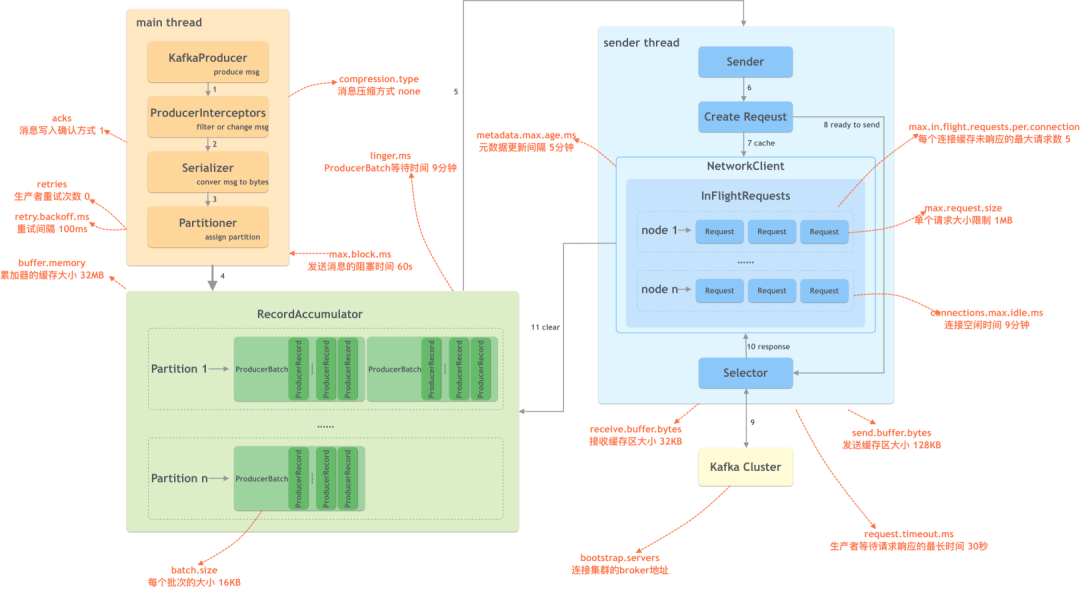
1 整体架构

在生产端主要有两个线程:main和sender,两者通过共享内存RecordAccumulator通信。
各步骤如下:
- KafkaProducer: 创建消息;
- 生产者拦截器: 在消息发送之前做一些准备工作,比如过滤不符合要求的消息、修改消息的内容等;
- 序列化器: 将消息转换成字节数组的形式;
- 分区器: 计算该消息的目标分区,然后数据会存储在RecordAccumulator中;
- 发送线程:
- 获取数据进行发送;
- 创建具体的请求;
- 如果请求过多,会将部分请求缓存起来;
- 将准备好的请求进行发送;
- 发送到kafka集群;
- 接收响应;
- 清理数据。
2 生产者参数
本部分参数解释由大模型生成,不一定正确,仅参考
2.1 acks(确认机制)
控制消息持久性的级别
python
# acks=0: 生产者不等待确认,吞吐量最高,但可能丢失数据
'acks': 0
# acks=1: 等待leader确认(默认),平衡了可靠性和性能
'acks': 1
# acks=all: 等待所有ISR副本确认,最可靠但延迟最高
'acks': 'all'2.2 compression.type(压缩类型)
消息压缩算法,减少网络传输和存储
python
# 不压缩
'compression.type': 'none'
# gzip压缩(压缩率高,但CPU消耗大)
'compression.type': 'gzip'
# snappy压缩(速度快,压缩率适中)
'compression.type': 'snappy'
# lz4压缩(性能最好的压缩算法之一)
'compression.type': 'lz4'
# zstd压缩(最新的高效压缩算法)
'compression.type': 'zstd'2.3 retries(重试次数)
发送失败时的重试次数
python
# 重试3次(包含初始发送,总共4次尝试)
'retries': 3
# 无限重试(谨慎使用)
'retries': 21474836472.4 retry.backoff.ms(重试间隔)
重试之间的等待时间(毫秒)
python
# 每次重试等待100毫秒
'retry.backoff.ms': 1002.5 max.block.ms(最大阻塞时间)
生产者阻塞等待的最大时间
python
# 当缓冲区满或元数据不可用时,最多阻塞60秒
'max.block.ms': 600002.6 buffer.memory(缓冲区内存)
生产者缓冲区的总字节数
python
# 默认32MB
'buffer.memory': 33554432 # 32MB
# 高吞吐场景可以增大缓冲区
'buffer.memory': 67108864 # 64MB2.7 batch.size(批次大小)
定义:
- 每个批次的最大字节数,生产者将发送到同一分区的多条消息合并成一个批次(batch)。
作用:
- 将多个消息合并成一个批次,减少网络请求次数,提高吞吐量。
- 当批次达到设置的大小时,批次会被发送。
注意:
- 如果批次大小设置得较大,需要等待更多消息填满批次,可能会增加延迟。
- 如果设置得过小,可能导致批次频繁发送,增加网络开销。
默认值:
- 16KB (16384字节)
python
# batch.size 工作原理示意图
生产者内存:
┌─────────────────────────────────────────────────────────┐
│ Producer Buffer Memory │
│ ┌───────────────────────────────────────────────────┐ │
│ │ batch.size = 16KB (默认) │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐│ │
│ │ │ 分区0批次 │ │ 分区1批次 │ │ 分区2批次 ││ │
│ │ │ 16KB上限 │ │ 16KB上限 │ │ 16KB上限 ││ │
│ │ │ │ │ │ │ ││ │
│ │ │ 消息1,2,3...│ │ 消息1,2,3...│ │ 消息1,2,3...││ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘│ │
│ │ │ │
│ │ 当批次满或linger.ms到期时发送 │ │
│ └───────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
# 配置示例
config = {
'batch.size': 16384, # 16KB
# 每个分区都有自己的批次缓冲区
# 当分区0的批次达到16KB时,会发送这个批次
}2.8 linger.ms
定义:
- 批次等待更多消息加入的时间(毫秒)。
作用:
- 用于控制一个batch从创建开始到发送到发送线程的的等待时间。 让生产者在发送批次之前等待一段时间,以便积累更多的消息到同一个批次中,从而提高吞吐量。
基本工作流程:
-
python
# 假设配置: config = { 'batch.size': 16384, # 16KB 'linger.ms': 100 # 100毫秒 } # 生产者工作流程: 1. 当第一条消息到达某个分区的批次缓冲区时,启动一个计时器(100ms) 2. 在100ms内,后续到达该分区的消息会被添加到同一个批次 3. 触发条件(满足任何一个即发送批次): a) 批次大小达到16KB → 立即发送 b) 计时器到达100ms → 发送当前批次中的所有消息 c) 其他条件(如缓冲区满、flush调用等)
2.9 metadata.max.age.ms
元数据: 指客户端生产者需要知道的集群信息:
python
元数据结构示例:
{
"brokers": [
{"id": 1, "host": "broker1", "port": 9092},
{"id": 2, "host": "broker2", "port": 9092},
{"id": 3, "host": "broker3", "port": 9092}
],
"topics": [
{
"name": "orders",
"partitions": [
{
"id": 0,
"leader": 1, # 分区主副本在broker1
"replicas": [1, 2, 3],
"isr": [1, 2] # 同步副本列表
},
{
"id": 1,
"leader": 2, # 分区主副本在broker2
"replicas": [2, 3, 1],
"isr": [2, 3]
}
]
}
]
}为什么需要元数据刷新?
元数据会变化的情况:
- 主题创建/删除
- 分区增加/减少
- Broker 故障或重启
- 分区领导权转移(Leader Election)
- 副本重新分配(Reassignment)
- Broker 扩展/缩减
元数据获取与更新的触发时机:
-
主动刷新时机
- 定期刷新(由 metadata.max.age.ms 控制)
- 首次连接时
- 明确请求时
-
被动/紧急刷新时机
python# 当发生以下错误时,会自动刷新元数据: # 1. LEADER_NOT_AVAILABLE (5) # 找不到分区Leader error_codes = { 5: "LEADER_NOT_AVAILABLE", # 2. UNKNOWN_TOPIC_OR_PARTITION (3) # 主题或分区不存在 3: "UNKNOWN_TOPIC_OR_PARTITION", # 3. NOT_LEADER_FOR_PARTITION (6) # 当前broker不是分区Leader 6: "NOT_LEADER_FOR_PARTITION", # 4. NETWORK_EXCEPTION (13) # 网络异常 13: "NETWORK_EXCEPTION" }
2.10 max.in.flight.requests.per.connection(在途请求数)
每个连接允许的未确认请求数量
python
# 默认5个,提高吞吐量但可能打乱消息顺序
'max.in.flight.requests.per.connection': 5
# 设置为1保证消息顺序,但降低吞吐量
'max.in.flight.requests.per.connection': 12.11 max.request.size(最大请求大小)
定义:
- 生产者发送的单个请求的最大大小。
作用:
- 限制生产者发送的单个请求的大小,包括多个批次(每个批次可能属于不同分区)的总和。
- 防止请求过大,导致网络传输效率降低或阻塞。
注意:
- 一个请求可以包含多个批次,每个批次对应一个分区。
- 如果单个请求超过此大小,生产者会抛出RecordTooLargeException。
默认值:
- 1MB (1048576字节)
python
# max.request.size 与 batch.size 的关系
生产者发送请求时:
┌─────────────────────────────────────────────────────────┐
│ Producer Request (max.request.size) │
│ ┌───────────────────────────────────────────────────┐ │
│ │ 最大 1MB (默认) │ │
│ │ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ 批次1 │ │ 批次2 │ │ 批次3 │ │ │
│ │ │ (分区0) │ │ (分区1) │ │ (分区2) │ │ │
│ │ │ 16KB │ │ 16KB │ │ 16KB │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ │ │ │
│ │ ← 一个请求可以包含多个批次的聚合 → │ │
│ │ 总大小不能超过 max.request.size │ │
│ └───────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
# 配置示例
config = {
'max.request.size': 1048576, # 1MB
'batch.size': 16384, # 16KB
# 一个请求最多可以包含: 1MB / 16KB = 64个批次
}2.12 connections.max.idle.ms(连接空闲时间)
关闭空闲连接的时间(毫秒)
python
# 默认9分钟关闭空闲连接
'connections.max.idle.ms': 540000 # 9分钟2.13 receive.buffer.bytes(接收缓冲区大小)
定义:
- TCP接收缓冲区(SO_RCVBUF)的大小。
作用:
- 操作系统用于存储接收到的数据的缓冲区大小。
- 对于生产者来说,它接收来自broker的响应,因此需要接收缓冲区。
注意:
- 同样也是操作系统级别的TCP缓冲区设置。
- 在高速网络环境下,增加此值可以改善性能。
默认值:
- 32KB (32768字节)
2.14 send.buffer.bytes(发送缓冲区大小)
定义:
- TCP发送缓冲区(SO_SNDBUF)的大小。
作用:
- 操作系统用于存储待发送数据的缓冲区大小。
- 如果设置较大,可以在网络拥堵时缓冲更多数据,避免立即阻塞。
注意:
- 这是操作系统级别的TCP缓冲区设置。
- 通常,在高速网络环境下,增加此值可以提高吞吐量。
默认值:
- 128KB (131072字节)
2.15 request.timeout.ms(请求超时时间)
生产者等待响应的最大时间(毫秒)
python
# 默认30秒
'request.timeout.ms': 30000
# 网络不稳定时可以适当增大
'request.timeout.ms': 60000 # 60秒2.16 bootstrap.servers(引导服务器列表)
Kafka集群的连接地址
python
# 单个broker
'bootstrap.servers': 'localhost:9092'
# 多个broker(推荐,提供高可用性)
'bootstrap.servers': 'kafka1:9092,kafka2:9092,kafka3:9092'
# 包含安全协议
'bootstrap.servers': 'kafka1:9092,kafka2:9092',
'security.protocol': 'SASL_SSL',
'sasl.mechanism': 'PLAIN',
'sasl.username': 'user',
'sasl.password': 'password'