前文介绍:前面我们以及介绍了自然语言序列输入到模型中进行的词嵌入和位置编码的数据变化过程,编码器的结构和数据流动过程,本文在前文的基础上继续接着介绍解码器中的数据流动过程和解码器结构,阅读本文前最好参考前文:词嵌入和位置编码(超详细+图解)https://blog.csdn.net/Drise_/article/details/155502880?fromshare=blogdetail&sharetype=blogdetail&sharerId=155502880&sharerefer=PC&sharesource=Drise_&sharefrom=from_link
以下为***《Attention Is All You Need》*** 的transformer结构,本文会对解码器部分进行介绍:
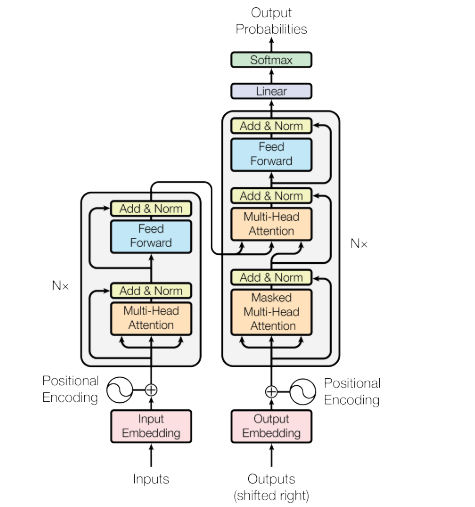
1.Decoder Stacks(解码器堆栈)
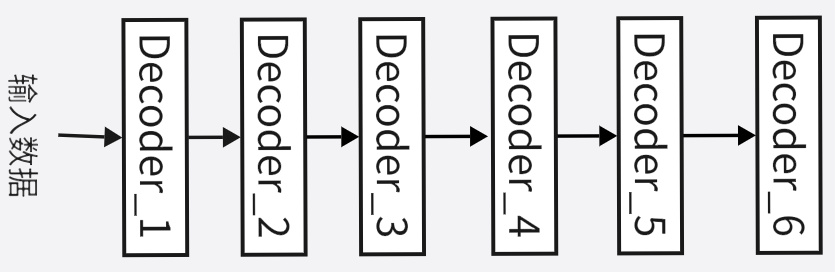
我们首先来介绍一下解码器部分的总体结构,也就是解码器堆栈。解码器堆栈也遵循解码器层间串行,层内并行计算的原则,首先是解码器层间并行,与编码器堆栈相同,第一个编码器输入接收词嵌入和位置编码的输出,其他编码器的输入为上一个编码器的输出,解码器堆栈也是如此。并且它的解码器(解码器层)个数也是6(Nx=6),解码器堆栈总体结构如下:
2.输入数据的不同
在前文我们介绍过token序列经过词嵌入和位置编码后作为编码器堆栈的输入数据,在解码器堆栈,它的输入数据同样要经过词嵌入和位置编码,但是存在一点不同。编码器的输入数据在未进行词嵌入和位置编码时的文本处理如下:

训练过程中,在解码器堆栈的输入数据的文本处理过程,也就是在上图的添加特殊token步骤上与编码器堆栈的输入数据的文本处理不同,添加特殊token步骤前编码器要对输入序列执行右移一位的操作,由于训练过程的编码器堆栈和解码器堆栈的输入数据的原始文本是相同的,这里沿用之前的例子***"if you",*** 也就导致***"if you"被截断为 "if",*** 有人可能会疑问这样不是导致信息残缺了吗,其实这和训练过程解码器的训练逻辑有关,下面会介绍Teacher Forcing。
在右移后解码器堆栈的输入数据要在开头添加一个特殊的token, 即***<sos>,*** 并且***sequence_length仍然为6,***因此对于解码器堆栈的原始输入文本的文本处理的结果如下(假设<sos>在词表中的索引为0):
0 ,123 , 2 , 2 , 2 , 2
接下在词嵌入和位置编码的过程与前文相同,我们现在就得到了解码器堆栈的输入向量,它的维度大小同样是(1,6,2),这三个维度分别是:
(batch_size, sequence_length , d_model/embedding_dim)
即为下面图片中图形的维度:

补充:
我们不禁产生一个疑问,为什么在训练过程解码器堆栈也需要输入原始文本经过词嵌入和位置编码生成的输入数据?
讲到这里我们必须讲到Teacher Forcing,Teacher Forcing是是序列生成模型(如 RNN 等 Seq2Seq 架构)中经典的训练策略,核心是用真实目标序列规避训练初期的错误累积问题。
该机制的核心思想是,训练解码器时,不使用模型上一时刻的预测输出作为当前时刻的输入,而是强制用目标序列中对应的真实值作为输入。就像学生做题时,老师直接给出上一步的正确答案,引导学生做下一步,而非让学生根据自己可能错的答案继续推导。
而在解码器堆栈中,我们输入的文本数据和编码器堆栈相同,也就是说我们的编码器一开始就有一份"标准答案" ,我们如何让解码器只能知道上一步的结果,而不偷看之后的正确答案呢,这就涉及到了sequence mask掩码机制,后文会详细介绍。
Teacher Forcing的训练策略也就导致我们可以在右移过程让序列缺失最后一个token,因为我们基于前面的所有token可以推断出最后一个token,并且进行完这一步操作我们的训练过程就结束了,所有我们不需要将最后一个token输入到解码器堆栈中。
并且右移在开头添加<sos>也让我们在第一步训练只有第一个token的信息,第二步训练只有第一二个token的信息,添加开头<sos>让整个解码器训练流程统一。
3.解码器结构
我们先来介绍一下每个解码器(解码器层)的结构,如下图:
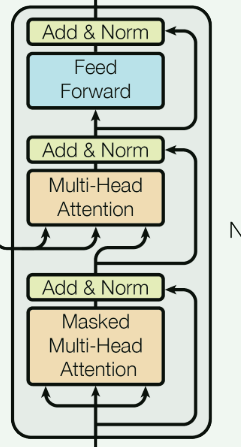
每个解码器由两个多头注意力层和一个前馈层组成,并且他们后都接了一个残差连接和归一化处理,可以观察到解码器的多头注意力层和编码器有所不同,接下来我们要详细介绍其中的细节。
(1)Masked Multi-Head Attention
首先我们看到编码器中的多头注意力层为Multi-Head Attention, 在解码器中则多了一个Masked, 这代表的是掩码机制,掩码机制的主要作用是,把序列的某些token"藏起来",让这些token不能够对此次的参数更新产生影响,在 transformer中主要有两种掩码机制,如下:
1.padding mask
这种掩码机制我们在前文讲过:词嵌入和位置编码,它的方法就是通过在序列对齐标准序列长度时填充<pad>,pad的位置在后续操作会变成一个极大的负数,从而导致softmax分数接近0。
2.sequence mask
sequence mask是解码器自注意力层的核心操作,核心目标是强制模型在预测第i个 token 时,只能关注前i−1个 token,完全屏蔽 "未来" 位置的信息,其实现逻辑如下:
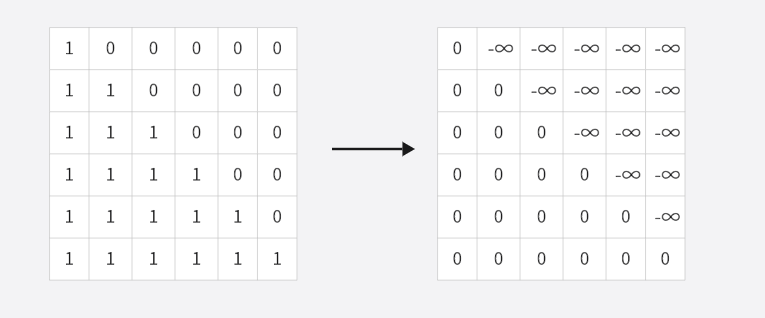
首先生成一个大小为sequence_length*sequence_length 大小的矩阵,其元素的填充规则是**可见位置设为 0,不可见(未来)位置设为极小值,**具体步骤如下:
我们继续延用我们的例子,***sequence_length=6,***先生成一个6*6的下三角矩阵,再把下三角矩阵中0的部分换为负无穷,1换为0,过程如下:
得到了掩码矩阵之后,我们就知道了每一时间步我们能够关注到的信息,比如第一个时间步,我们就看到第一行,为 0, **-∞,** **-∞,** **-∞,** **-∞,** **-∞** ,这就表示我们只能看到第一个token,其实这里的原理和padding mask是相同的,那就是极大的负数导致softmax分数接近0。
在解码器的mask使用的步骤也是这张图片:
不过在解码器中mask为sequence mask,详细过程可以看编码器详解
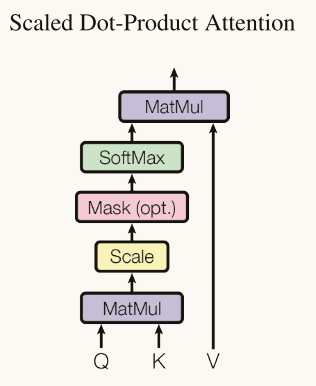
除了额外添加一个掩码机制,Masked Multi-Head Attention 的其他方面,比如注意力计算的步骤和编码器一模一样,建议可以查看编码器部分来理解。
(2)Multi-Head Attention
在解码器的Multi-Head Attention,Q , K , V(它们分别代表查询向量,键向量和值向量)的来源有所不同,我们前面编码器堆栈的输出,Q 来自解码器上一层(即掩码多头自注意力层)的输出,K 和 V 则均来自编码器的最终输出,如此得到的解码器的注意力分数用于预测下一位置的token
4.Feed Forward(前馈层)和 Add & Norm
在解码器的前馈层和残差归一化操作和编码器中是相同的,具体操作请看
如此经过六个解码器,我们得到了最终输出的是一个特征向量序列。这个向量序列里的每个向量都融合了三方面关键信息:解码器生成序列的前文依赖、编码器输入的全局上下文、当前生成位置的语义特征,且向量维度和模型设定的隐藏层维度。在通过线性层 + Softmax 层,形成可用于选择 token 的概率分布,这样我们就可以在训练过程预测**全部位置的token概率分布,**最终得到预测的token序列。