| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LangChain+Milvus实战:相似性搜索与MMR多样化检索全解析 |
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的"幻觉"
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
25、零基础学AI大模型之嵌入模型性能优化
26、零基础学AI大模型之向量数据库介绍与技术选型思考
27、零基础学AI大模型之Milvus向量数据库全解析
28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
29、零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用
30、零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例
31、零基础学AI大模型之Milvus索引实战
32、零基础学AI大模型之Milvus DML实战
33、零基础学AI大模型之Milvus向量Search查询综合案例实战
33、零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析
34、零基础学AI大模型之相似度Search与MMR最大边界相关搜索实战
35、零基础学AI大模型之LangChain整合Milvus:新增与删除数据实战
36、零基础学AI大模型之LangChain+Milvus实战:相似性搜索与MMR多样化检索全解析
本文章目录
- [零基础学AI大模型之LangChain Retriever](#零基础学AI大模型之LangChain Retriever)
-
- [1. 什么是LangChain Retriever?](#1. 什么是LangChain Retriever?)
-
- [1.1 核心定位与价值](#1.1 核心定位与价值)
- [1.2 关键补充:召回率(Recall)](#1.2 关键补充:召回率(Recall))
- [2. Retriever核心特性](#2. Retriever核心特性)
- [3. 核心检索器:VectorStoreRetriever详解](#3. 核心检索器:VectorStoreRetriever详解)
-
- [3.1 核心方法:as_retriever()](#3.1 核心方法:as_retriever())
- [3.2 关键参数:search_type(搜索类型)](#3.2 关键参数:search_type(搜索类型))
- [3.3 关键参数:search_kwargs(检索配置)](#3.3 关键参数:search_kwargs(检索配置))
- [4. 综合实战:VectorStoreRetriever+Milvus实战(个人技术场景适配)](#4. 综合实战:VectorStoreRetriever+Milvus实战(个人技术场景适配))
-
- [4.1 环境准备](#4.1 环境准备)
- [4.2 完整实战代码](#4.2 完整实战代码)
- [4.3 运行结果与个人场景分析](#4.3 运行结果与个人场景分析)
- [4.4 注意事项](#4.4 注意事项)
零基础学AI大模型之LangChain Retriever
在之前的系列文章中,我们已经完整拆解了RAG系统全链路(文档加载→分割→嵌入→向量存储),也深入实战了Milvus向量数据库的部署、索引与多类型查询。而今天要讲的 Retriever(检索器),正是串联"向量存储"与"大模型生成"的关键枢纽------作为RAG的数据入口,它直接决定大模型能获取到哪些精准上下文,是解决大模型"幻觉"、提升生成结果准确性的核心组件。
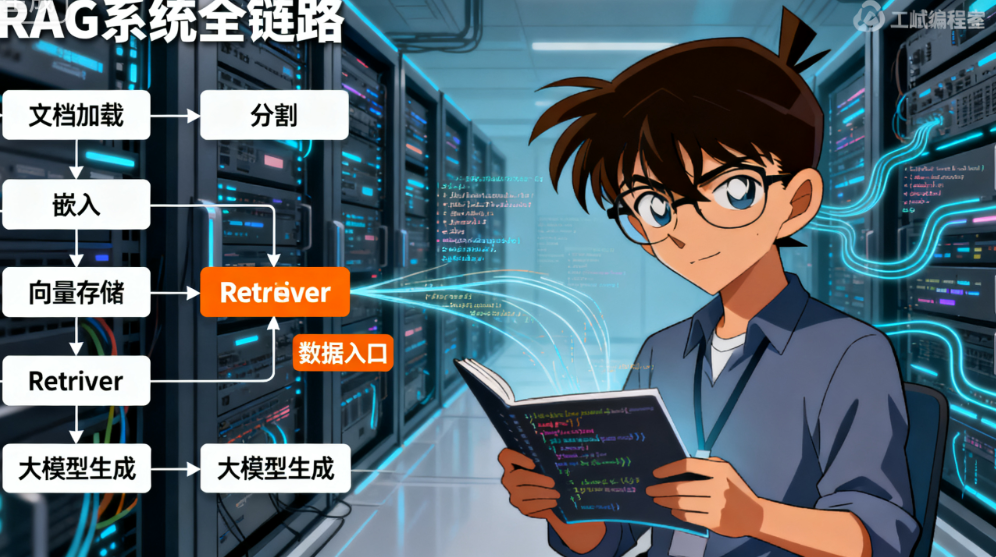
1. 什么是LangChain Retriever?
Retriever是LangChain中标准化的"检索接口",核心作用是从向量库、传统数据库、搜索引擎等各类数据源中,快速筛选出与查询相关的Document对象列表,是RAG架构中不可或缺的核心环节。
1.1 核心定位与价值
- 统一接口:无论数据来源是Milvus/FAISS向量库、MySQL传统数据库还是网页搜索引擎,最终输出格式均为Document列表,降低多源检索集成成本。
- 不直接管理存储:依赖VectorStore实现数据的向量化与持久化,自身专注于"检索逻辑"(如相似度计算、元数据过滤、结果重排序)。
- 提升RAG召回率:支持多源混合检索,可同时查询多个数据源,减少关键相关文档的遗漏。
1.2 关键补充:召回率(Recall)
检索场景中,召回率是衡量"找全相关结果"的核心指标。比如存在10篇与"LangChain实战"相关的个人技术笔记,系统检索出8篇,召回率即为80%。Retriever的设计目标之一,就是在保证一定准确率的前提下最大化召回率------避免漏掉关键技术细节,为大模型提供全面的上下文支撑。
2. Retriever核心特性
- 模块化设计:支持插件式扩展,可自定义检索算法(如混合搜索、结果重排序),适配不同技术场景(如技术问答、笔记检索)。
- 异步支持:通过
async_get_relevant_documents方法,满足高并发场景(如个人技术博客批量检索)的高效需求。 - 无缝链式调用:可与LangChain的Text Splitters、Memory、PromptTemplate等组件直接集成,快速搭建端到端RAG应用(如个人技术知识库问答)。
3. 核心检索器:VectorStoreRetriever详解
VectorStoreRetriever是最基础也最常用的检索器实现,基于向量库的相似度计算完成检索,支持多种搜索策略,也是本次实战的核心。
3.1 核心方法:as_retriever()
向量库实例(如Milvus、FAISS)通过as_retriever()方法可直接转换为Retriever对象,实现与LangChain链式调用(如RetrievalQA)的无缝对接,这也是我在个人技术项目中最常用的转换方式。
源码核心逻辑:
python
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
tags = kwargs.pop("tags", None) or [] + self._get_retriever_tags()
return VectorStoreRetriever(vectorstore=self, tags=tags, **kwargs)3.2 关键参数:search_type(搜索类型)

不同搜索类型适配不同技术场景,核心类型对比如下:
| 搜索类型 | 适用场景 | 对应Milvus操作 | 核心逻辑 |
|---|---|---|---|
| "similarity" | 基础技术查询,优先相关性 | search() | 基于余弦相似度,返回Top-K最相关的技术文档 |
| "mmr" | 技术文档汇总、多维度学习,需多样性结果 | max_marginal_relevance_search() | 在相似度基础上,通过lambda_mult控制多样性(0→纯相关,1→纯多样) |
| "similarity_score_threshold" | 精准技术筛选,剔除低相关内容 | search() + score_threshold | 仅返回相似度得分高于阈值的技术文档 |
3.3 关键参数:search_kwargs(检索配置)
通过字典传入检索的具体配置,核心参数如下(结合个人技术场景说明):
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| k | int | 4 | 返回的相关技术文档数量(如查询"LangChain链"时返回3篇核心笔记) |
| filter/expr | str/dict | None | 元数据过滤条件(如筛选"category:langchain"或"source:csdn.net/chandfy"的文档) |
| fetch_k | int | 20 | MMR检索专用,先获取fetch_k条相似技术文档,再筛选k条多样结果 |
| lambda_mult | float | 0.5 | MMR检索专用,平衡技术相关性与多样性(如学习LangChain时,既保留核心知识点又补充扩展内容) |
| score_threshold | float | None | 相似度阈值检索专用,仅保留得分高于该值的精准技术文档 |
4. 综合实战:VectorStoreRetriever+Milvus实战(个人技术场景适配)
4.1 环境准备
先安装依赖(若已安装可跳过):
bash
pip install langchain_core langchain_community langchain_milvus dashscope pymilvus4.2 完整实战代码
python
# 1. 导入依赖
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.documents import Document
# 2. 初始化嵌入模型(替换为自己的DashScope API密钥,从阿里云控制台获取)
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用文本嵌入模型,技术文档编码更精准
max_retries=3, # 失败重试次数,保障个人技术数据检索稳定性
dashscope_api_key="替换为你的API密钥" # 请勿直接使用示例密钥,避免泄露
)
# 3. 构造个人技术相关文档(基于我的博客系列、实战项目编写)
documents = [
Document(
page_content="工藤学编程的SpringBoot实战系列,详细拆解了SpringBoot3.X整合MinIO存储的原生方案,含配置步骤与避坑指南",
metadata={"source": "csdn.net/chandfy/minio", "category": "springboot", "series": "中间件整合"}
),
Document(
page_content="LangChain六大核心模块是工藤学AI大模型系列的重点,包括Model、Prompt、Chain、Retriever、Memory、Tool,含IO交互链路全解析",
metadata={"source": "csdn.net/chandfy/langchain-core", "category": "langchain", "series": "AI大模型"}
),
Document(
page_content="Milvus向量数据库是RAG系统的核心存储组件,工藤分享过Docker一键部署、Attu可视化安装、索引优化等完整实战",
metadata={"source": "csdn.net/chandfy/milvus-full", "category": "milvus", "series": "AI大模型"}
),
Document(
page_content="工藤学编程的分库分表实战文章,深入剖析了sharding-JDBC的分库分表执行流程,含分片策略与分布式事务处理",
metadata={"source": "csdn.net/chandfy/sharding-jdbc", "category": "java", "series": "分布式架构"}
),
Document(
page_content="LangChain Retriever是RAG的数据入口,工藤在系列文章中强调其标准化接口特性,支持多源检索与链式调用",
metadata={"source": "csdn.net/chandfy/langchain-retriever", "category": "langchain", "series": "AI大模型"}
),
Document(
page_content="RabbitMQ消息确认机制(ACK)是工藤中间件系列的重点,含生产者确认、消费者确认的代码实现与原理讲解",
metadata={"source": "csdn.net/chandfy/rabbitmq-ack", "category": "middleware", "series": "中间件整合"}
)
]
# 4. 初始化Milvus向量库并写入个人技术文档(承接之前部署的Milvus服务)
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="gongteng_tech_knowledge", # 个人技术知识库集合名称
connection_args={"uri": "http://192.168.229.128:19530"} # 替换为自己的Milvus连接地址(本地部署用http://localhost:19530)
)
# 5. 实战1:基础相似度检索(默认search_type="similarity")
print("=== 基础相似度检索结果(查询LangChain相关内容) ===")
similarity_retriever = vector_store.as_retriever(
search_kwargs={
"k": 2, # 返回Top2最相关的LangChain文档
"filter": {"category": "langchain"} # 仅筛选category为langchain的技术文档
}
)
similarity_results = similarity_retriever.invoke("LangChain的核心组件与检索器作用是什么?")
for idx, result in enumerate(similarity_results, 1):
print(f"[{idx}] 内容:{result.page_content}")
print(f"元数据:{result.metadata}\n")
# 6. 实战2:MMR多样性检索(search_type="mmr")
print("=== MMR多样性检索结果(查询中间件相关实战) ===")
mmr_retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 2, # 最终返回2条文档
"fetch_k": 10, # 先获取10条相似文档
"lambda_mult": 0.6 # 偏相关性,同时保证中间件类型多样性
}
)
mmr_results = mmr_retriever.invoke("工藤分享过哪些中间件整合实战?")
for idx, result in enumerate(mmr_results, 1):
print(f"[{idx}] 内容:{result.page_content}")
print(f"元数据:{result.metadata}\n")4.3 运行结果与个人场景分析
预期结果:
- 基础相似度检索:仅返回category为langchain的2条文档,分别是LangChain六大核心模块解析和Retriever作用说明,精准匹配"LangChain核心组件与检索器"的查询需求。
- MMR多样性检索:返回2条中间件相关实战文档,比如MinIO整合(SpringBoot系列)和RabbitMQ ACK机制(消息队列系列),既相关又不重复,覆盖不同中间件类型。
4.4 注意事项
- API密钥安全:DashScope API密钥需从阿里云DashScope控制台获取,切勿直接硬编码到公开项目中。
- Milvus连接:确保Milvus服务已启动,连接地址、端口与部署环境一致(本地Docker部署可改为
http://localhost:19530)。 - 文档扩展:可通过LangChain的WebBaseLoader爬取自己的CSDN博客,自动生成Document对象,批量导入向量库。
关注我,持续解锁AI大模型与Java生态的实战干货!