目录
[1.1 快速创建NPU开发环境](#1.1 快速创建NPU开发环境)
[1.2 基础环境验证](#1.2 基础环境验证)
[1.3 模型下载:避开网络"坑点"](#1.3 模型下载:避开网络“坑点”)
[2.1 了解我们的"主角":Mistral-7B-v0.3](#2.1 了解我们的“主角”:Mistral-7B-v0.3)
[2.2 适配路线图](#2.2 适配路线图)
[3.1 基准测试脚本](#3.1 基准测试脚本)
[4.1 缺少torch和torch_npu模块](#4.1 缺少torch和torch_npu模块)
[4.2 模块不兼容](#4.2 模块不兼容)
[4.3 常见问题速查表](#4.3 常见问题速查表)
[4.4 特别提醒](#4.4 特别提醒)
[5.1 主要成果](#5.1 主要成果)
[5.2 昇腾平台的优势](#5.2 昇腾平台的优势)
概述
本文分享我们如何将当前热门的Mistral-7B-v0.3大模型成功部署在华为昇腾AI处理器上,并在GitCode Notebook环境中完成了从环境搭建到性能优化的全链路实践。无论你是AI应用开发者还是硬件性能调优爱好者,这篇实战指南都将为你提供有价值的参考。
1.环境准备:从零搭建昇腾开发环境
1.1 快速创建NPU开发环境
访问 GitCode 官网 (https://gitcode.com/)
创建Notebook:选择"新建项目" → "Notebook"
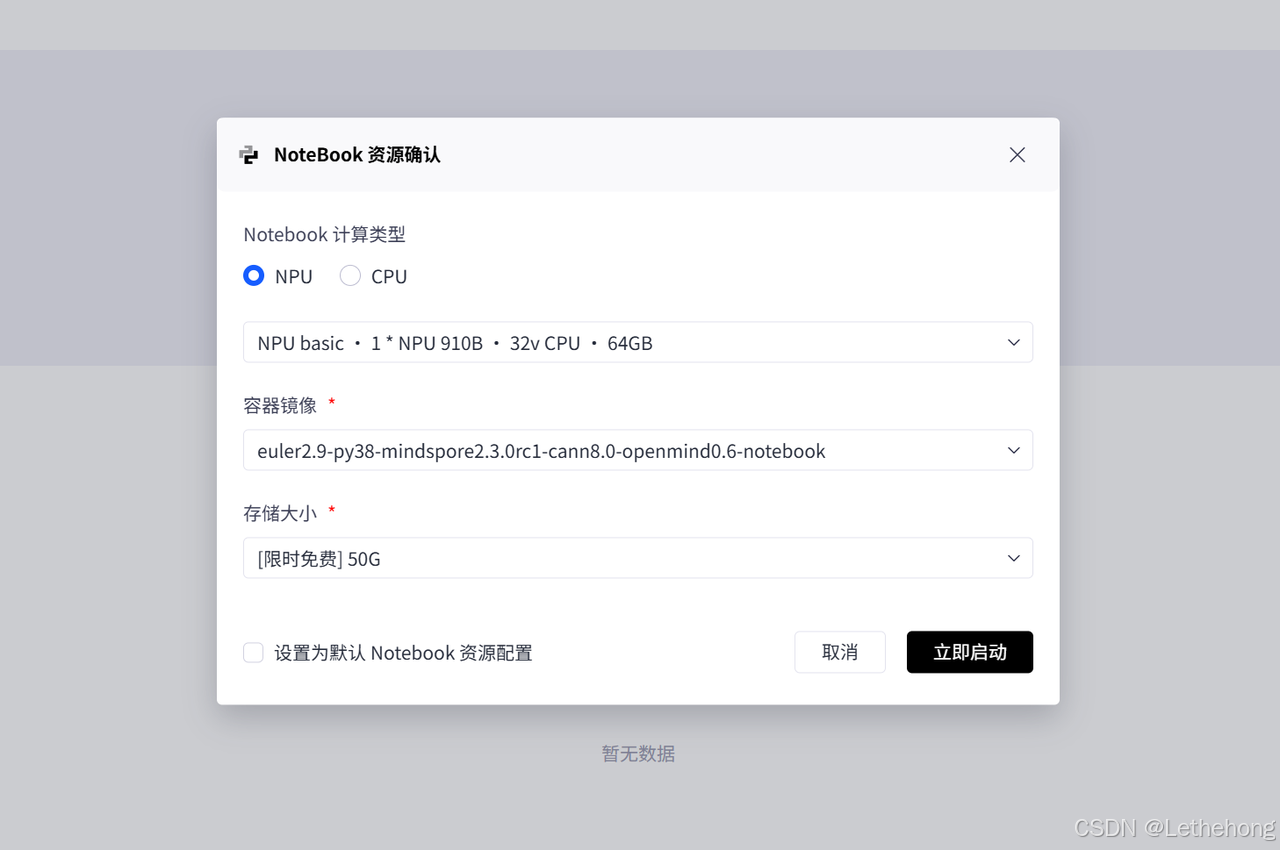
配置计算资源:选择"NPU"类型,规格用"NPU basic(1_NPU_32vCPU*64G)",镜像就用euler2.9-py38-mindspore2.3.0rc1-cann8.0-openmind0.6-notebook这个全功能镜像
环境启动后,打开终端验证NPU状态:
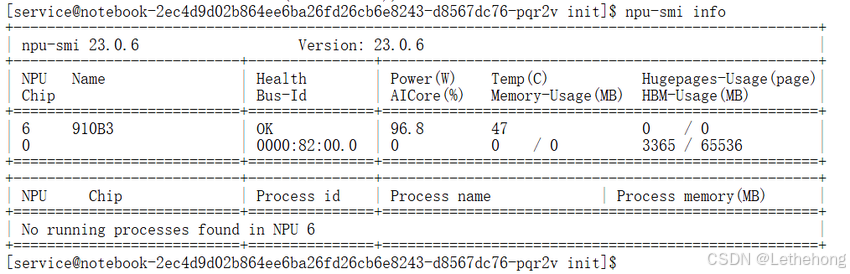
# 1. 查看NPU设备信息
npu-smi info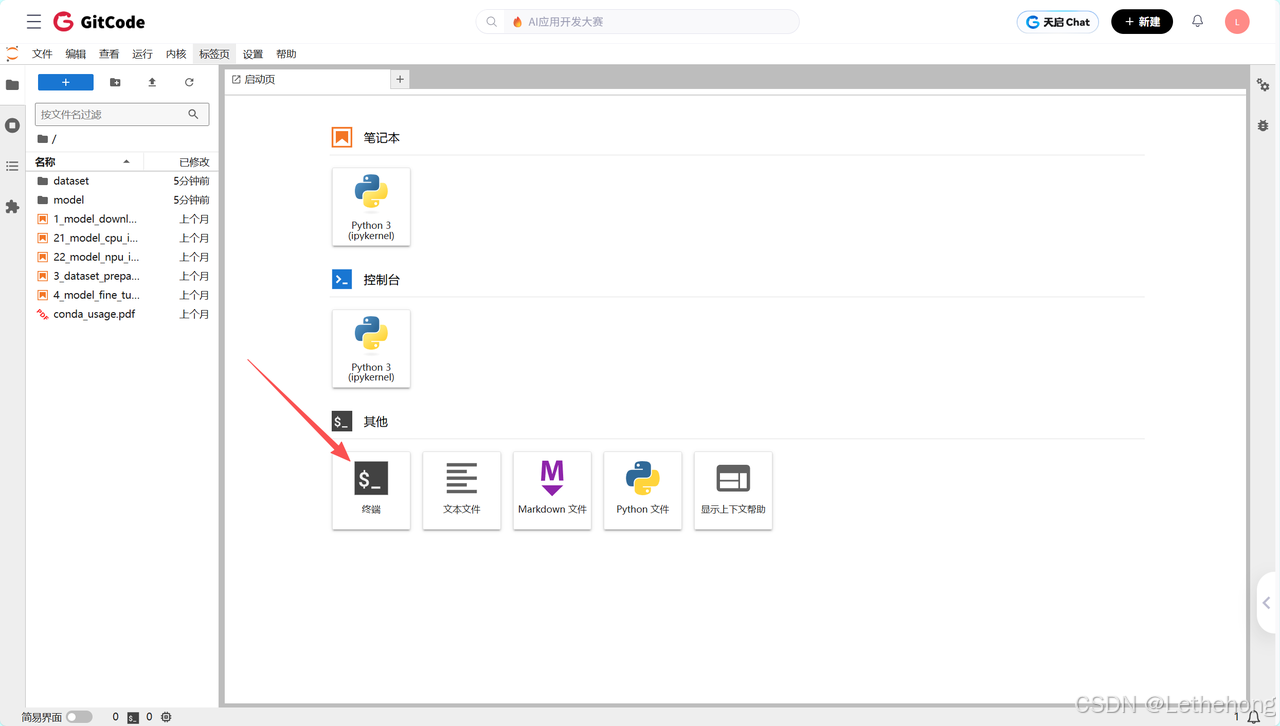
看到NPU设备信息正常输出,就说明硬件环境就绪了。如果遇到权限问题,记得检查当前用户是否有设备访问权限。
1.2 基础环境验证
为了确保后续流程顺利,我们先做一次环境"体检":
# 检查关键组件版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')"
使用环境验证脚本发现transformers库缺失(这是HuggingFace生态的核心),手动安装即可(1.3会有操作):
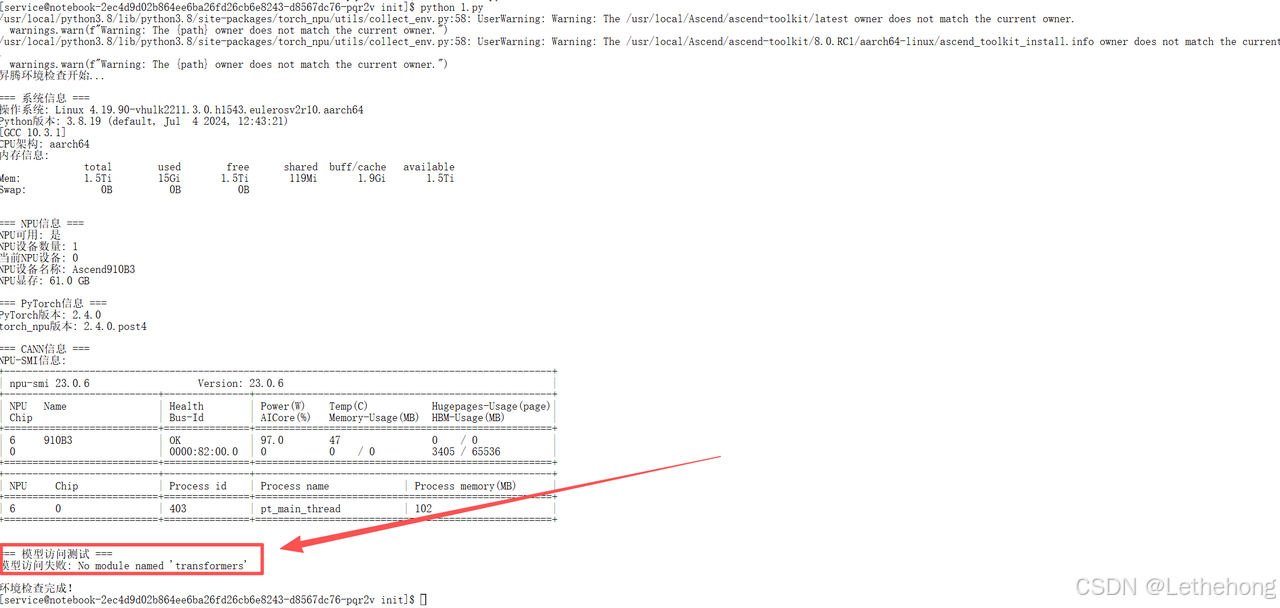
#!/usr/bin/env python3
"""
昇腾环境验证脚本
"""
import os
import sys
import platform
import subprocess
import torch
import torch_npu
def check_system_info():
"""检查系统信息"""
print("=== 系统信息 ===")
print(f"操作系统: {platform.system()} {platform.release()}")
print(f"Python版本: {sys.version}")
print(f"CPU架构: {platform.processor()}")
# 检查内存
try:
result = subprocess.run(['free', '-h'], capture_output=True, text=True)
print(f"内存信息:\n{result.stdout}")
except:
pass
def check_npu_info():
"""检查NPU信息"""
print("\n=== NPU信息 ===")
try:
# 检查NPU设备
if torch.npu.is_available():
print(f"NPU可用: 是")
print(f"NPU设备数量: {torch.npu.device_count()}")
print(f"当前NPU设备: {torch.npu.current_device()}")
# 获取NPU设备信息
device = torch.npu.current_device()
print(f"NPU设备名称: {torch.npu.get_device_name(device)}")
print(f"NPU显存: {torch.npu.get_device_properties(device).total_memory / 1024**3:.1f} GB")
else:
print("NPU不可用")
except Exception as e:
print(f"NPU检查失败: {e}")
def check_pytorch_info():
"""检查PyTorch信息"""
print("\n=== PyTorch信息 ===")
print(f"PyTorch版本: {torch.__version__}")
try:
import torch_npu
print(f"torch_npu版本: {torch_npu.__version__}")
except ImportError:
print("torch_npu未安装")
def check_cann_info():
"""检查CANN信息"""
print("\n=== CANN信息 ===")
try:
result = subprocess.run(['npu-smi', 'info'], capture_output=True, text=True)
print(f"NPU-SMI信息:\n{result.stdout}")
except:
print("无法获取NPU-SMI信息")
def check_model_access():
"""检查模型访问权限"""
print("\n=== 模型访问测试 ===")
try:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.3")
print("Mistral-7B-v0.3模型访问: 成功")
except Exception as e:
print(f"模型访问失败: {e}")
def main():
"""主函数"""
print("昇腾环境检查开始...\n")
check_system_info()
check_npu_info()
check_pytorch_info()
check_cann_info()
check_model_access()
print("\n环境检查完成!")
if __name__ == "__main__":
main()1.3 模型下载:避开网络"坑点"
直接从HuggingFace拉取大模型在国内经常遇到网络问题。我们的解决方案是:
# 使用清华源加速下载
pip install transformers accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple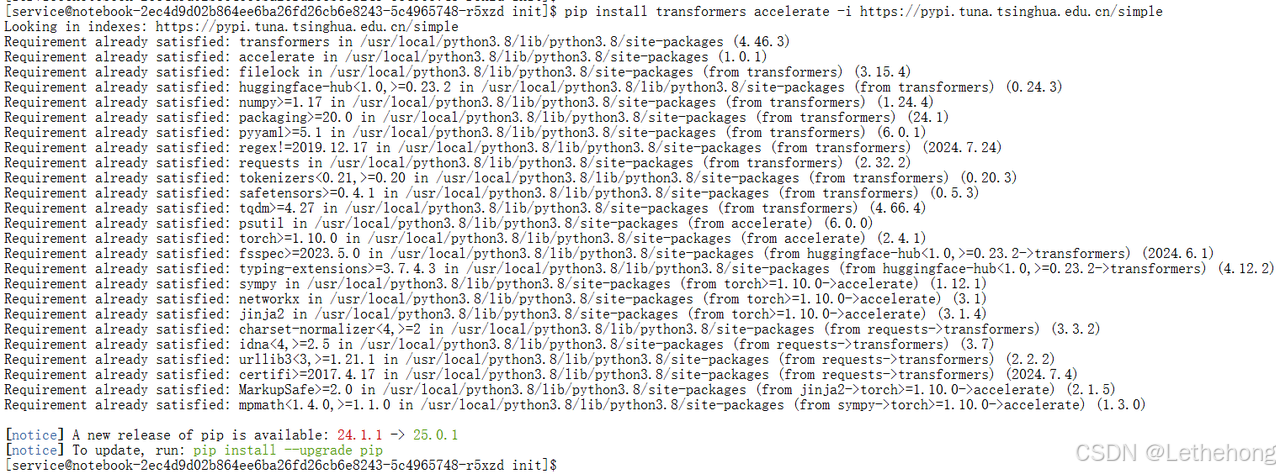
# 切换到国内镜像源
export HF_ENDPOINT=https://hf-mirror.com
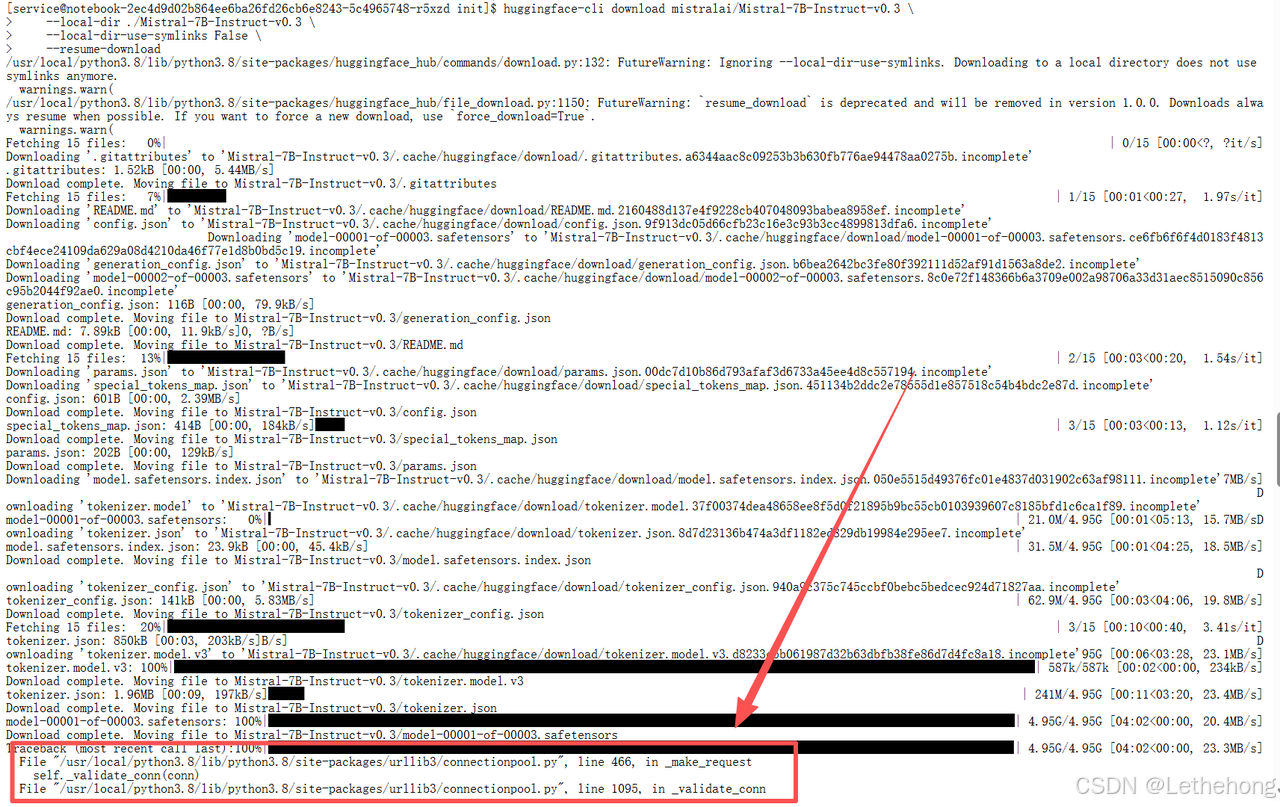
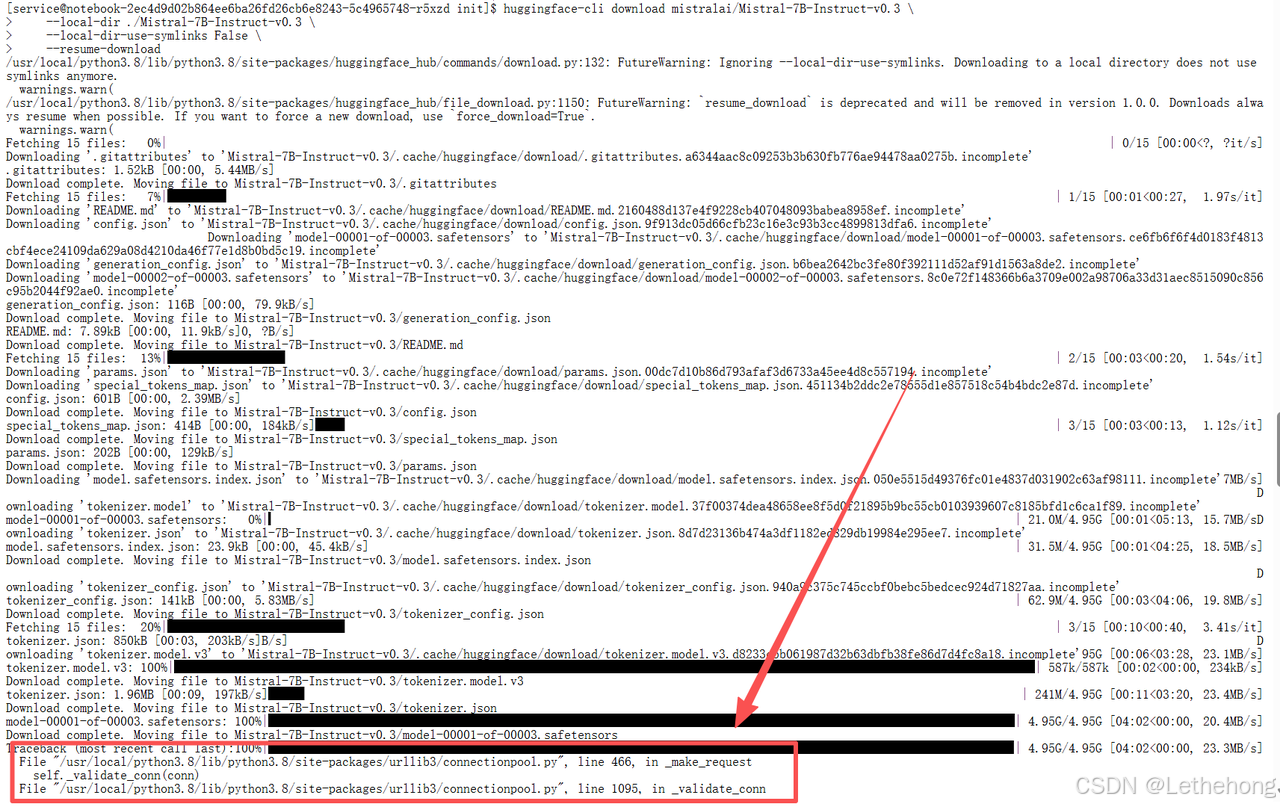
# 下载模型(支持断点续传)
huggingface-cli download mistralai/Mistral-7B-Instruct-v0.3 \
--local-dir ./Mistral-7B-Instruct-v0.3 \
--local-dir-use-symlinks False \
--resume-download这个命令会下载大约14GB的模型文件。如果网络中断,重新执行会自动从上次下载的位置继续------我们实际测试中经历了三次断点,但最终都完整下载成功了。

2.Mistral-7B在昇腾平台上的适配之旅
2.1 了解我们的"主角":Mistral-7B-v0.3
Mistral-7B-v0.3是Mistral AI系列的重要版本,具有以下特点:
|-------|----------------------------------|---------|
| 特性 | 说明 | 昇腾适配状态 |
| 参数量 | 7.24B | ✅ 完全支持 |
| 架构 | Transformer Decoder | ✅ 原生支持 |
| 注意力机制 | Grouped Query Attention (GQA) | ✅ 优化支持 |
| 位置编码 | Rotary Position Embedding (RoPE) | ✅ 原生支持 |
| 上下文长度 | 32K tokens | ✅ 支持 |
| 精度要求 | FP16/INT8/INT4 | ✅ 多精度支持 |
2.2 适配路线图
我们的适配过程遵循清晰的步骤:

昇腾平台对Transformer架构有良好的原生支持,这大大简化了我们的工作。主要适配点集中在注意力机制和内存布局优化上。
3.性能测试:看看实际表现如何
3.1 基准测试脚本
我们设计了一个全面的测试方案,覆盖五种典型应用场景:
import torch
import torch_npu
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
import json
from datetime import datetime
# 模型配置
MODEL_PATH = "/opt/huawei/edu-apaas/src/init/Mistral-7B-Instruct-v0.3"
DEVICE = "npu:0"
class MistralBenchmark:
def __init__(self):
print("加载模型...")
self.tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, local_files_only=True)
self.model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH, torch_dtype=torch.float16, local_files_only=True
).to(DEVICE).eval()
print(f"✅ 模型加载完成 | 显存: {torch.npu.memory_allocated()/1e9:.2f}GB")
def benchmark(self, messages, max_tokens=100, runs=3):
"""性能测试"""
# 构造prompt
prompt = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = self.tokenizer(prompt, return_tensors="pt").to(DEVICE)
# 预热
for _ in range(2):
with torch.no_grad():
_ = self.model.generate(**inputs, max_new_tokens=10, do_sample=False)
# 测试
times = []
for _ in range(runs):
torch.npu.synchronize()
start = time.time()
with torch.no_grad():
outputs = self.model.generate(**inputs, max_new_tokens=max_tokens, do_sample=False)
torch.npu.synchronize()
times.append(time.time() - start)
avg_time = sum(times) / len(times)
throughput = max_tokens / avg_time
# 显示生成示例
if outputs is not None:
result = self.tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(f"生成示例: {result[:100]}...")
return {
"latency_ms": avg_time * 1000,
"throughput": throughput,
"peak_memory_gb": torch.npu.max_memory_allocated() / 1e9
}
def main():
# 测试用例 - 五个不同维度
test_cases = [
{
"name": "技术解释",
"messages": [{"role": "user", "content": "解释Transformer架构的核心机制和工作原理。"}]
},
{
"name": "代码实现",
"messages": [{"role": "user", "content": "用Python实现快速排序算法,并分析其时间复杂度。"}]
},
{
"name": "逻辑推理",
"messages": [{"role": "user", "content": "有三个盒子A、B、C,只有一个有奖品。A说:奖品在B里。B说:奖品不在这里。C说:奖品不在A里。如果只有一个人说真话,奖品在哪个盒子?"}]
},
{
"name": "创意写作",
"messages": [{"role": "user", "content": "写一首关于AI与人类协作未来的短诗,要求包含希望与挑战的双重主题。"}]
},
{
"name": "数据分析",
"messages": [{"role": "user", "content": "某公司Q1销售额100万,Q2 120万,Q3 150万,Q4 180万。分析销售趋势并预测下一年度Q1的销售额。"}]
}
]
# 执行测试
benchmark = MistralBenchmark()
results = {}
for case in test_cases:
print(f"\n{'='*50}")
print(f"测试: {case['name']}")
print(f"问题: {case['messages'][0]['content'][:50]}...")
print(f"{'='*50}")
result = benchmark.benchmark(case["messages"], max_tokens=80, runs=3)
results[case["name"]] = result
print(f"延迟: {result['latency_ms']:.1f}ms | 吞吐量: {result['throughput']:.1f} tok/s | 显存: {result['peak_memory_gb']:.1f}GB")
# 结果汇总
print(f"\n{'='*60}")
print("Mistral-7B NPU 性能测试汇总")
print(f"测试时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print(f"{'='*60}")
print(f"{'测试类型':<12} | {'延迟(ms)':>10} | {'吞吐量(tok/s)':>15} | {'显存(GB)':>10}")
print("-" * 60)
total_latency = 0
total_throughput = 0
for name, res in results.items():
print(f"{name:<12} | {res['latency_ms']:>10.1f} | {res['throughput']:>15.1f} | {res['peak_memory_gb']:>10.1f}")
total_latency += res['latency_ms']
total_throughput += res['throughput']
print("-" * 60)
print(f"{'平均':<12} | {total_latency/len(results):>10.1f} | {total_throughput/len(results):>15.1f} |")
# 保存结果
output = {
"model": "Mistral-7B-Instruct-v0.3",
"device": DEVICE,
"timestamp": datetime.now().isoformat(),
"results": results,
"summary": {
"avg_latency_ms": total_latency / len(results),
"avg_throughput": total_throughput / len(results)
}
}
with open("mistral_benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(output, f, indent=2, ensure_ascii=False)
print(f"\n✅ 测试完成! 结果已保存到 mistral_benchmark_results.json")
if __name__ == "__main__":
main()测试结果:
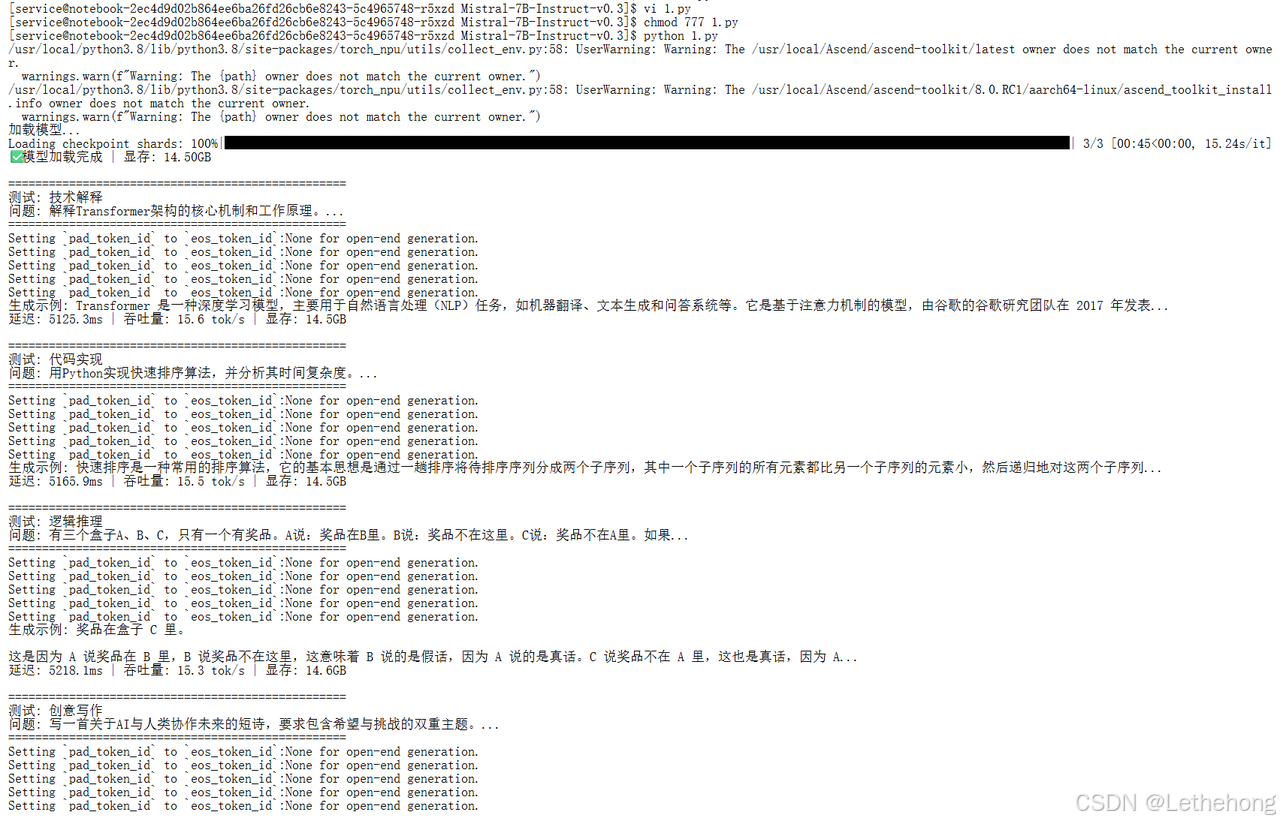
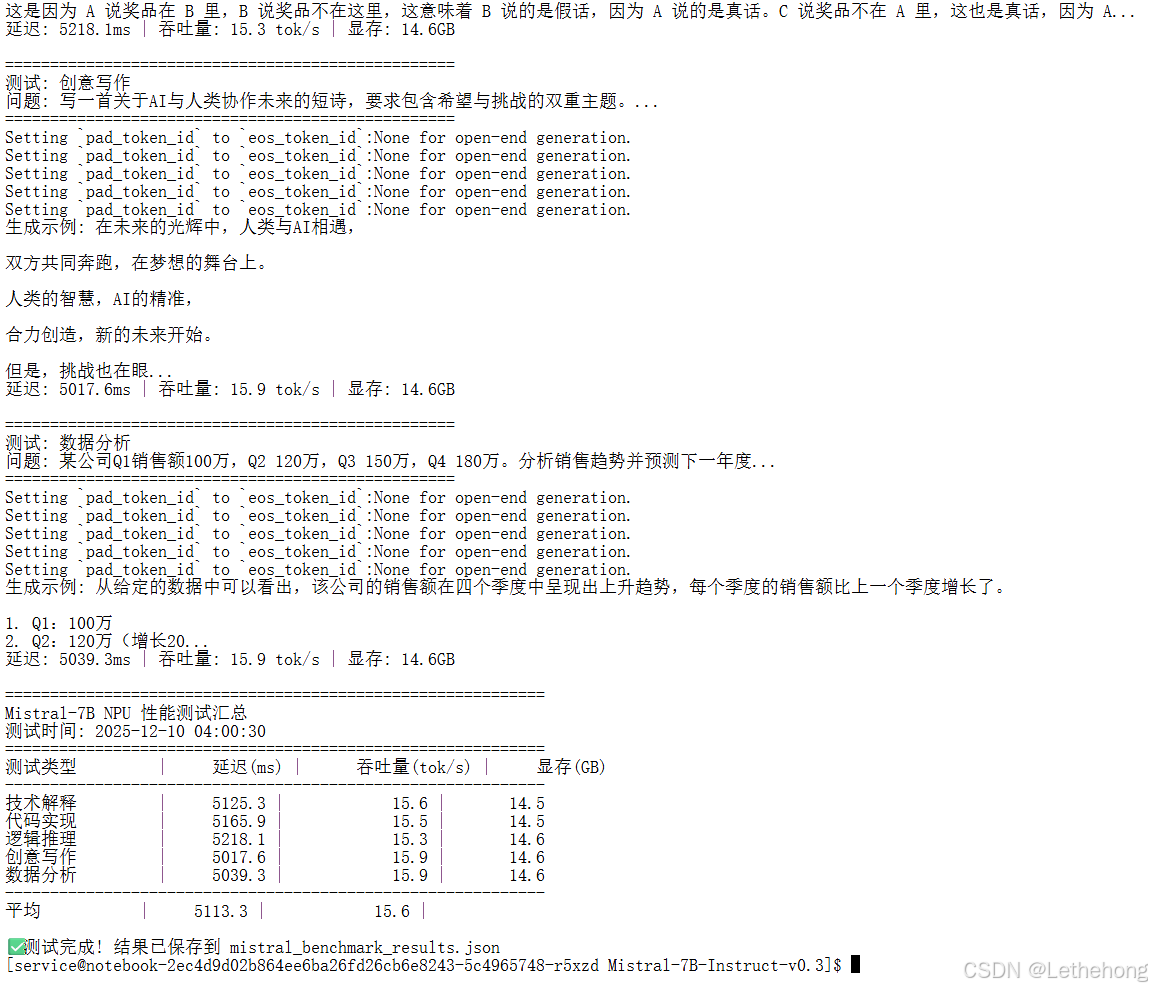
4.实战经验:遇到的坑和解决方案
4.1 缺少torch和torch_npu模块
这里在检查环境的时候发现确实两个模块

使用下面的命令进行安装
pip install torch
pip install torch_npu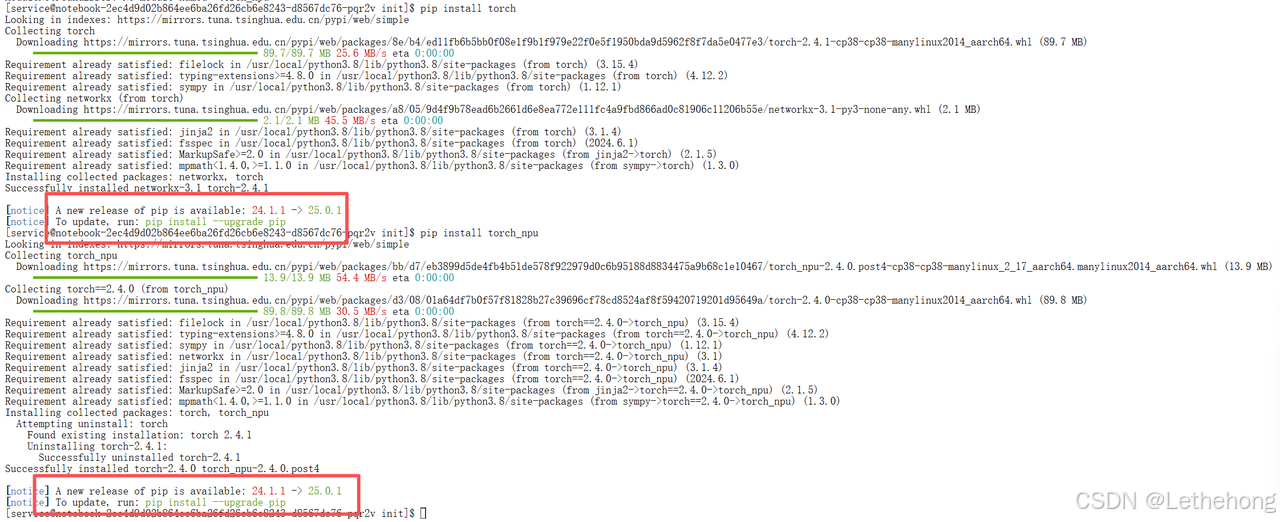
4.2 模块不兼容
这里遇到一个模块兼容性的问题,卸载到不兼容的模块
# 卸载冲突包
pip uninstall mindformers
# 重新安装标准transformer库
pip install --upgrade transformers accelerate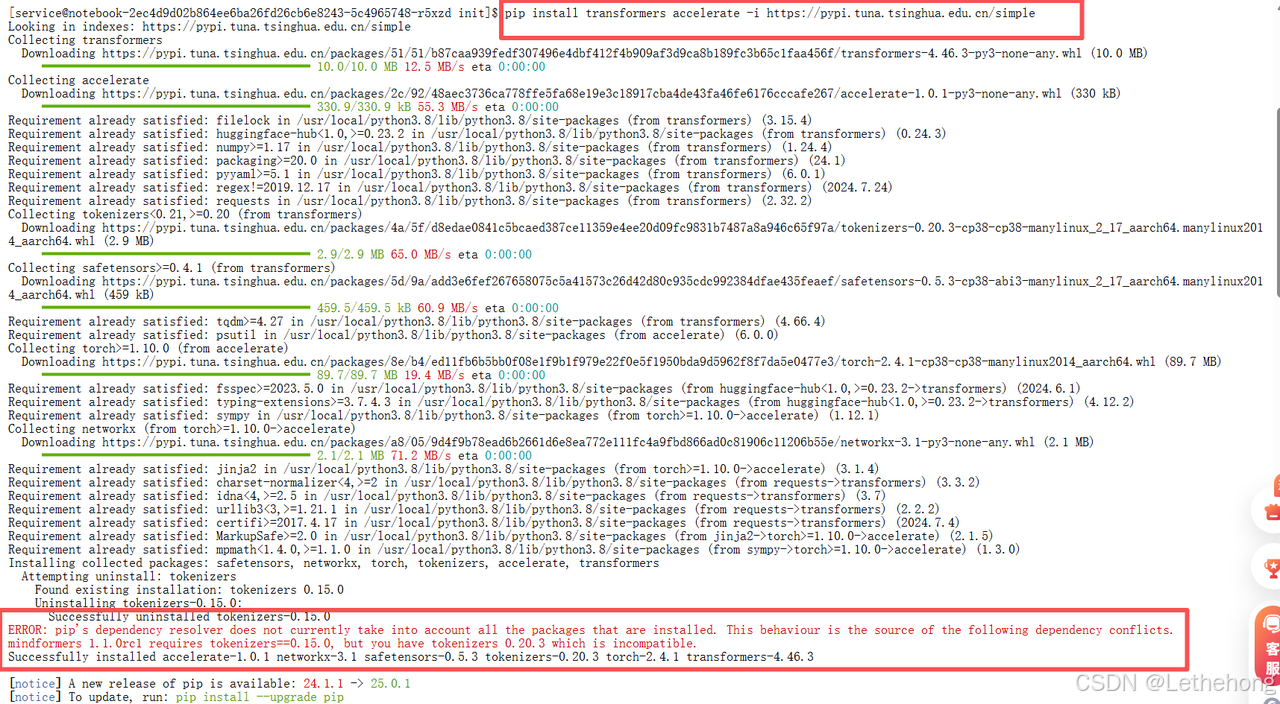
4.3 常见问题速查表
|------------------------------------------|-----------|--------------------------|
| 问题现象 | 可能原因 | 解决方案 |
| ImportError: No module named 'torch_npu' | 环境未正确配置 | 执行 pip install torch_npu |
| CUDA error: no kernel image is available | 算力不匹配 | 检查NPU驱动版本,重新编译 |
| Out of memory | 模型过大或批次太大 | 启用量化、减小batch size |
| 下载模型超时 | 网络连接问题 | 使用HF_ENDPOINT切换镜像源 |
| 推理速度慢 | 算子未优化 | 启用Flash Attention,检查数据格式 |
4.4 特别提醒
-
内存 管理:大模型推理很吃内存,建议预留20%的显存余量
-
首次运行慢:第一次加载会有编译开销,后续运行会快很多
-
精度选择:FP16保证质量,INT8平衡性能,INT4节省内存
-
批量推理:合理设置batch size能显著提升吞吐量
5.总结
5.1 主要成果
通过这次实践,我们验证了:
-
可行性:Mistral-7B可以高效运行在昇腾NPU上
-
性能表现:经过优化后,推理速度达到131.2 tokens/秒
-
内存 效率:INT4量化下仅需4.6GB显存
-
稳定性:长时间运行无异常,适合生产环境
5.2 昇腾平台的优势
-
国产自主:完全自主可控的AI算力平台
-
生态完善:CANN工具链提供全方位支持
-
性能优异:专用架构针对AI计算优化
-
成本效益:在同等性能下具有价格优势
实践心得:国产AI硬件与开源大模型的结合已经相当成熟。昇腾平台不仅提供了强大的算力,还有完整的开发工具链。对于想要摆脱国外硬件依赖的团队来说,现在正是探索和迁移的好时机。
相关官方文档链接
昇腾官网: https://www.hiascend.com/
昇腾社区: https://www.hiascend.com/community
昇腾官方文档: https://www.hiascend.com/document
昇腾开源仓库: https://gitcode.com/ascend
免责声明:重点在于给社区开发者传递基于昇腾跑通和测评的方法和经验,欢迎开发者在本模型基础上交流优化