TL;DR
- 场景:在大规模分布式缓存中使用 EVCache,需要搞清楚底层 Memcached 的内存管理与过期淘汰行为。
- 结论:EVCache 本质依赖 Memcached + Slab Allocation + 惰性过期 + 近似 LRU,性能好但也有内存碎片、淘汰抖动等工程风险。
- 产出:梳理 EVCache 底层 Memcached 架构、Slab Class/Item 结构、Lazy Expiration 与 LRU 淘汰逻辑,可直接用于容量规划与故障排查。
版本矩阵
| 组件/特性 | 已验证版本/范围 | 已验证说明 |
|---|---|---|
| Memcached 内核机制 | 1.4.x--1.6.x | Slab Allocation、Lazy Expiration、近似 LRU 的整体设计在该范围内保持一致,仅统计项与参数细节有差异。 |
| Slab Allocation 行为 | Memcached 1.6.x 主线 | Page=1MB、增长因子约 1.25 的默认策略在当前主流发行版中通用,具体 Chunk 起始值与数量可通过 stats slabs 实测。 |
| item 结构体布局 | 官方 memcached 源码主干 | 以 _stritem/item 结构为依据,不同版本在字段命名与附加标志位上可能有小差异,但整体布局和语义相同。 |
| EVCache 客户端架构 | 官方 Java 客户端(基于 Spymemcached) | 否(待补)文中只描述"EVCache 基于 Memcached + Spymemcached"的总体关系,未对特定版本 API 行为做逐一验证。 |
| 多线程与 libevent | Linux/Unix 主流部署环境 | 部分事件模型与线程池机制依赖编译参数和系统环境,文中为通用描述,实际部署需结合线上二进制与操作系统确认。 |
内部原理
EVCache 的内存存储是基于 Memcached 实现的。EVCache 的客户端是基于 Spymemcached 实现的。
Memcached
Memcached 是由 danga(丹加)公司开发的一套高性能的分布式内存对象缓存系统,最初是为 LiveJournal 社交平台设计的,用于缓解数据库负载压力。它通过将常用数据存储在内存中,显著减少了动态系统对后端数据库的访问次数,从而大幅提升应用性能。
核心特点:
-
客户端/服务器架构(C/S 模式):
- 采用经典的客户端-服务器模型
- 服务器端以守护进程方式运行,监听特定端口(默认 11211)
- 客户端通过 TCP/IP 或 UDP 协议与服务器通信
- 支持多种语言客户端(PHP、Java、Python等)
- 典型部署场景:Web 应用服务器作为客户端,连接独立的 Memcached 服务器集群
-
基于 libevent 的高性能事件处理:
- 使用 libevent 库实现高效的事件驱动模型
- 采用异步非阻塞 I/O 处理网络请求
- 单线程处理多个连接,避免线程切换开销
- 支持水平扩展,通过添加更多服务器节点提升整体容量
- 典型性能:单节点每秒可处理数万次请求
应用场景示例:
- 数据库查询结果缓存(如用户会话数据)
- API 响应缓存
- 页面片段缓存
- 计算密集型结果的临时存储
工作流程说明:
- 应用首先检查 Memcached 中是否存在所需数据
- 若命中缓存,直接返回结果
- 若未命中,则查询数据库
- 将数据库结果存入 Memcached(设置合理过期时间)
- 返回数据给应用
内存管理机制:
- 采用 LRU(最近最少使用)算法自动淘汰数据
- 内存分配使用 slab 机制,减少内存碎片
- 支持设置不同的过期时间策略
PS:libevent 是一个用C语言开发的,高性能,轻量级,专注于网络,不如ACE那么臃肿庞大,源代码很精炼易读,跨平台,支持多种IO多路复用技术,epoll、poll、select、kqueue等等,支持定时器和信号等事件,注册事件优先级。
此外,Memcached是多线程的。
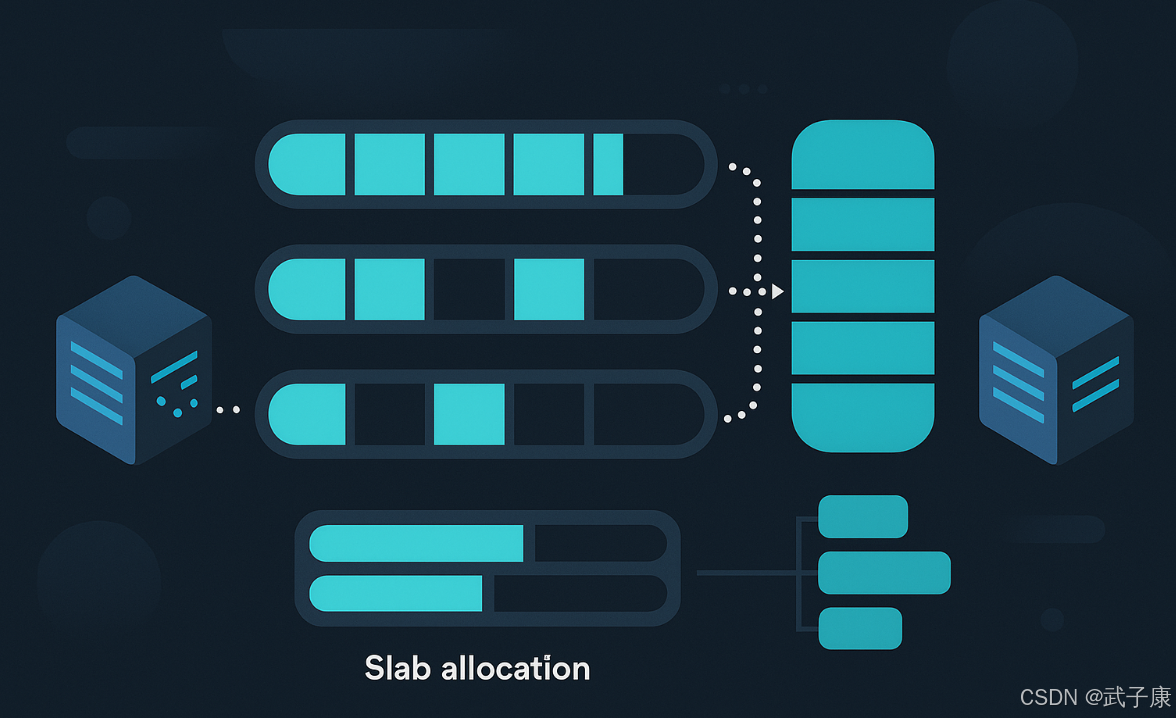
Slab Allocation
传统的内存分配方式是通过调用 malloc 和 free 函数动态分配和释放内存的。这种基于 Buddy System(伙伴系统)的分配方式是以 Page(通常为4KB或更大的内存页)为基本存储单位进行管理的。具体工作原理如下:
-
分配机制:
- 当程序请求内存时,系统会分配一个或多个完整的内存页
- 如果请求大小不足一页,仍然会分配整个页
- 内存释放后会被合并成更大的连续块
-
存在的问题:
- 内存碎片化严重:频繁分配释放不同大小的内存会导致大量无法利用的小内存碎片
- 效率问题:每次分配都需要经过复杂的内存查找和合并算法
- 浪费空间:小对象分配会占用整个内存页,造成空间浪费
- 加重OS负担:内存管理器需要频繁处理分配请求和碎片整理
Memcached采用了Slab Allocation(块分配)的内存管理机制来优化这些问题。Slab是源自Linux操作系统的一种高效内存分配机制,具有以下特点:
-
分配单位:
- 以Byte为单位进行精确分配
- 专为小内存分配场景设计
- 预先划分不同大小的内存块(chunk)
-
工作流程:
- 初始化时创建多个Slab Class,每个Class管理特定大小的内存块
- 例如:Class1管理88字节块,Class2管理112字节块等
- 请求分配时自动匹配最接近的Slab Class
-
优势体现:
- 减少内存碎片:固定大小的分配避免了外部碎片
- 提升性能:省去了复杂的内存查找过程
- 提高利用率:小对象不会浪费整个内存页
- 降低OS负担:大部分分配在用户空间完成
实际应用中,Slab Allocation特别适合Memcached这种需要频繁分配小内存块的场景。例如存储缓存条目时,可以根据对象大小自动选择最合适的Slab Class,既保证了内存利用率,又提高了分配效率。
Slab Allocation 是 Memcached 使用的一种高效内存管理机制,其核心原理如下:
- 内存分配基础:
- 以固定大小的 Page 为单位进行内存分配,默认每个 Page 大小为 1MB
- 通过
-m参数设置总内存大小(如memcached -m 64表示分配 64MB 内存)
- 内存分割机制:
- 将分配的内存分割成不同大小的 Chunk(块)
- Chunk 大小遵循增长因子(Growth Factor)规律,默认增长因子为 1.25
- 例如:第一个 Slab Class 的 Chunk 大小可能是 96B,下一个是 120B(96×1.25),依此类推
- Slab Class 组织:
- 将相同大小的 Chunk 组织成 Slab Class(组)
- 每个 Slab Class 包含多个 Page,每个 Page 包含多个相同大小的 Chunk
- 例如:96B 的 Slab Class 中,1MB Page 可包含约 10922 个 Chunk(1024×1024/96)
- 数据存储策略:
- 当存储数据时,Memcached 会选择能容纳该数据的最小 Slab Class
- 例如:100B 的数据会被存入 120B 的 Slab Class(而非更大的 144B)
- 这种策略最大限度地减少了内存浪费,但会导致每个 Item 都有少量内部碎片
- 优势特点:
- 避免了频繁的内存分配/释放操作
- 减少了内存碎片问题
- 通过预分配提高了内存访问效率
- 支持数据的快速存取
实际应用中,可以通过 stats slabs 命令查看各 Slab Class 的使用情况,包括:
- 每个 Slab Class 的 Chunk 大小
- 已使用的 Chunk 数量
- 内存使用率等信息

数据Item
Item就是我们要存储的数据,是以双向链表的形式存储的。
c
/**
* Structure for storing items within memcached.
* 表示 memcached 中的一条缓存记录(包含 key、元数据和 value)。
*/
typedef struct _stritem {
struct _stritem *next; // LRU 双向链表中的后向指针(next in LRU list)
struct _stritem *prev; // LRU 双向链表中的前向指针(prev in LRU list)
struct _stritem *h_next; /* 哈希桶中的后向指针(同一 hash bucket 的链表) */
rel_time_t time; /* 最近一次访问时间(用于 LRU),单位为相对时间 */
rel_time_t exptime; /* 过期时间(相对时间戳),0 表示不过期 */
int nbytes; /* value 区域的数据长度(包含结尾的 "\r\n") */
unsigned short refcount; /* 引用计数,用于并发访问和释放控制 */
uint8_t nsuffix; /* flags+length 组成的后缀字符串长度(包含 '\0') */
uint8_t it_flags; /* ITEM_* 标志位,标识 item 状态/类型 */
uint8_t slabs_clsid; /* 所属的 slab class ID,用于从正确的 slab 链回收 */
uint8_t nkey; /* key 的长度(包含结尾的 '\0') */
union {
uint64_t cas; /* CAS 版本号,用于 compare-and-swap 操作 */
char end; /* data 区域边界标记,用于内存布局对齐 */
} data[];
/* data[] 为柔性数组,紧随其后依次存放:
* 1) key 字符串(含 '\0')
* 2) 后缀字符串(flags + length 等,含 '\0')
* 3) value 数据(长度为 nbytes)
*/
} item;item的结构是两部分:
- item结构定义next、prev、time(最近访问时间)、exptime(过期时间)、nkey(key的长度)、refcount(引用次数)、nbytes(数据大小)、slabs_clsid
- item数据:CAS、key、suffix、value 组成
过期机制
Memcached 有两种过期机制:Lazy Expiration 和 LRU
Lazy Expiration
在 Memcached 的缓存机制中,采用的是惰性过期(Lazy Expiration)策略来处理数据的过期问题。这种策略的核心特点是:不会主动扫描和清理过期数据,而是在每次执行 get 操作时才会检查数据是否过期。
具体实现流程如下:
- 数据存储阶段:
- 当使用 set/add/replace 命令存储数据时,可以指定一个过期时间(exptime)
- 这个 exptime 可以是相对时间(如 3600 表示 1 小时后过期)或绝对时间戳
- 数据获取阶段:
- 当客户端发起 get 请求获取某个 key 对应的数据时
- Memcached 会先检查该 key 是否存在
- 如果存在,则获取该数据的元信息,包括存储时设置的 exptime
- 系统会计算当前时间(now)与 exptime 的差值(now - exptime)
- 如果差值大于 0(now > exptime),说明数据已过期
- 过期处理:
- 对于已过期的数据,Memcached 会立即将其从内存中删除
- 然后返回给客户端一个"未找到"的响应(NOT_FOUND)
- 如果数据未过期,则正常返回对应的 value 值
这种惰性过期机制的优势在于:
- 节省系统资源:不需要额外的后台线程或定时任务来扫描过期数据
- 按需处理:只有在真正访问数据时才进行过期检查
- 避免不必要的 CPU 开销:对于很少访问的过期数据,可以长期不被处理
典型应用场景:
- 缓存热点数据时,可以设置较短的过期时间
- 临时性数据存储,如会话信息、验证码等
- 需要及时更新的配置信息缓存
需要注意的是:
- 过期的数据不会立即从内存中释放,直到被访问时才会清理
- 长期不被访问的过期数据会一直占用内存空间
- 在高并发场景下,大量同时过期的 key 可能导致瞬时性能下降
LRU
当Memcached使用的内存超过配置的最大内存限制(通过-m参数指定,默认值为64MB)时,系统会触发LRU(Least Recently Used)算法来回收内存空间。这一过程主要通过slabs_alloc函数的内存分配失败作为触发条件。
内存淘汰的具体执行流程如下:
-
淘汰触发条件:
- 当slabs_alloc函数尝试为新数据分配内存失败时
- 当前内存使用量已达到或超过配置的最大内存限制
-
淘汰执行步骤:
(1) 系统从对应slab class的数据项列表(item list)的尾部开始逆向扫描
(2) 优先查找满足以下条件的item进行释放:
-
引用计数器(refcount)值为0的item(表示没有被任何客户端引用)
-
如果找不到refcount为0的item,则查找最近访问时间超过3小时的item(now-time > 3H)
(3) 如果上述条件都无法满足,则返回NULL表示淘汰失败
-
-
淘汰策略特点:
- 采用近似LRU算法,不是严格的LRU实现
- 优先淘汰两种类型的数据:
- 冷数据:长时间未被访问的item(3小时阈值)
- 无效数据:引用计数为0的item
- 淘汰是逐slab class进行的,不同大小的item分开管理
-
实际应用场景示例:
- 电商秒杀场景中,大量临时缓存数据可能在短时间内被淘汰
- 新闻热点场景中,过期的新闻缓存会被优先淘汰
- 用户会话数据中,长时间不活跃的会话会被清理
-
性能影响:
- 淘汰过程会产生额外的CPU开销
- 频繁触发淘汰可能影响服务响应时间
- 合理的最大内存配置可以减少淘汰频率
-
监控指标:
- evictions计数器会记录淘汰发生的次数
- 可以通过stats命令查看淘汰统计信息
- 监控evictions增长趋势可以判断内存配置是否合理
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 命中率正常但延迟偶发飙高,evictions 指标持续增长 | -m 配置过小或热点数据膨胀,频繁触发 LRU 淘汰,分配失败走回收路径 stats, stats slabs, stats items 查看 evictions、内存使用与热点 key 分布 | 提升 -m 配额或拆分业务缓存;调优 key 设计,减少大对象;必要时做本地缓存+多级缓存。 |
| 某些 key 偶尔"突然失踪",但业务认为远未到期 | LRU 淘汰优先回收"长时间未访问或 refcount=0 的 item",惰性过期未访问 stats items 比对 age、evicted、evicted_nonzero;抓取业务访问轨迹 | 调整缓存粒度与访问模式,确保核心 key 有足够访问频率;提高 value 复算能力,接受淘汰。 |
| 内存使用率看似不高,但无法再插入新数据,频繁 alloc 失败 | Slab Allocation 导致"类满"但结构浪费,某些 Slab Class 被大对象占用 stats slabs 查看各 Slab Class 的 chunk_size、used_chunks、free_chunks | 重新规划 key/value 大小,避免大量临界尺寸对象;按大小拆分实例;必要时重启重排内存。 |
| 过期时间到达后,监控中仍能看到大量"疑似已过期"的 key 存在 | 使用 Lazy Expiration,未被访问的过期数据不会主动清理 stats 中观察 curr_items 与访问 QPS,对比业务侧命中日志 | 接受惰性过期特性;对关键 key 通过主动 get 或批量扫描触发清理;结合短 TTL 与版本号设计。 |
| CAS 更新失败比例高,出现大量冲突重试 | 热点 key 写竞争严重,item.cas 版本频繁变化 打印 CAS 失败统计;抓取热点 key 抽样,分析写入并发模式 | 对热点 key 做分桶/分片;用"版本号 + 普通 set"替代严格 CAS;必要时业务侧加锁或排队。 |
| 某些 Slab Class 的 evicted_nonzero 偏高 | 被淘汰 item 在淘汰时仍有引用,说明有业务长持有或慢消费 stats slabs 中关注 evicted_nonzero;对相应 key 类型增加访问/释放日志 | 排查客户端长连接/长持有行为,缩短本地缓存持有时间;避免在业务里长时间保留 item 引用。 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接