文章目录
- 开篇导读
- 环境准备
- 部署Kubernetes集群
-
- kubeadm部署高可用集群
-
- [安装kubelet kubeadm kubectl](#安装kubelet kubeadm kubectl)
- 下载Kubernetes各版本镜像
- Kubeadm初始化Kubernetes集群
- 配置Kubectl配置文件config
- 安装网络插件Calico
- 二进制高可用集群
- 证书
-
- [安装 cfssl](#安装 cfssl)
- 制作CA证书
- 创建证书颁发机构(CA)
- 创建kube-apiserver证书
- 创建kube-controller-manager证书
- 创建kube-scheduler的证书
- 创建kube-proxy证书
- 创建集群管理员证书
- [创建 ServiceAccount Key](#创建 ServiceAccount Key)
- kubernetes离线安装包
- 配置文件
- 启动master组件
- 部署kubelet
- 部署kube-proxy
- 启动kubelet和kube-proxy
- [授权 apiserver 访问 kubelet](#授权 apiserver 访问 kubelet)
- [部署 CNI 网络](#部署 CNI 网络)
- [部署 CoreDNS](#部署 CoreDNS)
- K8S卸载
开篇导读
Docker是一个非常流行的容器化平台,它可以让我们方便构建、打包、发布和运行容器化应用程序。但是,在生产环境中,我们可能需要处理成百上千个容器,需要更好的管理这些容器,这就是Kubernetes的用武之地。Kubernetes是一个开源容器编排系统,它可以管理和部署容器化应用程序,自动化容器部署、扩展和故障恢复。Kubernetes可以让我们更好管理容器与容器相关的资源和服务,同时提供了许多强大的功能,如:负载均衡、自动扩展、滚动更新、健康检查等。Kubernetes的安装方法有很多,但官方推荐的只包括Kubeadm和二进制安装。因为Kubeadm和二进制安装可以提供更加稳定、更适合生产环境的Kubernetes。本文将演示如何使用二进制和kubeadm快速部署一个 Kubernetes v1.30 集群。
先了解下,Kubeadm和二进制两种安装方式的适用场景。Kubeadm是官方提供的开源工具,用于快速搭建K8S集群,也是比较方便和推荐的方式。其中的kubeadm init和kubeadm join这两个命令可以快速创建K8S集群。Kubeadm可以初始化K8S,且所有的组件都以Pod形式运行,具有故障自恢复能力。Kubeadm相当于使用程序脚本帮助我们自动完成集群安装,简化部署操作,证书、组件资源清单文件都是自动创建的。自动部署屏蔽了很多细节,使用者对各个模块的了解较少,遇到问题比较难排错。因此,Kubeadm适合需要经常部署K8S或对自动化要求比较高的场景使用。二进制安装就是手动安装,步骤繁琐,对K8S理解的更加全面。
Kubernetes 部署方式有很多,建议使用CNCF认证的安装方法进行安装,更多安装方法:https://www.cncf.io/training/certification/software-conformance

环境准备
主机环境预设
本示例中的Kubernetes集群部署将基于以下环境进行
OS: CentOS 7.9.2009
内核版本:5.4.225
Kubernetes:v1.30.0
Container Runtime: Docker CE 23.0.5
CRI:cri-dockerd v0.3.1
测试使用的Kubernetes集群可由一个master主机及一个以上(建议至少两个)node主机组成,这些主机可以是物理服务器,也可以运行于vmware、virtualbox或kvm等虚拟化平台上的虚拟机,甚至是公有云上的VPS主机。本案例使用的是虚拟机来进行部署,服务器清单如下:
| 节点 | ip | 用途 |
|---|---|---|
| master(3台) | 192.168.209.101/102/103 | Kubernetes控制端,通过一个vip做主备高可用 |
| etcd(3台) | 192.168.209.101/102/103 | 保存Kubernetes集群数据 |
| harbor(2台) | 192.168.209.101/102 | 镜像仓库 |
| nginx (2台) | 192.168.209.101/102 | 高可用etcd代理服务器 |
| node(2-N台) | 192.168.177.201/202 | 运行容器的服务器,高可用环境至少2台 |
配置静态ip
服务器或虚拟机的IP地址默认都是DHCP动态分配的,这样重启机器IP地址就会变化,为让IP固定不变,需设置静态IP。每台机器的ip都需要修改,我这里以master1为例
bash
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
......
ONBOOT="yes" #开机启动网络,必须yes
BOOTPROTO="static" #使用静态地址
IPADDR="192.168.209.101" #IP地址,需要和自己计算机所在的网段一致
NETMASK="255.255.255.0" #子网掩码,需要和自己计算机所在的网段一致
GATEWAY="192.168.209.2" #网关,可以使用route -n查看自己电脑网关地址
DNS1="8.8.8.8"配置文件修改完后,需要重启网络才能使配置生效
bash
service network restart升级内核
由于centos7.9的系统默认内核版本是3.10,3.10的内核有很多BUG,最常见的一个就是group memory leak。我们这里内核升级为5.4.225,查看我们本机的内核版本
bash
wget http://mirrors.coreix.net/elrepo-archive-archive/kernel/el7/x86_64/RPMS/kernel-lt-devel-5.4.225-1.el7.elrepo.x86_64.rpm
wget http://mirrors.coreix.net/elrepo-archive-archive/kernel/el7/x86_64/RPMS/kernel-lt-5.4.225-1.el7.elrepo.x86_64.rpm安装内核
bash
rpm -ivh kernel-lt-5.4.225-1.el7.elrepo.x86_64.rpm
rpm -ivh kernel-lt-devel-5.4.225-1.el7.elrepo.x86_64.rpm检查已安装内核版本
bash
rpm -qa | grep kernel查看系统上的所有可用内核
bash
awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg设置启动
bash
grub2-set-default 0生成 grub 配置文件,GRUB2 的配置文件通常为 /boot/grub2/grub.cfg,虽然此文件很灵活,但是我们并不需要手写所有内容。可以通过程序自动生成,或是直接修改生成之后的文件。通常情况下简单配置文件 /etc/default/grub ,然后用程序 grub-mkconfig 来产生文件 grub.cfg
bash
grub2-mkconfig -o /boot/grub2/grub.cfg重启机器
bash
reboot修改主机名
在K8s集群中,每个节点都需要一个唯一的名称标识自己,这个名称需要在加入集群时使用。若设置主机名,管理员可以更轻松管理容器,方便通过主机名识别和访问每个节点。在每个节点执行如下命令,修改主机名
bash
#hostnamectl set-hostname <主机名>
hostnamectl set-hostname k8s-master1
hostnamectl set-hostname k8s-master2
hostnamectl set-hostname k8s-master3
hostnamectl set-hostname k8s-node1
hostnamectl set-hostname k8s-node2配置hosts文件,把主机名称和IP对应关系添加到/etc/hosts。让每个k8s节点通过主机名互相通信,不需要记ip地址了,修改每台机器的/etc/hosts文件
bash
cat >> /etc/hosts << EOF
192.168.209.101 k8s-master1
192.168.209.102 k8s-master2
192.168.209.103 k8s-master3
192.168.209.201 k8s-node1
192.168.209.202 k8s-node2
EOF配置免密登录
配置控制节点到工作节点免密登录。在k8s集群中,控制节点需要能通过SSH链接到工作节点中,以执行各种命令和任务。每次都输入密码登录,非常麻烦,建议配置ssh免密登录,提高工作效率。在控制节点生成ssh密钥
bash
ssh-keygen选项直接回车,默认即可。 可以看到密钥文件生成在root目录下的.ssh目录中。默认情况下,生成一个id_rsa私钥文件和id_rsa.pub公钥文件,私钥应该保持安全,只有持有私钥的用户才能对它进行身份验证。公钥文件交给其他计算机上的授权用户,以便将它添加到本地计算机的授权列表,进而允许该用户在本地计算机上进行ssh连接。
安装 sshpass
bash
yum install sshpass接下来执行命令,将公钥文件发送给各个k8s节点服务器
bash
for i in {1..5};do sshpass -p '123456' ssh-copy-id root@192.168.209.20$i ;done以上命令分别将当前用户的公钥文件(默认~/.ssh/id_rsa.pub)复制到三个节点中,便于用户ssh免密登录。 ssh-copy-id工具会自动使用SSH协议进行连接,在目标计算机建立.ssh目录(若不存在),并将当前用户的公钥追加到目标计算机的~/.ssh/authorized_keys文件中。
关闭swap交换区
Linux中交换分区(Swap)类似于Windows的虚拟内存,就是当内存不足时,把一部分硬盘空间虚拟成内存使用,解决内存容量不足的问题。在k8s集群中,关闭交换分区可以确保内存不被交换出去,避免内存不足导致应用程序崩溃和节点异常。因为k8s在每个节点部署多个容器,若节点上的应用程序的内存超过了可用内存,操作系统就会将部分的内存换出到硬盘,降低了容器的性能和稳定性。所以在部署k8s集群时,需要关闭交换分区。kubelet 在 1.8 版本以后强制要求 swap 必须关闭,否则会报如下错误:
bash
Running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false或者kubeadm init时会报错:
bash
[ERROR Swap]: running with swap on is not supported. Please disable swap两种关闭方式,一种临时,一种永久
1、临时关闭
bash
swapoff -a2、永久关闭
使用vim命令打开/etc/fstab文件,直接注释掉挂载交换分区即可,每台机器都需要关闭
bash
#/dev/mapper/centos-swap swap swap defaults 0 0fstab全称(File System Table),系统启动时,会读取这个文件的数据,并根据其中的信息自动挂载文件系统。所以最好重启下机器,重新读取一下fstab文件,或者再执行下临时方案就行了。
关闭防火墙
在安装k8s集群时,关闭Firewalld防火墙可以避免由于防火墙造成的k8s集群组件无法正常通信的问题。k8s需要使用大量的网络端口进行通信,包括etcd、kubelet、kube-proxy等组件都需要开放对应的端口才能工作。在关闭防火墙前,确保已经采取了安全措施,如安全组来保护节点安全问性。每台机器都执行
bash
systemctl stop firewalld; systemctl disable firewalld关闭SELinux
安装k8s集群,通常关闭SELinux,默认情况下,SELinux可能会阻止k8s某些操作,如挂载卷和访问容器日志等。可能使k8s无法正常工作。关闭SELinux,每台机器都执行
bash
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config验证是否已经关闭,如果显示Disabled,那么说明已经关闭了
bash
getenforce配置时间同步
在k8s集群中,时间同步很重要,因为k8s各个组件之间需要通过时间戳确定事件的先后顺序,若各个节点的时间不同步,会导致k8s出现各种问题。每台机器都执行
bash
yum -y install ntpdate # 安装软件
ntpdate cn.pool.ntp.org # 同步网络时间定时任务同步时间,每三十分钟执行一次
bash
[root@k8s-master1 ~]# crontab -e
*/30 * * * * /usr/sbin/ntpdate cn.pool.ntp.org如果第一次没有实现时间同步,可以使用相关命令来完成相关的同步操作,输入 ntpdate time1.aliyun.com ,然后回车
修改内核参数
安装IPVS
bash
yum -y install conntrack-tools ipvsadm ipset conntrack libseccomp加载 IPVS 模块、加载br_netfilter模块,kube-prox开启ipvs的前置条件。br_netfilter叫透明防火墙,又称桥接模式防火墙。就是在网桥设备中增加防火墙功能,开启ip6tables和iptables需要加载透明防火墙
bash
cat > /etc/sysconfig/modules/ipvs.modules <<"EOF"
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in ${ipvs_modules}; do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done
EOF执行脚本
bash
sh /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs增加kubernetes转发配置
bash
cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp.keepaliv.probes = 3
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp.max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp.max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.top_timestamps = 0
net.core.somaxconn = 16384
EOF立即生效
bash
sysctl --system接下来我们修改limits.conf文件
bash
cat >> /etc/security/limits.conf << EOF
* soft nofile 655360
* hard nofile 131072
* soft nproc 655350
* hard nproc 655350
* soft memlock unlimited
* hard memlock unlimited
EOF部署 Keepalived + Nginx
在高可用 Kubernetes 集群中,可以通过 Keepalived + Nginx 实现 API Server 的高可用。这里为了节约服务器,将 Keepalived + Nginx 部署在 Master 节点上。Keepalived 提供固定入口(VIP),Nginx 提供负载均衡(16443 → 三台 Master 的 6443),最终实现 Kubernetes 控制平面的高可用。
Keepalived 提供虚拟IP:192.168.209.100,VIP 始终会漂移到某一台 Master 节点上,确保对外始终有一个固定的访问入口。Nginx 作为反向代理,在每台 Master 节点上部署 Nginx。Nginx 监听 16443 端口,对外提供统一的访问入口。Nginx 会将来自 VIP:16443 的请求,反向代理到本机或其他 Master 节点的 6443(Kubernetes API Server 的默认端口),这样就实现了多个 Master 节点的负载均衡。对 kubectl 客户端而言,只需要访问 192.168.209.100:16443。请求会先进入 Nginx,再由 Nginx 负载均衡转发到三台 Master 的 6443 端口,从而实现 API Server 的高可用。
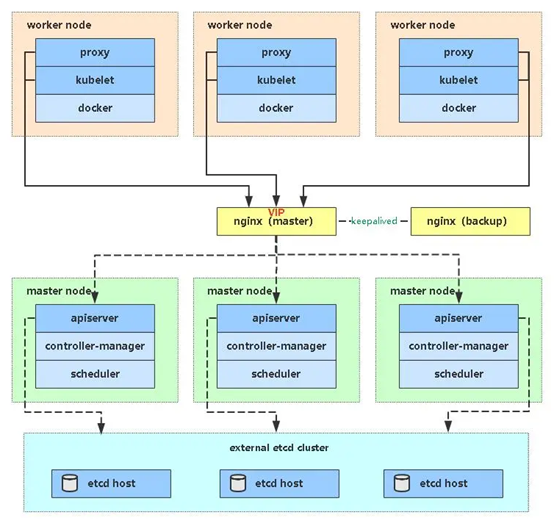
haproxy+keepalived高可用如图所示
部署 Nginx
安装Nginx,我这里部署在了 k8s-master1 和 k8s-master2 节点。添加 CentOS 7 Nginx yum 资源库
bash
sudo rpm -Uvh http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm安装Nginx
bash
yum -y install nginx修改nginx配置文件,修改upstream处各个端口,改为三个master节点的IP
bash
cat > /etc/nginx/nginx.conf << "EOF"
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.209.101:6443;
server 192.168.209.102:6443;
server 192.168.209.103:6443;
}
server {
listen 16443;
proxy_pass k8s-apiserver;
}
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
EOF启动nginx并设置开机自启
bash
systemctl enable --now nginx.service && systemctl status nginx安装 Keepalived
安装keepalived,我这里部署在了 k8s-master1 和 k8s-master2 节点
bash
yum -y install keepalivedk8s-master1节点配置keepalived
bash
mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf_bak
NODE_IP=`hostname -i`
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_kubernetes {
script "/etc/keepalived/check_kubernetes.sh" #检测脚本文件
interval 5 #检测时间间隔
weight -5 #权重
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER # 主机状态master,从节点为BACKUP
interface ens33 #设置实例绑定的网卡
mcast_src_ip ${NODE_IP} # 广播的原地址
virtual_router_id 51 #同一实例下virtual_router_id必须相同
priority 100 #设置优先级,优先级高的会被竞选为Master
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.209.100 #设置VIP,可以设置多个
}
}
EOFk8s-master2节点配置keepalived
bash
mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf_bak
NODE_IP=`hostname -i`
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_kubernetes {
script "/etc/keepalived/check_kubernetes.sh" #检测脚本文件
interval 5 #检测时间间隔
weight -5 #权重
fall 3
rise 2
}
vrrp_instance VI_1 {
state BACKUP # 主机状态master,从节点为BACKUP
interface ens33 #设置实例绑定的网卡
mcast_src_ip ${NODE_IP} # 广播的原地址
virtual_router_id 51 #同一实例下virtual_router_id必须相同
priority 100 #设置优先级,优先级高的会被竞选为Master
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
192.168.209.100 #设置VIP,可以设置多个
}
}
EOF启动keepalived,并设置开机自启
bash
systemctl enable --now keepalived && systemctl status keepalived在 k8s-master1 节点执行 ip a show 会发现多了一个VIP
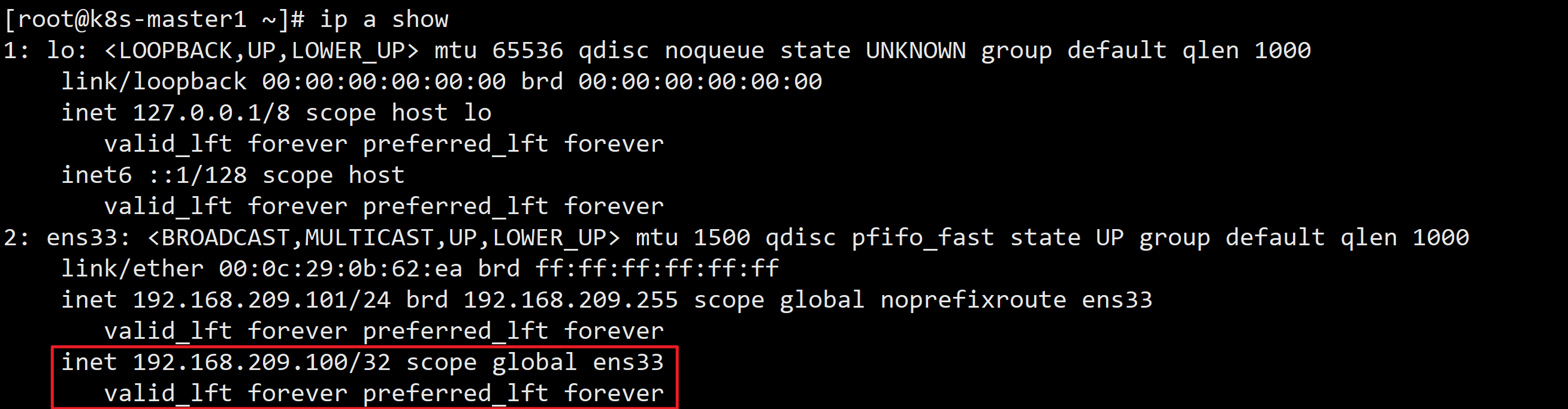
在 k8s-master1 节点停止keepalived,模拟事故
bash
systemctl stop keepalived此时,在 k8s-master2 节点执行 ip a show 会发现多了一个VIP,说明keepalived生效了
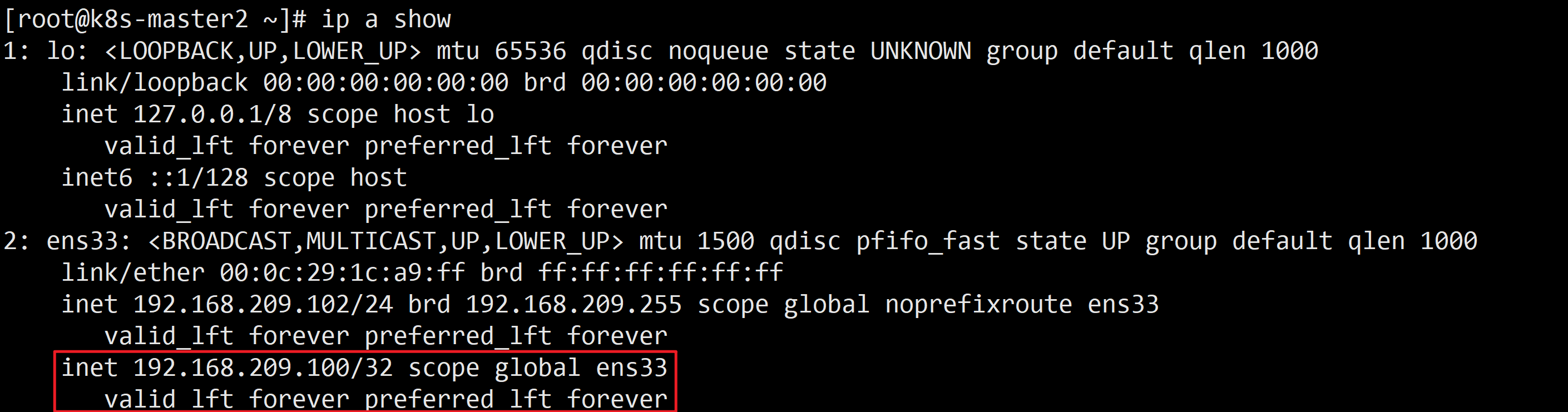
安装Docker-CE
K8s是一个容器编排和管理系统,它的任务是在集群中部署、运行和管理容器化应用程序。因此,Kubernetes需要一个容器运行时来管理容器,以便能够将容器化的应用程序部署和运行在集群中。Docker和Containerd都是常用的容器运行时,因此在安装Kubernetes前需要安装其一。从k8s1.20版本开始,k8s官方将默认的容器运行时从Docker改为了Containerd。在1.24版本后,Docker作为容器运行时已经被弃用,Containerd成为唯一推荐的容器运行时,所有节点均安装,安装步骤如下:
yum在线安装
安装 yum-utils 软件包
bash
yum -y install yum-utils添加阿里源docker-ce镜像仓库
bash
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo查看可用docker版本,注意:docker和k8s版本有指定要求 可前往github查看对应版本https://github.com/kubernetes/kubernetes/tree/master/CHANGELOG
bash
yum list docker-ce --showduplicates | sort -r安装指定版本,如:docker-ce-20.10.24-3.el7
bash
yum -y install docker-ce-25.0.5-1.el7 docker-ce-cli-25.0.5启动docker服务并设置开机自启
bash
systemctl start docker && systemctl enable docker配置阿里镜像加速
bash
cat > /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://d6mtathr.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF重启docker服务
bash
systemctl restart dockerDocker离线部署流程
之前做了一个xx项目,使用的服务器都是内网环境,所以自己整合了一下Docker离线部署的方法分享给大家
1、下载docker离线安装包,大家根据自己的需求下载自己对应的版本。此处我下载的是25.0.5版本
2、将离线包上传到服务器,可以使用xftp等软件将离线包放入服务器指定目录,我这里上传到了/opt/docker目录下,没有的话可以自己创建docker文件夹,解压
bash
tar -xf docker-25.0.5.tgz
mv docker/* /usr/local/bin/3、创建系统配置文件
bash
cat > /usr/lib/systemd/system/docker.service <<"EOF"
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/local/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF这个单元文件定义了Docker服务的配置和行为,包括以下几点:
在[Unit]段中,描述了该服务的简要说明和相关文档链接,以及依赖的其他服务。
在[Service]段中,定义了服务的启动、重新加载和关闭的命令,以及资源限制和重启策略等。
在[Install]段中,指定了服务的启动级别。
启动docker服务并设置开机自启
bash
systemctl start docker && systemctl enable docker配置阿里镜像加速,并修改Cgroup Driver为systemd(新版无需执行),Kubernetes v1.22版本开始,未明确设置kubelet的cgroup driver时,则默认即会将其设置为systemd。从 Docker 20.03 版本开始,默认使用 systemd 作为 Cgroup 驱动程序。如果系统没有安装 systemd,Docker 会自动切换到 cgroupfs 驱动程序。因此 Docker 20.03 版本之后此步无需再执行此步
bash
cat > /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://d6mtathr.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF重启docker服务
bash
systemctl restart docker部署cri-docker
自 1.24 版起,Dockershim 已从 Kubernetes 项目中移除。因为历史问题docker却不支持kubernetes主推的CRI(容器运行时接口)标准,所以docker不能再作为kubernetes的容器运行时了,即从kubernetesv1.24开始不再使用docker了。但是如果想继续使用docker的话,可以在kubelet和docker之间加上一个中间层cri-docker。cri-docker是一个支持CRI标准的shim(垫片)。一头通过CRI跟kubelet交互,另一头跟docker api交互,从而间接的实现了kubernetes以docker作为容器运行时。但是这种架构缺点也很明显,调用链更长,效率更低。
下载cri-docker: https://github.com/Mirantis/cri-dockerd/tags
bash
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.11/cri-dockerd-0.3.11.amd64.tgz解压,然后拷贝到其他节点
bash
tar -xf cri-dockerd-0.3.11.amd64.tgz
cp cri-dockerd/cri-dockerd /usr/local/bin/
scp /usr/local/bin/cri-dockerd k8s-master2:/usr/local/bin/
scp /usr/local/bin/cri-dockerd k8s-master3:/usr/local/bin/创建cri-docker启动文件,然后拷贝到其他节点
bash
cat > /usr/lib/systemd/system/cri-docker.service << "EOF"
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/local/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF创建cri-docker.socket
bash
cat > /usr/lib/systemd/system/cri-docker.socket << EOF
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
EOF启动cri-docker并设置开机自动启动
bash
systemctl enable cri-docker --now查看状态
bash
systemctl is-active cri-docker部署Kubernetes集群
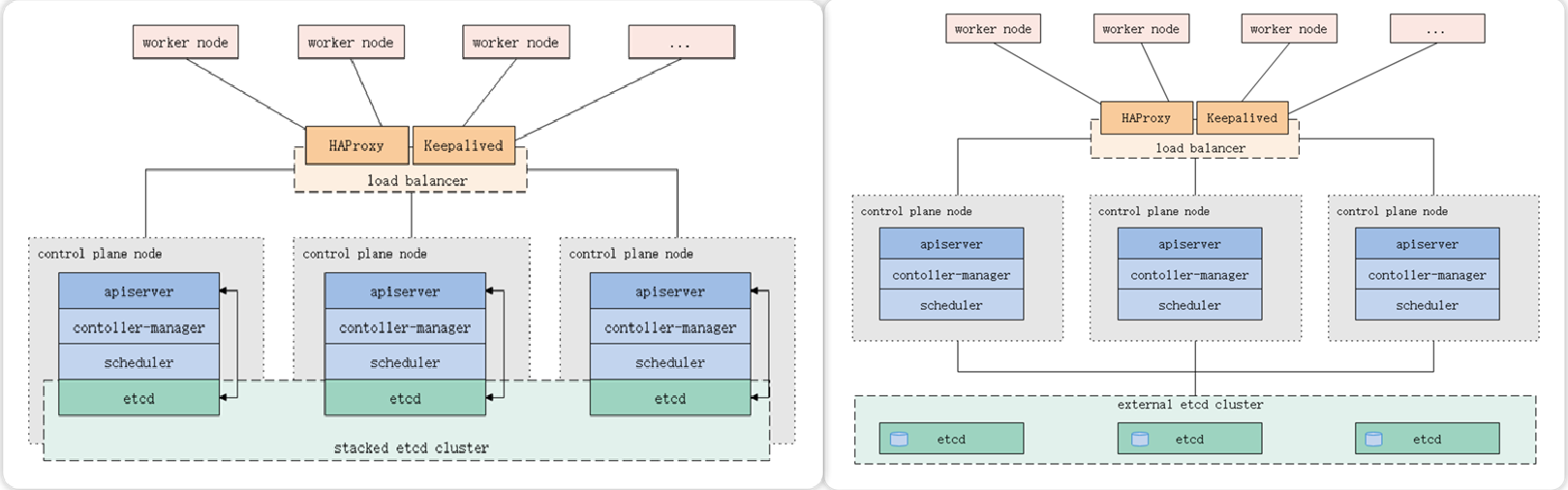
kubeadm部署高可用集群
kubeadm不仅支持集群部署,还支持集群升级、卸载、数字证书更新等功能。目前kubeadm安装的k8s集群证书默认是一年365天,过期后就无法使用。kubeadm支持部署如下两种高可用模型
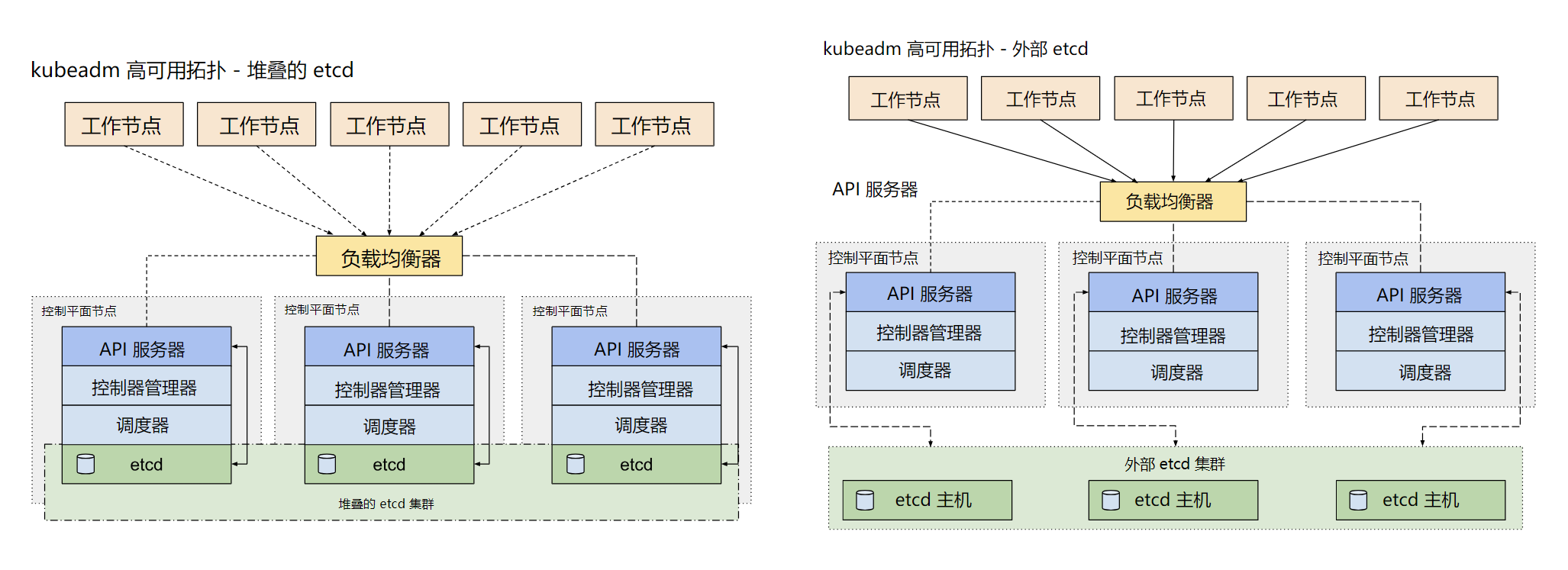
安装kubelet kubeadm kubectl
配置kubernetes源,每台机器都执行
bash
cat << EOF | tee /etc/yum.repos.d/kubernetes.repo
[k8s]
name=k8s
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm/
gpgcheck=0
EOF查看可安装的版本,选择合适的版本,这里选择1.30.0-150500.1.1
bash
yum list kubeadm.x86_64 --showduplicates
yum list kubelet.x86_64 --showduplicates
yum list kubectl.x86_64 --showduplicates
yum -y install kubeadm-1.30.0-150500.1.1 kubelet-1.30.0-150500.1.1 kubectl-1.30.0-150500.1.1修改kubelet文件,配置kublet的cgroup驱动与docker一致
bash
[root@k8s-master1 ~]# cat /etc/docker/daemon.json
{
......
"exec-opts": ["native.cgroupdriver=systemd"]
}
[root@k8s-master1 ~]# cat /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"设置kubelet开机自启
bash
systemctl enable kubelet下载Kubernetes各版本镜像
查看各版本镜像列表,如果查看其他版本镜像列表,只需要修改版本号即可
bash
[root@k8s-master1 ~]# kubeadm config images list --kubernetes-version=v1.30.0
registry.k8s.io/kube-apiserver:v1.30.0
registry.k8s.io/kube-controller-manager:v1.30.0
registry.k8s.io/kube-scheduler:v1.30.0
registry.k8s.io/kube-proxy:v1.30.0
registry.k8s.io/coredns/coredns:v1.11.1
registry.k8s.io/pause:3.9
registry.k8s.io/etcd:3.5.12-0使用下面脚本下载阿里云kubernetes核心镜像,然后修改tag,这样yaml文件的镜像名称就可以不用修改了
bash
#!/bin/bash
url=registry.cn-hangzhou.aliyuncs.com/google_containers
version=v1.30.0
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $NF}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename registry.k8s.io/$imagename
docker rmi -f $url/$imagename
donecoredns镜像比较特殊,需要手动处理
bash
docker tag registry.k8s.io/coredns:v1.11.1 registry.k8s.io/coredns/coredns:v1.11.1
docker rmi registry.k8s.io/coredns:v1.11.1Kubeadm初始化Kubernetes集群
这里只需要在第一个主节点k8s-master1操作,生成kubeadm-config.yaml配置文件。kubeadm config print init-defaults 是Kubeadm的命令,用于打印默认的Kubernetes初始化配置内容,并且输出到一个文件中。之后使用kubeadm init初始化k8s集群,可以使用这个文件作为输入,而不是手动输入
bash
kubeadm config print init-defaults --component-configs KubeletConfiguration > kubeadm-config.yaml修改kubeadm-config.yaml配置文件,需要修改和添加的部分包括:
1、advertiseAddress处 改为 k8s-master1的IP
2、添加或修改nodeRegistration: 对应的配置
3、添加certSANs 处配置,配置为keepalived VIP地址
4、修改etcd配置
5、修改imageRepository配置
6、添加controlPlaneEndpoint处配置,配置为VIP:16443
bash
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s #指定token有效期,默认24小时,0s为永不失效
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.209.101 #指定当前master主机IP
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock
imagePullPolicy: IfNotPresent
name: k8s-master1 #修改为本机主机名
taints: null
---
apiServer:
certSANs:
- 192.168.209.100
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
#内置ETCD,也就是pod方式部署
etcd:
local:
dataDir: /var/lib/etcd
#如果已经部署了ETCD,可以使用如下配置
#etcd:
# external:
# endpoints:
# - http://192.168.209.101:2379
# - http://192.168.209.102:2379
# - http://192.168.209.103:2379
imageRepository: registry.k8s.io
kind: ClusterConfiguration
kubernetesVersion: 1.30.0
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 # 指定Pod的网段
serviceSubnet: 10.96.0.0/12 # 指定service的网段
controlPlaneEndpoint: "192.168.209.100:16443"
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMaximumGCAge: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
text:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0skubeadm初始化Kubenetes集群
bash
kubeadm init --config kubeadm-config.yaml --upload-certs --v=9如果我们执行kubeadm init初始化集群失败,或者不想把这台机器作为控制节点来使用了,那么我们可以使用kubeadm reset命令将kubernetes集群进行重置
bash
kubeadm reset -f配置Kubectl配置文件config
默认安装kubernetes后,kubectl是无权限访问kubernetes的API的,所以需要一个config文件,相当于是对kubectl进行授权,这样kubectl命令可以使用config文件中的用户和证书对kubernetes集群进行管理。 在家目录创建一个.kube目录,存放全局config文件
bash
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config # 将admin.conf拷贝到$HOME/.kube
sudo chown $(id -u):$(id -g) $HOME/.kube/config # 设置权限查看kubernetes集群,节点状态为NotReady,因为没有安装网络插件
bash
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane 13s v1.30.0在 k8s-master2 和 k8s-master3 执行主节点join,k8s-master1 执行init后提示的带control-plane的命令。在命令后添加--cri-socket unix:///var/run/cri-dockerd.sock
bash
kubeadm join 192.168.209.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:40b8d855d33684256b9b20b332a13da397ca85cfa4379c8ae8f52c0a9d9788a3 \
--control-plane --certificate-key e7888ec8bb448e002439d5b97856c420d2e694078ec76ba06614b35c24a55db6 \
--cri-socket unix:///var/run/cri-dockerd.sockk8s-master2和k8s-master3 join后,执行提示的三条命令
bash
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config在node节点执行join,k8s-master1 init后提示的不带control-plane的命令,在命令后添加--cri-socket unix:///var/run/cri-dockerd.sock
bash
kubeadm join 192.168.209.100:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:40b8d855d33684256b9b20b332a13da397ca85cfa4379c8ae8f52c0a9d9788a3 \
--cri-socket unix:///var/run/cri-dockerd.sock可以看到,集群中又增加了两位小伙伴,它们的角色现在都是None,通常来讲我们是将另外两个none角色的节点称之为工作节点,ok了,集群中状态都是NotReady状态,我们安装完网络插件就好了。至此,kubernetes的5个节点都安装好了
bash
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane 2m v1.30.0
k8s-master2 NotReady control-plane 3m v1.30.0
k8s-master3 NotReady control-plane 3m v1.30.0
k8s-node1 NotReady <none> 66s v1.30.0
k8s-node2 NotReady <none> 50s v1.30.0安装网络插件Calico
直接执行
bash
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml如果无法下载,那么去github全局搜索calico,点击进入项目,在Releases下下载自己需要的calico版本的离线包(文章以3.27.3版本为例)。不同版本的kubernets需要不同版本的calico,具体对应版本需自行查询。我们解压calico的离线包后会得到很多文件,并不是全部需要。首先将calico.yaml文件上传至服务器,然后使用cat calico.yaml |grep image:命令查看calico所需的镜像包
bash
cat calico.yaml |grep image:这里显示安装calico需要三个镜像,去解压的离线包imgaes文件夹中找到对应的三个离线镜像包文件,这里对应的分别是calico-cni.tar,calico-kube-controllers.tar和calico-node.tar三个离线包,将这三个离线镜像上传至服务器。至此kubernets 1.30版本的calico部署完成,我们查看节点,发现都是Ready
bash
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready control-plane 19m v1.30.0
k8s-master2 Ready control-plane 18m v1.30.0
k8s-master3 Ready control-plane 16m v1.30.0
k8s-node1 Ready <none> 7m3s v1.30.0
k8s-node2 Ready <none> 6m47s v1.30.0下面我们来运行一个容器,验证是否可以正常运行
bash
kubectl run nginx-pod --image=nginx查看pod
bash
[root@k8s-master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 10m二进制高可用集群
证书
这里使用官方推荐的 CFSSL 工具来生成证书。CFSSL是CloudFlare开源的一款PKI/TLS工具,使用Go语言编写。所有的证书颁发出来都需要两个步骤:
1、有一个证书颁发机构
2、提交证书申请,根据申请CA机构颁发证书给我们、cfssl也一样
在kubernetes 集群中需要的证书种类如下:
etcd 节点需要标识自己服务的server cert,也需要client cert与etcd集群其他节点交互,当然可以分别指定2个证书,也可以使用一个对等证书
master 节点需要标识 apiserver服务的server cert,也需要client cert连接etcd集群,这里也使用一个对等证书
kubectl calico kube-proxy 只需要client cert,因此证书请求中 hosts 字段可以为空
kubelet证书比较特殊,不是手动生成,它由node节点TLS BootStrap向apiserver请求,由master节点的controller-manager 自动签发,包含一个client cert 和一个server cert
client certificate:用于服务端认证客户端,例如etcdctl、etcd proxy、fleetctl、docker客户端
server certificate:服务端使用,客户端以此验证服务端身份,例如docker服务端、kube-apiserver
peer certificate:双向证书,用于etcd集群成员间通信
根据认证对象可以将证书分成三类:
服务器证书server cert,
客户端证书client cert,
对等证书peer cert,表示既是server cert又是client cert
安装 cfssl
下载 cfssl 工具用于生成证书,其他版本见 release 页面。只需要在其中一台master节点安装即可
bash
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.4/cfssl_1.6.4_linux_amd64 -O cfssl
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.4/cfssljson_1.6.4_linux_amd64-O cfssljson
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.4/cfssl-certinfo_1.6.4_linux_amd64 -O cfssl-certinfocfssljson:将从cfssl和multirootca等获得的json格式的输出转化为证书格式的文件(证书,密钥,CSR和bundle)进行存储
cfssl-certinfo:可显示CSR或证书文件的详细信息;可用于证书校验
赋予权限
bash
chmod +x cfssl cfssljson cfssl-certinfo
mv cfssl* /usr/local/bin验证
bash
cfssl version
cfssljson -version制作CA证书
创建工作目录
bash
mkdir -p /etc/kubernetes/pki创建证书颁发机构(CA)
创建ca配置文件,相当于证书颁发机构的工作规章制度
创建配置文件:使用命令生成、手动生成
bash
#使用命令生成默认配置文件
#cfssl print-defaults config > /etc/kubernetes/pki/ca-config.json
#手动生成
cat > /etc/kubernetes/pki/ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "876000h"
},
"profiles": {
"kubernetes": {
"expiry": "876000h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOFdefault.expiry:默认证书有效期(单位:h),我们这里证书有效期是十年
profiles.etcd:为服务使用该配置文件颁发证书的配置模块
signing:签署,表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE
key encipherment:密钥加密
profiles:指定了不同角色的配置信息;可以定义多个 profiles,分别指定不同的过期时间、使用场景等参数;后续在签名证书时使用某个 profile
server auth:服务器身份验证;表示 client 可以用该 CA 对 server 提供的证书进行验证
client auth:客户端身份验证;表示 server 可以用该 CA 对 client 提供的证书进行验证
我们自己准备一个证书申请请求书。证书机构就会根据我们请求签发证书
bash
#使用命令生成默认配置文件
#cfssl print-defaults csr > /etc/kubernetes/pki/ca-csr.json
#手动创建配置文件
cat > /etc/kubernetes/pki/ca-csr.json << EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "Kubernetes",
"OU": "Kubernetes-manual"
}
]
}
EOFhosts:包含的授权范围,不在此范围的的节点或者服务使用此证书就会报证书不匹配错误,证书如果不包含可能会出现无法连接的情况;
Key: 指定使用的加密算法,一般使用rsa非对称加密算法(algo:rsa;size:2048)
CN:Common Name,从证书中提取该字段作为请求的用户名 (User Name);浏览器使用该字段验证网站是否合法;CN是域名,也就是你现在使用什么域名就写什么域名。
C:国家(CN中国)
ST:类似省份(如湖南省等)
L:城市(如北京市)
O:Organization,从证书中提取该字段作为请求用户所属的组 (Group)
创建证书
bash
cfssl gencert -initca /etc/kubernetes/pki/ca-csr.json | cfssljson -bare /etc/kubernetes/pki/ca检查
bash
[root@k8s-master1 ~]# ls /etc/kubernetes/pki/
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem创建kube-apiserver证书
配置kube-apiserver请求csr文件
bash
cat > /etc/kubernetes/pki/kube-apiserver-csr.json << EOF
{
"CN": "kube-apiserver",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"192.168.209.101",
"192.168.209.102",
"192.168.209.103",
"192.168.209.201",
"192.168.209.202",
"192.168.209.100",
"10.96.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "Kubernetes",
"OU": "Kubernetes-manual"
}
]
}
EOFhosts字段指定该证书的授权范围,包括apiserver节点IP、负载均衡器节点IP地址、VIP地址、Kubernetes服务IP和域名。其中Kubernetes服务IP是apiserver自动创建的,一般是--service-cluster-ip-range参数指定的网段的第一个IP地址。本例中为10.0.0.1,--service-cluster-ip-range参数在kube-apiserver.conf和kube-controller-manager.conf中配置。192.168.209.100是我准备的负载均衡器地址,负载均衡可以自己搭建,也可以购买云厂商LB
生成apiserver证书
bash
cfssl gencert -ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=/etc/kubernetes/pki/ca-config.json \
-profile=kubernetes \
/etc/kubernetes/pki/kube-apiserver-csr.json | cfssljson -bare /etc/kubernetes/pki/kube-apiserver-ca=ca.pem:指定证书的颁发机构(CA)文件路径;
-ca-key=ca-key.pem:指定证书的颁发机构(CA)私钥文件路径;
-config=ca-config.json:指定CA配置文件的路径,该文件定义了证书的有效期、加密算法等设置;
-profile=kubernetes:指定使用的证书配置文件,该文件定义了证书的用途和扩展属性;
apiserver-csr.json:指定API Server的证书签名请求配置文件路径;
cfssljson -bare apiserver:通过管道符将cfssl命令的输出传递给cfssljson命令,并使用-bare参数直接输出裸证书,即只生成证书文件,不包含其他格式的文件,最后指定证书文件名前缀为apiserver,实际生成的文件名为apiserver.csr、apiserver.pem、apiserver-key.pem;
所以,这个命令将会生成API Server的证书和私钥,并保存到指定的文件中,查看生成的证书
bash
[root@k8s-master1 ~]# ls /etc/kubernetes/pki/kube-apiserver*
/etc/kubernetes/pki/kube-apiserver.csr /etc/kubernetes/pki/kube-apiserver-key.pem
/etc/kubernetes/pki/kube-apiserver-csr.json /etc/kubernetes/pki/kube-apiserver.pem生成 API Server 聚合证书
bash
cat > /etc/kubernetes/pki/front-proxy-ca-csr.json << EOF
{
"CN": "front-proxy-ca",
"key": {
"algo": "rsa",
"size": 2048
},
"ca": {
"expiry": "876000h"
}
}
EOF生成apiserver聚合CA证书和私钥
bash
cfssl gencert -initca /etc/kubernetes/pki/front-proxy-ca-csr.json | cfssljson -bare /etc/kubernetes/pki/front-proxy-ca创建front-proxy-client-csr.json文件
bash
cat > /etc/kubernetes/pki/front-proxy-client-csr.json << EOF
{
"CN": "front-proxy-client",
"hosts": [""],
"key": {
"algo": "rsa",
"size": 2048
}
}
EOF生成用于Kubernetes的front-proxy-client证书
bash
cfssl gencert -ca=/etc/kubernetes/pki/front-proxy-ca.pem -ca-key=/etc/kubernetes/pki/front-proxy-ca-key.pem -config=/etc/kubernetes/pki/ca-config.json -profile=kubernetes /etc/kubernetes/pki/front-proxy-client-csr.json | cfssljson -bare /etc/kubernetes/pki/front-proxy-client创建kube-controller-manager证书
配置kube-controller-manager请求csr文件
bash
cat > /etc/kubernetes/pki/kube-controller-manager-csr.json << EOF
{
"CN": "system:kube-controller-manager",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "system:kube-controller-manager",
"OU": "Kubernetes-manual"
}
]
}
EOF生成controller-manager证书
bash
cfssl gencert -ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=/etc/kubernetes/pki/ca-config.json \
-profile=kubernetes \
/etc/kubernetes/pki/kube-controller-manager-csr.json | cfssljson -bare /etc/kubernetes/pki/kube-controller-manager创建kube-scheduler的证书
配置kube-scheduler请求csr文件
bash
cat > /etc/kubernetes/pki/kube-scheduler-csr.json << EOF
{
"CN": "system:kube-scheduler",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "system:kube-scheduler",
"OU": "Kubernetes-manual"
}
]
}
EOF生成kube-scheduler证书
bash
cfssl gencert -ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=/etc/kubernetes/pki/ca-config.json \
-profile=kubernetes \
/etc/kubernetes/pki/kube-scheduler-csr.json | cfssljson -bare /etc/kubernetes/pki/kube-scheduler创建kube-proxy证书
bash
cat > /etc/kubernetes/pki/kube-proxy-csr.json << EOF
{
"CN":"system:kube-proxy",
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"Beijing",
"ST":"Beijing",
"O":"system:kube-proxy",
"OU":"Kubernetes-manual"
}
]
}
EOF生成kube-proxy证书
bash
cfssl gencert -ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=/etc/kubernetes/pki/ca-config.json \
-profile=kubernetes \
/etc/kubernetes/pki/kube-proxy-csr.json | cfssljson -bare /etc/kubernetes/pki/kube-proxy创建集群管理员证书
bash
cat > /etc/kubernetes/pki/admin-csr.json << EOF
{
"CN":"admin",
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"Beijing",
"ST":"Beijing",
"O":"system:masters",
"OU":"Kubernetes-manual"
}
]
}
EOF为kubectl生成自签证书
bash
cfssl gencert -ca=/etc/kubernetes/pki/ca.pem \
-ca-key=/etc/kubernetes/pki/ca-key.pem \
-config=/etc/kubernetes/pki/ca-config.json \
-profile=kubernetes \
/etc/kubernetes/pki/admin-csr.json | cfssljson -bare /etc/kubernetes/pki/admin创建 ServiceAccount Key
bash
openssl genrsa -out /etc/kubernetes/pki/sa.key 2048
openssl rsa -in /etc/kubernetes/pki/sa.key -pubout -out /etc/kubernetes/pki/sa.pubkubernetes离线安装包
下载kubernetes离线安装包,我这里下载的是1.30.0版本
bash
wget https://dl.k8s.io/v1.30.0/kubernetes-server-linux-amd64.tar.gz在 k8s-master1 节点解压kubelet,kubectl等到 /usr/local/bin
bash
tar -xf kubernetes-server-linux-amd64.tar.gz --strip-components=3 -C /usr/local/bin kubernetes/server/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy}master需要全部组件
bash
for i in k8s-master2 k8s-master3;do scp /usr/local/bin/kube{let,ctl,-apiserver,-controller-manager,-scheduler,-proxy} $i:/usr/local/bin; donenode节点只需要 kubelet、kube-proxy
bash
for i in k8s-node1 k8s-node2;do scp /usr/local/bin/{kubelet,kube-proxy} $i:/usr/local/bin; done配置文件
配置apiserver服务
所有Master节点创建kube-apiserver.service,根据下方参数说明表和实际情况修改参数值。我们这里使用的k8s service网段为10.96.0.0/16,该网段不能和宿主机的网段、Pod网段的重复。特别注意:docker的网桥默认为 172.17.0.1/16,不要使用这个网段
bash
cat > /etc/kubernetes/conf/kube-apiserver.conf << "EOF"
KUBE_APISERVER_OPTS="--v=2 \
--allow-privileged=true \
--bind-address=192.168.209.101 \
--secure-port=6443 \
--advertise-address=192.168.209.101 \
--service-cluster-ip-range=10.0.0.0/24 \
--service-node-port-range=30000-32767 \
--etcd-servers=https://192.168.209.101:2379,https://192.168.209.102:2379,https://192.168.209.103:2379 \
--etcd-cafile=/etc/etcd/cert/etcd-ca.pem \
--etcd-certfile=/etc/etcd/cert/etcd.pem \
--etcd-keyfile=/etc/etcd/cert/etcd-key.pem \
--client-ca-file=/etc/kubernetes/pki/ca.pem \
--tls-cert-file=/etc/kubernetes/pki/kube-apiserver.pem \
--tls-private-key-file=/etc/kubernetes/pki/kube-apiserver-key.pem \
--kubelet-client-certificate=/etc/kubernetes/pki/kube-apiserver.pem \
--kubelet-client-key=/etc/kubernetes/pki/kube-apiserver-key.pem \
--service-account-key-file=/etc/kubernetes/pki/sa.pub \
--service-account-signing-key-file=/etc/kubernetes/pki/sa.key \
--service-account-issuer=https://kubernetes.default.svc.cluster.local \
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \
--authorization-mode=RBAC,Node \
--enable-bootstrap-token-auth=true \
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \
--requestheader-allowed-names=aggregator \
--requestheader-group-headers=X-Remote-Group \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-username-headers=X-Remote-User \
--enable-aggregator-routing=true \
--token-auth-file=/etc/kubernetes/pki/token.csv \
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=100 \
--audit-log-path=/var/log/k8s-audit.log \
--default-not-ready-toleration-seconds=20 \
--default-unreachable-toleration-seconds=20"
EOF参数解释如下:
bash
# 指定日志级别为 2(日志级别分 0-8),数字越大,日志越详细
KUBE_APISERVER_OPTS="--v=2 \
# 允许特权容器运行
--allow-privileged=true \
# 设置监听地址
--bind-address=192.168.209.101 \
# 设置监听端口,默认为 6443
--secure-port=6443 \
# 通告地址,让其他节点通过此 IP 来连接 API Server
--advertise-address=192.168.209.101 \
# 指定 Kubernetes 集群中 Service 的 CIDR 范围,例如 10.0.0.0/24,该 CIDR 范围不能与部署机器的 IP 地址有重合
--service-cluster-ip-range=10.0.0.0/24 \
# 指定 Kubernetes 集群中 NodePort 的范围,默认值为 30000~32767
--service-node-port-range=30000-32767 \
# 指定 etcd 服务器的地址
--etcd-servers=https://192.168.209.101:2379,https://192.168.209.102:2379,https://192.168.209.103:2379 \
# 指定 etcd 服务器的 CA 证书
--etcd-cafile=/etc/etcd/cert/etcd-ca.pem \
# 指定 etcd 服务器的证书
--etcd-certfile=/etc/etcd/cert/etcd.pem \
# 指定 etcd 服务器的私钥
--etcd-keyfile=/etc/etcd/cert/etcd-key.pem \
# 指定客户端 CA 的证书
--client-ca-file=/etc/kubernetes/pki/ca.pem \
# 指定 API Server 服务的证书
--tls-cert-file=/etc/kubernetes/pki/kube-apiserver.pem \
# 指定 API Server 服务的私钥
--tls-private-key-file=/etc/kubernetes/pki/kube-apiserver-key.pem \
# 指定与 kubelet 通信的客户端证书和私钥
--kubelet-client-certificate=/etc/kubernetes/pki/kube-apiserver.pem \
--kubelet-client-key=/etc/kubernetes/pki/kube-apiserver-key.pem \
# 指定服务账户公钥文件
--service-account-key-file=/etc/kubernetes/pki/sa.pub \
# 指定服务账户签名密钥文件
--service-account-signing-key-file=/etc/kubernetes/pki/sa.key \
# 指定服务账户的发布者
--service-account-issuer=https://kubernetes.default.svc.cluster.local \
# 指定启用的准入插件
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota \
# 指定授权模式
--authorization-mode=RBAC,Node \
# 启用 bootstrap token 引导令牌认证
--enable-bootstrap-token-auth=true \
# 指定请求头中的客户端 CA 证书
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
# 指定代理客户端的证书和私钥
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \
# 指定请求头中允许的名字
--requestheader-allowed-names=aggregator \
# 指定请求头中的组头
--requestheader-group-headers=X-Remote-Group \
# 指定请求头中的额外头前缀
--requestheader-extra-headers-prefix=X-Remote-Extra- \
# 指定请求头中的用户名头
--requestheader-username-headers=X-Remote-User \
# 启用聚合路由
--enable-aggregator-routing=true \
# 指定用于身份验证的令牌文件
--token-auth-file=/etc/kubernetes/pki/token.csv \
# 设置日志轮转、日志路径相关的配置参数
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=100 \
--audit-log-path=/var/log/k8s-audit.log \
--default-not-ready-toleration-seconds=20 \
--default-unreachable-toleration-seconds=20"创建kube-apiserver的Service文件
bash
cat > /usr/lib/systemd/system/kube-apiserver.service << "EOF"
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/etc/kubernetes/conf/kube-apiserver.conf
ExecStart=/usr/local/bin/kube-apiserver $KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOFkube-controller-manage
创建kube-controller-manage配置文件,并根据下方参数说明表和实际情况修改参数值
bash
cat > /etc/kubernetes/conf/kube-controller-manager.conf << "EOF"
KUBE_CONTROLLER_MANAGER_OPTS="--v=2 \
--bind-address=127.0.0.1 \
--root-ca-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--service-account-private-key-file=/etc/kubernetes/pki/sa.key \
--kubeconfig=/etc/kubernetes/conf/kube-controller-manager.kubeconfig \
--leader-elect=true \
--use-service-account-credentials=true \
--node-monitor-grace-period=20s \
--node-monitor-period=2s \
--controllers=*,bootstrapsigner,tokencleaner \
--allocate-node-cidrs=true \
--service-cluster-ip-range=10.0.0.0/24 \
--cluster-cidr=10.244.0.0/16 \
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
--cluster-signing-duration=876000h0m0s \
--node-startup-grace-period=20s \
--node-eviction-rate=1"
EOF参数解释如下:
bash
# 指定日志级别为 2(日志级别分 0-8),数字越大,日志越详细
KUBE_CONTROLLER_MANAGER_OPTS="--v=2 \
# 设置监听地址
--bind-address=127.0.0.1 \
# 设置根证书的路径,用于验证其他组件的证书
--root-ca-file=/etc/kubernetes/pki/ca.pem \
# 设置用于签名集群证书的证书文件路径
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
# 设置用于签名集群证书的私钥文件路径
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
# 设置用于签名服务账户令牌的私钥文件路径
--service-account-private-key-file=/etc/kubernetes/pki/sa.key \
# 指定 kubeconfig 文件的路径,此文件包含了与 Kubernetes API 服务器通信所需的配置信息
--kubeconfig=/etc/kubernetes/conf/kube-controller-manager.kubeconfig \
# 设置启用 Leader 选举机制,确保只有一个控制器管理器作为 Leader 在运行
--leader-elect=true \
# 设置使用服务账户的凭据进行认证和授权
--use-service-account-credentials=true \
# 设置将一个运行的 Node 节点标记为不健康之前允许其无响应的时间
--node-monitor-grace-period=20s \
# 设置节点控制器对节点状态进行同步的周期
--node-monitor-period=2s \
# --controllers:设置要启用的控制器列表。* 表示启用所有默认启用的控制器;foo 表示启用名为 foo 的控制器;-foo 表示禁用名为 foo 的控制器。控制器的全集:attachdetach、bootstrapsigner、cloud-node-lifecycle、clusterrole-aggregation、cronjob、csrapproving、csrcleaner、csrsigning、daemonset、deployment、disruption、endpoint、endpointslice、endpointslicemirroring、ephemeral-volume、garbagecollector、horizontalpodautoscaling、job、namespace、nodeipam、nodelifecycle、persistentvolume-binder、persistentvolume-expander、podgc、pv-protection、pvc-protection、replicaset、replicationcontroller、resourcequota、root-ca-cert-publisher、route、service、serviceaccount、serviceaccount-token、statefulset、tokencleaner、ttl、ttl-after-finished;
默认禁用的控制器:bootstrapsigner 和 tokencleaner
--controllers=*,bootstrapsigner,tokencleaner \
# 设置允许基于 CNI 来为 Pod 分配和设置子网掩码
--allocate-node-cidrs=true \
# 指定 Kubernetes 集群中 Service 的 CIDR 范围,与 kube-apiserver.conf 中的 --service-cluster-ip-range 参数配置保持一致
--service-cluster-ip-range=10.0.0.0/24 \
# 定义集群的 CIDR 范围,要与 CNI 插件的 CIDR 范围保持一致
--cluster-cidr=10.244.0.0/16 \
# 设置请求头中客户端 CA 的证书文件路径,用于认证请求头中的 CA 证书
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
# 设置签发证书的有效期
--cluster-signing-duration=876000h0m0s \
# 设置将一个启动节点标记为不健康之前允许其无响应的时间
--node-startup-grace-period=20s \
# 设置删除不健康节点上的 pod 的宽限时间
--node-eviction-rate=1"生成kube-controller-manager访问apiserver的kubeconfig配置文件,只需在master1上执行。kubectl config set-cluster命令的作用是在kubeconfig文件中设置集群信息,包括证书颁发机构、证书、kube-apiserver地址等。
bash
KUBE_APISERVER="https://192.168.209.100:16443"
KUBE_CONFIG="/etc/kubernetes/conf/kube-controller-manager.kubeconfig"
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}--certificate-authority选项指定了集群的证书颁发机构(CA)的路径,这个CA会验证kube-apiserver提供的证书是否合法。
--embed-certs选项用于将证书嵌入到生成的kubeconfig文件中,这样就不需要在kubeconfig文件中单独指定证书文件路径。
--server选项指定kube-apiserver的地址,我这里的vip是192.168.209.100,nginx监听端口16433
--kubeconfig选项指定生成的kubeconfig文件的路径和名称。
设置一个用户项,以便后续使用该文件进行身份验证和访问 Kubernetes API
bash
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=/etc/kubernetes/pki/kube-controller-manager.pem \
--client-key=/etc/kubernetes/pki/kube-controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}system:kube-controller-manager: 是设置用户凭据的名称,system:是Kubernetes API Server内置的身份验证器使用的用户标识符前缀,它表示是一个系统用户,在本例中是kube-controller-manager组件使用的身份。
--client-certificate: 指定kube-controller-manager.pem客户端证书的路径。
--client-key: 指定kube-controller-manager-key.pem客户端私钥的路径。
--embed-certs: 表示将证书和私钥直接嵌入到生成的kubeconfig文件中,而不是通过引用外部文件。
--kubeconfig:指定生成的kubeconfig文件的路径和名称。
配置Kubernetes控制器管理器的上下文信息
bash
kubectl config set-context system:kube-controller-manager@kubernetes \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=${KUBE_CONFIG}kubectl config set-context system:kube-controller-manager@kubernetes: 设置上下文的名称为system:kube-controller-manager@kubernetes,这是一个标识符,用于唯一标识该上下文。
--cluster=kubernetes: 指定集群的名称为kubernetes,这是一个现有集群的标识符,表示要管理的Kubernetes集群。
--user=system:kube-controller-manager: 指定使用的用户身份为system:kube-controller-manager。这是一个特殊的用户身份,具有控制 Kubernetes控制器管理器的权限。
--kubeconfig选项指定生成的kubeconfig文件的路径和名称。kubeconfig文件是一个用于管理Kubernetes配置的文件,包含了集群、用户和上下文的相关信息。
设置默认环境,设置kubectl使用指定的上下文环境来执行操作,上下文环境是kubectl用来确定要连接到哪个Kubernetes集群以及使用哪个身份验证信息的配置,通过执行这个命令,kubectl将使用指定的上下文来执行后续的操作,包括部署和管理Kubernetes资源。
bash
kubectl config use-context system:kube-controller-manager@kubernetes \
--kubeconfig=${KUBE_CONFIG}kubectl config use-context是用来设置当前上下文环境的命令
system:kube-controller-manager@kubernetes是指定的上下文名称,它告诉kubectl要使用的Kubernetes集群和身份验证信息。
--kubeconfig选项指定生成的kubeconfig文件的路径和名称,kubeconfig文件是存储集群连接和身份验证信息的配置文件
创建kube-controller-manager的Service文件
bash
cat > /usr/lib/systemd/system/kube-controller-manager.service << "EOF"
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/etc/kubernetes/conf/kube-controller-manager.conf
ExecStart=/usr/local/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOFkube-scheduler配置文件
创建kube-scheduler配置文件,并根据下方参数说明表和实际情况修改参数值
bash
cat > /etc/kubernetes/conf/kube-scheduler.conf << "EOF"
KUBE_SCHEDULER_OPTS="--v=2 \
--bind-address=127.0.0.1 \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/conf/kube-scheduler.kubeconfig"
EOF参数解释如下:
bash
# 指定日志级别为 2(日志级别分 0-8),数字越大,日志越详细
KUBE_SCHEDULER_OPTS="--v=2 \
# 设置监听地址
--bind-address=127.0.0.1 \
# 启用自动选举
--leader-elect=true \
# 指定 kubeconfig 文件的路径,此文件包含了与 Kubernetes API 服务器通信所需的配置信息
--kubeconfig=/etc/kubernetes/conf/kube-scheduler.kubeconfig"生成kube-scheduler访问apiserver的kubeconfig配置文件
bash
# KUBE_APISERVER地址修改为实际环境apiserver的IP:Port或VIP:Port
KUBE_APISERVER="https://192.168.209.100:16443"
KUBE_CONFIG="/etc/kubernetes/conf/kube-scheduler.kubeconfig"
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials system:kube-scheduler \
--client-certificate=/etc/kubernetes/pki/kube-scheduler.pem \
--client-key=/etc/kubernetes/pki/kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context system:kube-scheduler@kubernetes \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context system:kube-scheduler@kubernetes --kubeconfig=${KUBE_CONFIG}创建kube-scheduler的Service文件
bash
cat > /usr/lib/systemd/system/kube-scheduler.service << "EOF"
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/etc/kubernetes/conf/kube-scheduler.conf
ExecStart=/usr/local/bin/kube-scheduler $KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF创建token
随机生成一个 32 位字符串,用以创建 token.csv 文件。token.csv文件的格式为:第一列为随机字符串,第二列为用户名,第三列为UID,第四列用户组。此处 apiserver 配置的 token(32 位随机字符串)必须要与后面 node 节点 bootstrap.kubeconfig 配置文件里的 token 一致
bash
token=`head -c 16 /dev/urandom | od -An -t x | tr -d ' '`
echo "$token,kubelet-bootstrap,10001,'system:node-bootstrappers'" > /etc/kubernetes/pki/token.csv分发配置
在master2和master3节点创建目录
bash
mkdir /etc/kubernetes分发配置文件和证书
bash
scp -r /etc/kubernetes/{pki,conf} k8s-master2:/etc/kubernetes/
scp -r /etc/kubernetes/{pki,conf} k8s-master3:/etc/kubernetes/
scp -r /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service k8s-master2:/usr/lib/systemd/system/
scp -r /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service k8s-master3:/usr/lib/systemd/system/修改其余 Master 节点上 kube-apiserver.conf 配置文件中的 --bind-address 和 --advertise-address 参数为本机 IP,以master2节点为例
bash
[root@k8s-master2 ~]# cat /etc/kubernetes/conf/kube-apiserver.conf
...
--bind-address=192.168.209.102 \
--advertise-address=192.168.209.102 \
...启动master组件
在所有 Master 节点上执行以下命令设置 api-server、controller-manager、scheduler 开机自启并启动
bash
systemctl daemon-reload
systemctl start kube-apiserver && systemctl enable kube-apiserver
systemctl start kube-controller-manager && systemctl enable kube-controller-manager
systemctl start kube-scheduler && systemctl enable kube-scheduler
systemctl status kube-apiserver
systemctl status kube-controller-manager
systemctl status kube-scheduler在 master1 节点上执行以下命令生成 kubectl 访问集群的 kubeconfig 文件
bash
mkdir -p /root/.kube
# KUBE_APISERVER地址修改为实际环境apiserver的IP:Port或VIP:Port
KUBE_CONFIG="/root/.kube/config"
KUBE_APISERVER="https://192.168.209.100:16443"
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kubernetes-admin \
--client-certificate=/etc/kubernetes/pki/admin.pem \
--client-key=/etc/kubernetes/pki/admin-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context kubernetes-admin@kubernetes \
--cluster=kubernetes \
--user=kubernetes-admin \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context kubernetes-admin@kubernetes --kubeconfig=${KUBE_CONFIG}将 /root/.kube 目录拷贝到其余 master 节点上,使得所有 master 节点均可通过 kubectl 访问集群
bash
scp -r /root/.kube/ k8s-master2:/root/
scp -r /root/.kube/ k8s-master3:/root/此时你可以通过执行 kubectl get cs 获取 Kubernetes 的各服务端组件状态看是否为 Healthy
bash
[root@k8s-master1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy ok 在任意一台 master 上执行以下命令授权 kubelet-bootstrap 用户允许请求证书
bash
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap部署kubelet
在k8s node节点执行,创建kubelet.conf文件,并根据下方参数说明表和实际情况修改参数值
bash
mkdir -p /etc/kubernetes/conf
cat > /etc/kubernetes/conf/kubelet.conf << "EOF"
KUBELET_OPTS="--v=2 \
--hostname-override=k8s-node1 \
--bootstrap-kubeconfig=/etc/kubernetes/conf/bootstrap.kubeconfig \
--kubeconfig=/etc/kubernetes/conf/kubelet.kubeconfig \
--config=/etc/kubernetes/conf/kubelet-config.yml \
--cert-dir=/etc/kubernetes/pki \
--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 \
--container-runtime-endpoint=unix:///var/run/cri-dockerd.sock"
EOF参数释义
bash
# 指定日志级别为 2(日志级别分 0-8),数字越大,日志越详细
KUBELET_OPTS="--v=2 \
# 指定当前节点注册到 Kubernetes 显示的名称(集群内唯一),建议设置为本机主机名
--hostname-override=easyk8s1 \
# 指定用于启动引导 kubelet 的 kubeconfig 配置的 bootstrap-kubeconfig 文件路径和名称
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \
# 指定 kubelet 的 kubeconfig 文件的路径和名称
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \
# 指定 kubelet 的配置文件路径和名称
--config=/opt/kubernetes/cfg/kubelet-config.yml \
# 指定证书存放目录
--cert-dir=/opt/kubernetes/ssl \
# 指定管理 Pod 网络容器的 pause 镜像(registry.aliyuncs.com/google_containers/pause:3.9)[可选参数],此参数在新版本中已弃用,将在未来版本中删除,pause 镜像信息将从 CRI(例如 cri-dockerd)中获取
--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 \
# 指定使用的 CRI socket 路径,例如 unix:///var/run/cri-dockerd.sock [可选参数]\
--container-runtime-endpoint=unix:///var/run/cri-dockerd.sock"在启动 kubelet 时,如果 --kubeconfig 标志所指定的文件并不存在,会使用通过标志 --bootstrap-kubeconfig 所指定的启动引导 kubeconfig 配置来向 API 服务器请求客户端证书。在证书请求被批复并被 kubelet 收回时,一个引用所生成的密钥和所获得证书的 kubeconfig 文件会被写入到通过 --kubeconfig 所指定的文件路径下。证书和密钥文件会被放到 --cert-dir 所指定的目录中。
创建kubelet-config.yml配置文件,并根据下方参数说明表和实际情况修改参数值
bash
# 创建kubelet-config.yml配置文件,并根据下方参数说明表和实际情况修改参数值
cat > /etc/kubernetes/conf/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
cgroupDriver: systemd
clusterDNS:
- 10.0.0.2
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOFclusterDNS:指定集群 DNS 服务器地址,一般是 --service-cluster-ip-range 参数指定的网段的第二个 IP 地址
clusterDomain:指定集群的域名后缀,默认为 cluster.local
创建kubelet的Service文件
bash
cat > /usr/lib/systemd/system/kubelet.service << "EOF"
[Unit]
Description=Kubernetes Kubelet
After=docker.service
Wants=docker.service
[Service]
EnvironmentFile=/etc/kubernetes/conf/kubelet.conf
ExecStart=/usr/local/bin/kubelet $KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF执行以下操作生成 bootstrap.kubeconfig 配置文件和 kube-proxy.kubeconfig 配置文件,并拷贝到所有 Node 节点。在安装了cfssl工具的主机上生成kubelet bootstrap kubeconfig配置文件。建议用master1节点
bash
# KUBE_APISERVER地址修改为实际环境apiserver的IP:Port或VIP:Port
# TOKEN修改为master节点/etc/kubernetes/pki/token.csv中的token值
KUBE_CONFIG="/etc/kubernetes/conf/bootstrap.kubeconfig"
KUBE_APISERVER="https://192.168.209.100:16443"
TOKEN="bd7f74be3a0ceaf28e4d920bf4d2f603"
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kubelet-bootstrap \
--token=${TOKEN} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context kubelet-bootstrap@kubernetes \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context kubelet-bootstrap@kubernetes --kubeconfig=${KUBE_CONFIG}将bootstrap.kubeconfig文件拷贝到所有node节点上
bash
scp /etc/kubernetes/conf/bootstrap.kubeconfig k8s-node1:/etc/kubernetes/conf/
bash
scp /etc/kubernetes/conf/{kubelet.conf,kubelet-config.yml,bootstrap.kubeconfig} k8s-node2:/etc/kubernetes/conf/
scp /usr/lib/systemd/system/kubelet.service k8s-node2:/usr/lib/systemd/system/修改/etc/kubernetes/conf/kubelet.conf文件--hostname-override
部署kube-proxy
创建kube-proxy.conf文件,并根据下方参数说明表和实际情况修改参数值
bash
cat > /etc/kubernetes/conf/kube-proxy.conf << "EOF"
KUBE_PROXY_OPTS="--v=2 \
--config=/etc/kubernetes/conf/kube-proxy-config.yml"
EOF创建kube-proxy-config.yml配置文件,并根据下方参数说明表和实际情况修改参数值
bash
cat > /etc/kubernetes/conf/kube-proxy-config.yml << EOF
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
metricsBindAddress: 0.0.0.0:10249
clientConnection:
kubeconfig: /etc/kubernetes/conf/kube-proxy.kubeconfig
hostnameOverride: k8s-node1
clusterCIDR: 10.0.0.0/24
mode: ipvs
ipvs:
scheduler: "rr"
iptables:
masqueradeAll: true
EOF创建kube-proxy的Service文件
bash
cat > /usr/lib/systemd/system/kube-proxy.service << "EOF"
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/etc/kubernetes/conf/kube-proxy.conf
ExecStart=/usr/local/bin/kube-proxy $KUBE_PROXY_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF在安装了cfssl工具的主机上生成kube-proxy.kubeconfig配置文件。建议用master1节点
bash
# KUBE_APISERVER地址修改为实际环境apiserver的IP:Port或VIP:Port
KUBE_CONFIG="/etc/kubernetes/conf/kube-proxy.kubeconfig"
KUBE_APISERVER="https://192.168.209.100:16443"
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-proxy \
--client-certificate=/etc/kubernetes/pki/kube-proxy.pem \
--client-key=/etc/kubernetes/pki/kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context kube-proxy@kubernetes \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context kube-proxy@kubernetes --kubeconfig=${KUBE_CONFIG}将kube-proxy.kubeconfig文件拷贝到所有node节点上
bash
scp -r /etc/kubernetes/conf/kube-proxy.kubeconfig k8s-node1:/etc/kubernetes/conf/拷贝 ca 证书和 kube-proxy 的自签证书和私钥到所有 Node 节点的 目录下
bash
scp -r /etc/kubernetes/pki/{ca.pem,kube-proxy.pem,kube-proxy-key.pem} k8s-node1:/etc/kubernetes/pki/
bash
scp /etc/kubernetes/conf/{kube-proxy.kubeconfig,kube-proxy.conf} k8s-node2:/etc/kubernetes/conf/
scp /etc/kubernetes/pki/{ca.pem,kube-proxy.pem,kube-proxy-key.pem} k8s-node2:/etc/kubernetes/pki/
scp /usr/lib/systemd/system/kube-proxy.service k8s-node2:/usr/lib/systemd/system/启动kubelet和kube-proxy
设置 kubelet 和 kube-proxy 开机自启并启动
bash
systemctl daemon-reload
systemctl start kubelet && systemctl enable kubelet
systemctl start kube-proxy && systemctl enable kube-proxy
systemctl status kubelet
systemctl status kube-proxy如果启动失败,
bash
journalctl -u kubelet -n 50 --no-pager当 kubelet 和 kube-proxy 成功启动后,此时在任意一台 master 节点上执行 kubectl get csr 可以看到有新的节点请求颁发证书 (CONDITION 字段处于 Pending 状态)
bash
[root@k8s-master1 ~]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
node-csr-7yFqd8ONnkvIfoHRCmkT-bWcP5gR54EjJUMkTaxLLJY 49s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap <none> Pending执行以下命令允许给 Node 颁发证书,node-csr-xxxxxx替换成执行kubectl get csr查询到的节点NAME值,多个用空格隔开
bash
kubectl certificate approve node-csr-7yFqd8ONnkvIfoHRCmkT-bWcP5gR54EjJUMkTaxLLJY授权颁发证书后,在任意一台 master 节点执行 kubectl get node 能看到 Node 节点都还处于 NotReady 状态,这是因为现在还没安装网络插件
若 kubectl 或 kube-proxy 配置文件中的 hostname-override 配置参数漏修改,导致授权后 master 无法正常获取到 Node 节点信息,除了修改 kubelet.conf 的 --hostname-override 配置和 kube-proxy-config.yml 的 hostnameOverride 配置外,还需要将 kubelet.kubeconfig 文件(这个文件是 master 认证后客户端自动生成的)删除,才可重新申请授权,否则报错信息类似如下:
bash
kubelet_node_status.go:94] Unable to register node "k8s-node2" with API server: nodes "k8s-node2" is forbidden: node "k8s-node1" is not allowed to modify node "k8s-node2"TLS Bootstrapping 机制流程(Kubelet)
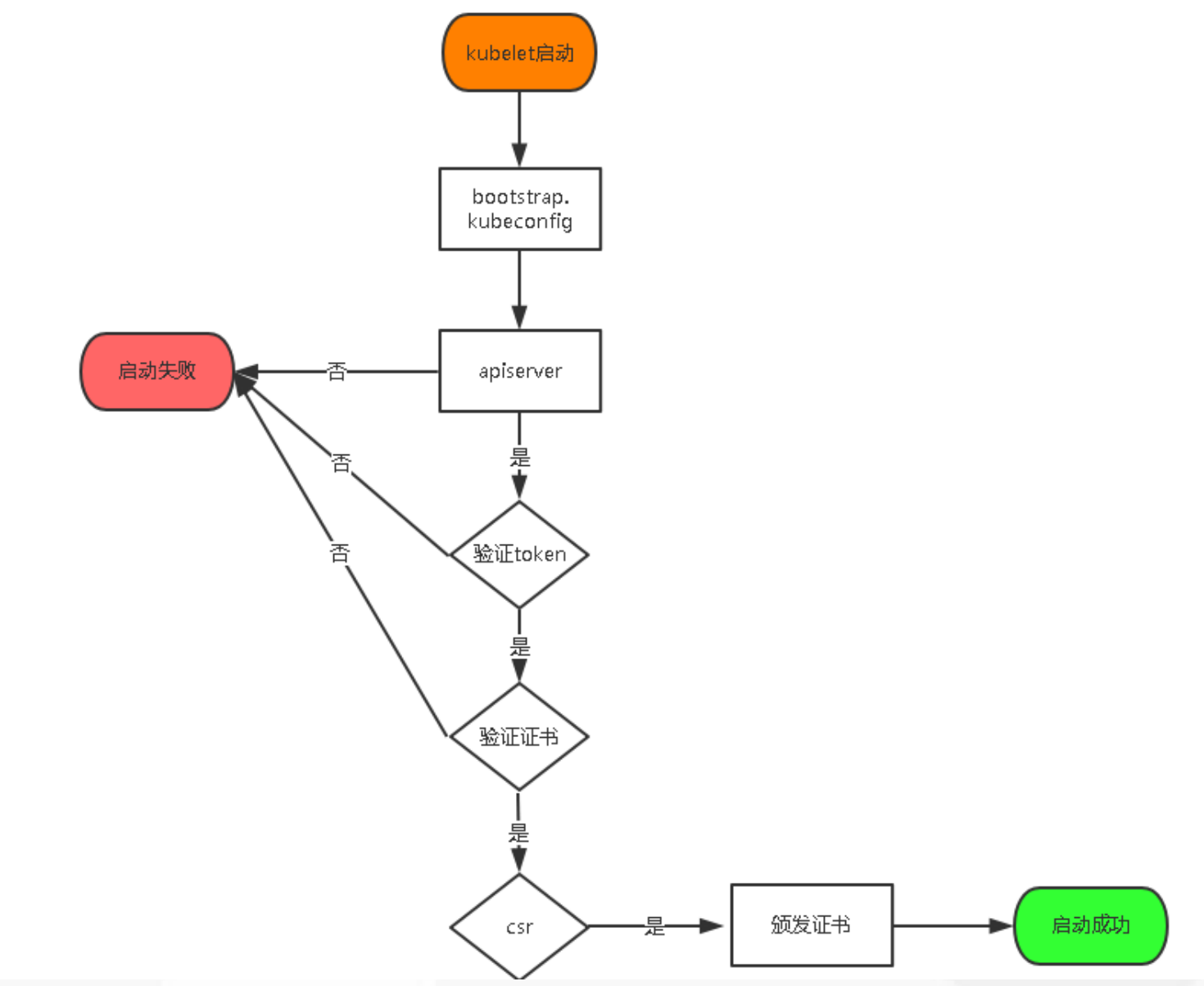
授权 apiserver 访问 kubelet
为提供安全性,kubelet 禁止匿名访问,必须授权才可以。一个常见的表现就是无法通过 kubectl logs 查看 pod 的日志,错误输出类似如下:
bash
Error from server (Forbidden): Forbidden (user=kube-apiserver, verb=get, resource=nodes, subresource=proxy) ( pods/log calico-node-gnh4r)在任意一台 master 节点上执行以下命令进行授权
bash
cat << EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
- pods/log
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kube-apiserver
EOF部署 CNI 网络
Kubernetes 支持多种网络类型,本文将介绍 Calico 网络的安装方法
Github 地址:https://github.com/projectcalico/calico
Calico 官方安装文档:https://docs.tigera.io/calico/latest/getting-started/
Calico 与 Kubernetes 版本兼容性说明:https://docs.tigera.io/calico/latest/getting-started/kubernetes/requirements#kubernetes-requirements
直接执行
bash
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml如果无法下载,那么去github全局搜索calico,点击进入项目,在Releases下下载自己需要的calico版本的离线包(文章以3.27.3版本为例)。不同版本的kubernets需要不同版本的calico,具体对应版本需自行查询。我们解压calico的离线包后会得到很多文件,并不是全部需要。首先将calico.yaml文件上传至服务器,然后使用cat calico.yaml |grep image:命令查看calico所需的镜像包
bash
cat calico.yaml |grep image:这里显示安装calico需要三个镜像,去解压的离线包imgaes文件夹中找到对应的三个离线镜像包文件,这里对应的分别是calico-cni.tar,calico-kube-controllers.tar和calico-node.tar三个离线包,将这三个离线镜像上传至服务器。至此kubernets 1.30版本的calico部署完成,我们查看节点,发现都是Ready
bash
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready control-plane 19m v1.30.0
k8s-master2 Ready control-plane 18m v1.30.0
k8s-master3 Ready control-plane 16m v1.30.0
k8s-node1 Ready <none> 7m3s v1.30.0
k8s-node2 Ready <none> 6m47s v1.30.0下面我们在任意一个 master 节点上执行以下命令创建一个 nginx pod 并暴露端口测试是否可以从外部正常访问。创建nginx deployment
bash
kubectl create deployment web --image=nginx暴露端口
bash
kubectl expose deployment web --port=80 --type=NodePort查看对应的访问端口
bash
kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web NodePort 10.0.0.34 <none> 80:32163/TCP 61s部署 CoreDNS
部署 CoreDNS 主要是为了给 Kubernetes 的 Service 提供 DNS 解析服务,使得程序可以通过 Service 的名称进行访问。DNS 服务监视 Kubernetes API,为每一个 Service 创建 DNS 记录用于域名解析。ClusterIP A 记录格式:<service-name>.<namespace-name>.svc.<domain_suffix>,示例:my-svc.my-namespace.svc.cluster.local
使用 kubeadm 方式部署的 Kubernetes 会自动安装 CoreDNS,二进制部署方式则需要自行安装。从 Github 地址https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/coredns上下载 coredns.yaml.base 文件到任意 master 节点,并重命名为 coredns.yaml。然后参考下方标注修改其中的部分参数
__MACHINE_GENERATED_WARNING__替换为 This is a file generated from the base underscore template file: coredns.yaml.base
__PILLAR__DNS__DOMAIN__或__DNS__DOMAIN__替换为 cluster.local, 若要使用非默认域名如 koenli.net 记得要与 node 节点上 /etc/kubernetes/conf/kubelet-config.yml 文件中的 clusterDomain 参数保持一致,并要调整 api-server 证书中的 hosts 字段值并重新颁发证书
__PILLAR__DNS__MEMORY__LIMIT__或__DNS__MEMORY__LIMIT__替换为 170Mi,此内存限制的值可根据实际环境资源进行调整
__PILLAR__DNS__SERVER__或__DNS__SERVER__替换为 10.0.0.2,此 IP 地址需要与 Node 节点上 /etc/kubernetes/conf/kubelet-config.yml 文件中配置的 clusterDNS 字段的 IP 一致
bash
# This is a file generated from the base underscore template file: coredns.yaml.base
apiVersion: v1
kind: ServiceAccount
metadata:
name: coredns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: Reconcile
name: system:coredns
rules:
- apiGroups:
- ""
resources:
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
priorityClassName: system-cluster-critical
serviceAccountName: coredns
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values: ["kube-dns"]
topologyKey: kubernetes.io/hostname
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
kubernetes.io/os: linux
containers:
- name: coredns
image: registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.11.1
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /ready
port: 8181
scheme: HTTP
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- ALL
readOnlyRootFilesystem: true
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.0.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
- name: metrics
port: 9153
protocol: TCP执行以下命令进行安装
bash
kubectl apply -f coredns.yaml查看 CoreDNS 的 pod 创建情况,待所有 Pod 均为 Running 状态后表示部署完成
bash
watch kubectl get pod -n kube-system在任意 master 节点上执行以下命令创建一个 busybox 容器,在容器中 ping service 的名称看是否可以正常解析出 IP 地址,如果可以则说明 DNS 服务部署成功。
bash
cat > /root/bs.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
EOF
kubectl apply -f /root/bs.yaml
watch kubectl get pods
# 待pod处于Running状态后执行以下命令进入容器中
kubectl exec -ti busybox sh
# 在容器中执行以下命令如果出现类似输出则说明解析正常
/ # nslookup kubernetes
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
/ # exit
# 删除测试容器
kubectl delete -f /root/bs.yamlK8S卸载
注:这里针对的是使用Kubeadm方式安装的Kubernetes集群。以下全部操作都是使用root用户进行,非root用户可以使用sudo,并且全部命令都需要在Kubernetes集群的所有节点分别执行
1、停止K8S,所有节点执行:
bash
systemctl stop kubelet
systemctl stop etcd
systemctl stop docker2、清空K8S集群设置,所有节点执行:
bash
kubeadm reset -f3、删除K8S相关软件,所有节点执行:
列出kube关键字的软件
bash
yum list installed | grep kube卸载相关软件
bash
yum -y remove kube*再次查看确保都卸载完成
bash
[root@k8s-master1 ~]# yum list installed | grep kube
cri-tools.x86_64 1.26.0-0 @kubernetes单独卸载
bash
yum -y remove cri-tools.x86_64最终确认已经完全卸载掉
bash
yum list installed | grep kube4、删除docker,所有节点执行
卸载Docker Engine、CLI、Containerd和Docker合成包
bash
yum -y remove docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin docker-ce-rootless-extras手动删除所有镜像、容器和卷
bash
rm -rf /var/lib/docker
rm -rf /var/lib/containerd5、彻底删除相关文件,在所有节点使用root用户执行以下命令,如果是非root请全部命令前都加上sudo
bash
rm -rvf $HOME/.kube
rm -rvf ~/.kube/
rm -rvf /etc/kubernetes/
rm -rvf /etc/systemd/system/kubelet.service.d
rm -rvf /etc/systemd/system/kubelet.service
rm -rvf /usr/bin/kube*
rm -rvf /etc/cni
rm -rvf /opt/cni
rm -rvf /var/lib/etcd
rm -rvf /var/etcd6、至此已完成了Kubenetes的彻底卸载并清理相关文件的操作,若是不放心可以进行检验。如果以下命令执行后都没有输出,那就说明K8S已经彻底卸载完成
bash
systemctl status docker
systemctl | grep kube
yum list installed | grep kube
yum list installed | docker
rpm -qa | grep kube
rpm -qa | grep docker