基于HuffmanTree的文件压缩以及解压缩小程序
前言
本程序的设计初衷旨在复习,熟悉数组方式创建HuffmanTree,同时练习C++文件操作相关语法,C++声明与定义分离的特性,并尽力实现识别所有特殊字符,在此基础上,模拟实现现在正常软件的压缩和解压缩的最基础功能。事实上,直接真正创建树结构的难度反而低一些,且部分操作会简略不少,也更方便检查,代码中有注释,并且实现的整体难度也不大,这里直接给出源码
源码
HuffmanTree.h
cpp
//思路的话,有两种,一种是直接创建真正的二叉树,但因为这种思路过于简单无趣,暂且搁置,最终决定使用法二:使用vector模拟二叉树
#pragma once
#include<iostream>
#include<unordered_map>
#include<string>
#include<vector>
#include<unordered_set>
//using namespace std;
namespace dzh
{
enum STATUS
{
EMPTY = 1,
FULL = 2
};
//小堆的比较用仿函数(小堆用大于)
struct Compare
{
bool operator()(std::pair<STATUS, std::pair<char, int>> a, std::pair<STATUS, std::pair<char, int>> b);
};
struct HuffmanNode
{
HuffmanNode(int weight, char data, STATUS status = EMPTY, int left = -1, int right = -1, int parent = -1);
int _weight = -1;
int _left = -1;
int _right = -1;
int _parent = -1;
char _data = ' ';
STATUS _status = EMPTY;
};
std::ostream& operator<<(std::ostream& os, const HuffmanNode& t);
class HuffmanTree
{
public:
HuffmanTree(std::string filename);//创建HuffmanTree以及编码表的构造函数
void EnCode(std::string codeFileName);//压缩文件
void DeCode(std::string codeFileName, std::string deCodeFileName);//解压文件
void PrintTree();//打印HuffmanTree的信息
void PrintTable();//打印编码表
size_t UniqueCharCount();//获取唯一字符的个数
size_t SourceCharCount();//获取源文件的字符个数
private:
std::vector<HuffmanNode> _root;
std::unordered_map<char, std::string> _table;
std::unordered_map<std::string, char> _retable;
size_t _uniqueCharCount = 0;
size_t _sourceCharCount = 0;
std::string _fileName = "";
std::unordered_set<std::string> _codeFileName;
};
void Random();//实现的ABCD按给定权值随机生成至文件中的测试用函数
void test1();
void test2();
}HuffmanTree.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS 1
//遇到中文字符直接断言的问题已经解决,原因是微软的isspace函数具备断言检查,详情见同目录下的"C++_char与unsignedchar_强转_字符操作函数相关.cpp"
//而文件操作(包括二进制文件)时就老老实实使用char类型,当需要检查时再用static_cast关键字强转为unsigned char
#include"HuffmanTree.h"
#include<iostream>
#include<queue>
#include<unordered_map>
#include<string>
#include<vector>
#include<fstream>
#include<assert.h>
#include<stack>
#include<unordered_set>
#include<limits>
#include<cctype>//isspace函数所在头文件
#include<random>
#include<algorithm>//shuffle函数所在头文件
using namespace std;
namespace dzh
{
bool Compare::operator()(pair<STATUS, pair<char, int>> a, pair<STATUS, pair<char, int>> b)
{
return a.second.second > b.second.second;
}
HuffmanNode::HuffmanNode(int weight, char data, STATUS status, int left, int right, int parent)
:_weight(weight)
, _left(left)
, _right(right)
, _parent(parent)
, _data(data)
, _status(status)
{
}
ostream& operator<<(ostream& os, const HuffmanNode& t)
{
//使用isspace函数判断空白字符,若为真则输出" "
if (isspace(static_cast<unsigned char>(t._data)))
{
os << "权重:" << t._weight << " 左孩子:" << t._left << " 右孩子:" << t._right << " 父母:" << t._parent << " 字符:" << " " << endl;
}
else
{
os << "权重:" << t._weight << " 左孩子:" << t._left << " 右孩子:" << t._right << " 父母:" << t._parent << " 字符:" << t._data << endl;
}
return os;
}
HuffmanTree::HuffmanTree(string filename)
:_fileName(filename)
{
unordered_map<char, int> m;
// ofstream ofs(filename);
ifstream ifs(filename, ios_base::binary | ios_base::in);
//读取文件,并使用哈希计算每个字符出现的次数
if (ifs.is_open())
{
char c = ' ';
while (ifs.read(reinterpret_cast<char*>(&c), 1))
{
++_sourceCharCount;
++m[c];
}
}
else
{
assert(false);
}
ifs.close();
//注意判断一下文件中没有数据的情况,直接停止程序
if (m.empty())
{
cout << "文件中没有数据!" << endl;
assert(false);
}
_uniqueCharCount = m.size();//将哈希中的size赋值给_uniqueCharCount
//将哈希中的数据入小堆
priority_queue<pair<STATUS, pair<char, int>>, vector<pair<STATUS, pair<char, int>>>, Compare> q;
for (const auto& e : m)
{
q.emplace(pair<STATUS, pair<char, int>>(FULL, e));
}
//将小堆中的数据依次存放入vector,即创建仿二叉树
//此过程共分为两步,第一步是将创建的所有节点全部放入vector
//第二步是为vector中的每个节点找到对应的parentnode
//第一步
while (q.size() > 1)//当堆中数据个数为1时,说明树已经创建完毕了
{
// cout << q.size() << endl;
HuffmanNode n1(q.top().second.second, q.top().second.first, q.top().first);
q.pop();
HuffmanNode n2(q.top().second.second, q.top().second.first, q.top().first);
q.pop();
pair<STATUS, pair<char, int>> parentnode(EMPTY, pair<char, int>(' ', n1._weight + n2._weight));
q.emplace(parentnode);
_root.emplace_back(n1);
_root.emplace_back(n2);
}
assert(!q.empty());
_root.emplace_back(q.top().second.second, q.top().second.first, q.top().first);//将堆中剩下的根节点放到vector中
q.pop();
//第二步
//由于上面使用优先级队列进行vector的插入,所以,现在vector中的数据应是根据weight的值进行从小到大排列的,因此,现在仅需要每次循环都依次访问两个数据
for (size_t i = 0; _root.size() != 0 && i < _root.size() - 1; i += 2)//最先要注意的就是size==0的问题,由于返回值是size_t,所以要极力避免size == 0 && size - 1的情况
{
for (size_t j = i + 2; j < _root.size(); ++j)//由于vector是按照从小到大的顺序排列的,所以直接从i+2的位置开始搜索权重合适且data为空的节点
{
if (_root[j]._weight == _root[i]._weight + _root[i + 1]._weight && _root[j]._status == EMPTY && _root[j]._left == -1 && _root[j]._right == -1)
{
_root[i]._parent = j;
_root[i + 1]._parent = j;
_root[j]._left = i;
_root[j]._right = i + 1;
break;
}
}
}
//建好模拟树后,开始建立编码表与反编码表
_table.reserve(_uniqueCharCount * 4 / 3);//利用_uniqueCharCount提前扩充好哈希表(注意,一般负载因子是0.75,所以这里使用负载因子的倒数),避免后续可能的多次扩充造成的资源浪费
_retable.reserve(_uniqueCharCount * 4 / 3);
string codes = "";
stack<char> sk;
char mid = '0';
//assert(_root.empty());
for (size_t i = 0; i < _root.size(); ++i)
{
const auto& e = _root[i];
//cout << e._data << endl;
if (e._status != EMPTY)
{
//cout << 1 << endl;
int child = i;
int parent = e._parent;
while (parent != -1)
{
if (&_root[(_root)[parent]._left] == &_root[child])//使用地址进行左右节点的比较,先开始使用的data进行比较,但因为中间节点的data均为' ',会导致无法正确区分,想到了可以直接使用地址进行比较
{
mid = '0';
}
else
{
mid = '1';
}
// cout << mid << endl;
sk.emplace(mid);
child = parent;
parent = _root[parent]._parent;
}
while (!sk.empty())
{
codes += sk.top();
// cout << sk.top();
sk.pop();
}
//cout << codes << endl;
_table.emplace(e._data, codes);
_retable.emplace(codes, e._data);
codes = "";
}
}
}
//使用二进制形式写入01,是最终的结果函数
void HuffmanTree::EnCode(string codeFileName)
{
//一个源文件可能需要被压缩成多份,因此使用哈希存储压缩文件的文件名,方便解压时判断文件是否是被该类压缩的
while (codeFileName == _fileName)
{
cout << "不能将源文件压缩至源文件,请重新输入一个非源文件的文件名!";
cin >> codeFileName;
}
_codeFileName.emplace(codeFileName);
ifstream ifs(_fileName, ios_base::binary | ios_base::in);
ofstream ofs(codeFileName, ios_base::binary | ios_base::out);
char ch = ' ';//用于读取源文件中的字符
unsigned char buf = 0;//用于记录二进制位
string s = "";
int count = 7;//用于记录当前char未被使用的比特位数(范围为0~7)
while (ifs.read(reinterpret_cast<char*>(&ch), 1))
{
s = _table[ch];
for (const auto& e : s)
{
size_t bitValue = e - '0';
buf |= (bitValue << count);
--count;
if (count == -1)
{
ofs.write(reinterpret_cast<const char*>(&buf), 1);
buf = 0;
count = 7;
}
}
}
//记得处理最后存储在buf中但比特位还未使用完全的数据
if (count != 7)
{
ofs.write(reinterpret_cast<const char*>(&buf), 1);
}
ofs.close();
ifs.close();
cout << "压缩成功!" << endl;
}
void HuffmanTree::DeCode(string codeFileName, string deCodeFileName)
{
if (_codeFileName.find(codeFileName) == _codeFileName.end())
{
cout << "所解压的文件不是由当前对象压缩的!" << endl;
return;
}
ifstream ifs(codeFileName, ios_base::binary | ios_base::in);
assert(ifs.is_open());
ofstream ofs(deCodeFileName, ios_base::out);
char ch = ' ';//用于将转码后的字符写入文件
unsigned char buf = 0;//用于记录二进制位
string decodedOutput = "";//用于读取二进制中的比特位
int count = 7;//用于记录当前已经读取完毕的比特位(范围为0~7)
size_t num = 0;//记录成功转换的字符个数,与压缩时的总字数对比,相等则停止转换
while (ifs.read(reinterpret_cast<char*>(&buf), 1))
{
while (count > -1)
{
if (num == _sourceCharCount)//读取到最后一个字节,可能出现bit中遇到填充用的二进制的0的情况,此时仅需break内部循环即可,因为此时已是最后一次外部循环
{
break;
}
char binNum = ((buf >> count) & 1) + '0';//这里一定注意运算符优先级问题,要把1放到小括号中,先与&运算,再+
--count;
decodedOutput += binNum;
if (_retable.find(decodedOutput) != _retable.end())
{
ch = (_retable)[decodedOutput];
// cout << ch << " ";
ofs << ch;
ch = ' ';
decodedOutput = "";
++num;
}
}
count = 7;
}
if (ifs.eof())
{
cout << "文件解压成功!" << endl;
}
else if (ifs.fail())
{
cout << "文件解压失败!" << endl;
}
else if (ifs.bad())
{
cout << "ifstream出现系统级错误!" << endl;
}
else
{
assert(false);
}
}
void HuffmanTree::PrintTree()
{
for (size_t i = 0; i < _root.size(); ++i)
{
cout << "当前节点的序号为:" << i << " " << _root[i] << endl;
}
}
void HuffmanTree::PrintTable()
{
for (const auto& e : _table)
{
//使用isspace函数判断空白字符,若为真则输出" "
if (isspace(static_cast<unsigned char>(e.first)))
{
cout << "字符为:" << " " << " 编码为:" << e.second << endl;
continue;
}
cout << "字符为:" << e.first << " 编码为:" << e.second << endl;
}
}
size_t HuffmanTree::UniqueCharCount()
{
return _uniqueCharCount;
}
size_t HuffmanTree::SourceCharCount()
{
return _sourceCharCount;
}
void Random()
{
std::ofstream ofs("chartest.txt", std::ios_base::out);
std::random_device rd;
std::mt19937 gen(rd());
int num1, num2, num3, num4;
cout << "请依次输入A,B,C,D的权值:";
cin >> num1 >> num2 >> num3 >> num4;
std::unordered_map<char, int> um{ {'A', num1}, {'B', num2}, {'C', num3}, {'D', num4} };
std::vector<char> vc;
for(const auto& e : um)
{
vc.insert(vc.end(), e.second, e.first);
}
std::shuffle(vc.begin(), vc.end(), gen);
for (const auto& e : vc)
{
ofs << e;
}
//RAII
}
void test1()
{
Random();
cin.ignore(numeric_limits<streamsize>::max(), '\n');
HuffmanTree ht("chartest.txt");
cout << "总字符数为:" << ht.SourceCharCount() << endl;
cout << "HuffmanTree为:" << endl;
ht.PrintTree();
cout << "编码表为:" << endl;
ht.PrintTable();
cout << "请输入压缩文件的文件名:" << endl;
string codeFileName;
cin >> codeFileName;
cin.clear();
cin.ignore(numeric_limits<streamsize>::max(), '\n');
ht.EnCode(codeFileName);
cout << "请输入需要解压的文件的文件名以及接收解压后文件的文件名:" << endl;
string deCodeFileName;
cin >> codeFileName >> deCodeFileName;
cin.clear();
cin.ignore(numeric_limits<streamsize>::max(), '\n');
ht.DeCode(codeFileName, deCodeFileName);
}
void test2()
{
Random();
HuffmanTree ht("HuffmanTree_test.txt");
string codeFileName;
ht.PrintTable();
ht.PrintTree();
ht.EnCode("zip.txt");
ht.DeCode("zip.txt", "yuanwenjian.txt");
cout << ht.SourceCharCount() << "\n";
}
}test.cpp
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include"HuffmanTree.h"
#include<iostream>
using namespace std;
using namespace dzh;
int main()
{
try
{
test1();
//test2();
return 0;
}
catch (const std::bad_alloc& errid)
{
cout << "内存申请失败!" << endl;
}
catch (...)
{
cout << "出现未知异常!" << endl;
}
}运行结果
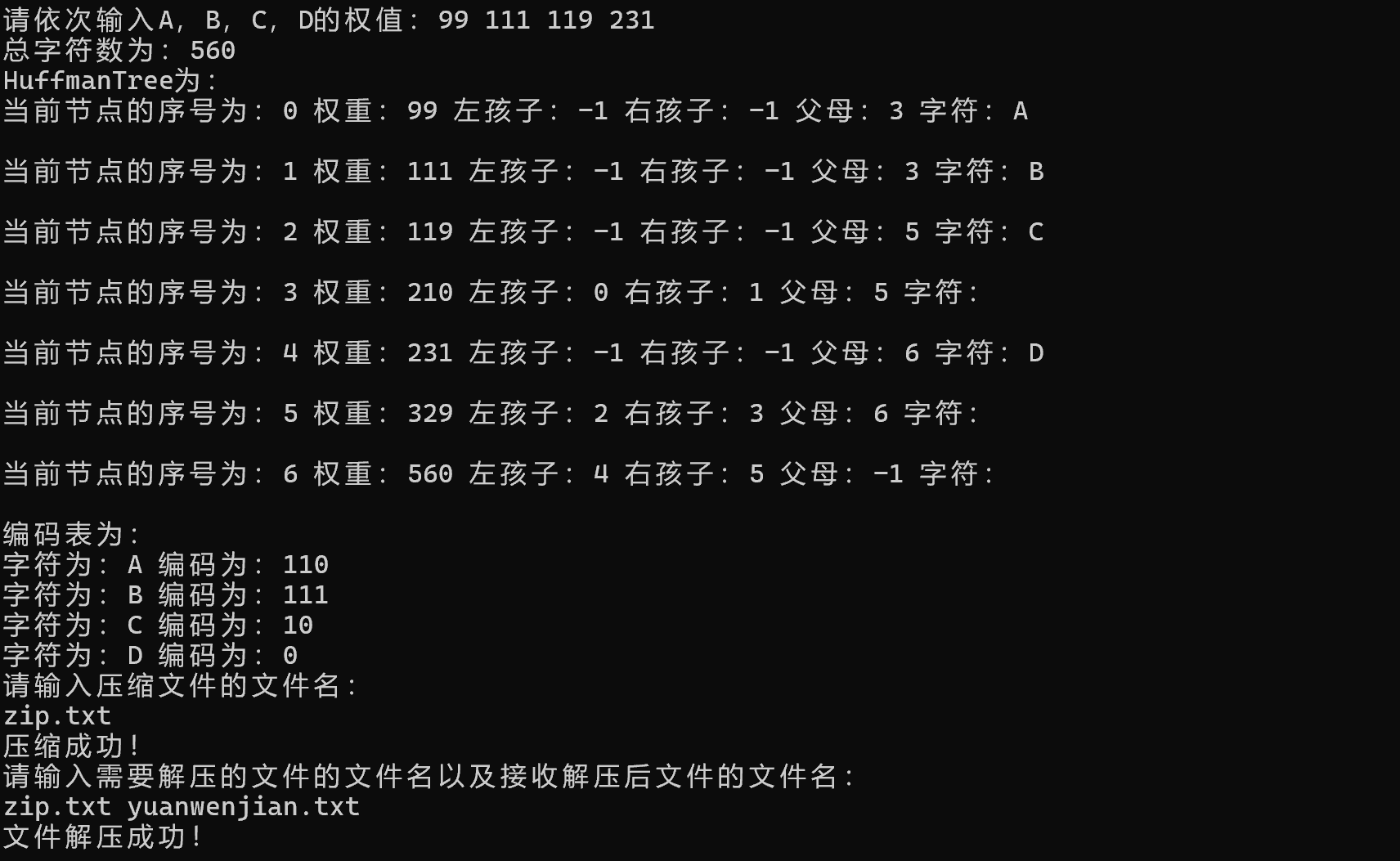
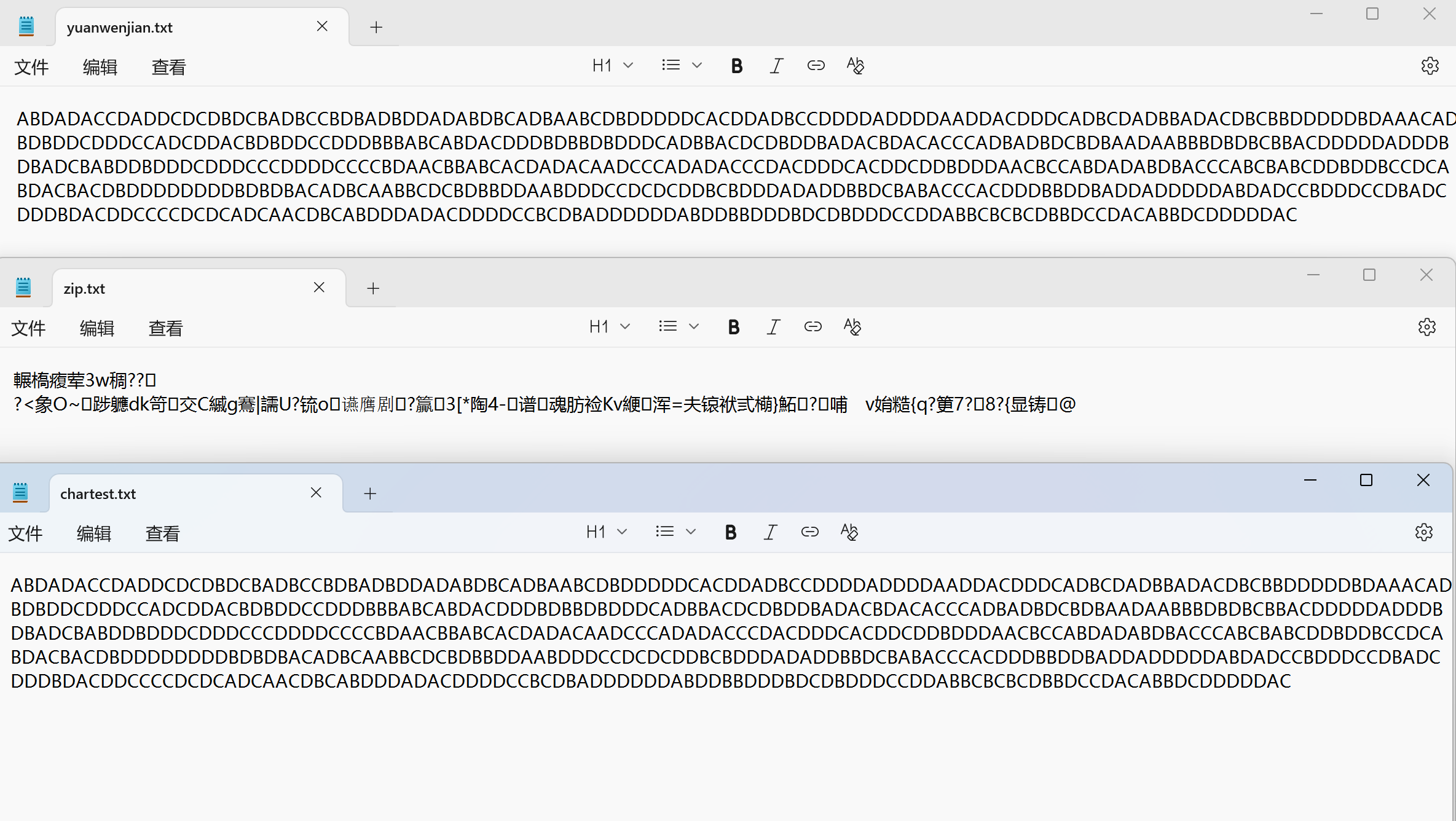
可以发现,程序运行成功,结果也正确
注意点
- 程序运行第一个让输入的程序名是压缩文件的文件名,就是打算把源文件压缩到哪里,就像正常压缩软件,都是把源文件压缩成一个新文件,而非直接覆盖源文件
- 比如说源文件是test.txt,那可以把源文件压缩到zip.txt,然后,第二个输入是把压缩文件zip解压缩到一个如yuanwenjian.txt的新文件,然后程序的行为就是把压缩文件zip.txt解压到yuanwenjian.txt
- 使用时,
特别需要注意文件里面的换行符以及制表符等空白字符,这种字符虽然在文件里面可能不容易发现,但是仍然会被编码,相应的进行压缩以及解压缩操作 - 对于中文字符,该程序也是可以进行处理的,不过,由于每个中文字符在windows下占据的是3字节,所以程序计算一个中文字符会按照+3来计算,要想解决这个问题,似乎需要编码相关的知识,由于目前这样计算字节,程序也不算错,且作者还未学习编码相关知识,就先这样放着了
结语
总结:通过这个项目,作者理解了Huffman编码的原理和C++文件操作的基础使用,虽然程序在极端情况下(如超大文件)还有优化空间,但核心功能已经完备。
欢迎交流:如果你在实现过程中遇到任何问题,或者有更好的优化思路,欢迎在评论区留言讨论!