前言:你的电脑真的"快"吗?

大家好,我是你们的老朋友。
最近看到了一个疑问:"我买了个3.0GHz的CPU,为什么跑代码还是比隔壁老王那台2.5GHz的慢?
其实,衡量一台计算机的性能,绝不仅仅是看一个主频那么简单。今天这篇博客,我们就基于《计算机组成原理》的核心知识点,来一次地毯式的扫盲。我们将从存储器、CPU、到整体系统架构,逐一拆解那些看似高大上实则很接地气的性能指标。
不管你是为了应付期末考试、准备考研,还是单纯想在买电脑时不再被忽悠,这篇文章都值得你收藏反复研读。
一、存储器的容量指标
计算机的"快"离不开"大"。存储器作为数据的临时或永久驻扎地,其容量大小直接决定了系统能吞吐多少数据。我们先从最基础的**主存储器(内存)**说起。
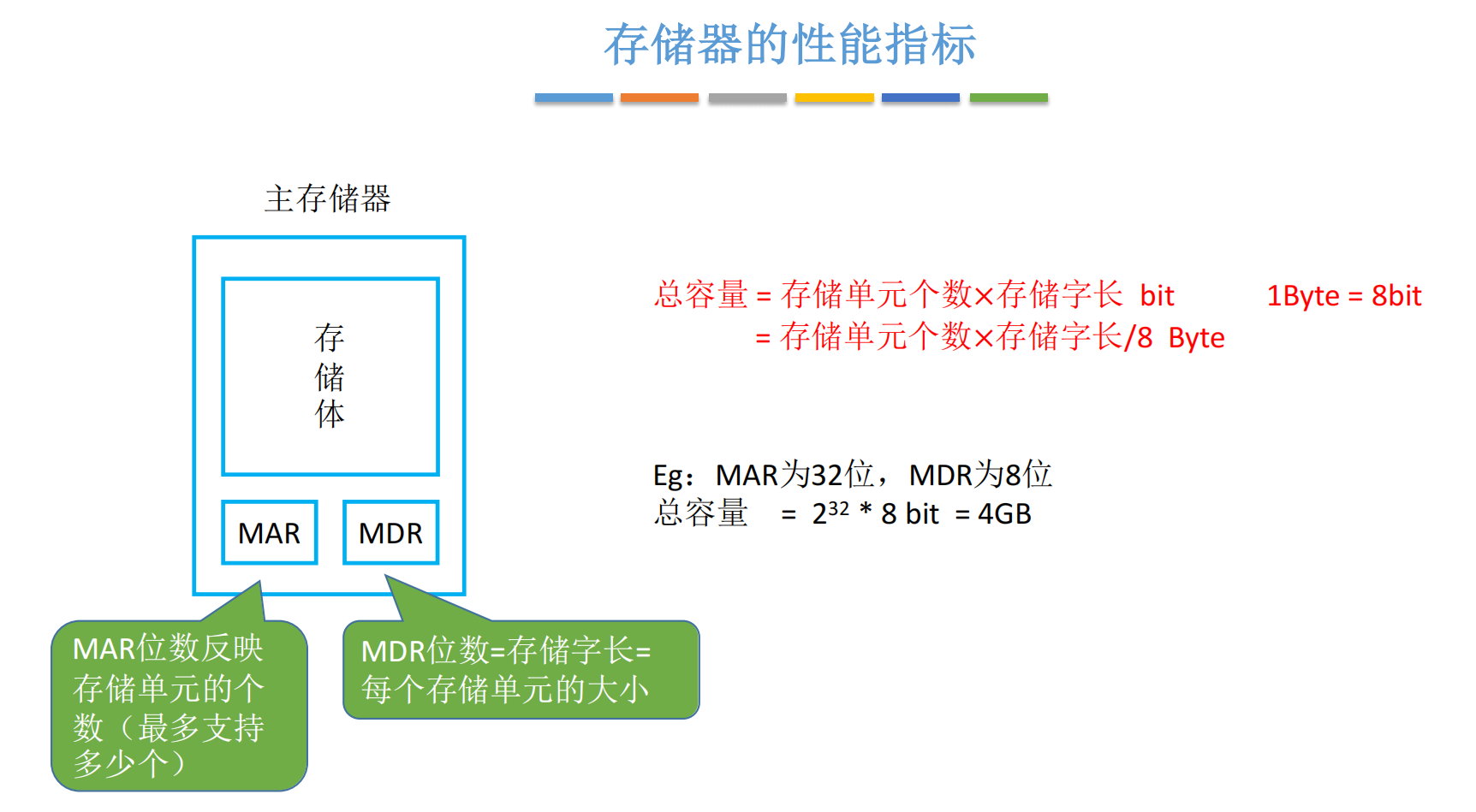
1.1 核心硬件:MAR 与 MDR
在之前的文章中,我们介绍了冯·诺依曼架构的五大部件。其中,主存储器的容量实际上是由两个关键寄存器决定的:
-
MAR (Memory Address Register):地址寄存器
-
MDR (Memory Data Register):数据寄存器
我们说过MAR,也就是地址寄存器的位数可以反映出这个存储体里边总共有多少个存储单元。另外,MDR数据寄存器的位数可以反映出每一个存储单元可以存放多少个二进制比特位.
所以我们只需要利用这样的两个信息就可以算出整个存储器它总共可以存放多少个二进制比特位,那如果把比特再除以八的话,就可以转换成字节.
容量计算公式
存储器的总容量(Capacity)可以通过以下公式计算:
总容量=存储单元个数×存储字长\text{总容量} = \text{存储单元个数} \times \text{存储字长}总容量=存储单元个数×存储字长
代入硬件参数:
总容量=2MAR位数×MDR位数\text{总容量} = 2^{\text{MAR位数}} \times \text{MDR位数}总容量=2MAR位数×MDR位数
假设一个主存储器的 MAR 为 32 位,MDR 为 8 位,求它的总容量。
-
计算单元数 :MAR = 32位,意味着它能表示 2322^{32}232 个不同的地址。
-
计算单体容量:MDR = 8位,意味着每个地址存 8 bit(即 1 Byte)。
-
总容量:
232×8 bit=4 GB2^{32} \times 8 \text{ bit} = 4 \text{ GB}232×8 bit=4 GB
这里有一个细节:虽然理论上限是 4GB,但在实际硬件设计中,这只是寻址空间的最大值,实际安装的内存可能只有 1GB 或 2GB。但在做题时,除非题目另有说明,我们通常按最大理论值计算。
1.2 K、M、G 的"两副面孔"
这是平常最容易出错的地方!单位简写一样,但含义可能完全不同。
-
场景 A:描述存储容量、文件大小
-
此时,K=210=1024K = 2^{10} = 1024K=210=1024。
-
例如:1 KB=1024 Bytes1 \text{ KB} = 1024 \text{ Bytes}1 KB=1024 Bytes。
-
进率是 1024。
-
-
场景 B:描述传输速率、频率、时钟速度
-
此时,k=103=1000k = 10^3 = 1000k=103=1000。
-
例如:CPU主频 3GHz,这里的 G 是 10910^9109;网速 100Mbps,这里的 M 是 10610^6106。
-
进率是 1000。
-
注意区分大小写 :在严格的学术表达中,描述速率时通常用小写 kkk(如 kbps),描述容量用大写 KKK(如 KB),但现在的很多题目和资料容易混用。核心判断标准是:看它是在存东西(容量),还是在跑东西(速度)。
二、CPU 的性能指标
买 CPU 时,大家第一眼看的就是"主频"。比如 Intel i9-13900K 的最大睿频可达 5.8GHz。这个数字到底代表什么?

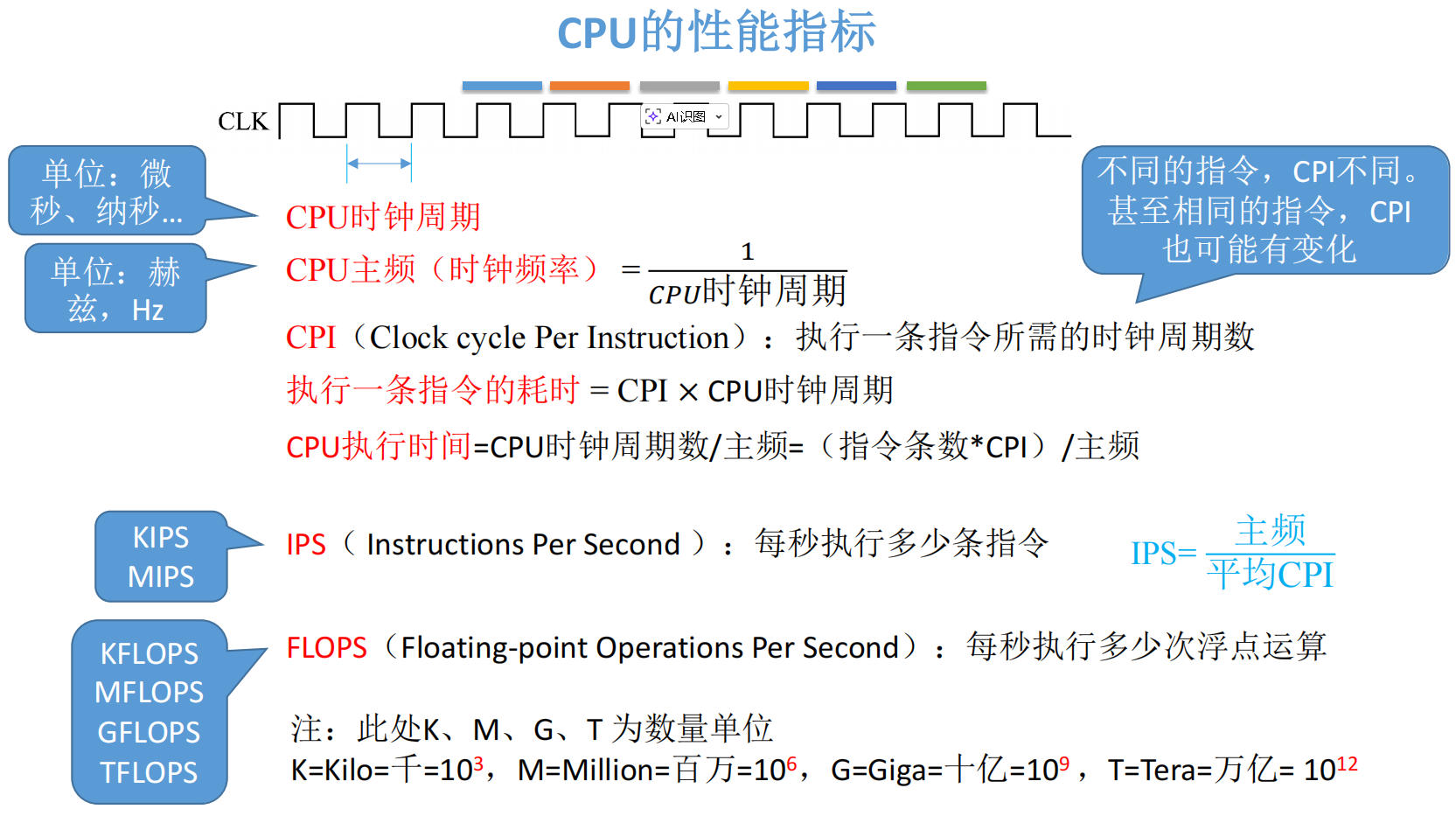
2.1 主频与时钟周期
CPU 内部流淌着数字脉冲信号,你可以把它看作是 CPU 的"心跳":

-
主频 (fff):每秒钟心跳的次数,数字脉冲信号的振荡频率。单位是赫兹(Hz)。
-
时钟周期 (TTT) :跳动一次所花费的时间,即单个脉冲信号的时间⻓度。单位通常是微秒(μs\mu sμs)或纳秒(nsnsns)。
主频又可以称为时钟频率,它的单位是Hz。主频等于10赫兹的意思就是说:每秒钟有十个脉冲信号
公式关系:
f=1Tf = \frac{1}{T}f=T1
或者
T=1fT = \frac{1}{f}T=f1
把 CPU 工作就像是在做课间操:
- 脉冲信号就是那个喊口号的人:"一二三四,二二三四......"
- 主频就是喊口号的语速。喊得越快,大家的动作节奏就越快。
- 动作就是指令。有的动作(指令)简单,喊一声"一"就做完了;有的动作复杂(比如跳跃运动),可能需要喊"一二三四"四个节拍才能做完。
同架构下,一个CPU的主频越⾼,其性能越强,但这并⾮决定CPU性能高低的唯⼀因素。
2.2 核心指标:CPI (Cycles Per Instruction)
单纯看主频是不够的。如果老王喊口号特别快(主频高),但他每做一个动作都需要喊100次口号;而你喊得慢,但每喊一次口号就能完成一个动作,最后谁做得快还不一定呢。
这就引入了 CPI ------ 执行一条指令所需的时钟周期数。
一般题目给我们的CPI都是一个平均值。
不同的指令,复杂度天差地别:
-
取数指令 (Load):可能需要访问内存,步骤繁琐,假设需要 9 个周期。
-
乘法指令 (Mul):运算复杂,假设需要 11 个周期。
-
加法指令 (Add):非常简单,可能 1-2 个周期搞定。
-
系统状态:如果内存当前很忙(负荷大),CPU 取数时还得排队等待,这也增加了周期数。
所以,我们谈论 CPI 时,通常指 平均 CPI。
关于CPI,有以下推导链条:
-
程序总指令数 :III
-
平均 CPI :CPICPICPI
-
总时钟周期数 :I×CPII \times CPII×CPI
-
CPU 执行时间 (tcput_{cpu}tcpu):
tcpu=总周期数×时钟周期长度=I×CPIft_{cpu} = \text{总周期数} \times \text{时钟周期长度} = \frac{I \times CPI}{f}tcpu=总周期数×时钟周期长度=fI×CPI
如果有以下题目
某 CPU 主频为 1000 Hz(为了好算,实际没这么慢),运行一个包含 100 条指令的程序。已知该程序的平均 CPI = 3。求程序执行时间。
解题思路:
- 计算总共需要的"心跳"次数:
100 条指令×3 (周期/条)=300 个周期100 \text{ 条指令} \times 3 \text{ (周期/条)} = 300 \text{ 个周期}100 条指令×3 (周期/条)=300 个周期
- 计算一次"心跳"的时间:
T=1f=11000 秒=1 msT = \frac{1}{f} = \frac{1}{1000} \text{ 秒} = 1 \text{ ms}T=f1=10001 秒=1 ms
- 计算总时间:
300×1 ms=300 ms=0.3 s300 \times 1 \text{ ms} = 300 \text{ ms} = 0.3 \text{ s}300×1 ms=300 ms=0.3 s
指令的条数还有平均每执行一条指令所需要的时钟周期数,这两个数值乘起来就刚好等于总共需要多少个CPU时钟周期,然后再乘以主频分之一就可以得到最终的耗时
2.3 进阶指标:IPS 与 FLOPS
除了算时间,我们还想知道"每秒能干多少活"。
1. IPS (Instructions Per Second)
代表每秒可以执行多少条指令。
IPS=主频平均CPIIPS = \frac{\text{主频}}{\text{平均CPI}}IPS=平均CPI主频
如果单位为MIPS (Million IPS),就代表每秒可以执行百万条指令。(这里的M就是百万的意思,即
106{10^6}106
MIPS=fCPI×106MIPS = \frac{f}{CPI \times 10^6}MIPS=CPI×106f
(注意:这里的 fff 如果单位是 Hz,分母要除以 10610^6106;如果 fff 也就是 MHz,则直接除以 CPI)
2. FLOPS (Floating-point Operations Per Second)
每秒执行多少次浮点运算。
这是衡量科学计算能力(如气象预测、核爆模拟、AI训练)的关键指标。
-
MFLOPS (10610^6106)
-
GFLOPS (10910^9109)
-
TFLOPS (101210^{12}1012)
-
PFLOPS (101510^{15}1015)
在 IPS 和 FLOPS 中,前缀 K, M, G, T 全部遵循 10310^3103 进率!
1 MIPS=1,000,000 条指令/秒1 \text{ MIPS} = 1,000,000 \text{ 条指令/秒}1 MIPS=1,000,000 条指令/秒
不要和存储容量的 2202^{20}220 搞混了!
三、系统整体性能
CPU 再快,如果数据运不过来,也是白搭。这就要看系统的整体"路况"。
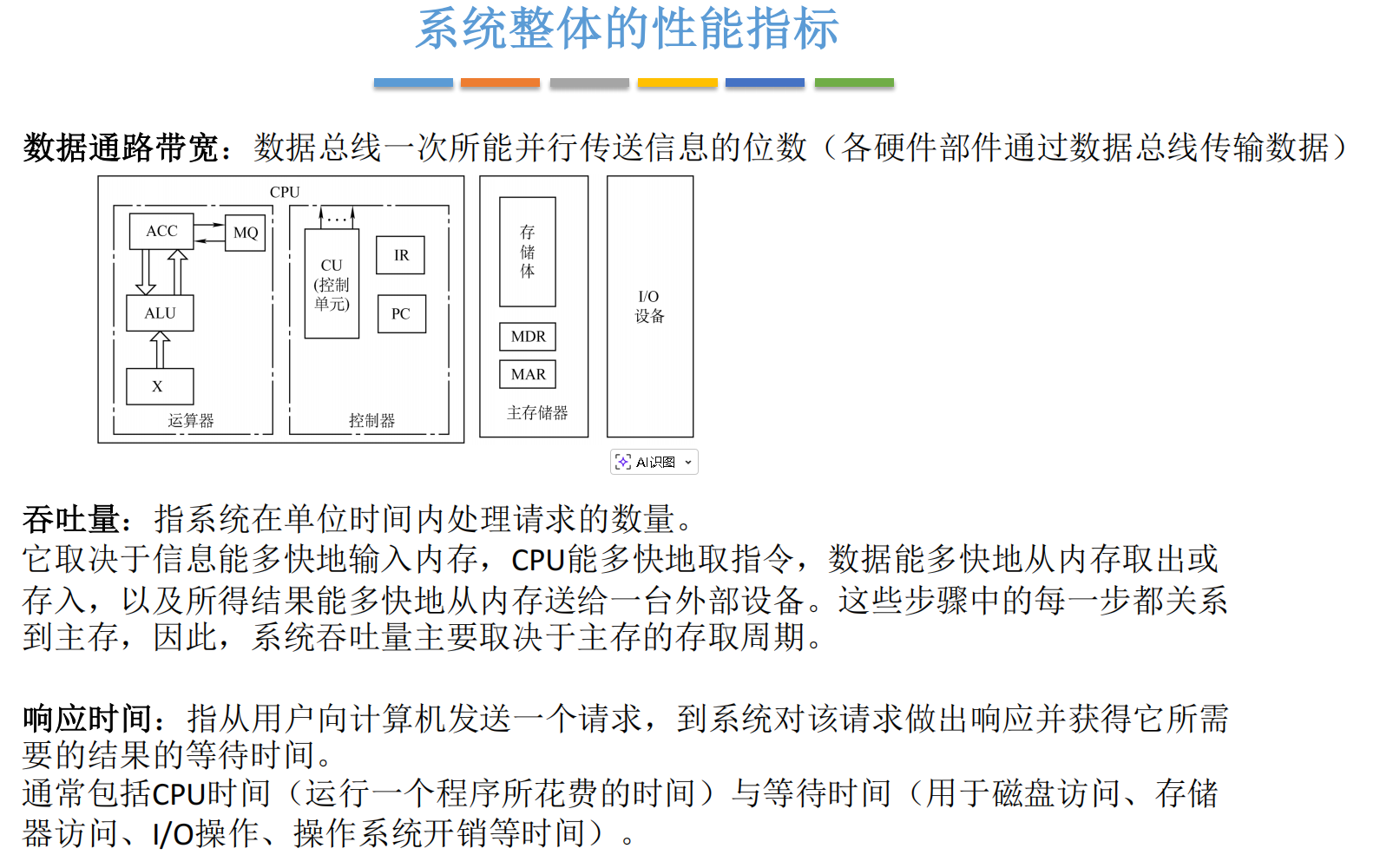
3.1 数据通路带宽 (Data Path Bandwidth)
定义:数据总线一次能并行传送信息的位数。
类比:这就像公路的车道数。
-
8位带宽 = 单车道
-
64位带宽 = 8车道高速公路
这个指标指的是数据总线一次可以并行的、传送多少个二进制信息位
我们的CPU和内存,还有内存和IO设备,它们之间的信息传输都是通过数据总线来进行的。
比如说有一台计算机,它的数据通路带宽为八个比特的话,那要从存储体里边读出16个比特的数据,把它读到CPU里边,就需要进行两次的数据传输,每一次只能传送八个比特,那进行两次传输肯定要比进行一次要更慢,所以数据通路的带宽会直接的影响到各个硬件部件之间数据传输的一个效率。
3.2 吞吐量 (Throughput)
定义:单位时间内处理请求的数量。
场景解析:
-
对于 CPU:每秒执行多少指令。
-
对于 淘宝服务器:每秒处理多少个 HTTP 请求。
-
对于 食堂阿姨:每秒能给多少个学生打完饭。
吞吐量是一个宏观指标,取决于系统中最慢的那个环节(木桶效应),在不同的场景,我们需要结合具体的事例来理解。
决定因素:
- 信息输⼊内存的速度
- CPU取指令速度
- 内存存取数据速度
- 结果输出到外部设备的速度
3.3 响应时间 (Response Time)
定义:从用户发起请求到系统给出第一次响应的时间。
公式:
响应时间=CPU时间+等待时间+IO时间+...\text{响应时间} = \text{CPU时间} + \text{等待时间} + \text{IO时间} + \dots响应时间=CPU时间+等待时间+IO时间+...
比如你在电脑上点右键,从按下鼠标微动开关,到屏幕上弹出菜单的这几毫秒,就是响应时间。SSD 硬盘之所以比机械硬盘快,很大程度上是因为它极大地缩短了 IO 的响应时间。
比如说你给你的朋友发送一条信息,那一直到你接收到他的回复为止。这段时间就是你的朋友接收到你的这个请求之后,所需要的一个响应时间,那对于计算机来说,影响这个响应时间的因素也有很多。
四、动态测试------基准程序 (Benchmarks)
前面说的都是静态指标。但现实中,厂家会不会"虚标"?架构会不会影响效率?这时候就需要基准程序(俗称"跑分软件")。
4.1 什么是基准程序?
其实就是一段设计好的、包含各种指令(加减乘除、访存、逻辑运算)的代码。
- 鲁大师 、Geekbench 、3DMark 、Cinebench 本质上都是基准程序。
- 它们模拟真实的使用场景,记录运行时间或得分。
4.2 灵魂三问
在学习性能指标时,这三个反直觉的问题最容易让人掉坑:

Q1:主频高的 CPU 一定比主频低的快吗?
❌ 答案:不一定。
理由:
速度∝fCPI\text{速度} \propto \frac{f}{CPI}速度∝CPIf
如果 CPU A 主频 2GHz,但 CPI=10(平均10个周期做一条指令),那么它每秒只能做 0.2G 条指令。
如果 CPU B 主频 1GHz,但 CPI=1(平均1个周期做一条指令),那么它每秒能做 1G 条指令。
结论:B 虽然主频低,但效率高,速度反而快 5 倍!
Q2:主频相同,CPI 也相同,性能就一定一样吗?
❌ 答案:不一定。
理由:指令集不同。
CPU A 支持硬件乘法指令,一步到位。
CPU B 不支持乘法,需要用 10 次加法来模拟一次乘法。
虽然物理指标一样,但做同样一件事情,B 需要的指令条数(Instruction Count)暴增,导致变慢。
Q3:跑分软件分高,机器就一定好用吗?
❌ 答案:不一定。
理由:场景不匹配。
用测试显卡的程序(大量浮点和图像指令)去测一台专门做数据库查询的服务器(大量整数和访存指令),即使显卡分再高,对数据库性能也毫无参考价值。这就是为什么有"高分低能"的说法。
随着 AI 和超算的发展,T (Tera) 都不够用了。所以增加了更大的单位,大家需要混个眼熟,由小到大排列:
-
K (Kilo) - 10310^3103
-
M (Mega) - 10610^6106
-
G (Giga) - 10910^9109
-
T (Tera) - 101210^{12}1012
-
P (Peta) - 101510^{15}1015 (千万亿次)
-
E (Exa) - 101810^{18}1018 (百亿亿次)
-
Z (Zetta) - 102110^{21}1021 (十万亿亿次)
我国的"神威·太湖之光"超级计算机,峰值性能约为 125 PFLOPS(每秒 12.5 亿亿次浮点运算)。如果用旧单位写,那就是 1.25×10171.25 \times 10^{17}1.25×1017 次,太麻烦了,用 P 就简洁得多。
总结
今天我们系统地梳理了计算机性能的度量指标,重点内容浓缩如下:
-
存储容量 :2MAR×MDR2^{\text{MAR}} \times \text{MDR}2MAR×MDR。记住容量算 2102^{10}210,速度算 10310^3103。
-
CPU时间 :这是万恶之源,公式 I×CPIf\frac{I \times CPI}{f}fI×CPI 必须刻在DNA里。
-
辩证思维:不要迷信单一指标(主频论),要看综合表现(执行时间)。
看到这里,下次再有人跟你吹嘘"我这电脑主频 5.0GHz 宇宙无敌"的时候,你就可以微微一笑,反手问他一句:"哦?那你的 CPI 是多少?浮点运算能力几个 GFLOPS 啊?"
计算机组成原理看似枯燥,其实全是逻辑之美。今天的"避坑指南"希望能帮大家把地基打牢。
别光学不练,赶紧去把文中的公式在草稿纸上推导一遍! 觉得有用的话,点个关注不迷路,我是你们的老朋友,我们要一起在技术的海洋里"兴风作浪"!希望本篇内容能对各位有用,我们下篇见!